Start at 0.4.2 of OpenCompass
This commit is contained in:
commit
8339154e58
|
|
@ -0,0 +1,5 @@
|
||||||
|
[codespell]
|
||||||
|
skip = *.ipynb
|
||||||
|
count =
|
||||||
|
quiet-level = 3
|
||||||
|
ignore-words-list = nd, ans, ques, rouge, softwares, wit
|
||||||
|
|
@ -0,0 +1,135 @@
|
||||||
|
.DS_Store
|
||||||
|
output_*/
|
||||||
|
outputs/
|
||||||
|
scripts/
|
||||||
|
icl_inference_output/
|
||||||
|
.vscode/
|
||||||
|
tmp/
|
||||||
|
configs/eval_subjective_alignbench_test.py
|
||||||
|
configs/openai_key.py
|
||||||
|
configs/secrets.py
|
||||||
|
configs/datasets/log.json
|
||||||
|
configs/eval_debug*.py
|
||||||
|
configs/viz_*.py
|
||||||
|
configs/**/*_bkup.py
|
||||||
|
opencompass/**/*_bkup.py
|
||||||
|
data
|
||||||
|
work_dirs
|
||||||
|
outputs
|
||||||
|
models/*
|
||||||
|
configs/internal/
|
||||||
|
# Byte-compiled / optimized / DLL files
|
||||||
|
__pycache__/
|
||||||
|
*.py[cod]
|
||||||
|
*$py.class
|
||||||
|
*.ipynb
|
||||||
|
|
||||||
|
# C extensions
|
||||||
|
*.so
|
||||||
|
|
||||||
|
# Distribution / packaging
|
||||||
|
.Python
|
||||||
|
build/
|
||||||
|
develop-eggs/
|
||||||
|
dist/
|
||||||
|
downloads/
|
||||||
|
eggs/
|
||||||
|
.eggs/
|
||||||
|
lib/
|
||||||
|
lib64/
|
||||||
|
parts/
|
||||||
|
sdist/
|
||||||
|
var/
|
||||||
|
wheels/
|
||||||
|
*.egg-info/
|
||||||
|
.installed.cfg
|
||||||
|
*.egg
|
||||||
|
MANIFEST
|
||||||
|
|
||||||
|
# PyInstaller
|
||||||
|
# Usually these files are written by a python script from a template
|
||||||
|
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||||
|
*.manifest
|
||||||
|
*.spec
|
||||||
|
|
||||||
|
# Installer logs
|
||||||
|
pip-log.txt
|
||||||
|
pip-delete-this-directory.txt
|
||||||
|
|
||||||
|
# Unit test / coverage reports
|
||||||
|
htmlcov/
|
||||||
|
.tox/
|
||||||
|
.coverage
|
||||||
|
.coverage.*
|
||||||
|
.cache
|
||||||
|
nosetests.xml
|
||||||
|
coverage.xml
|
||||||
|
*.cover
|
||||||
|
.hypothesis/
|
||||||
|
.pytest_cache/
|
||||||
|
|
||||||
|
# Translations
|
||||||
|
*.mo
|
||||||
|
*.pot
|
||||||
|
|
||||||
|
# Django stuff:
|
||||||
|
*.log
|
||||||
|
local_settings.py
|
||||||
|
db.sqlite3
|
||||||
|
|
||||||
|
# Flask stuff:
|
||||||
|
instance/
|
||||||
|
.webassets-cache
|
||||||
|
|
||||||
|
# Scrapy stuff:
|
||||||
|
.scrapy
|
||||||
|
|
||||||
|
.idea
|
||||||
|
|
||||||
|
# Auto generate documentation
|
||||||
|
docs/en/_build/
|
||||||
|
docs/zh_cn/_build/
|
||||||
|
|
||||||
|
# .zip
|
||||||
|
*.zip
|
||||||
|
|
||||||
|
# sft config ignore list
|
||||||
|
configs/sft_cfg/*B_*
|
||||||
|
configs/sft_cfg/1B/*
|
||||||
|
configs/sft_cfg/7B/*
|
||||||
|
configs/sft_cfg/20B/*
|
||||||
|
configs/sft_cfg/60B/*
|
||||||
|
configs/sft_cfg/100B/*
|
||||||
|
|
||||||
|
configs/cky/
|
||||||
|
configs/_internal_legacy*
|
||||||
|
# in case llama clone in the opencompass
|
||||||
|
llama/
|
||||||
|
|
||||||
|
# in case ilagent clone in the opencompass
|
||||||
|
ilagent/
|
||||||
|
|
||||||
|
# ignore the config file for criticbench evaluation
|
||||||
|
configs/sft_cfg/criticbench_eval/*
|
||||||
|
|
||||||
|
# path of turbomind's model after runing `lmdeploy.serve.turbomind.deploy`
|
||||||
|
turbomind/
|
||||||
|
|
||||||
|
# cibench output
|
||||||
|
*.db
|
||||||
|
*.pth
|
||||||
|
*.pt
|
||||||
|
*.onnx
|
||||||
|
*.gz
|
||||||
|
*.gz.*
|
||||||
|
*.png
|
||||||
|
*.txt
|
||||||
|
*.jpg
|
||||||
|
*.json
|
||||||
|
*.jsonl
|
||||||
|
*.csv
|
||||||
|
*.npy
|
||||||
|
*.c
|
||||||
|
|
||||||
|
# aliyun
|
||||||
|
core.*
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
assign:
|
||||||
|
issues: enabled
|
||||||
|
pull_requests: disabled
|
||||||
|
strategy:
|
||||||
|
# random
|
||||||
|
daily-shift-based
|
||||||
|
scedule:
|
||||||
|
'*/1 * * * *'
|
||||||
|
assignees:
|
||||||
|
- bittersweet1999
|
||||||
|
- liushz
|
||||||
|
- MaiziXiao
|
||||||
|
- acylam
|
||||||
|
- tonysy
|
||||||
|
|
@ -0,0 +1,123 @@
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
tests/data/|
|
||||||
|
tests/dataset/|
|
||||||
|
opencompass/models/internal/|
|
||||||
|
opencompass/utils/internal/|
|
||||||
|
opencompass/openicl/icl_evaluator/hf_metrics/|
|
||||||
|
opencompass/datasets/lawbench/utils|
|
||||||
|
opencompass/datasets/lawbench/evaluation_functions/|
|
||||||
|
opencompass/datasets/medbench/|
|
||||||
|
opencompass/datasets/teval/|
|
||||||
|
opencompass/datasets/NPHardEval/|
|
||||||
|
opencompass/datasets/TheoremQA|
|
||||||
|
opencompass/datasets/subjective/mtbench101.py|
|
||||||
|
docs/zh_cn/advanced_guides/compassbench_intro.md |
|
||||||
|
docs/zh_cn/advanced_guides/compassbench_v2_0.md |
|
||||||
|
opencompass/utils/datasets.py |
|
||||||
|
opencompass/utils/datasets_info.py
|
||||||
|
)
|
||||||
|
repos:
|
||||||
|
- repo: https://gitee.com/openmmlab/mirrors-flake8
|
||||||
|
rev: 5.0.4
|
||||||
|
hooks:
|
||||||
|
- id: flake8
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
opencompass/configs/|
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://gitee.com/openmmlab/mirrors-isort
|
||||||
|
rev: 5.11.5
|
||||||
|
hooks:
|
||||||
|
- id: isort
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
opencompass/configs/|
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://gitee.com/openmmlab/mirrors-yapf
|
||||||
|
rev: v0.32.0
|
||||||
|
hooks:
|
||||||
|
- id: yapf
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
opencompass/configs/|
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://gitee.com/openmmlab/mirrors-codespell
|
||||||
|
rev: v2.2.1
|
||||||
|
hooks:
|
||||||
|
- id: codespell
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
.*\.jsonl|
|
||||||
|
.*\.md.template|
|
||||||
|
opencompass/configs/ |
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://gitee.com/openmmlab/mirrors-pre-commit-hooks
|
||||||
|
rev: v4.3.0
|
||||||
|
hooks:
|
||||||
|
- id: trailing-whitespace
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
dicts/|
|
||||||
|
projects/.*?/dicts/|
|
||||||
|
)
|
||||||
|
- id: check-yaml
|
||||||
|
- id: end-of-file-fixer
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
dicts/|
|
||||||
|
projects/.*?/dicts/|
|
||||||
|
)
|
||||||
|
- id: requirements-txt-fixer
|
||||||
|
- id: double-quote-string-fixer
|
||||||
|
- id: check-merge-conflict
|
||||||
|
- id: fix-encoding-pragma
|
||||||
|
args: ["--remove"]
|
||||||
|
- id: mixed-line-ending
|
||||||
|
args: ["--fix=lf"]
|
||||||
|
- repo: https://gitee.com/openmmlab/mirrors-mdformat
|
||||||
|
rev: 0.7.9
|
||||||
|
hooks:
|
||||||
|
- id: mdformat
|
||||||
|
args: ["--number", "--table-width", "200"]
|
||||||
|
additional_dependencies:
|
||||||
|
- mdformat-openmmlab
|
||||||
|
- mdformat_frontmatter
|
||||||
|
- linkify-it-py
|
||||||
|
exclude: configs/
|
||||||
|
- repo: https://gitee.com/openmmlab/mirrors-docformatter
|
||||||
|
rev: v1.3.1
|
||||||
|
hooks:
|
||||||
|
- id: docformatter
|
||||||
|
args: ["--in-place", "--wrap-descriptions", "79"]
|
||||||
|
- repo: local
|
||||||
|
hooks:
|
||||||
|
- id: update-dataset-suffix
|
||||||
|
name: dataset suffix updater
|
||||||
|
entry: ./tools/update_dataset_suffix.py
|
||||||
|
language: script
|
||||||
|
pass_filenames: true
|
||||||
|
require_serial: true
|
||||||
|
files: ^opencompass/configs/datasets
|
||||||
|
- repo: local
|
||||||
|
hooks:
|
||||||
|
- id: update-dataset-suffix-pacakge
|
||||||
|
name: dataset suffix updater(package)
|
||||||
|
entry: ./tools/update_dataset_suffix.py
|
||||||
|
language: script
|
||||||
|
pass_filenames: false
|
||||||
|
# require_serial: true
|
||||||
|
# files: ^opencompass/configs/datasets
|
||||||
|
args:
|
||||||
|
- --root_folder
|
||||||
|
- opencompass/configs/datasets
|
||||||
|
# - repo: https://github.com/open-mmlab/pre-commit-hooks
|
||||||
|
# rev: v0.2.0 # Use the ref you want to point at
|
||||||
|
# hooks:
|
||||||
|
# - id: check-algo-readme
|
||||||
|
# - id: check-copyright
|
||||||
|
# args: ["mmocr", "tests", "tools"] # these directories will be checked
|
||||||
|
|
@ -0,0 +1,123 @@
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
tests/data/|
|
||||||
|
tests/dataset/|
|
||||||
|
opencompass/models/internal/|
|
||||||
|
opencompass/utils/internal/|
|
||||||
|
opencompass/openicl/icl_evaluator/hf_metrics/|
|
||||||
|
opencompass/datasets/lawbench/utils|
|
||||||
|
opencompass/datasets/lawbench/evaluation_functions/|
|
||||||
|
opencompass/datasets/medbench/|
|
||||||
|
opencompass/datasets/teval/|
|
||||||
|
opencompass/datasets/NPHardEval/|
|
||||||
|
opencompass/datasets/TheoremQA|
|
||||||
|
opencompass/datasets/subjective/mtbench101.py|
|
||||||
|
docs/zh_cn/advanced_guides/compassbench_intro.md |
|
||||||
|
docs/zh_cn/advanced_guides/compassbench_v2_0.md |
|
||||||
|
opencompass/utils/datasets.py |
|
||||||
|
opencompass/utils/datasets_info.py
|
||||||
|
)
|
||||||
|
repos:
|
||||||
|
- repo: https://github.com/PyCQA/flake8
|
||||||
|
rev: 5.0.4
|
||||||
|
hooks:
|
||||||
|
- id: flake8
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
opencompass/configs/|
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://github.com/PyCQA/isort
|
||||||
|
rev: 5.11.5
|
||||||
|
hooks:
|
||||||
|
- id: isort
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
opencompass/configs/|
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://github.com/pre-commit/mirrors-yapf
|
||||||
|
rev: v0.32.0
|
||||||
|
hooks:
|
||||||
|
- id: yapf
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
opencompass/configs/|
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://github.com/codespell-project/codespell
|
||||||
|
rev: v2.2.1
|
||||||
|
hooks:
|
||||||
|
- id: codespell
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
.*\.jsonl|
|
||||||
|
.*\.md.template|
|
||||||
|
opencompass/configs/ |
|
||||||
|
examples/
|
||||||
|
)
|
||||||
|
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||||
|
rev: v4.3.0
|
||||||
|
hooks:
|
||||||
|
- id: trailing-whitespace
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
dicts/|
|
||||||
|
projects/.*?/dicts/|
|
||||||
|
)
|
||||||
|
- id: check-yaml
|
||||||
|
- id: end-of-file-fixer
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
dicts/|
|
||||||
|
projects/.*?/dicts/|
|
||||||
|
)
|
||||||
|
- id: requirements-txt-fixer
|
||||||
|
- id: double-quote-string-fixer
|
||||||
|
- id: check-merge-conflict
|
||||||
|
- id: fix-encoding-pragma
|
||||||
|
args: ["--remove"]
|
||||||
|
- id: mixed-line-ending
|
||||||
|
args: ["--fix=lf"]
|
||||||
|
- repo: https://github.com/executablebooks/mdformat
|
||||||
|
rev: 0.7.9
|
||||||
|
hooks:
|
||||||
|
- id: mdformat
|
||||||
|
args: ["--number", "--table-width", "200"]
|
||||||
|
additional_dependencies:
|
||||||
|
- mdformat-openmmlab
|
||||||
|
- mdformat_frontmatter
|
||||||
|
- linkify-it-py
|
||||||
|
exclude: configs/
|
||||||
|
- repo: https://github.com/myint/docformatter
|
||||||
|
rev: v1.3.1
|
||||||
|
hooks:
|
||||||
|
- id: docformatter
|
||||||
|
args: ["--in-place", "--wrap-descriptions", "79"]
|
||||||
|
- repo: local
|
||||||
|
hooks:
|
||||||
|
- id: update-dataset-suffix
|
||||||
|
name: dataset suffix updater
|
||||||
|
entry: ./tools/update_dataset_suffix.py
|
||||||
|
language: script
|
||||||
|
pass_filenames: true
|
||||||
|
require_serial: true
|
||||||
|
files: ^opencompass/configs/datasets
|
||||||
|
- repo: local
|
||||||
|
hooks:
|
||||||
|
- id: update-dataset-suffix-pacakge
|
||||||
|
name: dataset suffix updater(package)
|
||||||
|
entry: ./tools/update_dataset_suffix.py
|
||||||
|
language: script
|
||||||
|
pass_filenames: false
|
||||||
|
# require_serial: true
|
||||||
|
# files: ^opencompass/configs/datasets
|
||||||
|
args:
|
||||||
|
- --root_folder
|
||||||
|
- opencompass/configs/datasets
|
||||||
|
# - repo: https://github.com/open-mmlab/pre-commit-hooks
|
||||||
|
# rev: v0.2.0 # Use the ref you want to point at
|
||||||
|
# hooks:
|
||||||
|
# - id: check-algo-readme
|
||||||
|
# - id: check-copyright
|
||||||
|
# args: ["mmocr", "tests", "tools"] # these directories will be checked
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
FROM python:3.10-slim
|
||||||
|
|
||||||
|
# 安装依赖
|
||||||
|
RUN apt-get update && apt-get install -y \
|
||||||
|
git build-essential curl unzip && \
|
||||||
|
rm -rf /var/lib/apt/lists/*
|
||||||
|
|
||||||
|
# 设置工作目录
|
||||||
|
WORKDIR /app
|
||||||
|
|
||||||
|
# 复制项目代码
|
||||||
|
COPY . /app
|
||||||
|
|
||||||
|
# 安装 Python 依赖
|
||||||
|
RUN pip install --upgrade pip && \
|
||||||
|
pip install -r requirements.txt && \
|
||||||
|
pip install openai
|
||||||
|
|
||||||
|
# 下载 OpenCompass 官方数据集(保留原始结构)
|
||||||
|
# RUN curl -L -o OpenCompassData.zip https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip && \
|
||||||
|
# unzip OpenCompassData.zip && \
|
||||||
|
# rm OpenCompassData.zip
|
||||||
|
|
||||||
|
# 设置 PYTHONPATH,确保 opencompass 模块可用
|
||||||
|
ENV PYTHONPATH=/app
|
||||||
|
|
||||||
|
# 默认运行评测任务(确保你已准备好 eval_myopenai_cmmlu.py)
|
||||||
|
CMD ["python", "run.py", "eval_myopenai_cmmlu.py", "--mode", "all", "-w", "results/myopenai_cmmlu"]
|
||||||
|
|
@ -0,0 +1,203 @@
|
||||||
|
Copyright 2020 OpenCompass Authors. All rights reserved.
|
||||||
|
|
||||||
|
Apache License
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
APPENDIX: How to apply the Apache License to your work.
|
||||||
|
|
||||||
|
To apply the Apache License to your work, attach the following
|
||||||
|
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||||
|
replaced with your own identifying information. (Don't include
|
||||||
|
the brackets!) The text should be enclosed in the appropriate
|
||||||
|
comment syntax for the file format. We also recommend that a
|
||||||
|
file or class name and description of purpose be included on the
|
||||||
|
same "printed page" as the copyright notice for easier
|
||||||
|
identification within third-party archives.
|
||||||
|
|
||||||
|
Copyright 2020 OpenCompass Authors.
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
|
|
@ -0,0 +1,3 @@
|
||||||
|
recursive-include opencompass/configs *.py *.yml *.json *.txt *.md
|
||||||
|
recursive-include opencompass/openicl/icl_evaluator/hf_metrics *.py
|
||||||
|
recursive-include opencompass/datasets *.py *.yml *.json *.txt *.md *.yaml
|
||||||
|
|
@ -0,0 +1,437 @@
|
||||||
|
<div align="center">
|
||||||
|
<img src="docs/en/_static/image/logo.svg" width="500px"/>
|
||||||
|
<br />
|
||||||
|
<br />
|
||||||
|
|
||||||
|
[![][github-release-shield]][github-release-link]
|
||||||
|
[![][github-releasedate-shield]][github-releasedate-link]
|
||||||
|
[![][github-contributors-shield]][github-contributors-link]<br>
|
||||||
|
[![][github-forks-shield]][github-forks-link]
|
||||||
|
[![][github-stars-shield]][github-stars-link]
|
||||||
|
[![][github-issues-shield]][github-issues-link]
|
||||||
|
[![][github-license-shield]][github-license-link]
|
||||||
|
|
||||||
|
<!-- [](https://pypi.org/project/opencompass/) -->
|
||||||
|
|
||||||
|
[🌐Website](https://opencompass.org.cn/) |
|
||||||
|
[📖CompassHub](https://hub.opencompass.org.cn/home) |
|
||||||
|
[📊CompassRank](https://rank.opencompass.org.cn/home) |
|
||||||
|
[📘Documentation](https://opencompass.readthedocs.io/en/latest/) |
|
||||||
|
[🛠️Installation](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) |
|
||||||
|
[🤔Reporting Issues](https://github.com/open-compass/opencompass/issues/new/choose)
|
||||||
|
|
||||||
|
English | [简体中文](README_zh-CN.md)
|
||||||
|
|
||||||
|
[![][github-trending-shield]][github-trending-url]
|
||||||
|
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
👋 join us on <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> and <a href="https://r.vansin.top/?r=opencompass" target="_blank">WeChat</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
> \[!IMPORTANT\]
|
||||||
|
>
|
||||||
|
> **Star Us**, You will receive all release notifications from GitHub without any delay ~ ⭐️
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary><kbd>Star History</kbd></summary>
|
||||||
|
<picture>
|
||||||
|
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&theme=dark&type=Date">
|
||||||
|
<img width="100%" src="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&type=Date">
|
||||||
|
</picture>
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## 🧭 Welcome
|
||||||
|
|
||||||
|
to **OpenCompass**!
|
||||||
|
|
||||||
|
Just like a compass guides us on our journey, OpenCompass will guide you through the complex landscape of evaluating large language models. With its powerful algorithms and intuitive interface, OpenCompass makes it easy to assess the quality and effectiveness of your NLP models.
|
||||||
|
|
||||||
|
🚩🚩🚩 Explore opportunities at OpenCompass! We're currently **hiring full-time researchers/engineers and interns**. If you're passionate about LLM and OpenCompass, don't hesitate to reach out to us via [email](mailto:zhangsongyang@pjlab.org.cn). We'd love to hear from you!
|
||||||
|
|
||||||
|
🔥🔥🔥 We are delighted to announce that **the OpenCompass has been recommended by the Meta AI**, click [Get Started](https://ai.meta.com/llama/get-started/#validation) of Llama for more information.
|
||||||
|
|
||||||
|
> **Attention**<br />
|
||||||
|
> Breaking Change Notice: In version 0.4.0, we are consolidating all AMOTIC configuration files (previously located in ./configs/datasets, ./configs/models, and ./configs/summarizers) into the opencompass package. Users are advised to update their configuration references to reflect this structural change.
|
||||||
|
|
||||||
|
## 🚀 What's New <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
||||||
|
|
||||||
|
- **\[2025.03.11\]** We have supported evaluation for `SuperGPQA` which is a great benchmark for measuring LLM knowledge ability 🔥🔥🔥
|
||||||
|
- **\[2025.02.28\]** We have added a tutorial for `DeepSeek-R1` series model, please check [Evaluating Reasoning Model](docs/en/user_guides/deepseek_r1.md) for more details! 🔥🔥🔥
|
||||||
|
- **\[2025.02.15\]** We have added two powerful evaluation tools: `GenericLLMEvaluator` for LLM-as-judge evaluations and `MATHEvaluator` for mathematical reasoning assessments. Check out the documentation for [LLM Judge](docs/en/advanced_guides/llm_judge.md) and [Math Evaluation](docs/en/advanced_guides/general_math.md) for more details! 🔥🔥🔥
|
||||||
|
- **\[2025.01.16\]** We now support the [InternLM3-8B-Instruct](https://huggingface.co/internlm/internlm3-8b-instruct) model which has enhanced performance on reasoning and knowledge-intensive tasks.
|
||||||
|
- **\[2024.12.17\]** We have provided the evaluation script for the December [CompassAcademic](examples/eval_academic_leaderboard_202412.py), which allows users to easily reproduce the official evaluation results by configuring it.
|
||||||
|
- **\[2024.11.14\]** OpenCompass now offers support for a sophisticated benchmark designed to evaluate complex reasoning skills — [MuSR](https://arxiv.org/pdf/2310.16049). Check out the [demo](examples/eval_musr.py) and give it a spin! 🔥🔥🔥
|
||||||
|
- **\[2024.11.14\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [BABILong](https://arxiv.org/pdf/2406.10149). Have a look at the [demo](examples/eval_babilong.py) and give it a try! 🔥🔥🔥
|
||||||
|
- **\[2024.10.14\]** We now support the OpenAI multilingual QA dataset [MMMLU](https://huggingface.co/datasets/openai/MMMLU). Feel free to give it a try! 🔥🔥🔥
|
||||||
|
- **\[2024.09.19\]** We now support [Qwen2.5](https://huggingface.co/Qwen)(0.5B to 72B) with multiple backend(huggingface/vllm/lmdeploy). Feel free to give them a try! 🔥🔥🔥
|
||||||
|
- **\[2024.09.17\]** We now support OpenAI o1(`o1-mini-2024-09-12` and `o1-preview-2024-09-12`). Feel free to give them a try! 🔥🔥🔥
|
||||||
|
- **\[2024.09.05\]** We now support answer extraction through model post-processing to provide a more accurate representation of the model's capabilities. As part of this update, we have integrated [XFinder](https://github.com/IAAR-Shanghai/xFinder) as our first post-processing model. For more detailed information, please refer to the [documentation](opencompass/utils/postprocessors/xfinder/README.md), and give it a try! 🔥🔥🔥
|
||||||
|
- **\[2024.08.20\]** OpenCompass now supports the [SciCode](https://github.com/scicode-bench/SciCode): A Research Coding Benchmark Curated by Scientists. 🔥🔥🔥
|
||||||
|
- **\[2024.08.16\]** OpenCompass now supports the brand new long-context language model evaluation benchmark — [RULER](https://arxiv.org/pdf/2404.06654). RULER provides an evaluation of long-context including retrieval, multi-hop tracing, aggregation, and question answering through flexible configurations. Check out the [RULER](configs/datasets/ruler/README.md) evaluation config now! 🔥🔥🔥
|
||||||
|
- **\[2024.08.09\]** We have released the example data and configuration for the CompassBench-202408, welcome to [CompassBench](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_intro.html) for more details. 🔥🔥🔥
|
||||||
|
- **\[2024.08.01\]** We supported the [Gemma2](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315) models. Welcome to try! 🔥🔥🔥
|
||||||
|
- **\[2024.07.23\]** We supported the [ModelScope](www.modelscope.cn) datasets, you can load them on demand without downloading all the data to your local disk. Welcome to try! 🔥🔥🔥
|
||||||
|
- **\[2024.07.17\]** We are excited to announce the release of NeedleBench's [technical report](http://arxiv.org/abs/2407.11963). We invite you to visit our [support documentation](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html) for detailed evaluation guidelines. 🔥🔥🔥
|
||||||
|
- **\[2024.07.04\]** OpenCompass now supports InternLM2.5, which has **outstanding reasoning capability**, **1M Context window and** and **stronger tool use**, you can try the models in [OpenCompass Config](https://github.com/open-compass/opencompass/tree/main/configs/models/hf_internlm) and [InternLM](https://github.com/InternLM/InternLM) .🔥🔥🔥.
|
||||||
|
- **\[2024.06.20\]** OpenCompass now supports one-click switching between inference acceleration backends, enhancing the efficiency of the evaluation process. In addition to the default HuggingFace inference backend, it now also supports popular backends [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm). This feature is available via a simple command-line switch and through deployment APIs. For detailed usage, see the [documentation](docs/en/advanced_guides/accelerator_intro.md).🔥🔥🔥.
|
||||||
|
|
||||||
|
> [More](docs/en/notes/news.md)
|
||||||
|
|
||||||
|
## 📊 Leaderboard
|
||||||
|
|
||||||
|
We provide [OpenCompass Leaderboard](https://rank.opencompass.org.cn/home) for the community to rank all public models and API models. If you would like to join the evaluation, please provide the model repository URL or a standard API interface to the email address `opencompass@pjlab.org.cn`.
|
||||||
|
|
||||||
|
You can also refer to [CompassAcademic](configs/eval_academic_leaderboard_202412.py) to quickly reproduce the leaderboard results. The currently selected datasets include Knowledge Reasoning (MMLU-Pro/GPQA Diamond), Logical Reasoning (BBH), Mathematical Reasoning (MATH-500, AIME), Code Generation (LiveCodeBench, HumanEval), and Instruction Following (IFEval)."
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝Back to top</a></p>
|
||||||
|
|
||||||
|
## 🛠️ Installation
|
||||||
|
|
||||||
|
Below are the steps for quick installation and datasets preparation.
|
||||||
|
|
||||||
|
### 💻 Environment Setup
|
||||||
|
|
||||||
|
We highly recommend using conda to manage your python environment.
|
||||||
|
|
||||||
|
- #### Create your virtual environment
|
||||||
|
|
||||||
|
```bash
|
||||||
|
conda create --name opencompass python=3.10 -y
|
||||||
|
conda activate opencompass
|
||||||
|
```
|
||||||
|
|
||||||
|
- #### Install OpenCompass via pip
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -U opencompass
|
||||||
|
|
||||||
|
## Full installation (with support for more datasets)
|
||||||
|
# pip install "opencompass[full]"
|
||||||
|
|
||||||
|
## Environment with model acceleration frameworks
|
||||||
|
## Manage different acceleration frameworks using virtual environments
|
||||||
|
## since they usually have dependency conflicts with each other.
|
||||||
|
# pip install "opencompass[lmdeploy]"
|
||||||
|
# pip install "opencompass[vllm]"
|
||||||
|
|
||||||
|
## API evaluation (i.e. Openai, Qwen)
|
||||||
|
# pip install "opencompass[api]"
|
||||||
|
```
|
||||||
|
|
||||||
|
- #### Install OpenCompass from source
|
||||||
|
|
||||||
|
If you want to use opencompass's latest features, or develop new features, you can also build it from source
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/open-compass/opencompass opencompass
|
||||||
|
cd opencompass
|
||||||
|
pip install -e .
|
||||||
|
# pip install -e ".[full]"
|
||||||
|
# pip install -e ".[vllm]"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 📂 Data Preparation
|
||||||
|
|
||||||
|
You can choose one for the following method to prepare datasets.
|
||||||
|
|
||||||
|
#### Offline Preparation
|
||||||
|
|
||||||
|
You can download and extract the datasets with the following commands:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Download dataset to data/ folder
|
||||||
|
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
||||||
|
unzip OpenCompassData-core-20240207.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Automatic Download from OpenCompass
|
||||||
|
|
||||||
|
We have supported download datasets automatic from the OpenCompass storage server. You can run the evaluation with extra `--dry-run` to download these datasets.
|
||||||
|
Currently, the supported datasets are listed in [here](https://github.com/open-compass/opencompass/blob/main/opencompass/utils/datasets_info.py#L259). More datasets will be uploaded recently.
|
||||||
|
|
||||||
|
#### (Optional) Automatic Download with ModelScope
|
||||||
|
|
||||||
|
Also you can use the [ModelScope](www.modelscope.cn) to load the datasets on demand.
|
||||||
|
|
||||||
|
Installation:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install modelscope[framework]
|
||||||
|
export DATASET_SOURCE=ModelScope
|
||||||
|
```
|
||||||
|
|
||||||
|
Then submit the evaluation task without downloading all the data to your local disk. Available datasets include:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
|
||||||
|
```
|
||||||
|
|
||||||
|
Some third-party features, like Humaneval and Llama, may require additional steps to work properly, for detailed steps please refer to the [Installation Guide](https://opencompass.readthedocs.io/en/latest/get_started/installation.html).
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝Back to top</a></p>
|
||||||
|
|
||||||
|
## 🏗️ ️Evaluation
|
||||||
|
|
||||||
|
After ensuring that OpenCompass is installed correctly according to the above steps and the datasets are prepared. Now you can start your first evaluation using OpenCompass!
|
||||||
|
|
||||||
|
### Your first evaluation with OpenCompass!
|
||||||
|
|
||||||
|
OpenCompass support setting your configs via CLI or a python script. For simple evaluation settings we recommend using CLI, for more complex evaluation, it is suggested using the script way. You can find more example scripts under the configs folder.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# CLI
|
||||||
|
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen
|
||||||
|
|
||||||
|
# Python scripts
|
||||||
|
opencompass examples/eval_chat_demo.py
|
||||||
|
```
|
||||||
|
|
||||||
|
You can find more script examples under [examples](./examples) folder.
|
||||||
|
|
||||||
|
### API evaluation
|
||||||
|
|
||||||
|
OpenCompass, by its design, does not really discriminate between open-source models and API models. You can evaluate both model types in the same way or even in one settings.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OPENAI_API_KEY="YOUR_OPEN_API_KEY"
|
||||||
|
# CLI
|
||||||
|
opencompass --models gpt_4o_2024_05_13 --datasets demo_gsm8k_chat_gen
|
||||||
|
|
||||||
|
# Python scripts
|
||||||
|
opencompass examples/eval_api_demo.py
|
||||||
|
|
||||||
|
# You can use o1_mini_2024_09_12/o1_preview_2024_09_12 for o1 models, we set max_completion_tokens=8192 as default.
|
||||||
|
```
|
||||||
|
|
||||||
|
### Accelerated Evaluation
|
||||||
|
|
||||||
|
Additionally, if you want to use an inference backend other than HuggingFace for accelerated evaluation, such as LMDeploy or vLLM, you can do so with the command below. Please ensure that you have installed the necessary packages for the chosen backend and that your model supports accelerated inference with it. For more information, see the documentation on inference acceleration backends [here](docs/en/advanced_guides/accelerator_intro.md). Below is an example using LMDeploy:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# CLI
|
||||||
|
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen -a lmdeploy
|
||||||
|
|
||||||
|
# Python scripts
|
||||||
|
opencompass examples/eval_lmdeploy_demo.py
|
||||||
|
```
|
||||||
|
|
||||||
|
### Supported Models and Datasets
|
||||||
|
|
||||||
|
OpenCompass has predefined configurations for many models and datasets. You can list all available model and dataset configurations using the [tools](./docs/en/tools.md#list-configs).
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# List all configurations
|
||||||
|
python tools/list_configs.py
|
||||||
|
# List all configurations related to llama and mmlu
|
||||||
|
python tools/list_configs.py llama mmlu
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Supported Models
|
||||||
|
|
||||||
|
If the model is not on the list but supported by Huggingface AutoModel class or encapsulation of inference engine based on OpenAI interface (see [docs](https://opencompass.readthedocs.io/en/latest/advanced_guides/new_model.html) for details), you can also evaluate it with OpenCompass. You are welcome to contribute to the maintenance of the OpenCompass supported model and dataset lists.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Supported Datasets
|
||||||
|
|
||||||
|
Currently, OpenCompass have provided standard recommended configurations for datasets. Generally, config files ending with `_gen.py` or `_llm_judge_gen.py` will point to the recommended config we provide for this dataset. You can refer to [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for more details.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Recommended Evaluation Config based on Rules
|
||||||
|
opencompass --datasets aime2024_gen --models hf_internlm2_5_1_8b_chat
|
||||||
|
|
||||||
|
# Recommended Evaluation Config based on LLM Judge
|
||||||
|
opencompass --datasets aime2024_llm_judge_gen --models hf_internlm2_5_1_8b_chat
|
||||||
|
```
|
||||||
|
|
||||||
|
If you want to use multiple GPUs to evaluate the model in data parallel, you can use `--max-num-worker`.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2
|
||||||
|
```
|
||||||
|
|
||||||
|
> \[!TIP\]
|
||||||
|
>
|
||||||
|
> `--hf-num-gpus` is used for model parallel(huggingface format), `--max-num-worker` is used for data parallel.
|
||||||
|
|
||||||
|
> \[!TIP\]
|
||||||
|
>
|
||||||
|
> configuration with `_ppl` is designed for base model typically.
|
||||||
|
> configuration with `_gen` can be used for both base model and chat model.
|
||||||
|
|
||||||
|
Through the command line or configuration files, OpenCompass also supports evaluating APIs or custom models, as well as more diversified evaluation strategies. Please read the [Quick Start](https://opencompass.readthedocs.io/en/latest/get_started/quick_start.html) to learn how to run an evaluation task.
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝Back to top</a></p>
|
||||||
|
|
||||||
|
## 📣 OpenCompass 2.0
|
||||||
|
|
||||||
|
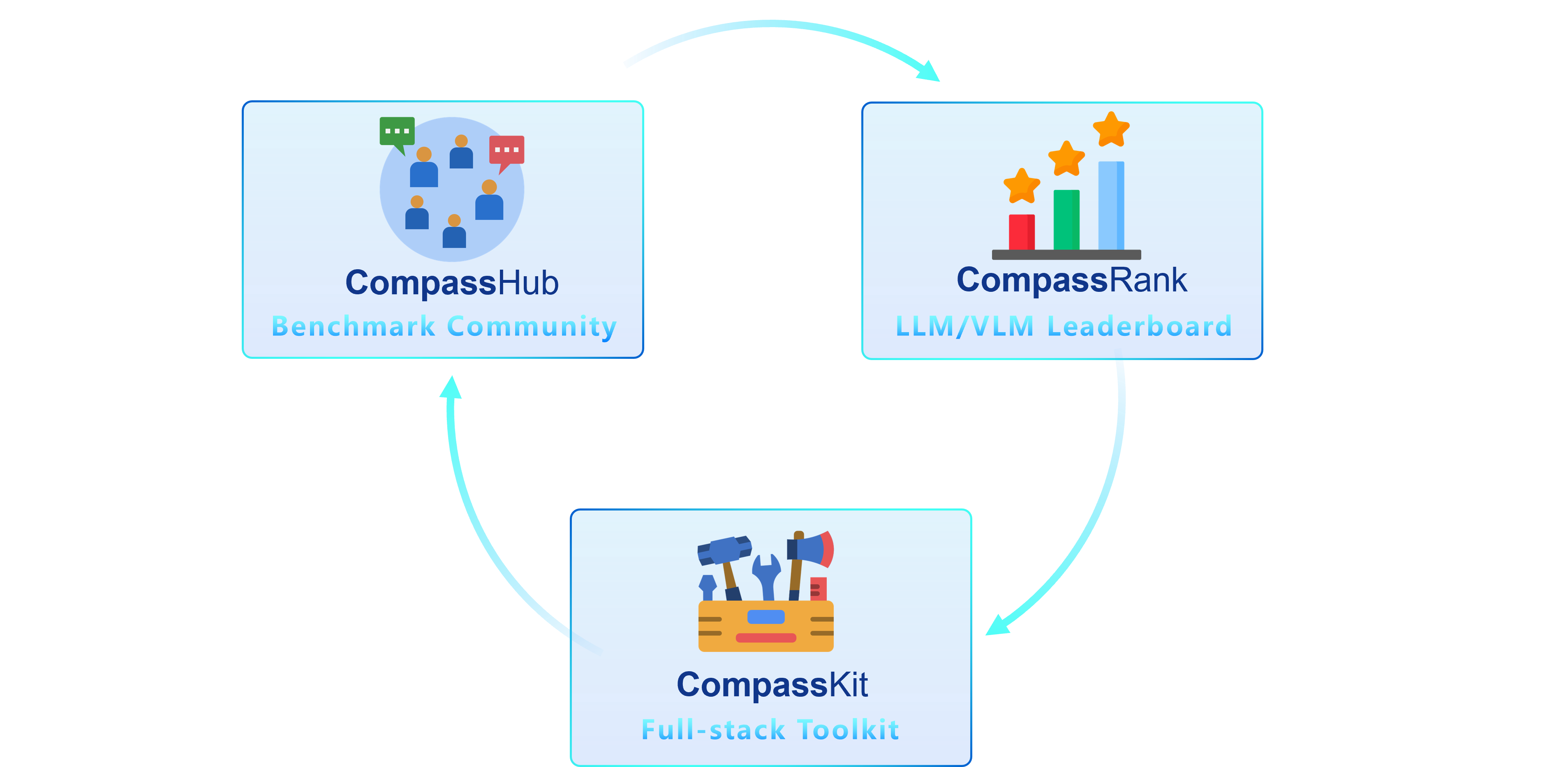
We are thrilled to introduce OpenCompass 2.0, an advanced suite featuring three key components: [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home).
|
||||||
|
|
||||||
|
|
||||||
|
**CompassRank** has been significantly enhanced into the leaderboards that now incorporates both open-source benchmarks and proprietary benchmarks. This upgrade allows for a more comprehensive evaluation of models across the industry.
|
||||||
|
|
||||||
|
**CompassHub** presents a pioneering benchmark browser interface, designed to simplify and expedite the exploration and utilization of an extensive array of benchmarks for researchers and practitioners alike. To enhance the visibility of your own benchmark within the community, we warmly invite you to contribute it to CompassHub. You may initiate the submission process by clicking [here](https://hub.opencompass.org.cn/dataset-submit).
|
||||||
|
|
||||||
|
**CompassKit** is a powerful collection of evaluation toolkits specifically tailored for Large Language Models and Large Vision-language Models. It provides an extensive set of tools to assess and measure the performance of these complex models effectively. Welcome to try our toolkits for in your research and products.
|
||||||
|
|
||||||
|
## ✨ Introduction
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
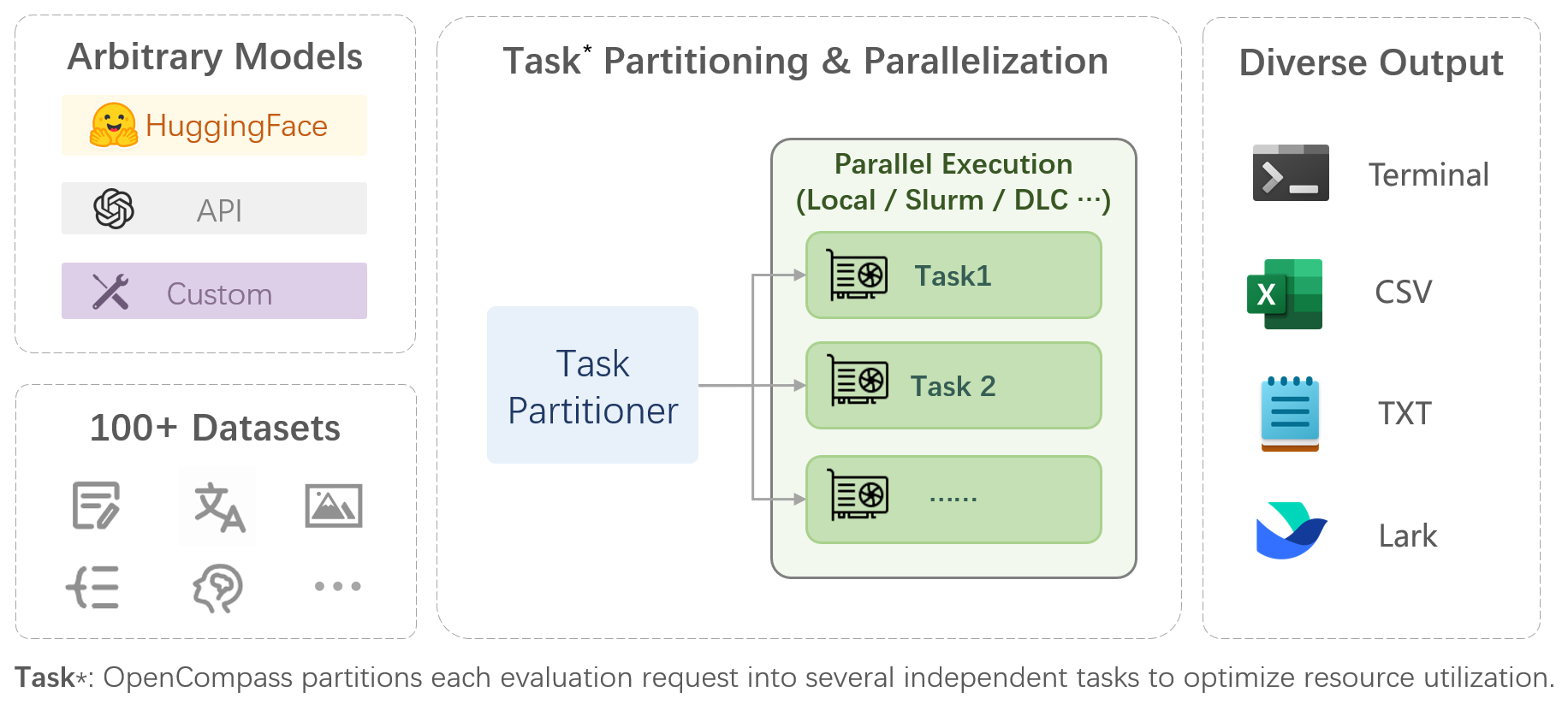
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include:
|
||||||
|
|
||||||
|
- **Comprehensive support for models and datasets**: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions.
|
||||||
|
|
||||||
|
- **Efficient distributed evaluation**: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours.
|
||||||
|
|
||||||
|
- **Diversified evaluation paradigms**: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models.
|
||||||
|
|
||||||
|
- **Modular design with high extensibility**: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded!
|
||||||
|
|
||||||
|
- **Experiment management and reporting mechanism**: Use config files to fully record each experiment, and support real-time reporting of results.
|
||||||
|
|
||||||
|
## 📖 Dataset Support
|
||||||
|
|
||||||
|
We have supported a statistical list of all datasets that can be used on this platform in the documentation on the OpenCompass website.
|
||||||
|
|
||||||
|
You can quickly find the dataset you need from the list through sorting, filtering, and searching functions.
|
||||||
|
|
||||||
|
In addition, we provide a recommended configuration for each dataset, and some datasets also support LLM Judge-based configurations.
|
||||||
|
|
||||||
|
Please refer to the dataset statistics chapter of [docs](https://opencompass.readthedocs.io/en/latest/dataset_statistics.html) for details.
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝Back to top</a></p>
|
||||||
|
|
||||||
|
## 📖 Model Support
|
||||||
|
|
||||||
|
<table align="center">
|
||||||
|
<tbody>
|
||||||
|
<tr align="center" valign="bottom">
|
||||||
|
<td>
|
||||||
|
<b>Open-source Models</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>API Models</b>
|
||||||
|
</td>
|
||||||
|
<!-- <td>
|
||||||
|
<b>Custom Models</b>
|
||||||
|
</td> -->
|
||||||
|
</tr>
|
||||||
|
<tr valign="top">
|
||||||
|
<td>
|
||||||
|
|
||||||
|
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
||||||
|
- [Baichuan](https://github.com/baichuan-inc)
|
||||||
|
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
||||||
|
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
|
||||||
|
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
|
||||||
|
- [Gemma](https://huggingface.co/google/gemma-7b)
|
||||||
|
- [InternLM](https://github.com/InternLM/InternLM)
|
||||||
|
- [LLaMA](https://github.com/facebookresearch/llama)
|
||||||
|
- [LLaMA3](https://github.com/meta-llama/llama3)
|
||||||
|
- [Qwen](https://github.com/QwenLM/Qwen)
|
||||||
|
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
||||||
|
- [Vicuna](https://github.com/lm-sys/FastChat)
|
||||||
|
- [WizardLM](https://github.com/nlpxucan/WizardLM)
|
||||||
|
- [Yi](https://github.com/01-ai/Yi)
|
||||||
|
- ……
|
||||||
|
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
|
||||||
|
- OpenAI
|
||||||
|
- Gemini
|
||||||
|
- Claude
|
||||||
|
- ZhipuAI(ChatGLM)
|
||||||
|
- Baichuan
|
||||||
|
- ByteDance(YunQue)
|
||||||
|
- Huawei(PanGu)
|
||||||
|
- 360
|
||||||
|
- Baidu(ERNIEBot)
|
||||||
|
- MiniMax(ABAB-Chat)
|
||||||
|
- SenseTime(nova)
|
||||||
|
- Xunfei(Spark)
|
||||||
|
- ……
|
||||||
|
|
||||||
|
</td>
|
||||||
|
|
||||||
|
</tr>
|
||||||
|
</tbody>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝Back to top</a></p>
|
||||||
|
|
||||||
|
## 🔜 Roadmap
|
||||||
|
|
||||||
|
- [x] Subjective Evaluation
|
||||||
|
- [x] Release CompassAreana.
|
||||||
|
- [x] Subjective evaluation.
|
||||||
|
- [x] Long-context
|
||||||
|
- [x] Long-context evaluation with extensive datasets.
|
||||||
|
- [ ] Long-context leaderboard.
|
||||||
|
- [x] Coding
|
||||||
|
- [ ] Coding evaluation leaderboard.
|
||||||
|
- [x] Non-python language evaluation service.
|
||||||
|
- [x] Agent
|
||||||
|
- [ ] Support various agent frameworks.
|
||||||
|
- [x] Evaluation of tool use of the LLMs.
|
||||||
|
- [x] Robustness
|
||||||
|
- [x] Support various attack methods.
|
||||||
|
|
||||||
|
## 👷♂️ Contributing
|
||||||
|
|
||||||
|
We appreciate all contributions to improving OpenCompass. Please refer to the [contributing guideline](https://opencompass.readthedocs.io/en/latest/notes/contribution_guide.html) for the best practice.
|
||||||
|
|
||||||
|
<!-- Copy-paste in your Readme.md file -->
|
||||||
|
|
||||||
|
<!-- Made with [OSS Insight](https://ossinsight.io/) -->
|
||||||
|
|
||||||
|
<a href="https://github.com/open-compass/opencompass/graphs/contributors" target="_blank">
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<th colspan="2">
|
||||||
|
<br><img src="https://contrib.rocks/image?repo=open-compass/opencompass"><br><br>
|
||||||
|
</th>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
</a>
|
||||||
|
|
||||||
|
## 🤝 Acknowledgements
|
||||||
|
|
||||||
|
Some code in this project is cited and modified from [OpenICL](https://github.com/Shark-NLP/OpenICL).
|
||||||
|
|
||||||
|
Some datasets and prompt implementations are modified from [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub) and [instruct-eval](https://github.com/declare-lab/instruct-eval).
|
||||||
|
|
||||||
|
## 🖊️ Citation
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝Back to top</a></p>
|
||||||
|
|
||||||
|
[github-contributors-link]: https://github.com/open-compass/opencompass/graphs/contributors
|
||||||
|
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/opencompass?color=c4f042&labelColor=black&style=flat-square
|
||||||
|
[github-forks-link]: https://github.com/open-compass/opencompass/network/members
|
||||||
|
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/opencompass?color=8ae8ff&labelColor=black&style=flat-square
|
||||||
|
[github-issues-link]: https://github.com/open-compass/opencompass/issues
|
||||||
|
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/opencompass?color=ff80eb&labelColor=black&style=flat-square
|
||||||
|
[github-license-link]: https://github.com/open-compass/opencompass/blob/main/LICENSE
|
||||||
|
[github-license-shield]: https://img.shields.io/github/license/open-compass/opencompass?color=white&labelColor=black&style=flat-square
|
||||||
|
[github-release-link]: https://github.com/open-compass/opencompass/releases
|
||||||
|
[github-release-shield]: https://img.shields.io/github/v/release/open-compass/opencompass?color=369eff&labelColor=black&logo=github&style=flat-square
|
||||||
|
[github-releasedate-link]: https://github.com/open-compass/opencompass/releases
|
||||||
|
[github-releasedate-shield]: https://img.shields.io/github/release-date/open-compass/opencompass?labelColor=black&style=flat-square
|
||||||
|
[github-stars-link]: https://github.com/open-compass/opencompass/stargazers
|
||||||
|
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/opencompass?color=ffcb47&labelColor=black&style=flat-square
|
||||||
|
[github-trending-shield]: https://trendshift.io/api/badge/repositories/6630
|
||||||
|
[github-trending-url]: https://trendshift.io/repositories/6630
|
||||||
|
|
@ -0,0 +1,426 @@
|
||||||
|
<div align="center">
|
||||||
|
<img src="docs/zh_cn/_static/image/logo.svg" width="500px"/>
|
||||||
|
<br />
|
||||||
|
<br />
|
||||||
|
|
||||||
|
[![][github-release-shield]][github-release-link]
|
||||||
|
[![][github-releasedate-shield]][github-releasedate-link]
|
||||||
|
[![][github-contributors-shield]][github-contributors-link]<br>
|
||||||
|
[![][github-forks-shield]][github-forks-link]
|
||||||
|
[![][github-stars-shield]][github-stars-link]
|
||||||
|
[![][github-issues-shield]][github-issues-link]
|
||||||
|
[![][github-license-shield]][github-license-link]
|
||||||
|
|
||||||
|
<!-- [](https://pypi.org/project/opencompass/) -->
|
||||||
|
|
||||||
|
[🌐官方网站](https://opencompass.org.cn/) |
|
||||||
|
[📖数据集社区](https://hub.opencompass.org.cn/home) |
|
||||||
|
[📊性能榜单](https://rank.opencompass.org.cn/home) |
|
||||||
|
[📘文档教程](https://opencompass.readthedocs.io/zh_CN/latest/index.html) |
|
||||||
|
[🛠️安装](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html) |
|
||||||
|
[🤔报告问题](https://github.com/open-compass/opencompass/issues/new/choose)
|
||||||
|
|
||||||
|
[English](/README.md) | 简体中文
|
||||||
|
|
||||||
|
[![][github-trending-shield]][github-trending-url]
|
||||||
|
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
👋 加入我们的 <a href="https://discord.gg/KKwfEbFj7U" target="_blank">Discord</a> 和 <a href="https://r.vansin.top/?r=opencompass" target="_blank">微信社区</a>
|
||||||
|
</p>
|
||||||
|
|
||||||
|
> \[!IMPORTANT\]
|
||||||
|
>
|
||||||
|
> **收藏项目**,你将能第一时间获取 OpenCompass 的最新动态~⭐️
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary><kbd>Star History</kbd></summary>
|
||||||
|
<picture>
|
||||||
|
<source media="(prefers-color-scheme: dark)" srcset="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&theme=dark&type=Date">
|
||||||
|
<img width="100%" src="https://api.star-history.com/svg?repos=open-compass%2Fopencompass&type=Date">
|
||||||
|
</picture>
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## 🧭 欢迎
|
||||||
|
|
||||||
|
来到**OpenCompass**!
|
||||||
|
|
||||||
|
就像指南针在我们的旅程中为我们导航一样,我们希望OpenCompass能够帮助你穿越评估大型语言模型的重重迷雾。OpenCompass提供丰富的算法和功能支持,期待OpenCompass能够帮助社区更便捷地对NLP模型的性能进行公平全面的评估。
|
||||||
|
|
||||||
|
🚩🚩🚩 欢迎加入 OpenCompass!我们目前**招聘全职研究人员/工程师和实习生**。如果您对 LLM 和 OpenCompass 充满热情,请随时通过[电子邮件](mailto:zhangsongyang@pjlab.org.cn)与我们联系。我们非常期待与您交流!
|
||||||
|
|
||||||
|
🔥🔥🔥 祝贺 **OpenCompass 作为大模型标准测试工具被Meta AI官方推荐**, 点击 Llama 的 [入门文档](https://ai.meta.com/llama/get-started/#validation) 获取更多信息。
|
||||||
|
|
||||||
|
> **注意**<br />
|
||||||
|
> 重要通知:从 v0.4.0 版本开始,所有位于 ./configs/datasets、./configs/models 和 ./configs/summarizers 目录下的 AMOTIC 配置文件将迁移至 opencompass 包中。请及时更新您的配置文件路径。
|
||||||
|
|
||||||
|
## 🚀 最新进展 <a><img width="35" height="20" src="https://user-images.githubusercontent.com/12782558/212848161-5e783dd6-11e8-4fe0-bbba-39ffb77730be.png"></a>
|
||||||
|
|
||||||
|
- **\[2025.03.11\]** 现已支持 `SuperGPQA` 覆盖285 个研究生学科的知识能力评测,欢迎尝试!🔥🔥🔥
|
||||||
|
- **\[2025.02.28\]** 我们为 `DeepSeek-R1` 系列模型添加了教程,请查看 [评估推理模型](docs/en/user_guides/deepseek_r1.md) 了解更多详情!🔥🔥🔥
|
||||||
|
- **\[2025.02.15\]** 我们新增了两个实用的评测工具:用于LLM作为评判器的`GenericLLMEvaluator`和用于数学推理评估的`MATHEvaluator`。查看[LLM评判器](docs/zh_cn/advanced_guides/llm_judge.md)和[数学能力评测](docs/zh_cn/advanced_guides/general_math.md)文档了解更多详情!🔥🔥🔥
|
||||||
|
- **\[2025.01.16\]** 我们现已支持 [InternLM3-8B-Instruct](https://huggingface.co/internlm/internlm3-8b-instruct) 模型,该模型在推理、知识类任务上取得同量级最优性能,欢迎尝试。
|
||||||
|
- **\[2024.12.17\]** 我们提供了12月CompassAcademic学术榜单评估脚本 [CompassAcademic](configs/eval_academic_leaderboard_202412.py),你可以通过简单地配置复现官方评测结果。
|
||||||
|
- **\[2024.10.14\]** 现已支持OpenAI多语言问答数据集[MMMLU](https://huggingface.co/datasets/openai/MMMLU),欢迎尝试! 🔥🔥🔥
|
||||||
|
- **\[2024.09.19\]** 现已支持[Qwen2.5](https://huggingface.co/Qwen)(0.5B to 72B) ,可以使用多种推理后端(huggingface/vllm/lmdeploy), 欢迎尝试! 🔥🔥🔥
|
||||||
|
- **\[2024.09.05\]** 现已支持OpenAI o1 模型(`o1-mini-2024-09-12` and `o1-preview-2024-09-12`), 欢迎尝试! 🔥🔥🔥
|
||||||
|
- **\[2024.09.05\]** OpenCompass 现在支持通过模型后处理来进行答案提取,以更准确地展示模型的能力。作为此次更新的一部分,我们集成了 [XFinder](https://github.com/IAAR-Shanghai/xFinder) 作为首个后处理模型。具体信息请参阅 [文档](opencompass/utils/postprocessors/xfinder/README.md),欢迎尝试! 🔥🔥🔥
|
||||||
|
- **\[2024.08.20\]** OpenCompass 现已支持 [SciCode](https://github.com/scicode-bench/SciCode): A Research Coding Benchmark Curated by Scientists。 🔥🔥🔥
|
||||||
|
- **\[2024.08.16\]** OpenCompass 现已支持全新的长上下文语言模型评估基准——[RULER](https://arxiv.org/pdf/2404.06654)。RULER 通过灵活的配置,提供了对长上下文包括检索、多跳追踪、聚合和问答等多种任务类型的评测,欢迎访问[RULER](configs/datasets/ruler/README.md)。🔥🔥🔥
|
||||||
|
- **\[2024.07.23\]** 我们支持了[Gemma2](https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315)模型,欢迎试用!🔥🔥🔥
|
||||||
|
- **\[2024.07.23\]** 我们支持了[ModelScope](www.modelscope.cn)数据集,您可以按需加载,无需事先下载全部数据到本地,欢迎试用!🔥🔥🔥
|
||||||
|
- **\[2024.07.17\]** 我们发布了CompassBench-202407榜单的示例数据和评测规则,敬请访问 [CompassBench](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/compassbench_intro.html) 获取更多信息。 🔥🔥🔥
|
||||||
|
- **\[2024.07.17\]** 我们正式发布 NeedleBench 的[技术报告](http://arxiv.org/abs/2407.11963)。诚邀您访问我们的[帮助文档](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/needleinahaystack_eval.html)进行评估。🔥🔥🔥
|
||||||
|
- **\[2024.07.04\]** OpenCompass 现已支持 InternLM2.5, 它拥有卓越的推理性能、有效支持百万字超长上下文以及工具调用能力整体升级,欢迎访问[OpenCompass Config](https://github.com/open-compass/opencompass/tree/main/configs/models/hf_internlm) 和 [InternLM](https://github.com/InternLM/InternLM) .🔥🔥🔥.
|
||||||
|
- **\[2024.06.20\]** OpenCompass 现已支持一键切换推理加速后端,助力评测过程更加高效。除了默认的HuggingFace推理后端外,还支持了常用的 [LMDeploy](https://github.com/InternLM/lmdeploy) 和 [vLLM](https://github.com/vllm-project/vllm) ,支持命令行一键切换和部署 API 加速服务两种方式,详细使用方法见[文档](docs/zh_cn/advanced_guides/accelerator_intro.md)。欢迎试用!🔥🔥🔥.
|
||||||
|
|
||||||
|
> [更多](docs/zh_cn/notes/news.md)
|
||||||
|
|
||||||
|
## 📊 性能榜单
|
||||||
|
|
||||||
|
我们将陆续提供开源模型和 API 模型的具体性能榜单,请见 [OpenCompass Leaderboard](https://rank.opencompass.org.cn/home) 。如需加入评测,请提供模型仓库地址或标准的 API 接口至邮箱 `opencompass@pjlab.org.cn`.
|
||||||
|
|
||||||
|
你也可以参考[CompassAcademic](configs/eval_academic_leaderboard_202412.py),快速地复现榜单的结果,目前选取的数据集包括 综合知识推理 (MMLU-Pro/GPQA Diamond) ,逻辑推理 (BBH) ,数学推理 (MATH-500, AIME) ,代码生成 (LiveCodeBench, HumanEval) ,指令跟随 (IFEval) 。
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
||||||
|
|
||||||
|
## 🛠️ 安装指南
|
||||||
|
|
||||||
|
下面提供了快速安装和数据集准备的步骤。
|
||||||
|
|
||||||
|
### 💻 环境搭建
|
||||||
|
|
||||||
|
我们强烈建议使用 `conda` 来管理您的 Python 环境。
|
||||||
|
|
||||||
|
- #### 创建虚拟环境
|
||||||
|
|
||||||
|
```bash
|
||||||
|
conda create --name opencompass python=3.10 -y
|
||||||
|
conda activate opencompass
|
||||||
|
```
|
||||||
|
|
||||||
|
- #### 通过pip安装OpenCompass
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 支持绝大多数数据集及模型
|
||||||
|
pip install -U opencompass
|
||||||
|
|
||||||
|
# 完整安装(支持更多数据集)
|
||||||
|
# pip install "opencompass[full]"
|
||||||
|
|
||||||
|
# 模型推理后端,由于这些推理后端通常存在依赖冲突,建议使用不同的虚拟环境来管理它们。
|
||||||
|
# pip install "opencompass[lmdeploy]"
|
||||||
|
# pip install "opencompass[vllm]"
|
||||||
|
|
||||||
|
# API 测试(例如 OpenAI、Qwen)
|
||||||
|
# pip install "opencompass[api]"
|
||||||
|
```
|
||||||
|
|
||||||
|
- #### 基于源码安装OpenCompass
|
||||||
|
|
||||||
|
如果希望使用 OpenCompass 的最新功能,也可以从源代码构建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/open-compass/opencompass opencompass
|
||||||
|
cd opencompass
|
||||||
|
pip install -e .
|
||||||
|
# pip install -e ".[full]"
|
||||||
|
# pip install -e ".[vllm]"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 📂 数据准备
|
||||||
|
|
||||||
|
#### 提前离线下载
|
||||||
|
|
||||||
|
OpenCompass支持使用本地数据集进行评测,数据集的下载和解压可以通过以下命令完成:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 下载数据集到 data/ 处
|
||||||
|
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
||||||
|
unzip OpenCompassData-core-20240207.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 从 OpenCompass 自动下载
|
||||||
|
|
||||||
|
我们已经支持从OpenCompass存储服务器自动下载数据集。您可以通过额外的 `--dry-run` 参数来运行评估以下载这些数据集。
|
||||||
|
目前支持的数据集列表在[这里](https://github.com/open-compass/opencompass/blob/main/opencompass/utils/datasets_info.py#L259)。更多数据集将会很快上传。
|
||||||
|
|
||||||
|
#### (可选) 使用 ModelScope 自动下载
|
||||||
|
|
||||||
|
另外,您还可以使用[ModelScope](www.modelscope.cn)来加载数据集:
|
||||||
|
环境准备:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install modelscope
|
||||||
|
export DATASET_SOURCE=ModelScope
|
||||||
|
```
|
||||||
|
|
||||||
|
配置好环境后,无需下载全部数据,直接提交评测任务即可。目前支持的数据集有:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
|
||||||
|
```
|
||||||
|
|
||||||
|
有部分第三方功能,如 Humaneval 以及 Llama,可能需要额外步骤才能正常运行,详细步骤请参考[安装指南](https://opencompass.readthedocs.io/zh_CN/latest/get_started/installation.html)。
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
||||||
|
|
||||||
|
## 🏗️ ️评测
|
||||||
|
|
||||||
|
在确保按照上述步骤正确安装了 OpenCompass 并准备好了数据集之后,现在您可以开始使用 OpenCompass 进行首次评估!
|
||||||
|
|
||||||
|
- ### 首次评测
|
||||||
|
|
||||||
|
OpenCompass 支持通过命令行界面 (CLI) 或 Python 脚本来设置配置。对于简单的评估设置,我们推荐使用 CLI;而对于更复杂的评估,则建议使用脚本方式。你可以在examples文件夹下找到更多脚本示例。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 命令行界面 (CLI)
|
||||||
|
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen
|
||||||
|
|
||||||
|
# Python 脚本
|
||||||
|
opencompass examples/eval_chat_demo.py
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以在[examples](./examples) 文件夹下找到更多的脚本示例。
|
||||||
|
|
||||||
|
- ### API评测
|
||||||
|
|
||||||
|
OpenCompass 在设计上并不区分开源模型与 API 模型。您可以以相同的方式或甚至在同一设置中评估这两种类型的模型。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OPENAI_API_KEY="YOUR_OPEN_API_KEY"
|
||||||
|
# 命令行界面 (CLI)
|
||||||
|
opencompass --models gpt_4o_2024_05_13 --datasets demo_gsm8k_chat_gen
|
||||||
|
|
||||||
|
# Python 脚本
|
||||||
|
opencompass examples/eval_api_demo.py
|
||||||
|
|
||||||
|
|
||||||
|
# 现已支持 o1_mini_2024_09_12/o1_preview_2024_09_12 模型, 默认情况下 max_completion_tokens=8192.
|
||||||
|
```
|
||||||
|
|
||||||
|
- ### 推理后端
|
||||||
|
|
||||||
|
另外,如果您想使用除 HuggingFace 之外的推理后端来进行加速评估,比如 LMDeploy 或 vLLM,可以通过以下命令进行。请确保您已经为所选的后端安装了必要的软件包,并且您的模型支持该后端的加速推理。更多信息,请参阅关于推理加速后端的文档 [这里](docs/zh_cn/advanced_guides/accelerator_intro.md)。以下是使用 LMDeploy 的示例:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass --models hf_internlm2_5_1_8b_chat --datasets demo_gsm8k_chat_gen -a lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
- ### 支持的模型与数据集
|
||||||
|
|
||||||
|
OpenCompass 预定义了许多模型和数据集的配置,你可以通过 [工具](./docs/zh_cn/tools.md#ListConfigs) 列出所有可用的模型和数据集配置。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 列出所有配置
|
||||||
|
python tools/list_configs.py
|
||||||
|
# 列出所有跟 llama 及 mmlu 相关的配置
|
||||||
|
python tools/list_configs.py llama mmlu
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 支持的模型
|
||||||
|
|
||||||
|
如果模型不在列表中,但支持 Huggingface AutoModel 类或支持针对 OpenAI 接口的推理引擎封装(详见[官方文档](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/new_model.html)),您仍然可以使用 OpenCompass 对其进行评估。欢迎您贡献维护 OpenCompass 支持的模型和数据集列表。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 支持的数据集
|
||||||
|
|
||||||
|
目前,OpenCompass针对数据集给出了标准的推荐配置。通常,`_gen.py`或`_llm_judge_gen.py`为结尾的配置文件将指向我们为该数据集提供的推荐配置。您可以参阅[官方文档](https://opencompass.readthedocs.io/zh-cn/latest/dataset_statistics.html) 的数据集统计章节来获取详细信息。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 基于规则的推荐配置
|
||||||
|
opencompass --datasets aime2024_gen --models hf_internlm2_5_1_8b_chat
|
||||||
|
|
||||||
|
# 基于LLM Judge的推荐配置
|
||||||
|
opencompass --datasets aime2024_llm_judge_gen --models hf_internlm2_5_1_8b_chat
|
||||||
|
```
|
||||||
|
|
||||||
|
此外,如果你想在多块 GPU 上使用模型进行推理,您可以使用 `--max-num-worker` 参数。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
CUDA_VISIBLE_DEVICES=0,1 opencompass --datasets demo_gsm8k_chat_gen --hf-type chat --hf-path internlm/internlm2_5-1_8b-chat --max-num-worker 2
|
||||||
|
```
|
||||||
|
|
||||||
|
> \[!TIP\]
|
||||||
|
>
|
||||||
|
> `--hf-num-gpus` 用于 模型并行(huggingface 格式),`--max-num-worker` 用于数据并行。
|
||||||
|
|
||||||
|
> \[!TIP\]
|
||||||
|
>
|
||||||
|
> configuration with `_ppl` is designed for base model typically.
|
||||||
|
> 配置带 `_ppl` 的配置设计给基础模型使用。
|
||||||
|
> 配置带 `_gen` 的配置可以同时用于基础模型和对话模型。
|
||||||
|
|
||||||
|
通过命令行或配置文件,OpenCompass 还支持评测 API 或自定义模型,以及更多样化的评测策略。请阅读[快速开始](https://opencompass.readthedocs.io/zh_CN/latest/get_started/quick_start.html)了解如何运行一个评测任务。
|
||||||
|
|
||||||
|
更多教程请查看我们的[文档](https://opencompass.readthedocs.io/zh_CN/latest/index.html)。
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
||||||
|
|
||||||
|
## 📣 OpenCompass 2.0
|
||||||
|
|
||||||
|
我们很高兴发布 OpenCompass 司南 2.0 大模型评测体系,它主要由三大核心模块构建而成:[CompassKit](https://github.com/open-compass)、[CompassHub](https://hub.opencompass.org.cn/home)以及[CompassRank](https://rank.opencompass.org.cn/home)。
|
||||||
|
|
||||||
|
**CompassRank** 系统进行了重大革新与提升,现已成为一个兼容并蓄的排行榜体系,不仅囊括了开源基准测试项目,还包含了私有基准测试。此番升级极大地拓宽了对行业内各类模型进行全面而深入测评的可能性。
|
||||||
|
|
||||||
|
**CompassHub** 创新性地推出了一个基准测试资源导航平台,其设计初衷旨在简化和加快研究人员及行业从业者在多样化的基准测试库中进行搜索与利用的过程。为了让更多独具特色的基准测试成果得以在业内广泛传播和应用,我们热忱欢迎各位将自定义的基准数据贡献至CompassHub平台。只需轻点鼠标,通过访问[这里](https://hub.opencompass.org.cn/dataset-submit),即可启动提交流程。
|
||||||
|
|
||||||
|
**CompassKit** 是一系列专为大型语言模型和大型视觉-语言模型打造的强大评估工具合集,它所提供的全面评测工具集能够有效地对这些复杂模型的功能性能进行精准测量和科学评估。在此,我们诚挚邀请您在学术研究或产品研发过程中积极尝试运用我们的工具包,以助您取得更加丰硕的研究成果和产品优化效果。
|
||||||
|
|
||||||
|
## ✨ 介绍
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
OpenCompass 是面向大模型评测的一站式平台。其主要特点如下:
|
||||||
|
|
||||||
|
- **开源可复现**:提供公平、公开、可复现的大模型评测方案
|
||||||
|
|
||||||
|
- **全面的能力维度**:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
|
||||||
|
|
||||||
|
- **丰富的模型支持**:已支持 20+ HuggingFace 及 API 模型
|
||||||
|
|
||||||
|
- **分布式高效评测**:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
|
||||||
|
|
||||||
|
- **多样化评测范式**:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
|
||||||
|
|
||||||
|
- **灵活化拓展**:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
|
||||||
|
|
||||||
|
## 📖 数据集支持
|
||||||
|
|
||||||
|
我们已经在OpenCompass官网的文档中支持了所有可在本平台上使用的数据集的统计列表。
|
||||||
|
|
||||||
|
您可以通过排序、筛选和搜索等功能从列表中快速找到您需要的数据集。
|
||||||
|
|
||||||
|
详情请参阅 [官方文档](https://opencompass.readthedocs.io/zh-cn/latest/dataset_statistics.html) 的数据集统计章节。
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
||||||
|
|
||||||
|
## 📖 模型支持
|
||||||
|
|
||||||
|
<table align="center">
|
||||||
|
<tbody>
|
||||||
|
<tr align="center" valign="bottom">
|
||||||
|
<td>
|
||||||
|
<b>开源模型</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>API 模型</b>
|
||||||
|
</td>
|
||||||
|
<!-- <td>
|
||||||
|
<b>自定义模型</b>
|
||||||
|
</td> -->
|
||||||
|
</tr>
|
||||||
|
<tr valign="top">
|
||||||
|
<td>
|
||||||
|
|
||||||
|
- [Alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
||||||
|
- [Baichuan](https://github.com/baichuan-inc)
|
||||||
|
- [BlueLM](https://github.com/vivo-ai-lab/BlueLM)
|
||||||
|
- [ChatGLM2](https://github.com/THUDM/ChatGLM2-6B)
|
||||||
|
- [ChatGLM3](https://github.com/THUDM/ChatGLM3-6B)
|
||||||
|
- [Gemma](https://huggingface.co/google/gemma-7b)
|
||||||
|
- [InternLM](https://github.com/InternLM/InternLM)
|
||||||
|
- [LLaMA](https://github.com/facebookresearch/llama)
|
||||||
|
- [LLaMA3](https://github.com/meta-llama/llama3)
|
||||||
|
- [Qwen](https://github.com/QwenLM/Qwen)
|
||||||
|
- [TigerBot](https://github.com/TigerResearch/TigerBot)
|
||||||
|
- [Vicuna](https://github.com/lm-sys/FastChat)
|
||||||
|
- [WizardLM](https://github.com/nlpxucan/WizardLM)
|
||||||
|
- [Yi](https://github.com/01-ai/Yi)
|
||||||
|
- ……
|
||||||
|
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
|
||||||
|
- OpenAI
|
||||||
|
- Gemini
|
||||||
|
- Claude
|
||||||
|
- ZhipuAI(ChatGLM)
|
||||||
|
- Baichuan
|
||||||
|
- ByteDance(YunQue)
|
||||||
|
- Huawei(PanGu)
|
||||||
|
- 360
|
||||||
|
- Baidu(ERNIEBot)
|
||||||
|
- MiniMax(ABAB-Chat)
|
||||||
|
- SenseTime(nova)
|
||||||
|
- Xunfei(Spark)
|
||||||
|
- ……
|
||||||
|
|
||||||
|
</td>
|
||||||
|
|
||||||
|
</tr>
|
||||||
|
</tbody>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
||||||
|
|
||||||
|
## 🔜 路线图
|
||||||
|
|
||||||
|
- [x] 主观评测
|
||||||
|
- [x] 发布主观评测榜单
|
||||||
|
- [x] 发布主观评测数据集
|
||||||
|
- [x] 长文本
|
||||||
|
- [x] 支持广泛的长文本评测集
|
||||||
|
- [ ] 发布长文本评测榜单
|
||||||
|
- [x] 代码能力
|
||||||
|
- [ ] 发布代码能力评测榜单
|
||||||
|
- [x] 提供非Python语言的评测服务
|
||||||
|
- [x] 智能体
|
||||||
|
- [ ] 支持丰富的智能体方案
|
||||||
|
- [x] 提供智能体评测榜单
|
||||||
|
- [x] 鲁棒性
|
||||||
|
- [x] 支持各类攻击方法
|
||||||
|
|
||||||
|
## 👷♂️ 贡献
|
||||||
|
|
||||||
|
我们感谢所有的贡献者为改进和提升 OpenCompass 所作出的努力。请参考[贡献指南](https://opencompass.readthedocs.io/zh_CN/latest/notes/contribution_guide.html)来了解参与项目贡献的相关指引。
|
||||||
|
|
||||||
|
<a href="https://github.com/open-compass/opencompass/graphs/contributors" target="_blank">
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<th colspan="2">
|
||||||
|
<br><img src="https://contrib.rocks/image?repo=open-compass/opencompass"><br><br>
|
||||||
|
</th>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
</a>
|
||||||
|
|
||||||
|
## 🤝 致谢
|
||||||
|
|
||||||
|
该项目部分的代码引用并修改自 [OpenICL](https://github.com/Shark-NLP/OpenICL)。
|
||||||
|
|
||||||
|
该项目部分的数据集和提示词实现修改自 [chain-of-thought-hub](https://github.com/FranxYao/chain-of-thought-hub), [instruct-eval](https://github.com/declare-lab/instruct-eval)
|
||||||
|
|
||||||
|
## 🖊️ 引用
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
<p align="right"><a href="#top">🔝返回顶部</a></p>
|
||||||
|
|
||||||
|
[github-contributors-link]: https://github.com/open-compass/opencompass/graphs/contributors
|
||||||
|
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/opencompass?color=c4f042&labelColor=black&style=flat-square
|
||||||
|
[github-forks-link]: https://github.com/open-compass/opencompass/network/members
|
||||||
|
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/opencompass?color=8ae8ff&labelColor=black&style=flat-square
|
||||||
|
[github-issues-link]: https://github.com/open-compass/opencompass/issues
|
||||||
|
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/opencompass?color=ff80eb&labelColor=black&style=flat-square
|
||||||
|
[github-license-link]: https://github.com/open-compass/opencompass/blob/main/LICENSE
|
||||||
|
[github-license-shield]: https://img.shields.io/github/license/open-compass/opencompass?color=white&labelColor=black&style=flat-square
|
||||||
|
[github-release-link]: https://github.com/open-compass/opencompass/releases
|
||||||
|
[github-release-shield]: https://img.shields.io/github/v/release/open-compass/opencompass?color=369eff&labelColor=black&logo=github&style=flat-square
|
||||||
|
[github-releasedate-link]: https://github.com/open-compass/opencompass/releases
|
||||||
|
[github-releasedate-shield]: https://img.shields.io/github/release-date/open-compass/opencompass?labelColor=black&style=flat-square
|
||||||
|
[github-stars-link]: https://github.com/open-compass/opencompass/stargazers
|
||||||
|
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/opencompass?color=ffcb47&labelColor=black&style=flat-square
|
||||||
|
[github-trending-shield]: https://trendshift.io/api/badge/repositories/6630
|
||||||
|
[github-trending-url]: https://trendshift.io/repositories/6630
|
||||||
|
|
@ -0,0 +1,993 @@
|
||||||
|
- ifeval:
|
||||||
|
name: IFEval
|
||||||
|
category: Instruction Following
|
||||||
|
paper: https://arxiv.org/pdf/2311.07911
|
||||||
|
configpath: opencompass/configs/datasets/IFEval/IFEval_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- nphard:
|
||||||
|
name: NPHardEval
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2312.14890v2
|
||||||
|
configpath: opencompass/configs/datasets/NPHardEval/NPHardEval_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- pmmeval:
|
||||||
|
name: PMMEval
|
||||||
|
category: Language
|
||||||
|
paper: https://arxiv.org/pdf/2411.09116v1
|
||||||
|
configpath: opencompass/configs/datasets/PMMEval/pmmeval_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- theoremqa:
|
||||||
|
name: TheroremQA
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2305.12524
|
||||||
|
configpath: opencompass/configs/datasets/TheroremQA/TheoremQA_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- agieval:
|
||||||
|
name: AGIEval
|
||||||
|
category: Examination
|
||||||
|
paper: https://arxiv.org/pdf/2304.06364
|
||||||
|
configpath: opencompass/configs/datasets/agieval/agieval_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- babilong:
|
||||||
|
name: BABILong
|
||||||
|
category: Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2406.10149
|
||||||
|
configpath: opencompass/configs/datasets/babilong
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- bigcodebench:
|
||||||
|
name: BigCodeBench
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2406.15877
|
||||||
|
configpath: opencompass/configs/datasets/bigcodebench/bigcodebench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- calm:
|
||||||
|
name: CaLM
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2405.00622
|
||||||
|
configpath: opencompass/configs/datasets/calm/calm.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- infinitebench:
|
||||||
|
name: InfiniteBench (∞Bench)
|
||||||
|
category: Long Context
|
||||||
|
paper: https://aclanthology.org/2024.acl-long.814.pdf
|
||||||
|
configpath: opencompass/configs/datasets/infinitebench/infinitebench.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- korbench:
|
||||||
|
name: KOR-Bench
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2410.06526v1
|
||||||
|
configpath: opencompass/configs/datasets/korbench/korbench_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/korbench/korbench_llm_judge_gen.py
|
||||||
|
- lawbench:
|
||||||
|
name: LawBench
|
||||||
|
category: Knowledge / Law
|
||||||
|
paper: https://arxiv.org/pdf/2309.16289
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/lawbench/lawbench_zero_shot_gen_002588.py
|
||||||
|
- opencompass/configs/datasets/lawbench/lawbench_one_shot_gen_002588.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- leval:
|
||||||
|
name: L-Eval
|
||||||
|
category: Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2307.11088v1
|
||||||
|
configpath: opencompass/configs/datasets/leval/leval.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- livecodebench:
|
||||||
|
name: LiveCodeBench
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2403.07974
|
||||||
|
configpath: opencompass/configs/datasets/livecodebench/livecodebench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- livemathbench:
|
||||||
|
name: LiveMathBench
|
||||||
|
category: Math
|
||||||
|
paper: https://arxiv.org/pdf/2412.13147
|
||||||
|
configpath: opencompass/configs/datasets/livemathbench/livemathbench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- livereasonbench:
|
||||||
|
name: LiveReasonBench
|
||||||
|
category: Reasoning
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/livereasonbench/livereasonbench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- longbench:
|
||||||
|
name: LongBench
|
||||||
|
category: Long Context
|
||||||
|
paper: https://github.com/THUDM/LongBench
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/longbench/longbench.py
|
||||||
|
- opencompass/configs/datasets/longbenchv2/longbenchv2_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- lveval:
|
||||||
|
name: LV-Eval
|
||||||
|
category: Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2402.05136
|
||||||
|
configpath: opencompass/configs/datasets/lveval/lveval.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mastermath2024v1:
|
||||||
|
name: Mastermath2024v1
|
||||||
|
category: Math
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/mastermath2024v1/mastermath2024v1_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- medbench:
|
||||||
|
name: MedBench
|
||||||
|
category: Knowledge / Medicine
|
||||||
|
paper: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10778138
|
||||||
|
configpath: opencompass/configs/datasets/MedBench/medbench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- musr:
|
||||||
|
name: MuSR
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2310.16049
|
||||||
|
configpath: opencompass/configs/datasets/musr/musr_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/musr/musr_llm_judge_gen.py
|
||||||
|
- needlebench:
|
||||||
|
name: NeedleBench
|
||||||
|
category: Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2407.11963
|
||||||
|
configpath: opencompass/configs/datasets/needlebench
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- ruler:
|
||||||
|
name: RULER
|
||||||
|
category: Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2404.06654
|
||||||
|
configpath: opencompass/configs/datasets/ruler
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- alignment:
|
||||||
|
name: AlignBench
|
||||||
|
category: Subjective / Alignment
|
||||||
|
paper: https://arxiv.org/pdf/2311.18743
|
||||||
|
configpath: opencompass/configs/datasets/subjective/alignbench
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- alpaca:
|
||||||
|
name: AlpacaEval
|
||||||
|
category: Subjective / Instruction Following
|
||||||
|
paper: https://github.com/tatsu-lab/alpaca_eval
|
||||||
|
configpath: opencompass/configs/datasets/subjective/aplaca_eval
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- arenahard:
|
||||||
|
name: Arena-Hard
|
||||||
|
category: Subjective / Chatbot
|
||||||
|
paper: https://lmsys.org/blog/2024-04-19-arena-hard/
|
||||||
|
configpath: opencompass/configs/datasets/subjective/arena_hard
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- flames:
|
||||||
|
name: FLAMES
|
||||||
|
category: Subjective / Alignment
|
||||||
|
paper: https://arxiv.org/pdf/2311.06899
|
||||||
|
configpath: opencompass/configs/datasets/subjective/flames/flames_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- fofo:
|
||||||
|
name: FOFO
|
||||||
|
category: Subjective / Format Following
|
||||||
|
paper: https://arxiv.org/pdf/2402.18667
|
||||||
|
configpath: opencompass/configs/datasets/subjective/fofo
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- followbench:
|
||||||
|
name: FollowBench
|
||||||
|
category: Subjective / Instruction Following
|
||||||
|
paper: https://arxiv.org/pdf/2310.20410
|
||||||
|
configpath: opencompass/configs/datasets/subjective/followbench
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- hellobench:
|
||||||
|
name: HelloBench
|
||||||
|
category: Subjective / Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2409.16191
|
||||||
|
configpath: opencompass/configs/datasets/subjective/hellobench
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- judgerbench:
|
||||||
|
name: JudgerBench
|
||||||
|
category: Subjective / Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2410.16256
|
||||||
|
configpath: opencompass/configs/datasets/subjective/judgerbench
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- multiround:
|
||||||
|
name: MT-Bench-101
|
||||||
|
category: Subjective / Multi-Round
|
||||||
|
paper: https://arxiv.org/pdf/2402.14762
|
||||||
|
configpath: opencompass/configs/datasets/subjective/multiround
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- wildbench:
|
||||||
|
name: WildBench
|
||||||
|
category: Subjective / Real Task
|
||||||
|
paper: https://arxiv.org/pdf/2406.04770
|
||||||
|
configpath: opencompass/configs/datasets/subjective/wildbench
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- teval:
|
||||||
|
name: T-Eval
|
||||||
|
category: Tool Utilization
|
||||||
|
paper: https://arxiv.org/pdf/2312.14033
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/teval/teval_en_gen.py
|
||||||
|
- opencompass/configs/datasets/teval/teval_zh_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- finalceiq:
|
||||||
|
name: FinanceIQ
|
||||||
|
category: Knowledge / Finance
|
||||||
|
paper: https://github.com/Duxiaoman-DI/XuanYuan/tree/main/FinanceIQ
|
||||||
|
configpath: opencompass/configs/datasets/FinanceIQ/FinanceIQ_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- gaokaobench:
|
||||||
|
name: GAOKAOBench
|
||||||
|
category: Examination
|
||||||
|
paper: https://arxiv.org/pdf/2305.12474
|
||||||
|
configpath: opencompass/configs/datasets/GaokaoBench/GaokaoBench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- lcbench:
|
||||||
|
name: LCBench
|
||||||
|
category: Code
|
||||||
|
paper: https://github.com/open-compass/CodeBench/
|
||||||
|
configpath: opencompass/configs/datasets/LCBench/lcbench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- MMLUArabic:
|
||||||
|
name: ArabicMMLU
|
||||||
|
category: Language
|
||||||
|
paper: https://arxiv.org/pdf/2402.12840
|
||||||
|
configpath: opencompass/configs/datasets/MMLUArabic/MMLUArabic_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- OpenFinData:
|
||||||
|
name: OpenFinData
|
||||||
|
category: Knowledge / Finance
|
||||||
|
paper: https://github.com/open-compass/OpenFinData
|
||||||
|
configpath: opencompass/configs/datasets/OpenFinData/OpenFinData_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- QuALITY:
|
||||||
|
name: QuALITY
|
||||||
|
category: Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2112.08608
|
||||||
|
configpath: opencompass/configs/datasets/QuALITY/QuALITY_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- advglue:
|
||||||
|
name: Adversarial GLUE
|
||||||
|
category: Safety
|
||||||
|
paper: https://openreview.net/pdf?id=GF9cSKI3A_q
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/adv_glue/adv_glue_mnli/adv_glue_mnli_gen.py
|
||||||
|
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_mm/adv_glue_mnli_mm_gen.py
|
||||||
|
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_qnli/adv_glue_qnli_gen.py
|
||||||
|
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_qqp/adv_glue_qqp_gen.py
|
||||||
|
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_rte/adv_glue_rte_gen.py
|
||||||
|
- opencompass/configs/datasets/adv_glue/adv_glue_mnli_sst2/adv_glue_sst2_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- afqmcd:
|
||||||
|
name: CLUE / AFQMC
|
||||||
|
category: Language
|
||||||
|
paper: https://arxiv.org/pdf/2004.05986
|
||||||
|
configpath: opencompass/configs/datasets/CLUE_afqmc/CLUE_afqmc_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- aime2024:
|
||||||
|
name: AIME2024
|
||||||
|
category: Examination
|
||||||
|
paper: https://huggingface.co/datasets/Maxwell-Jia/AIME_2024
|
||||||
|
configpath: opencompass/configs/datasets/aime2024/aime2024_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/aime2024/aime2024_llm_judge_gen.py
|
||||||
|
- anli:
|
||||||
|
name: Adversarial NLI
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/1910.14599v2
|
||||||
|
configpath: opencompass/configs/datasets/anli/anli_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- anthropics_evals:
|
||||||
|
name: Anthropics Evals
|
||||||
|
category: Safety
|
||||||
|
paper: https://arxiv.org/pdf/2212.09251
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/anthropics_evals/airisk_gen.py
|
||||||
|
- opencompass/configs/datasets/anthropics_evals/persona_gen.py
|
||||||
|
- opencompass/configs/datasets/anthropics_evals/sycophancy_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- apps:
|
||||||
|
name: APPS
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2105.09938
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/apps/apps_gen.py
|
||||||
|
- opencompass/configs/datasets/apps/apps_mini_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- arc:
|
||||||
|
name: ARC
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/1803.05457
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/ARC_c/ARC_c_gen.py
|
||||||
|
- opencompass/configs/datasets/ARC_e/ARC_e_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- arc_prize_public_eval:
|
||||||
|
name: ARC Prize
|
||||||
|
category: ARC-AGI
|
||||||
|
paper: https://arcprize.org/guide#private
|
||||||
|
configpath: opencompass/configs/datasets/ARC_Prize_Public_Evaluation/arc_prize_public_evaluation_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- ax:
|
||||||
|
name: SuperGLUE / AX
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/SuperGLUE_AX_b/SuperGLUE_AX_b_gen.py
|
||||||
|
- opencompass/configs/datasets/SuperGLUE_AX_g/SuperGLUE_AX_g_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- bbh:
|
||||||
|
name: BIG-Bench Hard
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2210.09261
|
||||||
|
configpath: opencompass/configs/datasets/bbh/bbh_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/bbh/bbh_llm_judge_gen.py
|
||||||
|
- bbeh:
|
||||||
|
name: BIG-Bench Extra Hard
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/abs/2502.19187
|
||||||
|
configpath: opencompass/configs/datasets/bbeh
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- BoolQ:
|
||||||
|
name: SuperGLUE / BoolQ
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_BoolQ/SuperGLUE_BoolQ_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- c3:
|
||||||
|
name: CLUE / C3 (C³)
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2004.05986
|
||||||
|
configpath: opencompass/configs/datasets/CLUE_C3/CLUE_C3_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cb:
|
||||||
|
name: SuperGLUE / CB
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_CB/SuperGLUE_CB_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- ceval:
|
||||||
|
name: C-EVAL
|
||||||
|
category: Examination
|
||||||
|
paper: https://arxiv.org/pdf/2305.08322v1
|
||||||
|
configpath: opencompass/configs/datasets/ceval/ceval_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- charm:
|
||||||
|
name: CHARM
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2403.14112
|
||||||
|
configpath: opencompass/configs/datasets/CHARM/charm_reason_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- chembench:
|
||||||
|
name: ChemBench
|
||||||
|
category: Knowledge / Chemistry
|
||||||
|
paper: https://arxiv.org/pdf/2404.01475
|
||||||
|
configpath: opencompass/configs/datasets/ChemBench/ChemBench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- chid:
|
||||||
|
name: FewCLUE / CHID
|
||||||
|
category: Language
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_chid/FewCLUE_chid_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- chinese_simpleqa:
|
||||||
|
name: Chinese SimpleQA
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/2411.07140
|
||||||
|
configpath: opencompass/configs/datasets/chinese_simpleqa/chinese_simpleqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cibench:
|
||||||
|
name: CIBench
|
||||||
|
category: Code
|
||||||
|
paper: https://www.arxiv.org/pdf/2407.10499
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/CIBench/CIBench_generation_gen_8ab0dc.py
|
||||||
|
- opencompass/configs/datasets/CIBench/CIBench_template_gen_e6b12a.py
|
||||||
|
- opencompass/configs/datasets/CIBench/CIBench_template_oracle_gen_fecda1.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- civilcomments:
|
||||||
|
name: CivilComments
|
||||||
|
category: Safety
|
||||||
|
paper: https://arxiv.org/pdf/1903.04561
|
||||||
|
configpath: opencompass/configs/datasets/civilcomments/civilcomments_clp.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- clozeTest_maxmin:
|
||||||
|
name: Cloze Test-max/min
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2102.04664
|
||||||
|
configpath: opencompass/configs/datasets/clozeTest_maxmin/clozeTest_maxmin_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cluewsc:
|
||||||
|
name: FewCLUE / CLUEWSC
|
||||||
|
category: Language / WSC
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_cluewsc/FewCLUE_cluewsc_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cmb:
|
||||||
|
name: CMB
|
||||||
|
category: Knowledge / Medicine
|
||||||
|
paper: https://arxiv.org/pdf/2308.08833
|
||||||
|
configpath: opencompass/configs/datasets/cmb/cmb_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cmmlu:
|
||||||
|
name: CMMLU
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2306.09212
|
||||||
|
configpath: opencompass/configs/datasets/cmmlu/cmmlu_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/cmmlu/cmmlu_llm_judge_gen.py
|
||||||
|
- cmnli:
|
||||||
|
name: CLUE / CMNLI
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2004.05986
|
||||||
|
configpath: opencompass/configs/datasets/CLUE_cmnli/CLUE_cmnli_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cmo_fib:
|
||||||
|
name: cmo_fib
|
||||||
|
category: Examination
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/cmo_fib/cmo_fib_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cmrc:
|
||||||
|
name: CLUE / CMRC
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2004.05986
|
||||||
|
configpath: opencompass/configs/datasets/CLUE_CMRC/CLUE_CMRC_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- commonsenseqa:
|
||||||
|
name: CommonSenseQA
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/1811.00937v2
|
||||||
|
configpath: opencompass/configs/datasets/commonsenseqa/commonsenseqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- commonsenseqa_cn:
|
||||||
|
name: CommonSenseQA-CN
|
||||||
|
category: Knowledge
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/commonsenseqa_cn/commonsenseqacn_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- copa:
|
||||||
|
name: SuperGLUE / COPA
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_COPA/SuperGLUE_COPA_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- crowspairs:
|
||||||
|
name: CrowsPairs
|
||||||
|
category: Safety
|
||||||
|
paper: https://arxiv.org/pdf/2010.00133
|
||||||
|
configpath: opencompass/configs/datasets/crowspairs/crowspairs_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- crowspairs_cn:
|
||||||
|
name: CrowsPairs-CN
|
||||||
|
category: Safety
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/crowspairs_cn/crowspairscn_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cvalues:
|
||||||
|
name: CVALUES
|
||||||
|
category: Safety
|
||||||
|
paper: http://xdp-expriment.oss-cn-zhangjiakou.aliyuncs.com/shanqi.xgh/release_github/CValues.pdf
|
||||||
|
configpath: opencompass/configs/datasets/cvalues/cvalues_responsibility_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- drcd:
|
||||||
|
name: CLUE / DRCD
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2004.05986
|
||||||
|
configpath: opencompass/configs/datasets/CLUE_DRCD/CLUE_DRCD_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- drop:
|
||||||
|
name: DROP (DROP Simple Eval)
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/1903.00161
|
||||||
|
configpath: opencompass/configs/datasets/drop/drop_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/drop/drop_llm_judge_gen.py
|
||||||
|
- ds1000:
|
||||||
|
name: DS-1000
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2211.11501
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/ds1000/ds1000_gen_5c4bec.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- eprstmt:
|
||||||
|
name: FewCLUE / EPRSTMT
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_eprstmt/FewCLUE_eprstmt_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- flores:
|
||||||
|
name: Flores
|
||||||
|
category: Language
|
||||||
|
paper: https://aclanthology.org/D19-1632.pdf
|
||||||
|
configpath: opencompass/configs/datasets/flores/flores_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- game24:
|
||||||
|
name: Game24
|
||||||
|
category: Math
|
||||||
|
paper: https://huggingface.co/datasets/nlile/24-game
|
||||||
|
configpath: opencompass/configs/datasets/game24/game24_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- govrepcrs:
|
||||||
|
name: Government Report Dataset
|
||||||
|
category: Long Context
|
||||||
|
paper: https://aclanthology.org/2021.naacl-main.112.pdf
|
||||||
|
configpath: opencompass/configs/datasets/govrepcrs/govrepcrs_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- gpqa:
|
||||||
|
name: GPQA
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/2311.12022v1
|
||||||
|
configpath: opencompass/configs/datasets/gpqa/gpqa_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/gpqa/gpqa_llm_judge_gen.py
|
||||||
|
- gsm8k:
|
||||||
|
name: GSM8K
|
||||||
|
category: Math
|
||||||
|
paper: https://arxiv.org/pdf/2110.14168v2
|
||||||
|
configpath: opencompass/configs/datasets/gsm8k/gsm8k_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- gsm_hard:
|
||||||
|
name: GSM-Hard
|
||||||
|
category: Math
|
||||||
|
paper: https://proceedings.mlr.press/v202/gao23f/gao23f.pdf
|
||||||
|
configpath: opencompass/configs/datasets/gsm_hard/gsmhard_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- hle:
|
||||||
|
name: HLE(Humanity's Last Exam)
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://lastexam.ai/paper
|
||||||
|
configpath: opencompass/configs/datasets/HLE/hle_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- hellaswag:
|
||||||
|
name: HellaSwag
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/1905.07830
|
||||||
|
configpath: opencompass/configs/datasets/hellaswag/hellaswag_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/hellaswag/hellaswag_llm_judge_gen.py
|
||||||
|
- humaneval:
|
||||||
|
name: HumanEval
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2107.03374v2
|
||||||
|
configpath: opencompass/configs/datasets/humaneval/humaneval_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- humaneval_cn:
|
||||||
|
name: HumanEval-CN
|
||||||
|
category: Code
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/humaneval_cn/humaneval_cn_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- humaneval_multi:
|
||||||
|
name: Multi-HumanEval
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2210.14868
|
||||||
|
configpath: opencompass/configs/datasets/humaneval_multi/humaneval_multi_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- humaneval_multi:
|
||||||
|
name: HumanEval+
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2305.01210
|
||||||
|
configpath: opencompass/configs/datasets/humaneval_plus/humaneval_plus_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- humanevalx:
|
||||||
|
name: HumanEval-X
|
||||||
|
category: Code
|
||||||
|
paper: https://dl.acm.org/doi/pdf/10.1145/3580305.3599790
|
||||||
|
configpath: opencompass/configs/datasets/humanevalx/humanevalx_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- hungarian_math:
|
||||||
|
name: Hungarian_Math
|
||||||
|
category: Math
|
||||||
|
paper: https://huggingface.co/datasets/keirp/hungarian_national_hs_finals_exam
|
||||||
|
configpath: opencompass/configs/datasets/hungarian_exam/hungarian_exam_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- iwslt2017:
|
||||||
|
name: IWSLT2017
|
||||||
|
category: Language
|
||||||
|
paper: https://cris.fbk.eu/bitstream/11582/312796/1/iwslt17-overview.pdf
|
||||||
|
configpath: opencompass/configs/datasets/iwslt2017/iwslt2017_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- jigsawmultilingual:
|
||||||
|
name: JigsawMultilingual
|
||||||
|
category: Safety
|
||||||
|
paper: https://www.kaggle.com/competitions/jigsaw-multilingual-toxic-comment-classification/data
|
||||||
|
configpath: opencompass/configs/datasets/jigsawmultilingual/jigsawmultilingual_clp.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- lambada:
|
||||||
|
name: LAMBADA
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/1606.06031
|
||||||
|
configpath: opencompass/configs/datasets/lambada/lambada_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- lcsts:
|
||||||
|
name: LCSTS
|
||||||
|
category: Understanding
|
||||||
|
paper: https://aclanthology.org/D15-1229.pdf
|
||||||
|
configpath: opencompass/configs/datasets/lcsts/lcsts_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- livestembench:
|
||||||
|
name: LiveStemBench
|
||||||
|
category: ''
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/livestembench/livestembench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- llm_compression:
|
||||||
|
name: LLM Compression
|
||||||
|
category: Bits Per Character (BPC)
|
||||||
|
paper: https://arxiv.org/pdf/2404.09937
|
||||||
|
configpath: opencompass/configs/datasets/llm_compression/llm_compression.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- math:
|
||||||
|
name: MATH
|
||||||
|
category: Math
|
||||||
|
paper: https://arxiv.org/pdf/2103.03874
|
||||||
|
configpath: opencompass/configs/datasets/math
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- math500:
|
||||||
|
name: MATH500
|
||||||
|
category: Math
|
||||||
|
paper: https://github.com/openai/prm800k
|
||||||
|
configpath: opencompass/configs/datasets/math/math_prm800k_500_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/math/math_prm800k_500_llm_judge_gen.py
|
||||||
|
- math401:
|
||||||
|
name: MATH 401
|
||||||
|
category: Math
|
||||||
|
paper: https://arxiv.org/pdf/2304.02015
|
||||||
|
configpath: opencompass/configs/datasets/math401/math401_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mathbench:
|
||||||
|
name: MathBench
|
||||||
|
category: Math
|
||||||
|
paper: https://arxiv.org/pdf/2405.12209
|
||||||
|
configpath: opencompass/configs/datasets/mathbench/mathbench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mbpp:
|
||||||
|
name: MBPP
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2108.07732
|
||||||
|
configpath: opencompass/configs/datasets/mbpp/mbpp_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mbpp_cn:
|
||||||
|
name: MBPP-CN
|
||||||
|
category: Code
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/mbpp_cn/mbpp_cn_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mbpp_plus:
|
||||||
|
name: MBPP-PLUS
|
||||||
|
category: Code
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/mbpp_plus/mbpp_plus_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mgsm:
|
||||||
|
name: MGSM
|
||||||
|
category: Language / Math
|
||||||
|
paper: https://arxiv.org/pdf/2210.03057
|
||||||
|
configpath: opencompass/configs/datasets/mgsm/mgsm_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mmlu:
|
||||||
|
name: MMLU
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2009.03300
|
||||||
|
configpath: opencompass/configs/datasets/mmlu/mmlu_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/mmlu/mmlu_llm_judge_gen.py
|
||||||
|
- mmlu_cf:
|
||||||
|
name: MMLU-CF
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2412.15194
|
||||||
|
configpath: opencompass/configs/datasets/mmlu_cf/mmlu_cf_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mmlu_pro:
|
||||||
|
name: MMLU-Pro
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2406.01574
|
||||||
|
configpath: opencompass/configs/datasets/mmlu_pro/mmlu_pro_gen.py
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/mmlu_pro/mmlu_pro_llm_judge_gen.py
|
||||||
|
- mmmlu:
|
||||||
|
name: MMMLU
|
||||||
|
category: Language / Understanding
|
||||||
|
paper: https://huggingface.co/datasets/openai/MMMLU
|
||||||
|
configpath:
|
||||||
|
- opencompass/configs/datasets/mmmlu/mmmlu_gen.py
|
||||||
|
- opencompass/configs/datasets/mmmlu_lite/mmmlu_lite_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- multirc:
|
||||||
|
name: SuperGLUE / MultiRC
|
||||||
|
category: Understanding
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_MultiRC/SuperGLUE_MultiRC_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- multipl_e:
|
||||||
|
name: MultiPL-E
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2210.14868
|
||||||
|
configpath: opencompass/configs/datasets/multipl_e
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- narrativeqa:
|
||||||
|
name: NarrativeQA
|
||||||
|
category: Understanding
|
||||||
|
paper: https://github.com/google-deepmind/narrativeqa
|
||||||
|
configpath: opencompass/configs/datasets/narrativeqa/narrativeqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- natural_question:
|
||||||
|
name: NaturalQuestions
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://github.com/google-research-datasets/natural-questions
|
||||||
|
configpath: opencompass/configs/datasets/nq/nq_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- natural_question_cn:
|
||||||
|
name: NaturalQuestions-CN
|
||||||
|
category: Knowledge
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/nq_cn/nqcn_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- obqa:
|
||||||
|
name: OpenBookQA
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/1809.02789v1
|
||||||
|
configpath: opencompass/configs/datasets/obqa/obqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- olymmath:
|
||||||
|
name: OlymMATH
|
||||||
|
category: Math
|
||||||
|
paper: https://arxiv.org/abs/2503.21380
|
||||||
|
configpath: ''
|
||||||
|
configpath_llmjudge: opencompass/configs/datasets/OlymMATH/olymmath_llm_judeg_gen.py
|
||||||
|
- piqa:
|
||||||
|
name: OpenBookQA
|
||||||
|
category: Knowledge / Physics
|
||||||
|
paper: https://arxiv.org/pdf/1911.11641v1
|
||||||
|
configpath: opencompass/configs/datasets/piqa/piqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- py150:
|
||||||
|
name: py150
|
||||||
|
category: Code
|
||||||
|
paper: https://github.com/microsoft/CodeXGLUE/tree/main/Code-Code/CodeCompletion-line
|
||||||
|
configpath: opencompass/configs/datasets/py150/py150_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- qasper:
|
||||||
|
name: Qasper
|
||||||
|
category: Long Context
|
||||||
|
paper: https://arxiv.org/pdf/2105.03011
|
||||||
|
configpath: opencompass/configs/datasets/qasper/qasper_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- qaspercut:
|
||||||
|
name: Qasper-Cut
|
||||||
|
category: Long Context
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/qaspercut/qaspercut_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- race:
|
||||||
|
name: RACE
|
||||||
|
category: Examination
|
||||||
|
paper: https://arxiv.org/pdf/1704.04683
|
||||||
|
configpath: opencompass/configs/datasets/race/race_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- realtoxicprompts:
|
||||||
|
name: RealToxicPrompts
|
||||||
|
category: Safety
|
||||||
|
paper: https://arxiv.org/pdf/2009.11462
|
||||||
|
configpath: opencompass/configs/datasets/realtoxicprompts/realtoxicprompts_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- record:
|
||||||
|
name: SuperGLUE / ReCoRD
|
||||||
|
category: Understanding
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_ReCoRD/SuperGLUE_ReCoRD_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- rte:
|
||||||
|
name: SuperGLUE / RTE
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_RTE/SuperGLUE_RTE_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- ocnli:
|
||||||
|
name: CLUE / OCNLI
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2004.05986
|
||||||
|
configpath: opencompass/configs/datasets/CLUE_ocnli/CLUE_ocnli_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- ocnlifc:
|
||||||
|
name: FewCLUE / OCNLI-FC
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_ocnli_fc/FewCLUE_ocnli_fc_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- rolebench:
|
||||||
|
name: RoleBench
|
||||||
|
category: Role Play
|
||||||
|
paper: https://arxiv.org/pdf/2310.00746
|
||||||
|
configpath: opencompass/configs/datasets/rolebench
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- s3eval:
|
||||||
|
name: S3Eval
|
||||||
|
category: Long Context
|
||||||
|
paper: https://aclanthology.org/2024.naacl-long.69.pdf
|
||||||
|
configpath: opencompass/configs/datasets/s3eval/s3eval_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- scibench:
|
||||||
|
name: SciBench
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://sxkdz.github.io/files/publications/ICML/SciBench/SciBench.pdf
|
||||||
|
configpath: opencompass/configs/datasets/scibench/scibench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- scicode:
|
||||||
|
name: SciCode
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2407.13168
|
||||||
|
configpath: opencompass/configs/datasets/scicode/scicode_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- simpleqa:
|
||||||
|
name: SimpleQA
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/2411.04368
|
||||||
|
configpath: opencompass/configs/datasets/SimpleQA/simpleqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- siqa:
|
||||||
|
name: SocialIQA
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/1904.09728
|
||||||
|
configpath: opencompass/configs/datasets/siqa/siqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- squad20:
|
||||||
|
name: SQuAD2.0
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/1806.03822
|
||||||
|
configpath: opencompass/configs/datasets/squad20/squad20_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- storycloze:
|
||||||
|
name: StoryCloze
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://aclanthology.org/2022.emnlp-main.616.pdf
|
||||||
|
configpath: opencompass/configs/datasets/storycloze/storycloze_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- strategyqa:
|
||||||
|
name: StrategyQA
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2101.02235
|
||||||
|
configpath: opencompass/configs/datasets/strategyqa/strategyqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- summedits:
|
||||||
|
name: SummEdits
|
||||||
|
category: Language
|
||||||
|
paper: https://aclanthology.org/2023.emnlp-main.600.pdf
|
||||||
|
configpath: opencompass/configs/datasets/summedits/summedits_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- summscreen:
|
||||||
|
name: SummScreen
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2104.07091v1
|
||||||
|
configpath: opencompass/configs/datasets/summscreen/summscreen_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- svamp:
|
||||||
|
name: SVAMP
|
||||||
|
category: Math
|
||||||
|
paper: https://aclanthology.org/2021.naacl-main.168.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SVAMP/svamp_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- tabmwp:
|
||||||
|
name: TabMWP
|
||||||
|
category: Math / Table
|
||||||
|
paper: https://arxiv.org/pdf/2209.14610
|
||||||
|
configpath: opencompass/configs/datasets/TabMWP/TabMWP_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- taco:
|
||||||
|
name: TACO
|
||||||
|
category: Code
|
||||||
|
paper: https://arxiv.org/pdf/2312.14852
|
||||||
|
configpath: opencompass/configs/datasets/taco/taco_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- tnews:
|
||||||
|
name: FewCLUE / TNEWS
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_tnews/FewCLUE_tnews_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- bustm:
|
||||||
|
name: FewCLUE / BUSTM
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_bustm/FewCLUE_bustm_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- csl:
|
||||||
|
name: FewCLUE / CSL
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_csl/FewCLUE_csl_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- ocnli_fc:
|
||||||
|
name: FewCLUE / OCNLI-FC
|
||||||
|
category: Reasoning
|
||||||
|
paper: https://arxiv.org/pdf/2107.07498
|
||||||
|
configpath: opencompass/configs/datasets/FewCLUE_ocnli_fc
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- triviaqa:
|
||||||
|
name: TriviaQA
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/1705.03551v2
|
||||||
|
configpath: opencompass/configs/datasets/triviaqa/triviaqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- triviaqarc:
|
||||||
|
name: TriviaQA-RC
|
||||||
|
category: Knowledge / Understanding
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/triviaqarc/triviaqarc_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- truthfulqa:
|
||||||
|
name: TruthfulQA
|
||||||
|
category: Safety
|
||||||
|
paper: https://arxiv.org/pdf/2109.07958v2
|
||||||
|
configpath: opencompass/configs/datasets/truthfulqa/truthfulqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- tydiqa:
|
||||||
|
name: TyDi-QA
|
||||||
|
category: Language
|
||||||
|
paper: https://storage.googleapis.com/tydiqa/tydiqa.pdf
|
||||||
|
configpath: opencompass/configs/datasets/tydiqa/tydiqa_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- wic:
|
||||||
|
name: SuperGLUE / WiC
|
||||||
|
category: Language
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_WiC/SuperGLUE_WiC_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- wsc:
|
||||||
|
name: SuperGLUE / WSC
|
||||||
|
category: Language / WSC
|
||||||
|
paper: https://proceedings.neurips.cc/paper_files/paper/2019/file/4496bf24afe7fab6f046bf4923da8de6-Paper.pdf
|
||||||
|
configpath: opencompass/configs/datasets/SuperGLUE_WSC/SuperGLUE_WSC_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- winogrande:
|
||||||
|
name: WinoGrande
|
||||||
|
category: Language / WSC
|
||||||
|
paper: https://arxiv.org/pdf/1907.10641v2
|
||||||
|
configpath: opencompass/configs/datasets/winogrande/winogrande_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- xcopa:
|
||||||
|
name: XCOPA
|
||||||
|
category: Language
|
||||||
|
paper: https://arxiv.org/pdf/2005.00333
|
||||||
|
configpath: opencompass/configs/datasets/XCOPA/XCOPA_ppl.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- xiezhi:
|
||||||
|
name: Xiezhi
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/2306.05783
|
||||||
|
configpath: opencompass/configs/datasets/xiezhi/xiezhi_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- xlsum:
|
||||||
|
name: XLSum
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/2106.13822v1
|
||||||
|
configpath: opencompass/configs/datasets/XLSum/XLSum_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- xsum:
|
||||||
|
name: Xsum
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/1808.08745
|
||||||
|
configpath: opencompass/configs/datasets/Xsum/Xsum_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- cola:
|
||||||
|
name: GLUE / CoLA
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/1804.07461
|
||||||
|
configpath: opencompass/configs/datasets/GLUE_CoLA/GLUE_CoLA_ppl.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- mprc:
|
||||||
|
name: GLUE / MPRC
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/1804.07461
|
||||||
|
configpath: opencompass/configs/datasets/GLUE_MRPC/GLUE_MRPC_ppl.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- qqp:
|
||||||
|
name: GLUE / QQP
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/1804.07461
|
||||||
|
configpath: opencompass/configs/datasets/GLUE_QQP/GLUE_QQP_ppl.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- omni_math:
|
||||||
|
name: Omni-MATH
|
||||||
|
category: Math
|
||||||
|
paper: https://omni-math.github.io/
|
||||||
|
configpath: opencompass/configs/datasets/omni_math/omni_math_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- wikibench:
|
||||||
|
name: WikiBench
|
||||||
|
category: Knowledge
|
||||||
|
paper: ''
|
||||||
|
configpath: opencompass/configs/datasets/wikibench/wikibench_gen.py
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
- supergpqa:
|
||||||
|
name: SuperGPQA
|
||||||
|
category: Knowledge
|
||||||
|
paper: https://arxiv.org/pdf/2502.14739
|
||||||
|
configpath: opencompass/configs/datasets/supergpqa
|
||||||
|
configpath_llmjudge: ''
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
version: 2
|
||||||
|
|
||||||
|
# Set the version of Python and other tools you might need
|
||||||
|
build:
|
||||||
|
os: ubuntu-22.04
|
||||||
|
tools:
|
||||||
|
python: "3.8"
|
||||||
|
|
||||||
|
formats:
|
||||||
|
- epub
|
||||||
|
|
||||||
|
sphinx:
|
||||||
|
configuration: docs/en/conf.py
|
||||||
|
|
||||||
|
python:
|
||||||
|
install:
|
||||||
|
- requirements: requirements/docs.txt
|
||||||
|
|
@ -0,0 +1,20 @@
|
||||||
|
# Minimal makefile for Sphinx documentation
|
||||||
|
#
|
||||||
|
|
||||||
|
# You can set these variables from the command line, and also
|
||||||
|
# from the environment for the first two.
|
||||||
|
SPHINXOPTS ?=
|
||||||
|
SPHINXBUILD ?= sphinx-build
|
||||||
|
SOURCEDIR = .
|
||||||
|
BUILDDIR = _build
|
||||||
|
|
||||||
|
# Put it first so that "make" without argument is like "make help".
|
||||||
|
help:
|
||||||
|
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||||
|
|
||||||
|
.PHONY: help Makefile
|
||||||
|
|
||||||
|
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||||
|
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||||
|
%: Makefile
|
||||||
|
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||||
|
|
@ -0,0 +1,62 @@
|
||||||
|
.header-logo {
|
||||||
|
background-image: url("../image/logo.svg");
|
||||||
|
background-size: 275px 80px;
|
||||||
|
height: 80px;
|
||||||
|
width: 275px;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media screen and (min-width: 1100px) {
|
||||||
|
.header-logo {
|
||||||
|
top: -25px;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
pre {
|
||||||
|
white-space: pre;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media screen and (min-width: 2000px) {
|
||||||
|
.pytorch-content-left {
|
||||||
|
width: 1200px;
|
||||||
|
margin-left: 30px;
|
||||||
|
}
|
||||||
|
article.pytorch-article {
|
||||||
|
max-width: 1200px;
|
||||||
|
}
|
||||||
|
.pytorch-breadcrumbs-wrapper {
|
||||||
|
width: 1200px;
|
||||||
|
}
|
||||||
|
.pytorch-right-menu.scrolling-fixed {
|
||||||
|
position: fixed;
|
||||||
|
top: 45px;
|
||||||
|
left: 1580px;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
article.pytorch-article section code {
|
||||||
|
padding: .2em .4em;
|
||||||
|
background-color: #f3f4f7;
|
||||||
|
border-radius: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Disable the change in tables */
|
||||||
|
article.pytorch-article section table code {
|
||||||
|
padding: unset;
|
||||||
|
background-color: unset;
|
||||||
|
border-radius: unset;
|
||||||
|
}
|
||||||
|
|
||||||
|
table.autosummary td {
|
||||||
|
width: 50%
|
||||||
|
}
|
||||||
|
|
||||||
|
img.align-center {
|
||||||
|
display: block;
|
||||||
|
margin-left: auto;
|
||||||
|
margin-right: auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
article.pytorch-article p.rubric {
|
||||||
|
font-weight: bold;
|
||||||
|
}
|
||||||
{kind=link}
|
|
@ -0,0 +1,79 @@
|
||||||
|
<?xml version="1.0" encoding="utf-8"?>
|
||||||
|
<!-- Generator: Adobe Illustrator 27.3.1, SVG Export Plug-In . SVG Version: 6.00 Build 0) -->
|
||||||
|
<svg version="1.1" id="图层_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" x="0px" y="0px"
|
||||||
|
viewBox="0 0 210 36" style="enable-background:new 0 0 210 36;" xml:space="preserve">
|
||||||
|
<style type="text/css">
|
||||||
|
.st0{fill:#5878B4;}
|
||||||
|
.st1{fill:#36569B;}
|
||||||
|
.st2{fill:#1B3882;}
|
||||||
|
</style>
|
||||||
|
<g id="_x33_">
|
||||||
|
<g>
|
||||||
|
<path class="st0" d="M16.5,22.6l-6.4,3.1l5.3-0.2L16.5,22.6z M12.3,33.6l1.1-2.9l-5.3,0.2L12.3,33.6z M21.6,33.3l6.4-3.1l-5.3,0.2
|
||||||
|
L21.6,33.3z M25.8,22.4l-1.1,2.9l5.3-0.2L25.8,22.4z M31.5,26.2l-7.1,0.2l-1.7-1.1l1.5-4L22.2,20L19,21.5l-1.5,3.9l-2.7,1.3
|
||||||
|
l-7.1,0.2l-3.2,1.5l2.1,1.4l7.1-0.2l0,0l1.7,1.1l-1.5,4L16,36l3.2-1.5l1.5-3.9l0,0l2.6-1.2l0,0l7.2-0.2l3.2-1.5L31.5,26.2z
|
||||||
|
M20.2,28.7c-1,0.5-2.3,0.5-3,0.1c-0.6-0.4-0.4-1.2,0.6-1.6c1-0.5,2.3-0.5,3-0.1C21.5,27.5,21.2,28.2,20.2,28.7z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
<g id="_x32_">
|
||||||
|
<g>
|
||||||
|
<path class="st1" d="M33.5,19.8l-1.3-6.5l-1.5,1.9L33.5,19.8z M27.5,5.1l-4.2-2.7L26,7L27.5,5.1z M20.7,5.7l1.3,6.5l1.5-1.9
|
||||||
|
L20.7,5.7z M26.8,20.4l4.2,2.7l-2.7-4.6L26.8,20.4z M34,22.3l-3.6-6.2l0,0l-0.5-2.7l2-2.6l-0.6-3.2l-2.1-1.4l-2,2.6l-1.7-1.1
|
||||||
|
l-3.7-6.3L19.6,0l0.6,3.2l3.7,6.3l0,0l0.5,2.6l0,0l-2,2.6l0.6,3.2l2.1,1.4l1.9-2.5l1.7,1.1l3.7,6.3l2.1,1.4L34,22.3z M27.5,14.6
|
||||||
|
c-0.6-0.4-1.3-1.6-1.5-2.6c-0.2-1,0.2-1.5,0.8-1.1c0.6,0.4,1.3,1.6,1.5,2.6C28.5,14.6,28.1,15.1,27.5,14.6z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
<g id="_x31_">
|
||||||
|
<g>
|
||||||
|
<path class="st2" d="M12,2.8L5.6,5.9l3.8,1.7L12,2.8z M1.1,14.4l1.3,6.5l2.6-4.8L1.1,14.4z M9.1,24l6.4-3.1l-3.8-1.7L9.1,24z
|
||||||
|
M20,12.4l-1.3-6.5l-2.6,4.8L20,12.4z M20.4,14.9l-5.1-2.3l0,0l-0.5-2.7l3.5-6.5l-0.6-3.2l-3.2,1.5L11,8.1L8.3,9.4l0,0L3.2,7.1
|
||||||
|
L0,8.6l0.6,3.2l5.2,2.3l0.5,2.7v0l-3.5,6.6l0.6,3.2l3.2-1.5l3.5-6.5l2.6-1.2l0,0l5.2,2.4l3.2-1.5L20.4,14.9z M10.9,15.2
|
||||||
|
c-1,0.5-1.9,0-2.1-1c-0.2-1,0.4-2.2,1.4-2.7c1-0.5,1.9,0,2.1,1C12.5,13.5,11.9,14.7,10.9,15.2z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
<path id="字" class="st2" d="M49.5,26.5c-2.5,0-4.4-0.7-5.7-2c-1.8-1.6-2.6-4-2.6-7.1c0-3.2,0.9-5.5,2.6-7.1c1.3-1.3,3.2-2,5.7-2
|
||||||
|
c2.5,0,4.4,0.7,5.7,2c1.7,1.6,2.6,4,2.6,7.1c0,3.1-0.9,5.5-2.6,7.1C53.8,25.8,51.9,26.5,49.5,26.5z M52.9,21.8
|
||||||
|
c0.8-1.1,1.3-2.6,1.3-4.5c0-1.9-0.4-3.4-1.3-4.5c-0.8-1.1-2-1.6-3.4-1.6c-1.4,0-2.6,0.5-3.4,1.6c-0.9,1.1-1.3,2.6-1.3,4.5
|
||||||
|
c0,1.9,0.4,3.4,1.3,4.5c0.9,1.1,2,1.6,3.4,1.6C50.9,23.4,52,22.9,52.9,21.8z M70.9,14.6c1,1.1,1.5,2.7,1.5,4.9c0,2.2-0.5,4-1.5,5.1
|
||||||
|
c-1,1.2-2.3,1.8-3.9,1.8c-1,0-1.9-0.3-2.5-0.8c-0.4-0.3-0.7-0.7-1.1-1.2V31h-3.3V13.2h3.2v1.9c0.4-0.6,0.7-1,1.1-1.3
|
||||||
|
c0.7-0.6,1.6-0.9,2.6-0.9C68.6,12.9,69.9,13.5,70.9,14.6z M69,19.6c0-1-0.2-1.9-0.7-2.6c-0.4-0.8-1.2-1.1-2.2-1.1
|
||||||
|
c-1.2,0-2,0.6-2.5,1.7c-0.2,0.6-0.4,1.4-0.4,2.3c0,1.5,0.4,2.5,1.2,3.1c0.5,0.4,1,0.5,1.7,0.5c0.9,0,1.6-0.4,2.1-1.1
|
||||||
|
C68.8,21.8,69,20.8,69,19.6z M85.8,22.2c-0.1,0.8-0.5,1.5-1.2,2.3c-1.1,1.2-2.6,1.9-4.6,1.9c-1.6,0-3.1-0.5-4.3-1.6
|
||||||
|
c-1.2-1-1.9-2.8-1.9-5.1c0-2.2,0.6-3.9,1.7-5.1c1.1-1.2,2.6-1.8,4.4-1.8c1.1,0,2,0.2,2.9,0.6c0.9,0.4,1.6,1,2.1,1.9
|
||||||
|
c0.5,0.8,0.8,1.6,1,2.6c0.1,0.6,0.1,1.4,0.1,2.5h-8.7c0,1.3,0.4,2.2,1.2,2.7c0.5,0.3,1,0.5,1.7,0.5c0.7,0,1.2-0.2,1.7-0.6
|
||||||
|
c0.2-0.2,0.4-0.5,0.6-0.9H85.8z M82.5,18.3c-0.1-0.9-0.3-1.6-0.8-2c-0.5-0.5-1.1-0.7-1.8-0.7c-0.8,0-1.4,0.2-1.8,0.7
|
||||||
|
c-0.4,0.5-0.7,1.1-0.8,2H82.5z M94.3,15.7c-1.1,0-1.9,0.5-2.3,1.4c-0.2,0.5-0.3,1.2-0.3,1.9V26h-3.3V13.2h3.2v1.9
|
||||||
|
c0.4-0.7,0.8-1.1,1.2-1.4c0.7-0.5,1.6-0.8,2.6-0.8c1.3,0,2.4,0.3,3.2,1c0.8,0.7,1.3,1.8,1.3,3.4V26h-3.4v-7.8c0-0.7-0.1-1.2-0.3-1.5
|
||||||
|
C95.8,16,95.2,15.7,94.3,15.7z M115.4,24.7c-1.3,1.2-2.9,1.8-4.9,1.8c-2.5,0-4.4-0.8-5.9-2.4c-1.4-1.6-2.1-3.8-2.1-6.6
|
||||||
|
c0-3,0.8-5.3,2.4-7c1.4-1.4,3.2-2.1,5.4-2.1c2.9,0,5,1,6.4,2.9c0.7,1.1,1.1,2.1,1.2,3.2h-3.6c-0.2-0.8-0.5-1.5-0.9-1.9
|
||||||
|
c-0.7-0.8-1.6-1.1-2.9-1.1c-1.3,0-2.3,0.5-3.1,1.6c-0.8,1.1-1.1,2.6-1.1,4.5s0.4,3.4,1.2,4.4c0.8,1,1.8,1.4,3.1,1.4
|
||||||
|
c1.3,0,2.2-0.4,2.9-1.2c0.4-0.4,0.7-1.1,0.9-2h3.6C117.5,22,116.7,23.5,115.4,24.7z M130.9,14.8c1.1,1.4,1.6,2.9,1.6,4.8
|
||||||
|
c0,1.9-0.5,3.5-1.6,4.8c-1.1,1.3-2.7,2-4.9,2c-2.2,0-3.8-0.7-4.9-2c-1.1-1.3-1.6-2.9-1.6-4.8c0-1.8,0.5-3.4,1.6-4.8
|
||||||
|
c1.1-1.4,2.7-2,4.9-2C128.2,12.8,129.9,13.5,130.9,14.8z M126,15.6c-1,0-1.7,0.3-2.3,1c-0.5,0.7-0.8,1.7-0.8,3c0,1.3,0.3,2.3,0.8,3
|
||||||
|
c0.5,0.7,1.3,1,2.3,1c1,0,1.7-0.3,2.3-1c0.5-0.7,0.8-1.7,0.8-3c0-1.3-0.3-2.3-0.8-3C127.7,16,127,15.6,126,15.6z M142.1,16.7
|
||||||
|
c-0.3-0.6-0.8-0.9-1.7-0.9c-1,0-1.6,0.3-1.9,0.9c-0.2,0.4-0.3,0.9-0.3,1.6V26h-3.4V13.2h3.2v1.9c0.4-0.7,0.8-1.1,1.2-1.4
|
||||||
|
c0.6-0.5,1.5-0.8,2.5-0.8c1,0,1.8,0.2,2.4,0.6c0.5,0.4,0.9,0.9,1.1,1.5c0.4-0.8,1-1.3,1.6-1.7c0.7-0.4,1.5-0.5,2.3-0.5
|
||||||
|
c0.6,0,1.1,0.1,1.7,0.3c0.5,0.2,1,0.6,1.5,1.1c0.4,0.4,0.6,1,0.7,1.6c0.1,0.4,0.1,1.1,0.1,1.9l0,8.1h-3.4v-8.1
|
||||||
|
c0-0.5-0.1-0.9-0.2-1.2c-0.3-0.6-0.8-0.9-1.6-0.9c-0.9,0-1.6,0.4-1.9,1.1c-0.2,0.4-0.3,0.9-0.3,1.5V26h-3.4v-7.6
|
||||||
|
C142.4,17.6,142.3,17.1,142.1,16.7z M167,14.6c1,1.1,1.5,2.7,1.5,4.9c0,2.2-0.5,4-1.5,5.1c-1,1.2-2.3,1.8-3.9,1.8
|
||||||
|
c-1,0-1.9-0.3-2.5-0.8c-0.4-0.3-0.7-0.7-1.1-1.2V31h-3.3V13.2h3.2v1.9c0.4-0.6,0.7-1,1.1-1.3c0.7-0.6,1.6-0.9,2.6-0.9
|
||||||
|
C164.7,12.9,166,13.5,167,14.6z M165.1,19.6c0-1-0.2-1.9-0.7-2.6c-0.4-0.8-1.2-1.1-2.2-1.1c-1.2,0-2,0.6-2.5,1.7
|
||||||
|
c-0.2,0.6-0.4,1.4-0.4,2.3c0,1.5,0.4,2.5,1.2,3.1c0.5,0.4,1,0.5,1.7,0.5c0.9,0,1.6-0.4,2.1-1.1C164.9,21.8,165.1,20.8,165.1,19.6z
|
||||||
|
M171.5,14.6c0.9-1.1,2.4-1.7,4.5-1.7c1.4,0,2.6,0.3,3.7,0.8c1.1,0.6,1.6,1.6,1.6,3.1v5.9c0,0.4,0,0.9,0,1.5c0,0.4,0.1,0.7,0.2,0.9
|
||||||
|
c0.1,0.2,0.3,0.3,0.5,0.4V26h-3.6c-0.1-0.3-0.2-0.5-0.2-0.7c0-0.2-0.1-0.5-0.1-0.8c-0.5,0.5-1,0.9-1.6,1.3c-0.7,0.4-1.5,0.6-2.4,0.6
|
||||||
|
c-1.2,0-2.1-0.3-2.9-1c-0.8-0.7-1.1-1.6-1.1-2.8c0-1.6,0.6-2.7,1.8-3.4c0.7-0.4,1.6-0.7,2.9-0.8l1.1-0.1c0.6-0.1,1.1-0.2,1.3-0.3
|
||||||
|
c0.5-0.2,0.7-0.5,0.7-0.9c0-0.5-0.2-0.9-0.6-1.1c-0.4-0.2-0.9-0.3-1.6-0.3c-0.8,0-1.3,0.2-1.7,0.6c-0.2,0.3-0.4,0.7-0.5,1.2h-3.2
|
||||||
|
C170.6,16.2,170.9,15.3,171.5,14.6z M173.9,23.6c0.3,0.3,0.7,0.4,1.1,0.4c0.7,0,1.4-0.2,2-0.6c0.6-0.4,0.9-1.2,0.9-2.3v-1.2
|
||||||
|
c-0.2,0.1-0.4,0.2-0.6,0.3c-0.2,0.1-0.5,0.2-0.9,0.2l-0.8,0.1c-0.7,0.1-1.2,0.3-1.5,0.5c-0.5,0.3-0.8,0.8-0.8,1.4
|
||||||
|
C173.5,22.9,173.6,23.3,173.9,23.6z M193.1,13.8c1,0.6,1.6,1.7,1.7,3.3h-3.3c0-0.4-0.2-0.8-0.4-1c-0.4-0.5-1-0.7-1.9-0.7
|
||||||
|
c-0.7,0-1.2,0.1-1.6,0.3c-0.3,0.2-0.5,0.5-0.5,0.8c0,0.4,0.2,0.7,0.5,0.8c0.3,0.2,1.5,0.5,3.5,0.9c1.3,0.3,2.3,0.8,3,1.4
|
||||||
|
c0.7,0.6,1,1.4,1,2.4c0,1.3-0.5,2.3-1.4,3.1c-0.9,0.8-2.4,1.2-4.4,1.2c-2,0-3.5-0.4-4.5-1.3c-1-0.9-1.4-1.9-1.4-3.2h3.4
|
||||||
|
c0.1,0.6,0.2,1,0.5,1.3c0.4,0.4,1.2,0.7,2.3,0.7c0.7,0,1.2-0.1,1.6-0.3c0.4-0.2,0.6-0.5,0.6-0.9c0-0.4-0.2-0.7-0.5-0.9
|
||||||
|
c-0.3-0.2-1.5-0.5-3.5-1c-1.4-0.4-2.5-0.8-3.1-1.3c-0.6-0.5-0.9-1.3-0.9-2.3c0-1.2,0.5-2.2,1.4-3c0.9-0.9,2.2-1.3,3.9-1.3
|
||||||
|
C190.8,12.9,192.1,13.2,193.1,13.8z M206.5,13.8c1,0.6,1.6,1.7,1.7,3.3h-3.3c0-0.4-0.2-0.8-0.4-1c-0.4-0.5-1-0.7-1.9-0.7
|
||||||
|
c-0.7,0-1.2,0.1-1.6,0.3c-0.3,0.2-0.5,0.5-0.5,0.8c0,0.4,0.2,0.7,0.5,0.8c0.3,0.2,1.5,0.5,3.5,0.9c1.3,0.3,2.3,0.8,3,1.4
|
||||||
|
c0.7,0.6,1,1.4,1,2.4c0,1.3-0.5,2.3-1.4,3.1c-0.9,0.8-2.4,1.2-4.4,1.2c-2,0-3.5-0.4-4.5-1.3c-1-0.9-1.4-1.9-1.4-3.2h3.4
|
||||||
|
c0.1,0.6,0.2,1,0.5,1.3c0.4,0.4,1.2,0.7,2.3,0.7c0.7,0,1.2-0.1,1.6-0.3c0.4-0.2,0.6-0.5,0.6-0.9c0-0.4-0.2-0.7-0.5-0.9
|
||||||
|
c-0.3-0.2-1.5-0.5-3.5-1c-1.4-0.4-2.5-0.8-3.1-1.3c-0.6-0.5-0.9-1.3-0.9-2.3c0-1.2,0.5-2.2,1.4-3c0.9-0.9,2.2-1.3,3.9-1.3
|
||||||
|
C204.2,12.9,205.5,13.2,206.5,13.8z"/>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 7.0 KiB |
{kind=link}
|
|
@ -0,0 +1,31 @@
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<svg id="_图层_2" data-name="图层 2" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 34.59 36">
|
||||||
|
<defs>
|
||||||
|
<style>
|
||||||
|
.cls-1 {
|
||||||
|
fill: #36569b;
|
||||||
|
}
|
||||||
|
|
||||||
|
.cls-2 {
|
||||||
|
fill: #1b3882;
|
||||||
|
}
|
||||||
|
|
||||||
|
.cls-3 {
|
||||||
|
fill: #5878b4;
|
||||||
|
}
|
||||||
|
</style>
|
||||||
|
</defs>
|
||||||
|
<g id="_图层_1-2" data-name="图层 1">
|
||||||
|
<g>
|
||||||
|
<g id="_3" data-name="3">
|
||||||
|
<path class="cls-3" d="m16.53,22.65l-6.37,3.07,5.27-.16,1.1-2.91Zm-4.19,10.95l1.12-2.91-5.27.17,4.15,2.74Zm9.3-.29l6.37-3.07-5.27.16-1.1,2.91Zm4.19-10.95l-1.12,2.91,5.27-.17-4.15-2.74Zm5.72,3.81l-7.08.23-1.73-1.14,1.5-3.95-2.06-1.36-3.16,1.53-1.48,3.89-2.67,1.29-7.14.23-3.16,1.53,2.07,1.36,7.13-.23h0s1.69,1.11,1.69,1.11l-1.51,3.98,2.06,1.36,3.16-1.53,1.5-3.95h0s2.56-1.24,2.56-1.24h0s7.23-.24,7.23-.24l3.16-1.53-2.06-1.36Zm-11.29,2.56c-.99.48-2.31.52-2.96.1-.65-.42-.37-1.15.62-1.63.99-.48,2.31-.52,2.96-.1.65.42.37,1.15-.62,1.63Z"/>
|
||||||
|
</g>
|
||||||
|
<g id="_2" data-name="2">
|
||||||
|
<path class="cls-1" d="m33.5,19.84l-1.26-6.51-1.46,1.88,2.72,4.63Zm-6.05-14.69l-4.16-2.74,2.71,4.64,1.45-1.89Zm-6.73.58l1.26,6.51,1.46-1.88-2.72-4.63Zm6.05,14.69l4.16,2.74-2.71-4.64-1.45,1.89Zm7.19,1.91l-3.63-6.2h0s-.53-2.74-.53-2.74l1.96-2.56-.63-3.23-2.07-1.36-1.96,2.56-1.69-1.11-3.71-6.33-2.07-1.36.63,3.23,3.68,6.28h0s.51,2.62.51,2.62h0s-1.99,2.6-1.99,2.6l.63,3.23,2.06,1.36,1.95-2.54,1.73,1.14,3.69,6.29,2.07,1.36-.63-3.23Zm-6.47-7.7c-.65-.42-1.33-1.59-1.52-2.6-.2-1.01.17-1.49.81-1.06.65.42,1.33,1.59,1.52,2.6.2,1.01-.17,1.49-.81,1.06Z"/>
|
||||||
|
</g>
|
||||||
|
<g id="_1" data-name="1">
|
||||||
|
<path class="cls-2" d="m11.96,2.82l-6.37,3.07,3.81,1.74,2.55-4.81ZM1.07,14.37l1.26,6.53,2.56-4.8-3.82-1.73Zm7.99,9.59l6.37-3.07-3.81-1.74-2.55,4.81Zm10.89-11.55l-1.26-6.53-2.56,4.8,3.82,1.73Zm.45,2.53l-5.13-2.32h0s-.53-2.71-.53-2.71l3.47-6.53-.63-3.24-3.16,1.53-3.42,6.43-2.67,1.29h0s-5.17-2.34-5.17-2.34l-3.16,1.53.63,3.24,5.17,2.33.51,2.65h0s-3.49,6.57-3.49,6.57l.63,3.24,3.16-1.53,3.46-6.52,2.56-1.24h0s5.24,2.37,5.24,2.37l3.16-1.53-.63-3.24Zm-9.52.24c-.99.48-1.95.04-2.14-.97-.2-1.01.44-2.22,1.43-2.69.99-.48,1.95-.04,2.14.97.2,1.01-.44,2.22-1.43,2.7Z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.1 KiB |
|
|
@ -0,0 +1,20 @@
|
||||||
|
var collapsedSections = ['Dataset Statistics'];
|
||||||
|
|
||||||
|
$(document).ready(function () {
|
||||||
|
$('.dataset').DataTable({
|
||||||
|
"stateSave": false,
|
||||||
|
"lengthChange": false,
|
||||||
|
"pageLength": 20,
|
||||||
|
"order": [],
|
||||||
|
"language": {
|
||||||
|
"info": "Show _START_ to _END_ Items(Totally _TOTAL_ )",
|
||||||
|
"infoFiltered": "(Filtered from _MAX_ Items)",
|
||||||
|
"search": "Search:",
|
||||||
|
"zeroRecords": "Item Not Found",
|
||||||
|
"paginate": {
|
||||||
|
"next": "Next",
|
||||||
|
"previous": "Previous"
|
||||||
|
},
|
||||||
|
}
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
@ -0,0 +1,18 @@
|
||||||
|
{% extends "layout.html" %}
|
||||||
|
|
||||||
|
{% block body %}
|
||||||
|
|
||||||
|
<h1>Page Not Found</h1>
|
||||||
|
<p>
|
||||||
|
The page you are looking for cannot be found.
|
||||||
|
</p>
|
||||||
|
<p>
|
||||||
|
If you just switched documentation versions, it is likely that the page you were on is moved. You can look for it in
|
||||||
|
the content table left, or go to <a href="{{ pathto(root_doc) }}">the homepage</a>.
|
||||||
|
</p>
|
||||||
|
<!-- <p>
|
||||||
|
If you cannot find documentation you want, please <a
|
||||||
|
href="">open an issue</a> to tell us!
|
||||||
|
</p> -->
|
||||||
|
|
||||||
|
{% endblock %}
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
.. role:: hidden
|
||||||
|
:class: hidden-section
|
||||||
|
.. currentmodule:: {{ module }}
|
||||||
|
|
||||||
|
|
||||||
|
{{ name | underline}}
|
||||||
|
|
||||||
|
.. autoclass:: {{ name }}
|
||||||
|
:members:
|
||||||
|
|
||||||
|
..
|
||||||
|
autogenerated from _templates/autosummary/class.rst
|
||||||
|
note it does not have :inherited-members:
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
.. role:: hidden
|
||||||
|
:class: hidden-section
|
||||||
|
.. currentmodule:: {{ module }}
|
||||||
|
|
||||||
|
|
||||||
|
{{ name | underline}}
|
||||||
|
|
||||||
|
.. autoclass:: {{ name }}
|
||||||
|
:members:
|
||||||
|
:special-members: __call__
|
||||||
|
|
||||||
|
..
|
||||||
|
autogenerated from _templates/callable.rst
|
||||||
|
note it does not have :inherited-members:
|
||||||
|
|
@ -0,0 +1,142 @@
|
||||||
|
# Accelerate Evaluation Inference with vLLM or LMDeploy
|
||||||
|
|
||||||
|
## Background
|
||||||
|
|
||||||
|
During the OpenCompass evaluation process, the Huggingface transformers library is used for inference by default. While this is a very general solution, there are scenarios where more efficient inference methods are needed to speed up the process, such as leveraging VLLM or LMDeploy.
|
||||||
|
|
||||||
|
- [LMDeploy](https://github.com/InternLM/lmdeploy) is a toolkit designed for compressing, deploying, and serving large language models (LLMs), developed by the [MMRazor](https://github.com/open-mmlab/mmrazor) and [MMDeploy](https://github.com/open-mmlab/mmdeploy) teams.
|
||||||
|
- [vLLM](https://github.com/vllm-project/vllm) is a fast and user-friendly library for LLM inference and serving, featuring advanced serving throughput, efficient PagedAttention memory management, continuous batching of requests, fast model execution via CUDA/HIP graphs, quantization techniques (e.g., GPTQ, AWQ, SqueezeLLM, FP8 KV Cache), and optimized CUDA kernels.
|
||||||
|
|
||||||
|
## Preparation for Acceleration
|
||||||
|
|
||||||
|
First, check whether the model you want to evaluate supports inference acceleration using vLLM or LMDeploy. Additionally, ensure you have installed vLLM or LMDeploy as per their official documentation. Below are the installation methods for reference:
|
||||||
|
|
||||||
|
### LMDeploy Installation Method
|
||||||
|
|
||||||
|
Install LMDeploy using pip (Python 3.8+) or from [source](https://github.com/InternLM/lmdeploy/blob/main/docs/en/build.md):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
### VLLM Installation Method
|
||||||
|
|
||||||
|
Install vLLM using pip or from [source](https://vllm.readthedocs.io/en/latest/getting_started/installation.html#build-from-source):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
## Accelerated Evaluation Using VLLM or LMDeploy
|
||||||
|
|
||||||
|
### Method 1: Using Command Line Parameters to Change the Inference Backend
|
||||||
|
|
||||||
|
OpenCompass offers one-click evaluation acceleration. During evaluation, it can automatically convert Huggingface transformer models to VLLM or LMDeploy models for use. Below is an example code for evaluating the GSM8k dataset using the default Huggingface version of the llama3-8b-instruct model:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# eval_gsm8k.py
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# Select a dataset list
|
||||||
|
from .datasets.gsm8k.gsm8k_0shot_gen_a58960 import gsm8k_datasets as datasets
|
||||||
|
# Select an interested model
|
||||||
|
from ..models.hf_llama.hf_llama3_8b_instruct import models
|
||||||
|
```
|
||||||
|
|
||||||
|
Here, `hf_llama3_8b_instruct` specifies the original Huggingface model configuration, as shown below:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.models import HuggingFacewithChatTemplate
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFacewithChatTemplate,
|
||||||
|
abbr='llama-3-8b-instruct-hf',
|
||||||
|
path='meta-llama/Meta-Llama-3-8B-Instruct',
|
||||||
|
max_out_len=1024,
|
||||||
|
batch_size=8,
|
||||||
|
run_cfg=dict(num_gpus=1),
|
||||||
|
stop_words=['<|end_of_text|>', '<|eot_id|>'],
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
To evaluate the GSM8k dataset using the default Huggingface version of the llama3-8b-instruct model, use:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py config/eval_gsm8k.py
|
||||||
|
```
|
||||||
|
|
||||||
|
To accelerate the evaluation using vLLM or LMDeploy, you can use the following script:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py config/eval_gsm8k.py -a vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
or
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py config/eval_gsm8k.py -a lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
### Method 2: Accelerating Evaluation via Deployed Inference Acceleration Service API
|
||||||
|
|
||||||
|
OpenCompass also supports accelerating evaluation by deploying vLLM or LMDeploy inference acceleration service APIs. Follow these steps:
|
||||||
|
|
||||||
|
1. Install the openai package:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install openai
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Deploy the inference acceleration service API for vLLM or LMDeploy. Below is an example for LMDeploy:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
lmdeploy serve api_server meta-llama/Meta-Llama-3-8B-Instruct --model-name Meta-Llama-3-8B-Instruct --server-port 23333
|
||||||
|
```
|
||||||
|
|
||||||
|
Parameters for starting the api_server can be checked using `lmdeploy serve api_server -h`, such as --tp for tensor parallelism, --session-len for the maximum context window length, --cache-max-entry-count for adjusting the k/v cache memory usage ratio, etc.
|
||||||
|
|
||||||
|
3. Once the service is successfully deployed, modify the evaluation script by changing the model configuration path to the service address, as shown below:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.models import OpenAISDK
|
||||||
|
|
||||||
|
api_meta_template = dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', api_role='HUMAN'),
|
||||||
|
dict(role='BOT', api_role='BOT', generate=True),
|
||||||
|
],
|
||||||
|
reserved_roles=[dict(role='SYSTEM', api_role='SYSTEM')],
|
||||||
|
)
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
abbr='Meta-Llama-3-8B-Instruct-LMDeploy-API',
|
||||||
|
type=OpenAISDK,
|
||||||
|
key='EMPTY', # API key
|
||||||
|
openai_api_base='http://0.0.0.0:23333/v1', # Service address
|
||||||
|
path='Meta-Llama-3-8B-Instruct', # Model name for service request
|
||||||
|
tokenizer_path='meta-llama/Meta-Llama-3.1-8B-Instruct', # The tokenizer name or path, if set to `None`, uses the default `gpt-4` tokenizer
|
||||||
|
rpm_verbose=True, # Whether to print request rate
|
||||||
|
meta_template=api_meta_template, # Service request template
|
||||||
|
query_per_second=1, # Service request rate
|
||||||
|
max_out_len=1024, # Maximum output length
|
||||||
|
max_seq_len=4096, # Maximum input length
|
||||||
|
temperature=0.01, # Generation temperature
|
||||||
|
batch_size=8, # Batch size
|
||||||
|
retry=3, # Number of retries
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## Acceleration Effect and Performance Comparison
|
||||||
|
|
||||||
|
Below is a comparison table of the acceleration effect and performance when using VLLM or LMDeploy on a single A800 GPU for evaluating the Llama-3-8B-Instruct model on the GSM8k dataset:
|
||||||
|
|
||||||
|
| Inference Backend | Accuracy | Inference Time (minutes:seconds) | Speedup (relative to Huggingface) |
|
||||||
|
| ----------------- | -------- | -------------------------------- | --------------------------------- |
|
||||||
|
| Huggingface | 74.22 | 24:26 | 1.0 |
|
||||||
|
| LMDeploy | 73.69 | 11:15 | 2.2 |
|
||||||
|
| VLLM | 72.63 | 07:52 | 3.1 |
|
||||||
|
|
@ -0,0 +1,113 @@
|
||||||
|
# CircularEval
|
||||||
|
|
||||||
|
## Background
|
||||||
|
|
||||||
|
For multiple-choice questions, when a Language Model (LLM) provides the correct option, it does not necessarily imply a true understanding and reasoning of the question. It could be a guess. To differentiate these scenarios and reduce LLM bias towards options, CircularEval (CircularEval) can be utilized. A multiple-choice question is augmented by shuffling its options, and if the LLM correctly answers all variations of the augmented question, it is considered correct under CircularEval.
|
||||||
|
|
||||||
|
## Adding Your Own CircularEval Dataset
|
||||||
|
|
||||||
|
Generally, to evaluate a dataset using CircularEval, both its loading and evaluation methods need to be rewritten. Modifications are required in both the OpenCompass main library and configuration files. We will use C-Eval as an example for explanation.
|
||||||
|
|
||||||
|
OpenCompass main library:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets.ceval import CEvalDataset
|
||||||
|
from opencompass.datasets.circular import CircularDatasetMeta
|
||||||
|
|
||||||
|
class CircularCEvalDataset(CEvalDataset, metaclass=CircularDatasetMeta):
|
||||||
|
# The overloaded dataset class
|
||||||
|
dataset_class = CEvalDataset
|
||||||
|
|
||||||
|
# Splits of the DatasetDict that need CircularEval. For CEvalDataset, which loads [dev, val, test], we only need 'val' and 'test' for CircularEval, not 'dev'
|
||||||
|
default_circular_splits = ['val', 'test']
|
||||||
|
|
||||||
|
# List of keys to be shuffled
|
||||||
|
default_option_keys = ['A', 'B', 'C', 'D']
|
||||||
|
|
||||||
|
# If the content of 'answer_key' is one of ['A', 'B', 'C', 'D'], representing the correct answer. This field indicates how to update the correct answer after shuffling options. Choose either this or default_answer_key_switch_method
|
||||||
|
default_answer_key = 'answer'
|
||||||
|
|
||||||
|
# If 'answer_key' content is not one of ['A', 'B', 'C', 'D'], a function can be used to specify the correct answer after shuffling options. Choose either this or default_answer_key
|
||||||
|
# def default_answer_key_switch_method(item, circular_pattern):
|
||||||
|
# # 'item' is the original data item
|
||||||
|
# # 'circular_pattern' is a tuple indicating the order after shuffling options, e.g., ('D', 'A', 'B', 'C') means the original option A is now D, and so on
|
||||||
|
# item['answer'] = circular_pattern['ABCD'.index(item['answer'])]
|
||||||
|
# return item
|
||||||
|
```
|
||||||
|
|
||||||
|
`CircularCEvalDataset` accepts the `circular_pattern` parameter with two values:
|
||||||
|
|
||||||
|
- `circular`: Indicates a single cycle. It is the default value. ABCD is expanded to ABCD, BCDA, CDAB, DABC, a total of 4 variations.
|
||||||
|
- `all_possible`: Indicates all permutations. ABCD is expanded to ABCD, ABDC, ACBD, ACDB, ADBC, ADCB, BACD, ..., a total of 24 variations.
|
||||||
|
|
||||||
|
Additionally, we provide a `CircularEvaluator` to replace `AccEvaluator`. This Evaluator also accepts `circular_pattern`, and it should be consistent with the above. It produces the following metrics:
|
||||||
|
|
||||||
|
- `acc_{origin|circular|all_possible}`: Treating each question with shuffled options as separate, calculating accuracy.
|
||||||
|
- `perf_{origin|circular|all_possible}`: Following Circular logic, a question is considered correct only if all its variations with shuffled options are answered correctly, calculating accuracy.
|
||||||
|
- `more_{num}_{origin|circular|all_possible}`: According to Circular logic, a question is deemed correct if the number of its variations answered correctly is greater than or equal to num, calculating accuracy.
|
||||||
|
|
||||||
|
OpenCompass configuration file:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.datasets.circular import CircularCEvalDataset
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
|
||||||
|
|
||||||
|
for d in ceval_datasets:
|
||||||
|
# Overloading the load method
|
||||||
|
d['type'] = CircularCEvalDataset
|
||||||
|
# Renaming for differentiation from non-circular evaluation versions
|
||||||
|
d['abbr'] = d['abbr'] + '-circular-4'
|
||||||
|
# Overloading the evaluation method
|
||||||
|
d['eval_cfg']['evaluator'] = {'type': CircularEvaluator}
|
||||||
|
|
||||||
|
# The dataset after the above operations looks like this:
|
||||||
|
# dict(
|
||||||
|
# type=CircularCEvalDataset,
|
||||||
|
# path='./data/ceval/formal_ceval', # Unchanged
|
||||||
|
# name='computer_network', # Unchanged
|
||||||
|
# abbr='ceval-computer_network-circular-4',
|
||||||
|
# reader_cfg=dict(...), # Unchanged
|
||||||
|
# infer_cfg=dict(...), # Unchanged
|
||||||
|
# eval_cfg=dict(evaluator=dict(type=CircularEvaluator), ...),
|
||||||
|
# )
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, for better presentation of results in CircularEval, consider using the following summarizer:
|
||||||
|
|
||||||
|
```python
|
||||||
|
|
||||||
|
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.summarizers import CircularSummarizer
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from ...summarizers.groups.ceval.ceval_summary_groups
|
||||||
|
|
||||||
|
new_summary_groups = []
|
||||||
|
for item in ceval_summary_groups:
|
||||||
|
new_summary_groups.append(
|
||||||
|
{
|
||||||
|
'name': item['name'] + '-circular-4',
|
||||||
|
'subsets': [i + '-circular-4' for i in item['subsets']],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
summarizer = dict(
|
||||||
|
type=CircularSummarizer,
|
||||||
|
# Select specific metrics to view
|
||||||
|
metric_types=['acc_origin', 'perf_circular'],
|
||||||
|
dataset_abbrs = [
|
||||||
|
'ceval-circular-4',
|
||||||
|
'ceval-humanities-circular-4',
|
||||||
|
'ceval-stem-circular-4',
|
||||||
|
'ceval-social-science-circular-4',
|
||||||
|
'ceval-other-circular-4',
|
||||||
|
],
|
||||||
|
summary_groups=new_summary_groups,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
For more complex evaluation examples, refer to this sample code: https://github.com/open-compass/opencompass/tree/main/configs/eval_circular.py
|
||||||
|
|
@ -0,0 +1,104 @@
|
||||||
|
# Code Evaluation Tutorial
|
||||||
|
|
||||||
|
This tutorial primarily focuses on evaluating a model's coding proficiency, using `humaneval` and `mbpp` as examples.
|
||||||
|
|
||||||
|
## pass@1
|
||||||
|
|
||||||
|
If you only need to generate a single response to evaluate the pass@1 performance, you can directly use [configs/datasets/humaneval/humaneval_gen_8e312c.py](https://github.com/open-compass/opencompass/blob/main/configs/datasets/humaneval/humaneval_gen_8e312c.py) and [configs/datasets/mbpp/deprecated_mbpp_gen_1e1056.py](https://github.com/open-compass/opencompass/blob/main/configs/datasets/mbpp/deprecated_mbpp_gen_1e1056.py), referring to the general [quick start tutorial](../get_started/quick_start.md).
|
||||||
|
|
||||||
|
For multilingual evaluation, please refer to the [Multilingual Code Evaluation Tutorial](./code_eval_service.md).
|
||||||
|
|
||||||
|
## pass@k
|
||||||
|
|
||||||
|
If you need to generate multiple responses for a single example to evaluate the pass@k performance, consider the following two situations. Here we take 10 responses as an example:
|
||||||
|
|
||||||
|
### Typical Situation
|
||||||
|
|
||||||
|
For most models that support the `num_return_sequences` parameter in HF's generation, we can use it directly to obtain multiple responses. Refer to the following configuration file:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets import MBPPDatasetV2, MBPPPassKEvaluator
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.humaneval.humaneval_gen_8e312c import humaneval_datasets
|
||||||
|
from .datasets.mbpp.deprecated_mbpp_gen_1e1056 import mbpp_datasets
|
||||||
|
|
||||||
|
mbpp_datasets[0]['type'] = MBPPDatasetV2
|
||||||
|
mbpp_datasets[0]['eval_cfg']['evaluator']['type'] = MBPPPassKEvaluator
|
||||||
|
mbpp_datasets[0]['reader_cfg']['output_column'] = 'test_column'
|
||||||
|
|
||||||
|
datasets = []
|
||||||
|
datasets += humaneval_datasets
|
||||||
|
datasets += mbpp_datasets
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceCausalLM,
|
||||||
|
...,
|
||||||
|
generation_kwargs=dict(
|
||||||
|
num_return_sequences=10,
|
||||||
|
do_sample=True,
|
||||||
|
top_p=0.95,
|
||||||
|
temperature=0.8,
|
||||||
|
),
|
||||||
|
...,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
For `mbpp`, new changes are needed in the dataset and evaluation, so we simultaneously modify the `type`, `eval_cfg.evaluator.type`, `reader_cfg.output_column` fields to accommodate these requirements.
|
||||||
|
|
||||||
|
We also need model responses with randomness, thus setting the `generation_kwargs` parameter is necessary. Note that we need to set `num_return_sequences` to get the number of responses.
|
||||||
|
|
||||||
|
Note: `num_return_sequences` must be greater than or equal to k, as pass@k itself is a probability estimate.
|
||||||
|
|
||||||
|
You can specifically refer to the following configuration file [configs/eval_code_passk.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_code_passk.py)
|
||||||
|
|
||||||
|
### For Models That Do Not Support Multiple Responses
|
||||||
|
|
||||||
|
This applies to some HF models with poorly designed APIs or missing features. In this case, we need to repeatedly construct datasets to achieve multiple response effects. Refer to the following configuration:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets import MBPPDatasetV2, MBPPPassKEvaluator
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.humaneval.humaneval_gen_8e312c import humaneval_datasets
|
||||||
|
from .datasets.mbpp.deprecated_mbpp_gen_1e1056 import mbpp_datasets
|
||||||
|
|
||||||
|
humaneval_datasets[0]['abbr'] = 'openai_humaneval_pass10'
|
||||||
|
humaneval_datasets[0]['num_repeats'] = 10
|
||||||
|
mbpp_datasets[0]['abbr'] = 'mbpp_pass10'
|
||||||
|
mbpp_datasets[0]['num_repeats'] = 10
|
||||||
|
mbpp_datasets[0]['type'] = MBPPDatasetV2
|
||||||
|
mbpp_datasets[0]['eval_cfg']['evaluator']['type'] = MBPPPassKEvaluator
|
||||||
|
mbpp_datasets[0]['reader_cfg']['output_column'] = 'test_column'
|
||||||
|
|
||||||
|
datasets = []
|
||||||
|
datasets += humaneval_datasets
|
||||||
|
datasets += mbpp_datasets
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceCausalLM,
|
||||||
|
...,
|
||||||
|
generation_kwargs=dict(
|
||||||
|
do_sample=True,
|
||||||
|
top_p=0.95,
|
||||||
|
temperature=0.8,
|
||||||
|
),
|
||||||
|
...,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
Since the dataset's prompt has not been modified, we need to replace the corresponding fields to achieve the purpose of repeating the dataset.
|
||||||
|
You need to modify these fields:
|
||||||
|
|
||||||
|
- `num_repeats`: the number of times the dataset is repeated
|
||||||
|
- `abbr`: It's best to modify the dataset abbreviation along with the number of repetitions because the number of datasets will change, preventing potential issues arising from discrepancies with the values in `.cache/dataset_size.json`.
|
||||||
|
|
||||||
|
For `mbpp`, modify the `type`, `eval_cfg.evaluator.type`, `reader_cfg.output_column` fields as well.
|
||||||
|
|
||||||
|
We also need model responses with randomness, thus setting the `generation_kwargs` parameter is necessary.
|
||||||
|
|
||||||
|
You can specifically refer to the following configuration file [configs/eval_code_passk_repeat_dataset.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_code_passk_repeat_dataset.py)
|
||||||
|
|
@ -0,0 +1,224 @@
|
||||||
|
# Code Evaluation Docker Tutorial
|
||||||
|
|
||||||
|
To complete the LLM code capability evaluation, we need to build a separate evaluation environment to avoid executing erroneous code in the development environment, which would inevitably cause losses. The code evaluation service currently used by OpenCompass can refer to the [code-evaluator](https://github.com/open-compass/code-evaluator) project. The following will introduce evaluation tutorials around the code evaluation service.
|
||||||
|
|
||||||
|
1. humaneval-x
|
||||||
|
|
||||||
|
This is a multi-programming language dataset [humaneval-x](https://huggingface.co/datasets/THUDM/humaneval-x).
|
||||||
|
You can download the dataset from this [download link](https://github.com/THUDM/CodeGeeX2/tree/main/benchmark/humanevalx). Please download the language file (××.jsonl.gz) that needs to be evaluated and place it in the `./data/humanevalx` folder.
|
||||||
|
|
||||||
|
The currently supported languages are `python`, `cpp`, `go`, `java`, `js`.
|
||||||
|
|
||||||
|
2. DS1000
|
||||||
|
|
||||||
|
This is a Python multi-algorithm library dataset [ds1000](https://github.com/xlang-ai/DS-1000).
|
||||||
|
You can download the dataset from this [download link](https://github.com/xlang-ai/DS-1000/blob/main/ds1000_data.zip).
|
||||||
|
|
||||||
|
The currently supported algorithm libraries are `Pandas`, `Numpy`, `Tensorflow`, `Scipy`, `Sklearn`, `Pytorch`, `Matplotlib`.
|
||||||
|
|
||||||
|
## Launching the Code Evaluation Service
|
||||||
|
|
||||||
|
1. Ensure you have installed Docker, please refer to [Docker installation document](https://docs.docker.com/engine/install/).
|
||||||
|
2. Pull the source code of the code evaluation service project and build the Docker image.
|
||||||
|
|
||||||
|
Choose the dockerfile corresponding to the dataset you need, and replace `humanevalx` or `ds1000` in the command below.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git clone https://github.com/open-compass/code-evaluator.git
|
||||||
|
docker build -t code-eval-{your-dataset}:latest -f docker/{your-dataset}/Dockerfile .
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Create a container with the following commands:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
# Log output format
|
||||||
|
docker run -it -p 5000:5000 code-eval-{your-dataset}:latest python server.py
|
||||||
|
|
||||||
|
# Run the program in the background
|
||||||
|
# docker run -itd -p 5000:5000 code-eval-{your-dataset}:latest python server.py
|
||||||
|
|
||||||
|
# Using different ports
|
||||||
|
# docker run -itd -p 5001:5001 code-eval-{your-dataset}:latest python server.py --port 5001
|
||||||
|
```
|
||||||
|
|
||||||
|
**Note:**
|
||||||
|
|
||||||
|
- If you encounter a timeout during the evaluation of Go, please use the following command when creating the container.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
docker run -it -p 5000:5000 -e GO111MODULE=on -e GOPROXY=https://goproxy.io code-eval-{your-dataset}:latest python server.py
|
||||||
|
```
|
||||||
|
|
||||||
|
4. To ensure you have access to the service, use the following command to check the inference environment and evaluation service connection status. (If both inferences and code evaluations run on the same host, skip this step.)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
ping your_service_ip_address
|
||||||
|
telnet your_service_ip_address your_service_port
|
||||||
|
```
|
||||||
|
|
||||||
|
## Local Code Evaluation
|
||||||
|
|
||||||
|
When the model inference and code evaluation services are running on the same host or within the same local area network, direct code reasoning and evaluation can be performed. **Note: DS1000 is currently not supported, please proceed with remote evaluation.**
|
||||||
|
|
||||||
|
### Configuration File
|
||||||
|
|
||||||
|
We provide [the configuration file](https://github.com/open-compass/opencompass/blob/main/configs/eval_codegeex2.py) of using `humanevalx` for evaluation on `codegeex2` as reference.
|
||||||
|
|
||||||
|
The dataset and related post-processing configurations files can be found at this [link](https://github.com/open-compass/opencompass/tree/main/configs/datasets/humanevalx) with attention paid to the `evaluator` field in the humanevalx_eval_cfg_dict.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||||
|
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||||
|
from opencompass.datasets import HumanevalXDataset, HumanevalXEvaluator
|
||||||
|
|
||||||
|
humanevalx_reader_cfg = dict(
|
||||||
|
input_columns=['prompt'], output_column='task_id', train_split='test')
|
||||||
|
|
||||||
|
humanevalx_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='{prompt}'),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer, max_out_len=1024))
|
||||||
|
|
||||||
|
humanevalx_eval_cfg_dict = {
|
||||||
|
lang : dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=HumanevalXEvaluator,
|
||||||
|
language=lang,
|
||||||
|
ip_address="localhost", # replace to your code_eval_server ip_address, port
|
||||||
|
port=5000), # refer to https://github.com/open-compass/code-evaluator to launch a server
|
||||||
|
pred_role='BOT')
|
||||||
|
for lang in ['python', 'cpp', 'go', 'java', 'js'] # do not support rust now
|
||||||
|
}
|
||||||
|
|
||||||
|
humanevalx_datasets = [
|
||||||
|
dict(
|
||||||
|
type=HumanevalXDataset,
|
||||||
|
abbr=f'humanevalx-{lang}',
|
||||||
|
language=lang,
|
||||||
|
path='./data/humanevalx',
|
||||||
|
reader_cfg=humanevalx_reader_cfg,
|
||||||
|
infer_cfg=humanevalx_infer_cfg,
|
||||||
|
eval_cfg=humanevalx_eval_cfg_dict[lang])
|
||||||
|
for lang in ['python', 'cpp', 'go', 'java', 'js']
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
### Task Launch
|
||||||
|
|
||||||
|
Refer to the [Quick Start](../get_started.html)
|
||||||
|
|
||||||
|
## Remote Code Evaluation
|
||||||
|
|
||||||
|
Model inference and code evaluation services located in different machines which cannot be accessed directly require prior model inference before collecting the code evaluation results. The configuration file and inference process can be reused from the previous tutorial.
|
||||||
|
|
||||||
|
### Collect Inference Results(Only for Humanevalx)
|
||||||
|
|
||||||
|
In OpenCompass's tools folder, there is a script called `collect_code_preds.py` provided to process and collect the inference results after providing the task launch configuration file during startup along with specifying the working directory used corresponding to the task.
|
||||||
|
It is the same with `-r` option in `run.py`. More details can be referred through the [documentation](https://opencompass.readthedocs.io/en/latest/get_started/quick_start.html#launching-evaluation).
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python tools/collect_code_preds.py [config] [-r latest]
|
||||||
|
```
|
||||||
|
|
||||||
|
The collected results will be organized as following under the `-r` folder:
|
||||||
|
|
||||||
|
```
|
||||||
|
workdir/humanevalx
|
||||||
|
├── codegeex2-6b
|
||||||
|
│ ├── humanevalx_cpp.json
|
||||||
|
│ ├── humanevalx_go.json
|
||||||
|
│ ├── humanevalx_java.json
|
||||||
|
│ ├── humanevalx_js.json
|
||||||
|
│ └── humanevalx_python.json
|
||||||
|
├── CodeLlama-13b
|
||||||
|
│ ├── ...
|
||||||
|
├── CodeLlama-13b-Instruct
|
||||||
|
│ ├── ...
|
||||||
|
├── CodeLlama-13b-Python
|
||||||
|
│ ├── ...
|
||||||
|
├── ...
|
||||||
|
```
|
||||||
|
|
||||||
|
For DS1000, you just need to obtain the corresponding prediction file generated by `opencompass`.
|
||||||
|
|
||||||
|
### Code Evaluation
|
||||||
|
|
||||||
|
Make sure your code evaluation service is started, and use `curl` to request:
|
||||||
|
|
||||||
|
#### The following only supports Humanevalx
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@{result_absolute_path}' -F 'dataset={dataset/language}' {your_service_ip_address}:{your_service_port}/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
For example:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./examples/humanevalx/python.json' -F 'dataset=humanevalx/python' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
The we have:
|
||||||
|
|
||||||
|
```
|
||||||
|
"{\"pass@1\": 37.19512195121951%}"
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, we offer an extra option named `with_prompt`(Defaults to `True`), since some models(like `WizardCoder`) generate complete codes without requiring the form of concatenating prompt and prediction. You may refer to the following commands for evaluation.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./examples/humanevalx/python.json' -F 'dataset=humanevalx/python' -H 'with-prompt: False' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
#### The following only supports DS1000
|
||||||
|
|
||||||
|
Make sure the code evaluation service is started, then use `curl` to submit a request:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./internlm-chat-7b-hf-v11/ds1000_Numpy.json' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
DS1000 supports additional debug parameters. Be aware that a large amount of log will be generated when it is turned on:
|
||||||
|
|
||||||
|
- `full`: Additional print out of the original prediction for each error sample, post-processing prediction, running program, and final error.
|
||||||
|
- `half`: Additional print out of the running program and final error for each error sample.
|
||||||
|
- `error`: Additional print out of the final error for each error sample.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./internlm-chat-7b-hf-v11/ds1000_Numpy.json' -F 'debug=error' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also modify the `num_workers` in the same way to control the degree of parallelism.
|
||||||
|
|
||||||
|
## Advanced Tutorial
|
||||||
|
|
||||||
|
Besides evaluating the supported HUMANEVAList data set, users might also need:
|
||||||
|
|
||||||
|
### Support New Dataset
|
||||||
|
|
||||||
|
Please refer to the [tutorial on supporting new datasets](./new_dataset.md).
|
||||||
|
|
||||||
|
### Modify Post-Processing
|
||||||
|
|
||||||
|
1. For local evaluation, follow the post-processing section in the tutorial on supporting new datasets to modify the post-processing method.
|
||||||
|
2. For remote evaluation, please modify the post-processing part in the tool's `collect_code_preds.py`.
|
||||||
|
3. Some parts of post-processing could also be modified in the code evaluation service, more information will be available in the next section.
|
||||||
|
|
||||||
|
### Debugging Code Evaluation Service
|
||||||
|
|
||||||
|
When supporting new datasets or modifying post-processors, it is possible that modifications need to be made to the original code evaluation service. Please make changes based on the following steps:
|
||||||
|
|
||||||
|
1. Remove the installation of the `code-evaluator` in `Dockerfile`, mount the `code-evaluator` when starting the container instead:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
docker run -it -p 5000:5000 -v /local/path/of/code-evaluator:/workspace/code-evaluator code-eval:latest bash
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install and start the code evaluation service locally. At this point, any necessary modifications can be made to the local copy of the `code-evaluator`.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
cd code-evaluator && pip install -r requirements.txt
|
||||||
|
python server.py
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,124 @@
|
||||||
|
# Data Contamination Assessment
|
||||||
|
|
||||||
|
**Data Contamination** refers to the phenomenon where data intended for downstream testing tasks appear in the training data of large language models (LLMs), resulting in artificially inflated performance metrics in downstream tasks (such as summarization, natural language inference, text classification), which do not accurately reflect the model's true generalization capabilities.
|
||||||
|
|
||||||
|
Since the source of data contamination lies in the training data used by LLMs, the most direct method to detect data contamination is to collide test data with training data and then report the extent of overlap between the two. The classic GPT-3 [paper](https://arxiv.org/pdf/2005.14165.pdf) reported on this in Table C.1.
|
||||||
|
|
||||||
|
However, today's open-source community often only publishes model parameters, not training datasets. In such cases, how to determine the presence and extent of data contamination remains unsolved. OpenCompass offers two possible solutions.
|
||||||
|
|
||||||
|
## Contamination Data Annotation Based on Self-Built Co-Distribution Data
|
||||||
|
|
||||||
|
Referencing the method mentioned in Section 5.2 of [Skywork](https://arxiv.org/pdf/2310.19341.pdf), we directly used the dataset [mock_gsm8k_test](https://huggingface.co/datasets/Skywork/mock_gsm8k_test) uploaded to HuggingFace by Skywork.
|
||||||
|
|
||||||
|
In this method, the authors used GPT-4 to synthesize data similar to the original GSM8K style, and then calculated the perplexity on the GSM8K training set (train), GSM8K test set (test), and GSM8K reference set (ref). Since the GSM8K reference set was newly generated, the authors considered it as clean, not belonging to any training set of any model. They posited:
|
||||||
|
|
||||||
|
- If the test set's perplexity is significantly lower than the reference set's, the test set might have appeared in the model's training phase;
|
||||||
|
- If the training set's perplexity is significantly lower than the test set's, the training set might have been overfitted by the model.
|
||||||
|
|
||||||
|
The following configuration file can be referenced:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.gsm8k_contamination.gsm8k_contamination_ppl_ecdd22 import gsm8k_datasets # includes training, test, and reference sets
|
||||||
|
from .models.qwen.hf_qwen_7b import models as hf_qwen_7b_model # model under review
|
||||||
|
from .models.yi.hf_yi_6b import models as hf_yi_6b_model
|
||||||
|
|
||||||
|
datasets = [*gsm8k_datasets]
|
||||||
|
models = [*hf_qwen_7b_model, *hf_yi_6b_model]
|
||||||
|
```
|
||||||
|
|
||||||
|
An example output is as follows:
|
||||||
|
|
||||||
|
```text
|
||||||
|
dataset version metric mode internlm-7b-hf qwen-7b-hf yi-6b-hf chatglm3-6b-base-hf qwen-14b-hf baichuan2-13b-base-hf internlm-20b-hf aquila2-34b-hf ...
|
||||||
|
--------------- --------- ----------- ------- ---------------- ------------ ---------- --------------------- ------------- ----------------------- ----------------- ---------------- ...
|
||||||
|
gsm8k-train-ppl 0b8e46 average_ppl unknown 1.5 0.78 1.37 1.16 0.5 0.76 1.41 0.78 ...
|
||||||
|
gsm8k-test-ppl 0b8e46 average_ppl unknown 1.56 1.33 1.42 1.3 1.15 1.13 1.52 1.16 ...
|
||||||
|
gsm8k-ref-ppl f729ba average_ppl unknown 1.55 1.2 1.43 1.35 1.27 1.19 1.47 1.35 ...
|
||||||
|
```
|
||||||
|
|
||||||
|
Currently, this solution only supports the GSM8K dataset. We welcome the community to contribute more datasets.
|
||||||
|
|
||||||
|
Consider cite the following paper if you find it helpful:
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
}
|
||||||
|
@misc{wei2023skywork,
|
||||||
|
title={Skywork: A More Open Bilingual Foundation Model},
|
||||||
|
author={Tianwen Wei and Liang Zhao and Lichang Zhang and Bo Zhu and Lijie Wang and Haihua Yang and Biye Li and Cheng Cheng and Weiwei Lü and Rui Hu and Chenxia Li and Liu Yang and Xilin Luo and Xuejie Wu and Lunan Liu and Wenjun Cheng and Peng Cheng and Jianhao Zhang and Xiaoyu Zhang and Lei Lin and Xiaokun Wang and Yutuan Ma and Chuanhai Dong and Yanqi Sun and Yifu Chen and Yongyi Peng and Xiaojuan Liang and Shuicheng Yan and Han Fang and Yahui Zhou},
|
||||||
|
year={2023},
|
||||||
|
eprint={2310.19341},
|
||||||
|
archivePrefix={arXiv},
|
||||||
|
primaryClass={cs.CL}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Contamination Data Annotation Based on Classic Pre-trained Sets
|
||||||
|
|
||||||
|
Thanks to [Contamination_Detector](https://github.com/liyucheng09/Contamination_Detector) and @liyucheng09 for providing this method.
|
||||||
|
|
||||||
|
In this method, the authors search the test datasets (such as C-Eval, ARC, HellaSwag, etc.) using the Common Crawl database and Bing search engine, then mark each test sample as clean / question contaminated / both question and answer contaminated.
|
||||||
|
|
||||||
|
During testing, OpenCompass
|
||||||
|
|
||||||
|
will report the accuracy or perplexity of ceval on subsets composed of these three labels. Generally, the accuracy ranges from low to high: clean, question contaminated, both question and answer contaminated subsets. The authors believe:
|
||||||
|
|
||||||
|
- If the performance of the three is relatively close, the contamination level of the model on that test set is light; otherwise, it is heavy.
|
||||||
|
|
||||||
|
The following configuration file can be referenced [link](https://github.com/open-compass/opencompass/blob/main/configs/eval_contamination.py):
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.ceval.ceval_clean_ppl import ceval_datasets # ceval dataset with contamination tags
|
||||||
|
from .models.yi.hf_yi_6b import models as hf_yi_6b_model # model under review
|
||||||
|
from .models.qwen.hf_qwen_7b import models as hf_qwen_7b_model
|
||||||
|
from .summarizers.contamination import ceval_summarizer as summarizer # output formatting
|
||||||
|
|
||||||
|
datasets = [*ceval_datasets]
|
||||||
|
models = [*hf_yi_6b_model, *hf_qwen_7b_model]
|
||||||
|
```
|
||||||
|
|
||||||
|
An example output is as follows:
|
||||||
|
|
||||||
|
```text
|
||||||
|
dataset version mode yi-6b-hf - - qwen-7b-hf - - ...
|
||||||
|
---------------------------------------------- --------- ------ ---------------- ----------------------------- --------------------------------------- ---------------- ----------------------------- --------------------------------------- ...
|
||||||
|
- - - accuracy - clean accuracy - input contaminated accuracy - input-and-label contaminated accuracy - clean accuracy - input contaminated accuracy - input-and-label contaminated ...
|
||||||
|
...
|
||||||
|
ceval-humanities - ppl 74.42 75.00 82.14 67.44 50.00 70.54 ...
|
||||||
|
ceval-stem - ppl 53.70 57.14 85.61 47.41 52.38 67.63 ...
|
||||||
|
ceval-social-science - ppl 81.60 84.62 83.09 76.00 61.54 72.79 ...
|
||||||
|
ceval-other - ppl 72.31 73.91 75.00 58.46 39.13 61.88 ...
|
||||||
|
ceval-hard - ppl 44.35 37.50 70.00 41.13 25.00 30.00 ...
|
||||||
|
ceval - ppl 67.32 71.01 81.17 58.97 49.28 67.82 ...
|
||||||
|
```
|
||||||
|
|
||||||
|
Currently, this solution only supports the C-Eval, MMLU, HellaSwag and ARC. [Contamination_Detector](https://github.com/liyucheng09/Contamination_Detector) also includes CSQA and WinoGrande, but these have not yet been implemented in OpenCompass. We welcome the community to contribute more datasets.
|
||||||
|
|
||||||
|
Consider cite the following paper if you find it helpful:
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
}
|
||||||
|
@article{Li2023AnOS,
|
||||||
|
title={An Open Source Data Contamination Report for Llama Series Models},
|
||||||
|
author={Yucheng Li},
|
||||||
|
journal={ArXiv},
|
||||||
|
year={2023},
|
||||||
|
volume={abs/2310.17589},
|
||||||
|
url={https://api.semanticscholar.org/CorpusID:264490711}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,149 @@
|
||||||
|
# Custom Dataset Tutorial
|
||||||
|
|
||||||
|
This tutorial is intended for temporary and informal use of datasets. If the dataset requires long-term use or has specific needs for custom reading/inference/evaluation, it is strongly recommended to implement it according to the methods described in [new_dataset.md](./new_dataset.md).
|
||||||
|
|
||||||
|
In this tutorial, we will introduce how to test a new dataset without implementing a config or modifying the OpenCompass source code. We support two types of tasks: multiple choice (`mcq`) and question & answer (`qa`). For `mcq`, both ppl and gen inferences are supported; for `qa`, gen inference is supported.
|
||||||
|
|
||||||
|
## Dataset Format
|
||||||
|
|
||||||
|
We support datasets in both `.jsonl` and `.csv` formats.
|
||||||
|
|
||||||
|
### Multiple Choice (`mcq`)
|
||||||
|
|
||||||
|
For `mcq` datasets, the default fields are as follows:
|
||||||
|
|
||||||
|
- `question`: The stem of the multiple-choice question.
|
||||||
|
- `A`, `B`, `C`, ...: Single uppercase letters representing the options, with no limit on the number. Defaults to parsing consecutive letters strating from `A` as options.
|
||||||
|
- `answer`: The correct answer to the multiple-choice question, which must be one of the options used above, such as `A`, `B`, `C`, etc.
|
||||||
|
|
||||||
|
Non-default fields will be read in but are not used by default. To use them, specify in the `.meta.json` file.
|
||||||
|
|
||||||
|
An example of the `.jsonl` format:
|
||||||
|
|
||||||
|
```jsonl
|
||||||
|
{"question": "165+833+650+615=", "A": "2258", "B": "2263", "C": "2281", "answer": "B"}
|
||||||
|
{"question": "368+959+918+653+978=", "A": "3876", "B": "3878", "C": "3880", "answer": "A"}
|
||||||
|
{"question": "776+208+589+882+571+996+515+726=", "A": "5213", "B": "5263", "C": "5383", "answer": "B"}
|
||||||
|
{"question": "803+862+815+100+409+758+262+169=", "A": "4098", "B": "4128", "C": "4178", "answer": "C"}
|
||||||
|
```
|
||||||
|
|
||||||
|
An example of the `.csv` format:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
question,A,B,C,answer
|
||||||
|
127+545+588+620+556+199=,2632,2635,2645,B
|
||||||
|
735+603+102+335+605=,2376,2380,2410,B
|
||||||
|
506+346+920+451+910+142+659+850=,4766,4774,4784,C
|
||||||
|
504+811+870+445=,2615,2630,2750,B
|
||||||
|
```
|
||||||
|
|
||||||
|
### Question & Answer (`qa`)
|
||||||
|
|
||||||
|
For `qa` datasets, the default fields are as follows:
|
||||||
|
|
||||||
|
- `question`: The stem of the question & answer question.
|
||||||
|
- `answer`: The correct answer to the question & answer question. It can be missing, indicating the dataset has no correct answer.
|
||||||
|
|
||||||
|
Non-default fields will be read in but are not used by default. To use them, specify in the `.meta.json` file.
|
||||||
|
|
||||||
|
An example of the `.jsonl` format:
|
||||||
|
|
||||||
|
```jsonl
|
||||||
|
{"question": "752+361+181+933+235+986=", "answer": "3448"}
|
||||||
|
{"question": "712+165+223+711=", "answer": "1811"}
|
||||||
|
{"question": "921+975+888+539=", "answer": "3323"}
|
||||||
|
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}
|
||||||
|
```
|
||||||
|
|
||||||
|
An example of the `.csv` format:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
question,answer
|
||||||
|
123+147+874+850+915+163+291+604=,3967
|
||||||
|
149+646+241+898+822+386=,3142
|
||||||
|
332+424+582+962+735+798+653+214=,4700
|
||||||
|
649+215+412+495+220+738+989+452=,4170
|
||||||
|
```
|
||||||
|
|
||||||
|
## Command Line List
|
||||||
|
|
||||||
|
Custom datasets can be directly called for evaluation through the command line.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--models hf_llama2_7b \
|
||||||
|
--custom-dataset-path xxx/test_mcq.csv \
|
||||||
|
--custom-dataset-data-type mcq \
|
||||||
|
--custom-dataset-infer-method ppl
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--models hf_llama2_7b \
|
||||||
|
--custom-dataset-path xxx/test_qa.jsonl \
|
||||||
|
--custom-dataset-data-type qa \
|
||||||
|
--custom-dataset-infer-method gen
|
||||||
|
```
|
||||||
|
|
||||||
|
In most cases, `--custom-dataset-data-type` and `--custom-dataset-infer-method` can be omitted. OpenCompass will
|
||||||
|
|
||||||
|
set them based on the following logic:
|
||||||
|
|
||||||
|
- If options like `A`, `B`, `C`, etc., can be parsed from the dataset file, it is considered an `mcq` dataset; otherwise, it is considered a `qa` dataset.
|
||||||
|
- The default `infer_method` is `gen`.
|
||||||
|
|
||||||
|
## Configuration File
|
||||||
|
|
||||||
|
In the original configuration file, simply add a new item to the `datasets` variable. Custom datasets can be mixed with regular datasets.
|
||||||
|
|
||||||
|
```python
|
||||||
|
datasets = [
|
||||||
|
{"path": "xxx/test_mcq.csv", "data_type": "mcq", "infer_method": "ppl"},
|
||||||
|
{"path": "xxx/test_qa.jsonl", "data_type": "qa", "infer_method": "gen"},
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## Supplemental Information for Dataset `.meta.json`
|
||||||
|
|
||||||
|
OpenCompass will try to parse the input dataset file by default, so in most cases, the `.meta.json` file is **not necessary**. However, if the dataset field names are not the default ones, or custom prompt words are required, it should be specified in the `.meta.json` file.
|
||||||
|
|
||||||
|
The file is placed in the same directory as the dataset, with the filename followed by `.meta.json`. An example file structure is as follows:
|
||||||
|
|
||||||
|
```tree
|
||||||
|
.
|
||||||
|
├── test_mcq.csv
|
||||||
|
├── test_mcq.csv.meta.json
|
||||||
|
├── test_qa.jsonl
|
||||||
|
└── test_qa.jsonl.meta.json
|
||||||
|
```
|
||||||
|
|
||||||
|
Possible fields in this file include:
|
||||||
|
|
||||||
|
- `abbr` (str): Abbreviation of the dataset, serving as its ID.
|
||||||
|
- `data_type` (str): Type of dataset, options are `mcq` and `qa`.
|
||||||
|
- `infer_method` (str): Inference method, options are `ppl` and `gen`.
|
||||||
|
- `human_prompt` (str): User prompt template for generating prompts. Variables in the template are enclosed in `{}`, like `{question}`, `{opt1}`, etc. If `template` exists, this field will be ignored.
|
||||||
|
- `bot_prompt` (str): Bot prompt template for generating prompts. Variables in the template are enclosed in `{}`, like `{answer}`, etc. If `template` exists, this field will be ignored.
|
||||||
|
- `template` (str or dict): Question template for generating prompts. Variables in the template are enclosed in `{}`, like `{question}`, `{opt1}`, etc. The relevant syntax is in [here](../prompt/prompt_template.md) regarding `infer_cfg['prompt_template']['template']`.
|
||||||
|
- `input_columns` (list): List of input fields for reading data.
|
||||||
|
- `output_column` (str): Output field for reading data.
|
||||||
|
- `options` (list): List of options for reading data, valid only when `data_type` is `mcq`.
|
||||||
|
|
||||||
|
For example:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"human_prompt": "Question: 127 + 545 + 588 + 620 + 556 + 199 =\nA. 2632\nB. 2635\nC. 2645\nAnswer: Let's think step by step, 127 + 545 + 588 + 620 + 556 + 199 = 672 + 588 + 620 + 556 + 199 = 1260 + 620 + 556 + 199 = 1880 + 556 + 199 = 2436 + 199 = 2635. So the answer is B.\nQuestion: {question}\nA. {A}\nB. {B}\nC. {C}\nAnswer: ",
|
||||||
|
"bot_prompt": "{answer}"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
or
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"template": "Question: {my_question}\nX. {X}\nY. {Y}\nZ. {Z}\nW. {W}\nAnswer:",
|
||||||
|
"input_columns": ["my_question", "X", "Y", "Z", "W"],
|
||||||
|
"output_column": "my_answer",
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,71 @@
|
||||||
|
# Evaluation with Lightllm
|
||||||
|
|
||||||
|
We now support the evaluation of large language models using [Lightllm](https://github.com/ModelTC/lightllm) for inference. Developed by SenseTime, LightLLM is a Python-based LLM (Large Language Model) inference and serving framework, notable for its lightweight design, easy scalability, and high-speed performance. Lightllm provides support for various large Language models, allowing users to perform model inference through Lightllm, locally deploying it as a service. During the evaluation process, OpenCompass feeds data to Lightllm through an API and processes the response. OpenCompass has been adapted for compatibility with Lightllm, and this tutorial will guide you on using OpenCompass to evaluate models with Lightllm as the inference backend.
|
||||||
|
|
||||||
|
## Setup
|
||||||
|
|
||||||
|
### Install OpenCompass
|
||||||
|
|
||||||
|
Please follow the [instructions](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) to install the OpenCompass and prepare the evaluation datasets.
|
||||||
|
|
||||||
|
### Install Lightllm
|
||||||
|
|
||||||
|
Please follow the [Lightllm homepage](https://github.com/ModelTC/lightllm) to install the Lightllm. Pay attention to aligning the versions of relevant dependencies, especially the version of the Transformers.
|
||||||
|
|
||||||
|
## Evaluation
|
||||||
|
|
||||||
|
We use the evaluation of Humaneval with the llama2-7B model as an example.
|
||||||
|
|
||||||
|
### Step-1: Deploy the model locally as a service using Lightllm.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m lightllm.server.api_server --model_dir /path/llama2-7B \
|
||||||
|
--host 0.0.0.0 \
|
||||||
|
--port 1030 \
|
||||||
|
--nccl_port 2066 \
|
||||||
|
--max_req_input_len 4096 \
|
||||||
|
--max_req_total_len 6144 \
|
||||||
|
--tp 1 \
|
||||||
|
--trust_remote_code \
|
||||||
|
--max_total_token_num 120000
|
||||||
|
```
|
||||||
|
|
||||||
|
\*\*Note: \*\* tp can be configured to enable TensorParallel inference on several gpus, suitable for the inference of very large models.
|
||||||
|
|
||||||
|
\*\*Note: \*\* The max_total_token_num in the above command will affect the throughput performance during testing. It can be configured according to the documentation on the [Lightllm homepage](https://github.com/ModelTC/lightllm). As long as it does not run out of memory, it is often better to set it as high as possible.
|
||||||
|
|
||||||
|
\*\*Note: \*\* If you want to start multiple LightLLM services on the same machine, you need to reconfigure the above port and nccl_port.
|
||||||
|
|
||||||
|
You can use the following Python script to quickly test whether the current service has been successfully started.
|
||||||
|
|
||||||
|
```python
|
||||||
|
import time
|
||||||
|
import requests
|
||||||
|
import json
|
||||||
|
|
||||||
|
url = 'http://localhost:8080/generate'
|
||||||
|
headers = {'Content-Type': 'application/json'}
|
||||||
|
data = {
|
||||||
|
'inputs': 'What is AI?',
|
||||||
|
"parameters": {
|
||||||
|
'do_sample': False,
|
||||||
|
'ignore_eos': False,
|
||||||
|
'max_new_tokens': 1024,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
response = requests.post(url, headers=headers, data=json.dumps(data))
|
||||||
|
if response.status_code == 200:
|
||||||
|
print(response.json())
|
||||||
|
else:
|
||||||
|
print('Error:', response.status_code, response.text)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Step-2: Evaluate the above model using OpenCompass.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py configs/eval_lightllm.py
|
||||||
|
```
|
||||||
|
|
||||||
|
You are expected to get the evaluation results after the inference and evaluation.
|
||||||
|
|
||||||
|
\*\*Note: \*\*In `eval_lightllm.py`, please align the configured URL with the service address from the previous step.
|
||||||
|
|
@ -0,0 +1,88 @@
|
||||||
|
# Evaluation with LMDeploy
|
||||||
|
|
||||||
|
We now support evaluation of models accelerated by the [LMDeploy](https://github.com/InternLM/lmdeploy). LMDeploy is a toolkit designed for compressing, deploying, and serving LLM. It has a remarkable inference performance. We now illustrate how to evaluate a model with the support of LMDeploy in OpenCompass.
|
||||||
|
|
||||||
|
## Setup
|
||||||
|
|
||||||
|
### Install OpenCompass
|
||||||
|
|
||||||
|
Please follow the [instructions](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) to install the OpenCompass and prepare the evaluation datasets.
|
||||||
|
|
||||||
|
### Install LMDeploy
|
||||||
|
|
||||||
|
Install lmdeploy via pip (python 3.8+)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
The default prebuilt package is compiled on CUDA 12. However, if CUDA 11+ is required, you can install lmdeploy by:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export LMDEPLOY_VERSION=0.6.0
|
||||||
|
export PYTHON_VERSION=310
|
||||||
|
pip install https://github.com/InternLM/lmdeploy/releases/download/v${LMDEPLOY_VERSION}/lmdeploy-${LMDEPLOY_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux2014_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118
|
||||||
|
```
|
||||||
|
|
||||||
|
## Evaluation
|
||||||
|
|
||||||
|
When evaluating a model, it is necessary to prepare an evaluation configuration that specifies information such as the evaluation dataset, the model, and inference parameters.
|
||||||
|
|
||||||
|
Taking [internlm2-chat-7b](https://huggingface.co/internlm/internlm2-chat-7b) as an example, the evaluation config is as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# configure the dataset
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# choose a list of datasets
|
||||||
|
from .datasets.mmlu.mmlu_gen_a484b3 import mmlu_datasets
|
||||||
|
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
|
||||||
|
from .datasets.triviaqa.triviaqa_gen_2121ce import triviaqa_datasets
|
||||||
|
from opencompass.configs.datasets.gsm8k.gsm8k_0shot_v2_gen_a58960 import \
|
||||||
|
gsm8k_datasets
|
||||||
|
# and output the results in a chosen format
|
||||||
|
from .summarizers.medium import summarizer
|
||||||
|
|
||||||
|
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
|
||||||
|
|
||||||
|
# configure lmdeploy
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# configure the model
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr=f'internlm2-chat-7b-lmdeploy',
|
||||||
|
# model path, which can be the address of a model repository on the Hugging Face Hub or a local path
|
||||||
|
path='internlm/internlm2-chat-7b',
|
||||||
|
# inference backend of LMDeploy. It can be either 'turbomind' or 'pytorch'.
|
||||||
|
# If the model is not supported by 'turbomind', it will fallback to
|
||||||
|
# 'pytorch'
|
||||||
|
backend='turbomind',
|
||||||
|
# For the detailed engine config and generation config, please refer to
|
||||||
|
# https://github.com/InternLM/lmdeploy/blob/main/lmdeploy/messages.py
|
||||||
|
engine_config=dict(tp=1),
|
||||||
|
gen_config=dict(do_sample=False),
|
||||||
|
# the max size of the context window
|
||||||
|
max_seq_len=7168,
|
||||||
|
# the max number of new tokens
|
||||||
|
max_out_len=1024,
|
||||||
|
# the max number of prompts that LMDeploy receives
|
||||||
|
# in `generate` function
|
||||||
|
batch_size=5000,
|
||||||
|
run_cfg=dict(num_gpus=1),
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
Place the aforementioned configuration in a file, such as "configs/eval_internlm2_lmdeploy.py". Then, in the home folder of OpenCompass, start evaluation by the following command:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py configs/eval_internlm2_lmdeploy.py -w outputs
|
||||||
|
```
|
||||||
|
|
||||||
|
You are expected to get the evaluation results after the inference and evaluation.
|
||||||
|
|
@ -0,0 +1,269 @@
|
||||||
|
# LLM as Judge Evaluation
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
The GenericLLMEvaluator is particularly useful for scenarios where rule-based methods (like regular expressions) cannot perfectly judge outputs, such as:
|
||||||
|
|
||||||
|
- Cases where models output answer content without option identifiers
|
||||||
|
- Factual judgment datasets that are difficult to evaluate with rules
|
||||||
|
- Open-ended responses requiring complex understanding and reasoning
|
||||||
|
- Evaluation that requires a lot of rules to be designed
|
||||||
|
|
||||||
|
OpenCompass provides the GenericLLMEvaluator component to facilitate LLM-as-judge evaluations.
|
||||||
|
|
||||||
|
## Dataset Format
|
||||||
|
|
||||||
|
The dataset for LLM judge evaluation should be in either JSON Lines (.jsonl) or CSV format. Each entry should contain at least:
|
||||||
|
|
||||||
|
- A problem or question
|
||||||
|
- A reference answer or gold standard
|
||||||
|
- (The model's prediction will be generated during evaluation)
|
||||||
|
|
||||||
|
Example JSONL format:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"problem": "What is the capital of France?", "answer": "Paris"}
|
||||||
|
```
|
||||||
|
|
||||||
|
Example CSV format:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
problem,answer
|
||||||
|
"What is the capital of France?","Paris"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Configuration
|
||||||
|
|
||||||
|
### Using LLM for Evaluation via Command Line
|
||||||
|
|
||||||
|
Some datasets in OpenCompass already include LLM judge configurations.
|
||||||
|
You need to use a model service (such as OpenAI or DeepSeek's official API) or start a model service locally using tools like LMDeploy, vLLM, or SGLang.
|
||||||
|
|
||||||
|
Then, you can set the environment variables for the evaluation service and evaluate models using the following commands:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OC_JUDGE_MODEL=Qwen/Qwen2.5-32B-Instruct
|
||||||
|
export OC_JUDGE_API_KEY=sk-1234
|
||||||
|
export OC_JUDGE_API_BASE=http://172.30.56.1:4000/v1
|
||||||
|
```
|
||||||
|
|
||||||
|
Note that by default, OpenCompass will use these three environment variables, but if you use configuration files to configure the evaluation service, these environment variables will not take effect.
|
||||||
|
|
||||||
|
### ### Using LLM for Evaluation via Configuration Files
|
||||||
|
|
||||||
|
To set up an LLM judge evaluation, you'll need to configure three main components:
|
||||||
|
|
||||||
|
1. Dataset Reader Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
reader_cfg = dict(
|
||||||
|
input_columns=['problem'], # Column name for the question
|
||||||
|
output_column='answer' # Column name for the reference answer
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Inference Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}', # Template for prompting the model
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Evaluation Configuration with LLM Judge
|
||||||
|
|
||||||
|
```python
|
||||||
|
eval_cfg = dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=GenericLLMEvaluator, # Using LLM as evaluator
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
begin=[
|
||||||
|
dict(
|
||||||
|
role='SYSTEM',
|
||||||
|
fallback_role='HUMAN',
|
||||||
|
prompt="You are a helpful assistant who evaluates the correctness and quality of models' outputs.",
|
||||||
|
)
|
||||||
|
],
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', prompt=YOUR_JUDGE_TEMPLATE), # Template for the judge
|
||||||
|
],
|
||||||
|
),
|
||||||
|
),
|
||||||
|
dataset_cfg=dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
path='path/to/your/dataset',
|
||||||
|
file_name='your_dataset.jsonl',
|
||||||
|
reader_cfg=reader_cfg,
|
||||||
|
),
|
||||||
|
judge_cfg=YOUR_JUDGE_MODEL_CONFIG, # Configuration for the judge model
|
||||||
|
dict_postprocessor=dict(type=generic_llmjudge_postprocess), # Post-processing the judge's output
|
||||||
|
),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Using CustomDataset with GenericLLMEvaluator
|
||||||
|
|
||||||
|
Here's how to set up a complete configuration for LLM judge evaluation:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
from opencompass.datasets import CustomDataset
|
||||||
|
from opencompass.evaluator import GenericLLMEvaluator
|
||||||
|
from opencompass.datasets import generic_llmjudge_postprocess
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||||
|
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||||
|
|
||||||
|
# Import your judge model configuration
|
||||||
|
with read_base():
|
||||||
|
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_14b_instruct import (
|
||||||
|
models as judge_model,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Define your judge template
|
||||||
|
JUDGE_TEMPLATE = """
|
||||||
|
Please evaluate whether the following response correctly answers the question.
|
||||||
|
Question: {problem}
|
||||||
|
Reference Answer: {answer}
|
||||||
|
Model Response: {prediction}
|
||||||
|
|
||||||
|
Is the model response correct? If correct, answer "A"; if incorrect, answer "B".
|
||||||
|
""".strip()
|
||||||
|
|
||||||
|
# Dataset reader configuration
|
||||||
|
reader_cfg = dict(input_columns=['problem'], output_column='answer')
|
||||||
|
|
||||||
|
# Inference configuration for the model being evaluated
|
||||||
|
infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}',
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Evaluation configuration with LLM judge
|
||||||
|
eval_cfg = dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=GenericLLMEvaluator,
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
begin=[
|
||||||
|
dict(
|
||||||
|
role='SYSTEM',
|
||||||
|
fallback_role='HUMAN',
|
||||||
|
prompt="You are a helpful assistant who evaluates the correctness and quality of models' outputs.",
|
||||||
|
)
|
||||||
|
],
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', prompt=JUDGE_TEMPLATE),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
),
|
||||||
|
dataset_cfg=dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
path='path/to/your/dataset',
|
||||||
|
file_name='your_dataset.jsonl',
|
||||||
|
reader_cfg=reader_cfg,
|
||||||
|
),
|
||||||
|
judge_cfg=judge_model[0],
|
||||||
|
dict_postprocessor=dict(type=generic_llmjudge_postprocess),
|
||||||
|
),
|
||||||
|
pred_role='BOT',
|
||||||
|
)
|
||||||
|
|
||||||
|
# Dataset configuration
|
||||||
|
datasets = [
|
||||||
|
dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
abbr='my-dataset',
|
||||||
|
path='path/to/your/dataset',
|
||||||
|
file_name='your_dataset.jsonl',
|
||||||
|
reader_cfg=reader_cfg,
|
||||||
|
infer_cfg=infer_cfg,
|
||||||
|
eval_cfg=eval_cfg,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# Model configuration for the model being evaluated
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr='model-to-evaluate',
|
||||||
|
path='path/to/your/model',
|
||||||
|
# ... other model configurations
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# Output directory
|
||||||
|
work_dir = './outputs/llm_judge_eval'
|
||||||
|
```
|
||||||
|
|
||||||
|
## GenericLLMEvaluator
|
||||||
|
|
||||||
|
The GenericLLMEvaluator is designed to use an LLM as a judge for evaluating model outputs. Key features include:
|
||||||
|
|
||||||
|
1. Flexible prompt templates for instructing the judge
|
||||||
|
2. Support for various judge models (local or API-based)
|
||||||
|
3. Customizable evaluation criteria through prompt engineering
|
||||||
|
4. Post-processing of judge outputs to extract structured evaluations
|
||||||
|
|
||||||
|
**Important Note**: The current generic version of the judge template only supports outputs in the format of "A" (correct) or "B" (incorrect), and does not support other output formats (like "CORRECT" or "INCORRECT"). This is because the post-processing function `generic_llmjudge_postprocess` is specifically designed to parse this format.
|
||||||
|
|
||||||
|
The evaluator works by:
|
||||||
|
|
||||||
|
1. Taking the original problem, reference answer, and model prediction
|
||||||
|
2. Formatting them into a prompt for the judge model
|
||||||
|
3. Parsing the judge's response to determine the evaluation result (looking for "A" or "B")
|
||||||
|
4. Aggregating results across the dataset
|
||||||
|
|
||||||
|
If you would like to see the full details of evaluation results, you can add `--dump-eval-details` to the command line when you start the job.
|
||||||
|
Example evaluation output:
|
||||||
|
|
||||||
|
```python
|
||||||
|
{
|
||||||
|
'accuracy': 75.0, # Percentage of responses judged as correct
|
||||||
|
'details': [
|
||||||
|
{
|
||||||
|
'origin_prompt': """
|
||||||
|
Please evaluate whether the following response correctly answers the question.
|
||||||
|
Question: What is the capital of France?
|
||||||
|
Reference Answer: Paris
|
||||||
|
Model Response: Paris
|
||||||
|
Is the model response correct? If correct, answer "A"; if incorrect, answer "B".
|
||||||
|
""",
|
||||||
|
'gold': 'Paris',
|
||||||
|
'prediction': 'A',
|
||||||
|
},
|
||||||
|
# ... more results
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Complete Example
|
||||||
|
|
||||||
|
For a complete working example, refer to the `eval_llm_judge.py` file in the examples directory, which demonstrates how to evaluate mathematical problem-solving using an LLM judge.
|
||||||
|
|
@ -0,0 +1,169 @@
|
||||||
|
# Long Context Evaluation Guidance
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
Although large-scale language models (LLMs) such as GPT-4 have demonstrated significant advantages in handling natural language tasks, most current open-source models can only handle texts with a length of a few thousand tokens, which limits their ability to process long contexts such as reading books and writing text summaries. To explore the performance of models in dealing with long contexts, we use the [L-Eval](https://github.com/OpenLMLab/LEval) and [LongBench](https://github.com/THUDM/LongBench) datasets to test the model's ability to handle long contexts.
|
||||||
|
|
||||||
|
## Existing Algorithms and models
|
||||||
|
|
||||||
|
When dealing with long context inputs, the two main challenges faced by large models are the inference time cost and catastrophic forgetting. Recently, a large amount of research has been devoted to extending the model length, focusing on three improvement directions:
|
||||||
|
|
||||||
|
- Attention mechanisms. The ultimate goal of these methods is to reduce the computation cost of query-key pairs, but they may affect the performance of downstream tasks.
|
||||||
|
- Input methods. Some studies divide long context inputs into chunks or retrieve pre-existing text segments to enhance the model's ability to handle long contexts, but these methods are only effective for some tasks and are difficult to adapt to multiple downstream tasks.
|
||||||
|
- Position encoding. This research includes RoPE, ALiBi, Position Interpolation etc., which have shown good results in length extrapolation. These methods have been used to train long context models such as ChatGLM2-6B-32k and LongChat-32k.
|
||||||
|
|
||||||
|
First, we introduce some popular position encoding algorithms.
|
||||||
|
|
||||||
|
### RoPE
|
||||||
|
|
||||||
|
RoPE is a type of positional embedding that injects the information of position in Transformer. It encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation. A graphic illustration of RoPE is shown below.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/08c57958-0dcb-40d7-b91b-33f20ca2d89f>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding.
|
||||||
|
|
||||||
|
RoPE is adopted in many LLMs including LLaMA, LLaMA 2 and Vicuna-7b-v1.5-16k.
|
||||||
|
|
||||||
|
### ALiBi
|
||||||
|
|
||||||
|
Though RoPE and other alternatives to the original sinusoidal position method(like T5 bias) have improved extrapolation, they are considerably slower than the sinusoidal approach and use extra memory and parameter. Therefore, Attention with Linear Biases (ALiBi) is introduced to facilitate efficient extrapolation.
|
||||||
|
|
||||||
|
For an input subsequence of length L, the attention sublayer computes the attention scores for the ith query
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
q_{i} \in R^{1 \times d}, (1 \leq i \leq L)
|
||||||
|
```
|
||||||
|
|
||||||
|
in each head, given the first i keys
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
K \in R^{i \times d}
|
||||||
|
```
|
||||||
|
|
||||||
|
where d is the head dimension.
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
softmax(q_{i}K^{T})
|
||||||
|
```
|
||||||
|
|
||||||
|
ALiBi negatively biases attention scores with a linearly decreasing penalty proportional to the distance between the relevant key and query. The only modification it applies is after the query-key dot product, where it adds a static, non-learned bias.
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
softmax(q_{i}K^{T}+m\cdot[-(i-1),...,-2,-1,0])
|
||||||
|
```
|
||||||
|
|
||||||
|
where scalar m is a head-specific slope fixed before training.
|
||||||
|
|
||||||
|
ALiBi eliminates position embeddings and it is as fast as the sinusoidal approach. It is used in LLMs including mpt-7b-storywriter, which is prepared to handle extremely long inputs.
|
||||||
|
|
||||||
|
### Position Interpolation(PI)
|
||||||
|
|
||||||
|
Many existing pre-trained LLMs including LLaMA use positional encodings that have weak extrapolation properties(e.g. RoPE). Position Interpolation is proposed and it can easily enable very long context windows while preserving model quality relatively well for the tasks within its original context window size.
|
||||||
|
|
||||||
|
The key idea of Position Interpolation is directly down-scale the position indices so that the maximum position index matches the previous context window limit in the pre-training stage. In other words, to accommodate more input tokens, the algorithm interpolates position encodings at neighboring integer positions, utilizing the fact that position encodings can be applied on non-integer positions, as opposed toextrapolating outside the trained positions, which may lead to catastrophic values. The algorithm requires only a very short period of fine-tuning for the model to fully adapt to greatly extended context windows.
|
||||||
|
|
||||||
|
An illustration of Position Interpolation method is shown below. Lower left illustrates Position Interpolation where it downscales the position indices (blue and green dots) themselves from \[0, 4096\] to \[0, 2048\] to force them to reside in the pretrained range.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/406454ba-a811-4c66-abbe-3a5528947257>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
Position Interpolation empowers ChatGLM2-6B-32k, a model based on ChatGLM2-6B, to deal with a 32k context window size.
|
||||||
|
|
||||||
|
Next, we introduce some long context language models we evaluate.
|
||||||
|
|
||||||
|
### XGen-7B-8k
|
||||||
|
|
||||||
|
XGen-7B-8k is trained with standard dense attention on up to 8k sequence length for up to 1.5T tokens. To mitigate slow training, XGen-7B-8k introduces training in stages with increasing sequence length. First, 800B tokens with sequence length of 2k tokens are observed, then 400B tokens with 4k, finally, 300B tokens with 8k length.
|
||||||
|
|
||||||
|
### Vicuna-7b-v1.5-16k
|
||||||
|
|
||||||
|
Vicuna-7b-v1.5-16k is fine-tuned from LLaMA 2 with supervised instruction fine-tuning and linear RoPE scaling. The training data is around 125K conversations collected from ShareGPT, a website where users can share their ChatGPT conversation. These conversations are packed into sequences that contain 16k tokens each.
|
||||||
|
|
||||||
|
### LongChat-7b-v1.5-32k
|
||||||
|
|
||||||
|
LongChat-7b-v1.5-32k is fine-tuned from LLaMA 2 models, which were originally pretrained with 4k context length. The training recipe can be conceptually described in two steps. The first step is condensing RoPE. Since the LLaMA model has not observed scenarios where position_ids > 4096 during the pre-training phase, LongChat condenses position_ids > 4096 to be within 0 to 4096. The second step is fine-tuning LongChat model on curated conversation data. In this step, the data is cleaned using FastChat data pipeline and truncated to the maximum length of model.
|
||||||
|
|
||||||
|
### ChatGLM2-6B-32k
|
||||||
|
|
||||||
|
The ChatGLM2-6B-32k further strengthens the ability to understand long texts based on the ChatGLM2-6B. Based on the method of Positional Interpolation, and trained with a 32K context length during the dialogue alignment, ChatGLM2-6B-32k can better handle up to 32K context length.
|
||||||
|
|
||||||
|
## [L-Eval](https://github.com/OpenLMLab/LEval)
|
||||||
|
|
||||||
|
L-Eval is a long context dataset built by OpenLMLab, consisting of 18 subtasks, including texts from various fields such as law, economy, and technology. The dataset consists of a total of 411 documents, over 2000 test cases, with an average document length of 7217 words. The subtasks in this dataset are divided into close-ended and open-ended categories, with 5 close-ended tasks evaluated using the exact match criterion and 13 open-ended tasks evaluated using Rouge scores.
|
||||||
|
|
||||||
|
## [LongBench](https://github.com/THUDM/LongBench)
|
||||||
|
|
||||||
|
LongBench is a long context dataset built by THUDM, consisting of 21 subtasks with a total of 4750 test cases. This dataset is the first long context dataset that includes both English and Chinese texts, with an average English text length of 6711 words and an average Chinese text length of 13386 characters. The 21 subtasks are divided into 6 types, providing a more comprehensive evaluation of the model's capabilities in various aspects.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/4555e937-c519-4e9c-ad8d-7370430d466a>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
## Evaluation Method
|
||||||
|
|
||||||
|
Due to the different maximum input lengths accepted by different models, in order to compare these large models more fairly, when the input length exceeds the maximum input limit of the model, we will trim the middle part of the input text to avoid missing prompt words.
|
||||||
|
|
||||||
|
## Long Context Ability Ranking
|
||||||
|
|
||||||
|
In the LongBench and L-Eval ability rankings, we select the average ranking **(The lower the better)** of each model in the subtask as the standard. It can be seen that GPT-4 and GPT-3.5-turbo-16k still occupy a leading position in long context tasks, while models like ChatGLM2-6B-32k also show significant improvement in long context ability after position interpolation based on ChatGLM2-6B.
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/29b5ad12-d9a3-4255-be0a-f770923fe514>
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/680b4cda-c2b1-45d1-8c33-196dee1a38f3>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
The original scores are shown below.
|
||||||
|
|
||||||
|
| L-Eval | GPT-4 | GPT-3.5-turbo-16k | chatglm2-6b-32k | vicuna-7b-v1.5-16k | xgen-7b-8k | internlm-chat-7b-8k | longchat-7b-v1.5-32k | chatglm2-6b |
|
||||||
|
| ----------------- | ----- | ----------------- | --------------- | ------------------ | ---------- | ------------------- | -------------------- | ----------- |
|
||||||
|
| coursera | 61.05 | 50 | 45.35 | 26.74 | 33.72 | 40.12 | 27.91 | 38.95 |
|
||||||
|
| gsm100 | 92 | 78 | 27 | 11 | 8 | 19 | 5 | 8 |
|
||||||
|
| quality | 81.19 | 62.87 | 44.55 | 11.39 | 33.66 | 45.54 | 29.7 | 41.09 |
|
||||||
|
| tpo | 72.93 | 74.72 | 56.51 | 17.47 | 44.61 | 60.59 | 17.1 | 56.51 |
|
||||||
|
| topic_retrieval | 100 | 79.33 | 44.67 | 24.67 | 1.33 | 0 | 25.33 | 1.33 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| financialqa | 53.49 | 50.32 | 35.41 | 44.59 | 39.28 | 25.09 | 34.07 | 17.82 |
|
||||||
|
| gov_report | 50.84 | 50.48 | 42.97 | 48.17 | 38.52 | 31.29 | 36.52 | 41.88 |
|
||||||
|
| legal_contract_qa | 31.23 | 27.97 | 34.21 | 24.25 | 21.36 | 19.28 | 13.32 | 17.59 |
|
||||||
|
| meeting_summ | 31.44 | 33.54 | 29.13 | 28.52 | 27.96 | 17.56 | 22.32 | 15.98 |
|
||||||
|
| multidocqa | 37.81 | 35.84 | 28.6 | 26.88 | 24.41 | 22.43 | 21.85 | 19.66 |
|
||||||
|
| narrativeqa | 25.87 | 25.73 | 18.24 | 20.58 | 16.87 | 13.81 | 16.87 | 1.16 |
|
||||||
|
| nq | 67.36 | 66.91 | 41.06 | 36.44 | 29.43 | 16.42 | 35.02 | 0.92 |
|
||||||
|
| news_summ | 34.52 | 40.41 | 32.72 | 33.98 | 26.87 | 22.48 | 30.33 | 29.51 |
|
||||||
|
| paper_assistant | 42.26 | 41.76 | 34.59 | 35.83 | 25.39 | 28.25 | 30.42 | 30.43 |
|
||||||
|
| patent_summ | 48.61 | 50.62 | 46.04 | 48.87 | 46.53 | 30.3 | 41.6 | 41.25 |
|
||||||
|
| review_summ | 31.98 | 33.37 | 21.88 | 29.21 | 26.85 | 16.61 | 20.02 | 19.68 |
|
||||||
|
| scientificqa | 49.76 | 48.32 | 31.27 | 31 | 27.43 | 33.01 | 20.98 | 13.61 |
|
||||||
|
| tvshow_summ | 34.84 | 31.36 | 23.97 | 27.88 | 26.6 | 14.55 | 25.09 | 19.45 |
|
||||||
|
|
||||||
|
| LongBench | GPT-4 | GPT-3.5-turbo-16k | chatglm2-6b-32k | longchat-7b-v1.5-32k | vicuna-7b-v1.5-16k | internlm-chat-7b-8k | chatglm2-6b | xgen-7b-8k |
|
||||||
|
| ------------------- | ----- | ----------------- | --------------- | -------------------- | ------------------ | ------------------- | ----------- | ---------- |
|
||||||
|
| NarrativeQA | 31.2 | 25.79 | 19.27 | 19.19 | 23.65 | 12.24 | 13.09 | 18.85 |
|
||||||
|
| Qasper | 42.77 | 43.4 | 33.93 | 30.36 | 31.45 | 24.81 | 22.52 | 20.18 |
|
||||||
|
| MultiFieldQA-en | 55.1 | 54.35 | 45.58 | 44.6 | 43.38 | 25.41 | 38.09 | 37 |
|
||||||
|
| MultiFieldQA-zh | 64.4 | 61.92 | 52.94 | 32.35 | 44.65 | 36.13 | 37.67 | 14.7 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| HotpotQA | 59.85 | 52.49 | 46.41 | 34.43 | 34.17 | 27.42 | 27.35 | 28.78 |
|
||||||
|
| 2WikiMQA | 67.52 | 41.7 | 33.63 | 23.06 | 20.45 | 26.24 | 22.83 | 20.13 |
|
||||||
|
| Musique | 37.53 | 27.5 | 21.57 | 12.42 | 13.92 | 9.75 | 7.26 | 11.34 |
|
||||||
|
| DuReader (zh) | 38.65 | 29.37 | 38.53 | 20.25 | 20.42 | 11.11 | 17.18 | 8.57 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| GovReport | 32.09 | 29.92 | 32.47 | 29.83 | 29.27 | 18.38 | 22.86 | 23.37 |
|
||||||
|
| QMSum | 24.37 | 23.67 | 23.19 | 22.71 | 23.37 | 18.45 | 21.23 | 21.12 |
|
||||||
|
| Multi_news | 28.52 | 27.05 | 25.12 | 26.1 | 27.83 | 24.52 | 24.7 | 23.69 |
|
||||||
|
| VCSUM (zh) | 15.54 | 16.88 | 15.95 | 13.46 | 15.76 | 12.91 | 14.07 | 0.98 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| TREC | 78.5 | 73.5 | 30.96 | 29.23 | 32.06 | 39 | 24.46 | 29.31 |
|
||||||
|
| TriviaQA | 92.19 | 92.75 | 80.64 | 64.19 | 46.53 | 79.55 | 64.19 | 69.58 |
|
||||||
|
| SAMSum | 46.32 | 43.16 | 29.49 | 25.23 | 25.23 | 43.05 | 20.22 | 16.05 |
|
||||||
|
| LSHT (zh) | 41.5 | 34.5 | 22.75 | 20 | 24.75 | 20.5 | 16 | 18.67 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| Passage Count | 8.5 | 3 | 3 | 1 | 3 | 1.76 | 3 | 1 |
|
||||||
|
| PassageRetrieval-en | 75 | 73 | 57.5 | 20.5 | 16.5 | 7 | 5.5 | 12 |
|
||||||
|
| PassageRetrieval-zh | 96 | 82.5 | 58 | 15 | 21 | 2.29 | 5 | 3.75 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| LCC | 59.25 | 53.49 | 53.3 | 51.46 | 49.3 | 49.32 | 46.59 | 44.1 |
|
||||||
|
| RepoBench-P | 55.42 | 55.95 | 46.66 | 52.18 | 41.49 | 35.86 | 41.97 | 41.83 |
|
||||||
|
|
@ -0,0 +1,190 @@
|
||||||
|
# General Math Evaluation Guidance
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
Mathematical reasoning is a crucial capability for large language models (LLMs). To evaluate a model's mathematical abilities, we need to test its capability to solve mathematical problems step by step and provide accurate final answers. OpenCompass provides a convenient way to evaluate mathematical reasoning through the CustomDataset and MATHEvaluator components.
|
||||||
|
|
||||||
|
## Dataset Format
|
||||||
|
|
||||||
|
The math evaluation dataset should be in either JSON Lines (.jsonl) or CSV format. Each problem should contain at least:
|
||||||
|
|
||||||
|
- A problem statement
|
||||||
|
- A solution/answer (typically in LaTeX format with the final answer in \\boxed{})
|
||||||
|
|
||||||
|
Example JSONL format:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"problem": "Find the value of x if 2x + 3 = 7", "solution": "Let's solve step by step:\n2x + 3 = 7\n2x = 7 - 3\n2x = 4\nx = 2\nTherefore, \\boxed{2}"}
|
||||||
|
```
|
||||||
|
|
||||||
|
Example CSV format:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
problem,solution
|
||||||
|
"Find the value of x if 2x + 3 = 7","Let's solve step by step:\n2x + 3 = 7\n2x = 7 - 3\n2x = 4\nx = 2\nTherefore, \\boxed{2}"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Configuration
|
||||||
|
|
||||||
|
To evaluate mathematical reasoning, you'll need to set up three main components:
|
||||||
|
|
||||||
|
1. Dataset Reader Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
math_reader_cfg = dict(
|
||||||
|
input_columns=['problem'], # Column name for the question
|
||||||
|
output_column='solution' # Column name for the answer
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Inference Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
math_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}\nPlease reason step by step, and put your final answer within \\boxed{}.',
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Evaluation Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
math_eval_cfg = dict(
|
||||||
|
evaluator=dict(type=MATHEvaluator),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Using CustomDataset
|
||||||
|
|
||||||
|
Here's how to set up a complete configuration for math evaluation:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
from opencompass.datasets import CustomDataset
|
||||||
|
|
||||||
|
math_datasets = [
|
||||||
|
dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
abbr='my-math-dataset', # Dataset abbreviation
|
||||||
|
path='path/to/your/dataset', # Path to your dataset file
|
||||||
|
reader_cfg=math_reader_cfg,
|
||||||
|
infer_cfg=math_infer_cfg,
|
||||||
|
eval_cfg=math_eval_cfg,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## MATHEvaluator
|
||||||
|
|
||||||
|
The MATHEvaluator is specifically designed to evaluate mathematical answers. It is developed based on the math_verify library, which provides mathematical expression parsing and verification capabilities, supporting extraction and equivalence verification for both LaTeX and general expressions.
|
||||||
|
|
||||||
|
The MATHEvaluator implements:
|
||||||
|
|
||||||
|
1. Extracts answers from both predictions and references using LaTeX extraction
|
||||||
|
2. Handles various LaTeX formats and environments
|
||||||
|
3. Verifies mathematical equivalence between predicted and reference answers
|
||||||
|
4. Provides detailed evaluation results including:
|
||||||
|
- Accuracy score
|
||||||
|
- Detailed comparison between predictions and references
|
||||||
|
- Parse results of both predicted and reference answers
|
||||||
|
|
||||||
|
The evaluator supports:
|
||||||
|
|
||||||
|
- Basic arithmetic operations
|
||||||
|
- Fractions and decimals
|
||||||
|
- Algebraic expressions
|
||||||
|
- Trigonometric functions
|
||||||
|
- Roots and exponents
|
||||||
|
- Mathematical symbols and operators
|
||||||
|
|
||||||
|
Example evaluation output:
|
||||||
|
|
||||||
|
```python
|
||||||
|
{
|
||||||
|
'accuracy': 85.0, # Percentage of correct answers
|
||||||
|
'details': [
|
||||||
|
{
|
||||||
|
'predictions': 'x = 2', # Parsed prediction
|
||||||
|
'references': 'x = 2', # Parsed reference
|
||||||
|
'correct': True # Whether they match
|
||||||
|
},
|
||||||
|
# ... more results
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Complete Example
|
||||||
|
|
||||||
|
Here's a complete example of how to set up math evaluation:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
from opencompass.datasets import CustomDataset
|
||||||
|
from opencompass.openicl.icl_evaluator.math_evaluator import MATHEvaluator
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||||
|
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||||
|
|
||||||
|
# Dataset reader configuration
|
||||||
|
math_reader_cfg = dict(input_columns=['problem'], output_column='solution')
|
||||||
|
|
||||||
|
# Inference configuration
|
||||||
|
math_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}\nPlease reason step by step, and put your final answer within \\boxed{}.',
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Evaluation configuration
|
||||||
|
math_eval_cfg = dict(
|
||||||
|
evaluator=dict(type=MATHEvaluator),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Dataset configuration
|
||||||
|
math_datasets = [
|
||||||
|
dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
abbr='my-math-dataset',
|
||||||
|
path='path/to/your/dataset.jsonl', # or .csv
|
||||||
|
reader_cfg=math_reader_cfg,
|
||||||
|
infer_cfg=math_infer_cfg,
|
||||||
|
eval_cfg=math_eval_cfg,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# Model configuration
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr='your-model-name',
|
||||||
|
path='your/model/path',
|
||||||
|
# ... other model configurations
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# Output directory
|
||||||
|
work_dir = './outputs/math_eval'
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,197 @@
|
||||||
|
# Needle In A Haystack Experimental Evaluation
|
||||||
|
|
||||||
|
## Introduction to the Needle In A Haystack Test
|
||||||
|
|
||||||
|
The Needle In A Haystack test (inspired by [NeedleInAHaystack](https://github.com/gkamradt/LLMTest_NeedleInAHaystack/blob/main/LLMNeedleHaystackTester.py)) is an evaluation method that randomly inserts key information into long texts to form prompts for large language models (LLMs). The test aims to detect whether large models can extract such key information from extensive texts, thereby assessing the models' capabilities in processing and understanding long documents.
|
||||||
|
|
||||||
|
## Task Overview
|
||||||
|
|
||||||
|
Within the `NeedleBench` framework of `OpenCompass`, we have designed a series of increasingly challenging test scenarios to comprehensively evaluate the models' abilities in long text information extraction and reasoning. For a complete introduction, refer to our [technical report](https://arxiv.org/abs/2407.11963):
|
||||||
|
|
||||||
|
- **Single-Needle Retrieval Task (S-RT)**: Assesses an LLM's ability to extract a single key piece of information from a long text, testing its precision in recalling specific details within broad narratives. This corresponds to the **original Needle In A Haystack test** setup.
|
||||||
|
|
||||||
|
- **Multi-Needle Retrieval Task (M-RT)**: Explores an LLM's capability to retrieve multiple related pieces of information from long texts, simulating real-world scenarios of complex queries on comprehensive documents.
|
||||||
|
|
||||||
|
- **Multi-Needle Reasoning Task (M-RS)**: Evaluates an LLM's long-text abilities by extracting and utilizing multiple key pieces of information, requiring the model to have a comprehensive understanding of each key information fragment.
|
||||||
|
|
||||||
|
- **Ancestral Trace Challenge (ATC)**: Uses the "relational needle" to test an LLM's ability to handle multi-layer logical challenges in real long texts. In the ATC task, a series of logical reasoning questions are used to test the model's memory and analytical skills for every detail in the text. For this task, we remove the irrelevant text (Haystack) setting, designing all texts as critical information, requiring the LLM to use all the content and reasoning in the text accurately to answer the questions.
|
||||||
|
|
||||||
|
### Evaluation Steps
|
||||||
|
|
||||||
|
> Note: In the latest code, OpenCompass has been set to automatically load the dataset from [Huggingface API](https://huggingface.co/datasets/opencompass/NeedleBench), so you can **skip directly** the following steps of manually downloading and placing the dataset.
|
||||||
|
|
||||||
|
1. Download the dataset from [here](https://github.com/open-compass/opencompass/files/14741330/needlebench.zip).
|
||||||
|
|
||||||
|
2. Place the downloaded files in the `opencompass/data/needlebench/` directory. The expected file structure in the `needlebench` directory is shown below:
|
||||||
|
|
||||||
|
```
|
||||||
|
opencompass/
|
||||||
|
├── configs
|
||||||
|
├── docs
|
||||||
|
├── data
|
||||||
|
│ └── needlebench
|
||||||
|
│ ├── multi_needle_reasoning_en.json
|
||||||
|
│ ├── multi_needle_reasoning_zh.json
|
||||||
|
│ ├── names.json
|
||||||
|
│ ├── needles.jsonl
|
||||||
|
│ ├── PaulGrahamEssays.jsonl
|
||||||
|
│ ├── zh_finance.jsonl
|
||||||
|
│ ├── zh_game.jsonl
|
||||||
|
│ ├── zh_government.jsonl
|
||||||
|
│ ├── zh_movie.jsonl
|
||||||
|
│ ├── zh_tech.jsonl
|
||||||
|
│ ├── zh_general.jsonl
|
||||||
|
├── LICENSE
|
||||||
|
├── opencompass
|
||||||
|
├── outputs
|
||||||
|
├── run.py
|
||||||
|
├── more...
|
||||||
|
```
|
||||||
|
|
||||||
|
### `OpenCompass` Environment Setup
|
||||||
|
|
||||||
|
```bash
|
||||||
|
conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
|
||||||
|
conda activate opencompass
|
||||||
|
git clone https://github.com/open-compass/opencompass opencompass
|
||||||
|
cd opencompass
|
||||||
|
pip install -e .
|
||||||
|
```
|
||||||
|
|
||||||
|
### Configuring the Dataset
|
||||||
|
|
||||||
|
We have pre-configured datasets for common text lengths (4k, 8k, 32k, 128k, 200k, 1000k) in `configs/datasets/needlebench`, allowing you to flexibly create datasets that meet your needs by defining related parameters in the configuration files.
|
||||||
|
|
||||||
|
### Evaluation Example
|
||||||
|
|
||||||
|
#### Evaluating `InternLM2-7B` Model Deployed Using `LMDeploy`
|
||||||
|
|
||||||
|
For example, to evaluate the `InternLM2-7B` model deployed using `LMDeploy` for all tasks in NeedleBench-4K, you can directly use the following command in the command line. This command calls the pre-defined model and dataset configuration files without needing to write additional configuration files:
|
||||||
|
|
||||||
|
##### Local Evaluation
|
||||||
|
|
||||||
|
If you are evaluating the model locally, the command below will utilize all available GPUs on your machine. You can limit the GPU access for `OpenCompass` by setting the `CUDA_VISIBLE_DEVICES` environment variable. For instance, using `CUDA_VISIBLE_DEVICES=0,1,2,3 python run.py ...` will only expose the first four GPUs to OpenCompass, ensuring that it does not use more than these four GPUs.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Local Evaluation
|
||||||
|
python run.py --dataset needlebench_4k --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Evaluation on a Slurm Cluster
|
||||||
|
|
||||||
|
If using `Slurm`, you can add parameters such as `--slurm -p partition_name -q reserved --max-num-workers 16`, as shown below:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Slurm Evaluation
|
||||||
|
python run.py --dataset needlebench_4k --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Evaluating a Subdataset Only
|
||||||
|
|
||||||
|
If you only want to test the original NeedleInAHaystack task setup, you could change the dataset parameter to `needlebench_single_4k`, which corresponds to the single needle version of the NeedleInAHaystack test at 4k length:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --dataset needlebench_single_4k --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also choose to evaluate a specific subdataset, such as changing the `--datasets` parameter to `needlebench_single_4k/needlebench_zh_datasets` for testing just the Chinese version of the single needle 4K length NeedleInAHaystack task. The parameter after `/` represents the subdataset, which can be found in the dataset variable of `configs/datasets/needlebench/needlebench_4k/needlebench_single_4k.py` :
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --dataset needlebench_single_4k/needlebench_zh_datasets --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
Be sure to install the [LMDeploy](https://github.com/InternLM/lmdeploy) tool before starting the evaluation:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
This command initiates the evaluation process, with parameters `-p partition_name -q auto` and `--max-num-workers 16` used to specify the Slurm partition name and the maximum number of worker processes.
|
||||||
|
|
||||||
|
#### Evaluating Other `Huggingface` Models
|
||||||
|
|
||||||
|
For other models, we recommend writing an additional configuration file to modify the model's `max_seq_len` and `max_out_len` parameters so the model can receive the complete long text content, as we have prepared in the `configs/eval_needlebench.py` file. The complete content is as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
# We use mmengine.config to import variables from other configuration files
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# from .models.hf_internlm.lmdeploy_internlm2_chat_7b import models as internlm2_chat_7b_200k
|
||||||
|
from .models.hf_internlm.hf_internlm2_chat_7b import models as internlm2_chat_7b
|
||||||
|
|
||||||
|
# Evaluate needlebench_4k, adjust the configuration to use 8k, 32k, 128k, 200k, or 1000k if necessary.
|
||||||
|
# from .datasets.needlebench.needlebench_4k.needlebench_4k import needlebench_datasets
|
||||||
|
# from .summarizers.needlebench import needlebench_4k_summarizer as summarizer
|
||||||
|
|
||||||
|
# only eval original "needle in a haystack test" in needlebench_4k
|
||||||
|
from .datasets.needlebench.needlebench_4k.needlebench_single_4k import needlebench_zh_datasets, needlebench_en_datasets
|
||||||
|
from .summarizers.needlebench import needlebench_4k_summarizer as summarizer
|
||||||
|
|
||||||
|
# eval Ancestral Tracing Challenge(ATC)
|
||||||
|
# from .datasets.needlebench.atc.atc_choice_50 import needlebench_datasets
|
||||||
|
# from .summarizers.needlebench import atc_summarizer_50 as summarizer
|
||||||
|
|
||||||
|
datasets = sum([v for k, v in locals().items() if ('datasets' in k)], [])
|
||||||
|
|
||||||
|
for m in internlm2_chat_7b:
|
||||||
|
m['max_seq_len'] = 30768 # Ensure InternLM2-7B model can receive the complete long text, other models need to adjust according to their maximum sequence length support.
|
||||||
|
m['max_out_len'] = 2000 # Ensure that in the multi-needle recall task, the model can receive a complete response
|
||||||
|
|
||||||
|
models = internlm2_chat_7b
|
||||||
|
|
||||||
|
work_dir = './outputs/needlebench'
|
||||||
|
```
|
||||||
|
|
||||||
|
Once the test `config` file is written, we can pass the corresponding config file path through the `run.py` file in the command line, such as:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_needlebench.py --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
Note, at this point, we do not need to pass in the `--dataset, --models, --summarizer` parameters, as we have already defined these configurations in the config file. You can manually adjust the `--max-num-workers` setting to adjust the number of parallel workers.
|
||||||
|
|
||||||
|
### Visualization
|
||||||
|
|
||||||
|
We have built-in result visualization into the `summarizer` implementation in the latest code version. You can find the corresponding visualizations in the plots directory of the respective output folder, eliminating the need for manual visualization of scores across various depths and lengths.
|
||||||
|
|
||||||
|
If you use this method, please add a reference:
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
|
||||||
|
@misc{li2024needlebenchllmsretrievalreasoning,
|
||||||
|
title={NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?},
|
||||||
|
author={Mo Li and Songyang Zhang and Yunxin Liu and Kai Chen},
|
||||||
|
year={2024},
|
||||||
|
eprint={2407.11963},
|
||||||
|
archivePrefix={arXiv},
|
||||||
|
primaryClass={cs.CL},
|
||||||
|
url={https://arxiv.org/abs/2407.11963},
|
||||||
|
}
|
||||||
|
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished={\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
|
@misc{LLMTest_NeedleInAHaystack,
|
||||||
|
title={LLMTest Needle In A Haystack - Pressure Testing LLMs},
|
||||||
|
author={gkamradt},
|
||||||
|
year={2023},
|
||||||
|
howpublished={\url{https://github.com/gkamradt/LLMTest_NeedleInAHaystack}}
|
||||||
|
}
|
||||||
|
|
||||||
|
@misc{wei2023skywork,
|
||||||
|
title={Skywork: A More Open Bilingual Foundation Model},
|
||||||
|
author={Tianwen Wei and Liang Zhao and Lichang Zhang and Bo Zhu and Lijie Wang and Haihua Yang and Biye Li and Cheng Cheng and Weiwei Lü and Rui Hu and Chenxia Li and Liu Yang and Xilin Luo and Xuejie Wu and Lunan Liu and Wenjun Cheng and Peng Cheng and Jianhao Zhang and Xiaoyu Zhang and Lei Lin and Xiaokun Wang and Yutuan Ma and Chuanhai Dong and Yanqi Sun and Yifu Chen and Yongyi Peng and Xiaojuan Liang and Shuicheng Yan and Han Fang and Yahui Zhou},
|
||||||
|
year={2023},
|
||||||
|
eprint={2310.19341},
|
||||||
|
archivePrefix={arXiv},
|
||||||
|
primaryClass={cs.CL}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,105 @@
|
||||||
|
# Add a dataset
|
||||||
|
|
||||||
|
Although OpenCompass has already included most commonly used datasets, users need to follow the steps below to support a new dataset if wanted:
|
||||||
|
|
||||||
|
1. Add a dataset script `mydataset.py` to the `opencompass/datasets` folder. This script should include:
|
||||||
|
|
||||||
|
- The dataset and its loading method. Define a `MyDataset` class that implements the data loading method `load` as a static method. This method should return data of type `datasets.Dataset`. We use the Hugging Face dataset as the unified interface for datasets to avoid introducing additional logic. Here's an example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import datasets
|
||||||
|
from .base import BaseDataset
|
||||||
|
|
||||||
|
class MyDataset(BaseDataset):
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def load(**kwargs) -> datasets.Dataset:
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
- (Optional) If the existing evaluators in OpenCompass do not meet your needs, you need to define a `MyDatasetEvaluator` class that implements the scoring method `score`. This method should take `predictions` and `references` as input and return the desired dictionary. Since a dataset may have multiple metrics, the method should return a dictionary containing the metrics and their corresponding scores. Here's an example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||||
|
|
||||||
|
class MyDatasetEvaluator(BaseEvaluator):
|
||||||
|
|
||||||
|
def score(self, predictions: List, references: List) -> dict:
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
- (Optional) If the existing postprocessors in OpenCompass do not meet your needs, you need to define the `mydataset_postprocess` method. This method takes an input string and returns the corresponding postprocessed result string. Here's an example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def mydataset_postprocess(text: str) -> str:
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
2. After defining the dataset loading, data postprocessing, and evaluator methods, you need to add the following configurations to the configuration file:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets import MyDataset, MyDatasetEvaluator, mydataset_postprocess
|
||||||
|
|
||||||
|
mydataset_eval_cfg = dict(
|
||||||
|
evaluator=dict(type=MyDatasetEvaluator),
|
||||||
|
pred_postprocessor=dict(type=mydataset_postprocess))
|
||||||
|
|
||||||
|
mydataset_datasets = [
|
||||||
|
dict(
|
||||||
|
type=MyDataset,
|
||||||
|
...,
|
||||||
|
reader_cfg=...,
|
||||||
|
infer_cfg=...,
|
||||||
|
eval_cfg=mydataset_eval_cfg)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- To facilitate the access of your datasets to other users, you need to specify the channels for downloading the datasets in the configuration file. Specifically, you need to first fill in a dataset name given by yourself in the `path` field in the `mydataset_datasets` configuration, and this name will be mapped to the actual download path in the `opencompass/utils/datasets_info.py` file. Here's an example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
mmlu_datasets = [an
|
||||||
|
dict(
|
||||||
|
...,
|
||||||
|
path='opencompass/mmlu',
|
||||||
|
...,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- Next, you need to create a dictionary key in `opencompass/utils/datasets_info.py` with the same name as the one you provided above. If you have already hosted the dataset on HuggingFace or Modelscope, please add a dictionary key to the `DATASETS_MAPPING` dictionary and fill in the HuggingFace or Modelscope dataset address in the `hf_id` or `ms_id` key, respectively. You can also specify a default local address. Here's an example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
"opencompass/mmlu": {
|
||||||
|
"ms_id": "opencompass/mmlu",
|
||||||
|
"hf_id": "opencompass/mmlu",
|
||||||
|
"local": "./data/mmlu/",
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
- If you wish for the provided dataset to be directly accessible from the OpenCompass OSS repository when used by others, you need to submit the dataset files in the Pull Request phase. We will then transfer the dataset to the OSS on your behalf and create a new dictionary key in the `DATASET_URL`.
|
||||||
|
|
||||||
|
- To ensure the optionality of data sources, you need to improve the method `load` in the dataset script `mydataset.py`. Specifically, you need to implement a functionality to switch among different download sources based on the setting of the environment variable `DATASET_SOURCE`. It should be noted that if the environment variable `DATASET_SOURCE` is not set, the dataset will default to being downloaded from the OSS repository. Here's an example from `opencompass/dataset/cmmlu.py`:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def load(path: str, name: str, **kwargs):
|
||||||
|
...
|
||||||
|
if environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||||
|
...
|
||||||
|
else:
|
||||||
|
...
|
||||||
|
return dataset
|
||||||
|
```
|
||||||
|
|
||||||
|
3. After completing the dataset script and config file, you need to register the information of your new dataset in the file `dataset-index.yml` at the main directory, so that it can be added to the dataset statistics list on the OpenCompass website.
|
||||||
|
|
||||||
|
- The keys that need to be filled in include `name`: the name of your dataset, `category`: the category of your dataset, `paper`: the URL of the paper or project, and `configpath`: the path to the dataset config file. Here's an example:
|
||||||
|
|
||||||
|
```
|
||||||
|
- mydataset:
|
||||||
|
name: MyDataset
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/xxxxxxx
|
||||||
|
configpath: opencompass/configs/datasets/MyDataset
|
||||||
|
```
|
||||||
|
|
||||||
|
Detailed dataset configuration files and other required configuration files can be referred to in the [Configuration Files](../user_guides/config.md) tutorial. For guides on launching tasks, please refer to the [Quick Start](../get_started/quick_start.md) tutorial.
|
||||||
|
|
@ -0,0 +1,73 @@
|
||||||
|
# Add a Model
|
||||||
|
|
||||||
|
Currently, we support HF models, some model APIs, and some third-party models.
|
||||||
|
|
||||||
|
## Adding API Models
|
||||||
|
|
||||||
|
To add a new API-based model, you need to create a new file named `mymodel_api.py` under `opencompass/models` directory. In this file, you should inherit from `BaseAPIModel` and implement the `generate` method for inference and the `get_token_len` method to calculate the length of tokens. Once you have defined the model, you can modify the corresponding configuration file.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ..base_api import BaseAPIModel
|
||||||
|
|
||||||
|
class MyModelAPI(BaseAPIModel):
|
||||||
|
|
||||||
|
is_api: bool = True
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
path: str,
|
||||||
|
max_seq_len: int = 2048,
|
||||||
|
query_per_second: int = 1,
|
||||||
|
retry: int = 2,
|
||||||
|
**kwargs):
|
||||||
|
super().__init__(path=path,
|
||||||
|
max_seq_len=max_seq_len,
|
||||||
|
meta_template=meta_template,
|
||||||
|
query_per_second=query_per_second,
|
||||||
|
retry=retry)
|
||||||
|
...
|
||||||
|
|
||||||
|
def generate(
|
||||||
|
self,
|
||||||
|
inputs,
|
||||||
|
max_out_len: int = 512,
|
||||||
|
temperature: float = 0.7,
|
||||||
|
) -> List[str]:
|
||||||
|
"""Generate results given a list of inputs."""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def get_token_len(self, prompt: str) -> int:
|
||||||
|
"""Get lengths of the tokenized string."""
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
## Adding Third-Party Models
|
||||||
|
|
||||||
|
To add a new third-party model, you need to create a new file named `mymodel.py` under `opencompass/models` directory. In this file, you should inherit from `BaseModel` and implement the `generate` method for generative inference, the `get_ppl` method for discriminative inference, and the `get_token_len` method to calculate the length of tokens. Once you have defined the model, you can modify the corresponding configuration file.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ..base import BaseModel
|
||||||
|
|
||||||
|
class MyModel(BaseModel):
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
pkg_root: str,
|
||||||
|
ckpt_path: str,
|
||||||
|
tokenizer_only: bool = False,
|
||||||
|
meta_template: Optional[Dict] = None,
|
||||||
|
**kwargs):
|
||||||
|
...
|
||||||
|
|
||||||
|
def get_token_len(self, prompt: str) -> int:
|
||||||
|
"""Get lengths of the tokenized strings."""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def generate(self, inputs: List[str], max_out_len: int) -> List[str]:
|
||||||
|
"""Generate results given a list of inputs. """
|
||||||
|
pass
|
||||||
|
|
||||||
|
def get_ppl(self,
|
||||||
|
inputs: List[str],
|
||||||
|
mask_length: Optional[List[int]] = None) -> List[float]:
|
||||||
|
"""Get perplexity scores given a list of inputs."""
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,186 @@
|
||||||
|
# Using Large Models as JudgeLLM for Objective Evaluation
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
Traditional objective evaluations often rely on standard answers for reference. However, in practical applications, the predicted results of models may vary due to differences in the model's instruction-following capabilities or imperfections in post-processing functions. This can lead to incorrect extraction of answers and comparison with standard answers, resulting in potentially inaccurate evaluation outcomes. To address this issue, we have adopted a process similar to subjective evaluations by introducing JudgeLLM post-prediction to assess the consistency between model responses and standard answers. ([LLM-as-a-Judge](https://arxiv.org/abs/2306.05685)).
|
||||||
|
|
||||||
|
Currently, all models supported by the opencompass repository can be directly used as JudgeLLM. Additionally, we are planning to support dedicated JudgeLLMs.
|
||||||
|
|
||||||
|
## Currently Supported Objective Evaluation Datasets
|
||||||
|
|
||||||
|
1. MATH ([https://github.com/hendrycks/math](https://github.com/hendrycks/math))
|
||||||
|
|
||||||
|
## Custom JudgeLLM Objective Dataset Evaluation
|
||||||
|
|
||||||
|
OpenCompass currently supports most datasets that use `GenInferencer` for inference. The specific process for custom JudgeLLM objective evaluation includes:
|
||||||
|
|
||||||
|
1. Building evaluation configurations using API models or open-source models for inference of question answers.
|
||||||
|
2. Employing a selected evaluation model (JudgeLLM) to assess the outputs of the model.
|
||||||
|
|
||||||
|
### Step One: Building Evaluation Configurations, Using MATH as an Example
|
||||||
|
|
||||||
|
Below is the Config for evaluating the MATH dataset with JudgeLLM, with the evaluation model being *Llama3-8b-instruct* and the JudgeLLM being *Llama3-70b-instruct*. For more detailed config settings, please refer to `configs/eval_math_llm_judge.py`. The following is a brief version of the annotations to help users understand the meaning of the configuration file.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Most of the code in this file is copied from https://github.com/openai/simple-evals/blob/main/math_eval.py
|
||||||
|
from mmengine.config import read_base
|
||||||
|
with read_base():
|
||||||
|
from .models.hf_llama.hf_llama3_8b_instruct import models as hf_llama3_8b_instruct_model # noqa: F401, F403
|
||||||
|
from .models.hf_llama.hf_llama3_70b_instruct import models as hf_llama3_70b_instruct_model # noqa: F401, F403
|
||||||
|
from .datasets.math.math_llm_judge import math_datasets # noqa: F401, F403
|
||||||
|
from opencompass.datasets import math_judement_preprocess
|
||||||
|
from opencompass.partitioners import NaivePartitioner, SizePartitioner
|
||||||
|
from opencompass.partitioners.sub_naive import SubjectiveNaivePartitioner
|
||||||
|
from opencompass.partitioners.sub_size import SubjectiveSizePartitioner
|
||||||
|
from opencompass.runners import LocalRunner
|
||||||
|
from opencompass.runners import SlurmSequentialRunner
|
||||||
|
from opencompass.tasks import OpenICLInferTask
|
||||||
|
from opencompass.tasks.subjective_eval import SubjectiveEvalTask
|
||||||
|
from opencompass.summarizers import AllObjSummarizer
|
||||||
|
from opencompass.openicl.icl_evaluator import LMEvaluator
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
|
||||||
|
|
||||||
|
# ------------- Prompt Settings ----------------------------------------
|
||||||
|
# Evaluation template, please modify the template as needed, JudgeLLM typically uses [Yes] or [No] as the response. For the MATH dataset, the evaluation template is as follows:
|
||||||
|
eng_obj_prompt = """
|
||||||
|
Look at the following two expressions (answers to a math problem) and judge whether they are equivalent. Only perform trivial simplifications
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
|
||||||
|
Expression 1: $2x+3$
|
||||||
|
Expression 2: $3+2x$
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
|
||||||
|
Expression 1: 3/2
|
||||||
|
Expression 2: 1.5
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
|
||||||
|
Expression 1: $x^2+2x+1$
|
||||||
|
Expression 2: $y^2+2y+1$
|
||||||
|
|
||||||
|
[No]
|
||||||
|
|
||||||
|
Expression 1: $x^2+2x+1$
|
||||||
|
Expression 2: $(x+1)^2$
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
|
||||||
|
Expression 1: 3245/5
|
||||||
|
Expression 2: 649
|
||||||
|
|
||||||
|
[No]
|
||||||
|
(these are actually equal, don't mark them equivalent if you need to do nontrivial simplifications)
|
||||||
|
|
||||||
|
Expression 1: 2/(-3)
|
||||||
|
Expression 2: -2/3
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
(trivial simplifications are allowed)
|
||||||
|
|
||||||
|
Expression 1: 72 degrees
|
||||||
|
Expression 2: 72
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
(give benefit of the doubt to units)
|
||||||
|
|
||||||
|
Expression 1: 64
|
||||||
|
Expression 2: 64 square feet
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
(give benefit of the doubt to units)
|
||||||
|
|
||||||
|
Expression 1: 64
|
||||||
|
Expression 2:
|
||||||
|
|
||||||
|
[No]
|
||||||
|
(only mark as equivalent if both expressions are nonempty)
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
YOUR TASK
|
||||||
|
|
||||||
|
|
||||||
|
Respond with only "[Yes]" or "[No]" (without quotes). Do not include a rationale.
|
||||||
|
Expression 1: {obj_gold}
|
||||||
|
Expression 2: {prediction}
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
# ------------- Inference Phase ----------------------------------------
|
||||||
|
# Models to be evaluated
|
||||||
|
models = [*hf_llama3_8b_instruct_model]
|
||||||
|
# Evaluation models
|
||||||
|
judge_models = hf_llama3_70b_instruct_model
|
||||||
|
|
||||||
|
eng_datasets = [*math_datasets]
|
||||||
|
chn_datasets = []
|
||||||
|
datasets = eng_datasets + chn_datasets
|
||||||
|
|
||||||
|
|
||||||
|
for d in eng_datasets:
|
||||||
|
d['eval_cfg']= dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=LMEvaluator,
|
||||||
|
# If you need to preprocess model predictions before judging,
|
||||||
|
# you can specify a pred_postprocessor function here
|
||||||
|
pred_postprocessor=dict(type=math_judement_preprocess),
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt = eng_obj_prompt
|
||||||
|
),
|
||||||
|
]),
|
||||||
|
),
|
||||||
|
),
|
||||||
|
pred_role="BOT",
|
||||||
|
)
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=SizePartitioner, max_task_size=40000),
|
||||||
|
runner=dict(
|
||||||
|
type=LocalRunner,
|
||||||
|
max_num_workers=256,
|
||||||
|
task=dict(type=OpenICLInferTask)),
|
||||||
|
)
|
||||||
|
|
||||||
|
# ------------- Evaluation Configuration --------------------------------
|
||||||
|
eval = dict(
|
||||||
|
partitioner=dict(
|
||||||
|
type=SubjectiveSizePartitioner, max_task_size=80000, mode='singlescore', models=models, judge_models=judge_models,
|
||||||
|
),
|
||||||
|
runner=dict(type=LocalRunner,
|
||||||
|
max_num_workers=16, task=dict(type=SubjectiveEvalTask)),
|
||||||
|
)
|
||||||
|
|
||||||
|
summarizer = dict(
|
||||||
|
type=AllObjSummarizer
|
||||||
|
)
|
||||||
|
|
||||||
|
# Output folder
|
||||||
|
work_dir = 'outputs/obj_all/'
|
||||||
|
```
|
||||||
|
|
||||||
|
### Step Two: Launch Evaluation and Output Results
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py eval_math_llm_judge.py
|
||||||
|
```
|
||||||
|
|
||||||
|
This will initiate two rounds of evaluation. The first round involves model inference to obtain predicted answers to questions, and the second round involves JudgeLLM evaluating the consistency between the predicted answers and the standard answers, and scoring them.
|
||||||
|
|
||||||
|
- The results of model predictions will be saved in `output/.../timestamp/predictions/xxmodel/xxx.json`
|
||||||
|
- The JudgeLLM's evaluation responses will be saved in `output/.../timestamp/results/xxmodel/xxx.json`
|
||||||
|
- The evaluation report will be output to `output/.../timestamp/summary/timestamp/xxx.csv`
|
||||||
|
|
||||||
|
## Results
|
||||||
|
|
||||||
|
Using the Llama3-8b-instruct as the evaluation model and the Llama3-70b-instruct as the evaluator, the MATH dataset was assessed with the following results:
|
||||||
|
|
||||||
|
| Model | JudgeLLM Evaluation | Naive Evaluation |
|
||||||
|
| ------------------- | ------------------- | ---------------- |
|
||||||
|
| llama-3-8b-instruct | 27.7 | 27.8 |
|
||||||
|
|
@ -0,0 +1,65 @@
|
||||||
|
# Evaluation Results Persistence
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
Normally, the evaluation results of OpenCompass will be saved to your work directory. But in some cases, there may be a need for data sharing among users or quickly browsing existing public evaluation results. Therefore, we provide an interface that can quickly transfer evaluation results to external public data stations, and on this basis, provide functions such as uploading, overwriting, and reading.
|
||||||
|
|
||||||
|
## Quick Start
|
||||||
|
|
||||||
|
### Uploading
|
||||||
|
|
||||||
|
By adding `args` to the evaluation command or adding configuration in the Eval script, the results of evaluation can be stored in the path you specify. Here are the examples:
|
||||||
|
|
||||||
|
(Approach 1) Add an `args` option to the command and specify your public path address.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path'
|
||||||
|
```
|
||||||
|
|
||||||
|
(Approach 2) Add configuration in the Eval script.
|
||||||
|
|
||||||
|
```pythonE
|
||||||
|
station_path = '/your_path'
|
||||||
|
```
|
||||||
|
|
||||||
|
### Overwriting
|
||||||
|
|
||||||
|
The above storage method will first determine whether the same task result already exists in the data station based on the `abbr` attribute in the model and dataset configuration before uploading data. If results already exists, cancel this storage. If you need to update these results, please add the `station-overwrite` option to the command, here is an example:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path' --station-overwrite
|
||||||
|
```
|
||||||
|
|
||||||
|
### Reading
|
||||||
|
|
||||||
|
You can directly read existing results from the data station to avoid duplicate evaluation tasks. The read results will directly participate in the 'summarize' step. When using this configuration, only tasks that do not store results in the data station will be initiated. Here is an example:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path' --read-from-station
|
||||||
|
```
|
||||||
|
|
||||||
|
### Command Combination
|
||||||
|
|
||||||
|
1. Only upload the results under your latest working directory to the data station, without supplementing tasks that missing results:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path' -r latest -m viz
|
||||||
|
```
|
||||||
|
|
||||||
|
## Storage Format of the Data Station
|
||||||
|
|
||||||
|
In the data station, the evaluation results are stored as `json` files for each `model-dataset` pair. The specific directory form is `/your_path/dataset_name/model_name.json `. Each `json` file stores a dictionary corresponding to the results, including `predictions`, `results`, and `cfg`, here is an example:
|
||||||
|
|
||||||
|
```pythonE
|
||||||
|
Result = {
|
||||||
|
'predictions': List[Dict],
|
||||||
|
'results': Dict,
|
||||||
|
'cfg': Dict = {
|
||||||
|
'models': Dict,
|
||||||
|
'datasets': Dict,
|
||||||
|
(Only subjective datasets)'judge_models': Dict
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Among this three keys, `predictions` records the predictions of the model on each item of data in the dataset. `results` records the total score of the model on the dataset. `cfg` records detailed configurations of the model and the dataset in this evaluation task.
|
||||||
|
|
@ -0,0 +1,108 @@
|
||||||
|
# Prompt Attack
|
||||||
|
|
||||||
|
We support prompt attack following the idea of [PromptBench](https://github.com/microsoft/promptbench). The main purpose here is to evaluate the robustness of prompt instruction, which means when attack/modify the prompt to instruct the task, how well can this task perform as the original task.
|
||||||
|
|
||||||
|
## Set up environment
|
||||||
|
|
||||||
|
Some components are necessary to prompt attack experiment, therefore we need to set up environments.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git clone https://github.com/microsoft/promptbench.git
|
||||||
|
pip install textattack==0.3.8
|
||||||
|
export PYTHONPATH=$PYTHONPATH:promptbench/
|
||||||
|
```
|
||||||
|
|
||||||
|
## How to attack
|
||||||
|
|
||||||
|
### Add a dataset config
|
||||||
|
|
||||||
|
We will use GLUE-wnli dataset as example, most configuration settings can refer to [config.md](../user_guides/config.md) for help.
|
||||||
|
|
||||||
|
First we need support the basic dataset config, you can find the existing config files in `configs` or support your own config according to [new-dataset](./new_dataset.md)
|
||||||
|
|
||||||
|
Take the following `infer_cfg` as example, we need to define the prompt template. `adv_prompt` is the basic prompt placeholder to be attacked in the experiment. `sentence1` and `sentence2` are the input columns of this dataset. The attack will only modify the `adv_prompt` here.
|
||||||
|
|
||||||
|
Then, we should use `AttackInferencer` with `original_prompt_list` and `adv_key` to tell the inferencer where to attack and what text to be attacked.
|
||||||
|
|
||||||
|
More details can refer to `configs/datasets/promptbench/promptbench_wnli_gen_50662f.py` config file.
|
||||||
|
|
||||||
|
```python
|
||||||
|
original_prompt_list = [
|
||||||
|
'Are the following two sentences entailment or not_entailment? Answer me with "A. entailment" or "B. not_entailment", just one word. ',
|
||||||
|
"Does the relationship between the given sentences represent entailment or not_entailment? Respond with 'A. entailment' or 'B. not_entailment'.",
|
||||||
|
...,
|
||||||
|
]
|
||||||
|
|
||||||
|
wnli_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(round=[
|
||||||
|
dict(
|
||||||
|
role="HUMAN",
|
||||||
|
prompt="""{adv_prompt}
|
||||||
|
Sentence 1: {sentence1}
|
||||||
|
Sentence 2: {sentence2}
|
||||||
|
Answer:"""),
|
||||||
|
]),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(
|
||||||
|
type=AttackInferencer,
|
||||||
|
original_prompt_list=original_prompt_list,
|
||||||
|
adv_key='adv_prompt'))
|
||||||
|
```
|
||||||
|
|
||||||
|
### Add a eval config
|
||||||
|
|
||||||
|
We should use `OpenICLAttackTask` here for attack task. Also `NaivePartitioner` should be used because the attack experiment will run the whole dataset repeatedly for nearly hurdurds times to search the best attack, we do not want to split the dataset for convenience.
|
||||||
|
|
||||||
|
```note
|
||||||
|
Please choose a small dataset(example < 1000) for attack, due to the aforementioned repeated search, otherwise the time cost is enumerous.
|
||||||
|
```
|
||||||
|
|
||||||
|
There are several other options in `attack` config:
|
||||||
|
|
||||||
|
- `attack`: attack type, available options includes `textfooler`, `textbugger`, `deepwordbug`, `bertattack`, `checklist`, `stresstest`;
|
||||||
|
- `query_budget`: upper boundary of queries, which means the total numbers of running the dataset;
|
||||||
|
- `prompt_topk`: number of topk prompt to be attacked. In most case, the original prompt list is great than 10, running the whole set is time consuming.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Please run whole dataset at a time, aka use `NaivePartitioner` only
|
||||||
|
# Please use `OpenICLAttackTask` if want to perform attack experiment
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=NaivePartitioner),
|
||||||
|
runner=dict(
|
||||||
|
type=SlurmRunner,
|
||||||
|
max_num_workers=8,
|
||||||
|
task=dict(type=OpenICLAttackTask),
|
||||||
|
retry=0),
|
||||||
|
)
|
||||||
|
|
||||||
|
attack = dict(
|
||||||
|
attack='textfooler',
|
||||||
|
query_budget=100,
|
||||||
|
prompt_topk=2,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Run the experiment
|
||||||
|
|
||||||
|
Please use `--mode infer` when run the attack experiment, and set `PYTHONPATH` env.
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py configs/eval_attack.py --mode infer
|
||||||
|
```
|
||||||
|
|
||||||
|
All the results will be saved in `attack` folder.
|
||||||
|
The content includes the original prompt accuracy and the attacked prompt with dropped accuracy of `topk` prompt, for instance:
|
||||||
|
|
||||||
|
```
|
||||||
|
Prompt: Assess the connection between the following sentences and classify it as 'A. entailment' or 'B. not_entailment'., acc: 59.15%
|
||||||
|
Prompt: Does the relationship between the given sentences represent entailment or not_entailment? Respond with 'A. entailment' or 'B. not_entailment'., acc: 57.75%
|
||||||
|
Prompt: Analyze the two provided sentences and decide if their relationship is 'A. entailment' or 'B. not_entailment'., acc: 56.34%
|
||||||
|
Prompt: Identify whether the given pair of sentences demonstrates entailment or not_entailment. Answer with 'A. entailment' or 'B. not_entailment'., acc: 54.93%
|
||||||
|
...
|
||||||
|
Original prompt: Assess the connection between the following sentences and classify it as 'A. entailment' or 'B. not_entailment'.
|
||||||
|
Attacked prompt: b"Assess the attach between the following sentences and sorted it as 'A. entailment' or 'B. not_entailment'."
|
||||||
|
Original acc: 59.15%, attacked acc: 40.85%, dropped acc: 18.31%
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,171 @@
|
||||||
|
# Subjective Evaluation Guidance
|
||||||
|
|
||||||
|
## Introduction
|
||||||
|
|
||||||
|
Subjective evaluation aims to assess the model's performance in tasks that align with human preferences. The key criterion for this evaluation is human preference, but it comes with a high cost of annotation.
|
||||||
|
|
||||||
|
To explore the model's subjective capabilities, we employ JudgeLLM as a substitute for human assessors ([LLM-as-a-Judge](https://arxiv.org/abs/2306.05685)).
|
||||||
|
|
||||||
|
A popular evaluation method involves
|
||||||
|
|
||||||
|
- Compare Mode: comparing model responses pairwise to calculate their win rate
|
||||||
|
- Score Mode: another method involves calculate scores with single model response ([Chatbot Arena](https://chat.lmsys.org/)).
|
||||||
|
|
||||||
|
We support the use of GPT-4 (or other JudgeLLM) for the subjective evaluation of models based on above methods.
|
||||||
|
|
||||||
|
## Currently Supported Subjective Evaluation Datasets
|
||||||
|
|
||||||
|
1. AlignBench Chinese Scoring Dataset (https://github.com/THUDM/AlignBench)
|
||||||
|
2. MTBench English Scoring Dataset, two-turn dialogue (https://github.com/lm-sys/FastChat)
|
||||||
|
3. MTBench101 English Scoring Dataset, multi-turn dialogue (https://github.com/mtbench101/mt-bench-101)
|
||||||
|
4. AlpacaEvalv2 English Compare Dataset (https://github.com/tatsu-lab/alpaca_eval)
|
||||||
|
5. ArenaHard English Compare Dataset, mainly focused on coding (https://github.com/lm-sys/arena-hard/tree/main)
|
||||||
|
6. Fofo English Scoring Dataset (https://github.com/SalesforceAIResearch/FoFo/)
|
||||||
|
7. Wildbench English Score and Compare Dataset(https://github.com/allenai/WildBench)
|
||||||
|
|
||||||
|
## Initiating Subjective Evaluation
|
||||||
|
|
||||||
|
Similar to existing objective evaluation methods, you can configure related settings in `configs/eval_subjective.py`.
|
||||||
|
|
||||||
|
### Basic Parameters: Specifying models, datasets, and judgemodels
|
||||||
|
|
||||||
|
Similar to objective evaluation, import the models and datasets that need to be evaluated, for example:
|
||||||
|
|
||||||
|
```
|
||||||
|
with read_base():
|
||||||
|
from .datasets.subjective.alignbench.alignbench_judgeby_critiquellm import alignbench_datasets
|
||||||
|
from .datasets.subjective.alpaca_eval.alpacav2_judgeby_gpt4 import subjective_datasets as alpacav2
|
||||||
|
from .models.qwen.hf_qwen_7b import models
|
||||||
|
```
|
||||||
|
|
||||||
|
It is worth noting that since the model setup parameters for subjective evaluation are often different from those for objective evaluation, it often requires setting up `do_sample` for inference instead of `greedy`. You can modify the relevant parameters in the configuration file as needed, for example:
|
||||||
|
|
||||||
|
```
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceChatGLM3,
|
||||||
|
abbr='chatglm3-6b-hf2',
|
||||||
|
path='THUDM/chatglm3-6b',
|
||||||
|
tokenizer_path='THUDM/chatglm3-6b',
|
||||||
|
model_kwargs=dict(
|
||||||
|
device_map='auto',
|
||||||
|
trust_remote_code=True,
|
||||||
|
),
|
||||||
|
tokenizer_kwargs=dict(
|
||||||
|
padding_side='left',
|
||||||
|
truncation_side='left',
|
||||||
|
trust_remote_code=True,
|
||||||
|
),
|
||||||
|
generation_kwargs=dict(
|
||||||
|
do_sample=True,
|
||||||
|
),
|
||||||
|
meta_template=api_meta_template,
|
||||||
|
max_out_len=2048,
|
||||||
|
max_seq_len=4096,
|
||||||
|
batch_size=8,
|
||||||
|
run_cfg=dict(num_gpus=1, num_procs=1),
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
The judgemodel is usually set to a powerful model like GPT4, and you can directly enter your API key according to the configuration in the config file, or use a custom model as the judgemodel.
|
||||||
|
|
||||||
|
### Specifying Other Parameters
|
||||||
|
|
||||||
|
In addition to the basic parameters, you can also modify the `infer` and `eval` fields in the config to set a more appropriate partitioning method. The currently supported partitioning methods mainly include three types: NaivePartitioner, SizePartitioner, and NumberWorkPartitioner. You can also specify your own workdir to save related files.
|
||||||
|
|
||||||
|
## Subjective Evaluation with Custom Dataset
|
||||||
|
|
||||||
|
The specific process includes:
|
||||||
|
|
||||||
|
1. Data preparation
|
||||||
|
2. Model response generation
|
||||||
|
3. Evaluate the response with a JudgeLLM
|
||||||
|
4. Generate JudgeLLM's response and calculate the metric
|
||||||
|
|
||||||
|
### Step-1: Data Preparation
|
||||||
|
|
||||||
|
This step requires preparing the dataset file and implementing your own dataset class under `Opencompass/datasets/subjective/`, returning the read data in the format of `list of dict`.
|
||||||
|
|
||||||
|
Actually, you can prepare the data in any format you like (csv, json, jsonl, etc.). However, to make it easier to get started, it is recommended to construct the data according to the format of the existing subjective datasets or according to the following json format.
|
||||||
|
We provide mini test-set for **Compare Mode** and **Score Mode** as below:
|
||||||
|
|
||||||
|
```python
|
||||||
|
###COREV2
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"question": "如果我在空中垂直抛球,球最初向哪个方向行进?",
|
||||||
|
"capability": "知识-社会常识",
|
||||||
|
"others": {
|
||||||
|
"question": "如果我在空中垂直抛球,球最初向哪个方向行进?",
|
||||||
|
"evaluating_guidance": "",
|
||||||
|
"reference_answer": "上"
|
||||||
|
}
|
||||||
|
},...]
|
||||||
|
|
||||||
|
###CreationV0.1
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"question": "请你扮演一个邮件管家,我让你给谁发送什么主题的邮件,你就帮我扩充好邮件正文,并打印在聊天框里。你需要根据我提供的邮件收件人以及邮件主题,来斟酌用词,并使用合适的敬语。现在请给导师发送邮件,询问他是否可以下周三下午15:00进行科研同步会,大约200字。",
|
||||||
|
"capability": "邮件通知",
|
||||||
|
"others": ""
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
The json must includes the following fields:
|
||||||
|
|
||||||
|
- 'question': Question description
|
||||||
|
- 'capability': The capability dimension of the question.
|
||||||
|
- 'others': Other needed information.
|
||||||
|
|
||||||
|
If you want to modify prompt on each single question, you can full some other information into 'others' and construct it.
|
||||||
|
|
||||||
|
### Step-2: Evaluation Configuration(Compare Mode)
|
||||||
|
|
||||||
|
Taking Alignbench as an example, `configs/datasets/subjective/alignbench/alignbench_judgeby_critiquellm.py`:
|
||||||
|
|
||||||
|
1. First, you need to set `subjective_reader_cfg` to receive the relevant fields returned from the custom Dataset class and specify the output fields when saving files.
|
||||||
|
2. Then, you need to specify the root path `data_path` of the dataset and the dataset filename `subjective_all_sets`. If there are multiple sub-files, you can add them to this list.
|
||||||
|
3. Specify `subjective_infer_cfg` and `subjective_eval_cfg` to configure the corresponding inference and evaluation prompts.
|
||||||
|
4. Specify additional information such as `mode` at the corresponding location. Note that the fields required for different subjective datasets may vary.
|
||||||
|
5. Define post-processing and score statistics. For example, the postprocessing function `alignbench_postprocess` located under `opencompass/opencompass/datasets/subjective/alignbench`.
|
||||||
|
|
||||||
|
### Step-3: Launch the Evaluation
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py config/eval_subjective_score.py -r
|
||||||
|
```
|
||||||
|
|
||||||
|
The `-r` parameter allows the reuse of model inference and GPT-4 evaluation results.
|
||||||
|
|
||||||
|
The response of JudgeLLM will be output to `output/.../results/timestamp/xxmodel/xxdataset/.json`.
|
||||||
|
The evaluation report will be output to `output/.../summary/timestamp/report.csv`.
|
||||||
|
|
||||||
|
## Multi-round Subjective Evaluation in OpenCompass
|
||||||
|
|
||||||
|
In OpenCompass, we also support subjective multi-turn dialogue evaluation. For instance, the evaluation of MT-Bench can be referred to in `configs/datasets/subjective/multiround`.
|
||||||
|
|
||||||
|
In the multi-turn dialogue evaluation, you need to organize the data format into the following dialogue structure:
|
||||||
|
|
||||||
|
```
|
||||||
|
"dialogue": [
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "Imagine you are participating in a race with a group of people. If you have just overtaken the second person, what's your current position? Where is the person you just overtook?"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"role": "assistant",
|
||||||
|
"content": ""
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "If the \"second person\" is changed to \"last person\" in the above question, what would the answer be?"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"role": "assistant",
|
||||||
|
"content": ""
|
||||||
|
}
|
||||||
|
],
|
||||||
|
```
|
||||||
|
|
||||||
|
It's important to note that due to the different question types in MTBench having different temperature settings, we need to divide the original data files into three different subsets according to the temperature for separate inference. For different subsets, we can set different temperatures. For specific settings, please refer to `configs\datasets\subjective\multiround\mtbench_single_judge_diff_temp.py`.
|
||||||
|
|
@ -0,0 +1,230 @@
|
||||||
|
# flake8: noqa
|
||||||
|
# Configuration file for the Sphinx documentation builder.
|
||||||
|
#
|
||||||
|
# This file only contains a selection of the most common options. For a full
|
||||||
|
# list see the documentation:
|
||||||
|
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
||||||
|
|
||||||
|
# -- Path setup --------------------------------------------------------------
|
||||||
|
|
||||||
|
# If extensions (or modules to document with autodoc) are in another directory,
|
||||||
|
# add these directories to sys.path here. If the directory is relative to the
|
||||||
|
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
||||||
|
#
|
||||||
|
import os
|
||||||
|
import subprocess
|
||||||
|
import sys
|
||||||
|
|
||||||
|
import pytorch_sphinx_theme
|
||||||
|
from sphinx.builders.html import StandaloneHTMLBuilder
|
||||||
|
|
||||||
|
sys.path.insert(0, os.path.abspath('../../'))
|
||||||
|
|
||||||
|
# -- Project information -----------------------------------------------------
|
||||||
|
|
||||||
|
project = 'OpenCompass'
|
||||||
|
copyright = '2023, OpenCompass'
|
||||||
|
author = 'OpenCompass Authors'
|
||||||
|
|
||||||
|
# The full version, including alpha/beta/rc tags
|
||||||
|
version_file = '../../opencompass/__init__.py'
|
||||||
|
|
||||||
|
|
||||||
|
def get_version():
|
||||||
|
with open(version_file, 'r') as f:
|
||||||
|
exec(compile(f.read(), version_file, 'exec'))
|
||||||
|
return locals()['__version__']
|
||||||
|
|
||||||
|
|
||||||
|
release = get_version()
|
||||||
|
|
||||||
|
# -- General configuration ---------------------------------------------------
|
||||||
|
|
||||||
|
# Add any Sphinx extension module names here, as strings. They can be
|
||||||
|
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
||||||
|
# ones.
|
||||||
|
extensions = [
|
||||||
|
'sphinx.ext.autodoc',
|
||||||
|
'sphinx.ext.autosummary',
|
||||||
|
'sphinx.ext.intersphinx',
|
||||||
|
'sphinx.ext.napoleon',
|
||||||
|
'sphinx.ext.viewcode',
|
||||||
|
'myst_parser',
|
||||||
|
'sphinx_copybutton',
|
||||||
|
'sphinx_tabs.tabs',
|
||||||
|
'notfound.extension',
|
||||||
|
'sphinxcontrib.jquery',
|
||||||
|
'sphinx_design',
|
||||||
|
]
|
||||||
|
|
||||||
|
# Add any paths that contain templates here, relative to this directory.
|
||||||
|
templates_path = ['_templates']
|
||||||
|
|
||||||
|
# The suffix(es) of source filenames.
|
||||||
|
# You can specify multiple suffix as a list of string:
|
||||||
|
#
|
||||||
|
source_suffix = {
|
||||||
|
'.rst': 'restructuredtext',
|
||||||
|
'.md': 'markdown',
|
||||||
|
}
|
||||||
|
|
||||||
|
language = 'en'
|
||||||
|
|
||||||
|
# The master toctree document.
|
||||||
|
root_doc = 'index'
|
||||||
|
|
||||||
|
# List of patterns, relative to source directory, that match files and
|
||||||
|
# directories to ignore when looking for source files.
|
||||||
|
# This pattern also affects html_static_path and html_extra_path.
|
||||||
|
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
||||||
|
|
||||||
|
# -- Options for HTML output -------------------------------------------------
|
||||||
|
|
||||||
|
# The theme to use for HTML and HTML Help pages. See the documentation for
|
||||||
|
# a list of builtin themes.
|
||||||
|
#
|
||||||
|
html_theme = 'pytorch_sphinx_theme'
|
||||||
|
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
||||||
|
|
||||||
|
# Theme options are theme-specific and customize the look and feel of a theme
|
||||||
|
# further. For a list of options available for each theme, see the
|
||||||
|
# documentation.
|
||||||
|
# yapf: disable
|
||||||
|
html_theme_options = {
|
||||||
|
'menu': [
|
||||||
|
{
|
||||||
|
'name': 'GitHub',
|
||||||
|
'url': 'https://github.com/open-compass/opencompass'
|
||||||
|
},
|
||||||
|
],
|
||||||
|
# Specify the language of shared menu
|
||||||
|
'menu_lang': 'en',
|
||||||
|
# Disable the default edit on GitHub
|
||||||
|
'default_edit_on_github': False,
|
||||||
|
}
|
||||||
|
# yapf: enable
|
||||||
|
|
||||||
|
# Add any paths that contain custom static files (such as style sheets) here,
|
||||||
|
# relative to this directory. They are copied after the builtin static files,
|
||||||
|
# so a file named "default.css" will overwrite the builtin "default.css".
|
||||||
|
html_static_path = ['_static']
|
||||||
|
html_css_files = [
|
||||||
|
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.css',
|
||||||
|
'css/readthedocs.css'
|
||||||
|
]
|
||||||
|
html_js_files = [
|
||||||
|
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.js',
|
||||||
|
'js/custom.js'
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Options for HTMLHelp output ---------------------------------------------
|
||||||
|
|
||||||
|
# Output file base name for HTML help builder.
|
||||||
|
htmlhelp_basename = 'opencompassdoc'
|
||||||
|
|
||||||
|
# -- Options for LaTeX output ------------------------------------------------
|
||||||
|
|
||||||
|
latex_elements = {
|
||||||
|
# The paper size ('letterpaper' or 'a4paper').
|
||||||
|
#
|
||||||
|
# 'papersize': 'letterpaper',
|
||||||
|
|
||||||
|
# The font size ('10pt', '11pt' or '12pt').
|
||||||
|
#
|
||||||
|
# 'pointsize': '10pt',
|
||||||
|
|
||||||
|
# Additional stuff for the LaTeX preamble.
|
||||||
|
#
|
||||||
|
# 'preamble': '',
|
||||||
|
}
|
||||||
|
|
||||||
|
# Grouping the document tree into LaTeX files. List of tuples
|
||||||
|
# (source start file, target name, title,
|
||||||
|
# author, documentclass [howto, manual, or own class]).
|
||||||
|
latex_documents = [
|
||||||
|
(root_doc, 'opencompass.tex', 'OpenCompass Documentation', author,
|
||||||
|
'manual'),
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Options for manual page output ------------------------------------------
|
||||||
|
|
||||||
|
# One entry per manual page. List of tuples
|
||||||
|
# (source start file, name, description, authors, manual section).
|
||||||
|
man_pages = [(root_doc, 'opencompass', 'OpenCompass Documentation', [author],
|
||||||
|
1)]
|
||||||
|
|
||||||
|
# -- Options for Texinfo output ----------------------------------------------
|
||||||
|
|
||||||
|
# Grouping the document tree into Texinfo files. List of tuples
|
||||||
|
# (source start file, target name, title, author,
|
||||||
|
# dir menu entry, description, category)
|
||||||
|
texinfo_documents = [
|
||||||
|
(root_doc, 'opencompass', 'OpenCompass Documentation', author,
|
||||||
|
'OpenCompass Authors', 'AGI evaluation toolbox and benchmark.',
|
||||||
|
'Miscellaneous'),
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Options for Epub output -------------------------------------------------
|
||||||
|
|
||||||
|
# Bibliographic Dublin Core info.
|
||||||
|
epub_title = project
|
||||||
|
|
||||||
|
# The unique identifier of the text. This can be a ISBN number
|
||||||
|
# or the project homepage.
|
||||||
|
#
|
||||||
|
# epub_identifier = ''
|
||||||
|
|
||||||
|
# A unique identification for the text.
|
||||||
|
#
|
||||||
|
# epub_uid = ''
|
||||||
|
|
||||||
|
# A list of files that should not be packed into the epub file.
|
||||||
|
epub_exclude_files = ['search.html']
|
||||||
|
|
||||||
|
# set priority when building html
|
||||||
|
StandaloneHTMLBuilder.supported_image_types = [
|
||||||
|
'image/svg+xml', 'image/gif', 'image/png', 'image/jpeg'
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Extension configuration -------------------------------------------------
|
||||||
|
# Ignore >>> when copying code
|
||||||
|
copybutton_prompt_text = r'>>> |\.\.\. '
|
||||||
|
copybutton_prompt_is_regexp = True
|
||||||
|
|
||||||
|
# Auto-generated header anchors
|
||||||
|
myst_heading_anchors = 3
|
||||||
|
# Enable "colon_fence" extension of myst.
|
||||||
|
myst_enable_extensions = ['colon_fence', 'dollarmath']
|
||||||
|
|
||||||
|
# Configuration for intersphinx
|
||||||
|
intersphinx_mapping = {
|
||||||
|
'python': ('https://docs.python.org/3', None),
|
||||||
|
'numpy': ('https://numpy.org/doc/stable', None),
|
||||||
|
'torch': ('https://pytorch.org/docs/stable/', None),
|
||||||
|
'mmengine': ('https://mmengine.readthedocs.io/en/latest/', None),
|
||||||
|
'transformers':
|
||||||
|
('https://huggingface.co/docs/transformers/main/en/', None),
|
||||||
|
}
|
||||||
|
napoleon_custom_sections = [
|
||||||
|
# Custom sections for data elements.
|
||||||
|
('Meta fields', 'params_style'),
|
||||||
|
('Data fields', 'params_style'),
|
||||||
|
]
|
||||||
|
|
||||||
|
# Disable docstring inheritance
|
||||||
|
autodoc_inherit_docstrings = False
|
||||||
|
# Mock some imports during generate API docs.
|
||||||
|
autodoc_mock_imports = ['rich', 'attr', 'einops']
|
||||||
|
# Disable displaying type annotations, these can be very verbose
|
||||||
|
autodoc_typehints = 'none'
|
||||||
|
|
||||||
|
# The not found page
|
||||||
|
notfound_template = '404.html'
|
||||||
|
|
||||||
|
|
||||||
|
def builder_inited_handler(app):
|
||||||
|
subprocess.run(['./statis.py'])
|
||||||
|
|
||||||
|
|
||||||
|
def setup(app):
|
||||||
|
app.connect('builder-inited', builder_inited_handler)
|
||||||
|
|
@ -0,0 +1,2 @@
|
||||||
|
[html writers]
|
||||||
|
table_style: colwidths-auto
|
||||||
|
|
@ -0,0 +1,128 @@
|
||||||
|
# FAQ
|
||||||
|
|
||||||
|
## General
|
||||||
|
|
||||||
|
### What are the differences and connections between `ppl` and `gen`?
|
||||||
|
|
||||||
|
`ppl` stands for perplexity, an index used to evaluate a model's language modeling capabilities. In the context of OpenCompass, it generally refers to a method of answering multiple-choice questions: given a context, the model needs to choose the most appropriate option from multiple choices. In this case, we concatenate the n options with the context to form n sequences, then calculate the model's perplexity for these n sequences. We consider the option corresponding to the sequence with the lowest perplexity as the model's reasoning result for this question. This evaluation method is simple and direct in post-processing, with high certainty.
|
||||||
|
|
||||||
|
`gen` is an abbreviation for generate. In the context of OpenCompass, it refers to the model's continuation writing result given a context as the reasoning result for a question. Generally, the string obtained from continuation writing requires a heavier post-processing process to extract reliable answers and complete the evaluation.
|
||||||
|
|
||||||
|
In terms of usage, multiple-choice questions and some multiple-choice-like questions of the base model use `ppl`, while the base model's multiple-selection and non-multiple-choice questions use `gen`. All questions of the chat model use `gen`, as many commercial API models do not expose the `ppl` interface. However, there are exceptions, such as when we want the base model to output the problem-solving process (e.g., Let's think step by step), we will also use `gen`, but the overall usage is as shown in the following table:
|
||||||
|
|
||||||
|
| | ppl | gen |
|
||||||
|
| ---------- | -------------- | -------------------- |
|
||||||
|
| Base Model | Only MCQ Tasks | Tasks Other Than MCQ |
|
||||||
|
| Chat Model | None | All Tasks |
|
||||||
|
|
||||||
|
Similar to `ppl`, conditional log probability (`clp`) calculates the probability of the next token given a context. It is also only applicable to multiple-choice questions, and the range of probability calculation is limited to the tokens corresponding to the option numbers. The option corresponding to the token with the highest probability is considered the model's reasoning result. Compared to `ppl`, `clp` calculation is more efficient, requiring only one inference, whereas `ppl` requires n inferences. However, the drawback is that `clp` is subject to the tokenizer. For example, the presence or absence of space symbols before and after an option can change the tokenizer's encoding result, leading to unreliable test results. Therefore, `clp` is rarely used in OpenCompass.
|
||||||
|
|
||||||
|
### How does OpenCompass control the number of shots in few-shot evaluations?
|
||||||
|
|
||||||
|
In the dataset configuration file, there is a retriever field indicating how to recall samples from the dataset as context examples. The most commonly used is `FixKRetriever`, which means using a fixed k samples, hence k-shot. There is also `ZeroRetriever`, which means not using any samples, which in most cases implies 0-shot.
|
||||||
|
|
||||||
|
On the other hand, in-context samples can also be directly specified in the dataset template. In this case, `ZeroRetriever` is also used, but the evaluation is not 0-shot and needs to be determined based on the specific template. Refer to [prompt](../prompt/prompt_template.md) for more details
|
||||||
|
|
||||||
|
### How does OpenCompass allocate GPUs?
|
||||||
|
|
||||||
|
OpenCompass processes evaluation requests using the unit termed as "task". Each task is an independent combination of model(s) and dataset(s). The GPU resources needed for a task are determined entirely by the model being evaluated, specifically by the `num_gpus` parameter.
|
||||||
|
|
||||||
|
During evaluation, OpenCompass deploys multiple workers to execute tasks in parallel. These workers continuously try to secure GPU resources and run tasks until they succeed. As a result, OpenCompass always strives to leverage all available GPU resources to their maximum capacity.
|
||||||
|
|
||||||
|
For instance, if you're using OpenCompass on a local machine equipped with 8 GPUs, and each task demands 4 GPUs, then by default, OpenCompass will employ all 8 GPUs to concurrently run 2 tasks. However, if you adjust the `--max-num-workers` setting to 1, then only one task will be processed at a time, utilizing just 4 GPUs.
|
||||||
|
|
||||||
|
### Why doesn't the GPU behavior of HuggingFace models align with my expectations?
|
||||||
|
|
||||||
|
This is a complex issue that needs to be explained from both the supply and demand sides:
|
||||||
|
|
||||||
|
The supply side refers to how many tasks are being run. A task is a combination of a model and a dataset, and it primarily depends on how many models and datasets need to be tested. Additionally, since OpenCompass splits a larger task into multiple smaller tasks, the number of data entries per sub-task (`--max-partition-size`) also affects the number of tasks. (The `--max-partition-size` is proportional to the actual number of data entries, but the relationship is not 1:1).
|
||||||
|
|
||||||
|
The demand side refers to how many workers are running. Since OpenCompass instantiates multiple models for inference simultaneously, we use `--hf-num-gpus` to specify how many GPUs each instance uses. Note that `--hf-num-gpus` is a parameter specific to HuggingFace models and setting this parameter for non-HuggingFace models will not have any effect. We also use `--max-num-workers` to indicate the maximum number of instances running at the same time. Lastly, due to issues like GPU memory and insufficient load, OpenCompass also supports running multiple instances on the same GPU, which is managed by the parameter `--max-num-workers-per-gpu`. Therefore, it can be generally assumed that we will use a total of `--hf-num-gpus` * `--max-num-workers` / `--max-num-workers-per-gpu` GPUs.
|
||||||
|
|
||||||
|
In summary, when tasks run slowly or the GPU load is low, we first need to check if the supply is sufficient. If not, consider reducing `--max-partition-size` to split the tasks into finer parts. Next, we need to check if the demand is sufficient. If not, consider increasing `--max-num-workers` and `--max-num-workers-per-gpu`. Generally, **we set `--hf-num-gpus` to the minimum value that meets the demand and do not adjust it further.**
|
||||||
|
|
||||||
|
### How do I control the number of GPUs that OpenCompass occupies?
|
||||||
|
|
||||||
|
Currently, there isn't a direct method to specify the number of GPUs OpenCompass can utilize. However, the following are some indirect strategies:
|
||||||
|
|
||||||
|
**If evaluating locally:**
|
||||||
|
You can limit OpenCompass's GPU access by setting the `CUDA_VISIBLE_DEVICES` environment variable. For instance, using `CUDA_VISIBLE_DEVICES=0,1,2,3 python run.py ...` will only expose the first four GPUs to OpenCompass, ensuring it uses no more than these four GPUs simultaneously.
|
||||||
|
|
||||||
|
**If using Slurm or DLC:**
|
||||||
|
Although OpenCompass doesn't have direct access to the resource pool, you can adjust the `--max-num-workers` parameter to restrict the number of evaluation tasks being submitted simultaneously. This will indirectly manage the number of GPUs that OpenCompass employs. For instance, if each task requires 4 GPUs, and you wish to allocate a total of 8 GPUs, then you should set `--max-num-workers` to 2.
|
||||||
|
|
||||||
|
### `libGL.so.1` not foune
|
||||||
|
|
||||||
|
opencv-python depends on some dynamic libraries that are not present in the environment. The simplest solution is to uninstall opencv-python and then install opencv-python-headless.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip uninstall opencv-python
|
||||||
|
pip install opencv-python-headless
|
||||||
|
```
|
||||||
|
|
||||||
|
Alternatively, you can install the corresponding dependency libraries according to the error message
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo apt-get update
|
||||||
|
sudo apt-get install -y libgl1 libglib2.0-0
|
||||||
|
```
|
||||||
|
|
||||||
|
## Network
|
||||||
|
|
||||||
|
### My tasks failed with error: `('Connection aborted.', ConnectionResetError(104, 'Connection reset by peer'))` or `urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='cdn-lfs.huggingface.co', port=443)`
|
||||||
|
|
||||||
|
Because of HuggingFace's implementation, OpenCompass requires network (especially the connection to HuggingFace) for the first time it loads some datasets and models. Additionally, it connects to HuggingFace each time it is launched. For a successful run, you may:
|
||||||
|
|
||||||
|
- Work behind a proxy by specifying the environment variables `http_proxy` and `https_proxy`;
|
||||||
|
- Use the cache files from other machines. You may first run the experiment on a machine that has access to the Internet, and then copy the cached files to the offline one. The cached files are located at `~/.cache/huggingface/` by default ([doc](https://huggingface.co/docs/datasets/cache#cache-directory)). When the cached files are ready, you can start the evaluation in offline mode:
|
||||||
|
```python
|
||||||
|
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 HF_EVALUATE_OFFLINE=1 python run.py ...
|
||||||
|
```
|
||||||
|
With which no more network connection is needed for the evaluation. However, error will still be raised if the files any dataset or model is missing from the cache.
|
||||||
|
- Use mirror like [hf-mirror](https://hf-mirror.com/)
|
||||||
|
```python
|
||||||
|
HF_ENDPOINT=https://hf-mirror.com python run.py ...
|
||||||
|
```
|
||||||
|
|
||||||
|
### My server cannot connect to the Internet, how can I use OpenCompass?
|
||||||
|
|
||||||
|
Use the cache files from other machines, as suggested in the answer to [Network-Q1](#my-tasks-failed-with-error-connection-aborted-connectionreseterror104-connection-reset-by-peer-or-urllib3exceptionsmaxretryerror-httpsconnectionpoolhostcdn-lfshuggingfaceco-port443).
|
||||||
|
|
||||||
|
### In evaluation phase, I'm running into an error saying that `FileNotFoundError: Couldn't find a module script at opencompass/accuracy.py. Module 'accuracy' doesn't exist on the Hugging Face Hub either.`
|
||||||
|
|
||||||
|
HuggingFace tries to load the metric (e.g. `accuracy`) as an module online, and it could fail if the network is unreachable. Please refer to [Network-Q1](#my-tasks-failed-with-error-connection-aborted-connectionreseterror104-connection-reset-by-peer-or-urllib3exceptionsmaxretryerror-httpsconnectionpoolhostcdn-lfshuggingfaceco-port443) for guidelines to fix your network issue.
|
||||||
|
|
||||||
|
The issue has been fixed in the latest version of OpenCompass, so you might also consider pull from the latest version.
|
||||||
|
|
||||||
|
## Efficiency
|
||||||
|
|
||||||
|
### Why does OpenCompass partition each evaluation request into tasks?
|
||||||
|
|
||||||
|
Given the extensive evaluation time and the vast quantity of datasets, conducting a comprehensive linear evaluation on LLM models can be immensely time-consuming. To address this, OpenCompass divides the evaluation request into multiple independent "tasks". These tasks are then dispatched to various GPU groups or nodes, achieving full parallelism and maximizing the efficiency of computational resources.
|
||||||
|
|
||||||
|
### How does task partitioning work?
|
||||||
|
|
||||||
|
Each task in OpenCompass represents a combination of specific model(s) and portions of the dataset awaiting evaluation. OpenCompass offers a variety of task partitioning strategies, each tailored for different scenarios. During the inference stage, the prevalent partitioning method seeks to balance task size, or computational cost. This cost is heuristically derived from the dataset size and the type of inference.
|
||||||
|
|
||||||
|
### Why does it take more time to evaluate LLM models on OpenCompass?
|
||||||
|
|
||||||
|
There is a tradeoff between the number of tasks and the time to load the model. For example, if we partition an request that evaluates a model against a dataset into 100 tasks, the model will be loaded 100 times in total. When resources are abundant, these 100 tasks can be executed in parallel, so the additional time spent on model loading can be ignored. However, if resources are limited, these 100 tasks will operate more sequentially, and repeated loadings can become a bottleneck in execution time.
|
||||||
|
|
||||||
|
Hence, if users find that the number of tasks greatly exceeds the available GPUs, we advise setting the `--max-partition-size` to a larger value.
|
||||||
|
|
||||||
|
## Model
|
||||||
|
|
||||||
|
### How to use the downloaded huggingface models?
|
||||||
|
|
||||||
|
If you have already download the checkpoints of the model, you can specify the local path of the model. For example
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --datasets siqa_gen winograd_ppl --hf-type base --hf-path /path/to/model
|
||||||
|
```
|
||||||
|
|
||||||
|
## Dataset
|
||||||
|
|
||||||
|
### How to build a new dataset?
|
||||||
|
|
||||||
|
- For building new objective dataset: [new_dataset](../advanced_guides/new_dataset.md)
|
||||||
|
- For building new subjective dataset: [subjective_evaluation](../advanced_guides/subjective_evaluation.md)
|
||||||
|
|
@ -0,0 +1,141 @@
|
||||||
|
# Installation
|
||||||
|
|
||||||
|
## Basic Installation
|
||||||
|
|
||||||
|
1. Prepare the OpenCompass runtime environment using Conda:
|
||||||
|
|
||||||
|
```conda create --name opencompass python=3.10 -y
|
||||||
|
# conda create --name opencompass_lmdeploy python=3.10 -y
|
||||||
|
|
||||||
|
conda activate opencompass
|
||||||
|
```
|
||||||
|
|
||||||
|
If you want to customize the PyTorch version or related CUDA version, please refer to the [official documentation](https://pytorch.org/get-started/locally/) to set up the PyTorch environment. Note that OpenCompass requires `pytorch>=1.13`.
|
||||||
|
|
||||||
|
2. Install OpenCompass:
|
||||||
|
- pip Installation
|
||||||
|
```bash
|
||||||
|
# For support of most datasets and models
|
||||||
|
pip install -U opencompass
|
||||||
|
|
||||||
|
# Complete installation (supports more datasets)
|
||||||
|
# pip install "opencompass[full]"
|
||||||
|
|
||||||
|
# API Testing (e.g., OpenAI, Qwen)
|
||||||
|
# pip install "opencompass[api]"
|
||||||
|
```
|
||||||
|
- Building from Source Code If you want to use the latest features of OpenCompass
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/open-compass/opencompass opencompass
|
||||||
|
cd opencompass
|
||||||
|
pip install -e .
|
||||||
|
```
|
||||||
|
|
||||||
|
## Other Installations
|
||||||
|
|
||||||
|
### Inference Backends
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Model inference backends. Since these backends often have dependency conflicts,
|
||||||
|
# we recommend using separate virtual environments to manage them.
|
||||||
|
pip install "opencompass[lmdeploy]"
|
||||||
|
# pip install "opencompass[vllm]"
|
||||||
|
```
|
||||||
|
|
||||||
|
- LMDeploy
|
||||||
|
|
||||||
|
You can check if the inference backend has been installed successfully with the following command. For more information, refer to the [official documentation](https://lmdeploy.readthedocs.io/en/latest/get_started.html)
|
||||||
|
|
||||||
|
```bash
|
||||||
|
lmdeploy chat internlm/internlm2_5-1_8b-chat --backend turbomind
|
||||||
|
```
|
||||||
|
|
||||||
|
- vLLM
|
||||||
|
|
||||||
|
You can check if the inference backend has been installed successfully with the following command. For more information, refer to the [official documentation](https://docs.vllm.ai/en/latest/getting_started/quickstart.html)
|
||||||
|
|
||||||
|
```bash
|
||||||
|
vllm serve facebook/opt-125m
|
||||||
|
```
|
||||||
|
|
||||||
|
### API
|
||||||
|
|
||||||
|
OpenCompass supports different commercial model API calls, which you can install via pip or by referring to the [API dependencies](https://github.com/open-compass/opencompass/blob/main/requirements/api.txt) for specific API model dependencies.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install "opencompass[api]"
|
||||||
|
|
||||||
|
# pip install openai # GPT-3.5-Turbo / GPT-4-Turbo / GPT-4 / GPT-4o (API)
|
||||||
|
# pip install anthropic # Claude (API)
|
||||||
|
# pip install dashscope # Qwen (API)
|
||||||
|
# pip install volcengine-python-sdk # ByteDance Volcano Engine (API)
|
||||||
|
# ...
|
||||||
|
```
|
||||||
|
|
||||||
|
### Datasets
|
||||||
|
|
||||||
|
The basic installation supports most fundamental datasets. For certain datasets (e.g., Alpaca-eval, Longbench, etc.), additional dependencies need to be installed.
|
||||||
|
|
||||||
|
You can install these through pip or refer to the [additional dependencies](<(https://github.com/open-compass/opencompass/blob/main/requirements/extra.txt)>) for specific dependencies.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install "opencompass[full]"
|
||||||
|
```
|
||||||
|
|
||||||
|
For HumanEvalX / HumanEval+ / MBPP+, you need to manually clone the Git repository and install it.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone --recurse-submodules git@github.com:open-compass/human-eval.git
|
||||||
|
cd human-eval
|
||||||
|
pip install -e .
|
||||||
|
pip install -e evalplus
|
||||||
|
```
|
||||||
|
|
||||||
|
Some agent evaluations require installing numerous dependencies, which may conflict with existing runtime environments. We recommend creating separate conda environments to manage these.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# T-Eval
|
||||||
|
pip install lagent==0.1.2
|
||||||
|
# CIBench
|
||||||
|
pip install -r requirements/agent.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
# Dataset Preparation
|
||||||
|
|
||||||
|
The datasets supported by OpenCompass mainly include three parts:
|
||||||
|
|
||||||
|
1. Huggingface datasets: The [Huggingface Datasets](https://huggingface.co/datasets) provide a large number of datasets, which will **automatically download** when running with this option.
|
||||||
|
Translate the paragraph into English:
|
||||||
|
|
||||||
|
2. ModelScope Datasets: [ModelScope OpenCompass Dataset](https://modelscope.cn/organization/opencompass) supports automatic downloading of datasets from ModelScope.
|
||||||
|
|
||||||
|
To enable this feature, set the environment variable: `export DATASET_SOURCE=ModelScope`. The available datasets include (sourced from OpenCompassData-core.zip):
|
||||||
|
|
||||||
|
```plain
|
||||||
|
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
|
||||||
|
```
|
||||||
|
|
||||||
|
3. Custom dataset: OpenCompass also provides some Chinese custom **self-built** datasets. Please run the following command to **manually download and extract** them.
|
||||||
|
|
||||||
|
Run the following commands to download and place the datasets in the `${OpenCompass}/data` directory can complete dataset preparation.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Run in the OpenCompass directory
|
||||||
|
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
||||||
|
unzip OpenCompassData-core-20240207.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
If you need to use the more comprehensive dataset (~500M) provided by OpenCompass, You can download and `unzip` it using the following command:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
|
||||||
|
unzip OpenCompassData-complete-20240207.zip
|
||||||
|
cd ./data
|
||||||
|
find . -name "*.zip" -exec unzip "{}" \;
|
||||||
|
```
|
||||||
|
|
||||||
|
The list of datasets included in both `.zip` can be found [here](https://github.com/open-compass/opencompass/releases/tag/0.2.2.rc1)
|
||||||
|
|
||||||
|
OpenCompass has supported most of the datasets commonly used for performance comparison, please refer to `configs/dataset` for the specific list of supported datasets.
|
||||||
|
|
||||||
|
For next step, please read [Quick Start](./quick_start.md).
|
||||||
|
|
@ -0,0 +1,300 @@
|
||||||
|
# Quick Start
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Overview
|
||||||
|
|
||||||
|
OpenCompass provides a streamlined workflow for evaluating a model, which consists of the following stages: **Configure** -> **Inference** -> **Evaluation** -> **Visualization**.
|
||||||
|
|
||||||
|
**Configure**: This is your starting point. Here, you'll set up the entire evaluation process, choosing the model(s) and dataset(s) to assess. You also have the option to select an evaluation strategy, the computation backend, and define how you'd like the results displayed.
|
||||||
|
|
||||||
|
**Inference & Evaluation**: OpenCompass efficiently manages the heavy lifting, conducting parallel inference and evaluation on your chosen model(s) and dataset(s). The **Inference** phase is all about producing outputs from your datasets, whereas the **Evaluation** phase measures how well these outputs align with the gold standard answers. While this procedure is broken down into multiple "tasks" that run concurrently for greater efficiency, be aware that working with limited computational resources might introduce some unexpected overheads, and resulting in generally slower evaluation. To understand this issue and know how to solve it, check out [FAQ: Efficiency](faq.md#efficiency).
|
||||||
|
|
||||||
|
**Visualization**: Once the evaluation is done, OpenCompass collates the results into an easy-to-read table and saves them as both CSV and TXT files. If you need real-time updates, you can activate lark reporting and get immediate status reports in your Lark clients.
|
||||||
|
|
||||||
|
Coming up, we'll walk you through the basics of OpenCompass, showcasing evaluations of pretrained models [OPT-125M](https://huggingface.co/facebook/opt-125m) and [OPT-350M](https://huggingface.co/facebook/opt-350m) on the [SIQA](https://huggingface.co/datasets/social_i_qa) and [Winograd](https://huggingface.co/datasets/winograd_wsc) benchmark tasks. Their configuration files can be found at [configs/eval_demo.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_demo.py).
|
||||||
|
|
||||||
|
Before running this experiment, please make sure you have installed OpenCompass locally and it should run successfully under one _GTX-1660-6G_ GPU.
|
||||||
|
For larger parameterized models like Llama-7B, refer to other examples provided in the [configs directory](https://github.com/open-compass/opencompass/tree/main/configs).
|
||||||
|
|
||||||
|
## Configuring an Evaluation Task
|
||||||
|
|
||||||
|
In OpenCompass, each evaluation task consists of the model to be evaluated and the dataset. The entry point for evaluation is `run.py`. Users can select the model and dataset to be tested either via command line or configuration files.
|
||||||
|
|
||||||
|
`````{tabs}
|
||||||
|
````{tab} Command Line (Custom HF Model)
|
||||||
|
|
||||||
|
For HuggingFace models, users can set model parameters directly through the command line without additional configuration files. For instance, for the `facebook/opt-125m` model, you can evaluate it with the following command:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --datasets siqa_gen winograd_ppl \
|
||||||
|
--hf-type base \
|
||||||
|
--hf-path facebook/opt-125m
|
||||||
|
```
|
||||||
|
|
||||||
|
Note that in this way, OpenCompass only evaluates one model at a time, while other ways can evaluate multiple models at once.
|
||||||
|
|
||||||
|
```{caution}
|
||||||
|
`--hf-num-gpus` does not stand for the actual number of GPUs to use in evaluation, but the minimum required number of GPUs for this model. [More](faq.md#how-does-opencompass-allocate-gpus)
|
||||||
|
```
|
||||||
|
|
||||||
|
:::{dropdown} More detailed example
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
```bash
|
||||||
|
python run.py --datasets siqa_gen winograd_ppl \
|
||||||
|
--hf-type base \ # HuggingFace model type, base or chat
|
||||||
|
--hf-path facebook/opt-125m \ # HuggingFace model path
|
||||||
|
--tokenizer-path facebook/opt-125m \ # HuggingFace tokenizer path (if the same as the model path, can be omitted)
|
||||||
|
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # Arguments to construct the tokenizer
|
||||||
|
--model-kwargs device_map='auto' \ # Arguments to construct the model
|
||||||
|
--max-seq-len 2048 \ # Maximum sequence length the model can accept
|
||||||
|
--max-out-len 100 \ # Maximum number of tokens to generate
|
||||||
|
--min-out-len 100 \ # Minimum number of tokens to generate
|
||||||
|
--batch-size 64 \ # Batch size
|
||||||
|
--hf-num-gpus 1 # Number of GPUs required to run the model
|
||||||
|
```
|
||||||
|
```{seealso}
|
||||||
|
For all HuggingFace related parameters supported by `run.py`, please read [Launching Evaluation Task](../user_guides/experimentation.md#launching-an-evaluation-task).
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
````
|
||||||
|
````{tab} Command Line
|
||||||
|
|
||||||
|
Users can combine the models and datasets they want to test using `--models` and `--datasets`.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --models hf_opt_125m hf_opt_350m --datasets siqa_gen winograd_ppl
|
||||||
|
```
|
||||||
|
|
||||||
|
The models and datasets are pre-stored in the form of configuration files in `configs/models` and `configs/datasets`. Users can view or filter the currently available model and dataset configurations using `tools/list_configs.py`.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# List all configurations
|
||||||
|
python tools/list_configs.py
|
||||||
|
# List all configurations related to llama and mmlu
|
||||||
|
python tools/list_configs.py llama mmlu
|
||||||
|
```
|
||||||
|
|
||||||
|
:::{dropdown} More about `list_configs`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
Running `python tools/list_configs.py llama mmlu` gives the output like:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-----------------+-----------------------------------+
|
||||||
|
| Model | Config Path |
|
||||||
|
|-----------------+-----------------------------------|
|
||||||
|
| hf_llama2_13b | configs/models/hf_llama2_13b.py |
|
||||||
|
| hf_llama2_70b | configs/models/hf_llama2_70b.py |
|
||||||
|
| ... | ... |
|
||||||
|
+-----------------+-----------------------------------+
|
||||||
|
+-------------------+---------------------------------------------------+
|
||||||
|
| Dataset | Config Path |
|
||||||
|
|-------------------+---------------------------------------------------|
|
||||||
|
| cmmlu_gen | configs/datasets/cmmlu/cmmlu_gen.py |
|
||||||
|
| cmmlu_gen_ffe7c0 | configs/datasets/cmmlu/cmmlu_gen_ffe7c0.py |
|
||||||
|
| ... | ... |
|
||||||
|
+-------------------+---------------------------------------------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
Users can use the names in the first column as input parameters for `--models` and `--datasets` in `python run.py`. For datasets, the same name with different suffixes generally indicates that its prompts or evaluation methods are different.
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{dropdown} Model not on the list?
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
If you want to evaluate other models, please check out the "Command Line (Custom HF Model)" tab for the way to construct a custom HF model without a configuration file, or "Configuration File" tab to learn the general way to prepare your model configurations.
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
````
|
||||||
|
|
||||||
|
````{tab} Configuration File
|
||||||
|
|
||||||
|
In addition to configuring the experiment through the command line, OpenCompass also allows users to write the full configuration of the experiment in a configuration file and run it directly through `run.py`. The configuration file is organized in Python format and must include the `datasets` and `models` fields.
|
||||||
|
|
||||||
|
The test configuration for this time is [configs/eval_demo.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_demo.py). This configuration introduces the required dataset and model configurations through the [inheritance mechanism](../user_guides/config.md#inheritance-mechanism) and combines the `datasets` and `models` fields in the required format.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.siqa.siqa_gen import siqa_datasets
|
||||||
|
from .datasets.winograd.winograd_ppl import winograd_datasets
|
||||||
|
from .models.opt.hf_opt_125m import opt125m
|
||||||
|
from .models.opt.hf_opt_350m import opt350m
|
||||||
|
|
||||||
|
datasets = [*siqa_datasets, *winograd_datasets]
|
||||||
|
models = [opt125m, opt350m]
|
||||||
|
```
|
||||||
|
|
||||||
|
When running tasks, we just need to pass the path of the configuration file to `run.py`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_demo.py
|
||||||
|
```
|
||||||
|
|
||||||
|
:::{dropdown} More about `models`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
OpenCompass provides a series of pre-defined model configurations under `configs/models`. Below is the configuration snippet related to [opt-350m](https://github.com/open-compass/opencompass/blob/main/configs/models/opt/hf_opt_350m.py) (`configs/models/opt/hf_opt_350m.py`):
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Evaluate models supported by HuggingFace's `AutoModelForCausalLM` using `HuggingFaceBaseModel`
|
||||||
|
from opencompass.models import HuggingFaceBaseModel
|
||||||
|
|
||||||
|
models = [
|
||||||
|
# OPT-350M
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceBaseModel,
|
||||||
|
# Initialization parameters for `HuggingFaceBaseModel`
|
||||||
|
path='facebook/opt-350m',
|
||||||
|
# Below are common parameters for all models, not specific to HuggingFaceBaseModel
|
||||||
|
abbr='opt-350m-hf', # Model abbreviation
|
||||||
|
max_out_len=1024, # Maximum number of generated tokens
|
||||||
|
batch_size=32, # Batch size
|
||||||
|
run_cfg=dict(num_gpus=1), # The required GPU numbers for this model
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
When using configurations, we can specify the relevant files through the command-line argument ` --models` or import the model configurations into the `models` list in the configuration file using the inheritance mechanism.
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
More information about model configuration can be found in [Prepare Models](../user_guides/models.md).
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{dropdown} More about `datasets`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
Similar to models, dataset configuration files are provided under `configs/datasets`. Users can use `--datasets` in the command line or import related configurations in the configuration file via inheritance
|
||||||
|
|
||||||
|
Below is a dataset-related configuration snippet from `configs/eval_demo.py`:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base # Use mmengine.read_base() to read the base configuration
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# Directly read the required dataset configurations from the preset dataset configurations
|
||||||
|
from .datasets.winograd.winograd_ppl import winograd_datasets # Read Winograd configuration, evaluated based on PPL (perplexity)
|
||||||
|
from .datasets.siqa.siqa_gen import siqa_datasets # Read SIQA configuration, evaluated based on generation
|
||||||
|
|
||||||
|
datasets = [*siqa_datasets, *winograd_datasets] # The final config needs to contain the required evaluation dataset list 'datasets'
|
||||||
|
```
|
||||||
|
|
||||||
|
Dataset configurations are typically of two types: 'ppl' and 'gen', indicating the evaluation method used. Where `ppl` means discriminative evaluation and `gen` means generative evaluation.
|
||||||
|
|
||||||
|
Moreover, [configs/datasets/collections](https://github.com/open-compass/opencompass/blob/main/configs/datasets/collections) houses various dataset collections, making it convenient for comprehensive evaluations. OpenCompass often uses [`base_medium.py`](/configs/datasets/collections/base_medium.py) for full-scale model testing. To replicate results, simply import that file, for example:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --models hf_llama_7b --datasets base_medium
|
||||||
|
```
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
You can find more information from [Dataset Preparation](../user_guides/datasets.md).
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
|
||||||
|
````
|
||||||
|
|
||||||
|
`````
|
||||||
|
|
||||||
|
```{warning}
|
||||||
|
OpenCompass usually assumes network is available. If you encounter network issues or wish to run OpenCompass in an offline environment, please refer to [FAQ - Network - Q1](./faq.md#network) for solutions.
|
||||||
|
```
|
||||||
|
|
||||||
|
The following sections will use configuration-based method as an example to explain the other features.
|
||||||
|
|
||||||
|
## Launching Evaluation
|
||||||
|
|
||||||
|
Since OpenCompass launches evaluation processes in parallel by default, we can start the evaluation in `--debug` mode for the first run and check if there is any problem. In `--debug` mode, the tasks will be executed sequentially and output will be printed in real time.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_demo.py -w outputs/demo --debug
|
||||||
|
```
|
||||||
|
|
||||||
|
The pretrained models 'facebook/opt-350m' and 'facebook/opt-125m' will be automatically downloaded from HuggingFace during the first run.
|
||||||
|
If everything is fine, you should see "Starting inference process" on screen:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
[2023-07-12 18:23:55,076] [opencompass.openicl.icl_inferencer.icl_gen_inferencer] [INFO] Starting inference process...
|
||||||
|
```
|
||||||
|
|
||||||
|
Then you can press `ctrl+c` to interrupt the program, and run the following command in normal mode:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_demo.py -w outputs/demo
|
||||||
|
```
|
||||||
|
|
||||||
|
In normal mode, the evaluation tasks will be executed parallelly in the background, and their output will be redirected to the output directory `outputs/demo/{TIMESTAMP}`. The progress bar on the frontend only indicates the number of completed tasks, regardless of their success or failure. **Any backend task failures will only trigger a warning message in the terminal.**
|
||||||
|
|
||||||
|
:::{dropdown} More parameters in `run.py`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
Here are some parameters related to evaluation that can help you configure more efficient inference tasks based on your environment:
|
||||||
|
|
||||||
|
- `-w outputs/demo`: Work directory to save evaluation logs and results. In this case, the experiment result will be saved to `outputs/demo/{TIMESTAMP}`.
|
||||||
|
- `-r`: Reuse existing inference results, and skip the finished tasks. If followed by a timestamp, the result under that timestamp in the workspace path will be reused; otherwise, the latest result in the specified workspace path will be reused.
|
||||||
|
- `--mode all`: Specify a specific stage of the task.
|
||||||
|
- all: (Default) Perform a complete evaluation, including inference and evaluation.
|
||||||
|
- infer: Perform inference on each dataset.
|
||||||
|
- eval: Perform evaluation based on the inference results.
|
||||||
|
- viz: Display evaluation results only.
|
||||||
|
- `--max-partition-size 2000`: Dataset partition size. Some datasets may be large, and using this parameter can split them into multiple sub-tasks to efficiently utilize resources. However, if the partition is too fine, the overall speed may be slower due to longer model loading times.
|
||||||
|
- `--max-num-workers 32`: Maximum number of parallel tasks. In distributed environments such as Slurm, this parameter specifies the maximum number of submitted tasks. In a local environment, it specifies the maximum number of tasks executed in parallel. Note that the actual number of parallel tasks depends on the available GPU resources and may not be equal to this number.
|
||||||
|
|
||||||
|
If you are not performing the evaluation on your local machine but using a Slurm cluster, you can specify the following parameters:
|
||||||
|
|
||||||
|
- `--slurm`: Submit tasks using Slurm on the cluster.
|
||||||
|
- `--partition(-p) my_part`: Slurm cluster partition.
|
||||||
|
- `--retry 2`: Number of retries for failed tasks.
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
The entry also supports submitting tasks to Alibaba Deep Learning Center (DLC), and more customized evaluation strategies. Please refer to [Launching an Evaluation Task](../user_guides/experimentation.md#launching-an-evaluation-task) for details.
|
||||||
|
```
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Visualizing Evaluation Results
|
||||||
|
|
||||||
|
After the evaluation is complete, the evaluation results table will be printed as follows:
|
||||||
|
|
||||||
|
```text
|
||||||
|
dataset version metric mode opt350m opt125m
|
||||||
|
--------- --------- -------- ------ --------- ---------
|
||||||
|
siqa e78df3 accuracy gen 21.55 12.44
|
||||||
|
winograd b6c7ed accuracy ppl 51.23 49.82
|
||||||
|
```
|
||||||
|
|
||||||
|
All run outputs will be directed to `outputs/demo/` directory with following structure:
|
||||||
|
|
||||||
|
```text
|
||||||
|
outputs/default/
|
||||||
|
├── 20200220_120000
|
||||||
|
├── 20230220_183030 # one experiment pre folder
|
||||||
|
│ ├── configs # Dumped config files for record. Multiple configs may be kept if different experiments have been re-run on the same experiment folder
|
||||||
|
│ ├── logs # log files for both inference and evaluation stages
|
||||||
|
│ │ ├── eval
|
||||||
|
│ │ └── infer
|
||||||
|
│ ├── predictions # Prediction results for each task
|
||||||
|
│ ├── results # Evaluation results for each task
|
||||||
|
│ └── summary # Summarized evaluation results for a single experiment
|
||||||
|
├── ...
|
||||||
|
```
|
||||||
|
|
||||||
|
The summarization process can be further customized in configuration and output the averaged score of some benchmarks (MMLU, C-Eval, etc.).
|
||||||
|
|
||||||
|
More information about obtaining evaluation results can be found in [Results Summary](../user_guides/summarizer.md).
|
||||||
|
|
||||||
|
## Additional Tutorials
|
||||||
|
|
||||||
|
To learn more about using OpenCompass, explore the following tutorials:
|
||||||
|
|
||||||
|
- [Prepare Datasets](../user_guides/datasets.md)
|
||||||
|
- [Prepare Models](../user_guides/models.md)
|
||||||
|
- [Task Execution and Monitoring](../user_guides/experimentation.md)
|
||||||
|
- [Understand Prompts](../prompt/overview.md)
|
||||||
|
- [Results Summary](../user_guides/summarizer.md)
|
||||||
|
- [Learn about Config](../user_guides/config.md)
|
||||||
|
|
@ -0,0 +1,97 @@
|
||||||
|
Welcome to OpenCompass' documentation!
|
||||||
|
==========================================
|
||||||
|
|
||||||
|
Getting started with OpenCompass
|
||||||
|
-------------------------------
|
||||||
|
|
||||||
|
To help you quickly familiarized with OpenCompass, we recommend you to walk through the following documents in order:
|
||||||
|
|
||||||
|
- First read the GetStarted_ section set up the environment, and run a mini experiment.
|
||||||
|
|
||||||
|
- Then learn its basic usage through the UserGuides_.
|
||||||
|
|
||||||
|
- If you want to tune the prompts, refer to the Prompt_.
|
||||||
|
|
||||||
|
- If you want to customize some modules, like adding a new dataset or model, we have provided the AdvancedGuides_.
|
||||||
|
|
||||||
|
- There are more handy tools, such as prompt viewer and lark bot reporter, all presented in Tools_.
|
||||||
|
|
||||||
|
We always welcome *PRs* and *Issues* for the betterment of OpenCompass.
|
||||||
|
|
||||||
|
.. _GetStarted:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: Get Started
|
||||||
|
|
||||||
|
get_started/installation.md
|
||||||
|
get_started/quick_start.md
|
||||||
|
get_started/faq.md
|
||||||
|
|
||||||
|
.. _UserGuides:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: User Guides
|
||||||
|
|
||||||
|
user_guides/framework_overview.md
|
||||||
|
user_guides/config.md
|
||||||
|
user_guides/datasets.md
|
||||||
|
user_guides/models.md
|
||||||
|
user_guides/evaluation.md
|
||||||
|
user_guides/experimentation.md
|
||||||
|
user_guides/metrics.md
|
||||||
|
user_guides/deepseek_r1.md
|
||||||
|
|
||||||
|
.. _Prompt:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: Prompt
|
||||||
|
|
||||||
|
prompt/overview.md
|
||||||
|
prompt/prompt_template.md
|
||||||
|
prompt/meta_template.md
|
||||||
|
prompt/chain_of_thought.md
|
||||||
|
|
||||||
|
|
||||||
|
.. _AdvancedGuides:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: Advanced Guides
|
||||||
|
|
||||||
|
advanced_guides/new_dataset.md
|
||||||
|
advanced_guides/custom_dataset.md
|
||||||
|
advanced_guides/new_model.md
|
||||||
|
advanced_guides/evaluation_lmdeploy.md
|
||||||
|
advanced_guides/accelerator_intro.md
|
||||||
|
advanced_guides/math_verify.md
|
||||||
|
advanced_guides/llm_judge.md
|
||||||
|
advanced_guides/code_eval.md
|
||||||
|
advanced_guides/code_eval_service.md
|
||||||
|
advanced_guides/subjective_evaluation.md
|
||||||
|
advanced_guides/persistence.md
|
||||||
|
|
||||||
|
.. _Tools:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: Tools
|
||||||
|
|
||||||
|
tools.md
|
||||||
|
|
||||||
|
.. _Dataset List:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: Dataset List
|
||||||
|
|
||||||
|
dataset_statistics.md
|
||||||
|
|
||||||
|
.. _Notes:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: Notes
|
||||||
|
|
||||||
|
notes/contribution_guide.md
|
||||||
|
|
||||||
|
Indexes & Tables
|
||||||
|
==================
|
||||||
|
|
||||||
|
* :ref:`genindex`
|
||||||
|
* :ref:`search`
|
||||||
|
|
@ -0,0 +1,158 @@
|
||||||
|
# Contributing to OpenCompass
|
||||||
|
|
||||||
|
- [Contributing to OpenCompass](#contributing-to-opencompass)
|
||||||
|
- [What is PR](#what-is-pr)
|
||||||
|
- [Basic Workflow](#basic-workflow)
|
||||||
|
- [Procedures in detail](#procedures-in-detail)
|
||||||
|
- [1. Get the most recent codebase](#1-get-the-most-recent-codebase)
|
||||||
|
- [2. Checkout a new branch from `main` branch](#2-checkout-a-new-branch-from-main-branch)
|
||||||
|
- [3. Commit your changes](#3-commit-your-changes)
|
||||||
|
- [4. Push your changes to the forked repository and create a PR](#4-push-your-changes-to-the-forked-repository-and-create-a-pr)
|
||||||
|
- [5. Discuss and review your code](#5-discuss-and-review-your-code)
|
||||||
|
- [6. Merge your branch to `main` branch and delete the branch](#6--merge-your-branch-to-main-branch-and-delete-the-branch)
|
||||||
|
- [Code style](#code-style)
|
||||||
|
- [Python](#python)
|
||||||
|
- [About Contributing Test Datasets](#about-contributing-test-datasets)
|
||||||
|
|
||||||
|
Thanks for your interest in contributing to OpenCompass! All kinds of contributions are welcome, including but not limited to the following.
|
||||||
|
|
||||||
|
- Fix typo or bugs
|
||||||
|
- Add documentation or translate the documentation into other languages
|
||||||
|
- Add new features and components
|
||||||
|
|
||||||
|
## What is PR
|
||||||
|
|
||||||
|
`PR` is the abbreviation of `Pull Request`. Here's the definition of `PR` in the [official document](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/about-pull-requests) of Github.
|
||||||
|
|
||||||
|
```
|
||||||
|
Pull requests let you tell others about changes you have pushed to a branch in a repository on GitHub. Once a pull request is opened, you can discuss and review the potential changes with collaborators and add follow-up commits before your changes are merged into the base branch.
|
||||||
|
```
|
||||||
|
|
||||||
|
## Basic Workflow
|
||||||
|
|
||||||
|
1. Get the most recent codebase
|
||||||
|
2. Checkout a new branch from `main` branch.
|
||||||
|
3. Commit your changes ([Don't forget to use pre-commit hooks!](#3-commit-your-changes))
|
||||||
|
4. Push your changes and create a PR
|
||||||
|
5. Discuss and review your code
|
||||||
|
6. Merge your branch to `main` branch
|
||||||
|
|
||||||
|
## Procedures in detail
|
||||||
|
|
||||||
|
### 1. Get the most recent codebase
|
||||||
|
|
||||||
|
- When you work on your first PR
|
||||||
|
|
||||||
|
Fork the OpenCompass repository: click the **fork** button at the top right corner of Github page
|
||||||
|

|
||||||
|
|
||||||
|
Clone forked repository to local
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone git@github.com:XXX/opencompass.git
|
||||||
|
```
|
||||||
|
|
||||||
|
Add source repository to upstream
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git remote add upstream git@github.com:InternLM/opencompass.git
|
||||||
|
```
|
||||||
|
|
||||||
|
- After your first PR
|
||||||
|
|
||||||
|
Checkout the latest branch of the local repository and pull the latest branch of the source repository.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git checkout main
|
||||||
|
git pull upstream main
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. Checkout a new branch from `main` branch
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git checkout main -b branchname
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3. Commit your changes
|
||||||
|
|
||||||
|
- If you are a first-time contributor, please install and initialize pre-commit hooks from the repository root directory first.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -U pre-commit
|
||||||
|
pre-commit install
|
||||||
|
```
|
||||||
|
|
||||||
|
- Commit your changes as usual. Pre-commit hooks will be triggered to stylize your code before each commit.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# coding
|
||||||
|
git add [files]
|
||||||
|
git commit -m 'messages'
|
||||||
|
```
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
Sometimes your code may be changed by pre-commit hooks. In this case, please remember to re-stage the modified files and commit again.
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4. Push your changes to the forked repository and create a PR
|
||||||
|
|
||||||
|
- Push the branch to your forked remote repository
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git push origin branchname
|
||||||
|
```
|
||||||
|
|
||||||
|
- Create a PR
|
||||||
|

|
||||||
|
|
||||||
|
- Revise PR message template to describe your motivation and modifications made in this PR. You can also link the related issue to the PR manually in the PR message (For more information, checkout the [official guidance](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue)).
|
||||||
|
|
||||||
|
- You can also ask a specific person to review the changes you've proposed.
|
||||||
|
|
||||||
|
### 5. Discuss and review your code
|
||||||
|
|
||||||
|
- Modify your codes according to reviewers' suggestions and then push your changes.
|
||||||
|
|
||||||
|
### 6. Merge your branch to `main` branch and delete the branch
|
||||||
|
|
||||||
|
- After the PR is merged by the maintainer, you can delete the branch you created in your forked repository.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git branch -d branchname # delete local branch
|
||||||
|
git push origin --delete branchname # delete remote branch
|
||||||
|
```
|
||||||
|
|
||||||
|
## Code style
|
||||||
|
|
||||||
|
### Python
|
||||||
|
|
||||||
|
We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
|
||||||
|
|
||||||
|
We use the following tools for linting and formatting:
|
||||||
|
|
||||||
|
- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
|
||||||
|
- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
|
||||||
|
- [yapf](https://github.com/google/yapf): A formatter for Python files.
|
||||||
|
- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
|
||||||
|
- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
|
||||||
|
- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
|
||||||
|
|
||||||
|
Style configurations of yapf and isort can be found in [setup.cfg](https://github.com/open-mmlab/OpenCompass/blob/main/setup.cfg).
|
||||||
|
|
||||||
|
## About Contributing Test Datasets
|
||||||
|
|
||||||
|
- Submitting Test Datasets
|
||||||
|
- Please implement logic for automatic dataset downloading in the code; or provide a method for obtaining the dataset in the PR. The OpenCompass maintainers will follow up accordingly. If the dataset is not yet public, please indicate so.
|
||||||
|
- Submitting Data Configuration Files
|
||||||
|
- Provide a README in the same directory as the data configuration. The README should include, but is not limited to:
|
||||||
|
- A brief description of the dataset
|
||||||
|
- The official link to the dataset
|
||||||
|
- Some test examples from the dataset
|
||||||
|
- Evaluation results of the dataset on relevant models
|
||||||
|
- Citation of the dataset
|
||||||
|
- (Optional) Summarizer of the dataset
|
||||||
|
- (Optional) If the testing process cannot be achieved simply by concatenating the dataset and model configuration files, a configuration file for conducting the test is also required.
|
||||||
|
- (Optional) If necessary, please add a description of the dataset in the relevant documentation sections. This is very necessary to help users understand the testing scheme. You can refer to the following types of documents in OpenCompass:
|
||||||
|
- [Circular Evaluation](../advanced_guides/circular_eval.md)
|
||||||
|
- [Code Evaluation](../advanced_guides/code_eval.md)
|
||||||
|
- [Contamination Assessment](../advanced_guides/contamination_eval.md)
|
||||||
|
|
@ -0,0 +1,40 @@
|
||||||
|
# News
|
||||||
|
|
||||||
|
- **\[2024.05.08\]** We supported the evaluation of 4 MoE models: [Mixtral-8x22B-v0.1](configs/models/mixtral/hf_mixtral_8x22b_v0_1.py), [Mixtral-8x22B-Instruct-v0.1](configs/models/mixtral/hf_mixtral_8x22b_instruct_v0_1.py), [Qwen1.5-MoE-A2.7B](configs/models/qwen/hf_qwen1_5_moe_a2_7b.py), [Qwen1.5-MoE-A2.7B-Chat](configs/models/qwen/hf_qwen1_5_moe_a2_7b_chat.py). Try them out now!
|
||||||
|
- **\[2024.04.30\]** We supported evaluating a model's compression efficiency by calculating its Bits per Character (BPC) metric on an [external corpora](configs/datasets/llm_compression/README.md) ([official paper](https://github.com/hkust-nlp/llm-compression-intelligence)). Check out the [llm-compression](configs/eval_llm_compression.py) evaluation config now! 🔥🔥🔥
|
||||||
|
- **\[2024.04.29\]** We report the performance of several famous LLMs on the common benchmarks, welcome to [documentation](https://opencompass.readthedocs.io/en/latest/user_guides/corebench.html) for more information! 🔥🔥🔥.
|
||||||
|
- **\[2024.04.26\]** We deprecated the multi-madality evaluating function from OpenCompass, related implement has moved to [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), welcome to use! 🔥🔥🔥.
|
||||||
|
- **\[2024.04.26\]** We supported the evaluation of [ArenaHard](configs/eval_subjective_arena_hard.py) welcome to try!🔥🔥🔥.
|
||||||
|
- **\[2024.04.22\]** We supported the evaluation of [LLaMA3](configs/models/hf_llama/hf_llama3_8b.py) 和 [LLaMA3-Instruct](configs/models/hf_llama/hf_llama3_8b_instruct.py), welcome to try! 🔥🔥🔥
|
||||||
|
- **\[2024.02.29\]** We supported the MT-Bench, AlpacalEval and AlignBench, more information can be found [here](https://opencompass.readthedocs.io/en/latest/advanced_guides/subjective_evaluation.html)
|
||||||
|
- **\[2024.01.30\]** We release OpenCompass 2.0. Click [CompassKit](https://github.com/open-compass), [CompassHub](https://hub.opencompass.org.cn/home), and [CompassRank](https://rank.opencompass.org.cn/home) for more information !
|
||||||
|
- **\[2024.01.17\]** We supported the evaluation of [InternLM2](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_keyset.py) and [InternLM2-Chat](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py), InternLM2 showed extremely strong performance in these tests, welcome to try!
|
||||||
|
- **\[2024.01.17\]** We supported the needle in a haystack test with multiple needles, more information can be found [here](https://opencompass.readthedocs.io/en/latest/advanced_guides/needleinahaystack_eval.html#id8).
|
||||||
|
- **\[2023.12.28\]** We have enabled seamless evaluation of all models developed using [LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory), a powerful toolkit for comprehensive LLM development.
|
||||||
|
- **\[2023.12.22\]** We have released [T-Eval](https://github.com/open-compass/T-Eval), a step-by-step evaluation benchmark to gauge your LLMs on tool utilization. Welcome to our [Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html) for more details!
|
||||||
|
- **\[2023.12.10\]** We have released [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), a toolkit for evaluating vision-language models (VLMs), currently support 20+ VLMs and 7 multi-modal benchmarks (including MMBench series).
|
||||||
|
- **\[2023.12.10\]** We have supported Mistral AI's MoE LLM: **Mixtral-8x7B-32K**. Welcome to [MixtralKit](https://github.com/open-compass/MixtralKit) for more details about inference and evaluation.
|
||||||
|
- **\[2023.11.22\]** We have supported many API-based models, include **Baidu, ByteDance, Huawei, 360**. Welcome to [Models](https://opencompass.readthedocs.io/en/latest/user_guides/models.html) section for more details.
|
||||||
|
- **\[2023.11.20\]** Thanks [helloyongyang](https://github.com/helloyongyang) for supporting the evaluation with [LightLLM](https://github.com/ModelTC/lightllm) as backent. Welcome to [Evaluation With LightLLM](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_lightllm.html) for more details.
|
||||||
|
- **\[2023.11.13\]** We are delighted to announce the release of OpenCompass v0.1.8. This version enables local loading of evaluation benchmarks, thereby eliminating the need for an internet connection. Please note that with this update, **you must re-download all evaluation datasets** to ensure accurate and up-to-date results.
|
||||||
|
- **\[2023.11.06\]** We have supported several API-based models, include **ChatGLM Pro@Zhipu, ABAB-Chat@MiniMax and Xunfei**. Welcome to [Models](https://opencompass.readthedocs.io/en/latest/user_guides/models.html) section for more details.
|
||||||
|
- **\[2023.10.24\]** We release a new benchmark for evaluating LLMs’ capabilities of having multi-turn dialogues. Welcome to [BotChat](https://github.com/open-compass/BotChat) for more details.
|
||||||
|
- **\[2023.09.26\]** We update the leaderboard with [Qwen](https://github.com/QwenLM/Qwen), one of the best-performing open-source models currently available, welcome to our [homepage](https://opencompass.org.cn) for more details.
|
||||||
|
- **\[2023.09.20\]** We update the leaderboard with [InternLM-20B](https://github.com/InternLM/InternLM), welcome to our [homepage](https://opencompass.org.cn) for more details.
|
||||||
|
- **\[2023.09.19\]** We update the leaderboard with WeMix-LLaMA2-70B/Phi-1.5-1.3B, welcome to our [homepage](https://opencompass.org.cn) for more details.
|
||||||
|
- **\[2023.09.18\]** We have released [long context evaluation guidance](docs/en/advanced_guides/longeval.md).
|
||||||
|
- **\[2023.09.08\]** We update the leaderboard with Baichuan-2/Tigerbot-2/Vicuna-v1.5, welcome to our [homepage](https://opencompass.org.cn) for more details.
|
||||||
|
- **\[2023.09.06\]** [**Baichuan2**](https://github.com/baichuan-inc/Baichuan2) team adpots OpenCompass to evaluate their models systematically. We deeply appreciate the community's dedication to transparency and reproducibility in LLM evaluation.
|
||||||
|
- **\[2023.09.02\]** We have supported the evaluation of [Qwen-VL](https://github.com/QwenLM/Qwen-VL) in OpenCompass.
|
||||||
|
- **\[2023.08.25\]** [**TigerBot**](https://github.com/TigerResearch/TigerBot) team adpots OpenCompass to evaluate their models systematically. We deeply appreciate the community's dedication to transparency and reproducibility in LLM evaluation.
|
||||||
|
- **\[2023.08.21\]** [**Lagent**](https://github.com/InternLM/lagent) has been released, which is a lightweight framework for building LLM-based agents. We are working with Lagent team to support the evaluation of general tool-use capability, stay tuned!
|
||||||
|
- **\[2023.08.18\]** We have supported evaluation for **multi-modality learning**, include **MMBench, SEED-Bench, COCO-Caption, Flickr-30K, OCR-VQA, ScienceQA** and so on. Leaderboard is on the road. Feel free to try multi-modality evaluation with OpenCompass !
|
||||||
|
- **\[2023.08.18\]** [Dataset card](https://opencompass.org.cn/dataset-detail/MMLU) is now online. Welcome new evaluation benchmark OpenCompass !
|
||||||
|
- **\[2023.08.11\]** [Model comparison](https://opencompass.org.cn/model-compare/GPT-4,ChatGPT,LLaMA-2-70B,LLaMA-65B) is now online. We hope this feature offers deeper insights!
|
||||||
|
- **\[2023.08.11\]** We have supported [LEval](https://github.com/OpenLMLab/LEval).
|
||||||
|
- **\[2023.08.10\]** OpenCompass is compatible with [LMDeploy](https://github.com/InternLM/lmdeploy). Now you can follow this [instruction](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_lmdeploy.html#) to evaluate the accelerated models provide by the **Turbomind**.
|
||||||
|
- **\[2023.08.10\]** We have supported [Qwen-7B](https://github.com/QwenLM/Qwen-7B) and [XVERSE-13B](https://github.com/xverse-ai/XVERSE-13B) ! Go to our [leaderboard](https://opencompass.org.cn/leaderboard-llm) for more results! More models are welcome to join OpenCompass.
|
||||||
|
- **\[2023.08.09\]** Several new datasets(**CMMLU, TydiQA, SQuAD2.0, DROP**) are updated on our [leaderboard](https://opencompass.org.cn/leaderboard-llm)! More datasets are welcomed to join OpenCompass.
|
||||||
|
- **\[2023.08.07\]** We have added a [script](tools/eval_mmbench.py) for users to evaluate the inference results of [MMBench](https://opencompass.org.cn/MMBench)-dev.
|
||||||
|
- **\[2023.08.05\]** We have supported [GPT-4](https://openai.com/gpt-4)! Go to our [leaderboard](https://opencompass.org.cn/leaderboard-llm) for more results! More models are welcome to join OpenCompass.
|
||||||
|
- **\[2023.07.27\]** We have supported [CMMLU](https://github.com/haonan-li/CMMLU)! More datasets are welcome to join OpenCompass.
|
||||||
|
|
@ -0,0 +1,127 @@
|
||||||
|
# Chain of Thought
|
||||||
|
|
||||||
|
## Background
|
||||||
|
|
||||||
|
During the process of reasoning, CoT (Chain of Thought) method is an efficient way to help LLMs deal complex questions, for example: math problem and relation inference. In OpenCompass, we support multiple types of CoT method.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 1. Zero Shot CoT
|
||||||
|
|
||||||
|
You can change the `PromptTemplate` of the dataset config, by simply add *Let's think step by step* to realize a Zero-Shot CoT prompt for your evaluation:
|
||||||
|
|
||||||
|
```python
|
||||||
|
qa_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template="Answer the question:\nQ: {question}?\nLet's think step by step:\n"
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 2. Few Shot CoT
|
||||||
|
|
||||||
|
Few-shot CoT can make LLMs easy to follow your instructions and get better answers. For few-shot CoT, add your CoT template to `PromptTemplate` like following config to create a one-shot prompt:
|
||||||
|
|
||||||
|
```python
|
||||||
|
qa_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=
|
||||||
|
'''Question: Mark's basketball team scores 25 2 pointers, 8 3 pointers and 10 free throws. Their opponents score double the 2 pointers but half the 3 pointers and free throws. What's the total number of points scored by both teams added together?
|
||||||
|
Let's think step by step
|
||||||
|
Answer:
|
||||||
|
Mark's team scores 25 2 pointers, meaning they scored 25*2= 50 points in 2 pointers.
|
||||||
|
His team also scores 6 3 pointers, meaning they scored 8*3= 24 points in 3 pointers
|
||||||
|
They scored 10 free throws, and free throws count as one point so they scored 10*1=10 points in free throws.
|
||||||
|
All together his team scored 50+24+10= 84 points
|
||||||
|
Mark's opponents scored double his team's number of 2 pointers, meaning they scored 50*2=100 points in 2 pointers.
|
||||||
|
His opponents scored half his team's number of 3 pointers, meaning they scored 24/2= 12 points in 3 pointers.
|
||||||
|
They also scored half Mark's team's points in free throws, meaning they scored 10/2=5 points in free throws.
|
||||||
|
All together Mark's opponents scored 100+12+5=117 points
|
||||||
|
The total score for the game is both team's scores added together, so it is 84+117=201 points
|
||||||
|
The answer is 201
|
||||||
|
|
||||||
|
Question: {question}\nLet's think step by step:\n{answer}
|
||||||
|
'''),
|
||||||
|
retriever=dict(type=ZeroRetriever)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 3. Self-Consistency
|
||||||
|
|
||||||
|
The SC (Self-Consistency) method is proposed in [this paper](https://arxiv.org/abs/2203.11171), which will sample multiple reasoning paths for the question, and make majority voting to the generated answers for LLMs. This method displays remarkable proficiency among reasoning tasks with high accuracy but may consume more time and resources when inferencing, because of the majority voting strategy. In OpenCompass, You can easily implement the SC method by replacing `GenInferencer` with `SCInferencer` in the dataset configuration and setting the corresponding parameters like:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# This SC gsm8k config can be found at: opencompass.configs.datasets.gsm8k.gsm8k_gen_a3e34a.py
|
||||||
|
gsm8k_infer_cfg = dict(
|
||||||
|
inferencer=dict(
|
||||||
|
type=SCInferencer, # Replace GenInferencer with SCInferencer.
|
||||||
|
generation_kwargs=dict(do_sample=True, temperature=0.7, top_k=40), # Set sample parameters to make sure model generate various output, only works for models load from HuggingFace now.
|
||||||
|
infer_type='SC',
|
||||||
|
sc_size = SAMPLE_SIZE
|
||||||
|
)
|
||||||
|
)
|
||||||
|
gsm8k_eval_cfg = dict(sc_size=SAMPLE_SIZE)
|
||||||
|
```
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
OpenCompass defaults to use argmax for sampling the next token. Therefore, if the sampling parameters are not specified, the model's inference results will be completely consistent each time, and multiple rounds of evaluation will be ineffective.
|
||||||
|
```
|
||||||
|
|
||||||
|
Where `SAMPLE_SIZE` is the number of reasoning paths in Self-Consistency, higher value usually outcome higher performance. The following figure from the original SC paper demonstrates the relation between reasoning paths and performance in several reasoning tasks:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
From the figure, it can be seen that in different reasoning tasks, performance tends to improve as the number of reasoning paths increases. However, for some tasks, increasing the number of reasoning paths may reach a limit, and further increasing the number of paths may not bring significant performance improvement. Therefore, it is necessary to conduct experiments and adjustments on specific tasks to find the optimal number of reasoning paths that best suit the task.
|
||||||
|
|
||||||
|
## 4. Tree-of-Thoughts
|
||||||
|
|
||||||
|
In contrast to the conventional CoT approach that considers only a single reasoning path, Tree-of-Thoughts (ToT) allows the language model to explore multiple diverse reasoning paths simultaneously. The model evaluates the reasoning process through self-assessment and makes global choices by conducting lookahead or backtracking when necessary. Specifically, this process is divided into the following four stages:
|
||||||
|
|
||||||
|
**1. Thought Decomposition**
|
||||||
|
|
||||||
|
Based on the nature of the problem, break down the problem into multiple intermediate steps. Each step can be a phrase, equation, or writing plan, depending on the nature of the problem.
|
||||||
|
|
||||||
|
**2. Thought Generation**
|
||||||
|
|
||||||
|
Assuming that solving the problem requires k steps, there are two methods to generate reasoning content:
|
||||||
|
|
||||||
|
- Independent sampling: For each state, the model independently extracts k reasoning contents from the CoT prompts, without relying on other reasoning contents.
|
||||||
|
- Sequential generation: Sequentially use "prompts" to guide the generation of reasoning content, where each reasoning content may depend on the previous one.
|
||||||
|
|
||||||
|
**3. Heuristic Evaluation**
|
||||||
|
|
||||||
|
Use heuristic methods to evaluate the contribution of each generated reasoning content to problem-solving. This self-evaluation is based on the model's self-feedback and involves designing prompts to have the model score multiple generated results.
|
||||||
|
|
||||||
|
**4. Search Algorithm Selection**
|
||||||
|
|
||||||
|
Based on the methods of generating and evaluating reasoning content, select an appropriate search algorithm. For example, you can use breadth-first search (BFS) or depth-first search (DFS) algorithms to systematically explore the thought tree, conducting lookahead and backtracking.
|
||||||
|
|
||||||
|
In OpenCompass, ToT parameters need to be set according to the requirements. Below is an example configuration for the 24-Point game from the [official paper](https://arxiv.org/pdf/2305.10601.pdf). Currently, ToT inference is supported only with Huggingface models:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# This ToT Game24 config can be found at: opencompass/configs/datasets/game24/game24_gen_8dfde3.py.
|
||||||
|
from opencompass.datasets import (Game24Dataset, game24_postprocess,
|
||||||
|
Game24Evaluator, Game24PromptWrapper)
|
||||||
|
|
||||||
|
generation_kwargs = dict(temperature=0.7)
|
||||||
|
|
||||||
|
game24_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='{input}'), # Directly pass the input content, as the Prompt needs to be specified in steps
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=ToTInferencer, # Replace GenInferencer with ToTInferencer
|
||||||
|
generation_kwargs=generation_kwargs,
|
||||||
|
method_generate='propose', # Method for generating reasoning content, can be independent sampling (sample) or sequential generation (propose)
|
||||||
|
method_evaluate='value', # Method for evaluating reasoning content, can be voting (vote) or scoring (value)
|
||||||
|
method_select='greedy', # Method for selecting reasoning content, can be greedy (greedy) or random (sample)
|
||||||
|
n_evaluate_sample=3,
|
||||||
|
n_select_sample=5,
|
||||||
|
task_wrapper=dict(type=Game24PromptWrapper) # This Wrapper class includes the prompts for each step and methods for generating and evaluating reasoning content, needs customization according to the task
|
||||||
|
))
|
||||||
|
```
|
||||||
|
|
||||||
|
If you want to use the ToT method on a custom dataset, you'll need to make additional configurations in the `opencompass.datasets.YourDataConfig.py` file to set up the `YourDataPromptWrapper` class. This is required for handling the thought generation and heuristic evaluation step within the ToT framework. For reasoning tasks similar to the game 24-Point, you can refer to the implementation in `opencompass/datasets/game24.py` for guidance.
|
||||||
|
|
@ -0,0 +1,263 @@
|
||||||
|
# Meta Template
|
||||||
|
|
||||||
|
## Background
|
||||||
|
|
||||||
|
In the Supervised Fine-Tuning (SFT) process of Language Model Learning (LLM), we often inject some predefined strings into the conversation according to actual requirements, in order to prompt the model to output content according to certain guidelines. For example, in some `chat` model fine-tuning, we may add system-level instructions at the beginning of each dialogue, and establish a format to represent the conversation between the user and the model. In a conversation, the model may expect the text format to be as follows:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
Meta instruction: You are now a helpful and harmless AI assistant.
|
||||||
|
HUMAN: Hi!<eoh>\n
|
||||||
|
Bot: Hello! How may I assist you?<eob>\n
|
||||||
|
```
|
||||||
|
|
||||||
|
During evaluation, we also need to enter questions according to the agreed format for the model to perform its best.
|
||||||
|
|
||||||
|
In addition, similar situations exist in API models. General API dialogue models allow users to pass in historical dialogues when calling, and some models also allow the input of SYSTEM level instructions. To better evaluate the ability of API models, we hope to make the data as close as possible to the multi-round dialogue template of the API model itself during the evaluation, rather than stuffing all the content into an instruction.
|
||||||
|
|
||||||
|
Therefore, we need to specify different parsing templates for different models. In OpenCompass, we call this set of parsing templates **Meta Template**. Meta Template is tied to the model's configuration and is combined with the dialogue template of the dataset during runtime to ultimately generate the most suitable prompt for the current model.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# When specifying, just pass the meta_template field into the model
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type='AnyModel',
|
||||||
|
meta_template = ..., # meta template
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
Next, we will introduce how to configure Meta Template on two types of models.
|
||||||
|
You are recommended to read [here](./prompt_template.md#dialogue-prompt) for the basic syntax of the dialogue template before reading this chapter.
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
In some cases (such as testing the base station), we don't need to inject any instructions into the normal dialogue, in which case we can leave the meta template empty. In this case, the prompt received by the model is defined only by the dataset configuration and is a regular string. If the dataset configuration uses a dialogue template, speeches from different roles will be concatenated with \n.
|
||||||
|
```
|
||||||
|
|
||||||
|
## Application on Language Models
|
||||||
|
|
||||||
|
The following figure shows several situations where the data is built into a prompt through the prompt template and meta template from the dataset in the case of 2-shot learning. Readers can use this figure as a reference to help understand the following sections.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
We will explain how to define the meta template with several examples.
|
||||||
|
|
||||||
|
Suppose that according to the dialogue template of the dataset, the following dialogue was produced:
|
||||||
|
|
||||||
|
```python
|
||||||
|
PromptList([
|
||||||
|
dict(role='HUMAN', prompt='1+1=?'),
|
||||||
|
dict(role='BOT', prompt='2'),
|
||||||
|
dict(role='HUMAN', prompt='2+2=?'),
|
||||||
|
dict(role='BOT', prompt='4'),
|
||||||
|
])
|
||||||
|
```
|
||||||
|
|
||||||
|
We want to pass this dialogue to a model that has already gone through SFT. The model's agreed dialogue begins with the speech of different roles with `<Role Name>:` and ends with a special token and \\n. Here is the complete string the model expects to receive:
|
||||||
|
|
||||||
|
```Plain
|
||||||
|
<HUMAN>: 1+1=?<eoh>
|
||||||
|
<BOT>: 2<eob>
|
||||||
|
<HUMAN>: 2+2=?<eoh>
|
||||||
|
<BOT>: 4<eob>
|
||||||
|
```
|
||||||
|
|
||||||
|
In the meta template, we only need to abstract the format of each round of dialogue into the following configuration:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# model meta template
|
||||||
|
meta_template = dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', begin='<HUMAN>: ', end='<eoh>\n'),
|
||||||
|
dict(role='BOT', begin='<BOT>: ', end='<eob>\n'),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
______________________________________________________________________
|
||||||
|
|
||||||
|
Some datasets may introduce SYSTEM-level roles:
|
||||||
|
|
||||||
|
```python
|
||||||
|
PromptList([
|
||||||
|
dict(role='SYSTEM', fallback_role='HUMAN', prompt='Solve the following math questions'),
|
||||||
|
dict(role='HUMAN', prompt='1+1=?'),
|
||||||
|
dict(role='BOT', prompt='2'),
|
||||||
|
dict(role='HUMAN', prompt='2+2=?'),
|
||||||
|
dict(role='BOT', prompt='4'),
|
||||||
|
])
|
||||||
|
```
|
||||||
|
|
||||||
|
Assuming the model also accepts the SYSTEM role, and expects the input to be:
|
||||||
|
|
||||||
|
```
|
||||||
|
<SYSTEM>: Solve the following math questions<eosys>\n
|
||||||
|
<HUMAN>: 1+1=?<eoh>\n
|
||||||
|
<BOT>: 2<eob>\n
|
||||||
|
<HUMAN>: 2+2=?<eoh>\n
|
||||||
|
<BOT>: 4<eob>\n
|
||||||
|
end of conversation
|
||||||
|
```
|
||||||
|
|
||||||
|
We can put the definition of the SYSTEM role into `reserved_roles`. Roles in `reserved_roles` will not appear in regular conversations, but they allow the dialogue template of the dataset configuration to call them in `begin` or `end`.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# model meta template
|
||||||
|
meta_template = dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', begin='<HUMAN>: ', end='<eoh>\n'),
|
||||||
|
dict(role='BOT', begin='<BOT>: ', end='<eob>\n'),
|
||||||
|
],
|
||||||
|
reserved_roles=[dict(role='SYSTEM', begin='<SYSTEM>: ', end='<eosys>\n'),],
|
||||||
|
),
|
||||||
|
```
|
||||||
|
|
||||||
|
If the model does not accept the SYSTEM role, it is not necessary to configure this item, and it can still run normally. In this case, the string received by the model becomes:
|
||||||
|
|
||||||
|
```
|
||||||
|
<HUMAN>: Solve the following math questions<eoh>\n
|
||||||
|
<HUMAN>: 1+1=?<eoh>\n
|
||||||
|
<BOT>: 2<eob>\n
|
||||||
|
<HUMAN>: 2+2=?<eoh>\n
|
||||||
|
<BOT>: 4<eob>\n
|
||||||
|
end of conversation
|
||||||
|
```
|
||||||
|
|
||||||
|
This is because in the predefined datasets in OpenCompass, each `SYSTEM` speech has a `fallback_role='HUMAN'`, that is, if the `SYSTEM` role in the meta template does not exist, the speaker will be switched to the `HUMAN` role.
|
||||||
|
|
||||||
|
______________________________________________________________________
|
||||||
|
|
||||||
|
Some models may need to consider embedding other strings at the beginning or end of the conversation, such as system instructions:
|
||||||
|
|
||||||
|
```
|
||||||
|
Meta instruction: You are now a helpful and harmless AI assistant.
|
||||||
|
<SYSTEM>: Solve the following math questions<eosys>\n
|
||||||
|
<HUMAN>: 1+1=?<eoh>\n
|
||||||
|
<BOT>: 2<eob>\n
|
||||||
|
<HUMAN>: 2+2=?<eoh>\n
|
||||||
|
<BOT>: 4<eob>\n
|
||||||
|
end of conversation
|
||||||
|
```
|
||||||
|
|
||||||
|
In this case, we can specify these strings by specifying the begin and end parameters.
|
||||||
|
|
||||||
|
```python
|
||||||
|
meta_template = dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', begin='<HUMAN>: ', end='<eoh>\n'),
|
||||||
|
dict(role='BOT', begin='<BOT>: ', end='<eob>\n'),
|
||||||
|
],
|
||||||
|
reserved_roles=[dict(role='SYSTEM', begin='<SYSTEM>: ', end='<eosys>\n'),],
|
||||||
|
begin="Meta instruction: You are now a helpful and harmless AI assistant.",
|
||||||
|
end="end of conversation",
|
||||||
|
),
|
||||||
|
```
|
||||||
|
|
||||||
|
______________________________________________________________________
|
||||||
|
|
||||||
|
In **generative** task evaluation, we will not directly input the answer to the model, but by truncating the prompt, while retaining the previous text, we leave the answer output by the model blank.
|
||||||
|
|
||||||
|
```
|
||||||
|
Meta instruction: You are now a helpful and harmless AI assistant.
|
||||||
|
<SYSTEM>: Solve the following math questions<eosys>\n
|
||||||
|
<HUMAN>: 1+1=?<eoh>\n
|
||||||
|
<BOT>: 2<eob>\n
|
||||||
|
<HUMAN>: 2+2=?<eoh>\n
|
||||||
|
<BOT>:
|
||||||
|
```
|
||||||
|
|
||||||
|
We only need to set the `generate` field in BOT's configuration to True, and OpenCompass will automatically leave the last utterance of BOT blank:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# model meta template
|
||||||
|
meta_template = dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', begin='<HUMAN>: ', end='<eoh>\n'),
|
||||||
|
dict(role='BOT', begin='<BOT>: ', end='<eob>\n', generate=True),
|
||||||
|
],
|
||||||
|
reserved_roles=[dict(role='SYSTEM', begin='<SYSTEM>: ', end='<eosys>\n'),],
|
||||||
|
begin="Meta instruction: You are now a helpful and harmless AI assistant.",
|
||||||
|
end="end of conversation",
|
||||||
|
),
|
||||||
|
```
|
||||||
|
|
||||||
|
Note that `generate` only affects generative inference. When performing discriminative inference, the prompt received by the model is still complete.
|
||||||
|
|
||||||
|
### Full Definition
|
||||||
|
|
||||||
|
```bash
|
||||||
|
models = [
|
||||||
|
dict(meta_template = dict(
|
||||||
|
begin="Meta instruction: You are now a helpful and harmless AI assistant.",
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', begin='HUMAN: ', end='<eoh>\n'), # begin and end can be a list of strings or integers.
|
||||||
|
dict(role='THOUGHTS', begin='THOUGHTS: ', end='<eot>\n', prompt='None'), # Here we can set the default prompt, which may be overridden by the specific dataset
|
||||||
|
dict(role='BOT', begin='BOT: ', generate=True, end='<eob>\n'),
|
||||||
|
],
|
||||||
|
end="end of conversion",
|
||||||
|
reserved_roles=[dict(role='SYSTEM', begin='SYSTEM: ', end='\n'),],
|
||||||
|
eos_token_id=10000,
|
||||||
|
),
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
The `meta_template` is a dictionary that can contain the following fields:
|
||||||
|
|
||||||
|
- `begin`, `end`: (str, optional) The beginning and ending of the prompt, typically some system-level instructions.
|
||||||
|
|
||||||
|
- `round`: (list) The template format of each round of dialogue. The content of the prompt for each round of dialogue is controlled by the dialogue template configured in the dataset.
|
||||||
|
|
||||||
|
- `reserved_roles`: (list, optional) Specify roles that do not appear in `round` but may be used in the dataset configuration, such as the `SYSTEM` role.
|
||||||
|
|
||||||
|
- `eos_token_id`: (int, optional): Specifies the ID of the model's eos token. If not set, it defaults to the eos token id in the tokenizer. Its main role is to trim the output of the model in generative tasks, so it should generally be set to the first token id of the end corresponding to the item with generate=True.
|
||||||
|
|
||||||
|
The `round` of the `meta_template` specifies the format of each role's speech in a round of dialogue. It accepts a list of dictionaries, each dictionary's keys are as follows:
|
||||||
|
|
||||||
|
- `role` (str): The name of the role participating in the dialogue. This string does not affect the actual prompt.
|
||||||
|
|
||||||
|
- `begin`, `end` (str): Specifies the fixed beginning or end when this role speaks.
|
||||||
|
|
||||||
|
- `prompt` (str): The role's prompt. It is allowed to leave it blank in the meta template, but in this case, it must be specified in the prompt of the dataset configuration.
|
||||||
|
|
||||||
|
- `generate` (bool): When specified as True, this role is the one the model plays. In generation tasks, the prompt received by the model will be cut off at the `begin` of this role, and the remaining content will be filled by the model.
|
||||||
|
|
||||||
|
## Application to API Models
|
||||||
|
|
||||||
|
The meta template of the API model is similar to the meta template of the general model, but the configuration is simpler. Users can, as per their requirements, directly use one of the two configurations below to evaluate the API model in a multi-turn dialogue manner:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# If the API model does not support system instructions
|
||||||
|
meta_template=dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', api_role='HUMAN'),
|
||||||
|
dict(role='BOT', api_role='BOT', generate=True)
|
||||||
|
],
|
||||||
|
)
|
||||||
|
|
||||||
|
# If the API model supports system instructions
|
||||||
|
meta_template=dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', api_role='HUMAN'),
|
||||||
|
dict(role='BOT', api_role='BOT', generate=True)
|
||||||
|
],
|
||||||
|
reserved_roles=[
|
||||||
|
dict(role='SYSTEM', api_role='SYSTEM'),
|
||||||
|
],
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Principle
|
||||||
|
|
||||||
|
Even though different API models accept different data structures, there are commonalities overall. Interfaces that accept dialogue history generally allow users to pass in prompts from the following three roles:
|
||||||
|
|
||||||
|
- User
|
||||||
|
- Robot
|
||||||
|
- System (optional)
|
||||||
|
|
||||||
|
In this regard, OpenCompass has preset three `api_role` values for API models: `HUMAN`, `BOT`, `SYSTEM`, and stipulates that in addition to regular strings, the input accepted by API models includes a middle format of dialogue represented by `PromptList`. The API model will repackage the dialogue in a multi-turn dialogue format and send it to the backend. However, to activate this feature, users need to map the roles `role` in the dataset prompt template to the corresponding `api_role` in the above meta template. The following figure illustrates the relationship between the input accepted by the API model and the Prompt Template and Meta Template.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Debugging
|
||||||
|
|
||||||
|
If you need to debug the prompt, it is recommended to use the `tools/prompt_viewer.py` script to preview the actual prompt received by the model after preparing the configuration file. Read [here](../tools.md#prompt-viewer) for more.
|
||||||
|
|
@ -0,0 +1,11 @@
|
||||||
|
# Prompt Overview
|
||||||
|
|
||||||
|
The prompt is the input to the Language Model (LLM), used to guide the model to generate text or calculate perplexity (PPL). The selection of prompts can significantly impact the accuracy of the evaluated model. The process of converting the dataset into a series of prompts is defined by templates.
|
||||||
|
|
||||||
|
In OpenCompass, we split the template into two parts: the data-side template and the model-side template. When evaluating a model, the data will pass through both the data-side template and the model-side template, ultimately transforming into the input required by the model.
|
||||||
|
|
||||||
|
The data-side template is referred to as [prompt_template](./prompt_template.md), which represents the process of converting the fields in the dataset into prompts.
|
||||||
|
|
||||||
|
The model-side template is referred to as [meta_template](./meta_template.md), which represents how the model transforms these prompts into its expected input.
|
||||||
|
|
||||||
|
We also offer some prompting examples regarding [Chain of Thought](./chain_of_thought.md).
|
||||||
|
|
@ -0,0 +1,497 @@
|
||||||
|
# Prompt Template
|
||||||
|
|
||||||
|
## Background
|
||||||
|
|
||||||
|
In language model evaluation, we often construct prompts from the original dataset according to certain rules to enable the model to answer questions as required.
|
||||||
|
|
||||||
|
Typically, we place instructions at the beginning of the prompt, followed by several in-context examples, and finally, we include the question. For example:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Solve the following questions.
|
||||||
|
1+1=?
|
||||||
|
2
|
||||||
|
3+9=?
|
||||||
|
12
|
||||||
|
5+6=?
|
||||||
|
```
|
||||||
|
|
||||||
|
Extensive experiments have shown that even with the same original test questions, different ways of constructing the prompt can affect the model's performance. Factors that may influence this include:
|
||||||
|
|
||||||
|
- The composition of the prompt itself, including instructions, in-context examples, and the format of the question.
|
||||||
|
- The selection of in-context examples, including the number and method of selection.
|
||||||
|
- The manner in which the prompt is used. Should the model complete the prompt based on the given context, or should it choose the best prompt among the candidate prompts?
|
||||||
|
|
||||||
|
OpenCompass defines the prompt construction strategy in the `infer_cfg` section of the dataset configuration. A typical `infer_cfg` is shown below:
|
||||||
|
|
||||||
|
```python
|
||||||
|
infer_cfg = dict(
|
||||||
|
ice_template=dict( # Template used to construct In Context Examples (ice).
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='{question}\n{answer}'
|
||||||
|
),
|
||||||
|
prompt_template=dict( # Template used to construct the main prompt.
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='Solve the following questions.\n</E>{question}\n{answer}',
|
||||||
|
ice_token="</E>"
|
||||||
|
),
|
||||||
|
retriever=dict(type=FixKRetriever, fix_id_list=[0, 1]), # Definition of how to retrieve in-context examples.
|
||||||
|
inferencer=dict(type=GenInferencer), # Method used to generate predictions.
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
In this document, we will mainly introduce the definitions of `ice_template`, `prompt_template`, and `inferencer`. For information on the `retriever`, please refer to other documents.
|
||||||
|
|
||||||
|
Let's start by introducing the basic syntax of the prompt.
|
||||||
|
|
||||||
|
## String-Based Prompt
|
||||||
|
|
||||||
|
String-based prompt is a classic form of template. Consider the following template:
|
||||||
|
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template="{anything}\nQuestion: {question}\nAnswer: {answer}"
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
At runtime, the fields within the `{}` will be replaced with corresponding fields from the data sample. If a field does not exist in the data sample, it will be kept as is in the output.
|
||||||
|
|
||||||
|
For example, let's consider a data example as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
example = {
|
||||||
|
'question': '1+1=?',
|
||||||
|
'answer': '2', # Assume the answer is in the reader_cfg.output_column
|
||||||
|
'irrelevant_infos': 'blabla',
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
After filling in the template, the result will be:
|
||||||
|
|
||||||
|
```text
|
||||||
|
{anything}
|
||||||
|
Question: 1+1=?
|
||||||
|
Answer:
|
||||||
|
```
|
||||||
|
|
||||||
|
As you can see, the actual answer for the question, represented by the field `answer`, does not appear in the generated result. This is because OpenCompass will mask fields that are written in `reader_cfg.output_column` to prevent answer leakage. For detailed explanations on `reader_cfg`, please refer to the relevant documentation on dataset configuration.
|
||||||
|
|
||||||
|
## Dialogue-Based Prompt
|
||||||
|
|
||||||
|
In practical testing, making models perform simple completions may not effectively test the performance of chat-based models. Therefore, we prefer prompts that take the form of dialogues. Additionally, different models have varying definitions of dialogue formats. Hence, we need prompts generated from the dataset to be more versatile, and the specific prompts required by each model can be generated during testing.
|
||||||
|
|
||||||
|
To achieve this, OpenCompass extends the string-based prompt to dialogue-based prompt. Dialogue-based prompt is more flexible, as it can combine with different [meta_templates](./meta_template.md) on the model side to generate prompts in various dialogue formats. It is applicable to both base and chat models, but their definitions are relatively complex.
|
||||||
|
|
||||||
|
Now, let's assume we have a data sample as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
example = {
|
||||||
|
'question': '1+1=?',
|
||||||
|
'answer': '2', # Assume the answer is in the reader_cfg.output_column
|
||||||
|
'irrelavent_infos': 'blabla',
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Next, let's showcase a few examples:
|
||||||
|
|
||||||
|
`````{tabs}
|
||||||
|
|
||||||
|
````{tab} Single-round Dialogue
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="Question: {question}"),
|
||||||
|
dict(role="BOT", prompt="Answer: {answer}"),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
The intermediate result obtained by OpenCompass after filling the data into the template is:
|
||||||
|
|
||||||
|
```python
|
||||||
|
PromptList([
|
||||||
|
dict(role='HUMAN', prompt='Question: 1+1=?'),
|
||||||
|
dict(role='BOT', prompt='Answer: '),
|
||||||
|
])
|
||||||
|
```
|
||||||
|
|
||||||
|
````
|
||||||
|
|
||||||
|
````{tab} Multi-round Dialogue
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="Question: 2+2=?"),
|
||||||
|
dict(role="BOT", prompt="Answer: 4"),
|
||||||
|
dict(role="HUMAN", prompt="Question: 3+3=?"),
|
||||||
|
dict(role="BOT", prompt="Answer: 6"),
|
||||||
|
dict(role="HUMAN", prompt="Question: {question}"),
|
||||||
|
dict(role="BOT", prompt="Answer: {answer}"),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
The intermediate result obtained by OpenCompass after filling the data into the template is:
|
||||||
|
|
||||||
|
```python
|
||||||
|
PromptList([
|
||||||
|
dict(role='HUMAN', prompt='Question: 2+2=?'),
|
||||||
|
dict(role='BOT', prompt='Answer: 4'),
|
||||||
|
dict(role='HUMAN', prompt='Question: 3+3=?'),
|
||||||
|
dict(role='BOT', prompt='Answer: 6'),
|
||||||
|
dict(role='HUMAN', prompt='Question: 1+1=?'),
|
||||||
|
dict(role='BOT', prompt='Answer: '),
|
||||||
|
])
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
|
||||||
|
````{tab} Dialogue with sys instruction
|
||||||
|
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
begin=[
|
||||||
|
dict(role='SYSTEM', fallback_role='HUMAN', prompt='Solve the following questions.'),
|
||||||
|
],
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="Question: {question}"),
|
||||||
|
dict(role="BOT", prompt="Answer: {answer}"),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
The intermediate result obtained by OpenCompass after filling the data into the template is:
|
||||||
|
|
||||||
|
```python
|
||||||
|
PromptList([
|
||||||
|
dict(role='SYSTEM', fallback_role='HUMAN', prompt='Solve the following questions.'),
|
||||||
|
dict(role='HUMAN', prompt='Question: 1+1=?'),
|
||||||
|
dict(role='BOT', prompt='Answer: '),
|
||||||
|
])
|
||||||
|
```
|
||||||
|
|
||||||
|
During the processing of a specific meta template, if the definition includes the SYSTEM role, the template designated for the SYSTEM role will be used for processing. On the other hand, if the SYSTEM role is not defined, the template assigned to the fallback_role role will be utilized, which, in this example, corresponds to the HUMAN role.
|
||||||
|
|
||||||
|
````
|
||||||
|
|
||||||
|
`````
|
||||||
|
|
||||||
|
In dialogue-based templates, prompts are organized in the form of conversations between different roles (`role`). In the current predefined dataset configuration of OpenCompass, some commonly used roles in a prompt include:
|
||||||
|
|
||||||
|
- `HUMAN`: Represents a human, usually the one asking questions.
|
||||||
|
- `BOT`: Represents the language model, usually the one providing answers.
|
||||||
|
- `SYSTEM`: Represents the system, typically used at the beginning of prompts to give instructions.
|
||||||
|
|
||||||
|
Furthermore, unlike string-based templates, the prompts generated by dialogue-based templates are transformed into an intermediate structure called PromptList. This structure will be further combined with the model-side [meta_templates](./meta_template.md) to assemble the final prompt. If no meta template is specified, the prompts in the PromptList will be directly concatenated into a single string.
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
The content within the PromptList in the example above is not the final input to the model and depends on the processing of the meta template. One potential source of misunderstanding is that in generative evaluations, the prompt of the last `BOT` role, `Answer: `, **will not** be inputted to the model. This is because API models generally cannot customize the initial part of model-generated responses. Therefore, this setting ensures consistency in the evaluation behavior between language models and API models. For more information, please refer to the documentation on [meta template](./meta_template.md).
|
||||||
|
```
|
||||||
|
|
||||||
|
<details>
|
||||||
|
<summary>Expand the complete parameter descriptions</summary>
|
||||||
|
|
||||||
|
- `begin`, `end`: (list, optional) The beginning and end of the prompt, typically containing system-level instructions. Each item inside can be **a dictionary or a string**.
|
||||||
|
|
||||||
|
- `round`: (list) The format of the dialogue in the template. Each item in the list must be a dictionary.
|
||||||
|
|
||||||
|
Each dictionary has the following parameters:
|
||||||
|
|
||||||
|
- `role` (str): The role name participating in the dialogue. It is used to associate with the names in meta_template but does not affect the actual generated prompt.
|
||||||
|
|
||||||
|
- `fallback_role` (str): The default role name to use in case the associated role is not found in the meta_template. Defaults to None.
|
||||||
|
|
||||||
|
- `prompt` (str): The dialogue content for the role.
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## Prompt Templates and `inferencer`
|
||||||
|
|
||||||
|
Once we understand the basic definition of prompt templates, we also need to organize them according to the type of `inferencer`.
|
||||||
|
|
||||||
|
OpenCompass mainly supports two types of inferencers: `GenInferencer` and `PPLInferencer`, corresponding to two different inference methods.
|
||||||
|
|
||||||
|
`GenInferencer` corresponds to generative inference. During inference, the model is asked to continue generating text based on the input prompt. In this case, the `template` represents a single template for each sentence, for example:
|
||||||
|
|
||||||
|
`````{tabs}
|
||||||
|
|
||||||
|
````{group-tab} String-based Prompt
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='Solve the following questions.\n{question}\n{answer}'
|
||||||
|
)
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
````{group-tab} Dialogue-Based Prompt
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
begin=[
|
||||||
|
dict(role='SYSTEM', fallback_role='HUMAN', prompt='Solve the following questions.'),
|
||||||
|
],
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="{question}"),
|
||||||
|
dict(role="BOT", prompt="{answer}"),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
`````
|
||||||
|
|
||||||
|
Then, the model's inference result will be a continuation of the concatenated string.
|
||||||
|
|
||||||
|
For `PPLInferencer`, it corresponds to discriminative inference. During inference, the model is asked to compute the perplexity (PPL) for each input string and select the item with the lowest perplexity as the model's inference result. In this case, `template` is a `dict` representing the template for each sentence, for example:
|
||||||
|
|
||||||
|
`````{tabs}
|
||||||
|
|
||||||
|
````{group-tab} String-based Prompt
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
"A": "Question: Which is true?\nA. {A}\nB. {B}\nC. {C}\nAnswer: A",
|
||||||
|
"B": "Question: Which is true?\nA. {A}\nB. {B}\nC. {C}\nAnswer: B",
|
||||||
|
"C": "Question: Which is true?\nA. {A}\nB. {B}\nC. {C}\nAnswer: C",
|
||||||
|
"UNK": "Question: Which is true?\nA. {A}\nB. {B}\nC. {C}\nAnswer: None of them is true.",
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
````{group-tab} Dialogue-Based Prompt
|
||||||
|
```python
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
"A": dict(
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="Question: Which is true?\nA. {A}\nB. {B}\nC. {C}"),
|
||||||
|
dict(role="BOT", prompt="Answer: A"),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
"B": dict(
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="Question: Which is true?\nA. {A}\nB. {B}\nC. {C}"),
|
||||||
|
dict(role="BOT", prompt="Answer: B"),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
"C": dict(
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="Question: Which is true?\nA. {A}\nB. {B}\nC. {C}"),
|
||||||
|
dict(role="BOT", prompt="Answer: C"),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
"UNK": dict(
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="Question: Which is true?\nA. {A}\nB. {B}\nC. {C}"),
|
||||||
|
dict(role="BOT", prompt="Answer: None of them is true."),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
`````
|
||||||
|
|
||||||
|
In this case, the model's inference result will be one of the four keys in the `template` ("A" / "B" / "C" / "UNK").
|
||||||
|
|
||||||
|
## `ice_template` and `prompt_template`
|
||||||
|
|
||||||
|
In OpenCompass, for 0-shot evaluation, we usually only need to define the `prompt_template` field to complete prompt construction. However, for few-shot evaluation, we also need to define the `ice_template` field, which manages the prompt templates corresponding to the in-context examples during context learning.
|
||||||
|
|
||||||
|
Both `ice_template` and `prompt_template` follow the same syntax and rules. The complete prompt construction process can be represented using the following pseudo-code:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def build_prompt():
|
||||||
|
ice = ice_template.format(*ice_example)
|
||||||
|
prompt = prompt_template.replace(prompt_template.ice_token, ice).format(*prompt_example)
|
||||||
|
return prompt
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, let's assume there are two training data (ex1, ex2) and one testing data (ex3):
|
||||||
|
|
||||||
|
```python
|
||||||
|
ex1 = {
|
||||||
|
'question': '2+2=?',
|
||||||
|
'answer': '4',
|
||||||
|
'irrelavent_infos': 'blabla',
|
||||||
|
}
|
||||||
|
ex2 = {
|
||||||
|
'question': '3+3=?',
|
||||||
|
'answer': '6',
|
||||||
|
'irrelavent_infos': 'blabla',
|
||||||
|
}
|
||||||
|
ex3 = {
|
||||||
|
'question': '1+1=?',
|
||||||
|
'answer': '2', # Assume the answer is in the reader_cfg.output_column
|
||||||
|
'irrelavent_infos': 'blabla',
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Next, let's take a look at the actual effects of different prompt construction methods:
|
||||||
|
|
||||||
|
`````{tabs}
|
||||||
|
|
||||||
|
````{group-tab} String-based Prompt
|
||||||
|
|
||||||
|
Template configurations are as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
infer_cfg=dict(
|
||||||
|
ice_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='{question}\n{answer}'
|
||||||
|
),
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='Solve the following questions.\n</E>{question}\n{answer}'
|
||||||
|
ice_token='</E>',
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
The resulting strings are as follows:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Solve the following questions.
|
||||||
|
2+2=?
|
||||||
|
4
|
||||||
|
3+3=?
|
||||||
|
6
|
||||||
|
1+1=?
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
````
|
||||||
|
|
||||||
|
````{group-tab} Dialogue-Based Prompt
|
||||||
|
|
||||||
|
Template configurations are as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
infer_cfg=dict(
|
||||||
|
ice_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="{question}"),
|
||||||
|
dict(role="BOT", prompt="{answer}"),
|
||||||
|
]
|
||||||
|
)
|
||||||
|
),
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
begin=[
|
||||||
|
dict(role='SYSTEM', fallback_role='HUMAN', prompt='Solve the following questions.'),
|
||||||
|
'</E>',
|
||||||
|
],
|
||||||
|
round=[
|
||||||
|
dict(role="HUMAN", prompt="{question}"),
|
||||||
|
dict(role="BOT", prompt="{answer}"),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
ice_token='</E>',
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
The intermediate results obtained by OpenCompass after filling the data into the templates are as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
PromptList([
|
||||||
|
dict(role='SYSTEM', fallback_role='HUMAN', prompt='Solve the following questions.'),
|
||||||
|
dict(role='HUMAN', prompt='2+2=?'),
|
||||||
|
dict(role='BOT', prompt='4'),
|
||||||
|
dict(role='HUMAN', prompt='3+3=?'),
|
||||||
|
dict(role='BOT', prompt='6'),
|
||||||
|
dict(role='HUMAN', prompt='1+1=?'),
|
||||||
|
dict(role='BOT', prompt=''),
|
||||||
|
])
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
`````
|
||||||
|
|
||||||
|
### Abbreviated Usage
|
||||||
|
|
||||||
|
It is worth noting that, for the sake of simplicity in the configuration file, the `prompt_template` field can be omitted. When the `prompt_template` field is omitted, the `ice_template` will be used as the `prompt_template` as well, to assemble the complete prompt. The following two `infer_cfg` configurations are equivalent:
|
||||||
|
|
||||||
|
<table class="docutils">
|
||||||
|
<thead>
|
||||||
|
<tr>
|
||||||
|
<th>Complete Form</th>
|
||||||
|
<th>Abbreviated Form</th>
|
||||||
|
<tbody>
|
||||||
|
<tr>
|
||||||
|
<td>
|
||||||
|
|
||||||
|
```python
|
||||||
|
infer_cfg=dict(
|
||||||
|
ice_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template="Q: {question}\nA: {answer}",
|
||||||
|
),
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template="</E>Q: {question}\nA: {answer}",
|
||||||
|
ice_token="</E>",
|
||||||
|
),
|
||||||
|
# ...
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
|
||||||
|
```python
|
||||||
|
infer_cfg=dict(
|
||||||
|
ice_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template="</E>Q: {question}\nA: {answer}",
|
||||||
|
ice_token="</E>",
|
||||||
|
),
|
||||||
|
# ...
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</thead>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
More generally, even in the case of 0-shot learning (i.e., when `retriever` is `ZeroRetriver`), this mechanism still applies. Therefore, the following configuration is also valid:
|
||||||
|
|
||||||
|
```python
|
||||||
|
datasets = [
|
||||||
|
dict(
|
||||||
|
infer_cfg=dict(
|
||||||
|
ice_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template="Q: {question}\nA: {answer}",
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
),
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## Usage Suggestion
|
||||||
|
|
||||||
|
It is suggested to use the [Prompt Viewer](../tools.md) tool to visualize the completed prompts, confirm the correctness of the templates, and ensure that the results meet expectations.
|
||||||
|
|
@ -0,0 +1,103 @@
|
||||||
|
#! /usr/bin/env python
|
||||||
|
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
import yaml
|
||||||
|
from tabulate import tabulate
|
||||||
|
|
||||||
|
OC_ROOT = Path(__file__).absolute().parents[2]
|
||||||
|
GITHUB_PREFIX = 'https://github.com/open-compass/opencompass/tree/main/'
|
||||||
|
DATASETZOO_TEMPLATE = """\
|
||||||
|
# Dataset Statistics
|
||||||
|
|
||||||
|
On this page, we have listed all the datasets supported by OpenCompass.
|
||||||
|
|
||||||
|
You can use sorting and search functions to find the dataset you need.
|
||||||
|
|
||||||
|
We provide recommended running configurations for each dataset,
|
||||||
|
and in some datasets also offer recommended configurations based on LLM Judge.
|
||||||
|
|
||||||
|
You can quickly start evaluation tasks based on the recommended configurations.
|
||||||
|
However, please note that these configurations may be updated over time.
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
with open('dataset_statistics.md', 'w') as f:
|
||||||
|
f.write(DATASETZOO_TEMPLATE)
|
||||||
|
|
||||||
|
load_path = str(OC_ROOT / 'dataset-index.yml')
|
||||||
|
|
||||||
|
with open(load_path, 'r') as f2:
|
||||||
|
data_list = yaml.load(f2, Loader=yaml.FullLoader)
|
||||||
|
|
||||||
|
HEADER = ['name', 'category', 'paper', 'configpath', 'configpath_llmjudge']
|
||||||
|
|
||||||
|
recommanded_dataset_list = [
|
||||||
|
'ifeval', 'aime2024', 'bbh', 'bigcodebench', 'cmmlu', 'drop', 'gpqa',
|
||||||
|
'hellaswag', 'humaneval', 'korbench', 'livecodebench', 'math', 'mmlu',
|
||||||
|
'mmlu_pro', 'musr'
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
def table_format(data_list):
|
||||||
|
table_format_list = []
|
||||||
|
for i in data_list:
|
||||||
|
table_format_list_sub = []
|
||||||
|
for j in i:
|
||||||
|
if j in recommanded_dataset_list:
|
||||||
|
link_token = '[link]('
|
||||||
|
else:
|
||||||
|
link_token = '[link(TBD)]('
|
||||||
|
|
||||||
|
for index in HEADER:
|
||||||
|
if index == 'paper':
|
||||||
|
table_format_list_sub.append('[link](' + i[j][index] + ')')
|
||||||
|
elif index == 'configpath_llmjudge':
|
||||||
|
if i[j][index] == '':
|
||||||
|
table_format_list_sub.append(i[j][index])
|
||||||
|
else:
|
||||||
|
table_format_list_sub.append(link_token +
|
||||||
|
GITHUB_PREFIX +
|
||||||
|
i[j][index] + ')')
|
||||||
|
elif index == 'configpath':
|
||||||
|
if isinstance(i[j][index], list):
|
||||||
|
sub_list_text = ''
|
||||||
|
for k in i[j][index]:
|
||||||
|
sub_list_text += (link_token + GITHUB_PREFIX + k +
|
||||||
|
') / ')
|
||||||
|
table_format_list_sub.append(sub_list_text[:-2])
|
||||||
|
else:
|
||||||
|
table_format_list_sub.append(link_token +
|
||||||
|
GITHUB_PREFIX +
|
||||||
|
i[j][index] + ')')
|
||||||
|
else:
|
||||||
|
table_format_list_sub.append(i[j][index])
|
||||||
|
table_format_list.append(table_format_list_sub)
|
||||||
|
return table_format_list
|
||||||
|
|
||||||
|
|
||||||
|
data_format_list = table_format(data_list)
|
||||||
|
|
||||||
|
|
||||||
|
def generate_table(data_list, title=None):
|
||||||
|
|
||||||
|
with open('dataset_statistics.md', 'a') as f:
|
||||||
|
if title is not None:
|
||||||
|
f.write(f'\n{title}')
|
||||||
|
f.write("""\n```{table}\n:class: dataset\n""")
|
||||||
|
header = [
|
||||||
|
'Name', 'Category', 'Paper or Repository', 'Recommended Config',
|
||||||
|
'Recommended Config (LLM Judge)'
|
||||||
|
]
|
||||||
|
table_cfg = dict(tablefmt='pipe',
|
||||||
|
floatfmt='.2f',
|
||||||
|
numalign='right',
|
||||||
|
stralign='center')
|
||||||
|
f.write(tabulate(data_list, header, **table_cfg))
|
||||||
|
f.write('\n```\n')
|
||||||
|
|
||||||
|
|
||||||
|
generate_table(
|
||||||
|
data_list=data_format_list,
|
||||||
|
title='## Supported Dataset List',
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,133 @@
|
||||||
|
# Useful Tools
|
||||||
|
|
||||||
|
## Prompt Viewer
|
||||||
|
|
||||||
|
This tool allows you to directly view the generated prompt without starting the full training process. If the passed configuration is only the dataset configuration (such as `configs/datasets/nq/nq_gen.py`), it will display the original prompt defined in the dataset configuration. If it is a complete evaluation configuration (including the model and the dataset), it will display the prompt received by the selected model during operation.
|
||||||
|
|
||||||
|
Running method:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python tools/prompt_viewer.py CONFIG_PATH [-n] [-a] [-p PATTERN]
|
||||||
|
```
|
||||||
|
|
||||||
|
- `-n`: Do not enter interactive mode, select the first model (if any) and dataset by default.
|
||||||
|
- `-a`: View the prompts received by all models and all dataset combinations in the configuration.
|
||||||
|
- `-p PATTERN`: Do not enter interactive mode, select all datasets that match the input regular expression.
|
||||||
|
|
||||||
|
## Case Analyzer (To be updated)
|
||||||
|
|
||||||
|
Based on existing evaluation results, this tool produces inference error samples and full samples with annotation information.
|
||||||
|
|
||||||
|
Running method:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python tools/case_analyzer.py CONFIG_PATH [-w WORK_DIR]
|
||||||
|
```
|
||||||
|
|
||||||
|
- `-w`: Work path, default is `'./outputs/default'`.
|
||||||
|
|
||||||
|
## Lark Bot
|
||||||
|
|
||||||
|
Users can configure the Lark bot to implement real-time monitoring of task status. Please refer to [this document](https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN?lang=zh-CN#7a28964d) for setting up the Lark bot.
|
||||||
|
|
||||||
|
Configuration method:
|
||||||
|
|
||||||
|
- Open the `configs/secrets.py` file, and add the following line to the file:
|
||||||
|
|
||||||
|
```python
|
||||||
|
lark_bot_url = 'YOUR_WEBHOOK_URL'
|
||||||
|
```
|
||||||
|
|
||||||
|
- Normally, the Webhook URL format is like https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxxxxxxxxxxxx .
|
||||||
|
|
||||||
|
- Inherit this file in the complete evaluation configuration
|
||||||
|
|
||||||
|
- To avoid the bot sending messages frequently and causing disturbance, the running status will not be reported automatically by default. If necessary, you can start status reporting through `-l` or `--lark`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_demo.py -l
|
||||||
|
```
|
||||||
|
|
||||||
|
## API Model Tester
|
||||||
|
|
||||||
|
This tool can quickly test whether the functionality of the API model is normal.
|
||||||
|
|
||||||
|
Running method:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python tools/test_api_model.py [CONFIG_PATH] -n
|
||||||
|
```
|
||||||
|
|
||||||
|
## Prediction Merger
|
||||||
|
|
||||||
|
This tool can merge patitioned predictions.
|
||||||
|
|
||||||
|
Running method:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python tools/prediction_merger.py CONFIG_PATH [-w WORK_DIR]
|
||||||
|
```
|
||||||
|
|
||||||
|
- `-w`: Work path, default is `'./outputs/default'`.
|
||||||
|
|
||||||
|
## List Configs
|
||||||
|
|
||||||
|
This tool can list or search all available model and dataset configurations. It supports fuzzy search, making it convenient for use in conjunction with `run.py`.
|
||||||
|
|
||||||
|
Usage:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python tools/list_configs.py [PATTERN1] [PATTERN2] [...]
|
||||||
|
```
|
||||||
|
|
||||||
|
If executed without any parameters, it will list all model configurations in the `configs/models` and `configs/dataset` directories by default.
|
||||||
|
|
||||||
|
Users can also pass any number of parameters. The script will list all configurations related to the provided strings, supporting fuzzy search and the use of the * wildcard. For example, the following command will list all configurations related to `mmlu` and `llama`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python tools/list_configs.py mmlu llama
|
||||||
|
```
|
||||||
|
|
||||||
|
Its output could be:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-----------------+-----------------------------------+
|
||||||
|
| Model | Config Path |
|
||||||
|
|-----------------+-----------------------------------|
|
||||||
|
| hf_llama2_13b | configs/models/hf_llama2_13b.py |
|
||||||
|
| hf_llama2_70b | configs/models/hf_llama2_70b.py |
|
||||||
|
| hf_llama2_7b | configs/models/hf_llama2_7b.py |
|
||||||
|
| hf_llama_13b | configs/models/hf_llama_13b.py |
|
||||||
|
| hf_llama_30b | configs/models/hf_llama_30b.py |
|
||||||
|
| hf_llama_65b | configs/models/hf_llama_65b.py |
|
||||||
|
| hf_llama_7b | configs/models/hf_llama_7b.py |
|
||||||
|
| llama2_13b_chat | configs/models/llama2_13b_chat.py |
|
||||||
|
| llama2_70b_chat | configs/models/llama2_70b_chat.py |
|
||||||
|
| llama2_7b_chat | configs/models/llama2_7b_chat.py |
|
||||||
|
+-----------------+-----------------------------------+
|
||||||
|
+-------------------+---------------------------------------------------+
|
||||||
|
| Dataset | Config Path |
|
||||||
|
|-------------------+---------------------------------------------------|
|
||||||
|
| cmmlu_gen | configs/datasets/cmmlu/cmmlu_gen.py |
|
||||||
|
| cmmlu_gen_ffe7c0 | configs/datasets/cmmlu/cmmlu_gen_ffe7c0.py |
|
||||||
|
| cmmlu_ppl | configs/datasets/cmmlu/cmmlu_ppl.py |
|
||||||
|
| cmmlu_ppl_fd1f2f | configs/datasets/cmmlu/cmmlu_ppl_fd1f2f.py |
|
||||||
|
| mmlu_gen | configs/datasets/mmlu/mmlu_gen.py |
|
||||||
|
| mmlu_gen_23a9a9 | configs/datasets/mmlu/mmlu_gen_23a9a9.py |
|
||||||
|
| mmlu_gen_5d1409 | configs/datasets/mmlu/mmlu_gen_5d1409.py |
|
||||||
|
| mmlu_gen_79e572 | configs/datasets/mmlu/mmlu_gen_79e572.py |
|
||||||
|
| mmlu_gen_a484b3 | configs/datasets/mmlu/mmlu_gen_a484b3.py |
|
||||||
|
| mmlu_ppl | configs/datasets/mmlu/mmlu_ppl.py |
|
||||||
|
| mmlu_ppl_ac766d | configs/datasets/mmlu/mmlu_ppl_ac766d.py |
|
||||||
|
+-------------------+---------------------------------------------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## Dataset Suffix Updater
|
||||||
|
|
||||||
|
This tool can quickly modify the suffixes of configuration files located under the `configs/dataset` directory, aligning them with the naming conventions based on prompt hash.
|
||||||
|
|
||||||
|
How to run:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python tools/update_dataset_suffix.py
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,172 @@
|
||||||
|
# Learn About Config
|
||||||
|
|
||||||
|
OpenCompass uses the OpenMMLab modern style configuration files. If you are familiar with the OpenMMLab style
|
||||||
|
configuration files, you can directly refer to
|
||||||
|
[A Pure Python style Configuration File (Beta)](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/config.html#a-pure-python-style-configuration-file-beta)
|
||||||
|
to understand the differences between the new-style and original configuration files. If you have not
|
||||||
|
encountered OpenMMLab style configuration files before, I will explain the usage of configuration files using
|
||||||
|
a simple example. Make sure you have installed the latest version of MMEngine to support the
|
||||||
|
new-style configuration files.
|
||||||
|
|
||||||
|
## Basic Format
|
||||||
|
|
||||||
|
OpenCompass configuration files are in Python format, following basic Python syntax. Each configuration item
|
||||||
|
is specified by defining variables. For example, when defining a model, we use the following configuration:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# model_cfg.py
|
||||||
|
from opencompass.models import HuggingFaceCausalLM
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceCausalLM,
|
||||||
|
path='huggyllama/llama-7b',
|
||||||
|
model_kwargs=dict(device_map='auto'),
|
||||||
|
tokenizer_path='huggyllama/llama-7b',
|
||||||
|
tokenizer_kwargs=dict(padding_side='left', truncation_side='left'),
|
||||||
|
max_seq_len=2048,
|
||||||
|
max_out_len=50,
|
||||||
|
run_cfg=dict(num_gpus=8, num_procs=1),
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
When reading the configuration file, use `Config.fromfile` from MMEngine for parsing:
|
||||||
|
|
||||||
|
```python
|
||||||
|
>>> from mmengine.config import Config
|
||||||
|
>>> cfg = Config.fromfile('./model_cfg.py')
|
||||||
|
>>> print(cfg.models[0])
|
||||||
|
{'type': HuggingFaceCausalLM, 'path': 'huggyllama/llama-7b', 'model_kwargs': {'device_map': 'auto'}, ...}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Inheritance Mechanism
|
||||||
|
|
||||||
|
OpenCompass configuration files use Python's import mechanism for file inheritance. Note that when inheriting
|
||||||
|
configuration files, we need to use the `read_base` context manager.
|
||||||
|
|
||||||
|
```python
|
||||||
|
# inherit.py
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .model_cfg import models # Inherits the 'models' from model_cfg.py
|
||||||
|
```
|
||||||
|
|
||||||
|
Parse the configuration file using `Config.fromfile`:
|
||||||
|
|
||||||
|
```python
|
||||||
|
>>> from mmengine.config import Config
|
||||||
|
>>> cfg = Config.fromfile('./inherit.py')
|
||||||
|
>>> print(cfg.models[0])
|
||||||
|
{'type': HuggingFaceCausalLM, 'path': 'huggyllama/llama-7b', 'model_kwargs': {'device_map': 'auto'}, ...}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Evaluation Configuration Example
|
||||||
|
|
||||||
|
```python
|
||||||
|
# configs/llama7b.py
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# Read the required dataset configurations directly from the preset dataset configurations
|
||||||
|
from .datasets.piqa.piqa_ppl import piqa_datasets
|
||||||
|
from .datasets.siqa.siqa_gen import siqa_datasets
|
||||||
|
|
||||||
|
# Concatenate the datasets to be evaluated into the datasets field
|
||||||
|
datasets = [*piqa_datasets, *siqa_datasets]
|
||||||
|
|
||||||
|
# Evaluate models supported by HuggingFace's `AutoModelForCausalLM` using `HuggingFaceCausalLM`
|
||||||
|
from opencompass.models import HuggingFaceCausalLM
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceCausalLM,
|
||||||
|
# Initialization parameters for `HuggingFaceCausalLM`
|
||||||
|
path='huggyllama/llama-7b',
|
||||||
|
tokenizer_path='huggyllama/llama-7b',
|
||||||
|
tokenizer_kwargs=dict(padding_side='left', truncation_side='left'),
|
||||||
|
max_seq_len=2048,
|
||||||
|
# Common parameters for all models, not specific to HuggingFaceCausalLM's initialization parameters
|
||||||
|
abbr='llama-7b', # Model abbreviation for result display
|
||||||
|
max_out_len=100, # Maximum number of generated tokens
|
||||||
|
batch_size=16,
|
||||||
|
run_cfg=dict(num_gpus=1), # Run configuration for specifying resource requirements
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## Dataset Configuration File Example
|
||||||
|
|
||||||
|
In the above example configuration file, we directly inherit the dataset-related configurations. Next, we will
|
||||||
|
use the PIQA dataset configuration file as an example to demonstrate the meanings of each field in the dataset
|
||||||
|
configuration file. If you do not intend to modify the prompt for model testing or add new datasets, you can
|
||||||
|
skip this section.
|
||||||
|
|
||||||
|
The PIQA dataset [configuration file](https://github.com/open-compass/opencompass/blob/main/configs/datasets/piqa/piqa_ppl_1cf9f0.py) is as follows.
|
||||||
|
It is a configuration for evaluating based on perplexity (PPL) and does not use In-Context Learning.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||||
|
from opencompass.openicl.icl_inferencer import PPLInferencer
|
||||||
|
from opencompass.openicl.icl_evaluator import AccEvaluator
|
||||||
|
from opencompass.datasets import HFDataset
|
||||||
|
|
||||||
|
# Reading configurations
|
||||||
|
# The loaded dataset is usually organized as dictionaries, specifying the input fields used to form the prompt
|
||||||
|
# and the output field used as the answer in each sample
|
||||||
|
piqa_reader_cfg = dict(
|
||||||
|
input_columns=['goal', 'sol1', 'sol2'],
|
||||||
|
output_column='label',
|
||||||
|
test_split='validation',
|
||||||
|
)
|
||||||
|
|
||||||
|
# Inference configurations
|
||||||
|
piqa_infer_cfg = dict(
|
||||||
|
# Prompt generation configuration
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
# Prompt template, the template format matches the inferencer type specified later
|
||||||
|
# Here, to calculate PPL, we need to specify the prompt template for each answer
|
||||||
|
template={
|
||||||
|
0: 'The following makes sense: \nQ: {goal}\nA: {sol1}\n',
|
||||||
|
1: 'The following makes sense: \nQ: {goal}\nA: {sol2}\n'
|
||||||
|
}),
|
||||||
|
# In-Context example configuration, specifying `ZeroRetriever` here, which means not using in-context example.
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
# Inference method configuration
|
||||||
|
# - PPLInferencer uses perplexity (PPL) to obtain answers
|
||||||
|
# - GenInferencer uses the model's generated results to obtain answers
|
||||||
|
inferencer=dict(type=PPLInferencer))
|
||||||
|
|
||||||
|
# Metric configuration, using Accuracy as the evaluation metric
|
||||||
|
piqa_eval_cfg = dict(evaluator=dict(type=AccEvaluator))
|
||||||
|
|
||||||
|
# Dataset configuration, where all the above variables are parameters for this configuration
|
||||||
|
# It is a list used to specify the configurations of different evaluation subsets of a dataset.
|
||||||
|
piqa_datasets = [
|
||||||
|
dict(
|
||||||
|
type=HFDataset,
|
||||||
|
path='piqa',
|
||||||
|
reader_cfg=piqa_reader_cfg,
|
||||||
|
infer_cfg=piqa_infer_cfg,
|
||||||
|
eval_cfg=piqa_eval_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
For detailed configuration of the **Prompt generation configuration**, you can refer to the [Prompt Template](../prompt/prompt_template.md).
|
||||||
|
|
||||||
|
## Advanced Evaluation Configuration
|
||||||
|
|
||||||
|
In OpenCompass, we support configuration options such as task partitioner and runner for more flexible and
|
||||||
|
efficient utilization of computational resources.
|
||||||
|
|
||||||
|
By default, we use size-based partitioning for inference tasks. You can specify the sample number threshold
|
||||||
|
for task partitioning using `--max-partition-size` when starting the task. Additionally, we use local
|
||||||
|
resources for inference and evaluation tasks by default. If you want to use Slurm cluster resources, you can
|
||||||
|
use the `--slurm` parameter and the `--partition` parameter to specify the Slurm runner backend when starting
|
||||||
|
the task.
|
||||||
|
|
||||||
|
Furthermore, if the above functionalities do not meet your requirements for task partitioning and runner
|
||||||
|
backend configuration, you can provide more detailed configurations in the configuration file. Please refer to
|
||||||
|
[Efficient Evaluation](./evaluation.md) for more information.
|
||||||
|
|
@ -0,0 +1,23 @@
|
||||||
|
# Performance of Common Benchmarks
|
||||||
|
|
||||||
|
We have identified several well-known benchmarks for evaluating large language models (LLMs), and provide detailed performance results of famous LLMs on these datasets.
|
||||||
|
|
||||||
|
| Model | Version | Metric | Mode | GPT-4-1106 | GPT-4-0409 | Claude-3-Opus | Llama-3-70b-Instruct(lmdeploy) | Mixtral-8x22B-Instruct-v0.1 |
|
||||||
|
| -------------------- | ------- | ---------------------------- | ---- | ---------- | ---------- | ------------- | ------------------------------ | --------------------------- |
|
||||||
|
| MMLU | - | naive_average | gen | 83.6 | 84.2 | 84.6 | 80.5 | 77.2 |
|
||||||
|
| CMMLU | - | naive_average | gen | 71.9 | 72.4 | 74.2 | 70.1 | 59.7 |
|
||||||
|
| CEval-Test | - | naive_average | gen | 69.7 | 70.5 | 71.7 | 66.9 | 58.7 |
|
||||||
|
| GaokaoBench | - | weighted_average | gen | 74.8 | 76.0 | 74.2 | 67.8 | 60.0 |
|
||||||
|
| Triviaqa_wiki(1shot) | 01cf41 | score | gen | 73.1 | 82.9 | 82.4 | 89.8 | 89.7 |
|
||||||
|
| NQ_open(1shot) | eaf81e | score | gen | 27.9 | 30.4 | 39.4 | 40.1 | 46.8 |
|
||||||
|
| Race-High | 9a54b6 | accuracy | gen | 89.3 | 89.6 | 90.8 | 89.4 | 84.8 |
|
||||||
|
| WinoGrande | 6447e6 | accuracy | gen | 80.7 | 83.3 | 84.1 | 69.7 | 76.6 |
|
||||||
|
| HellaSwag | e42710 | accuracy | gen | 92.7 | 93.5 | 94.6 | 87.7 | 86.1 |
|
||||||
|
| BBH | - | naive_average | gen | 82.7 | 78.5 | 78.5 | 80.5 | 79.1 |
|
||||||
|
| GSM-8K | 1d7fe4 | accuracy | gen | 80.5 | 79.7 | 87.7 | 90.2 | 88.3 |
|
||||||
|
| Math | 393424 | accuracy | gen | 61.9 | 71.2 | 60.2 | 47.1 | 50 |
|
||||||
|
| TheoremQA | ef26ca | accuracy | gen | 28.4 | 23.3 | 29.6 | 25.4 | 13 |
|
||||||
|
| HumanEval | 8e312c | humaneval_pass@1 | gen | 74.4 | 82.3 | 76.2 | 72.6 | 72.0 |
|
||||||
|
| MBPP(sanitized) | 1e1056 | score | gen | 78.6 | 77.0 | 76.7 | 71.6 | 68.9 |
|
||||||
|
| GPQA_diamond | 4baadb | accuracy | gen | 40.4 | 48.5 | 46.5 | 38.9 | 36.4 |
|
||||||
|
| IFEval | 3321a3 | Prompt-level-strict-accuracy | gen | 71.9 | 79.9 | 80.0 | 77.1 | 65.8 |
|
||||||
|
|
@ -0,0 +1,123 @@
|
||||||
|
# Configure Datasets
|
||||||
|
|
||||||
|
This tutorial mainly focuses on selecting datasets supported by OpenCompass and preparing their configs files. Please make sure you have downloaded the datasets following the steps in [Dataset Preparation](../get_started/installation.md#dataset-preparation).
|
||||||
|
|
||||||
|
## Directory Structure of Dataset Configuration Files
|
||||||
|
|
||||||
|
First, let's introduce the structure under the `configs/datasets` directory in OpenCompass, as shown below:
|
||||||
|
|
||||||
|
```
|
||||||
|
configs/datasets/
|
||||||
|
├── agieval
|
||||||
|
├── apps
|
||||||
|
├── ARC_c
|
||||||
|
├── ...
|
||||||
|
├── CLUE_afqmc # dataset
|
||||||
|
│ ├── CLUE_afqmc_gen_901306.py # different version of config
|
||||||
|
│ ├── CLUE_afqmc_gen.py
|
||||||
|
│ ├── CLUE_afqmc_ppl_378c5b.py
|
||||||
|
│ ├── CLUE_afqmc_ppl_6507d7.py
|
||||||
|
│ ├── CLUE_afqmc_ppl_7b0c1e.py
|
||||||
|
│ └── CLUE_afqmc_ppl.py
|
||||||
|
├── ...
|
||||||
|
├── XLSum
|
||||||
|
├── Xsum
|
||||||
|
└── z_bench
|
||||||
|
```
|
||||||
|
|
||||||
|
In the `configs/datasets` directory structure, we flatten all datasets directly, and there are multiple dataset configurations within the corresponding folders for each dataset.
|
||||||
|
|
||||||
|
The naming of the dataset configuration file is made up of `{dataset name}_{evaluation method}_{prompt version number}.py`. For example, `CLUE_afqmc/CLUE_afqmc_gen_db509b.py`, this configuration file is the `CLUE_afqmc` dataset under the Chinese universal ability, the corresponding evaluation method is `gen`, i.e., generative evaluation, and the corresponding prompt version number is `db509b`; similarly, `CLUE_afqmc_ppl_00b348.py` indicates that the evaluation method is `ppl`, i.e., discriminative evaluation, and the prompt version number is `00b348`.
|
||||||
|
|
||||||
|
In addition, files without a version number, such as: `CLUE_afqmc_gen.py`, point to the latest prompt configuration file of that evaluation method, which is usually the most accurate prompt.
|
||||||
|
|
||||||
|
## Dataset Selection
|
||||||
|
|
||||||
|
In each dataset configuration file, the dataset will be defined in the `{}_datasets` variable, such as `afqmc_datasets` in `CLUE_afqmc/CLUE_afqmc_gen_db509b.py`.
|
||||||
|
|
||||||
|
```python
|
||||||
|
afqmc_datasets = [
|
||||||
|
dict(
|
||||||
|
abbr="afqmc-dev",
|
||||||
|
type=AFQMCDatasetV2,
|
||||||
|
path="./data/CLUE/AFQMC/dev.json",
|
||||||
|
reader_cfg=afqmc_reader_cfg,
|
||||||
|
infer_cfg=afqmc_infer_cfg,
|
||||||
|
eval_cfg=afqmc_eval_cfg,
|
||||||
|
),
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
And `cmnli_datasets` in `CLUE_cmnli/CLUE_cmnli_ppl_b78ad4.py`.
|
||||||
|
|
||||||
|
```python
|
||||||
|
cmnli_datasets = [
|
||||||
|
dict(
|
||||||
|
type=HFDataset,
|
||||||
|
abbr='cmnli',
|
||||||
|
path='json',
|
||||||
|
split='train',
|
||||||
|
data_files='./data/CLUE/cmnli/cmnli_public/dev.json',
|
||||||
|
reader_cfg=cmnli_reader_cfg,
|
||||||
|
infer_cfg=cmnli_infer_cfg,
|
||||||
|
eval_cfg=cmnli_eval_cfg)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
Take these two datasets as examples. If users want to evaluate these two datasets at the same time, they can create a new configuration file in the `configs` directory. We use the import mechanism in the `mmengine` configuration to build the part of the dataset parameters in the evaluation script, as shown below:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.CLUE_afqmc.CLUE_afqmc_gen_db509b import afqmc_datasets
|
||||||
|
from .datasets.CLUE_cmnli.CLUE_cmnli_ppl_b78ad4 import cmnli_datasets
|
||||||
|
|
||||||
|
datasets = []
|
||||||
|
datasets += afqmc_datasets
|
||||||
|
datasets += cmnli_datasets
|
||||||
|
```
|
||||||
|
|
||||||
|
Users can choose different abilities, different datasets and different evaluation methods configuration files to build the part of the dataset in the evaluation script according to their needs.
|
||||||
|
|
||||||
|
For information on how to start an evaluation task and how to evaluate self-built datasets, please refer to the relevant documents.
|
||||||
|
|
||||||
|
### Multiple Evaluations on the Dataset
|
||||||
|
|
||||||
|
In the dataset configuration, you can set the parameter `n` to perform multiple evaluations on the same dataset and return the average metrics, for example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
afqmc_datasets = [
|
||||||
|
dict(
|
||||||
|
abbr="afqmc-dev",
|
||||||
|
type=AFQMCDatasetV2,
|
||||||
|
path="./data/CLUE/AFQMC/dev.json",
|
||||||
|
n=10, # Perform 10 evaluations
|
||||||
|
reader_cfg=afqmc_reader_cfg,
|
||||||
|
infer_cfg=afqmc_infer_cfg,
|
||||||
|
eval_cfg=afqmc_eval_cfg,
|
||||||
|
),
|
||||||
|
]
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, for binary evaluation metrics (such as accuracy, pass-rate, etc.), you can also set the parameter `k` in conjunction with `n` for [G-Pass@k](http://arxiv.org/abs/2412.13147) evaluation. The formula for G-Pass@k is:
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
\text{G-Pass@}k_\tau=E_{\text{Data}}\left[ \sum_{j=\lceil \tau \cdot k \rceil}^c \frac{{c \choose j} \cdot {n - c \choose k - j}}{{n \choose k}} \right],
|
||||||
|
```
|
||||||
|
|
||||||
|
where $n$ is the number of evaluations, and $c$ is the number of times that passed or were correct out of $n$ runs. An example configuration is as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
aime2024_datasets = [
|
||||||
|
dict(
|
||||||
|
abbr='aime2024',
|
||||||
|
type=Aime2024Dataset,
|
||||||
|
path='opencompass/aime2024',
|
||||||
|
k=[2, 4], # Return results for G-Pass@2 and G-Pass@4
|
||||||
|
n=12, # 12 evaluations
|
||||||
|
...
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,192 @@
|
||||||
|
# Tutorial for Evaluating Reasoning Models
|
||||||
|
|
||||||
|
OpenCompass provides an evaluation tutorial for DeepSeek R1 series reasoning models (mathematical datasets).
|
||||||
|
|
||||||
|
- At the model level, we recommend using the sampling approach to reduce repetitions caused by greedy decoding
|
||||||
|
- For datasets with limited samples, we employ multiple evaluation runs and take the average
|
||||||
|
- For answer validation, we utilize LLM-based verification to reduce misjudgments from rule-based evaluation
|
||||||
|
|
||||||
|
## Installation and Preparation
|
||||||
|
|
||||||
|
Please follow OpenCompass's installation guide.
|
||||||
|
|
||||||
|
## Evaluation Configuration Setup
|
||||||
|
|
||||||
|
We provide example configurations in `examples/eval_deepseek_r1.py`. Below is the configuration explanation:
|
||||||
|
|
||||||
|
### Configuration Interpretation
|
||||||
|
|
||||||
|
#### 1. Dataset and Validator Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Configuration supporting multiple runs (example)
|
||||||
|
from opencompass.configs.datasets.aime2024.aime2024_llmverify_repeat8_gen_e8fcee import aime2024_datasets
|
||||||
|
|
||||||
|
datasets = sum(
|
||||||
|
(v for k, v in locals().items() if k.endswith('_datasets')),
|
||||||
|
[],
|
||||||
|
)
|
||||||
|
|
||||||
|
# LLM validator configuration. Users need to deploy API services via LMDeploy/vLLM/SGLang or use OpenAI-compatible endpoints
|
||||||
|
verifier_cfg = dict(
|
||||||
|
abbr='qwen2-5-32B-Instruct',
|
||||||
|
type=OpenAISDK,
|
||||||
|
path='Qwen/Qwen2.5-32B-Instruct', # Replace with actual path
|
||||||
|
key='YOUR_API_KEY', # Use real API key
|
||||||
|
openai_api_base=['http://your-api-endpoint'], # Replace with API endpoint
|
||||||
|
query_per_second=16,
|
||||||
|
batch_size=1024,
|
||||||
|
temperature=0.001,
|
||||||
|
max_out_len=16384
|
||||||
|
)
|
||||||
|
|
||||||
|
# Apply validator to all datasets
|
||||||
|
for item in datasets:
|
||||||
|
if 'judge_cfg' in item['eval_cfg']['evaluator']:
|
||||||
|
item['eval_cfg']['evaluator']['judge_cfg'] = verifier_cfg
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 2. Model Configuration
|
||||||
|
|
||||||
|
We provided an example of evaluation based on LMDeploy as the reasoning model backend, users can modify path (i.e., HF path)
|
||||||
|
|
||||||
|
```python
|
||||||
|
# LMDeploy model configuration example
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr='deepseek-r1-distill-qwen-7b-turbomind',
|
||||||
|
path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B',
|
||||||
|
engine_config=dict(session_len=32768, max_batch_size=128, tp=1),
|
||||||
|
gen_config=dict(
|
||||||
|
do_sample=True,
|
||||||
|
temperature=0.6,
|
||||||
|
top_p=0.95,
|
||||||
|
max_new_tokens=32768
|
||||||
|
),
|
||||||
|
max_seq_len=32768,
|
||||||
|
batch_size=64,
|
||||||
|
run_cfg=dict(num_gpus=1),
|
||||||
|
pred_postprocessor=dict(type=extract_non_reasoning_content)
|
||||||
|
),
|
||||||
|
# Extendable 14B/32B configurations...
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 3. Evaluation Process Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Inference configuration
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=NumWorkerPartitioner, num_worker=1),
|
||||||
|
runner=dict(type=LocalRunner, task=dict(type=OpenICLInferTask))
|
||||||
|
|
||||||
|
# Evaluation configuration
|
||||||
|
eval = dict(
|
||||||
|
partitioner=dict(type=NaivePartitioner, n=8),
|
||||||
|
runner=dict(type=LocalRunner, task=dict(type=OpenICLEvalTask)))
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 4. Summary Configuration
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Multiple runs results average configuration
|
||||||
|
summary_groups = [
|
||||||
|
{
|
||||||
|
'name': 'AIME2024-Aveage8',
|
||||||
|
'subsets':[[f'aime2024-run{idx}', 'accuracy'] for idx in range(8)]
|
||||||
|
},
|
||||||
|
# Other dataset average configurations...
|
||||||
|
]
|
||||||
|
|
||||||
|
summarizer = dict(
|
||||||
|
dataset_abbrs=[
|
||||||
|
['AIME2024-Aveage8', 'naive_average'],
|
||||||
|
# Other dataset metrics...
|
||||||
|
],
|
||||||
|
summary_groups=summary_groups
|
||||||
|
)
|
||||||
|
|
||||||
|
# Work directory configuration
|
||||||
|
work_dir = "outputs/deepseek_r1_reasoning"
|
||||||
|
```
|
||||||
|
|
||||||
|
## Evaluation Execution
|
||||||
|
|
||||||
|
### Scenario 1: Model loaded on 1 GPU, data evaluated by 1 worker, using a total of 1 GPU
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass examples/eval_deepseek_r1.py --debug --dump-eval-details
|
||||||
|
```
|
||||||
|
|
||||||
|
Evaluation logs will be output in the command line.
|
||||||
|
|
||||||
|
### Scenario 2: Model loaded on 1 GPU, data evaluated by 8 workers, using a total of 8 GPUs
|
||||||
|
|
||||||
|
You need to modify the `infer` configuration in the configuration file and set `num_worker` to 8
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Inference configuration
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=NumWorkerPartitioner, num_worker=1),
|
||||||
|
runner=dict(type=LocalRunner, task=dict(type=OpenICLInferTask))
|
||||||
|
```
|
||||||
|
|
||||||
|
At the same time, remove the `--debug` parameter from the evaluation command
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass examples/eval_deepseek_r1.py --dump-eval-details
|
||||||
|
```
|
||||||
|
|
||||||
|
In this mode, OpenCompass will use multithreading to start `$num_worker` tasks. Specific logs will not be displayed in the command line, instead, detailed evaluation logs will be shown under `$work_dir`.
|
||||||
|
|
||||||
|
### Scenario 3: Model loaded on 2 GPUs, data evaluated by 4 workers, using a total of 8 GPUs
|
||||||
|
|
||||||
|
Note that in the model configuration, `num_gpus` in `run_cfg` needs to be set to 2 (if using an inference backend, parameters such as `tp` in LMDeploy also need to be modified accordingly to 2), and at the same time, set `num_worker` in the `infer` configuration to 4
|
||||||
|
|
||||||
|
```python
|
||||||
|
models += [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr='deepseek-r1-distill-qwen-14b-turbomind',
|
||||||
|
path='deepseek-ai/DeepSeek-R1-Distill-Qwen-14B',
|
||||||
|
engine_config=dict(session_len=32768, max_batch_size=128, tp=2),
|
||||||
|
gen_config=dict(
|
||||||
|
do_sample=True,
|
||||||
|
temperature=0.6,
|
||||||
|
top_p=0.95,
|
||||||
|
max_new_tokens=32768),
|
||||||
|
max_seq_len=32768,
|
||||||
|
max_out_len=32768,
|
||||||
|
batch_size=128,
|
||||||
|
run_cfg=dict(num_gpus=2),
|
||||||
|
pred_postprocessor=dict(type=extract_non_reasoning_content)
|
||||||
|
),
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Inference configuration
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=NumWorkerPartitioner, num_worker=4),
|
||||||
|
runner=dict(type=LocalRunner, task=dict(type=OpenICLInferTask))
|
||||||
|
```
|
||||||
|
|
||||||
|
### Evaluation Results
|
||||||
|
|
||||||
|
The evaluation results are displayed as follows:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
dataset version metric mode deepseek-r1-distill-qwen-7b-turbomind ---------------------------------- --------- ------------- ------ --------------------------------------- MATH - - - AIME2024-Aveage8 - naive_average gen 56.25
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
## Performance Baseline
|
||||||
|
|
||||||
|
Since the model uses Sampling for decoding, and the AIME dataset size is small, there may still be a performance fluctuation of 1-3 points even when averaging over 8 evaluations.
|
||||||
|
|
||||||
|
| Model | Dataset | Metric | Value |
|
||||||
|
| ---------------------------- | -------- | -------- | ----- |
|
||||||
|
| DeepSeek-R1-Distill-Qwen-7B | AIME2024 | Accuracy | 56.3 |
|
||||||
|
| DeepSeek-R1-Distill-Qwen-14B | AIME2024 | Accuracy | 74.2 |
|
||||||
|
| DeepSeek-R1-Distill-Qwen-32B | AIME2024 | Accuracy | 74.2 |
|
||||||
|
|
@ -0,0 +1,173 @@
|
||||||
|
# Efficient Evaluation
|
||||||
|
|
||||||
|
OpenCompass supports custom task partitioners (`Partitioner`), which enable flexible division of evaluation tasks. In conjunction with `Runner`, which controls the platform for task execution, such as a local machine or a cluster, OpenCompass can distribute large evaluation tasks to a vast number of computing nodes. This helps utilize computational resources efficiently and significantly accelerates the evaluation process.
|
||||||
|
|
||||||
|
By default, OpenCompass hides these details from users and automatically selects the recommended execution strategies. But users can still customize these strategies of the workflows according to their needs, just by adding the `infer` and/or `eval` fields to the configuration file:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.partitioners import SizePartitioner, NaivePartitioner
|
||||||
|
from opencompass.runners import SlurmRunner
|
||||||
|
from opencompass.tasks import OpenICLInferTask, OpenICLEvalTask
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=SizePartitioner, max_task_size=5000),
|
||||||
|
runner=dict(
|
||||||
|
type=SlurmRunner,
|
||||||
|
max_num_workers=64,
|
||||||
|
task=dict(type=OpenICLInferTask),
|
||||||
|
retry=5),
|
||||||
|
)
|
||||||
|
|
||||||
|
eval = dict(
|
||||||
|
partitioner=dict(type=NaivePartitioner),
|
||||||
|
runner=dict(
|
||||||
|
type=LocalRunner,
|
||||||
|
max_num_workers=32,
|
||||||
|
task=dict(type=OpenICLEvalTask)),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
The example above demonstrates the way to configure the execution strategies for the inference and evaluation stages. At the inference stage, the task will be divided into several sub-tasks, each of 5000 samples, and then submitted to the Slurm cluster for execution, where there are at most 64 tasks running in parallel. At the evaluation stage, each single model-dataset pair forms a task, and 32 processes are launched locally to compute the metrics.
|
||||||
|
|
||||||
|
The following sections will introduce the involved modules in detail.
|
||||||
|
|
||||||
|
## Task Partition (Partitioner)
|
||||||
|
|
||||||
|
Due to the long inference time of large language models and the vast amount of evaluation datasets, serial execution of a single evaluation task can be quite time-consuming. OpenCompass allows custom task partitioners (`Partitioner`) to divide large evaluation tasks into numerous independent smaller tasks, thus fully utilizing computational resources via parallel execution. Users can configure the task partitioning strategies for the inference and evaluation stages via `infer.partitioner` and `eval.partitioner`. Below, we will introduce all the partitioning strategies supported by OpenCompass.
|
||||||
|
|
||||||
|
### `NaivePartitioner`
|
||||||
|
|
||||||
|
This partitioner dispatches each combination of a model and dataset as an independent task. It is the most basic partitioning strategy and does not have any additional parameters.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.partitioners import NaivePartitioner
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=NaivePartitioner)
|
||||||
|
# ...
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
### `SizePartitioner`
|
||||||
|
|
||||||
|
```{warning}
|
||||||
|
For now, this partitioner is not suitable for evaluation tasks (`OpenICLEvalTask`).
|
||||||
|
```
|
||||||
|
|
||||||
|
This partitioner estimates the inference cost (time) of a dataset according to its size, multiplied by an empirical expansion coefficient. It then creates tasks by splitting larger datasets and merging smaller ones to ensure the inference costs of each sub-task are as equal as possible.
|
||||||
|
|
||||||
|
The commonly used parameters for this partitioner are as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.partitioners import SizePartitioner
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(
|
||||||
|
type=SizePartitioner,
|
||||||
|
max_task_size: int = 2000, # Maximum size of each task
|
||||||
|
gen_task_coef: int = 20, # Expansion coefficient for generative tasks
|
||||||
|
),
|
||||||
|
# ...
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
`SizePartitioner` estimates the inference cost of a dataset based on the type of the inference task and selects different expansion coefficients accordingly. For generative tasks, such as those using `GenInferencer`, a larger `gen_task_coef` is set; for discriminative tasks, like those using `PPLInferencer`, the number of labels in the prompt is used.
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
Currently, this partitioning strategy is still rather crude and does not accurately reflect the computational difference between generative and discriminative tasks. We look forward to the community proposing better partitioning strategies :)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Execution Backend (Runner)
|
||||||
|
|
||||||
|
In a multi-card, multi-machine cluster environment, if we want to implement parallel execution of multiple tasks, we usually need to rely on a cluster management system (like Slurm) for task allocation and scheduling. In OpenCompass, task allocation and execution are uniformly handled by the Runner. Currently, it supports both Slurm and PAI-DLC scheduling backends, and also provides a `LocalRunner` to directly launch tasks on the local machine.
|
||||||
|
|
||||||
|
### `LocalRunner`
|
||||||
|
|
||||||
|
`LocalRunner` is the most basic runner that can run tasks parallelly on the local machine.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.runners import LocalRunner
|
||||||
|
from opencompass.tasks import OpenICLInferTask
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
# ...
|
||||||
|
runner=dict(
|
||||||
|
type=LocalRunner,
|
||||||
|
max_num_workers=16, # Maximum number of processes to run in parallel
|
||||||
|
task=dict(type=OpenICLEvalTask), # Task to be run
|
||||||
|
)
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
The actual number of running tasks are both limited by the actual available GPU resources and the number of workers.
|
||||||
|
```
|
||||||
|
|
||||||
|
### `SlurmRunner`
|
||||||
|
|
||||||
|
`SlurmRunner` submits tasks to run on the Slurm cluster. The commonly used configuration fields are as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.runners import SlurmRunner
|
||||||
|
from opencompass.tasks import OpenICLInferTask
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
# ...
|
||||||
|
runner=dict(
|
||||||
|
type=SlurmRunner,
|
||||||
|
task=dict(type=OpenICLEvalTask), # Task to be run
|
||||||
|
max_num_workers=16, # Maximum concurrent evaluation task count
|
||||||
|
retry=2, # Retry count for failed tasks, can prevent accidental errors
|
||||||
|
),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
### `DLCRunner`
|
||||||
|
|
||||||
|
`DLCRunner` submits tasks to run on Alibaba's Deep Learning Center (DLC). This Runner depends on `dlc`. Firstly, you need to prepare `dlc` in the environment:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd ~
|
||||||
|
wget https://dlc-cli.oss-cn-zhangjiakou.aliyuncs.com/light/binary/linux/amd64/dlc
|
||||||
|
chmod +x ./dlc
|
||||||
|
sudo ln -rs dlc /usr/local/bin
|
||||||
|
./dlc config
|
||||||
|
```
|
||||||
|
|
||||||
|
Fill in the necessary information according to the prompts and get the `dlc` configuration file (like `/user/.dlc/config`) to complete the preparation. Then, specify the `DLCRunner` configuration in the configuration file as per the format:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.runners import DLCRunner
|
||||||
|
from opencompass.tasks import OpenICLInferTask
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
# ...
|
||||||
|
runner=dict(
|
||||||
|
type=DLCRunner,
|
||||||
|
task=dict(type=OpenICLEvalTask), # Task to be run
|
||||||
|
max_num_workers=16, # Maximum concurrent evaluation task count
|
||||||
|
aliyun_cfg=dict(
|
||||||
|
bashrc_path="/user/.bashrc", # Path to the bashrc for initializing the running environment
|
||||||
|
conda_env_name='opencompass', # Conda environment for OpenCompass
|
||||||
|
dlc_config_path="/user/.dlc/config", # Configuration file for dlc
|
||||||
|
workspace_id='ws-xxx', # DLC workspace ID
|
||||||
|
worker_image='xxx', # Image url for running tasks
|
||||||
|
),
|
||||||
|
retry=2, # Retry count for failed tasks, can prevent accidental errors
|
||||||
|
),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Task
|
||||||
|
|
||||||
|
A Task is a fundamental module in OpenCompass, a standalone script that executes the computationally intensive operations. Each task is designed to load a configuration file to determine parameter settings, and it can be executed in two distinct ways:
|
||||||
|
|
||||||
|
2. Instantiate a Task object, then call `task.run()`.
|
||||||
|
3. Call `get_command` method by passing in the config path and the command template string that contains `{task_cmd}` as a placeholder (e.g. `srun {task_cmd}`). The returned command string will be the full command and can be executed directly.
|
||||||
|
|
||||||
|
As of now, OpenCompass supports the following task types:
|
||||||
|
|
||||||
|
- `OpenICLInferTask`: Perform LM Inference task based on OpenICL framework.
|
||||||
|
- `OpenICLEvalTask`: Perform LM Evaluation task based on OpenEval framework.
|
||||||
|
|
||||||
|
In the future, more task types will be supported.
|
||||||
|
|
@ -0,0 +1,126 @@
|
||||||
|
# Task Execution and Monitoring
|
||||||
|
|
||||||
|
## Launching an Evaluation Task
|
||||||
|
|
||||||
|
The program entry for the evaluation task is `run.py`. The usage is as follows:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py $EXP {--slurm | --dlc | None} [-p PARTITION] [-q QUOTATYPE] [--debug] [-m MODE] [-r [REUSE]] [-w WORKDIR] [-l] [--dry-run] [--dump-eval-details]
|
||||||
|
```
|
||||||
|
|
||||||
|
Task Configuration (`$EXP`):
|
||||||
|
|
||||||
|
- `run.py` accepts a .py configuration file as task-related parameters, which must include the `datasets` and `models` fields.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_demo.py
|
||||||
|
```
|
||||||
|
|
||||||
|
- If no configuration file is provided, users can also specify models and datasets using `--models MODEL1 MODEL2 ...` and `--datasets DATASET1 DATASET2 ...`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --models hf_opt_350m hf_opt_125m --datasets siqa_gen winograd_ppl
|
||||||
|
```
|
||||||
|
|
||||||
|
- For HuggingFace related models, users can also define a model quickly in the command line through HuggingFace parameters and then specify datasets using `--datasets DATASET1 DATASET2 ...`.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --datasets siqa_gen winograd_ppl --hf-type base --hf-path huggyllama/llama-7b
|
||||||
|
```
|
||||||
|
|
||||||
|
Complete HuggingFace parameter descriptions:
|
||||||
|
|
||||||
|
- `--hf-path`: HuggingFace model path
|
||||||
|
- `--peft-path`: PEFT model path
|
||||||
|
- `--tokenizer-path`: HuggingFace tokenizer path (if it's the same as the model path, it can be omitted)
|
||||||
|
- `--model-kwargs`: Parameters for constructing the model
|
||||||
|
- `--tokenizer-kwargs`: Parameters for constructing the tokenizer
|
||||||
|
- `--max-out-len`: Maximum generated token count
|
||||||
|
- `--max-seq-len`: Maximum sequence length the model can accept
|
||||||
|
- `--batch-size`: Batch size
|
||||||
|
- `--hf-num-gpus`: Number of GPUs required to run the model. Please note that this parameter is only used to determine the number of GPUs required to run the model, and does not affect the actual number of GPUs used for the task. Refer to [Efficient Evaluation](./evaluation.md) for more details.
|
||||||
|
|
||||||
|
Starting Methods:
|
||||||
|
|
||||||
|
- Running on local machine: `run.py $EXP`.
|
||||||
|
- Running with slurm: `run.py $EXP --slurm -p $PARTITION_name`.
|
||||||
|
- Running with dlc: `run.py $EXP --dlc --aliyun-cfg $AliYun_Cfg`
|
||||||
|
- Customized starting: `run.py $EXP`. Here, $EXP is the configuration file which includes the `eval` and `infer` fields. For detailed configurations, please refer to [Efficient Evaluation](./evaluation.md).
|
||||||
|
|
||||||
|
The parameter explanation is as follows:
|
||||||
|
|
||||||
|
- `-p`: Specify the slurm partition;
|
||||||
|
- `-q`: Specify the slurm quotatype (default is None), with optional values being reserved, auto, spot. This parameter may only be used in some slurm variants;
|
||||||
|
- `--debug`: When enabled, inference and evaluation tasks will run in single-process mode, and output will be echoed in real-time for debugging;
|
||||||
|
- `-m`: Running mode, default is `all`. It can be specified as `infer` to only run inference and obtain output results; if there are already model outputs in `{WORKDIR}`, it can be specified as `eval` to only run evaluation and obtain evaluation results; if the evaluation results are ready, it can be specified as `viz` to only run visualization, which summarizes the results in tables; if specified as `all`, a full run will be performed, which includes inference, evaluation, and visualization.
|
||||||
|
- `-r`: Reuse existing inference results, and skip the finished tasks. If followed by a timestamp, the result under that timestamp in the workspace path will be reused; otherwise, the latest result in the specified workspace path will be reused.
|
||||||
|
- `-w`: Specify the working path, default is `./outputs/default`.
|
||||||
|
- `-l`: Enable status reporting via Lark bot.
|
||||||
|
- `--dry-run`: When enabled, inference and evaluation tasks will be dispatched but won't actually run for debugging.
|
||||||
|
- `--dump-eval-details`: When enabled,evaluation under the `results` folder will include more details, such as the correctness of each sample.
|
||||||
|
|
||||||
|
Using run mode `-m all` as an example, the overall execution flow is as follows:
|
||||||
|
|
||||||
|
1. Read the configuration file, parse out the model, dataset, evaluator, and other configuration information
|
||||||
|
2. The evaluation task mainly includes three stages: inference `infer`, evaluation `eval`, and visualization `viz`. After task division by Partitioner, they are handed over to Runner for parallel execution. Individual inference and evaluation tasks are abstracted into `OpenICLInferTask` and `OpenICLEvalTask` respectively.
|
||||||
|
3. After each stage ends, the visualization stage will read the evaluation results in `results/` to generate a table.
|
||||||
|
|
||||||
|
## Task Monitoring: Lark Bot
|
||||||
|
|
||||||
|
Users can enable real-time monitoring of task status by setting up a Lark bot. Please refer to [this document](https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN?lang=zh-CN#7a28964d) for setting up the Lark bot.
|
||||||
|
|
||||||
|
Configuration method:
|
||||||
|
|
||||||
|
1. Open the `configs/lark.py` file, and add the following line:
|
||||||
|
|
||||||
|
```python
|
||||||
|
lark_bot_url = 'YOUR_WEBHOOK_URL'
|
||||||
|
```
|
||||||
|
|
||||||
|
Typically, the Webhook URL is formatted like this: https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxxxxxxxxxxxxx .
|
||||||
|
|
||||||
|
2. Inherit this file in the complete evaluation configuration:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .lark import lark_bot_url
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
3. To avoid frequent messages from the bot becoming a nuisance, status updates are not automatically reported by default. You can start status reporting using `-l` or `--lark` when needed:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_demo.py -p {PARTITION} -l
|
||||||
|
```
|
||||||
|
|
||||||
|
## Run Results
|
||||||
|
|
||||||
|
All run results will be placed in `outputs/default/` directory by default, the directory structure is shown below:
|
||||||
|
|
||||||
|
```
|
||||||
|
outputs/default/
|
||||||
|
├── 20200220_120000
|
||||||
|
├── ...
|
||||||
|
├── 20230220_183030
|
||||||
|
│ ├── configs
|
||||||
|
│ ├── logs
|
||||||
|
│ │ ├── eval
|
||||||
|
│ │ └── infer
|
||||||
|
│ ├── predictions
|
||||||
|
│ │ └── MODEL1
|
||||||
|
│ └── results
|
||||||
|
│ └── MODEL1
|
||||||
|
```
|
||||||
|
|
||||||
|
Each timestamp contains the following content:
|
||||||
|
|
||||||
|
- configs folder, which stores the configuration files corresponding to each run with this timestamp as the output directory;
|
||||||
|
- logs folder, which stores the output log files of the inference and evaluation phases, each folder will store logs in subfolders by model;
|
||||||
|
- predictions folder, which stores the inferred json results, with a model subfolder;
|
||||||
|
- results folder, which stores the evaluated json results, with a model subfolder.
|
||||||
|
|
||||||
|
Also, all `-r` without specifying a corresponding timestamp will select the newest folder by sorting as the output directory.
|
||||||
|
|
||||||
|
## Introduction of Summerizer (to be updated)
|
||||||
|
|
@ -0,0 +1,90 @@
|
||||||
|
# Overview
|
||||||
|
|
||||||
|
## Evaluation Targets
|
||||||
|
|
||||||
|
The primary evaluation targets of this algorithm library are large language models. We introduce specific model types for evaluation using the large language model as an example.
|
||||||
|
|
||||||
|
- base Model: Typically obtained through training on massive textual data in a self-supervised manner (e.g., OpenAI's GPT-3, Meta's LLaMA). These models usually have powerful text continuation capabilities.
|
||||||
|
|
||||||
|
- Chat Model: Often built upon the base model and refined through directive fine-tuning or human preference alignment (e.g., OpenAI's ChatGPT, Shanghai AI Lab's Scholar Pu Tongue). These models can understand human instructions and have strong conversational skills.
|
||||||
|
|
||||||
|
## Tool Architecture
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
- Model Layer: This encompasses the primary model categories involved in large model evaluations. OpenCompass focuses on base models and chat models for in-depth evaluations.
|
||||||
|
- Capability Layer: OpenCompass evaluates models based on general capabilities and special features. In terms of general capabilities, models are evaluated on language, knowledge, understanding, reasoning, safety, and other dimensions. In terms of special capabilities, evaluations are based on long texts, code, tools, and knowledge enhancement.
|
||||||
|
- Method Layer: OpenCompass uses both objective and subjective evaluation methods. Objective evaluations can quickly assess a model's capability in tasks with definite answers (like multiple choice, fill in the blanks, closed-ended questions), while subjective evaluations measure user satisfaction with the model's replies. OpenCompass uses both model-assisted subjective evaluations and human feedback-driven subjective evaluations.
|
||||||
|
- Tool Layer: OpenCompass offers extensive functionalities for automated, efficient evaluations of large language models. This includes distributed evaluation techniques, prompt engineering, integration with evaluation databases, leaderboard publishing, report generation, and many more features.
|
||||||
|
|
||||||
|
## Capability Dimensions
|
||||||
|
|
||||||
|
### Design Philosophy
|
||||||
|
|
||||||
|
To accurately, comprehensively, and systematically assess the capabilities of large language models, OpenCompass takes a general AI perspective, integrating cutting-edge academic advancements and industrial best practices to propose an evaluation system tailored for real-world applications. OpenCompass's capability dimensions cover both general capabilities and special features.
|
||||||
|
|
||||||
|
### General Capabilities
|
||||||
|
|
||||||
|
General capabilities encompass examination, knowledge, language, understanding, reasoning, and safety, forming a comprehensive evaluation system across these six dimensions.
|
||||||
|
|
||||||
|
#### Examination Capability
|
||||||
|
|
||||||
|
This dimension aims to provide evaluation support from the perspective of human development, borrowing the classification logic from pedagogy. The core idea revolves around mandatory education, higher education, and vocational training, creating a comprehensive academic capability evaluation approach.
|
||||||
|
|
||||||
|
#### Knowledge Capability
|
||||||
|
|
||||||
|
Knowledge capability gauges the model's grasp on various knowledge types, including but not limited to general world knowledge and domain-specific expertise. This capability hopes that the model can answer a wide range of knowledge-based questions accurately and comprehensively.
|
||||||
|
|
||||||
|
#### Reasoning Capability
|
||||||
|
|
||||||
|
Reasoning is a crucial dimension for general AI. This evaluates the model's reasoning skills, including but not limited to mathematical computation, logical reasoning, causal inference, code generation and modification, and more.
|
||||||
|
|
||||||
|
#### Understanding Capability
|
||||||
|
|
||||||
|
This dimension evaluates the model's comprehension of text, including:
|
||||||
|
|
||||||
|
- Rhetorical techniques understanding and analysis: Grasping various rhetorical techniques used in text and analyzing and interpreting them.
|
||||||
|
- Text content summarization: Summarizing and extracting information from given content.
|
||||||
|
- Content creation: Open-ended or semi-open-ended content creation based on given themes or requirements.
|
||||||
|
|
||||||
|
#### Language Capability
|
||||||
|
|
||||||
|
This dimension evaluates the model's prior language knowledge, which includes but is not limited to:
|
||||||
|
|
||||||
|
- Word recognition and generation: Understanding language at the word level and tasks like word recognition, classification, definition, and generation.
|
||||||
|
- Grammar understanding and correction: Grasping grammar within the text and identifying and correcting grammatical errors.
|
||||||
|
- Cross-language translation: Translating given source language into target languages, assessing multilingual capabilities of current large models.
|
||||||
|
|
||||||
|
#### Safety Capability
|
||||||
|
|
||||||
|
In conjunction with the technical features of large language models, OpenCompass assesses the legality, compliance, and safety of model outputs, aiding the development of safe and responsible large models. This capability includes but is not limited to:
|
||||||
|
|
||||||
|
- Fairness
|
||||||
|
- Legality
|
||||||
|
- Harmlessness
|
||||||
|
- Ethical considerations
|
||||||
|
- Privacy protection
|
||||||
|
|
||||||
|
## Evaluation Methods
|
||||||
|
|
||||||
|
OpenCompass adopts a combination of objective and subjective evaluations. For capability dimensions and scenarios with definite answers, a comprehensive assessment of model capabilities is conducted using a well-constructed test set. For open-ended or semi-open-ended questions and model safety issues, a combination of objective and subjective evaluation methods is used.
|
||||||
|
|
||||||
|
### Objective Evaluation
|
||||||
|
|
||||||
|
For objective questions with standard answers, we can compare the discrepancy between the model's output and the standard answer using quantitative indicators. Given the high freedom in outputs of large language models, during evaluation, it's essential to standardize and design its inputs and outputs to minimize the influence of noisy outputs, ensuring a more comprehensive and objective assessment.
|
||||||
|
|
||||||
|
To better elicit the model's abilities in the evaluation domain and guide the model to output answers following specific templates, OpenCompass employs prompt engineering and in-context learning for objective evaluations.
|
||||||
|
|
||||||
|
In practice, we usually adopt the following two methods to evaluate model outputs:
|
||||||
|
|
||||||
|
- **Discriminative Evaluation**: This approach combines questions with candidate answers, calculates the model's perplexity on all combinations, and selects the answer with the lowest perplexity as the model's final output.
|
||||||
|
|
||||||
|
- **Generative Evaluation**: Used for generative tasks like language translation, code generation, logical analysis, etc. The question is used as the model's original input, leaving the answer area blank for the model to fill in. Post-processing of the output is often required to ensure it meets dataset requirements.
|
||||||
|
|
||||||
|
### Subjective Evaluation (Upcoming)
|
||||||
|
|
||||||
|
Language expression is lively and varied, and many scenarios and capabilities can't be judged solely by objective indicators. For evaluations like model safety and language capabilities, subjective evaluations based on human feelings better reflect the model's actual capabilities and align more with real-world applications.
|
||||||
|
|
||||||
|
OpenCompass's subjective evaluation approach relies on test subject's personal judgments to assess chat-capable large language models. In practice, we pre-construct a set of subjective test questions based on model capabilities and present different replies from various models to the same question to subjects, collecting their subjective scores. Given the high cost of subjective testing, this approach also uses high-performing large language models to simulate human subjective scoring. Actual evaluations will combine real human expert subjective evaluations with model-based subjective scores.
|
||||||
|
|
||||||
|
In conducting subjective evaluations, OpenCompass uses both **Single Model Reply Satisfaction Statistics** and **Multiple Model Satisfaction** Comparison methods.
|
||||||
|
|
@ -0,0 +1,63 @@
|
||||||
|
# Metric Calculation
|
||||||
|
|
||||||
|
In the evaluation phase, we typically select the corresponding evaluation metric strategy based on the characteristics of the dataset itself. The main criterion is the **type of standard answer**, generally including the following types:
|
||||||
|
|
||||||
|
- **Choice**: Common in classification tasks, judgment questions, and multiple-choice questions. Currently, this type of question dataset occupies the largest proportion, with datasets such as MMLU, CEval, etc. Accuracy is usually used as the evaluation standard-- `ACCEvaluator`.
|
||||||
|
- **Phrase**: Common in Q&A and reading comprehension tasks. This type of dataset mainly includes CLUE_CMRC, CLUE_DRCD, DROP datasets, etc. Matching rate is usually used as the evaluation standard--`EMEvaluator`.
|
||||||
|
- **Sentence**: Common in translation and generating pseudocode/command-line tasks, mainly including Flores, Summscreen, Govrepcrs, Iwdlt2017 datasets, etc. BLEU (Bilingual Evaluation Understudy) is usually used as the evaluation standard--`BleuEvaluator`.
|
||||||
|
- **Paragraph**: Common in text summary generation tasks, commonly used datasets mainly include Lcsts, TruthfulQA, Xsum datasets, etc. ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is usually used as the evaluation standard--`RougeEvaluator`.
|
||||||
|
- **Code**: Common in code generation tasks, commonly used datasets mainly include Humaneval, MBPP datasets, etc. Execution pass rate and `pass@k` are usually used as the evaluation standard. At present, Opencompass supports `MBPPEvaluator` and `HumanEvalEvaluator`.
|
||||||
|
|
||||||
|
There is also a type of **scoring-type** evaluation task without standard answers, such as judging whether the output of a model is toxic, which can directly use the related API service for scoring. At present, it supports `ToxicEvaluator`, and currently, the realtoxicityprompts dataset uses this evaluation method.
|
||||||
|
|
||||||
|
## Supported Evaluation Metrics
|
||||||
|
|
||||||
|
Currently, in OpenCompass, commonly used Evaluators are mainly located in the [`opencompass/openicl/icl_evaluator`](https://github.com/open-compass/opencompass/tree/main/opencompass/openicl/icl_evaluator) folder. There are also some dataset-specific indicators that are placed in parts of [`opencompass/datasets`](https://github.com/open-compass/opencompass/tree/main/opencompass/datasets). Below is a summary:
|
||||||
|
|
||||||
|
| Evaluation Strategy | Evaluation Metrics | Common Postprocessing Method | Datasets |
|
||||||
|
| --------------------- | -------------------- | ---------------------------- | -------------------------------------------------------------------- |
|
||||||
|
| `ACCEvaluator` | Accuracy | `first_capital_postprocess` | agieval, ARC, bbh, mmlu, ceval, commonsenseqa, crowspairs, hellaswag |
|
||||||
|
| `EMEvaluator` | Match Rate | None, dataset-specific | drop, CLUE_CMRC, CLUE_DRCD |
|
||||||
|
| `BleuEvaluator` | BLEU | None, `flores` | flores, iwslt2017, summscreen, govrepcrs |
|
||||||
|
| `RougeEvaluator` | ROUGE | None, dataset-specific | truthfulqa, Xsum, XLSum |
|
||||||
|
| `JiebaRougeEvaluator` | ROUGE | None, dataset-specific | lcsts |
|
||||||
|
| `HumanEvalEvaluator` | pass@k | `humaneval_postprocess` | humaneval_postprocess |
|
||||||
|
| `MBPPEvaluator` | Execution Pass Rate | None | mbpp |
|
||||||
|
| `ToxicEvaluator` | PerspectiveAPI | None | realtoxicityprompts |
|
||||||
|
| `AGIEvalEvaluator` | Accuracy | None | agieval |
|
||||||
|
| `AUCROCEvaluator` | AUC-ROC | None | jigsawmultilingual, civilcomments |
|
||||||
|
| `MATHEvaluator` | Accuracy | `math_postprocess` | math |
|
||||||
|
| `MccEvaluator` | Matthews Correlation | None | -- |
|
||||||
|
| `SquadEvaluator` | F1-scores | None | -- |
|
||||||
|
|
||||||
|
## How to Configure
|
||||||
|
|
||||||
|
The evaluation standard configuration is generally placed in the dataset configuration file, and the final xxdataset_eval_cfg will be passed to `dataset.infer_cfg` as an instantiation parameter.
|
||||||
|
|
||||||
|
Below is the definition of `govrepcrs_eval_cfg`, and you can refer to [configs/datasets/govrepcrs](https://github.com/open-compass/opencompass/tree/main/configs/datasets/govrepcrs).
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.openicl.icl_evaluator import BleuEvaluator
|
||||||
|
from opencompass.datasets import GovRepcrsDataset
|
||||||
|
from opencompass.utils.text_postprocessors import general_cn_postprocess
|
||||||
|
|
||||||
|
govrepcrs_reader_cfg = dict(.......)
|
||||||
|
govrepcrs_infer_cfg = dict(.......)
|
||||||
|
|
||||||
|
# Configuration of evaluation metrics
|
||||||
|
govrepcrs_eval_cfg = dict(
|
||||||
|
evaluator=dict(type=BleuEvaluator), # Use the common translator evaluator BleuEvaluator
|
||||||
|
pred_role='BOT', # Accept 'BOT' role output
|
||||||
|
pred_postprocessor=dict(type=general_cn_postprocess), # Postprocessing of prediction results
|
||||||
|
dataset_postprocessor=dict(type=general_cn_postprocess)) # Postprocessing of dataset standard answers
|
||||||
|
|
||||||
|
govrepcrs_datasets = [
|
||||||
|
dict(
|
||||||
|
type=GovRepcrsDataset, # Dataset class name
|
||||||
|
path='./data/govrep/', # Dataset path
|
||||||
|
abbr='GovRepcrs', # Dataset alias
|
||||||
|
reader_cfg=govrepcrs_reader_cfg, # Dataset reading configuration file, configure its reading split, column, etc.
|
||||||
|
infer_cfg=govrepcrs_infer_cfg, # Dataset inference configuration file, mainly related to prompt
|
||||||
|
eval_cfg=govrepcrs_eval_cfg) # Dataset result evaluation configuration file, evaluation standard, and preprocessing and postprocessing.
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,111 @@
|
||||||
|
# Prepare Models
|
||||||
|
|
||||||
|
To support the evaluation of new models in OpenCompass, there are several ways:
|
||||||
|
|
||||||
|
1. HuggingFace-based models
|
||||||
|
2. API-based models
|
||||||
|
3. Custom models
|
||||||
|
|
||||||
|
## HuggingFace-based Models
|
||||||
|
|
||||||
|
In OpenCompass, we support constructing evaluation models directly from HuggingFace's
|
||||||
|
`AutoModel.from_pretrained` and `AutoModelForCausalLM.from_pretrained` interfaces. If the model to be
|
||||||
|
evaluated follows the typical generation interface of HuggingFace models, there is no need to write code. You
|
||||||
|
can simply specify the relevant configurations in the configuration file.
|
||||||
|
|
||||||
|
Here is an example configuration file for a HuggingFace-based model:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Use `HuggingFace` to evaluate models supported by AutoModel.
|
||||||
|
# Use `HuggingFaceCausalLM` to evaluate models supported by AutoModelForCausalLM.
|
||||||
|
from opencompass.models import HuggingFaceCausalLM
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceCausalLM,
|
||||||
|
# Parameters for `HuggingFaceCausalLM` initialization.
|
||||||
|
path='huggyllama/llama-7b',
|
||||||
|
tokenizer_path='huggyllama/llama-7b',
|
||||||
|
tokenizer_kwargs=dict(padding_side='left', truncation_side='left'),
|
||||||
|
max_seq_len=2048,
|
||||||
|
batch_padding=False,
|
||||||
|
# Common parameters shared by various models, not specific to `HuggingFaceCausalLM` initialization.
|
||||||
|
abbr='llama-7b', # Model abbreviation used for result display.
|
||||||
|
max_out_len=100, # Maximum number of generated tokens.
|
||||||
|
batch_size=16, # The size of a batch during inference.
|
||||||
|
run_cfg=dict(num_gpus=1), # Run configuration to specify resource requirements.
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
Explanation of some of the parameters:
|
||||||
|
|
||||||
|
- `batch_padding=False`: If set to False, each sample in a batch will be inferred individually. If set to True,
|
||||||
|
a batch of samples will be padded and inferred together. For some models, such padding may lead to
|
||||||
|
unexpected results. If the model being evaluated supports sample padding, you can set this parameter to True
|
||||||
|
to speed up inference.
|
||||||
|
- `padding_side='left'`: Perform padding on the left side. Not all models support padding, and padding on the
|
||||||
|
right side may interfere with the model's output.
|
||||||
|
- `truncation_side='left'`: Perform truncation on the left side. The input prompt for evaluation usually
|
||||||
|
consists of both the in-context examples prompt and the input prompt. If the right side of the input prompt
|
||||||
|
is truncated, it may cause the input of the generation model to be inconsistent with the expected format.
|
||||||
|
Therefore, if necessary, truncation should be performed on the left side.
|
||||||
|
|
||||||
|
During evaluation, OpenCompass will instantiate the evaluation model based on the `type` and the
|
||||||
|
initialization parameters specified in the configuration file. Other parameters are used for inference,
|
||||||
|
summarization, and other processes related to the model. For example, in the above configuration file, we will
|
||||||
|
instantiate the model as follows during evaluation:
|
||||||
|
|
||||||
|
```python
|
||||||
|
model = HuggingFaceCausalLM(
|
||||||
|
path='huggyllama/llama-7b',
|
||||||
|
tokenizer_path='huggyllama/llama-7b',
|
||||||
|
tokenizer_kwargs=dict(padding_side='left', truncation_side='left'),
|
||||||
|
max_seq_len=2048,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## API-based Models
|
||||||
|
|
||||||
|
Currently, OpenCompass supports API-based model inference for the following:
|
||||||
|
|
||||||
|
- OpenAI (`opencompass.models.OpenAI`)
|
||||||
|
- ChatGLM (`opencompass.models.ZhiPuAI`)
|
||||||
|
- ABAB-Chat from MiniMax (`opencompass.models.MiniMax`)
|
||||||
|
- XunFei from XunFei (`opencompass.models.XunFei`)
|
||||||
|
|
||||||
|
Let's take the OpenAI configuration file as an example to see how API-based models are used in the
|
||||||
|
configuration file.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.models import OpenAI
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=OpenAI, # Using the OpenAI model
|
||||||
|
# Parameters for `OpenAI` initialization
|
||||||
|
path='gpt-4', # Specify the model type
|
||||||
|
key='YOUR_OPENAI_KEY', # OpenAI API Key
|
||||||
|
max_seq_len=2048, # The max input number of tokens
|
||||||
|
# Common parameters shared by various models, not specific to `OpenAI` initialization.
|
||||||
|
abbr='GPT-4', # Model abbreviation used for result display.
|
||||||
|
max_out_len=512, # Maximum number of generated tokens.
|
||||||
|
batch_size=1, # The size of a batch during inference.
|
||||||
|
run_cfg=dict(num_gpus=0), # Resource requirements (no GPU needed)
|
||||||
|
),
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
We have provided several examples for API-based models. Please refer to
|
||||||
|
|
||||||
|
```bash
|
||||||
|
configs
|
||||||
|
├── eval_zhipu.py
|
||||||
|
├── eval_xunfei.py
|
||||||
|
└── eval_minimax.py
|
||||||
|
```
|
||||||
|
|
||||||
|
## Custom Models
|
||||||
|
|
||||||
|
If the above methods do not support your model evaluation requirements, you can refer to
|
||||||
|
[Supporting New Models](../advanced_guides/new_model.md) to add support for new models in OpenCompass.
|
||||||
|
|
@ -0,0 +1,60 @@
|
||||||
|
# Results Summary
|
||||||
|
|
||||||
|
After the evaluation is complete, the results need to be printed on the screen or saved. This process is controlled by the summarizer.
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
If the summarizer appears in the overall config, all the evaluation results will be output according to the following logic.
|
||||||
|
If the summarizer does not appear in the overall config, the evaluation results will be output in the order they appear in the `dataset` config.
|
||||||
|
```
|
||||||
|
|
||||||
|
## Example
|
||||||
|
|
||||||
|
A typical summarizer configuration file is as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
summarizer = dict(
|
||||||
|
dataset_abbrs = [
|
||||||
|
'race',
|
||||||
|
'race-high',
|
||||||
|
'race-middle',
|
||||||
|
],
|
||||||
|
summary_groups=[
|
||||||
|
{'name': 'race', 'subsets': ['race-high', 'race-middle']},
|
||||||
|
]
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
The output is:
|
||||||
|
|
||||||
|
```text
|
||||||
|
dataset version metric mode internlm-7b-hf
|
||||||
|
----------- --------- ------------- ------ ----------------
|
||||||
|
race - naive_average ppl 76.23
|
||||||
|
race-high 0c332f accuracy ppl 74.53
|
||||||
|
race-middle 0c332f accuracy ppl 77.92
|
||||||
|
```
|
||||||
|
|
||||||
|
The summarizer tries to read the evaluation scores from the `{work_dir}/results/` directory using the `models` and `datasets` in the config as the full set. It then displays them in the order of the `summarizer.dataset_abbrs` list. Moreover, the summarizer tries to compute some aggregated metrics using `summarizer.summary_groups`. The `name` metric is only generated if and only if all values in `subsets` exist. This means if some scores are missing, the aggregated metric will also be missing. If scores can't be fetched by the above methods, the summarizer will use `-` in the respective cell of the table.
|
||||||
|
|
||||||
|
In addition, the output consists of multiple columns:
|
||||||
|
|
||||||
|
- The `dataset` column corresponds to the `summarizer.dataset_abbrs` configuration.
|
||||||
|
- The `version` column is the hash value of the dataset, which considers the dataset's evaluation method, prompt words, output length limit, etc. Users can verify whether two evaluation results are comparable using this column.
|
||||||
|
- The `metric` column indicates the evaluation method of this metric. For specific details, [metrics](./metrics.md).
|
||||||
|
- The `mode` column indicates how the inference result is obtained. Possible values are `ppl` / `gen`. For items in `summarizer.summary_groups`, if the methods of obtaining `subsets` are consistent, its value will be the same as subsets, otherwise it will be `mixed`.
|
||||||
|
- The subsequent columns represent different models.
|
||||||
|
|
||||||
|
## Field Description
|
||||||
|
|
||||||
|
The fields of summarizer are explained as follows:
|
||||||
|
|
||||||
|
- `dataset_abbrs`: (list, optional) Display list items. If omitted, all evaluation results will be output.
|
||||||
|
- `summary_groups`: (list, optional) Configuration for aggregated metrics.
|
||||||
|
|
||||||
|
The fields in `summary_groups` are:
|
||||||
|
|
||||||
|
- `name`: (str) Name of the aggregated metric.
|
||||||
|
- `subsets`: (list) Names of the metrics that are aggregated. Note that it can not only be the original `dataset_abbr` but also the name of another aggregated metric.
|
||||||
|
- `weights`: (list, optional) Weights of the metrics being aggregated. If omitted, the default is to use unweighted averaging.
|
||||||
|
|
||||||
|
Please note that we have stored the summary groups of datasets like MMLU, C-Eval, etc., under the `configs/summarizers/groups` path. It's recommended to consider using them first.
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
version: 2
|
||||||
|
|
||||||
|
# Set the version of Python and other tools you might need
|
||||||
|
build:
|
||||||
|
os: ubuntu-22.04
|
||||||
|
tools:
|
||||||
|
python: "3.8"
|
||||||
|
|
||||||
|
formats:
|
||||||
|
- epub
|
||||||
|
|
||||||
|
sphinx:
|
||||||
|
configuration: docs/zh_cn/conf.py
|
||||||
|
|
||||||
|
python:
|
||||||
|
install:
|
||||||
|
- requirements: requirements/docs.txt
|
||||||
|
|
@ -0,0 +1,20 @@
|
||||||
|
# Minimal makefile for Sphinx documentation
|
||||||
|
#
|
||||||
|
|
||||||
|
# You can set these variables from the command line, and also
|
||||||
|
# from the environment for the first two.
|
||||||
|
SPHINXOPTS ?=
|
||||||
|
SPHINXBUILD ?= sphinx-build
|
||||||
|
SOURCEDIR = .
|
||||||
|
BUILDDIR = _build
|
||||||
|
|
||||||
|
# Put it first so that "make" without argument is like "make help".
|
||||||
|
help:
|
||||||
|
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||||
|
|
||||||
|
.PHONY: help Makefile
|
||||||
|
|
||||||
|
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||||
|
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||||
|
%: Makefile
|
||||||
|
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||||
|
|
@ -0,0 +1,62 @@
|
||||||
|
.header-logo {
|
||||||
|
background-image: url("../image/logo.svg");
|
||||||
|
background-size: 275px 80px;
|
||||||
|
height: 80px;
|
||||||
|
width: 275px;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media screen and (min-width: 1100px) {
|
||||||
|
.header-logo {
|
||||||
|
top: -25px;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
pre {
|
||||||
|
white-space: pre;
|
||||||
|
}
|
||||||
|
|
||||||
|
@media screen and (min-width: 2000px) {
|
||||||
|
.pytorch-content-left {
|
||||||
|
width: 1200px;
|
||||||
|
margin-left: 30px;
|
||||||
|
}
|
||||||
|
article.pytorch-article {
|
||||||
|
max-width: 1200px;
|
||||||
|
}
|
||||||
|
.pytorch-breadcrumbs-wrapper {
|
||||||
|
width: 1200px;
|
||||||
|
}
|
||||||
|
.pytorch-right-menu.scrolling-fixed {
|
||||||
|
position: fixed;
|
||||||
|
top: 45px;
|
||||||
|
left: 1580px;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
article.pytorch-article section code {
|
||||||
|
padding: .2em .4em;
|
||||||
|
background-color: #f3f4f7;
|
||||||
|
border-radius: 5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
/* Disable the change in tables */
|
||||||
|
article.pytorch-article section table code {
|
||||||
|
padding: unset;
|
||||||
|
background-color: unset;
|
||||||
|
border-radius: unset;
|
||||||
|
}
|
||||||
|
|
||||||
|
table.autosummary td {
|
||||||
|
width: 50%
|
||||||
|
}
|
||||||
|
|
||||||
|
img.align-center {
|
||||||
|
display: block;
|
||||||
|
margin-left: auto;
|
||||||
|
margin-right: auto;
|
||||||
|
}
|
||||||
|
|
||||||
|
article.pytorch-article p.rubric {
|
||||||
|
font-weight: bold;
|
||||||
|
}
|
||||||
{kind=link}
|
|
@ -0,0 +1,79 @@
|
||||||
|
<?xml version="1.0" encoding="utf-8"?>
|
||||||
|
<!-- Generator: Adobe Illustrator 27.3.1, SVG Export Plug-In . SVG Version: 6.00 Build 0) -->
|
||||||
|
<svg version="1.1" id="图层_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" x="0px" y="0px"
|
||||||
|
viewBox="0 0 210 36" style="enable-background:new 0 0 210 36;" xml:space="preserve">
|
||||||
|
<style type="text/css">
|
||||||
|
.st0{fill:#5878B4;}
|
||||||
|
.st1{fill:#36569B;}
|
||||||
|
.st2{fill:#1B3882;}
|
||||||
|
</style>
|
||||||
|
<g id="_x33_">
|
||||||
|
<g>
|
||||||
|
<path class="st0" d="M16.5,22.6l-6.4,3.1l5.3-0.2L16.5,22.6z M12.3,33.6l1.1-2.9l-5.3,0.2L12.3,33.6z M21.6,33.3l6.4-3.1l-5.3,0.2
|
||||||
|
L21.6,33.3z M25.8,22.4l-1.1,2.9l5.3-0.2L25.8,22.4z M31.5,26.2l-7.1,0.2l-1.7-1.1l1.5-4L22.2,20L19,21.5l-1.5,3.9l-2.7,1.3
|
||||||
|
l-7.1,0.2l-3.2,1.5l2.1,1.4l7.1-0.2l0,0l1.7,1.1l-1.5,4L16,36l3.2-1.5l1.5-3.9l0,0l2.6-1.2l0,0l7.2-0.2l3.2-1.5L31.5,26.2z
|
||||||
|
M20.2,28.7c-1,0.5-2.3,0.5-3,0.1c-0.6-0.4-0.4-1.2,0.6-1.6c1-0.5,2.3-0.5,3-0.1C21.5,27.5,21.2,28.2,20.2,28.7z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
<g id="_x32_">
|
||||||
|
<g>
|
||||||
|
<path class="st1" d="M33.5,19.8l-1.3-6.5l-1.5,1.9L33.5,19.8z M27.5,5.1l-4.2-2.7L26,7L27.5,5.1z M20.7,5.7l1.3,6.5l1.5-1.9
|
||||||
|
L20.7,5.7z M26.8,20.4l4.2,2.7l-2.7-4.6L26.8,20.4z M34,22.3l-3.6-6.2l0,0l-0.5-2.7l2-2.6l-0.6-3.2l-2.1-1.4l-2,2.6l-1.7-1.1
|
||||||
|
l-3.7-6.3L19.6,0l0.6,3.2l3.7,6.3l0,0l0.5,2.6l0,0l-2,2.6l0.6,3.2l2.1,1.4l1.9-2.5l1.7,1.1l3.7,6.3l2.1,1.4L34,22.3z M27.5,14.6
|
||||||
|
c-0.6-0.4-1.3-1.6-1.5-2.6c-0.2-1,0.2-1.5,0.8-1.1c0.6,0.4,1.3,1.6,1.5,2.6C28.5,14.6,28.1,15.1,27.5,14.6z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
<g id="_x31_">
|
||||||
|
<g>
|
||||||
|
<path class="st2" d="M12,2.8L5.6,5.9l3.8,1.7L12,2.8z M1.1,14.4l1.3,6.5l2.6-4.8L1.1,14.4z M9.1,24l6.4-3.1l-3.8-1.7L9.1,24z
|
||||||
|
M20,12.4l-1.3-6.5l-2.6,4.8L20,12.4z M20.4,14.9l-5.1-2.3l0,0l-0.5-2.7l3.5-6.5l-0.6-3.2l-3.2,1.5L11,8.1L8.3,9.4l0,0L3.2,7.1
|
||||||
|
L0,8.6l0.6,3.2l5.2,2.3l0.5,2.7v0l-3.5,6.6l0.6,3.2l3.2-1.5l3.5-6.5l2.6-1.2l0,0l5.2,2.4l3.2-1.5L20.4,14.9z M10.9,15.2
|
||||||
|
c-1,0.5-1.9,0-2.1-1c-0.2-1,0.4-2.2,1.4-2.7c1-0.5,1.9,0,2.1,1C12.5,13.5,11.9,14.7,10.9,15.2z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
<path id="字" class="st2" d="M49.5,26.5c-2.5,0-4.4-0.7-5.7-2c-1.8-1.6-2.6-4-2.6-7.1c0-3.2,0.9-5.5,2.6-7.1c1.3-1.3,3.2-2,5.7-2
|
||||||
|
c2.5,0,4.4,0.7,5.7,2c1.7,1.6,2.6,4,2.6,7.1c0,3.1-0.9,5.5-2.6,7.1C53.8,25.8,51.9,26.5,49.5,26.5z M52.9,21.8
|
||||||
|
c0.8-1.1,1.3-2.6,1.3-4.5c0-1.9-0.4-3.4-1.3-4.5c-0.8-1.1-2-1.6-3.4-1.6c-1.4,0-2.6,0.5-3.4,1.6c-0.9,1.1-1.3,2.6-1.3,4.5
|
||||||
|
c0,1.9,0.4,3.4,1.3,4.5c0.9,1.1,2,1.6,3.4,1.6C50.9,23.4,52,22.9,52.9,21.8z M70.9,14.6c1,1.1,1.5,2.7,1.5,4.9c0,2.2-0.5,4-1.5,5.1
|
||||||
|
c-1,1.2-2.3,1.8-3.9,1.8c-1,0-1.9-0.3-2.5-0.8c-0.4-0.3-0.7-0.7-1.1-1.2V31h-3.3V13.2h3.2v1.9c0.4-0.6,0.7-1,1.1-1.3
|
||||||
|
c0.7-0.6,1.6-0.9,2.6-0.9C68.6,12.9,69.9,13.5,70.9,14.6z M69,19.6c0-1-0.2-1.9-0.7-2.6c-0.4-0.8-1.2-1.1-2.2-1.1
|
||||||
|
c-1.2,0-2,0.6-2.5,1.7c-0.2,0.6-0.4,1.4-0.4,2.3c0,1.5,0.4,2.5,1.2,3.1c0.5,0.4,1,0.5,1.7,0.5c0.9,0,1.6-0.4,2.1-1.1
|
||||||
|
C68.8,21.8,69,20.8,69,19.6z M85.8,22.2c-0.1,0.8-0.5,1.5-1.2,2.3c-1.1,1.2-2.6,1.9-4.6,1.9c-1.6,0-3.1-0.5-4.3-1.6
|
||||||
|
c-1.2-1-1.9-2.8-1.9-5.1c0-2.2,0.6-3.9,1.7-5.1c1.1-1.2,2.6-1.8,4.4-1.8c1.1,0,2,0.2,2.9,0.6c0.9,0.4,1.6,1,2.1,1.9
|
||||||
|
c0.5,0.8,0.8,1.6,1,2.6c0.1,0.6,0.1,1.4,0.1,2.5h-8.7c0,1.3,0.4,2.2,1.2,2.7c0.5,0.3,1,0.5,1.7,0.5c0.7,0,1.2-0.2,1.7-0.6
|
||||||
|
c0.2-0.2,0.4-0.5,0.6-0.9H85.8z M82.5,18.3c-0.1-0.9-0.3-1.6-0.8-2c-0.5-0.5-1.1-0.7-1.8-0.7c-0.8,0-1.4,0.2-1.8,0.7
|
||||||
|
c-0.4,0.5-0.7,1.1-0.8,2H82.5z M94.3,15.7c-1.1,0-1.9,0.5-2.3,1.4c-0.2,0.5-0.3,1.2-0.3,1.9V26h-3.3V13.2h3.2v1.9
|
||||||
|
c0.4-0.7,0.8-1.1,1.2-1.4c0.7-0.5,1.6-0.8,2.6-0.8c1.3,0,2.4,0.3,3.2,1c0.8,0.7,1.3,1.8,1.3,3.4V26h-3.4v-7.8c0-0.7-0.1-1.2-0.3-1.5
|
||||||
|
C95.8,16,95.2,15.7,94.3,15.7z M115.4,24.7c-1.3,1.2-2.9,1.8-4.9,1.8c-2.5,0-4.4-0.8-5.9-2.4c-1.4-1.6-2.1-3.8-2.1-6.6
|
||||||
|
c0-3,0.8-5.3,2.4-7c1.4-1.4,3.2-2.1,5.4-2.1c2.9,0,5,1,6.4,2.9c0.7,1.1,1.1,2.1,1.2,3.2h-3.6c-0.2-0.8-0.5-1.5-0.9-1.9
|
||||||
|
c-0.7-0.8-1.6-1.1-2.9-1.1c-1.3,0-2.3,0.5-3.1,1.6c-0.8,1.1-1.1,2.6-1.1,4.5s0.4,3.4,1.2,4.4c0.8,1,1.8,1.4,3.1,1.4
|
||||||
|
c1.3,0,2.2-0.4,2.9-1.2c0.4-0.4,0.7-1.1,0.9-2h3.6C117.5,22,116.7,23.5,115.4,24.7z M130.9,14.8c1.1,1.4,1.6,2.9,1.6,4.8
|
||||||
|
c0,1.9-0.5,3.5-1.6,4.8c-1.1,1.3-2.7,2-4.9,2c-2.2,0-3.8-0.7-4.9-2c-1.1-1.3-1.6-2.9-1.6-4.8c0-1.8,0.5-3.4,1.6-4.8
|
||||||
|
c1.1-1.4,2.7-2,4.9-2C128.2,12.8,129.9,13.5,130.9,14.8z M126,15.6c-1,0-1.7,0.3-2.3,1c-0.5,0.7-0.8,1.7-0.8,3c0,1.3,0.3,2.3,0.8,3
|
||||||
|
c0.5,0.7,1.3,1,2.3,1c1,0,1.7-0.3,2.3-1c0.5-0.7,0.8-1.7,0.8-3c0-1.3-0.3-2.3-0.8-3C127.7,16,127,15.6,126,15.6z M142.1,16.7
|
||||||
|
c-0.3-0.6-0.8-0.9-1.7-0.9c-1,0-1.6,0.3-1.9,0.9c-0.2,0.4-0.3,0.9-0.3,1.6V26h-3.4V13.2h3.2v1.9c0.4-0.7,0.8-1.1,1.2-1.4
|
||||||
|
c0.6-0.5,1.5-0.8,2.5-0.8c1,0,1.8,0.2,2.4,0.6c0.5,0.4,0.9,0.9,1.1,1.5c0.4-0.8,1-1.3,1.6-1.7c0.7-0.4,1.5-0.5,2.3-0.5
|
||||||
|
c0.6,0,1.1,0.1,1.7,0.3c0.5,0.2,1,0.6,1.5,1.1c0.4,0.4,0.6,1,0.7,1.6c0.1,0.4,0.1,1.1,0.1,1.9l0,8.1h-3.4v-8.1
|
||||||
|
c0-0.5-0.1-0.9-0.2-1.2c-0.3-0.6-0.8-0.9-1.6-0.9c-0.9,0-1.6,0.4-1.9,1.1c-0.2,0.4-0.3,0.9-0.3,1.5V26h-3.4v-7.6
|
||||||
|
C142.4,17.6,142.3,17.1,142.1,16.7z M167,14.6c1,1.1,1.5,2.7,1.5,4.9c0,2.2-0.5,4-1.5,5.1c-1,1.2-2.3,1.8-3.9,1.8
|
||||||
|
c-1,0-1.9-0.3-2.5-0.8c-0.4-0.3-0.7-0.7-1.1-1.2V31h-3.3V13.2h3.2v1.9c0.4-0.6,0.7-1,1.1-1.3c0.7-0.6,1.6-0.9,2.6-0.9
|
||||||
|
C164.7,12.9,166,13.5,167,14.6z M165.1,19.6c0-1-0.2-1.9-0.7-2.6c-0.4-0.8-1.2-1.1-2.2-1.1c-1.2,0-2,0.6-2.5,1.7
|
||||||
|
c-0.2,0.6-0.4,1.4-0.4,2.3c0,1.5,0.4,2.5,1.2,3.1c0.5,0.4,1,0.5,1.7,0.5c0.9,0,1.6-0.4,2.1-1.1C164.9,21.8,165.1,20.8,165.1,19.6z
|
||||||
|
M171.5,14.6c0.9-1.1,2.4-1.7,4.5-1.7c1.4,0,2.6,0.3,3.7,0.8c1.1,0.6,1.6,1.6,1.6,3.1v5.9c0,0.4,0,0.9,0,1.5c0,0.4,0.1,0.7,0.2,0.9
|
||||||
|
c0.1,0.2,0.3,0.3,0.5,0.4V26h-3.6c-0.1-0.3-0.2-0.5-0.2-0.7c0-0.2-0.1-0.5-0.1-0.8c-0.5,0.5-1,0.9-1.6,1.3c-0.7,0.4-1.5,0.6-2.4,0.6
|
||||||
|
c-1.2,0-2.1-0.3-2.9-1c-0.8-0.7-1.1-1.6-1.1-2.8c0-1.6,0.6-2.7,1.8-3.4c0.7-0.4,1.6-0.7,2.9-0.8l1.1-0.1c0.6-0.1,1.1-0.2,1.3-0.3
|
||||||
|
c0.5-0.2,0.7-0.5,0.7-0.9c0-0.5-0.2-0.9-0.6-1.1c-0.4-0.2-0.9-0.3-1.6-0.3c-0.8,0-1.3,0.2-1.7,0.6c-0.2,0.3-0.4,0.7-0.5,1.2h-3.2
|
||||||
|
C170.6,16.2,170.9,15.3,171.5,14.6z M173.9,23.6c0.3,0.3,0.7,0.4,1.1,0.4c0.7,0,1.4-0.2,2-0.6c0.6-0.4,0.9-1.2,0.9-2.3v-1.2
|
||||||
|
c-0.2,0.1-0.4,0.2-0.6,0.3c-0.2,0.1-0.5,0.2-0.9,0.2l-0.8,0.1c-0.7,0.1-1.2,0.3-1.5,0.5c-0.5,0.3-0.8,0.8-0.8,1.4
|
||||||
|
C173.5,22.9,173.6,23.3,173.9,23.6z M193.1,13.8c1,0.6,1.6,1.7,1.7,3.3h-3.3c0-0.4-0.2-0.8-0.4-1c-0.4-0.5-1-0.7-1.9-0.7
|
||||||
|
c-0.7,0-1.2,0.1-1.6,0.3c-0.3,0.2-0.5,0.5-0.5,0.8c0,0.4,0.2,0.7,0.5,0.8c0.3,0.2,1.5,0.5,3.5,0.9c1.3,0.3,2.3,0.8,3,1.4
|
||||||
|
c0.7,0.6,1,1.4,1,2.4c0,1.3-0.5,2.3-1.4,3.1c-0.9,0.8-2.4,1.2-4.4,1.2c-2,0-3.5-0.4-4.5-1.3c-1-0.9-1.4-1.9-1.4-3.2h3.4
|
||||||
|
c0.1,0.6,0.2,1,0.5,1.3c0.4,0.4,1.2,0.7,2.3,0.7c0.7,0,1.2-0.1,1.6-0.3c0.4-0.2,0.6-0.5,0.6-0.9c0-0.4-0.2-0.7-0.5-0.9
|
||||||
|
c-0.3-0.2-1.5-0.5-3.5-1c-1.4-0.4-2.5-0.8-3.1-1.3c-0.6-0.5-0.9-1.3-0.9-2.3c0-1.2,0.5-2.2,1.4-3c0.9-0.9,2.2-1.3,3.9-1.3
|
||||||
|
C190.8,12.9,192.1,13.2,193.1,13.8z M206.5,13.8c1,0.6,1.6,1.7,1.7,3.3h-3.3c0-0.4-0.2-0.8-0.4-1c-0.4-0.5-1-0.7-1.9-0.7
|
||||||
|
c-0.7,0-1.2,0.1-1.6,0.3c-0.3,0.2-0.5,0.5-0.5,0.8c0,0.4,0.2,0.7,0.5,0.8c0.3,0.2,1.5,0.5,3.5,0.9c1.3,0.3,2.3,0.8,3,1.4
|
||||||
|
c0.7,0.6,1,1.4,1,2.4c0,1.3-0.5,2.3-1.4,3.1c-0.9,0.8-2.4,1.2-4.4,1.2c-2,0-3.5-0.4-4.5-1.3c-1-0.9-1.4-1.9-1.4-3.2h3.4
|
||||||
|
c0.1,0.6,0.2,1,0.5,1.3c0.4,0.4,1.2,0.7,2.3,0.7c0.7,0,1.2-0.1,1.6-0.3c0.4-0.2,0.6-0.5,0.6-0.9c0-0.4-0.2-0.7-0.5-0.9
|
||||||
|
c-0.3-0.2-1.5-0.5-3.5-1c-1.4-0.4-2.5-0.8-3.1-1.3c-0.6-0.5-0.9-1.3-0.9-2.3c0-1.2,0.5-2.2,1.4-3c0.9-0.9,2.2-1.3,3.9-1.3
|
||||||
|
C204.2,12.9,205.5,13.2,206.5,13.8z"/>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 7.0 KiB |
{kind=link}
|
|
@ -0,0 +1,31 @@
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<svg id="_图层_2" data-name="图层 2" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 34.59 36">
|
||||||
|
<defs>
|
||||||
|
<style>
|
||||||
|
.cls-1 {
|
||||||
|
fill: #36569b;
|
||||||
|
}
|
||||||
|
|
||||||
|
.cls-2 {
|
||||||
|
fill: #1b3882;
|
||||||
|
}
|
||||||
|
|
||||||
|
.cls-3 {
|
||||||
|
fill: #5878b4;
|
||||||
|
}
|
||||||
|
</style>
|
||||||
|
</defs>
|
||||||
|
<g id="_图层_1-2" data-name="图层 1">
|
||||||
|
<g>
|
||||||
|
<g id="_3" data-name="3">
|
||||||
|
<path class="cls-3" d="m16.53,22.65l-6.37,3.07,5.27-.16,1.1-2.91Zm-4.19,10.95l1.12-2.91-5.27.17,4.15,2.74Zm9.3-.29l6.37-3.07-5.27.16-1.1,2.91Zm4.19-10.95l-1.12,2.91,5.27-.17-4.15-2.74Zm5.72,3.81l-7.08.23-1.73-1.14,1.5-3.95-2.06-1.36-3.16,1.53-1.48,3.89-2.67,1.29-7.14.23-3.16,1.53,2.07,1.36,7.13-.23h0s1.69,1.11,1.69,1.11l-1.51,3.98,2.06,1.36,3.16-1.53,1.5-3.95h0s2.56-1.24,2.56-1.24h0s7.23-.24,7.23-.24l3.16-1.53-2.06-1.36Zm-11.29,2.56c-.99.48-2.31.52-2.96.1-.65-.42-.37-1.15.62-1.63.99-.48,2.31-.52,2.96-.1.65.42.37,1.15-.62,1.63Z"/>
|
||||||
|
</g>
|
||||||
|
<g id="_2" data-name="2">
|
||||||
|
<path class="cls-1" d="m33.5,19.84l-1.26-6.51-1.46,1.88,2.72,4.63Zm-6.05-14.69l-4.16-2.74,2.71,4.64,1.45-1.89Zm-6.73.58l1.26,6.51,1.46-1.88-2.72-4.63Zm6.05,14.69l4.16,2.74-2.71-4.64-1.45,1.89Zm7.19,1.91l-3.63-6.2h0s-.53-2.74-.53-2.74l1.96-2.56-.63-3.23-2.07-1.36-1.96,2.56-1.69-1.11-3.71-6.33-2.07-1.36.63,3.23,3.68,6.28h0s.51,2.62.51,2.62h0s-1.99,2.6-1.99,2.6l.63,3.23,2.06,1.36,1.95-2.54,1.73,1.14,3.69,6.29,2.07,1.36-.63-3.23Zm-6.47-7.7c-.65-.42-1.33-1.59-1.52-2.6-.2-1.01.17-1.49.81-1.06.65.42,1.33,1.59,1.52,2.6.2,1.01-.17,1.49-.81,1.06Z"/>
|
||||||
|
</g>
|
||||||
|
<g id="_1" data-name="1">
|
||||||
|
<path class="cls-2" d="m11.96,2.82l-6.37,3.07,3.81,1.74,2.55-4.81ZM1.07,14.37l1.26,6.53,2.56-4.8-3.82-1.73Zm7.99,9.59l6.37-3.07-3.81-1.74-2.55,4.81Zm10.89-11.55l-1.26-6.53-2.56,4.8,3.82,1.73Zm.45,2.53l-5.13-2.32h0s-.53-2.71-.53-2.71l3.47-6.53-.63-3.24-3.16,1.53-3.42,6.43-2.67,1.29h0s-5.17-2.34-5.17-2.34l-3.16,1.53.63,3.24,5.17,2.33.51,2.65h0s-3.49,6.57-3.49,6.57l.63,3.24,3.16-1.53,3.46-6.52,2.56-1.24h0s5.24,2.37,5.24,2.37l3.16-1.53-.63-3.24Zm-9.52.24c-.99.48-1.95.04-2.14-.97-.2-1.01.44-2.22,1.43-2.69.99-.48,1.95-.04,2.14.97.2,1.01-.44,2.22-1.43,2.7Z"/>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
</g>
|
||||||
|
</svg>
|
||||||
|
After Width: | Height: | Size: 2.1 KiB |
|
|
@ -0,0 +1,20 @@
|
||||||
|
var collapsedSections = ['数据集统计'];
|
||||||
|
|
||||||
|
$(document).ready(function () {
|
||||||
|
$('.dataset').DataTable({
|
||||||
|
"stateSave": false,
|
||||||
|
"lengthChange": false,
|
||||||
|
"pageLength": 20,
|
||||||
|
"order": [],
|
||||||
|
"language": {
|
||||||
|
"info": "显示 _START_ 至 _END_ 条目(总计 _TOTAL_ )",
|
||||||
|
"infoFiltered": "(筛选自 _MAX_ 条目)",
|
||||||
|
"search": "搜索:",
|
||||||
|
"zeroRecords": "没有找到任何条目",
|
||||||
|
"paginate": {
|
||||||
|
"next": "下一页",
|
||||||
|
"previous": "上一页"
|
||||||
|
},
|
||||||
|
}
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
@ -0,0 +1,18 @@
|
||||||
|
{% extends "layout.html" %}
|
||||||
|
|
||||||
|
{% block body %}
|
||||||
|
|
||||||
|
<h1>Page Not Found</h1>
|
||||||
|
<p>
|
||||||
|
The page you are looking for cannot be found.
|
||||||
|
</p>
|
||||||
|
<p>
|
||||||
|
If you just switched documentation versions, it is likely that the page you were on is moved. You can look for it in
|
||||||
|
the content table left, or go to <a href="{{ pathto(root_doc) }}">the homepage</a>.
|
||||||
|
</p>
|
||||||
|
<!-- <p>
|
||||||
|
If you cannot find documentation you want, please <a
|
||||||
|
href="">open an issue</a> to tell us!
|
||||||
|
</p> -->
|
||||||
|
|
||||||
|
{% endblock %}
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
.. role:: hidden
|
||||||
|
:class: hidden-section
|
||||||
|
.. currentmodule:: {{ module }}
|
||||||
|
|
||||||
|
|
||||||
|
{{ name | underline}}
|
||||||
|
|
||||||
|
.. autoclass:: {{ name }}
|
||||||
|
:members:
|
||||||
|
|
||||||
|
..
|
||||||
|
autogenerated from _templates/autosummary/class.rst
|
||||||
|
note it does not have :inherited-members:
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
.. role:: hidden
|
||||||
|
:class: hidden-section
|
||||||
|
.. currentmodule:: {{ module }}
|
||||||
|
|
||||||
|
|
||||||
|
{{ name | underline}}
|
||||||
|
|
||||||
|
.. autoclass:: {{ name }}
|
||||||
|
:members:
|
||||||
|
:special-members: __call__
|
||||||
|
|
||||||
|
..
|
||||||
|
autogenerated from _templates/callable.rst
|
||||||
|
note it does not have :inherited-members:
|
||||||
|
|
@ -0,0 +1,142 @@
|
||||||
|
# 使用 vLLM 或 LMDeploy 来一键式加速评测推理
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
在 OpenCompass 评测过程中,默认使用 Huggingface 的 transformers 库进行推理,这是一个非常通用的方案,但在某些情况下,我们可能需要更高效的推理方法来加速这一过程,比如借助 VLLM 或 LMDeploy。
|
||||||
|
|
||||||
|
- [LMDeploy](https://github.com/InternLM/lmdeploy) 是一个用于压缩、部署和服务大型语言模型(LLM)的工具包,由 [MMRazor](https://github.com/open-mmlab/mmrazor) 和 [MMDeploy](https://github.com/open-mmlab/mmdeploy) 团队开发。
|
||||||
|
- [vLLM](https://github.com/vllm-project/vllm) 是一个快速且易于使用的 LLM 推理和服务库,具有先进的服务吞吐量、高效的 PagedAttention 内存管理、连续批处理请求、CUDA/HIP 图的快速模型执行、量化技术(如 GPTQ、AWQ、SqueezeLLM、FP8 KV Cache)以及优化的 CUDA 内核。
|
||||||
|
|
||||||
|
## 加速前准备
|
||||||
|
|
||||||
|
首先,请检查您要评测的模型是否支持使用 vLLM 或 LMDeploy 进行推理加速。其次,请确保您已经安装了 vLLM 或 LMDeploy,具体安装方法请参考它们的官方文档,下面是参考的安装方法:
|
||||||
|
|
||||||
|
### LMDeploy 安装方法
|
||||||
|
|
||||||
|
使用 pip (Python 3.8+) 或从 [源码](https://github.com/InternLM/lmdeploy/blob/main/docs/en/build.md) 安装 LMDeploy:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
### VLLM 安装方法
|
||||||
|
|
||||||
|
使用 pip 或从 [源码](https://vllm.readthedocs.io/en/latest/getting_started/installation.html#build-from-source) 安装 vLLM:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
## 评测时使用 VLLM 或 LMDeploy
|
||||||
|
|
||||||
|
### 方法1:使用命令行参数来变更推理后端
|
||||||
|
|
||||||
|
OpenCompass 提供了一键式的评测加速,可以在评测过程中自动将 Huggingface 的 transformers 模型转化为 VLLM 或 LMDeploy 的模型,以便在评测过程中使用。以下是使用默认 Huggingface 版本的 llama3-8b-instruct 模型评测 GSM8k 数据集的样例代码:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# eval_gsm8k.py
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# 选择一个数据集列表
|
||||||
|
from .datasets.gsm8k.gsm8k_0shot_gen_a58960 import gsm8k_datasets as datasets
|
||||||
|
# 选择一个感兴趣的模型
|
||||||
|
from ..models.hf_llama.hf_llama3_8b_instruct import models
|
||||||
|
```
|
||||||
|
|
||||||
|
其中 `hf_llama3_8b_instruct` 为原版 Huggingface 模型配置,内容如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.models import HuggingFacewithChatTemplate
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFacewithChatTemplate,
|
||||||
|
abbr='llama-3-8b-instruct-hf',
|
||||||
|
path='meta-llama/Meta-Llama-3-8B-Instruct',
|
||||||
|
max_out_len=1024,
|
||||||
|
batch_size=8,
|
||||||
|
run_cfg=dict(num_gpus=1),
|
||||||
|
stop_words=['<|end_of_text|>', '<|eot_id|>'],
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
默认 Huggingface 版本的 Llama3-8b-instruct 模型评测 GSM8k 数据集的方式如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py config/eval_gsm8k.py
|
||||||
|
```
|
||||||
|
|
||||||
|
如果需要使用 vLLM 或 LMDeploy 进行加速评测,可以使用下面的脚本:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py config/eval_gsm8k.py -a vllm
|
||||||
|
```
|
||||||
|
|
||||||
|
或
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py config/eval_gsm8k.py -a lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
### 方法2:通过部署推理加速服务API来加速评测
|
||||||
|
|
||||||
|
OpenCompass 还支持通过部署vLLM或LMDeploy的推理加速服务 API 来加速评测,参考步骤如下:
|
||||||
|
|
||||||
|
1. 安装openai包:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install openai
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 部署 vLLM 或 LMDeploy 的推理加速服务 API,具体部署方法请参考它们的官方文档,下面以LMDeploy为例:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
lmdeploy serve api_server meta-llama/Meta-Llama-3-8B-Instruct --model-name Meta-Llama-3-8B-Instruct --server-port 23333
|
||||||
|
```
|
||||||
|
|
||||||
|
api_server 启动时的参数可以通过命令行`lmdeploy serve api_server -h`查看。 比如,--tp 设置张量并行,--session-len 设置推理的最大上下文窗口长度,--cache-max-entry-count 调整 k/v cache 的内存使用比例等等。
|
||||||
|
|
||||||
|
3. 服务部署成功后,修改评测脚本,将模型配置中的路径改为部署的服务地址,如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.models import OpenAISDK
|
||||||
|
|
||||||
|
api_meta_template = dict(
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', api_role='HUMAN'),
|
||||||
|
dict(role='BOT', api_role='BOT', generate=True),
|
||||||
|
],
|
||||||
|
reserved_roles=[dict(role='SYSTEM', api_role='SYSTEM')],
|
||||||
|
)
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
abbr='Meta-Llama-3-8B-Instruct-LMDeploy-API',
|
||||||
|
type=OpenAISDK,
|
||||||
|
key='EMPTY', # API key
|
||||||
|
openai_api_base='http://0.0.0.0:23333/v1', # 服务地址
|
||||||
|
path='Meta-Llama-3-8B-Instruct ', # 请求服务时的 model name
|
||||||
|
tokenizer_path='meta-llama/Meta-Llama-3.1-8B-Instruct', # 请求服务时的 tokenizer name 或 path, 为None时使用默认tokenizer gpt-4
|
||||||
|
rpm_verbose=True, # 是否打印请求速率
|
||||||
|
meta_template=api_meta_template, # 服务请求模板
|
||||||
|
query_per_second=1, # 服务请求速率
|
||||||
|
max_out_len=1024, # 最大输出长度
|
||||||
|
max_seq_len=4096, # 最大输入长度
|
||||||
|
temperature=0.01, # 生成温度
|
||||||
|
batch_size=8, # 批处理大小
|
||||||
|
retry=3, # 重试次数
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## 加速效果及性能对比
|
||||||
|
|
||||||
|
下面是使用 VLLM 或 LMDeploy 在单卡 A800 上 Llama-3-8B-Instruct 模型对 GSM8k 数据集进行加速评测的效果及性能对比表:
|
||||||
|
|
||||||
|
| 推理后端 | 精度(Accuracy) | 推理时间(分钟:秒) | 加速比(相对于 Huggingface) |
|
||||||
|
| ----------- | ---------------- | -------------------- | ---------------------------- |
|
||||||
|
| Huggingface | 74.22 | 24:26 | 1.0 |
|
||||||
|
| LMDeploy | 73.69 | 11:15 | 2.2 |
|
||||||
|
| VLLM | 72.63 | 07:52 | 3.1 |
|
||||||
|
|
@ -0,0 +1,111 @@
|
||||||
|
# 循环评测
|
||||||
|
|
||||||
|
## 背景
|
||||||
|
|
||||||
|
对于选择题而言,当 LLM 给出正确的选项,并不一定代表着它能真正地理解题意并经过推理得出答案,它也有可能是蒙对的。为了将这两种情形区分开,同时也为了降低 LLM 对选项的偏见,我们可以尝试使用循环评测 (CircularEval)。我们会将一道选择题按照打乱选项的方式进行增广,若 LLM 可以在增广后的每道题上均得到正确的答案,那么我们认为在循环评测的意义下,这道题被做对了。
|
||||||
|
|
||||||
|
## 新增自己的循环评测数据集
|
||||||
|
|
||||||
|
一般来说,为了将一个数据集使用循环评测的方式进行评测,它的加载方式和评测方式是需要被重写的,OpenCompass 主库和配置文件均需要进行修改。后续我们以 C-Eval 为例进行讲解。
|
||||||
|
|
||||||
|
OpenCompass 主库:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets.ceval import CEvalDataset
|
||||||
|
from opencompass.datasets.circular import CircularDatasetMeta
|
||||||
|
|
||||||
|
class CircularCEvalDataset(CEvalDataset, metaclass=CircularDatasetMeta):
|
||||||
|
# 被重载的数据集类
|
||||||
|
dataset_class = CEvalDataset
|
||||||
|
|
||||||
|
# 若原 load 方法得到一 DatasetDict,其哪些 split 需要被循环评测。CEvalDataset load 得到 [dev, val, test],我们只需要对 val 和 test 进行循环评测,dev 不需要
|
||||||
|
default_circular_splits = ['val', 'test']
|
||||||
|
|
||||||
|
# 需要被打乱的 key 列表
|
||||||
|
default_option_keys = ['A', 'B', 'C', 'D']
|
||||||
|
|
||||||
|
# 若 answer_key 的内容属于是 ['A', 'B', 'C', 'D'] 之一,并表示正确答案。该字段表示打乱选项后,需要如何更新正确答案。与 default_answer_key_switch_method 二选一
|
||||||
|
default_answer_key = 'answer'
|
||||||
|
|
||||||
|
# 如果 answer_key 的内容不属于 ['A', 'B', 'C', 'D'] 之一,那么可以使用函数的方式来指定打乱选项后的正确答案。与 default_answer_key 二选一
|
||||||
|
# def default_answer_key_switch_method(item, circular_pattern):
|
||||||
|
# # item 是原本的数据项
|
||||||
|
# # circular_pattern 是一个 tuple,表示打乱选项后的顺序,例如 ('D', 'A', 'B', 'C') 表示原来的 A 选项变成了 D,原来的 B 选项变成了 A,以此类推
|
||||||
|
# item['answer'] = circular_pattern['ABCD'.index(item['answer'])]
|
||||||
|
# return item
|
||||||
|
```
|
||||||
|
|
||||||
|
`CircularCEvalDataset` 会接受 `circular_pattern` 参数,它有两个取值:
|
||||||
|
|
||||||
|
- `circular`: 表示单项循环。默认为该值。ABCD 会被扩充为 ABCD, BCDA, CDAB, DABC, 共 4 种
|
||||||
|
- `all_possible`: 表示全排列。ABCD 会被扩充为 ABCD, ABDC, ACBD, ACDB, ADBC, ADCB, BACD, ..., 共 24 种
|
||||||
|
|
||||||
|
另外我们提供了一个 `CircularEvaluator` 用于替换 `AccEvaluator`,该 Evaluator 同样接受 `circular_pattern`,该参数应与上述保持一致。它会产出以下指标:
|
||||||
|
|
||||||
|
- `acc_{origin|circular|all_possible}`: 将打乱后选项顺序后的题目视作多道单独的题目,计算准确率
|
||||||
|
- `perf_{origin|circular|all_possible}`: 按照 circular 的逻辑,若选项打乱后的题目都回答正确,才会视为这道题正确,计算准确率
|
||||||
|
- `more_{num}_{origin|circular|all_possible}`: 按照 circular 的逻辑,若选项打乱后的题目回答正确的数量大于等于 num,就会视为这道题正确,计算准确率
|
||||||
|
|
||||||
|
OpenCompass 配置文件:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.datasets.circular import CircularCEvalDataset
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
|
||||||
|
|
||||||
|
for d in ceval_datasets:
|
||||||
|
# 重载 load 方法
|
||||||
|
d['type'] = CircularCEvalDataset
|
||||||
|
# 为了与非循环评测版本做区分而进行改名
|
||||||
|
d['abbr'] = d['abbr'] + '-circular-4'
|
||||||
|
# 重载评测方法
|
||||||
|
d['eval_cfg']['evaluator'] = {'type': CircularEvaluator}
|
||||||
|
|
||||||
|
# 上述操作后的 dataset 形如下:
|
||||||
|
# dict(
|
||||||
|
# type=CircularCEvalDataset,
|
||||||
|
# path='./data/ceval/formal_ceval', # 未改变
|
||||||
|
# name='computer_network', # 未改变
|
||||||
|
# abbr='ceval-computer_network-circular-4',
|
||||||
|
# reader_cfg=dict(...), # 未改变
|
||||||
|
# infer_cfg=dict(...), # 未改变
|
||||||
|
# eval_cfg=dict(evaluator=dict(type=CircularEvaluator), ...),
|
||||||
|
# )
|
||||||
|
```
|
||||||
|
|
||||||
|
另外评测时为了针对循环评测有更良好的结果呈现,建议考虑使用以下 summarizer
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.summarizers import CircularSummarizer
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from ...summarizers.groups.ceval import ceval_summary_groups
|
||||||
|
|
||||||
|
new_summary_groups = []
|
||||||
|
for item in ceval_summary_groups:
|
||||||
|
new_summary_groups.append(
|
||||||
|
{
|
||||||
|
'name': item['name'] + '-circular-4',
|
||||||
|
'subsets': [i + '-circular-4' for i in item['subsets']],
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
summarizer = dict(
|
||||||
|
type=CircularSummarizer,
|
||||||
|
# 选择具体看哪些指标
|
||||||
|
metric_types=['acc_origin', 'perf_circular'],
|
||||||
|
dataset_abbrs = [
|
||||||
|
'ceval-circular-4',
|
||||||
|
'ceval-humanities-circular-4',
|
||||||
|
'ceval-stem-circular-4',
|
||||||
|
'ceval-social-science-circular-4',
|
||||||
|
'ceval-other-circular-4',
|
||||||
|
],
|
||||||
|
summary_groups=new_summary_groups,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
更多复杂的评测案例可以参考这个样例代码: https://github.com/open-compass/opencompass/tree/main/configs/eval_circular.py
|
||||||
|
|
@ -0,0 +1,106 @@
|
||||||
|
# 代码评测教程
|
||||||
|
|
||||||
|
这里以 `humaneval` 和 `mbpp` 为例,主要介绍如何评测模型的代码能力。
|
||||||
|
|
||||||
|
## pass@1
|
||||||
|
|
||||||
|
如果只需要生成单条回复来评测pass@1的性能,可以直接使用[configs/datasets/humaneval/humaneval_gen_8e312c.py](https://github.com/open-compass/opencompass/blob/main/configs/datasets/humaneval/humaneval_gen_8e312c.py) 和 [configs/datasets/mbpp/deprecated_mbpp_gen_1e1056.py](https://github.com/open-compass/opencompass/blob/main/configs/datasets/mbpp/deprecated_mbpp_gen_1e1056.py) 并参考通用的[快速上手教程](../get_started/quick_start.md)即可。
|
||||||
|
|
||||||
|
如果要进行多语言评测,可以参考[多语言代码评测教程](./code_eval_service.md)。
|
||||||
|
|
||||||
|
## pass@k
|
||||||
|
|
||||||
|
如果对于单个example需要生成多条回复来评测pass@k的性能,需要参考以下两种情况。这里以10回复为例子:
|
||||||
|
|
||||||
|
### 通常情况
|
||||||
|
|
||||||
|
对于绝大多数模型来说,模型支持HF的generation中带有`num_return_sequences` 参数,我们可以直接使用来获取多回复。可以参考以下配置文件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets import MBPPDatasetV2, MBPPPassKEvaluator
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.humaneval.humaneval_gen_8e312c import humaneval_datasets
|
||||||
|
from .datasets.mbpp.deprecated_mbpp_gen_1e1056 import mbpp_datasets
|
||||||
|
|
||||||
|
mbpp_datasets[0]['type'] = MBPPDatasetV2
|
||||||
|
mbpp_datasets[0]['eval_cfg']['evaluator']['type'] = MBPPPassKEvaluator
|
||||||
|
mbpp_datasets[0]['reader_cfg']['output_column'] = 'test_column'
|
||||||
|
|
||||||
|
datasets = []
|
||||||
|
datasets += humaneval_datasets
|
||||||
|
datasets += mbpp_datasets
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceCausalLM,
|
||||||
|
...,
|
||||||
|
generation_kwargs=dict(
|
||||||
|
num_return_sequences=10,
|
||||||
|
do_sample=True,
|
||||||
|
top_p=0.95,
|
||||||
|
temperature=0.8,
|
||||||
|
),
|
||||||
|
...,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 `mbpp`,在数据集和评测上需要有新的变更,所以同步修改`type`, `eval_cfg.evaluator.type`, `reader_cfg.output_column` 字段来适应新的需求。
|
||||||
|
|
||||||
|
另外我们需要模型的回复有随机性,同步需要设置`generation_kwargs`参数。这里注意要设置`num_return_sequences`得到回复数。
|
||||||
|
|
||||||
|
注意:`num_return_sequences` 必须大于等于k,本身pass@k是计算的概率估计。
|
||||||
|
|
||||||
|
具体可以参考以下配置文件
|
||||||
|
[configs/eval_code_passk.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_code_passk.py)
|
||||||
|
|
||||||
|
### 模型不支持多回复
|
||||||
|
|
||||||
|
适用于一些没有设计好的API以及功能缺失的HF模型。这个时候我们需要重复构造数据集来达到多回复的效果。这里可以参考以下配置文件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets import MBPPDatasetV2, MBPPPassKEvaluator
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.humaneval.humaneval_gen_8e312c import humaneval_datasets
|
||||||
|
from .datasets.mbpp.deprecated_mbpp_gen_1e1056 import mbpp_datasets
|
||||||
|
|
||||||
|
humaneval_datasets[0]['abbr'] = 'openai_humaneval_pass10'
|
||||||
|
humaneval_datasets[0]['num_repeats'] = 10
|
||||||
|
mbpp_datasets[0]['abbr'] = 'mbpp_pass10'
|
||||||
|
mbpp_datasets[0]['num_repeats'] = 10
|
||||||
|
mbpp_datasets[0]['type'] = MBPPDatasetV2
|
||||||
|
mbpp_datasets[0]['eval_cfg']['evaluator']['type'] = MBPPPassKEvaluator
|
||||||
|
mbpp_datasets[0]['reader_cfg']['output_column'] = 'test_column'
|
||||||
|
|
||||||
|
datasets = []
|
||||||
|
datasets += humaneval_datasets
|
||||||
|
datasets += mbpp_datasets
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceCausalLM,
|
||||||
|
...,
|
||||||
|
generation_kwargs=dict(
|
||||||
|
do_sample=True,
|
||||||
|
top_p=0.95,
|
||||||
|
temperature=0.8,
|
||||||
|
),
|
||||||
|
...,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
由于数据集的prompt并没有修改,我们需要替换对应的字段来达到数据集重复的目的。
|
||||||
|
需要修改以下字段:
|
||||||
|
|
||||||
|
- `num_repeats`: 数据集重复的次数
|
||||||
|
- `abbr`: 数据集的缩写最好随着重复次数一并修改,因为数据集数量会发生变化,防止与`.cache/dataset_size.json` 中的数值出现差异导致一些潜在的问题。
|
||||||
|
|
||||||
|
对于 `mbpp`,同样修改`type`, `eval_cfg.evaluator.type`, `reader_cfg.output_column` 字段。
|
||||||
|
|
||||||
|
另外我们需要模型的回复有随机性,同步需要设置`generation_kwargs`参数。
|
||||||
|
|
||||||
|
具体可以参考以下配置文件
|
||||||
|
[configs/eval_code_passk_repeat_dataset.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_code_passk_repeat_dataset.py)
|
||||||
|
|
@ -0,0 +1,222 @@
|
||||||
|
# 代码评测Docker教程
|
||||||
|
|
||||||
|
为了完成LLM代码能力评测,我们需要搭建一套独立的评测环境,避免在开发环境执行错误代码从而造成不可避免的损失。目前 OpenCompass 使用的代码评测服务可参考[code-evaluator](https://github.com/open-compass/code-evaluator)项目。接下来将围绕代码评测服务介绍不同需要下的评测教程。
|
||||||
|
|
||||||
|
1. humaneval-x
|
||||||
|
|
||||||
|
多编程语言的数据集 [humaneval-x](https://huggingface.co/datasets/THUDM/humaneval-x)
|
||||||
|
数据集[下载地址](https://github.com/THUDM/CodeGeeX2/tree/main/benchmark/humanevalx),请下载需要评测的语言(××.jsonl.gz)文件,并放入`./data/humanevalx`文件夹。
|
||||||
|
|
||||||
|
目前支持的语言有`python`, `cpp`, `go`, `java`, `js`。
|
||||||
|
|
||||||
|
2. DS1000
|
||||||
|
|
||||||
|
Python 多算法库数据集 [ds1000](https://github.com/xlang-ai/DS-1000)
|
||||||
|
数据集[下载地址](https://github.com/xlang-ai/DS-1000/blob/main/ds1000_data.zip)
|
||||||
|
|
||||||
|
目前支持的算法库有`Pandas`, `Numpy`, `Tensorflow`, `Scipy`, `Sklearn`, `Pytorch`, `Matplotlib`。
|
||||||
|
|
||||||
|
## 启动代码评测服务
|
||||||
|
|
||||||
|
1. 确保您已经安装了 docker,可参考[安装docker文档](https://docs.docker.com/engine/install/)
|
||||||
|
2. 拉取代码评测服务项目,并构建 docker 镜像
|
||||||
|
|
||||||
|
选择你需要的数据集对应的dockerfile,在下面命令中做替换 `humanevalx` 或者 `ds1000`。
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git clone https://github.com/open-compass/code-evaluator.git
|
||||||
|
docker build -t code-eval-{your-dataset}:latest -f docker/{your-dataset}/Dockerfile .
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 使用以下命令创建容器
|
||||||
|
|
||||||
|
```shell
|
||||||
|
# 输出日志格式
|
||||||
|
docker run -it -p 5000:5000 code-eval-{your-dataset}:latest python server.py
|
||||||
|
|
||||||
|
# 在后台运行程序
|
||||||
|
# docker run -itd -p 5000:5000 code-eval-{your-dataset}:latest python server.py
|
||||||
|
|
||||||
|
# 使用不同的端口
|
||||||
|
# docker run -itd -p 5001:5001 code-eval-{your-dataset}:latest python server.py --port 5001
|
||||||
|
```
|
||||||
|
|
||||||
|
**注:**
|
||||||
|
|
||||||
|
- 如在评测Go的过程中遇到timeout,请在创建容器时候使用以下命令
|
||||||
|
|
||||||
|
```shell
|
||||||
|
docker run -it -p 5000:5000 -e GO111MODULE=on -e GOPROXY=https://goproxy.io code-eval-{your-dataset}:latest python server.py
|
||||||
|
```
|
||||||
|
|
||||||
|
4. 为了确保您能够访问服务,通过以下命令检测推理环境和评测服务访问情况。 (如果推理和代码评测在同一主机中运行服务,就跳过这个操作)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
ping your_service_ip_address
|
||||||
|
telnet your_service_ip_address your_service_port
|
||||||
|
```
|
||||||
|
|
||||||
|
## 本地代码评测
|
||||||
|
|
||||||
|
模型推理和代码评测服务在同一主机,或者同一局域网中,可以直接进行代码推理及评测。**注意:DS1000暂不支持,请走异地评测**
|
||||||
|
|
||||||
|
### 配置文件
|
||||||
|
|
||||||
|
我们已经提供了 huamaneval-x 在 codegeex2 上评估的\[配置文件\]作为参考(https://github.com/open-compass/opencompass/blob/main/configs/eval_codegeex2.py)。
|
||||||
|
其中数据集以及相关后处理的配置文件为这个[链接](https://github.com/open-compass/opencompass/tree/main/configs/datasets/humanevalx), 需要注意 humanevalx_eval_cfg_dict 中的evaluator 字段。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||||
|
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||||
|
from opencompass.datasets import HumanevalXDataset, HumanevalXEvaluator
|
||||||
|
|
||||||
|
humanevalx_reader_cfg = dict(
|
||||||
|
input_columns=['prompt'], output_column='task_id', train_split='test')
|
||||||
|
|
||||||
|
humanevalx_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template='{prompt}'),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer, max_out_len=1024))
|
||||||
|
|
||||||
|
humanevalx_eval_cfg_dict = {
|
||||||
|
lang : dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=HumanevalXEvaluator,
|
||||||
|
language=lang,
|
||||||
|
ip_address="localhost", # replace to your code_eval_server ip_address, port
|
||||||
|
port=5000), # refer to https://github.com/open-compass/code-evaluator to launch a server
|
||||||
|
pred_role='BOT')
|
||||||
|
for lang in ['python', 'cpp', 'go', 'java', 'js'] # do not support rust now
|
||||||
|
}
|
||||||
|
|
||||||
|
humanevalx_datasets = [
|
||||||
|
dict(
|
||||||
|
type=HumanevalXDataset,
|
||||||
|
abbr=f'humanevalx-{lang}',
|
||||||
|
language=lang,
|
||||||
|
path='./data/humanevalx',
|
||||||
|
reader_cfg=humanevalx_reader_cfg,
|
||||||
|
infer_cfg=humanevalx_infer_cfg,
|
||||||
|
eval_cfg=humanevalx_eval_cfg_dict[lang])
|
||||||
|
for lang in ['python', 'cpp', 'go', 'java', 'js']
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
### 任务启动
|
||||||
|
|
||||||
|
参考[快速上手教程](../get_started.html)
|
||||||
|
|
||||||
|
## 异地代码评测
|
||||||
|
|
||||||
|
模型推理和代码评测服务分别在不可访问的不同机器中,需要先进行模型推理,收集代码推理结果。配置文件和推理流程都可以复用上面的教程。
|
||||||
|
|
||||||
|
### 收集推理结果(仅针对Humanevalx)
|
||||||
|
|
||||||
|
OpenCompass 在 `tools` 中提供了 `collect_code_preds.py` 脚本对推理结果进行后处理并收集,我们只需要提供启动任务时的配置文件,以及指定复用对应任务的工作目录,其配置与 `run.py` 中的 `-r` 一致,细节可参考[文档](https://opencompass.readthedocs.io/zh-cn/latest/get_started/quick_start.html#id4)。
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python tools/collect_code_preds.py [config] [-r latest]
|
||||||
|
```
|
||||||
|
|
||||||
|
收集到的结果将会按照以下的目录结构保存到 `-r` 对应的工作目录中:
|
||||||
|
|
||||||
|
```
|
||||||
|
workdir/humanevalx
|
||||||
|
├── codegeex2-6b
|
||||||
|
│ ├── humanevalx_cpp.json
|
||||||
|
│ ├── humanevalx_go.json
|
||||||
|
│ ├── humanevalx_java.json
|
||||||
|
│ ├── humanevalx_js.json
|
||||||
|
│ └── humanevalx_python.json
|
||||||
|
├── CodeLlama-13b
|
||||||
|
│ ├── ...
|
||||||
|
├── CodeLlama-13b-Instruct
|
||||||
|
│ ├── ...
|
||||||
|
├── CodeLlama-13b-Python
|
||||||
|
│ ├── ...
|
||||||
|
├── ...
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 DS1000 只需要拿到 `opencompasss` 对应生成的 prediction文件即可。
|
||||||
|
|
||||||
|
### 代码评测
|
||||||
|
|
||||||
|
#### 以下仅支持Humanevalx
|
||||||
|
|
||||||
|
确保代码评测服务启动的情况下,使用 `curl` 提交请求:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@{result_absolute_path}' -F 'dataset={dataset/language}' {your_service_ip_address}:{your_service_port}/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
例如:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./examples/humanevalx/python.json' -F 'dataset=humanevalx/python' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
得到结果:
|
||||||
|
|
||||||
|
```
|
||||||
|
"{\"pass@1\": 37.19512195121951%}"
|
||||||
|
```
|
||||||
|
|
||||||
|
另外我们额外提供了 `with-prompt` 选项(默认为True),由于有些模型生成结果包含完整的代码(如WizardCoder),不需要 prompt + prediciton 的形式进行拼接,可以参考以下命令进行评测。
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./examples/humanevalx/python.json' -F 'dataset=humanevalx/python' -H 'with-prompt: False' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 以下仅支持DS1000
|
||||||
|
|
||||||
|
确保代码评测服务启动的情况下,使用 `curl` 提交请求:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./internlm-chat-7b-hf-v11/ds1000_Numpy.json' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
DS1000支持额外 debug 参数,注意开启之后会有大量log
|
||||||
|
|
||||||
|
- `full`: 额外打印每个错误样本的原始prediction,后处理后的predcition,运行程序以及最终报错。
|
||||||
|
- `half`: 额外打印每个错误样本的运行程序以及最终报错。
|
||||||
|
- `error`: 额外打印每个错误样本的最终报错。
|
||||||
|
|
||||||
|
```shell
|
||||||
|
curl -X POST -F 'file=@./internlm-chat-7b-hf-v11/ds1000_Numpy.json' -F 'debug=error' localhost:5000/evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
另外还可以通过同样的方式修改`num_workers`来控制并行数。
|
||||||
|
|
||||||
|
## 进阶教程
|
||||||
|
|
||||||
|
除了评测已支持的 `humanevalx` 数据集以外,用户还可能有以下需求:
|
||||||
|
|
||||||
|
### 支持新数据集
|
||||||
|
|
||||||
|
可以参考[支持新数据集教程](./new_dataset.md)
|
||||||
|
|
||||||
|
### 修改后处理
|
||||||
|
|
||||||
|
1. 本地评测中,可以按照支持新数据集教程中的后处理部分来修改后处理方法;
|
||||||
|
2. 异地评测中,可以修改 `tools/collect_code_preds.py` 中的后处理部分;
|
||||||
|
3. 代码评测服务中,存在部分后处理也可以进行修改,详情参考下一部分教程;
|
||||||
|
|
||||||
|
### 代码评测服务 Debug
|
||||||
|
|
||||||
|
在支持新数据集或者修改后处理的过程中,可能会遇到需要修改原本的代码评测服务的情况,按照需求修改以下部分
|
||||||
|
|
||||||
|
1. 删除 `Dockerfile` 中安装 `code-evaluator` 的部分,在启动容器时将 `code-evaluator` 挂载
|
||||||
|
|
||||||
|
```shell
|
||||||
|
docker run -it -p 5000:5000 -v /local/path/of/code-evaluator:/workspace/code-evaluator code-eval:latest bash
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 安装并启动代码评测服务,此时可以根据需要修改本地 `code-evaluator` 中的代码来进行调试
|
||||||
|
|
||||||
|
```shell
|
||||||
|
cd code-evaluator && pip install -r requirements.txt
|
||||||
|
python server.py
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,194 @@
|
||||||
|
# CompassBench 介绍
|
||||||
|
|
||||||
|
## CompassBench 2.0 v1.3 版本
|
||||||
|
|
||||||
|
CompassBench(官方自建榜单)经历了多次更新迭代,从2024年7月起,OpenCompass将会公布自建榜单的评测规则(评测配置文件)和示例数据集文件,以帮助社区更好的了解自建榜单的评测逻辑和方法。
|
||||||
|
|
||||||
|
### 能力维度
|
||||||
|
|
||||||
|
2024年8月榜单将会包括以下能力维度:
|
||||||
|
|
||||||
|
| 能力 | 任务介绍 | 评测方式 | 示例数据地址 |
|
||||||
|
| -------- | -------------------------------------------------------------------------------------- | ------------------- | ------------------------------------------------------------------------------ |
|
||||||
|
| 语言 | 评测模型在信息抽取、信息抽取、内容总结、对话、创作等多种任务上的能力 | 主观评测 | https://github.com/open-compass/CompassBench/tree/main/v1_3_data/language |
|
||||||
|
| 推理 | 评测模型在逻辑推理、常识推理、表格推理等多种日常推理任务上的能力 | 主观评测 | https://github.com/open-compass/CompassBench/tree/main/v1_3_data/reasoning |
|
||||||
|
| 知识 | 评测模型在理科、工科、人文社科等多个领域的知识水平 | 客观评测 | https://github.com/open-compass/CompassBench/tree/main/v1_3_data/knowledge |
|
||||||
|
| 数学 | 评测模型在数值计算、高中及大学难度的数学问题上的能力 | 客观评测 | https://github.com/open-compass/CompassBench/tree/main/v1_3_data/math |
|
||||||
|
| 代码 | 评测模型在代码生成、代码补全、代码注释、代码重构、代码改写、计算机知识综合问答上的能力 | 客观评测 + 主观评测 | https://github.com/open-compass/CompassBench/tree/main/v1_3_data/code |
|
||||||
|
| 指令跟随 | 评测模型在基于各类语言、推理、知识等任务中,能否准确遵循复杂指令的能力 | 主观评测 | https://github.com/open-compass/CompassBench/tree/main/v1_3_data/instruct |
|
||||||
|
| 智能体 | 评估模型在复杂工具调用的能力,以及数据科学、数学等情况下使用代码解释器的能力 | 客观评测 | https://github.com/open-compass/T-Eval https://github.com/open-compass/CIBench |
|
||||||
|
|
||||||
|
### 评测方法
|
||||||
|
|
||||||
|
- 对于客观评测,将会采用0-shot + CoT的方式评测。
|
||||||
|
- OpenCompass在客观题评测的后处理上已进行较多优化,并在评测时在Prompt中对回答格式进行约束,对于因指令跟随问题带来的无法完成答案提取的情况,将视为回答错误
|
||||||
|
- 数学、智能体题目类型与给定的示例数据类似,但真实评测数据与开源数据不同
|
||||||
|
- 对于主观评测,将会采用基于大模型评价的方式进行评测。
|
||||||
|
- 我们对每一道问题均提供评测时的打分指引。
|
||||||
|
|
||||||
|
- 比较待测模型相对于参考回复的胜率,共设置为五档
|
||||||
|
|
||||||
|
- `A++`:回答A远胜于回答B。
|
||||||
|
- `A+`:回答A略优于回答B。
|
||||||
|
- `A=B`:回答A和回答B质量相同。
|
||||||
|
- `B+`:回答B略优于回答A。
|
||||||
|
- `B++`:回答B远胜于回答A。
|
||||||
|
- 主观评测配置文件
|
||||||
|
- [示例评测配置](https://github.com/open-compass/opencompass/blob/main/configs/eval_compassbench_v1_3_subjective.py)
|
||||||
|
- 主观评价提示词
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
# Instruction
|
||||||
|
|
||||||
|
You are an expert evaluator. Your task is to evaluate the quality of the \
|
||||||
|
responses generated by two AI models.
|
||||||
|
We will provide you with the user query and a pair of AI-generated \
|
||||||
|
responses (Response A and Response B).
|
||||||
|
You should first read the user query and the conversation history \
|
||||||
|
carefully for analyzing the task, and then evaluate the quality of the \
|
||||||
|
responses based on and rules provided below.
|
||||||
|
|
||||||
|
# Conversation between User and AI
|
||||||
|
|
||||||
|
## User Query
|
||||||
|
<|begin_of_query|>
|
||||||
|
|
||||||
|
{question}
|
||||||
|
|
||||||
|
<|end_of_query|>
|
||||||
|
|
||||||
|
## Response A
|
||||||
|
<|begin_of_response_A|>
|
||||||
|
|
||||||
|
{prediction}
|
||||||
|
|
||||||
|
<|end_of_response_A|>
|
||||||
|
|
||||||
|
## Response B
|
||||||
|
<|begin_of_response_B|>
|
||||||
|
|
||||||
|
{prediction2}
|
||||||
|
|
||||||
|
<|end_of_response_B|>
|
||||||
|
|
||||||
|
# Evaluation
|
||||||
|
|
||||||
|
## Checklist
|
||||||
|
|
||||||
|
<|begin_of_checklist|>
|
||||||
|
|
||||||
|
{checklist}
|
||||||
|
|
||||||
|
<|end_of_checklist|>
|
||||||
|
|
||||||
|
Please use this checklist to guide your evaluation, but do not limit your \
|
||||||
|
assessment to the checklist.
|
||||||
|
|
||||||
|
## Rules
|
||||||
|
|
||||||
|
You should compare the above two responses based on your analysis of the \
|
||||||
|
user queries and the conversation history.
|
||||||
|
You should first write down your analysis and the checklist that you used \
|
||||||
|
for the evaluation, and then provide your assessment according to the \
|
||||||
|
checklist.
|
||||||
|
There are five choices to give your final assessment: ["A++", "A+", \
|
||||||
|
"A=B", "B+", "B++"], which correspond to the following meanings:
|
||||||
|
|
||||||
|
- `A++`: Response A is much better than Response B.
|
||||||
|
- `A+`: Response A is only slightly better than Response B.
|
||||||
|
- `A=B`: Response A and B are of the same quality. Please use this \
|
||||||
|
choice sparingly.
|
||||||
|
- `B+`: Response B is only slightly better than Response A.
|
||||||
|
- `B++`: Response B is much better than Response A.
|
||||||
|
|
||||||
|
## Output Format
|
||||||
|
First, please output your analysis for each model response, and \
|
||||||
|
then summarize your assessment to three aspects: "reason A=B", \
|
||||||
|
"reason A>B", and "reason B>A", and finally make your choice for \
|
||||||
|
the final assessment.
|
||||||
|
|
||||||
|
Please provide your evaluation results in the following json \
|
||||||
|
format by filling in the placeholders in []:
|
||||||
|
|
||||||
|
{
|
||||||
|
"analysis of A": "[analysis of Response A]",
|
||||||
|
"analysis of B": "[analysis of Response B]",
|
||||||
|
"reason of A=B": "[where Response A and B perform equally well]",
|
||||||
|
"reason of A>B": "[where Response A is better than Response B]",
|
||||||
|
"reason of B>A": "[where Response B is better than Response A]",
|
||||||
|
"choice": "[A++ or A+ or A=B or B+ or B++]",
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
# 指令
|
||||||
|
|
||||||
|
您是一位专业评估专家。您的任务是评估两个AI模型生成回答的质量。
|
||||||
|
我们将为您提供用户问题及一对AI生成的回答(回答A和回答B)。
|
||||||
|
您应当首先仔细阅读用户问题,然后根据以下提供的规则评估回答的质量。
|
||||||
|
|
||||||
|
# 用户与AI之间的对话
|
||||||
|
|
||||||
|
## 用户问题
|
||||||
|
<|begin_of_query|>
|
||||||
|
|
||||||
|
{question}
|
||||||
|
|
||||||
|
<|end_of_query|>
|
||||||
|
|
||||||
|
## 回答A
|
||||||
|
<|begin_of_response_A|>
|
||||||
|
|
||||||
|
{prediction}
|
||||||
|
|
||||||
|
<|end_of_response_A|>
|
||||||
|
|
||||||
|
## 回答B
|
||||||
|
<|begin_of_response_B|>
|
||||||
|
|
||||||
|
{prediction2}
|
||||||
|
|
||||||
|
<|end_of_response_B|>
|
||||||
|
|
||||||
|
# 评估
|
||||||
|
|
||||||
|
## 检查清单
|
||||||
|
|
||||||
|
<|begin_of_checklist|>
|
||||||
|
|
||||||
|
{checklist}
|
||||||
|
|
||||||
|
<|end_of_checklist|>
|
||||||
|
|
||||||
|
请参考此检查清单来评估回答的质量,但不要局限于此检查清单。
|
||||||
|
|
||||||
|
## 规则
|
||||||
|
|
||||||
|
您应当基于用户查询,分析比较上述两种回答。
|
||||||
|
您应当基于检查清单写下您的分析,然后提供您的评价。
|
||||||
|
有五个选项供您做出最终评估:["A++", "A+", "A=B", "B+", "B++"],它们对应如下含义:
|
||||||
|
|
||||||
|
- `A++`:回答A远胜于回答B。
|
||||||
|
- `A+`:回答A略优于回答B。
|
||||||
|
- `A=B`:回答A和回答B质量相同。请谨慎使用此选项。
|
||||||
|
- `B+`:回答B略优于回答A。
|
||||||
|
- `B++`:回答B远胜于回答A。
|
||||||
|
|
||||||
|
## 输出格式
|
||||||
|
首先,请输出您对每个模型回答的分析,
|
||||||
|
然后总结您的评估到三个方面:"A=B的理由","A优于B的理由",和 "B优于A的理由",
|
||||||
|
最后做出您对最终评估的选择。
|
||||||
|
|
||||||
|
请按照以下json格式提供您的评估结果,通过填充[]中的占位符:
|
||||||
|
|
||||||
|
{
|
||||||
|
"回答A的分析": "[回答A的分析]",
|
||||||
|
"回答B的分析": "[回答B的分析]",
|
||||||
|
"A=B的理由": "[A和B回答差不多的理由]",
|
||||||
|
"A优于B的理由": "[回答A优于B的理由]",
|
||||||
|
"B优于A的理由": "[回答B优于A的理由]",
|
||||||
|
"choice": "[A++ or A+ or A=B or B+ or B++]",
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,48 @@
|
||||||
|
# CompassBench 2.0 介绍
|
||||||
|
|
||||||
|
|
||||||
|
## v1.0介绍
|
||||||
|
为支持OpenCompass的年度榜单,本文将提供CompassBench的整体介绍。
|
||||||
|
|
||||||
|
本次评测将在语言、知识、创作、推理、数学、代码、长文本、智能体能力的多项任务上开展评测,现提供任务介绍和题目示例。
|
||||||
|
|
||||||
|
- 评测方式采样主观与客观相结合的方式,具体根据各个任务不同进行具体设计。
|
||||||
|
- 针对推理、数学、代码、智能体等任务,将会采用Few-shot + CoT的评测方式。
|
||||||
|
- 对于填空题,通过在Prompt中提供Few-shot和输出格式约束来协助抽取答案。
|
||||||
|
- 对于选择题,针对同一问题,通过变换提问方式,减少随机影响。
|
||||||
|
- 对于开放式问题的评测,对同一问题进行多次采样,并采用多维度打分的方式进行评价。
|
||||||
|
|
||||||
|
> OpenCompass在客观题评测的后处理上已进行较多优化,并在评测时在Prompt中对回答格式进行约束,对于因指令跟随问题带来的无法完成答案提取的情况,将视为回答错误。OpenCompass将会在下一期加入指令跟随能力的评测。
|
||||||
|
|
||||||
|
| 能力 | 任务 | 介绍 | 题目示例 |
|
||||||
|
| ---- | ---- | ---- | ---- |
|
||||||
|
| 语言 | 信息抽取 | 信息抽取是指从文本中提取出特定类型的信息。这类任务通常用于处理结构化数据、知识图谱、问答系统等场景。 | ```"question": "野马队在分区轮以 23–16 击败了匹兹堡钢人队,在比赛的最后三分钟拿下 11 分。然后他们在美式足球联合会 (AFC) 锦标赛上以 20–18 击败了第 49 届超级碗卫冕冠军新英格兰爱国者队,在比赛还剩 17 秒 时拦截了新英格兰队的两分转换传球。尽管曼宁在本赛季的拦截上有问题,但他在两场季后赛中未投任何球。\n野马队在 AFC 锦标赛中打败了谁?"``` |
|
||||||
|
| 语言 | 意图识别 | 意图识别是对用户输入的文本或语音进行分析,判断其意图或需求。这类任务应用于智能客服、语音助手、聊天机器人等场景。 | ```"question": "中国文化的天人合一思想\n中西文化的基本差异之一就是,在人与自然的关系问题上,中国文化比较重视人与自然的和谐统一,而西方文化则强调,人要征服自然、改造自然才能求得自己的生存和发展。中国文化的这种特色,有时通过“天人合一”的命题表述出来。中国古代思想家一般都反对把天与人割裂开来、对立起来,而主张天人协调、天人合一。\n天人合一问题,就其理论实质而言,是关于人与自然的统一问题,或者说是自然界和精神的统一问题。应当承认,中国传统文化中的天人合一思想,内容十分复杂,其中既有正确的观点,也有错误的观点,我们必须实事求是地予以分析。但是,从文化的民族性以及对民族文化的推进作用和深远影响看,我们应当大胆肯定。中国古代思想家关于天人合一的思想,其最基本的涵义,就是充分肯定自然界和精神的统一,关注人类行为与自然界的协调问题。从这个意思上说,天人合一思想的,是非常有价值的。\n恩格斯对自然和精神的统一问题,有过一系列精辟的论述。他说:“我们一天天地学会更加正确地理解自然规律,学会认识我们对于自然界的惯常行程的干涉所引起的比较近或比较远的影响。”他还说:“自然界和精神是统一的。自然界不能是无理性的……而理性是不能和自然界矛盾的。”“思维规律和自然规律,只要它们被正确地认识,必然是互相一致的。”恩格斯的这些论述,深刻地揭示了自然和精神统一问题的丰富内涵。根据恩格斯的这些论述,考察中国古代的天人合一思想,不难看出,这种思想有着深刻的合理性。\n中国古代的天人合一思想,强调人与自然的统一,人的行为与自然的协调,道德理性与自然理性的一致,充分显示了中国古代思想家对于主客体之间、主观能动性和客观规律之间关系的辩证思考。根据这种思想,人不能违背自然规律,不能超越自然界的承受力去改造自然、征服自然、破坏自然,而只能在顺从自然规律的条件下去利用自然、调整自然,使之更符合人类的需要,也使自然界的万物都能生长发展。另一方面,自然界也不是主宰人其社会的神秘力量,而是可以认识、可以为我所用的客观对象。这种思想长期实践的结果,是达到自然界与人的统一,人的精神、行为与外在自然的统一,自我身心平衡与自然环境平衡的统一,以及由于这些统一而达到的天道与人道的统一,从而实现完满和谐的精神追求。中国文化的天人合一思想,对于解决当今世界由于工业化和无限制地征服自然而带来的自然环境被污染、生态平衡遭破坏等问题,具有重要的启迪意义;对于我们今天正在进行的社会主义现代化建设,更有着防患于未然的重大现实意义。\n(选自张岱年等主编的《中国文化概论》,有删改)\n根据原文提供的信息,下列推断不正确的一项是","A": "对人与自然关系的认识,中国古代天人合一思想有优于西方文化的地方。","B": "现代人重视和研究天人合一思想,是基于对现实及发展问题的思考。", "C": "肯定天人合一思想的合理性,并不意味着对其思想内容的全盘接受。", "D": "以天人合一思想为指导,可解决当今世界因工业化带来的各种社会问题。",``` |
|
||||||
|
| 语言 | 情感分析 | 情感分析是对文本中的情感或情绪进行识别和分析的任务。这类任务可用于情感倾向分析场景。例如,分析社交媒体上的用户评论,了解新闻或事件的倾向。| ```"question": "请问以下评价是正面评价还是负面评价?\n大众点评网的霸王餐,200份华辉拉肠双人试吃,员村一店是已经有经营两年以上的,年前装修过,干净齐整,下单的服务员亲切有礼,可能我是第一个用代码验证的,中间拖了点时间去验证,幸好周日10点左右没有平时的多人。拉肠一如既往的滑,皮蛋瘦肉粥很绵,皮蛋瘦肉超多,肉肠是一底带肉一底斋肠,以前没吃过鸡蛋肠觉得6蚊不太划算,现在发现是有三底肠粉的哦,不太喜欢吃肉的可以试下,很饱肚,鼓油是吃过这么多家肠粉店味道调得最好的。","A": "正面评价", "B": "负面评价"```|
|
||||||
|
| 语言 | 内容总结 | 内容总结是将一篇较长的文本压缩成一篇简短的概括性摘要。这类任务适用于需要快速了解文档核心内容的情境,如新闻标题、电子邮件摘要 | ```联合国减灾办公室负责人格拉瑟。联合国减灾办公室2016年2月11日联合国减灾办公室今天表示,2015年是有记录以来最热的一个年份,在这一年当中,自然灾害影响了近1亿人口。减灾办公室呼吁各国采取行动,应对气候变化,在最大程度上做出努力,防止和减少灾害的发生。联合国减灾办公室所公布的最新数据显示,在过去一年当中,受到灾害影响最重的国家都在亚洲,它们是中国、印度、菲律宾和印度尼西亚。自然灾害共导致2万2000人死亡,带来的经济损失约合660亿美元。然而,尽管这一数字惊人,但却低于1400亿的10年平均数字。其中的部分原因是各国政府采取了更好的防范措施。数据显示,2015年有5000万人深受旱灾之苦,增幅达40%。联合国减灾办公室负责人格拉瑟表示,2015年是记载中最热的一个年份,成因是气候变化和厄尔尼诺天气现象。他指出,最令人感到不安的一个趋势是2015年有记录的主要干旱增加了一倍。他强调,数据表明,减少温室气体排放和适应气候变化对于减少灾害风险至关重要。```|
|
||||||
|
| 语言 | 内容评价 | 内容评价是对文本的质量、价值或观点进行判断和评价的任务。这类任务可用于评论筛选、观点挖掘等场景。 | ```"question": "以下是一个问题以及针对该问题的两个答案,哪个答案更好?\n问题:创建一篇1000字的非剽窃新闻文章,关于任天堂将于2月8日星期三播出新的任天堂直面会,承诺将公布即将推出的Switch游戏的新细节。2月的任天堂直面会将在东部时间下午5点/太平洋时间下午2点,在公司的YouTube频道上直播。\n\n任天堂表示,星期三的任天堂直面会将持续“大约”40分钟,并将重点放在即将在2023年上半年推出的Nintendo Switch游戏上。\n\n任天堂宣布的Nintendo Switch游戏阵容包括《星之卡比:梦之泉豪华版》,这是2011年Wii游戏的重制版;《魔兵雅各:樱花与失落的恶魔》,这是一个以童话为灵感的冒险故事,主角是年轻的魔兵雅各;《塞尔达传说:王国之泪》,是《荒野之息》的续作;以及《皮克敏4》,这是一款长期运行的策略/动作系列的新作,仍然有些神秘。\n\n此外,任天堂的计划中,但日期尚未确定的还有《超级战争大战1+2:重启营》,这是两款Game Boy Advance时代的《超级战争》游戏的重制版。经过长时间的延迟,Switch版的《超级战争》合集据传很快就要推出。当然,任天堂在2023年还有其他一些大计划,包括2月17日在好莱坞环球影城开设的超级任天堂乐园主题公园,以及4月7日上映的《超级马里奥兄弟》电影。格斗游戏确实很酷,但可能会让人望而生畏。你可能会看到铁拳或街霸这样的竞技世界,然后想,“我可能很菜!而且没有正确的装备!而且我不懂这些术语!”但是停下来。你可以进入格斗游戏。对Pat Gill来说,这段旅程真的很有意义。以下是他如何拥抱格斗游戏,以及你也可以。\n答案 1:任天堂粉丝们正急切地期待着最新的任天堂直面发布会,该发布会定于2月8日星期三播出。该发布会将在公司的YouTube频道上以东部时间下午5点/太平洋时间下午2点的直播形式进行,承诺提供有关任天堂Switch即将推出的游戏的令人兴奋的新细节。\n\n据任天堂称,直面发布会将持续大约40分钟,专门关注2023年上半年将为Switch发布的游戏。已经宣布的一些游戏标题包括《星之卡比:梦之泉DX》、《魔兽传说:樱花与失落的恶魔》、《塞尔达传说:王国的泪滴》和《皮克敏4》。\n\n任天堂日程表上最受期待的游戏之一是《超级战争大战1+2:重启训练营》,这是两款经典Game Boy Advance游戏的重制版。尽管尚未正式宣布发行日期,但有传言称游戏将在经过长时间延迟后很快推出。\n\n除了游戏阵容外,任天堂还计划在2023年推出许多其他令人兴奋的项目,包括2月17日在好莱坞环球影城开放的超级任天堂乐园主题公园,以及4月7日上映的《超级马里奥兄弟》电影。\n\n对于格斗游戏爱好者来说,任天堂直面发布会承诺将是一个令人兴奋的活动,将提供任天堂Switch最新和最伟大游戏的一瞥。无论您是经验丰富的玩家还是刚刚开始,直面发布会中肯定会有适合每个人的内容。因此,请务必在2月8日星期三收看,以获取来自任天堂的所有最新消息和更新!\n答案 2:任天堂宣布将于2月8日星期三下午5点EST/下午2点PST,在公司的YouTube频道上播出新的任天堂Direct演示。演示将持续大约40分钟,并将提供有关2023年上半年即将推出的任天堂Switch游戏的新细节。\n\n公司宣布的任天堂Switch阵容包括《星之卡比:梦之返乡豪华版》,这是2011年Wii游戏的重制版;《魔兽师起源:赛瑞莎与失落的恶魔》,一个以童话为灵感的冒险,主角是年轻的贝约奈塔;《塞尔达传说:王国之泪》,《荒野之息》的续作;以及《皮克敏4》,这是一款长寿的策略/动作系列的新作,仍然有些神秘。\n\n此外,任天堂还有一些其他大计划,包括在2023年2月17日在好莱坞环球影城开设超级任天堂乐园主题公园,以及于4月7日上映《超级马里奥兄弟电影》。\n\n格斗游戏是一种受欢迎的游戏类型,可能是一种令人望而生畏的爱好。然而,人们是可以享受格斗游戏的,Pat Gill就是如何拥抱这种爱好的一个很好的例子。他从一个初学者开始,发现这是一段有意义的旅程。只要有正确的心态和资源,任何人都可以参与格斗游戏,并享受它们所提供的刺激和竞争。" ``` |
|
||||||
|
| 语言 | 多语言翻译 | 多语言翻译是将一种语言的文本转换为另一种语言的文本。这类任务适用于跨语言沟通、在线翻译等场景。|```"question": "Translate the following sentence from English to French: \"He [Wales] basically lied to us from the start. First, by acting as if this was for legal reasons. Second, by pretending he was listening to us, right up to his art deletion."```|
|
||||||
|
| 语言 | 中华传统文化理解 | 中华传统文化涉及对中国古代文学、艺术、哲学、历史等领域的研究 | ``` "question": "王实甫在《西厢记》中写道:“淋漓襟袖啼红泪,比司马青衫更湿”,其中“司马青衫”指的是什么"``` |
|
||||||
|
| 语言 | 中文语意理解 | 中文语意理解涉及理解文本中的词汇、短语和句子之间的语义关系,包括但不限于近义词、反义词、整体-部分关系、修饰关系等。 |``` "question": "“繁荣”与以下哪个词具有近义关系?", "A": "盛世", "B": "荣誉", "C": "繁花", "D": "昌盛"```|
|
||||||
|
| 语言 | 多轮对话 | 评价模型能否在多轮对话中保持上下文一致性和连贯性的能力,评估模型是否能够理解并记住对话的上下文信息,记住之前的对话内容。 |```[{'role': 'user','content': '我在做一项关于智能手机市场的研究,需要整理一些数据成 Markdown 表格。数据包括品牌名称、市场份额和热销型号。品牌有苹果、三星和华为。苹果的市场份额是30%,热销型号是iPhone 13;三星市场份额是25%,热销型号是Galaxy S21;华为市场份额是20%,热销型号是Mate 40。请帮我做一个表格。'},{'role': 'user','content': '看起来不错,不过我希望表格中的市场份额列展示为百分比和实际销量。苹果的销量是8000万部,三星是6000万部,华为是5000万部。'}, {'role': 'user', 'content': '很好。现在请把表格的标题中文改成英文,并且各列改成对齐方式:品牌列左对齐,市场份额列居中对齐,热销型号列右对齐。'},{'role': 'user', 'content': '可以,我注意到我们可能需要添加一列来表示这些品牌的总收入,苹果为500亿美元,三星为400亿美元,华为为350亿美元。此外,请按市场销量对行进行排序。'}]```|
|
||||||
|
| 知识 | 生活常识 | 考察普通社会上智力正常的人皆有或普遍拥有的,大众化的知识 | ```"question": "世界四大文明古国有哪些?```|
|
||||||
|
| 知识 | 自然科学(理科) | 关于自然现象的具体科学,研究自然界的本质和规律(理科):包括不限于数学,物理学,化学,生物学,天文学等 | ```"question": "群的研究对象是什么?"``` |
|
||||||
|
| 知识 | 自然科学(工科) | 关于自然现象的具体科学,研究自然界的本质和规律(工科):包括不限于计算机科学,医学,建筑学,材料学,机械学,测量学,气象学,环境学等 | ```"question": "下列关于信息安全的说法,正确的是( )。", "options": ["打开朋友转发的网页链接一定是安全的", "安装了杀毒软件后电脑就不会感染病毒", "数据加密是一种提高信息安全性的有效措施", "手机指纹识别技术能确保手机所有信息的安全"]``` |
|
||||||
|
| 知识 | 社会科学 | 研究社会现象的具体科学,力求揭示社会的本质和规律,例如经济学,政治学,军事学,社会学,管理学,教育学等。社会科学主要以人类社会的组织与结构、体制与关系、功能与效率、秩序与规范为研究认识之对象,并通过这种知识来为人类社会的有序管理、高效运作提供知识、理论和手段 | ```"question": "为了避免资金供应短缺和倒闭,企业经营者需要做什么?"``` |
|
||||||
|
| 知识 | 人文科学 | 设设计对人的问题的类型思考与情感体验,围绕着关乎人的心灵世界、关乎人的精神生命主题而展开的种种思想、观念、知识和理论的探索。它以人类自身,特别是人的内心情感世界为研究中心,以人自身的发展和完善作为学术探索的出发点和归宿。包括不限于文学,历史学、哲学、艺术、语言等 | ```"question": "光绪二十四年(1898)五月,维新派代表人物康有为从“中体西用”的角度论述了科举制度改革的必要性。这表明他( )", "options": ["在戊戌变法初期思想趋于保守", "认同洋务派的“中体西用”思想", "在教育改革方面与洋务派观点一致", "所说的“体”和“用”与洋务派不同"]``` |
|
||||||
|
| 创作 | 内容扩写 | 给定标题或者大纲的基础上,通过增加细节、描述和解释,使内容更加丰富、饱满和具有表现力。这种方法主要用于散文、小说等文学创作,以及学术论文、报告等实用文本 | ```请根据我给出的[外星人入侵、核弹、流亡]这些关键词来撰写一篇[科幻]题材的短篇故事。 \n故事需要拥有[引人入胜]的开头以及[反转]的结局,故事线[跌宕起伏]。\n注意请使用[刘慈欣]的写作风格为我撰写这篇故事。减少赘述,内容中不要有重复或意思相近的段落,大约800字``` |
|
||||||
|
| 创作 | 内容续写 | 现有文本的基础上,继续编写后面的内容。这种方法主要用于小说、故事等叙事性文本。续写部分通常要保持与原有文本的风格、情节和人物设定相一致,同时要求作者具备较强的想象力和创造力。 | ```题目:《新型能源技术在工业生产中的应用与效益》随着能源需求的不断增长和传统能源的有限性,新型能源技术在工业领域的应用备受瞩目。本文将着重探讨新型能源技术对工业生产的潜在影响,以及其在提高生产效益和减少环境影响方面的作用。请按照以上题目和摘要,完成一篇不少于1000字的论文``` |
|
||||||
|
| 创作 | 内容改写 | 不改变原文主题和基本结构的前提下,对文本进行一定程度的修改、重组和优化。这种方法主要用于修改学术论文、报告、文章等。内容改写的目的是提高文本的表达能力、逻辑性和可读性,同时避免重复。 | ```请帮我总结一封电子邮件的内容,总结需要包含以下四个部分:\n【重要性】根据内容判断事项是否重要,结果包含重要、不重要\n【紧急性】根据内容判断事项是否紧急,结果包含紧急、不紧急\n【核心内容】使用一句简短的话总结邮件最核心的内容。\n【需要回复内容】请判断邮件中哪些内容需要获得我的回复/确认,以列表形式呈现。\n 接下来,请根据下面邮件的内容,进行摘要:\n亲爱的全体员工:\n为了改善大家的身心健康,增强工作效率,公司特别安排了一场瑜伽兴趣培训,现将培训内容通知如下:\n日期及时间:8月15日(周六)上午9:00至11:00\n地点:公司三楼活动室(面积120平米,可容纳30人参加培训)\n培训内容:\n专业瑜伽教练将为大家进行基础的瑜伽技能和健康知识培训。 瑜伽是一种低强度有氧运动,适合各年龄层人群。它能够通过姿势练习、呼吸技巧等,改善身体的柔韧性和平衡感,帮助人体各系统更好地运行,有效减压提神。\n本次培训重点讲解:\n1)基本的瑜伽哲学及其健康效果介绍\n2)冥想和呼吸技巧演练\n3)10多个常见的基础瑜伽姿势示范及练习(包括猿人式、波浪式、斜 Supported Headstand 等)\n4)瑜伽练习时需要注意的安全事项\n5)瑜伽适宜穿戴的服装和个人物品\n6)参与培训后如何延续瑜伽运动\n培训具体流程:\n9:00-9:30 瑜伽基本概念介绍\n9:30-10:10 练习冥想、呼吸及基础姿势\n10:10-10:30 小休10分钟\n10:30-11:00 继续练习高难度姿势并解答问题\n如有意参加本次瑜伽兴趣培训,请于8月10日前用邮件或电话方式告知我们,我方将安排培训。\n若您有任何问题或建议,也欢迎与我联系。感谢您的收听与参与。```|
|
||||||
|
| 推理 | 逻辑推理 | 综合考察模型的几种常见逻辑推理模式:如演绎、归纳和溯因。 | ```"question": "在接下来的文本中,符号 -> 代表着一个简单的数学运算。\n695 - 472 -> 229\n222 - 62 -> 166\n689 - 439 -> ?",```|
|
||||||
|
| 推理 | 常识推理 | 常识推理是指基于日常生活中积累的知识和经验,对事物进行合理推断和判断的过程。它涉及到对常见事物、现象和规律的理解,通过综合分析得出合理的结论。 | ```"question": "美即好效应,指对一个外表英俊漂亮的人,人们很容易误认为他或她的其他方面也很不错。根据上述定义,下列哪项属于美即好效应?( )", "A": "外表英俊漂亮的人在应聘中更受招聘者的青睐", "B": "小芳认为自己的女儿是幼儿园中最漂亮的孩子", "C": "人们常说女孩因为可爱而美丽并非因为美丽而可爱", "D": "购物网站上有一个漂亮的模特往往会提高产品的销量"``` |
|
||||||
|
| 数学 | 初等数学 | 初等教育数学能力(小学数学) | ```"question": "小芳手上有40元。她的爸爸又给了她100元。她花了30元买了一条牛仔裤,又花了20元买了一个包。那么小芳还剩下多少钱呢?"```|
|
||||||
|
| 数学 | 中等数学 | 中等教育数学能力(初中和高中数学) | ```"question": "某地开展建设绿色家园活动,活动期间,计划每天种植相同数量的树木.该活动开始后,实际每天比原计划每天多植树$50$棵,实际植树$400$棵所需时间与原计划植树$300$棵所需时间相同.设实际每天植树$x$棵,则下列方程正确的是( )", "options": ["$\\frac{{400}}{{x-50}}=\\frac{{300}}{x}$", "$\\frac{{300}}{{x-50}}=\\frac{{400}}{x}$", "$\\frac{{400}}{{x+50}}=\\frac{{300}}{x}$", "$\\frac{{300}}{{x+50}}=\\frac{{400}}{x}$"]```|
|
||||||
|
| 数学 | 高等 | 高教育数学能力(大学和研究生数学) | ```"question": "已知有向曲线 $L$ 为球面 $x^2+y^2+z^2=2x$ 与平面 $2x-z-1=0$ 的交线,从 $z$ 轴正向往 $z$ 轴负向看去为逆时针方向,计算曲线积分$\\int_L(6xyz-yz^2)dx+2x^2zdy+xyzdz$.", "options": [ "$\\frac{4\\pi}{7\\sqrt5}$", "$\\frac{3\\pi}{7\\sqrt5}$", "$\\frac{3\\pi}{5\\sqrt5}$", "$\\frac{4\\pi}{5\\sqrt5}$"]``` |
|
||||||
|
| 代码 | 代码理解 | 输入为用户的需求文字或者部分代码,考察模型的逻辑推理能力和代码生成能力,考察模型对各类编程语言的掌握程度。内容包括不限于:算法和数据结构能力考察编程语言语法考察跨编程语言转换 | ```"question": "编写一个 Python 函数,用于检查两个数字是否仅在一个位置上不同。"```|
|
||||||
|
| 代码 | 代码分析 | 考察模型对代码的理解和分析能力,给定一段代码,进行代码意图分析,代码规范检查,错误检查等 | ```"question":"\n\ndef truncate_number(number: float) -> float:\n \"\"\" 给定一个正的浮点数,可以将其分解为整数部分(小于给定数字的最大整数)和小数部分(余数部分总是小于1)。\n\n 返回该数字的小数部分。\n >>> truncate_number(3.5)\n 0.5\n \"\"\"",``` |
|
||||||
|
| 长文本 | 长文本理解与推理 | 考察模型在不同的长度上下文(2k, 4k, 8k, 16k, 32k)情况下的理解和推理能力 | 略 |
|
||||||
|
| 智能体 | 任务规划 | 智能体根据用户的需求目标和具备工具条件,进行合理的任务拆解,科学地安排子任务的执行顺序和策略,对任务执行路径进行设计和规划,选择合适的策略。 | 略|
|
||||||
|
| 智能体 | 工具调用 | 评估模型能否准确的调用合适的API,在调用API时能否正确的传递参数 | 略 |
|
||||||
|
| 智能体 | 反思能力 | 评估模型在子任务执行失败时,是否具有反思和重新规划任务路径的能力 | 略 |
|
||||||
|
| 智能体 | 任务执行总结 | 评估模型能否根据子任务的执行结果进行总结分析,完成原始任务目标,正确地按指令输出回复 | 略|
|
||||||
|
| 智能体 | 多轮交互 | 评估模型在进行多轮复杂工具调用时的能力,在多轮情况下能否准确理解意图 | 略 |
|
||||||
|
|
@ -0,0 +1,122 @@
|
||||||
|
# 数据污染评估
|
||||||
|
|
||||||
|
**数据污染** 是指本应用在下游测试任务重的数据出现在了大语言模型 (LLM) 的训练数据中,从而导致在下游任务 (例如,摘要、自然语言推理、文本分类) 上指标虚高,无法反映模型真实泛化能力的现象。
|
||||||
|
|
||||||
|
由于数据污染的源头是出现在 LLM 所用的训练数据中,因此最直接的检测数据污染的方法就是将测试数据与训练数据进行碰撞,然后汇报两者之间有多少语料是重叠出现的,经典的 GPT-3 [论文](https://arxiv.org/pdf/2005.14165.pdf)中的表 C.1 会报告了相关内容。
|
||||||
|
|
||||||
|
但如今开源社区往往只会公开模型参数而非训练数据集,在此种情况下 如何判断是否存在数据污染问题或污染程度如何,这些问题还没有被广泛接受的解决方案。OpenCompass 提供了两种可能的解决方案。
|
||||||
|
|
||||||
|
## 基于自建同分布数据的污染数据标注
|
||||||
|
|
||||||
|
我们参考了 [Skywork](https://arxiv.org/pdf/2310.19341.pdf) 中 5.2 节提到的方法,直接使用了 Skywork 上传到 HuggingFace 上的数据集 [mock_gsm8k_test](https://huggingface.co/datasets/Skywork/mock_gsm8k_test)。
|
||||||
|
|
||||||
|
在该方法中,作者使用 GPT-4 合成了一批与原始 GSM8K 风格类似的数据,然后使用模型分别计算在 GSM8K 训练集 (train),GSM8K 测试集 (test),GSM8K 参考集 (ref) 上的困惑度。由于 GSM8K 参考集是最新生成的,作者认为它必然不属于任何模型的任何训练集中,即它是干净的。作者认为:
|
||||||
|
|
||||||
|
- 若 测试集 的困惑度远小于 参考集 的困惑度,那么 测试集 可能出现在了模型的训练阶段;
|
||||||
|
- 若 训练集 的困惑度远小于 测试集 的困惑度,那么 训练集 可能被模型过拟合了。
|
||||||
|
|
||||||
|
我们可以参考使用以下配置文件:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.gsm8k_contamination.gsm8k_contamination_ppl_ecdd22 import gsm8k_datasets # 包含训练、测试、参考集
|
||||||
|
from .models.qwen.hf_qwen_7b import models as hf_qwen_7b_model # 待审查的模型
|
||||||
|
from .models.yi.hf_yi_6b import models as hf_yi_6b_model
|
||||||
|
|
||||||
|
datasets = [*gsm8k_datasets]
|
||||||
|
models = [*hf_qwen_7b_model, *hf_yi_6b_model]
|
||||||
|
```
|
||||||
|
|
||||||
|
其样例输出如下:
|
||||||
|
|
||||||
|
```text
|
||||||
|
dataset version metric mode internlm-7b-hf qwen-7b-hf yi-6b-hf chatglm3-6b-base-hf qwen-14b-hf baichuan2-13b-base-hf internlm-20b-hf aquila2-34b-hf ...
|
||||||
|
--------------- --------- ----------- ------- ---------------- ------------ ---------- --------------------- ------------- ----------------------- ----------------- ---------------- ...
|
||||||
|
gsm8k-train-ppl 0b8e46 average_ppl unknown 1.5 0.78 1.37 1.16 0.5 0.76 1.41 0.78 ...
|
||||||
|
gsm8k-test-ppl 0b8e46 average_ppl unknown 1.56 1.33 1.42 1.3 1.15 1.13 1.52 1.16 ...
|
||||||
|
gsm8k-ref-ppl f729ba average_ppl unknown 1.55 1.2 1.43 1.35 1.27 1.19 1.47 1.35 ...
|
||||||
|
```
|
||||||
|
|
||||||
|
目前该方案仅支持 GSM8K 数据集,我们欢迎社区贡献更多的数据集。
|
||||||
|
|
||||||
|
如果使用了该方法,请添加引用:
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
}
|
||||||
|
@misc{wei2023skywork,
|
||||||
|
title={Skywork: A More Open Bilingual Foundation Model},
|
||||||
|
author={Tianwen Wei and Liang Zhao and Lichang Zhang and Bo Zhu and Lijie Wang and Haihua Yang and Biye Li and Cheng Cheng and Weiwei Lü and Rui Hu and Chenxia Li and Liu Yang and Xilin Luo and Xuejie Wu and Lunan Liu and Wenjun Cheng and Peng Cheng and Jianhao Zhang and Xiaoyu Zhang and Lei Lin and Xiaokun Wang and Yutuan Ma and Chuanhai Dong and Yanqi Sun and Yifu Chen and Yongyi Peng and Xiaojuan Liang and Shuicheng Yan and Han Fang and Yahui Zhou},
|
||||||
|
year={2023},
|
||||||
|
eprint={2310.19341},
|
||||||
|
archivePrefix={arXiv},
|
||||||
|
primaryClass={cs.CL}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 基于经典预训练集的污染数据标注
|
||||||
|
|
||||||
|
感谢 [Contamination_Detector](https://github.com/liyucheng09/Contamination_Detector) 以及 @liyucheng09 提供了本方法。
|
||||||
|
|
||||||
|
在该方法中,作者将测试数据集 (例如 C-Eval, ARC, HellaSwag 等) 使用 Common Crawl 数据库和 Bing 搜索引擎来进行检索,然后依次标记每条测试样本是 干净的 / 题目被污染的 / 题目和答案均被污染的。
|
||||||
|
|
||||||
|
测试时,OpenCompass 会分别汇报 ceval 在三种标签所组成的子集上的准确率或困惑度。一般来说,准确率从低到高依次是 干净的,题目被污染的,题目和答案均被污染的 子集。作者认为:
|
||||||
|
|
||||||
|
- 若三者性能较为接近,则模型在该测试集上的污染程度较轻;反之则污染程度较重。
|
||||||
|
|
||||||
|
我们可以参考使用以下配置文件 [link](https://github.com/open-compass/opencompass/blob/main/configs/eval_contamination.py):
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.ceval.ceval_clean_ppl import ceval_datasets # 有污染标记的 ceval 数据集
|
||||||
|
from .models.yi.hf_yi_6b import models as hf_yi_6b_model # 待审查的模型
|
||||||
|
from .models.qwen.hf_qwen_7b import models as hf_qwen_7b_model
|
||||||
|
from .summarizers.contamination import ceval_summarizer as summarizer # 输出格式整理
|
||||||
|
|
||||||
|
datasets = [*ceval_datasets]
|
||||||
|
models = [*hf_yi_6b_model, *hf_qwen_7b_model]
|
||||||
|
```
|
||||||
|
|
||||||
|
其样例输出如下:
|
||||||
|
|
||||||
|
```text
|
||||||
|
dataset version mode yi-6b-hf - - qwen-7b-hf - - ...
|
||||||
|
---------------------------------------------- --------- ------ ---------------- ----------------------------- --------------------------------------- ---------------- ----------------------------- --------------------------------------- ...
|
||||||
|
- - - accuracy - clean accuracy - input contaminated accuracy - input-and-label contaminated accuracy - clean accuracy - input contaminated accuracy - input-and-label contaminated ...
|
||||||
|
...
|
||||||
|
ceval-humanities - ppl 74.42 75.00 82.14 67.44 50.00 70.54 ...
|
||||||
|
ceval-stem - ppl 53.70 57.14 85.61 47.41 52.38 67.63 ...
|
||||||
|
ceval-social-science - ppl 81.60 84.62 83.09 76.00 61.54 72.79 ...
|
||||||
|
ceval-other - ppl 72.31 73.91 75.00 58.46 39.13 61.88 ...
|
||||||
|
ceval-hard - ppl 44.35 37.50 70.00 41.13 25.00 30.00 ...
|
||||||
|
ceval - ppl 67.32 71.01 81.17 58.97 49.28 67.82 ...
|
||||||
|
```
|
||||||
|
|
||||||
|
目前该方案仅支持 C-Eval, MMLU, HellaSwag 和 ARC 数据集,[Contamination_Detector](https://github.com/liyucheng09/Contamination_Detector) 中还包含了 CSQA 和 WinoGrande,但目前还没有在 OpenCompass 中实现。我们欢迎社区贡献更多的数据集。
|
||||||
|
|
||||||
|
如果使用了该方法,请添加引用:
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished = {\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
}
|
||||||
|
@article{Li2023AnOS,
|
||||||
|
title={An Open Source Data Contamination Report for Llama Series Models},
|
||||||
|
author={Yucheng Li},
|
||||||
|
journal={ArXiv},
|
||||||
|
year={2023},
|
||||||
|
volume={abs/2310.17589},
|
||||||
|
url={https://api.semanticscholar.org/CorpusID:264490711}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,147 @@
|
||||||
|
# 自定义数据集
|
||||||
|
|
||||||
|
本教程仅供临时性的、非正式的数据集使用,如果所用数据集需要长期使用,或者存在定制化读取 / 推理 / 评测需求的,强烈建议按照 [new_dataset.md](./new_dataset.md) 中介绍的方法进行实现。
|
||||||
|
|
||||||
|
在本教程中,我们将会介绍如何在不实现 config,不修改 OpenCompass 源码的情况下,对一新增数据集进行测试的方法。我们支持的任务类型包括选择 (`mcq`) 和问答 (`qa`) 两种,其中 `mcq` 支持 `ppl` 推理和 `gen` 推理;`qa` 支持 `gen` 推理。
|
||||||
|
|
||||||
|
## 数据集格式
|
||||||
|
|
||||||
|
我们支持 `.jsonl` 和 `.csv` 两种格式的数据集。
|
||||||
|
|
||||||
|
### 选择题 (`mcq`)
|
||||||
|
|
||||||
|
对于选择 (`mcq`) 类型的数据,默认的字段如下:
|
||||||
|
|
||||||
|
- `question`: 表示选择题的题干
|
||||||
|
- `A`, `B`, `C`, ...: 使用单个大写字母表示选项,个数不限定。默认只会从 `A` 开始,解析连续的字母作为选项。
|
||||||
|
- `answer`: 表示选择题的正确答案,其值必须是上述所选用的选项之一,如 `A`, `B`, `C` 等。
|
||||||
|
|
||||||
|
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 `.meta.json` 文件中进行指定。
|
||||||
|
|
||||||
|
`.jsonl` 格式样例如下:
|
||||||
|
|
||||||
|
```jsonl
|
||||||
|
{"question": "165+833+650+615=", "A": "2258", "B": "2263", "C": "2281", "answer": "B"}
|
||||||
|
{"question": "368+959+918+653+978=", "A": "3876", "B": "3878", "C": "3880", "answer": "A"}
|
||||||
|
{"question": "776+208+589+882+571+996+515+726=", "A": "5213", "B": "5263", "C": "5383", "answer": "B"}
|
||||||
|
{"question": "803+862+815+100+409+758+262+169=", "A": "4098", "B": "4128", "C": "4178", "answer": "C"}
|
||||||
|
```
|
||||||
|
|
||||||
|
`.csv` 格式样例如下:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
question,A,B,C,answer
|
||||||
|
127+545+588+620+556+199=,2632,2635,2645,B
|
||||||
|
735+603+102+335+605=,2376,2380,2410,B
|
||||||
|
506+346+920+451+910+142+659+850=,4766,4774,4784,C
|
||||||
|
504+811+870+445=,2615,2630,2750,B
|
||||||
|
```
|
||||||
|
|
||||||
|
### 问答题 (`qa`)
|
||||||
|
|
||||||
|
对于问答 (`qa`) 类型的数据,默认的字段如下:
|
||||||
|
|
||||||
|
- `question`: 表示问答题的题干
|
||||||
|
- `answer`: 表示问答题的正确答案。可缺失,表示该数据集无正确答案。
|
||||||
|
|
||||||
|
对于非默认字段,我们都会进行读入,但默认不会使用。如需使用,则需要在 `.meta.json` 文件中进行指定。
|
||||||
|
|
||||||
|
`.jsonl` 格式样例如下:
|
||||||
|
|
||||||
|
```jsonl
|
||||||
|
{"question": "752+361+181+933+235+986=", "answer": "3448"}
|
||||||
|
{"question": "712+165+223+711=", "answer": "1811"}
|
||||||
|
{"question": "921+975+888+539=", "answer": "3323"}
|
||||||
|
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}
|
||||||
|
```
|
||||||
|
|
||||||
|
`.csv` 格式样例如下:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
question,answer
|
||||||
|
123+147+874+850+915+163+291+604=,3967
|
||||||
|
149+646+241+898+822+386=,3142
|
||||||
|
332+424+582+962+735+798+653+214=,4700
|
||||||
|
649+215+412+495+220+738+989+452=,4170
|
||||||
|
```
|
||||||
|
|
||||||
|
## 命令行列表
|
||||||
|
|
||||||
|
自定义数据集可直接通过命令行来调用开始评测。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--models hf_llama2_7b \
|
||||||
|
--custom-dataset-path xxx/test_mcq.csv \
|
||||||
|
--custom-dataset-data-type mcq \
|
||||||
|
--custom-dataset-infer-method ppl
|
||||||
|
```
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--models hf_llama2_7b \
|
||||||
|
--custom-dataset-path xxx/test_qa.jsonl \
|
||||||
|
--custom-dataset-data-type qa \
|
||||||
|
--custom-dataset-infer-method gen
|
||||||
|
```
|
||||||
|
|
||||||
|
在绝大多数情况下,`--custom-dataset-data-type` 和 `--custom-dataset-infer-method` 可以省略,OpenCompass 会根据以下逻辑进行设置:
|
||||||
|
|
||||||
|
- 如果从数据集文件中可以解析出选项,如 `A`, `B`, `C` 等,则认定该数据集为 `mcq`,否则认定为 `qa`。
|
||||||
|
- 默认 `infer_method` 为 `gen`。
|
||||||
|
|
||||||
|
## 配置文件
|
||||||
|
|
||||||
|
在原配置文件中,直接向 `datasets` 变量中添加新的项即可即可。自定义数据集亦可与普通数据集混用。
|
||||||
|
|
||||||
|
```python
|
||||||
|
datasets = [
|
||||||
|
{"path": "xxx/test_mcq.csv", "data_type": "mcq", "infer_method": "ppl"},
|
||||||
|
{"path": "xxx/test_qa.jsonl", "data_type": "qa", "infer_method": "gen"},
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## 数据集补充信息 `.meta.json`
|
||||||
|
|
||||||
|
OpenCompass 会默认尝试对输入的数据集文件进行解析,因此在绝大多数情况下,`.meta.json` 文件都是 **不需要** 的。但是,如果数据集的字段名不是默认的字段名,或者需要自定义提示词,则需要在 `.meta.json` 文件中进行指定。
|
||||||
|
|
||||||
|
我们会在数据集同级目录下,以文件名+`.meta.json` 的形式放置一个表征数据集使用方法的文件,样例文件结构如下:
|
||||||
|
|
||||||
|
```tree
|
||||||
|
.
|
||||||
|
├── test_mcq.csv
|
||||||
|
├── test_mcq.csv.meta.json
|
||||||
|
├── test_qa.jsonl
|
||||||
|
└── test_qa.jsonl.meta.json
|
||||||
|
```
|
||||||
|
|
||||||
|
该文件可能字段如下:
|
||||||
|
|
||||||
|
- `abbr` (str): 数据集缩写,作为该数据集的 ID。
|
||||||
|
- `data_type` (str): 数据集类型,可选值为 `mcq` 和 `qa`.
|
||||||
|
- `infer_method` (str): 推理方法,可选值为 `ppl` 和 `gen`.
|
||||||
|
- `human_prompt` (str): 用户提示词模板,用于生成提示词。模板中的变量使用 `{}` 包裹,如 `{question}`,`{opt1}` 等。如存在 `template`,则该字段会被忽略。
|
||||||
|
- `bot_prompt` (str): 机器人提示词模板,用于生成提示词。模板中的变量使用 `{}` 包裹,如 `{answer}` 等。如存在 `template`,则该字段会被忽略。
|
||||||
|
- `template` (str or dict): 问题模板,用于生成提示词。模板中的变量使用 `{}` 包裹,如 `{question}`,`{opt1}` 等。相关语法见[此处](../prompt/prompt_template.md) 关于 `infer_cfg['prompt_template']['template']` 的内容。
|
||||||
|
- `input_columns` (list): 输入字段列表,用于读入数据。
|
||||||
|
- `output_column` (str): 输出字段,用于读入数据。
|
||||||
|
- `options` (list): 选项列表,用于读入数据,仅在 `data_type` 为 `mcq` 时有效。
|
||||||
|
|
||||||
|
样例如下:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"human_prompt": "Question: 127 + 545 + 588 + 620 + 556 + 199 =\nA. 2632\nB. 2635\nC. 2645\nAnswer: Let's think step by step, 127 + 545 + 588 + 620 + 556 + 199 = 672 + 588 + 620 + 556 + 199 = 1260 + 620 + 556 + 199 = 1880 + 556 + 199 = 2436 + 199 = 2635. So the answer is B.\nQuestion: {question}\nA. {A}\nB. {B}\nC. {C}\nAnswer: ",
|
||||||
|
"bot_prompt": "{answer}"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
或者
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"template": "Question: {my_question}\nX. {X}\nY. {Y}\nZ. {Z}\nW. {W}\nAnswer:",
|
||||||
|
"input_columns": ["my_question", "X", "Y", "Z", "W"],
|
||||||
|
"output_column": "my_answer",
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,71 @@
|
||||||
|
# 评测 Lightllm 模型
|
||||||
|
|
||||||
|
我们支持评测使用 [Lightllm](https://github.com/ModelTC/lightllm) 进行推理的大语言模型。Lightllm 是由商汤科技开发,是一个基于 Python 的 LLM 推理和服务框架,以其轻量级设计、易于扩展和高速性能而著称,Lightllm 对多种大模型都进行了支持。用户可以通过 Lightllm 进行模型推理,并且以服务的形式在本地起起来,在评测过程中,OpenCompass 通过 api 将数据喂给Lightllm,并对返回的结果进行处理。OpenCompass 对 Lightllm 进行了适配,本教程将介绍如何使用 OpenCompass 来对以 Lightllm 作为推理后端的模型进行评测。
|
||||||
|
|
||||||
|
## 环境配置
|
||||||
|
|
||||||
|
### 安装 OpenCompass
|
||||||
|
|
||||||
|
请根据 OpenCompass [安装指南](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) 来安装算法库和准备数据集。
|
||||||
|
|
||||||
|
### 安装 Lightllm
|
||||||
|
|
||||||
|
请根据 [Lightllm 主页](https://github.com/ModelTC/lightllm) 来安装 Lightllm。注意对齐相关依赖库的版本,尤其是 transformers 的版本。
|
||||||
|
|
||||||
|
## 评测
|
||||||
|
|
||||||
|
我们以 llama2-7B 评测 humaneval 作为例子来介绍如何评测。
|
||||||
|
|
||||||
|
### 第一步: 将模型通过 Lightllm 在本地以服务的形式起起来
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m lightllm.server.api_server --model_dir /path/llama2-7B \
|
||||||
|
--host 0.0.0.0 \
|
||||||
|
--port 1030 \
|
||||||
|
--nccl_port 2066 \
|
||||||
|
--max_req_input_len 4096 \
|
||||||
|
--max_req_total_len 6144 \
|
||||||
|
--tp 1 \
|
||||||
|
--trust_remote_code \
|
||||||
|
--max_total_token_num 120000
|
||||||
|
```
|
||||||
|
|
||||||
|
**注:** 上述命令可以通过 tp 的数量设置,在 tp 张卡上进行 TensorParallel 推理,适用于较大的模型的推理。
|
||||||
|
|
||||||
|
**注:** 上述命令中的 max_total_token_num,会影响测试过程中的吞吐性能,可以根据 [Lightllm 主页](https://github.com/ModelTC/lightllm) 上的文档,进行设置。只要不爆显存,往往设置越大越好。
|
||||||
|
|
||||||
|
**注:** 如果要在同一个机器上起多个 Lightllm 服务,需要重新设定上面的 port 和 nccl_port。
|
||||||
|
|
||||||
|
可以使用下面的 Python 脚本简单测试一下当前服务是否已经起成功
|
||||||
|
|
||||||
|
```python
|
||||||
|
import time
|
||||||
|
import requests
|
||||||
|
import json
|
||||||
|
|
||||||
|
url = 'http://localhost:8080/generate'
|
||||||
|
headers = {'Content-Type': 'application/json'}
|
||||||
|
data = {
|
||||||
|
'inputs': 'What is AI?',
|
||||||
|
"parameters": {
|
||||||
|
'do_sample': False,
|
||||||
|
'ignore_eos': False,
|
||||||
|
'max_new_tokens': 1024,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
response = requests.post(url, headers=headers, data=json.dumps(data))
|
||||||
|
if response.status_code == 200:
|
||||||
|
print(response.json())
|
||||||
|
else:
|
||||||
|
print('Error:', response.status_code, response.text)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 第二步: 使用 OpenCompass 评测上述模型
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py configs/eval_lightllm.py
|
||||||
|
```
|
||||||
|
|
||||||
|
当模型完成推理和指标计算后,我们便可获得模型的评测结果。
|
||||||
|
|
||||||
|
**注:** `eval_lightllm.py` 中,配置的 url 要和上一步服务地址对齐。
|
||||||
|
|
@ -0,0 +1,86 @@
|
||||||
|
# 使用 LMDeploy 加速评测
|
||||||
|
|
||||||
|
我们支持在评测大语言模型时,使用 [LMDeploy](https://github.com/InternLM/lmdeploy) 作为推理加速引擎。LMDeploy 是涵盖了 LLM 和 VLM 任务的全套轻量化、部署和服务解决方案,拥有卓越的推理性能。本教程将介绍如何使用 LMDeploy 加速对模型的评测。
|
||||||
|
|
||||||
|
## 环境配置
|
||||||
|
|
||||||
|
### 安装 OpenCompass
|
||||||
|
|
||||||
|
请根据 OpenCompass [安装指南](https://opencompass.readthedocs.io/en/latest/get_started/installation.html) 来安装算法库和准备数据集。
|
||||||
|
|
||||||
|
### 安装 LMDeploy
|
||||||
|
|
||||||
|
使用 pip 安装 LMDeploy (python 3.8+):
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
LMDeploy 预编译包默认基于 CUDA 12 编译。如果需要在 CUDA 11+ 下安装 LMDeploy,请执行以下命令:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export LMDEPLOY_VERSION=0.6.0
|
||||||
|
export PYTHON_VERSION=310
|
||||||
|
pip install https://github.com/InternLM/lmdeploy/releases/download/v${LMDEPLOY_VERSION}/lmdeploy-${LMDEPLOY_VERSION}+cu118-cp${PYTHON_VERSION}-cp${PYTHON_VERSION}-manylinux2014_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu118
|
||||||
|
```
|
||||||
|
|
||||||
|
## 评测
|
||||||
|
|
||||||
|
在评测一个模型时,需要准备一份评测配置,指明评测集、模型和推理参数等信息。
|
||||||
|
|
||||||
|
以 [internlm2-chat-7b](https://huggingface.co/internlm/internlm2-chat-7b) 模型为例,相关的配置信息如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# configure the dataset
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# choose a list of datasets
|
||||||
|
from .datasets.mmlu.mmlu_gen_a484b3 import mmlu_datasets
|
||||||
|
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
|
||||||
|
from .datasets.triviaqa.triviaqa_gen_2121ce import triviaqa_datasets
|
||||||
|
from opencompass.configs.datasets.gsm8k.gsm8k_0shot_v2_gen_a58960 import \
|
||||||
|
gsm8k_datasets
|
||||||
|
# and output the results in a chosen format
|
||||||
|
from .summarizers.medium import summarizer
|
||||||
|
|
||||||
|
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
|
||||||
|
|
||||||
|
# configure lmdeploy
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# configure the model
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr=f'internlm2-chat-7b-lmdeploy',
|
||||||
|
# model path, which can be the address of a model repository on the Hugging Face Hub or a local path
|
||||||
|
path='internlm/internlm2-chat-7b',
|
||||||
|
# inference backend of LMDeploy. It can be either 'turbomind' or 'pytorch'.
|
||||||
|
# If the model is not supported by 'turbomind', it will fallback to
|
||||||
|
# 'pytorch'
|
||||||
|
backend='turbomind',
|
||||||
|
# For the detailed engine config and generation config, please refer to
|
||||||
|
# https://github.com/InternLM/lmdeploy/blob/main/lmdeploy/messages.py
|
||||||
|
engine_config=dict(tp=1),
|
||||||
|
gen_config=dict(do_sample=False),
|
||||||
|
# the max size of the context window
|
||||||
|
max_seq_len=7168,
|
||||||
|
# the max number of new tokens
|
||||||
|
max_out_len=1024,
|
||||||
|
# the max number of prompts that LMDeploy receives
|
||||||
|
# in `generate` function
|
||||||
|
batch_size=5000,
|
||||||
|
run_cfg=dict(num_gpus=1),
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
把上述配置放在文件中,比如 "configs/eval_internlm2_lmdeploy.py"。然后,在 OpenCompass 的项目目录下,执行如下命令可得到评测结果:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py configs/eval_internlm2_lmdeploy.py -w outputs
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,268 @@
|
||||||
|
# LLM 作为评判器
|
||||||
|
|
||||||
|
## 简介
|
||||||
|
|
||||||
|
GenericLLMEvaluator组件特别适用于那些难以通过规则式方法(如正则表达式)进行完美判断的场景,例如:
|
||||||
|
|
||||||
|
- 模型不输出选项标识而只输出选项内容的情况
|
||||||
|
- 需要事实性判断的数据集
|
||||||
|
- 需要复杂理解和推理的开放式回答
|
||||||
|
- 需要设计大量规则的判断
|
||||||
|
|
||||||
|
OpenCompass提供了GenericLLMEvaluator组件来实现LLM作为评判器的评估。
|
||||||
|
|
||||||
|
## 数据集格式
|
||||||
|
|
||||||
|
用于LLM评判的数据集应该是JSON Lines (.jsonl)或CSV格式。每个条目至少应包含:
|
||||||
|
|
||||||
|
- 问题或任务
|
||||||
|
- 参考答案或标准答案
|
||||||
|
- (模型的预测将在评估过程中生成)
|
||||||
|
|
||||||
|
JSONL格式示例:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"problem": "法国的首都是什么?", "answer": "巴黎"}
|
||||||
|
```
|
||||||
|
|
||||||
|
CSV格式示例:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
problem,answer
|
||||||
|
"法国的首都是什么?","巴黎"
|
||||||
|
```
|
||||||
|
|
||||||
|
## 配置说明
|
||||||
|
|
||||||
|
### 基于命令行使用LLM进行评估
|
||||||
|
|
||||||
|
OpenCompass中部分数据集已经包含了LLM评判器的配置。
|
||||||
|
你需要使用一个模型服务(如OpenAI或DeepSeek官方提供的API)或本地使用LMDeploy、vLLM、SGLang等工具启动一个模型服务。
|
||||||
|
|
||||||
|
然后,你可以通过以下命令设置相关评估服务的环境变量,并对模型进行评估:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
export OC_JUDGE_MODEL=Qwen/Qwen2.5-32B-Instruct
|
||||||
|
export OC_JUDGE_API_KEY=sk-1234
|
||||||
|
export OC_JUDGE_API_BASE=http://172.30.56.1:4000/v1
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,默认情况下,OpenCompass会使用这三个环境变量,但如果你使用了基于配置文件的方式配置评估服务,这三个环境变量将不会生效。
|
||||||
|
|
||||||
|
### 基于配置文件使用LLM进行评估
|
||||||
|
|
||||||
|
对一个数据集设置LLM评判评估,你需要配置三个主要组件:
|
||||||
|
|
||||||
|
1. 数据集读取配置
|
||||||
|
|
||||||
|
```python
|
||||||
|
reader_cfg = dict(
|
||||||
|
input_columns=['problem'], # 问题列的名称
|
||||||
|
output_column='answer' # 参考答案列的名称
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 推理配置
|
||||||
|
|
||||||
|
```python
|
||||||
|
infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}', # 提示模型的模板
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 使用LLM评判器的评估配置
|
||||||
|
|
||||||
|
```python
|
||||||
|
eval_cfg = dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=GenericLLMEvaluator, # 使用LLM作为评估器
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
begin=[
|
||||||
|
dict(
|
||||||
|
role='SYSTEM',
|
||||||
|
fallback_role='HUMAN',
|
||||||
|
prompt="你是一个负责评估模型输出正确性和质量的助手。",
|
||||||
|
)
|
||||||
|
],
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', prompt=YOUR_JUDGE_TEMPLATE), # 评判器的模板
|
||||||
|
],
|
||||||
|
),
|
||||||
|
),
|
||||||
|
dataset_cfg=dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
path='path/to/your/dataset',
|
||||||
|
file_name='your_dataset.jsonl',
|
||||||
|
reader_cfg=reader_cfg,
|
||||||
|
),
|
||||||
|
judge_cfg=YOUR_JUDGE_MODEL_CONFIG, # 评判模型的配置
|
||||||
|
dict_postprocessor=dict(type=generic_llmjudge_postprocess), # 处理评判器输出的后处理器
|
||||||
|
),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 使用CustomDataset和GenericLLMEvaluator
|
||||||
|
|
||||||
|
以下是如何设置完整的LLM评判评估配置:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
from opencompass.datasets import CustomDataset
|
||||||
|
from opencompass.evaluator import GenericLLMEvaluator
|
||||||
|
from opencompass.datasets import generic_llmjudge_postprocess
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||||
|
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||||
|
|
||||||
|
# 导入评判模型配置
|
||||||
|
with read_base():
|
||||||
|
from opencompass.configs.models.qwen2_5.lmdeploy_qwen2_5_14b_instruct import (
|
||||||
|
models as judge_model,
|
||||||
|
)
|
||||||
|
|
||||||
|
# 定义评判模板
|
||||||
|
JUDGE_TEMPLATE = """
|
||||||
|
请评估以下回答是否正确地回答了问题。
|
||||||
|
问题:{problem}
|
||||||
|
参考答案:{answer}
|
||||||
|
模型回答:{prediction}
|
||||||
|
|
||||||
|
模型回答是否正确?如果正确,请回答"A";如果不正确,请回答"B"。
|
||||||
|
""".strip()
|
||||||
|
|
||||||
|
# 数据集读取配置
|
||||||
|
reader_cfg = dict(input_columns=['problem'], output_column='answer')
|
||||||
|
|
||||||
|
# 被评估模型的推理配置
|
||||||
|
infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}',
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
|
||||||
|
# 使用LLM评判器的评估配置
|
||||||
|
eval_cfg = dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=GenericLLMEvaluator,
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
begin=[
|
||||||
|
dict(
|
||||||
|
role='SYSTEM',
|
||||||
|
fallback_role='HUMAN',
|
||||||
|
prompt="你是一个负责评估模型输出正确性和质量的助手。",
|
||||||
|
)
|
||||||
|
],
|
||||||
|
round=[
|
||||||
|
dict(role='HUMAN', prompt=JUDGE_TEMPLATE),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
),
|
||||||
|
dataset_cfg=dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
path='path/to/your/dataset',
|
||||||
|
file_name='your_dataset.jsonl',
|
||||||
|
reader_cfg=reader_cfg,
|
||||||
|
),
|
||||||
|
judge_cfg=judge_model[0],
|
||||||
|
dict_postprocessor=dict(type=generic_llmjudge_postprocess),
|
||||||
|
),
|
||||||
|
pred_role='BOT',
|
||||||
|
)
|
||||||
|
|
||||||
|
# 数据集配置
|
||||||
|
datasets = [
|
||||||
|
dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
abbr='my-dataset',
|
||||||
|
path='path/to/your/dataset',
|
||||||
|
file_name='your_dataset.jsonl',
|
||||||
|
reader_cfg=reader_cfg,
|
||||||
|
infer_cfg=infer_cfg,
|
||||||
|
eval_cfg=eval_cfg,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# 被评估模型的配置
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr='model-to-evaluate',
|
||||||
|
path='path/to/your/model',
|
||||||
|
# ... 其他模型配置
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# 输出目录
|
||||||
|
work_dir = './outputs/llm_judge_eval'
|
||||||
|
```
|
||||||
|
|
||||||
|
## GenericLLMEvaluator
|
||||||
|
|
||||||
|
GenericLLMEvaluator专为使用LLM作为评判器评估模型输出而设计。主要特点包括:
|
||||||
|
|
||||||
|
1. 灵活的提示模板,用于指导评判器
|
||||||
|
2. 支持各种评判模型(本地或基于API)
|
||||||
|
3. 通过提示工程自定义评估标准
|
||||||
|
4. 对评判器输出进行后处理以提取结构化评估
|
||||||
|
|
||||||
|
**重要说明**:目前通用版本的评判模板只支持输出"A"(正确)或"B"(不正确)的格式,不支持其他输出格式(如"正确"或"不正确")。这是因为后处理函数`generic_llmjudge_postprocess`专门设计为解析这种格式。
|
||||||
|
|
||||||
|
评估器的工作原理:
|
||||||
|
|
||||||
|
1. 获取原始问题、参考答案和模型预测
|
||||||
|
2. 将它们格式化为评判模型的提示
|
||||||
|
3. 解析评判器的响应以确定评估结果(寻找"A"或"B")
|
||||||
|
4. 汇总整个数据集的结果
|
||||||
|
|
||||||
|
如果需要查看评估的详细结果,可以在启动任务时添加`--dump-eval-details`到命令行。
|
||||||
|
评估输出示例:
|
||||||
|
|
||||||
|
```python
|
||||||
|
{
|
||||||
|
'accuracy': 75.0, # 被判断为正确的回答百分比
|
||||||
|
'details': [
|
||||||
|
{
|
||||||
|
'origin_prompt': """
|
||||||
|
请评估以下回答是否正确地回答了问题。
|
||||||
|
问题:法国的首都是什么?
|
||||||
|
参考答案:巴黎
|
||||||
|
模型回答:法国的首都是巴黎。
|
||||||
|
模型回答是否正确?如果正确,请回答"A";如果不正确,请回答"B"。""",
|
||||||
|
'gold': '巴黎',
|
||||||
|
'prediction': 'A',
|
||||||
|
},
|
||||||
|
# ... 更多结果
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 完整示例
|
||||||
|
|
||||||
|
有关完整的工作示例,请参考examples目录中的`eval_llm_judge.py`文件,该文件演示了如何使用LLM评判器评估数学问题解决能力。
|
||||||
|
|
@ -0,0 +1,169 @@
|
||||||
|
# 长文本评测指引
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
虽然大语言模型(LLM)如GPT-4在处理自然语言任务已经展现出明显的优势,但目前的开源模型大多只能处理数千个token长度以内的文本,这限制了模型阅读书籍、撰写文本摘要等需要处理长文本的能力。为了探究模型在应对长文本能力时的表现,我们采用[L-Eval](https://github.com/OpenLMLab/LEval)和[LongBench](https://github.com/THUDM/LongBench)两个长文本数据集来测试模型长文本能力。
|
||||||
|
|
||||||
|
## 现有算法及模型
|
||||||
|
|
||||||
|
在处理长文本输入时,推理时间开销和灾难性遗忘是大模型面临的两大主要挑战。最近,大量研究致力于扩展模型长度,这些研究集中于以下三个改进方向。
|
||||||
|
|
||||||
|
- 注意力机制。这些方法的最终目的多为减少query-key对的计算开销,但可能对下游任务的效果产生影响。
|
||||||
|
- 输入方法。部分研究将长文本输入分块或将部分已有文本段重复输入模型以增强模型处理长文本能力,但这些方法只对部分任务有效,难以适应多种下游任务。
|
||||||
|
- 位置编码。这部分研究包括RoPE, ALiBi,位置插值等,在长度外推方面展现出了良好的效果。这些方法已经被用于训练如ChatGLM2-6b-32k和LongChat-32k等长文本模型。
|
||||||
|
|
||||||
|
首先,我们介绍一些流行的位置编码算法。
|
||||||
|
|
||||||
|
### RoPE
|
||||||
|
|
||||||
|
RoPE是一种在Transformer中注入位置信息的位置嵌入方法。它使用旋转矩阵对绝对位置进行编码,并同时在自注意力公式中融入显式的相对位置依赖关系。下图是RoPE机制的一个示例。
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/08c57958-0dcb-40d7-b91b-33f20ca2d89f>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
RoPE具有一些有价值的特性,例如可以扩展到任意序列长度、随着相对距离增加而减弱的token间依赖关系以及为线性自注意力提供相对位置编码的能力。
|
||||||
|
|
||||||
|
RoPE被应用于许多LLM模型,包括LLaMA、LLaMA 2和Vicuna-7b-v1.5-16k。
|
||||||
|
|
||||||
|
### ALiBi
|
||||||
|
|
||||||
|
尽管RoPE和其他替代原始位置编码的方法(如T5 bias)改善了外推能力,但它们的速度比原始方法慢得多,并且使用了额外的内存和参数。因此,作者引入了具有线性偏置的注意力(ALiBi)来促进高效的外推。
|
||||||
|
|
||||||
|
对于长度为L的输入子序列,注意力子层在每个head中计算第i个query
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
q_{i} \in R^{1 \times d}, (1 \leq i \leq L)
|
||||||
|
```
|
||||||
|
|
||||||
|
的注意力分数,给定前i个键
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
K \in R^{i \times d}
|
||||||
|
```
|
||||||
|
|
||||||
|
其中d是head维度。
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
softmax(q_{i}K^{T})
|
||||||
|
```
|
||||||
|
|
||||||
|
ALiBi通过与相关key和query之间的距离成比例的线性递减惩罚来负向偏置注意力分数。它唯一的修改是在query-key点积之后,在其中添加了一个静态的、非学习的偏置。
|
||||||
|
|
||||||
|
```{math}
|
||||||
|
softmax(q_{i}K^{T}+m\cdot[-(i-1),...,-2,-1,0])
|
||||||
|
```
|
||||||
|
|
||||||
|
其中m是在训练之前固定的head特定的斜率。
|
||||||
|
|
||||||
|
ALiBi去除了位置嵌入部分,它与原始位置编码方法一样快。它被用于包括mpt-7b-storywriter在内的大语言模型,该模型能够处理非常长的输入。
|
||||||
|
|
||||||
|
### 位置插值(PI)
|
||||||
|
|
||||||
|
许多现有的预训练LLM模型包括LLaMA,使用具有弱外推性质(例如RoPE)的位置编码。作者提出了一种位置插值方法,它可以轻松地实现非常长的上下文窗口,同时相对保持模型在其原始上下文窗口大小内的处理质量。
|
||||||
|
|
||||||
|
位置插值的关键思想是直接缩小位置索引,使得最大位置索引与预训练阶段的先前上下文窗口限制相匹配。换句话说,为了容纳更多的输入token,该算法在相邻的整数位置插值位置编码,利用位置编码可以应用于非整数位置的优势,它不需要在训练位置之外进行外推从而导致灾难性值的出现。该算法只需要很少的微调时间,模型就能完全适应大大扩展的上下文窗口。
|
||||||
|
|
||||||
|
下图展现了位置插值方法的机制。图中左下方说明了位置插值方法,它将位置索引(蓝色和绿色点)本身从\[0, 4096\]缩小到\[0, 2048\],从而使它们位于预训练范围内。
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/406454ba-a811-4c66-abbe-3a5528947257>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
位置插值使得基于ChatGLM2-6B的ChatGLM2-6B-32k模型能够处理32k的上下文窗口大小。
|
||||||
|
|
||||||
|
接下来,我们将介绍一些我们纳入评测范围的模型。
|
||||||
|
|
||||||
|
### XGen-7B-8k
|
||||||
|
|
||||||
|
XGen-7B-8k是使用标准的注意力机制训练的,训练文本最长为8k,总计1.5T个token。为了减少训练时间开销, XGen-7B-8k在不同阶段逐步增加输入文本长度。首先, 模型在序列长度为2k的文本上训练总计800B的token, 随后在长度为4k的文本上训练总计400B的token, 最后, 在长度为8k的文本上训练总计300B的token。
|
||||||
|
|
||||||
|
### Vicuna-7b-v1.5-16k
|
||||||
|
|
||||||
|
Vicuna-7b-v1.5-16k是从LLaMA 2微调而来的,它使用了有监督指导微调和线性RoPE扩展方法。训练数据量约为125K个对话,这些对话是从ShareGPT收集而来的。ShareGPT是一个用户可以分享他们与ChatGPT对话的网站。这些对话被打包成每个包含16k个token的序列。
|
||||||
|
|
||||||
|
### LongChat-7b-v1.5-32k
|
||||||
|
|
||||||
|
LongChat-7b-v1.5-32k也是从LLaMA 2模型微调得到, LLaMA 2模型最初使用4k的上下文长度进行预训练。LongChat-7b-v1.5-32k的第一步是压缩RoPE。由于LLaMA 2模型在预训练阶段没有训练输入位置大于4096的token,LongChat将位置大于4096的token压缩到0到4096之间。第二步是在对话数据上微调LongChat模型。在这一步中,LongChat使用FastChat中的步骤对数据进行清洗,并将对话文本截断到模型的最大长度。
|
||||||
|
|
||||||
|
### ChatGLM2-6B-32k
|
||||||
|
|
||||||
|
ChatGLM2-6B-32k进一步增强了ChatGLM2-6B的长文本能力。它采用位置插值方法,在对话对齐过程中使用32k上下文长度进行训练,因此ChatGLM2-6B-32k能够更好地处理长达32K的上下文长度。
|
||||||
|
|
||||||
|
## [L-Eval](https://github.com/OpenLMLab/LEval)
|
||||||
|
|
||||||
|
L-Eval是由OpenLMLab构建的一个长文本数据集,由18个子任务组成,其中包含法律、经济、科技等各个领域的文本。数据集总计411篇文档,超过2000条测例,文档平均长度为7217词。该数据集将子任务划分为close-ended和open-ended两类,5个close-ended任务使用完全匹配(Exact Match)作为评测标准,而13个open-ended任务则使用Rouge分数评测。
|
||||||
|
|
||||||
|
## [LongBench](https://github.com/THUDM/LongBench)
|
||||||
|
|
||||||
|
LongBench是由THUDM构建的长文本数据集,由21个子任务构成,总计4750条测例。该数据集是第一个包含中英双语的长文本数据集,其中英语文本长度平均为6711词,中文文本平均长度为13386字。21个子任务分为以下6种类型,对模型各方面能力提供了较为全面的评测。
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/4555e937-c519-4e9c-ad8d-7370430d466a>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
## 评测方法
|
||||||
|
|
||||||
|
由于不同模型能够接受的最大输入长度不同,为了更加公平地比较这些大模型,在输入长度超过模型最大输入限制时,我们将裁剪输入文本的中间部分,从而避免提示词缺失的情况。
|
||||||
|
|
||||||
|
## 长文本能力榜单
|
||||||
|
|
||||||
|
在LongBench和L-Eval能力榜单中,我们选取各模型在子任务上排名的平均值 **(排名数值越低越好)** 作为标准。可以看到GPT-4和GPT-3.5-turbo-16k在长文本任务中仍然占据领先地位,而例如ChatGLM2-6B-32k在基于ChatGLM2-6B使用位置插值后在长文本能力方面也有明显提升。
|
||||||
|
|
||||||
|
<div align="center">
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/29b5ad12-d9a3-4255-be0a-f770923fe514>
|
||||||
|
<img src=https://github.com/open-compass/opencompass/assets/75252858/680b4cda-c2b1-45d1-8c33-196dee1a38f3>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
原始分数如下所示。
|
||||||
|
|
||||||
|
| L-Eval | GPT-4 | GPT-3.5-turbo-16k | chatglm2-6b-32k | vicuna-7b-v1.5-16k | xgen-7b-8k | internlm-chat-7b-8k | longchat-7b-v1.5-32k | chatglm2-6b |
|
||||||
|
| ----------------- | ----- | ----------------- | --------------- | ------------------ | ---------- | ------------------- | -------------------- | ----------- |
|
||||||
|
| coursera | 61.05 | 50 | 45.35 | 26.74 | 33.72 | 40.12 | 27.91 | 38.95 |
|
||||||
|
| gsm100 | 92 | 78 | 27 | 11 | 8 | 19 | 5 | 8 |
|
||||||
|
| quality | 81.19 | 62.87 | 44.55 | 11.39 | 33.66 | 45.54 | 29.7 | 41.09 |
|
||||||
|
| tpo | 72.93 | 74.72 | 56.51 | 17.47 | 44.61 | 60.59 | 17.1 | 56.51 |
|
||||||
|
| topic_retrieval | 100 | 79.33 | 44.67 | 24.67 | 1.33 | 0 | 25.33 | 1.33 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| financialqa | 53.49 | 50.32 | 35.41 | 44.59 | 39.28 | 25.09 | 34.07 | 17.82 |
|
||||||
|
| gov_report | 50.84 | 50.48 | 42.97 | 48.17 | 38.52 | 31.29 | 36.52 | 41.88 |
|
||||||
|
| legal_contract_qa | 31.23 | 27.97 | 34.21 | 24.25 | 21.36 | 19.28 | 13.32 | 17.59 |
|
||||||
|
| meeting_summ | 31.44 | 33.54 | 29.13 | 28.52 | 27.96 | 17.56 | 22.32 | 15.98 |
|
||||||
|
| multidocqa | 37.81 | 35.84 | 28.6 | 26.88 | 24.41 | 22.43 | 21.85 | 19.66 |
|
||||||
|
| narrativeqa | 25.87 | 25.73 | 18.24 | 20.58 | 16.87 | 13.81 | 16.87 | 1.16 |
|
||||||
|
| nq | 67.36 | 66.91 | 41.06 | 36.44 | 29.43 | 16.42 | 35.02 | 0.92 |
|
||||||
|
| news_summ | 34.52 | 40.41 | 32.72 | 33.98 | 26.87 | 22.48 | 30.33 | 29.51 |
|
||||||
|
| paper_assistant | 42.26 | 41.76 | 34.59 | 35.83 | 25.39 | 28.25 | 30.42 | 30.43 |
|
||||||
|
| patent_summ | 48.61 | 50.62 | 46.04 | 48.87 | 46.53 | 30.3 | 41.6 | 41.25 |
|
||||||
|
| review_summ | 31.98 | 33.37 | 21.88 | 29.21 | 26.85 | 16.61 | 20.02 | 19.68 |
|
||||||
|
| scientificqa | 49.76 | 48.32 | 31.27 | 31 | 27.43 | 33.01 | 20.98 | 13.61 |
|
||||||
|
| tvshow_summ | 34.84 | 31.36 | 23.97 | 27.88 | 26.6 | 14.55 | 25.09 | 19.45 |
|
||||||
|
|
||||||
|
| LongBench | GPT-4 | GPT-3.5-turbo-16k | chatglm2-6b-32k | longchat-7b-v1.5-32k | vicuna-7b-v1.5-16k | internlm-chat-7b-8k | chatglm2-6b | xgen-7b-8k |
|
||||||
|
| ------------------- | ----- | ----------------- | --------------- | -------------------- | ------------------ | ------------------- | ----------- | ---------- |
|
||||||
|
| NarrativeQA | 31.2 | 25.79 | 19.27 | 19.19 | 23.65 | 12.24 | 13.09 | 18.85 |
|
||||||
|
| Qasper | 42.77 | 43.4 | 33.93 | 30.36 | 31.45 | 24.81 | 22.52 | 20.18 |
|
||||||
|
| MultiFieldQA-en | 55.1 | 54.35 | 45.58 | 44.6 | 43.38 | 25.41 | 38.09 | 37 |
|
||||||
|
| MultiFieldQA-zh | 64.4 | 61.92 | 52.94 | 32.35 | 44.65 | 36.13 | 37.67 | 14.7 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| HotpotQA | 59.85 | 52.49 | 46.41 | 34.43 | 34.17 | 27.42 | 27.35 | 28.78 |
|
||||||
|
| 2WikiMQA | 67.52 | 41.7 | 33.63 | 23.06 | 20.45 | 26.24 | 22.83 | 20.13 |
|
||||||
|
| Musique | 37.53 | 27.5 | 21.57 | 12.42 | 13.92 | 9.75 | 7.26 | 11.34 |
|
||||||
|
| DuReader (zh) | 38.65 | 29.37 | 38.53 | 20.25 | 20.42 | 11.11 | 17.18 | 8.57 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| GovReport | 32.09 | 29.92 | 32.47 | 29.83 | 29.27 | 18.38 | 22.86 | 23.37 |
|
||||||
|
| QMSum | 24.37 | 23.67 | 23.19 | 22.71 | 23.37 | 18.45 | 21.23 | 21.12 |
|
||||||
|
| Multi_news | 28.52 | 27.05 | 25.12 | 26.1 | 27.83 | 24.52 | 24.7 | 23.69 |
|
||||||
|
| VCSUM (zh) | 15.54 | 16.88 | 15.95 | 13.46 | 15.76 | 12.91 | 14.07 | 0.98 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| TREC | 78.5 | 73.5 | 30.96 | 29.23 | 32.06 | 39 | 24.46 | 29.31 |
|
||||||
|
| TriviaQA | 92.19 | 92.75 | 80.64 | 64.19 | 46.53 | 79.55 | 64.19 | 69.58 |
|
||||||
|
| SAMSum | 46.32 | 43.16 | 29.49 | 25.23 | 25.23 | 43.05 | 20.22 | 16.05 |
|
||||||
|
| LSHT (zh) | 41.5 | 34.5 | 22.75 | 20 | 24.75 | 20.5 | 16 | 18.67 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| Passage Count | 8.5 | 3 | 3 | 1 | 3 | 1.76 | 3 | 1 |
|
||||||
|
| PassageRetrieval-en | 75 | 73 | 57.5 | 20.5 | 16.5 | 7 | 5.5 | 12 |
|
||||||
|
| PassageRetrieval-zh | 96 | 82.5 | 58 | 15 | 21 | 2.29 | 5 | 3.75 |
|
||||||
|
| | | | | | | | | |
|
||||||
|
| LCC | 59.25 | 53.49 | 53.3 | 51.46 | 49.3 | 49.32 | 46.59 | 44.1 |
|
||||||
|
| RepoBench-P | 55.42 | 55.95 | 46.66 | 52.18 | 41.49 | 35.86 | 41.97 | 41.83 |
|
||||||
|
|
@ -0,0 +1,190 @@
|
||||||
|
# 数学能力评测
|
||||||
|
|
||||||
|
## 简介
|
||||||
|
|
||||||
|
数学推理能力是大语言模型(LLMs)的一项关键能力。为了评估模型的数学能力,我们需要测试其逐步解决数学问题并提供准确最终答案的能力。OpenCompass 通过 CustomDataset 和 MATHEvaluator 组件提供了一种便捷的数学推理评测方式。
|
||||||
|
|
||||||
|
## 数据集格式
|
||||||
|
|
||||||
|
数学评测数据集应该是 JSON Lines (.jsonl) 或 CSV 格式。每个问题至少应包含:
|
||||||
|
|
||||||
|
- 问题陈述
|
||||||
|
- 解答/答案(通常使用 LaTeX 格式,最终答案需要用 \\boxed{} 括起来)
|
||||||
|
|
||||||
|
JSONL 格式示例:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"problem": "求解方程 2x + 3 = 7", "solution": "让我们逐步解决:\n2x + 3 = 7\n2x = 7 - 3\n2x = 4\nx = 2\n因此,\\boxed{2}"}
|
||||||
|
```
|
||||||
|
|
||||||
|
CSV 格式示例:
|
||||||
|
|
||||||
|
```csv
|
||||||
|
problem,solution
|
||||||
|
"求解方程 2x + 3 = 7","让我们逐步解决:\n2x + 3 = 7\n2x = 7 - 3\n2x = 4\nx = 2\n因此,\\boxed{2}"
|
||||||
|
```
|
||||||
|
|
||||||
|
## 配置说明
|
||||||
|
|
||||||
|
要进行数学推理评测,你需要设置三个主要组件:
|
||||||
|
|
||||||
|
1. 数据集读取配置
|
||||||
|
|
||||||
|
```python
|
||||||
|
math_reader_cfg = dict(
|
||||||
|
input_columns=['problem'], # 问题列的名称
|
||||||
|
output_column='solution' # 答案列的名称
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 推理配置
|
||||||
|
|
||||||
|
```python
|
||||||
|
math_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}\n请逐步推理,并将最终答案放在 \\boxed{} 中。',
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 评测配置
|
||||||
|
|
||||||
|
```python
|
||||||
|
math_eval_cfg = dict(
|
||||||
|
evaluator=dict(type=MATHEvaluator),
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 使用 CustomDataset
|
||||||
|
|
||||||
|
以下是如何设置完整的数学评测配置:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
from opencompass.datasets import CustomDataset
|
||||||
|
|
||||||
|
math_datasets = [
|
||||||
|
dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
abbr='my-math-dataset', # 数据集简称
|
||||||
|
path='path/to/your/dataset', # 数据集文件路径
|
||||||
|
reader_cfg=math_reader_cfg,
|
||||||
|
infer_cfg=math_infer_cfg,
|
||||||
|
eval_cfg=math_eval_cfg,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
## MATHEvaluator
|
||||||
|
|
||||||
|
MATHEvaluator 是专门设计用于评估数学答案的评测器。它基于 math_verify 库进行开发,该库提供了数学表达式解析和验证功能,支持 LaTeX 和一般表达式的提取与等价性验证。
|
||||||
|
|
||||||
|
MATHEvaluator 具有以下功能:
|
||||||
|
|
||||||
|
1. 使用 LaTeX 提取器从预测和参考答案中提取答案
|
||||||
|
2. 处理各种 LaTeX 格式和环境
|
||||||
|
3. 验证预测答案和参考答案之间的数学等价性
|
||||||
|
4. 提供详细的评测结果,包括:
|
||||||
|
- 准确率分数
|
||||||
|
- 预测和参考答案的详细比较
|
||||||
|
- 预测和参考答案的解析结果
|
||||||
|
|
||||||
|
评测器支持:
|
||||||
|
|
||||||
|
- 基本算术运算
|
||||||
|
- 分数和小数
|
||||||
|
- 代数表达式
|
||||||
|
- 三角函数
|
||||||
|
- 根式和指数
|
||||||
|
- 数学符号和运算符
|
||||||
|
|
||||||
|
评测输出示例:
|
||||||
|
|
||||||
|
```python
|
||||||
|
{
|
||||||
|
'accuracy': 85.0, # 正确答案的百分比
|
||||||
|
'details': [
|
||||||
|
{
|
||||||
|
'predictions': 'x = 2', # 解析后的预测答案
|
||||||
|
'references': 'x = 2', # 解析后的参考答案
|
||||||
|
'correct': True # 是否匹配
|
||||||
|
},
|
||||||
|
# ... 更多结果
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 完整示例
|
||||||
|
|
||||||
|
以下是设置数学评测的完整示例:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
from opencompass.models import TurboMindModelwithChatTemplate
|
||||||
|
from opencompass.datasets import CustomDataset
|
||||||
|
from opencompass.openicl.icl_evaluator.math_evaluator import MATHEvaluator
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
from opencompass.openicl.icl_retriever import ZeroRetriever
|
||||||
|
from opencompass.openicl.icl_inferencer import GenInferencer
|
||||||
|
|
||||||
|
# 数据集读取配置
|
||||||
|
math_reader_cfg = dict(input_columns=['problem'], output_column='solution')
|
||||||
|
|
||||||
|
# 推理配置
|
||||||
|
math_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(
|
||||||
|
round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt='{problem}\n请逐步推理,并将最终答案放在 \\boxed{} 中。',
|
||||||
|
),
|
||||||
|
]
|
||||||
|
),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(type=GenInferencer),
|
||||||
|
)
|
||||||
|
|
||||||
|
# 评测配置
|
||||||
|
math_eval_cfg = dict(
|
||||||
|
evaluator=dict(type=MATHEvaluator),
|
||||||
|
)
|
||||||
|
|
||||||
|
# 数据集配置
|
||||||
|
math_datasets = [
|
||||||
|
dict(
|
||||||
|
type=CustomDataset,
|
||||||
|
abbr='my-math-dataset',
|
||||||
|
path='path/to/your/dataset.jsonl', # 或 .csv
|
||||||
|
reader_cfg=math_reader_cfg,
|
||||||
|
infer_cfg=math_infer_cfg,
|
||||||
|
eval_cfg=math_eval_cfg,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# 模型配置
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=TurboMindModelwithChatTemplate,
|
||||||
|
abbr='your-model-name',
|
||||||
|
path='your/model/path',
|
||||||
|
# ... 其他模型配置
|
||||||
|
)
|
||||||
|
]
|
||||||
|
|
||||||
|
# 输出目录
|
||||||
|
work_dir = './outputs/math_eval'
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,195 @@
|
||||||
|
# 大海捞针(Needle In A Haystack)实验评估
|
||||||
|
|
||||||
|
## 大海捞针测试简介
|
||||||
|
|
||||||
|
大海捞针测试(灵感来自[NeedleInAHaystack](https://github.com/gkamradt/LLMTest_NeedleInAHaystack/blob/main/LLMNeedleHaystackTester.py))是一种评估方法,它通过在长文本中随机插入关键信息,形成大型语言模型(LLM)的Prompt。该测试旨在检测大型模型是否能从长文本中提取出这些关键信息,从而评估模型处理长文本信息提取的能力,这可以反映LLM对长文本的理解基础能力。
|
||||||
|
|
||||||
|
## 任务介绍
|
||||||
|
|
||||||
|
在`OpenCompass`的`NeedleBench`框架中,为了全面评估模型在长文本信息提取和推理方面的能力,我们设计了一系列逐渐增加难度的测试方案。完整的介绍参见我们的[技术报告](https://arxiv.org/abs/2407.11963)。
|
||||||
|
|
||||||
|
- **单一信息检索任务(Single-Needle Retrieval Task, S-RT)**:评估LLM在长文本中提取单一关键信息的能力,测试其对广泛叙述中特定细节的精确回忆能力。这对应于**原始的大海捞针测试**任务设定。
|
||||||
|
|
||||||
|
- **多信息检索任务(Multi-Needle Retrieval Task, M-RT)**:探讨LLM从长文本中检索多个相关信息的能力,模拟实际场景中对综合文档的复杂查询。
|
||||||
|
|
||||||
|
- **多信息推理任务(Multi-Needle Reasoning Task, M-RS)**:通过提取并利用长文本中的多个关键信息来评估LLM的长文本能力,要求模型对各关键信息片段有综合理解。
|
||||||
|
|
||||||
|
- **祖先追溯挑战(Ancestral Trace Challenge, ATC)**:通过设计“亲属关系针”,测试LLM处理真实长文本中多层逻辑挑战的能力。在ATC任务中,通过一系列逻辑推理问题,检验模型对长文本中每个细节的记忆和分析能力,在此任务中,我们去掉了无关文本(Haystack)的设定,而是将所有文本设计为关键信息,LLM必须综合运用长文本中的所有内容和推理才能准确回答问题。
|
||||||
|
|
||||||
|
### 评估步骤
|
||||||
|
|
||||||
|
> 注意:在最新代码中,OpenCompass已经设置数据集从[Huggingface的接口](https://huggingface.co/datasets/opencompass/NeedleBench)中自动加载,可以直接跳过下面的手动下载安放数据集。
|
||||||
|
|
||||||
|
1. 从[这里](https://github.com/open-compass/opencompass/files/14741330/needlebench.zip)下载数据集。
|
||||||
|
|
||||||
|
2. 将下载的文件放置于`opencompass/data/needlebench/`目录下。`needlebench`目录中预期的文件结构如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
opencompass/
|
||||||
|
├── configs
|
||||||
|
├── docs
|
||||||
|
├── data
|
||||||
|
│ └── needlebench
|
||||||
|
│ ├── multi_needle_reasoning_en.json
|
||||||
|
│ ├── multi_needle_reasoning_zh.json
|
||||||
|
│ ├── names.json
|
||||||
|
│ ├── needles.jsonl
|
||||||
|
│ ├── PaulGrahamEssays.jsonl
|
||||||
|
│ ├── zh_finance.jsonl
|
||||||
|
│ ├── zh_game.jsonl
|
||||||
|
│ ├── zh_government.jsonl
|
||||||
|
│ ├── zh_movie.jsonl
|
||||||
|
│ ├── zh_tech.jsonl
|
||||||
|
│ ├── zh_general.jsonl
|
||||||
|
├── LICENSE
|
||||||
|
├── opencompass
|
||||||
|
├── outputs
|
||||||
|
├── run.py
|
||||||
|
├── more...
|
||||||
|
```
|
||||||
|
|
||||||
|
### `OpenCompass`环境配置
|
||||||
|
|
||||||
|
```bash
|
||||||
|
conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
|
||||||
|
conda activate opencompass
|
||||||
|
git clone https://github.com/open-compass/opencompass opencompass
|
||||||
|
cd opencompass
|
||||||
|
pip install -e .
|
||||||
|
```
|
||||||
|
|
||||||
|
### 配置数据集
|
||||||
|
|
||||||
|
我们在`configs/datasets/needlebench`中已经预先配置好了关于常见长度区间(4k, 8k, 32k, 128k, 200k, 1000k)的长文本测试设定,您可以通过在配置文件中定义相关参数,以灵活地创建适合您需求的数据集。
|
||||||
|
|
||||||
|
### 评估示例
|
||||||
|
|
||||||
|
#### 使用`LMDeploy`部署的 `InternLM2-7B` 模型进行评估
|
||||||
|
|
||||||
|
例如,使用`LMDeploy`部署的 `InternLM2-7B` 模型进行评估NeedleBench-4K的所有任务,可以在命令行中直接使用以下命令,该命令会调用预定义好的模型、数据集配置文件,而无需额外书写配置文件:
|
||||||
|
|
||||||
|
##### 本地评估
|
||||||
|
|
||||||
|
如果您在本地评估模型,下面命令会调用机器的所有可用GPU。您可以通过设置 `CUDA_VISIBLE_DEVICES` 环境变量来限制 `OpenCompass` 的 GPU 访问。例如,使用 `CUDA_VISIBLE_DEVICES=0,1,2,3 python run.py ...` 只会向 OpenCompass 暴露前四个 GPU,确保它同时使用的 GPU 数量不超过这四个。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 本地评估
|
||||||
|
python run.py --dataset needlebench_4k --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer
|
||||||
|
```
|
||||||
|
|
||||||
|
##### 在Slurm集群上评估
|
||||||
|
|
||||||
|
如果使用 `Slurm`,可以添加 `--slurm -p partition_name -q reserved --max-num-workers 16 `等参数,例如下面:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Slurm评估
|
||||||
|
python run.py --dataset needlebench_4k --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
##### 只评估子数据集
|
||||||
|
|
||||||
|
如果只想测试原始的大海捞针任务设定,比如可以更换数据集的参数为`needlebench_single_4k`,这对应于4k长度下的单针版本的大海捞针测试:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --dataset needlebench_single_4k --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
您也可以进一步选择子数据集,如更换数据集`--datasets`的参数为`needlebench_single_4k/needlebench_zh_datasets`,仅仅进行中文版本的单针4K长度下的大海捞针任务测试,其中`/`后面的参数代表子数据集,您可以在`configs/datasets/needlebench/needlebench_4k/needlebench_single_4k.py`中找到可选的子数据集变量,如:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --dataset needlebench_single_4k/needlebench_zh_datasets --models lmdeploy_internlm2_chat_7b --summarizer needlebench/needlebench_4k_summarizer --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
注意在评估前预先安装[LMDeploy](https://github.com/InternLM/lmdeploy)工具
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install lmdeploy
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令将启动评估流程,参数 `-p partition_name -q auto` 和 `--max-num-workers 32` 用于指定 Slurm 分区名称和最大工作进程数。
|
||||||
|
|
||||||
|
#### 评估其他`Huggingface`模型
|
||||||
|
|
||||||
|
对于其他模型,我们建议额外书写一个运行的配置文件以便对模型的`max_seq_len`, `max_out_len`参数进行修改,以便模型可以接收到完整的长文本内容。如我们预先写好的`configs/eval_needlebench.py`文件。完整内容如下
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
# 我们使用mmengine.config来import其他的配置文件中的变量
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# from .models.hf_internlm.lmdeploy_internlm2_chat_7b import models as internlm2_chat_7b_200k
|
||||||
|
from .models.hf_internlm.hf_internlm2_chat_7b import models as internlm2_chat_7b
|
||||||
|
|
||||||
|
# Evaluate needlebench_4k, adjust the configuration to use 8k, 32k, 128k, 200k, or 1000k if necessary.
|
||||||
|
# from .datasets.needlebench.needlebench_4k.needlebench_4k import needlebench_datasets
|
||||||
|
# from .summarizers.needlebench import needlebench_4k_summarizer as summarizer
|
||||||
|
|
||||||
|
# only eval original "needle in a haystack test" in needlebench_4k
|
||||||
|
from .datasets.needlebench.needlebench_4k.needlebench_single_4k import needlebench_zh_datasets, needlebench_en_datasets
|
||||||
|
from .summarizers.needlebench import needlebench_4k_summarizer as summarizer
|
||||||
|
|
||||||
|
# eval Ancestral Tracing Challenge(ATC)
|
||||||
|
# from .datasets.needlebench.atc.atc_choice_50 import needlebench_datasets
|
||||||
|
# from .summarizers.needlebench import atc_summarizer_50 as summarizer
|
||||||
|
|
||||||
|
datasets = sum([v for k, v in locals().items() if ('datasets' in k)], [])
|
||||||
|
|
||||||
|
for m in internlm2_chat_7b:
|
||||||
|
m['max_seq_len'] = 30768 # 保证InternLM2-7B模型能接收到完整的长文本,其他模型需要根据各自支持的最大序列长度修改。
|
||||||
|
m['max_out_len'] = 2000 # 保证在多针召回任务中能接收到模型完整的回答
|
||||||
|
|
||||||
|
models = internlm2_chat_7b
|
||||||
|
|
||||||
|
work_dir = './outputs/needlebench'
|
||||||
|
```
|
||||||
|
|
||||||
|
当书写好测试的`config`文件后,我们可以命令行中通过`run.py`文件传入对应的config文件路径,例如:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_needlebench.py --slurm -p partition_name -q reserved --max-num-workers 16
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,此时我们不需传入`--dataset, --models, --summarizer `等参数,因为我们已经在config文件中定义了这些配置。你可以自己手动调节`--max-num-workers`的设定以调节并行工作的workers的数量。
|
||||||
|
|
||||||
|
### 可视化
|
||||||
|
|
||||||
|
我们已经在最新的代码中将结果可视化内置到`summarizer`实现中,您在对应的output文件夹的plots目录下可以看到相应的可视化。而不需要自己手动可视化各个深度和长度下的分数。
|
||||||
|
|
||||||
|
如果使用了该方法,请添加引用:
|
||||||
|
|
||||||
|
```bibtex
|
||||||
|
|
||||||
|
@misc{li2024needlebenchllmsretrievalreasoning,
|
||||||
|
title={NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?},
|
||||||
|
author={Mo Li and Songyang Zhang and Yunxin Liu and Kai Chen},
|
||||||
|
year={2024},
|
||||||
|
eprint={2407.11963},
|
||||||
|
archivePrefix={arXiv},
|
||||||
|
primaryClass={cs.CL},
|
||||||
|
url={https://arxiv.org/abs/2407.11963},
|
||||||
|
}
|
||||||
|
|
||||||
|
@misc{2023opencompass,
|
||||||
|
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
|
||||||
|
author={OpenCompass Contributors},
|
||||||
|
howpublished={\url{https://github.com/open-compass/opencompass}},
|
||||||
|
year={2023}
|
||||||
|
}
|
||||||
|
|
||||||
|
@misc{LLMTest_NeedleInAHaystack,
|
||||||
|
title={LLMTest Needle In A Haystack - Pressure Testing LLMs},
|
||||||
|
author={gkamradt},
|
||||||
|
year={2023},
|
||||||
|
howpublished={\url{https://github.com/gkamradt/LLMTest_NeedleInAHaystack}}
|
||||||
|
}
|
||||||
|
|
||||||
|
@misc{wei2023skywork,
|
||||||
|
title={Skywork: A More Open Bilingual Foundation Model},
|
||||||
|
author={Tianwen Wei and Liang Zhao and Lichang Zhang and Bo Zhu and Lijie Wang and Haihua Yang and Biye Li and Cheng Cheng and Weiwei Lü and Rui Hu and Chenxia Li and Liu Yang and Xilin Luo and Xuejie Wu and Lunan Liu and Wenjun Cheng and Peng Cheng and Jianhao Zhang and Xiaoyu Zhang and Lei Lin and Xiaokun Wang and Yutuan Ma and Chuanhai Dong and Yanqi Sun and Yifu Chen and Yongyi Peng and Xiaojuan Liang and Shuicheng Yan and Han Fang and Yahui Zhou},
|
||||||
|
year={2023},
|
||||||
|
eprint={2310.19341},
|
||||||
|
archivePrefix={arXiv},
|
||||||
|
primaryClass={cs.CL}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,106 @@
|
||||||
|
# 支持新数据集
|
||||||
|
|
||||||
|
尽管 OpenCompass 已经包含了大多数常用数据集,用户在支持新数据集的时候需要完成以下几个步骤:
|
||||||
|
|
||||||
|
1. 在 `opencompass/datasets` 文件夹新增数据集脚本 `mydataset.py`, 该脚本需要包含:
|
||||||
|
|
||||||
|
- 数据集及其加载方式,需要定义一个 `MyDataset` 类,实现数据集加载方法 `load`,该方法为静态方法,需要返回 `datasets.Dataset` 类型的数据。这里我们使用 huggingface dataset 作为数据集的统一接口,避免引入额外的逻辑。具体示例如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import datasets
|
||||||
|
from .base import BaseDataset
|
||||||
|
|
||||||
|
class MyDataset(BaseDataset):
|
||||||
|
|
||||||
|
@staticmethod
|
||||||
|
def load(**kwargs) -> datasets.Dataset:
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
- (可选)如果 OpenCompass 已有的评测器不能满足需要,需要用户定义 `MyDatasetlEvaluator` 类,实现评分方法 `score`,需要根据输入的 `predictions` 和 `references` 列表,得到需要的字典。由于一个数据集可能存在多种 metric,需要返回一个 metrics 以及对应 scores 的相关字典。具体示例如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.openicl.icl_evaluator import BaseEvaluator
|
||||||
|
|
||||||
|
class MyDatasetlEvaluator(BaseEvaluator):
|
||||||
|
|
||||||
|
def score(self, predictions: List, references: List) -> dict:
|
||||||
|
pass
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
- (可选)如果 OpenCompass 已有的后处理方法不能满足需要,需要用户定义 `mydataset_postprocess` 方法,根据输入的字符串得到相应后处理的结果。具体示例如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def mydataset_postprocess(text: str) -> str:
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 在定义好数据集加载、评测以及数据后处理等方法之后,需要在配置文件中新增以下配置:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from opencompass.datasets import MyDataset, MyDatasetlEvaluator, mydataset_postprocess
|
||||||
|
|
||||||
|
mydataset_eval_cfg = dict(
|
||||||
|
evaluator=dict(type=MyDatasetlEvaluator),
|
||||||
|
pred_postprocessor=dict(type=mydataset_postprocess))
|
||||||
|
|
||||||
|
mydataset_datasets = [
|
||||||
|
dict(
|
||||||
|
type=MyDataset,
|
||||||
|
...,
|
||||||
|
reader_cfg=...,
|
||||||
|
infer_cfg=...,
|
||||||
|
eval_cfg=mydataset_eval_cfg)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- 为了使用户提供的数据集能够被其他使用者更方便的获取,需要用户在配置文件中给出下载数据集的渠道。具体的方式是首先在`mydataset_datasets`配置中的`path`字段填写用户指定的数据集名称,该名称将以mapping的方式映射到`opencompass/utils/datasets_info.py`中的实际下载路径。具体示例如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
mmlu_datasets = [
|
||||||
|
dict(
|
||||||
|
...,
|
||||||
|
path='opencompass/mmlu',
|
||||||
|
...,
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
- 接着,需要在`opencompass/utils/datasets_info.py`中创建对应名称的字典字段。如果用户已将数据集托管到huggingface或modelscope,那么请在`DATASETS_MAPPING`字典中添加对应名称的字段,并将对应的huggingface或modelscope数据集地址填入`ms_id`和`hf_id`;另外,还允许指定一个默认的`local`地址。具体示例如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
"opencompass/mmlu": {
|
||||||
|
"ms_id": "opencompass/mmlu",
|
||||||
|
"hf_id": "opencompass/mmlu",
|
||||||
|
"local": "./data/mmlu/",
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
- 如果希望提供的数据集在其他用户使用时能够直接从OpenCompass官方的OSS仓库获取,则需要在Pull Request阶段向我们提交数据集文件,我们将代为传输数据集至OSS,并在`DATASET_URL`新建字段。
|
||||||
|
|
||||||
|
- 为了确保数据来源的可选择性,用户需要根据所提供数据集的下载路径类型来完善数据集脚本`mydataset.py`中的`load`方法的功能。具体而言,需要用户实现根据环境变量`DATASET_SOURCE`的不同设置来切换不同的下载数据源的功能。需要注意的是,若未设置`DATASET_SOURCE`的值,将默认从OSS仓库下载数据。`opencompass/dataset/cmmlu.py`中的具体示例如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
def load(path: str, name: str, **kwargs):
|
||||||
|
...
|
||||||
|
if environ.get('DATASET_SOURCE') == 'ModelScope':
|
||||||
|
...
|
||||||
|
else:
|
||||||
|
...
|
||||||
|
return dataset
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 在完成数据集脚本和配置文件的构建后,需要在OpenCompass主目录下的`dataset-index.yml`配置文件中登记新数据集的相关信息,以使其加入OpenCompass官网Doc的数据集统计列表中。
|
||||||
|
|
||||||
|
- 需要填写的字段包括数据集名称`name`、数据集类型`category`、原文或项目地址`paper`、以及数据集配置文件的路径`configpath`。具体示例如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
- mydataset:
|
||||||
|
name: MyDataset
|
||||||
|
category: Understanding
|
||||||
|
paper: https://arxiv.org/pdf/xxxxxxx
|
||||||
|
configpath: opencompass/configs/datasets/MyDataset
|
||||||
|
```
|
||||||
|
|
||||||
|
详细的数据集配置文件以及其他需要的配置文件可以参考[配置文件](../user_guides/config.md)教程,启动任务相关的教程可以参考[快速开始](../get_started/quick_start.md)教程。
|
||||||
|
|
@ -0,0 +1,73 @@
|
||||||
|
# 支持新模型
|
||||||
|
|
||||||
|
目前我们已经支持的模型有 HF 模型、部分模型 API 、部分第三方模型。
|
||||||
|
|
||||||
|
## 新增API模型
|
||||||
|
|
||||||
|
新增基于API的模型,需要在 `opencompass/models` 下新建 `mymodel_api.py` 文件,继承 `BaseAPIModel`,并实现 `generate` 方法来进行推理,以及 `get_token_len` 方法来计算 token 的长度。在定义好之后修改对应配置文件名称即可。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ..base_api import BaseAPIModel
|
||||||
|
|
||||||
|
class MyModelAPI(BaseAPIModel):
|
||||||
|
|
||||||
|
is_api: bool = True
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
path: str,
|
||||||
|
max_seq_len: int = 2048,
|
||||||
|
query_per_second: int = 1,
|
||||||
|
retry: int = 2,
|
||||||
|
**kwargs):
|
||||||
|
super().__init__(path=path,
|
||||||
|
max_seq_len=max_seq_len,
|
||||||
|
meta_template=meta_template,
|
||||||
|
query_per_second=query_per_second,
|
||||||
|
retry=retry)
|
||||||
|
...
|
||||||
|
|
||||||
|
def generate(
|
||||||
|
self,
|
||||||
|
inputs,
|
||||||
|
max_out_len: int = 512,
|
||||||
|
temperature: float = 0.7,
|
||||||
|
) -> List[str]:
|
||||||
|
"""Generate results given a list of inputs."""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def get_token_len(self, prompt: str) -> int:
|
||||||
|
"""Get lengths of the tokenized string."""
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
||||||
|
## 新增第三方模型
|
||||||
|
|
||||||
|
新增基于第三方的模型,需要在 `opencompass/models` 下新建 `mymodel.py` 文件,继承 `BaseModel`,并实现 `generate` 方法来进行生成式推理, `get_ppl` 方法来进行判别式推理,以及 `get_token_len` 方法来计算 token 的长度。在定义好之后修改对应配置文件名称即可。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from ..base import BaseModel
|
||||||
|
|
||||||
|
class MyModel(BaseModel):
|
||||||
|
|
||||||
|
def __init__(self,
|
||||||
|
pkg_root: str,
|
||||||
|
ckpt_path: str,
|
||||||
|
tokenizer_only: bool = False,
|
||||||
|
meta_template: Optional[Dict] = None,
|
||||||
|
**kwargs):
|
||||||
|
...
|
||||||
|
|
||||||
|
def get_token_len(self, prompt: str) -> int:
|
||||||
|
"""Get lengths of the tokenized strings."""
|
||||||
|
pass
|
||||||
|
|
||||||
|
def generate(self, inputs: List[str], max_out_len: int) -> List[str]:
|
||||||
|
"""Generate results given a list of inputs. """
|
||||||
|
pass
|
||||||
|
|
||||||
|
def get_ppl(self,
|
||||||
|
inputs: List[str],
|
||||||
|
mask_length: Optional[List[int]] = None) -> List[float]:
|
||||||
|
"""Get perplexity scores given a list of inputs."""
|
||||||
|
pass
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,186 @@
|
||||||
|
# 用大模型做为JudgeLLM进行客观评测
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
通常的客观评测虽有标准答案作为参考,但是在实际应用中,模型预测结果可能因为模型指令遵循能力不同或后处理函数的不完善而产生差异,导致无法抽取到正确的答案并与标准答案进行对比。因此客观评测的结果可能并不完全准确。为了解决这一问题,我们参照主观评测,在预测完成后引入了JudgeLLM作为评价模型,以评估模型回答和标准答案的一致性。([LLM-as-a-Judge](https://arxiv.org/abs/2306.05685))。
|
||||||
|
|
||||||
|
目前opencompass仓库里支持的所有模型都可以直接作为JudgeLLM进行调用,此外一些专用的JudgeLLM我们也在计划支持中。
|
||||||
|
|
||||||
|
## 目前已支持的用JudgeLLM进行直接评测的客观评测数据集
|
||||||
|
|
||||||
|
1. MATH(https://github.com/hendrycks/math)
|
||||||
|
|
||||||
|
## 自定义JudgeLLM客观数据集评测
|
||||||
|
|
||||||
|
目前的OpenCompass支持大部分采用`GenInferencer`的数据集进行推理。自定义JudgeLLM客观评测的具体流程包括:
|
||||||
|
|
||||||
|
1. 构建评测配置,使用API模型或者开源模型进行问题答案的推理
|
||||||
|
2. 使用选定的评价模型(JudgeLLM)对模型输出进行评估
|
||||||
|
|
||||||
|
### 第一步:构建评测配置,以MATH为例
|
||||||
|
|
||||||
|
下面是对MATH数据集进行JudgeLLM评测的Config,评测模型为*Llama3-8b-instruct*,JudgeLLM为*Llama3-70b-instruct*。更详细的config setting请参考 `configs/eval_math_llm_judge.py`,下面我们提供了部分简略版的注释,方便用户理解配置文件的含义。
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Most of the code in this file is copied from https://github.com/openai/simple-evals/blob/main/math_eval.py
|
||||||
|
from mmengine.config import read_base
|
||||||
|
with read_base():
|
||||||
|
from .models.hf_llama.hf_llama3_8b_instruct import models as hf_llama3_8b_instruct_model # noqa: F401, F403
|
||||||
|
from .models.hf_llama.hf_llama3_70b_instruct import models as hf_llama3_70b_instruct_model # noqa: F401, F403
|
||||||
|
from .datasets.math.math_llm_judge import math_datasets # noqa: F401, F403
|
||||||
|
from opencompass.datasets import math_judement_preprocess
|
||||||
|
from opencompass.partitioners import NaivePartitioner, SizePartitioner
|
||||||
|
from opencompass.partitioners.sub_naive import SubjectiveNaivePartitioner
|
||||||
|
from opencompass.partitioners.sub_size import SubjectiveSizePartitioner
|
||||||
|
from opencompass.runners import LocalRunner
|
||||||
|
from opencompass.runners import SlurmSequentialRunner
|
||||||
|
from opencompass.tasks import OpenICLInferTask
|
||||||
|
from opencompass.tasks.subjective_eval import SubjectiveEvalTask
|
||||||
|
from opencompass.summarizers import AllObjSummarizer
|
||||||
|
from opencompass.openicl.icl_evaluator import LMEvaluator
|
||||||
|
from opencompass.openicl.icl_prompt_template import PromptTemplate
|
||||||
|
|
||||||
|
|
||||||
|
# ------------- Prompt设置 ----------------------------------------
|
||||||
|
# 评测模板,请根据需要修改模板,JudgeLLM默认采用[Yes]或[No]作为回答,在MATH数据集中,评测模板如下
|
||||||
|
eng_obj_prompt = """
|
||||||
|
Look at the following two expressions (answers to a math problem) and judge whether they are equivalent. Only perform trivial simplifications
|
||||||
|
|
||||||
|
Examples:
|
||||||
|
|
||||||
|
Expression 1: $2x+3$
|
||||||
|
Expression 2: $3+2x$
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
|
||||||
|
Expression 1: 3/2
|
||||||
|
Expression 2: 1.5
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
|
||||||
|
Expression 1: $x^2+2x+1$
|
||||||
|
Expression 2: $y^2+2y+1$
|
||||||
|
|
||||||
|
[No]
|
||||||
|
|
||||||
|
Expression 1: $x^2+2x+1$
|
||||||
|
Expression 2: $(x+1)^2$
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
|
||||||
|
Expression 1: 3245/5
|
||||||
|
Expression 2: 649
|
||||||
|
|
||||||
|
[No]
|
||||||
|
(these are actually equal, don't mark them equivalent if you need to do nontrivial simplifications)
|
||||||
|
|
||||||
|
Expression 1: 2/(-3)
|
||||||
|
Expression 2: -2/3
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
(trivial simplifications are allowed)
|
||||||
|
|
||||||
|
Expression 1: 72 degrees
|
||||||
|
Expression 2: 72
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
(give benefit of the doubt to units)
|
||||||
|
|
||||||
|
Expression 1: 64
|
||||||
|
Expression 2: 64 square feet
|
||||||
|
|
||||||
|
[Yes]
|
||||||
|
(give benefit of the doubt to units)
|
||||||
|
|
||||||
|
Expression 1: 64
|
||||||
|
Expression 2:
|
||||||
|
|
||||||
|
[No]
|
||||||
|
(only mark as equivalent if both expressions are nonempty)
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
YOUR TASK
|
||||||
|
|
||||||
|
|
||||||
|
Respond with only "[Yes]" or "[No]" (without quotes). Do not include a rationale.
|
||||||
|
Expression 1: {obj_gold}
|
||||||
|
Expression 2: {prediction}
|
||||||
|
|
||||||
|
"""
|
||||||
|
|
||||||
|
# -------------推理阶段 ----------------------------------------
|
||||||
|
# 需要评测的模型
|
||||||
|
models = [*hf_llama3_8b_instruct_model]
|
||||||
|
# 评价模型
|
||||||
|
judge_models = hf_llama3_70b_instruct_model
|
||||||
|
|
||||||
|
eng_datasets = [*math_datasets]
|
||||||
|
chn_datasets = []
|
||||||
|
datasets = eng_datasets + chn_datasets
|
||||||
|
|
||||||
|
|
||||||
|
for d in eng_datasets:
|
||||||
|
d['eval_cfg']= dict(
|
||||||
|
evaluator=dict(
|
||||||
|
type=LMEvaluator,
|
||||||
|
# 如果你需要在判断之前预处理模型预测,
|
||||||
|
# 你可以在这里指定pred_postprocessor函数
|
||||||
|
pred_postprocessor=dict(type=math_judement_preprocess),
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(round=[
|
||||||
|
dict(
|
||||||
|
role='HUMAN',
|
||||||
|
prompt = eng_obj_prompt
|
||||||
|
),
|
||||||
|
]),
|
||||||
|
),
|
||||||
|
),
|
||||||
|
pred_role="BOT",
|
||||||
|
)
|
||||||
|
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=SizePartitioner, max_task_size=40000),
|
||||||
|
runner=dict(
|
||||||
|
type=LocalRunner,
|
||||||
|
max_num_workers=256,
|
||||||
|
task=dict(type=OpenICLInferTask)),
|
||||||
|
)
|
||||||
|
|
||||||
|
# ------------- 评测配置 --------------------------------
|
||||||
|
eval = dict(
|
||||||
|
partitioner=dict(
|
||||||
|
type=SubjectiveSizePartitioner, max_task_size=80000, mode='singlescore', models=models, judge_models=judge_models,
|
||||||
|
),
|
||||||
|
runner=dict(type=LocalRunner,
|
||||||
|
max_num_workers=16, task=dict(type=SubjectiveEvalTask)),
|
||||||
|
)
|
||||||
|
|
||||||
|
summarizer = dict(
|
||||||
|
type=AllObjSummarizer
|
||||||
|
)
|
||||||
|
|
||||||
|
# 输出文件夹
|
||||||
|
work_dir = 'outputs/obj_all/'
|
||||||
|
```
|
||||||
|
|
||||||
|
### 第二步 启动评测并输出评测结果
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py eval_math_llm_judge.py
|
||||||
|
```
|
||||||
|
|
||||||
|
此时会进行两轮评测,第一轮是模型推理得到问题的预测答案,第二轮是JudgeLLM评测预测答案和标准答案的一致性,并打分。
|
||||||
|
|
||||||
|
- 模型预测的结果会保存在 `output/.../timestamp/predictions/xxmodel/xxx.json`
|
||||||
|
- JudgeLLM的评测回复会保存在 `output/.../timestamp/results/xxmodel/xxx.json`
|
||||||
|
- 评测报告则会输出到 `output/.../timestamp/summary/timestamp/xxx.csv`
|
||||||
|
|
||||||
|
## 评测结果
|
||||||
|
|
||||||
|
采用Llama3-8b-instruct作为评价模型,Llama3-70b-instruct作为评价器,对MATH数据集进行评价,结果如下:
|
||||||
|
|
||||||
|
| Model | JudgeLLM Evaluation | Naive Evaluation |
|
||||||
|
| ------------------- | ------------------- | ---------------- |
|
||||||
|
| llama-3-8b-instruct | 27.7 | 27.8 |
|
||||||
|
|
@ -0,0 +1,65 @@
|
||||||
|
# 评测结果持久化
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
通常情况下,OpenCompass的评测结果将会保存到工作目录下。 但在某些情况下,可能会产生用户间的数据共享,以及快速查看已有的公共评测结果等需求。 因此,我们提供了一个能够将评测结果快速转存到外部公共数据站的接口,并且在此基础上提供了对数据站的上传、更新、读取等功能。
|
||||||
|
|
||||||
|
## 快速开始
|
||||||
|
|
||||||
|
### 向数据站存储数据
|
||||||
|
|
||||||
|
通过在CLI评测指令中添加`args`或在Eval脚本中添加配置,即可将本次评测结果存储到您所指定的路径,示例如下:
|
||||||
|
|
||||||
|
(方式1)在指令中添加`args`选项并指定你的公共路径地址。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path'
|
||||||
|
```
|
||||||
|
|
||||||
|
(方式2)在Eval脚本中添加配置。
|
||||||
|
|
||||||
|
```pythonE
|
||||||
|
station_path = '/your_path'
|
||||||
|
```
|
||||||
|
|
||||||
|
### 向数据站更新数据
|
||||||
|
|
||||||
|
上述存储方法在上传数据前会首先根据模型和数据集配置中的`abbr`属性来判断数据站中是否已有相同任务结果。若已有结果,则取消本次存储。如果您需要更新这部分结果,请在指令中添加`station-overwrite`选项,示例如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path' --station-overwrite
|
||||||
|
```
|
||||||
|
|
||||||
|
### 读取数据站中已有的结果
|
||||||
|
|
||||||
|
您可以直接从数据站中读取已有的结果,以避免重复进行评测任务。读取到的结果会直接参与到`summarize`步骤。采用该配置时,仅有数据站中未存储结果的任务会被启动。示例如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path' --read-from-station
|
||||||
|
```
|
||||||
|
|
||||||
|
### 指令组合
|
||||||
|
|
||||||
|
1. 仅向数据站上传最新工作目录下结果,不补充运行缺失结果的任务:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
opencompass ... -sp '/your_path' -r latest -m viz
|
||||||
|
```
|
||||||
|
|
||||||
|
## 数据站存储格式
|
||||||
|
|
||||||
|
在数据站中,评测结果按照每个`model-dataset`对的结果存储为`json`文件。具体的目录组织形式为`/your_path/dataset_name/model_name.json`。每个`json`文件都存储了对应结果的字典,包括`predictions`、`results`以及`cfg`三个子项,具体示例如下:
|
||||||
|
|
||||||
|
```pythonE
|
||||||
|
Result = {
|
||||||
|
'predictions': List[Dict],
|
||||||
|
'results': Dict,
|
||||||
|
'cfg': Dict = {
|
||||||
|
'models': Dict,
|
||||||
|
'datasets': Dict,
|
||||||
|
(Only subjective datasets)'judge_models': Dict
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
其中,`predictions`记录了模型对数据集中每一条数据的prediction的结果,`results`记录了模型在该数据集上的评分,`cfg`记录了该评测任务中模型和数据集的详细配置。
|
||||||
|
|
@ -0,0 +1,108 @@
|
||||||
|
# 提示词攻击
|
||||||
|
|
||||||
|
OpenCompass 支持[PromptBench](https://github.com/microsoft/promptbench)的提示词攻击。其主要想法是评估提示指令的鲁棒性,也就是说,当攻击或修改提示以指导任务时,希望该任务能尽可能表现的像像原始任务一样好。
|
||||||
|
|
||||||
|
## 环境安装
|
||||||
|
|
||||||
|
提示词攻击需要依赖 `PromptBench` 中的组件,所以需要先配置好环境。
|
||||||
|
|
||||||
|
```shell
|
||||||
|
git clone https://github.com/microsoft/promptbench.git
|
||||||
|
pip install textattack==0.3.8
|
||||||
|
export PYTHONPATH=$PYTHONPATH:promptbench/
|
||||||
|
```
|
||||||
|
|
||||||
|
## 如何攻击
|
||||||
|
|
||||||
|
### 增加数据集配置文件
|
||||||
|
|
||||||
|
我们将使用GLUE-wnli数据集作为示例,大部分配置设置可以参考[config.md](../user_guides/config.md)获取帮助。
|
||||||
|
|
||||||
|
首先,我们需要支持基本的数据集配置,你可以在`configs`中找到现有的配置文件,或者根据[new-dataset](./new_dataset.md)支持你自己的配置。
|
||||||
|
|
||||||
|
以下面的`infer_cfg`为例,我们需要定义提示模板。`adv_prompt`是实验中要被攻击的基本提示占位符。`sentence1`和`sentence2`是此数据集的输入。攻击只会修改`adv_prompt`字段。
|
||||||
|
|
||||||
|
然后,我们应该使用`AttackInferencer`与`original_prompt_list`和`adv_key`告诉推理器在哪里攻击和攻击什么文本。
|
||||||
|
|
||||||
|
更多详细信息可以参考`configs/datasets/promptbench/promptbench_wnli_gen_50662f.py`配置文件。
|
||||||
|
|
||||||
|
```python
|
||||||
|
original_prompt_list = [
|
||||||
|
'Are the following two sentences entailment or not_entailment? Answer me with "A. entailment" or "B. not_entailment", just one word. ',
|
||||||
|
"Does the relationship between the given sentences represent entailment or not_entailment? Respond with 'A. entailment' or 'B. not_entailment'.",
|
||||||
|
...,
|
||||||
|
]
|
||||||
|
|
||||||
|
wnli_infer_cfg = dict(
|
||||||
|
prompt_template=dict(
|
||||||
|
type=PromptTemplate,
|
||||||
|
template=dict(round=[
|
||||||
|
dict(
|
||||||
|
role="HUMAN",
|
||||||
|
prompt="""{adv_prompt}
|
||||||
|
Sentence 1: {sentence1}
|
||||||
|
Sentence 2: {sentence2}
|
||||||
|
Answer:"""),
|
||||||
|
]),
|
||||||
|
),
|
||||||
|
retriever=dict(type=ZeroRetriever),
|
||||||
|
inferencer=dict(
|
||||||
|
type=AttackInferencer,
|
||||||
|
original_prompt_list=original_prompt_list,
|
||||||
|
adv_key='adv_prompt'))
|
||||||
|
```
|
||||||
|
|
||||||
|
### Add a eval config
|
||||||
|
|
||||||
|
我们应该在此处使用 `OpenICLAttackTask` 来进行攻击任务。还应该使用 `NaivePartitioner`,因为攻击实验将重复运行整个数据集近百次以搜索最佳攻击,为方便起见我们不希望拆分数据集。
|
||||||
|
|
||||||
|
```note
|
||||||
|
由于上述提到的重复搜索,请选择小型数据集(样本少于1000)进行攻击,否则时间成本将非常大。
|
||||||
|
```
|
||||||
|
|
||||||
|
在 `attack` 配置中还有其他几个选项:
|
||||||
|
|
||||||
|
- `attack`:攻击类型,可用选项包括`textfooler`, `textbugger`, `deepwordbug`, `bertattack`, `checklist`, `stresstest`;
|
||||||
|
- `query_budget`:查询次数的上界,即运行数据集的总次数;
|
||||||
|
- `prompt_topk`:要攻击的前k个提示的数量。在大多数情况下,原始提示列表大于10,运行整个集合是耗时的。
|
||||||
|
|
||||||
|
```python
|
||||||
|
# Please run whole dataset at a time, aka use `NaivePartitioner` only
|
||||||
|
# Please use `OpenICLAttackTask` if want to perform attack experiment
|
||||||
|
infer = dict(
|
||||||
|
partitioner=dict(type=NaivePartitioner),
|
||||||
|
runner=dict(
|
||||||
|
type=SlurmRunner,
|
||||||
|
max_num_workers=8,
|
||||||
|
task=dict(type=OpenICLAttackTask),
|
||||||
|
retry=0),
|
||||||
|
)
|
||||||
|
|
||||||
|
attack = dict(
|
||||||
|
attack='textfooler',
|
||||||
|
query_budget=100,
|
||||||
|
prompt_topk=2,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 运行试验
|
||||||
|
|
||||||
|
请当运行攻击实验的时候请使用 `--mode infer` 选项,并需要指定`PYTHONPATH`。
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py configs/eval_attack.py --mode infer
|
||||||
|
```
|
||||||
|
|
||||||
|
所有结果都将保存在名为“attack”的文件夹中。
|
||||||
|
内容包括原始提示的准确性和受到攻击的提示的准确性,以及前k个提示下降的准确性,例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
Prompt: Assess the connection between the following sentences and classify it as 'A. entailment' or 'B. not_entailment'., acc: 59.15%
|
||||||
|
Prompt: Does the relationship between the given sentences represent entailment or not_entailment? Respond with 'A. entailment' or 'B. not_entailment'., acc: 57.75%
|
||||||
|
Prompt: Analyze the two provided sentences and decide if their relationship is 'A. entailment' or 'B. not_entailment'., acc: 56.34%
|
||||||
|
Prompt: Identify whether the given pair of sentences demonstrates entailment or not_entailment. Answer with 'A. entailment' or 'B. not_entailment'., acc: 54.93%
|
||||||
|
...
|
||||||
|
Original prompt: Assess the connection between the following sentences and classify it as 'A. entailment' or 'B. not_entailment'.
|
||||||
|
Attacked prompt: b"Assess the attach between the following sentences and sorted it as 'A. entailment' or 'B. not_entailment'."
|
||||||
|
Original acc: 59.15%, attacked acc: 40.85%, dropped acc: 18.31%
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,172 @@
|
||||||
|
# 主观评测指引
|
||||||
|
|
||||||
|
## 介绍
|
||||||
|
|
||||||
|
主观评测旨在评估模型在符合人类偏好的能力上的表现。这种评估的黄金准则是人类喜好,但标注成本很高。
|
||||||
|
|
||||||
|
为了探究模型的主观能力,我们采用了JudgeLLM作为人类评估者的替代品([LLM-as-a-Judge](https://arxiv.org/abs/2306.05685))。
|
||||||
|
|
||||||
|
流行的评估方法主要有:
|
||||||
|
|
||||||
|
- Compare模式:将模型的回答进行两两比较,以计算对战其胜率。
|
||||||
|
- Score模式:针对单模型的回答进行打分(例如:[Chatbot Arena](https://chat.lmsys.org/))。
|
||||||
|
|
||||||
|
我们基于以上方法支持了JudgeLLM用于模型的主观能力评估(目前opencompass仓库里支持的所有模型都可以直接作为JudgeLLM进行调用,此外一些专用的JudgeLLM我们也在计划支持中)。
|
||||||
|
|
||||||
|
## 目前已支持的主观评测数据集
|
||||||
|
|
||||||
|
1. AlignBench 中文Scoring数据集(https://github.com/THUDM/AlignBench)
|
||||||
|
2. MTBench 英文Scoring数据集,两轮对话(https://github.com/lm-sys/FastChat)
|
||||||
|
3. MTBench101 英文Scoring数据集,多轮对话(https://github.com/mtbench101/mt-bench-101)
|
||||||
|
4. AlpacaEvalv2 英文Compare数据集(https://github.com/tatsu-lab/alpaca_eval)
|
||||||
|
5. ArenaHard 英文Compare数据集,主要面向coding(https://github.com/lm-sys/arena-hard/tree/main)
|
||||||
|
6. Fofo 英文Socring数据集(https://github.com/SalesforceAIResearch/FoFo/)
|
||||||
|
7. Wildbench 英文Score和Compare数据集(https://github.com/allenai/WildBench)
|
||||||
|
|
||||||
|
## 启动主观评测
|
||||||
|
|
||||||
|
类似于已有的客观评测方式,可以在configs/eval_subjective.py中进行相关配置
|
||||||
|
|
||||||
|
### 基本参数models, datasets 和 judgemodels的指定
|
||||||
|
|
||||||
|
类似于客观评测的方式,导入需要评测的models和datasets,例如
|
||||||
|
|
||||||
|
```
|
||||||
|
with read_base():
|
||||||
|
from .datasets.subjective.alignbench.alignbench_judgeby_critiquellm import alignbench_datasets
|
||||||
|
from .datasets.subjective.alpaca_eval.alpacav2_judgeby_gpt4 import subjective_datasets as alpacav2
|
||||||
|
from .models.qwen.hf_qwen_7b import models
|
||||||
|
```
|
||||||
|
|
||||||
|
值得注意的是,由于主观评测的模型设置参数通常与客观评测不同,往往需要设置`do_sample`的方式进行推理而不是`greedy`,故可以在配置文件中自行修改相关参数,例如
|
||||||
|
|
||||||
|
```
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceChatGLM3,
|
||||||
|
abbr='chatglm3-6b-hf2',
|
||||||
|
path='THUDM/chatglm3-6b',
|
||||||
|
tokenizer_path='THUDM/chatglm3-6b',
|
||||||
|
model_kwargs=dict(
|
||||||
|
device_map='auto',
|
||||||
|
trust_remote_code=True,
|
||||||
|
),
|
||||||
|
tokenizer_kwargs=dict(
|
||||||
|
padding_side='left',
|
||||||
|
truncation_side='left',
|
||||||
|
trust_remote_code=True,
|
||||||
|
),
|
||||||
|
generation_kwargs=dict(
|
||||||
|
do_sample=True,
|
||||||
|
),
|
||||||
|
meta_template=api_meta_template,
|
||||||
|
max_out_len=2048,
|
||||||
|
max_seq_len=4096,
|
||||||
|
batch_size=8,
|
||||||
|
run_cfg=dict(num_gpus=1, num_procs=1),
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
judgemodel通常被设置为GPT4等强力模型,可以直接按照config文件中的配置填入自己的API key,或使用自定义的模型作为judgemodel
|
||||||
|
|
||||||
|
### 其他参数的指定
|
||||||
|
|
||||||
|
除了基本参数以外,还可以在config中修改`infer`和`eval`字段里的partitioner,从而设置更合适的分片方式,目前支持的分片方式主要有三种:NaivePartitoner, SizePartitioner和NumberWorkPartitioner
|
||||||
|
以及可以指定自己的workdir用以保存相关文件。
|
||||||
|
|
||||||
|
## 自定义主观数据集评测
|
||||||
|
|
||||||
|
主观评测的具体流程包括:
|
||||||
|
|
||||||
|
1. 评测数据集准备
|
||||||
|
2. 使用API模型或者开源模型进行问题答案的推理
|
||||||
|
3. 使用选定的评价模型(JudgeLLM)对模型输出进行评估
|
||||||
|
4. 对评价模型返回的预测结果进行解析并计算数值指标
|
||||||
|
|
||||||
|
### 第一步:数据准备
|
||||||
|
|
||||||
|
这一步需要准备好数据集文件以及在`Opencompass/datasets/subjective/`下实现自己数据集的类,将读取到的数据以`list of dict`的格式return
|
||||||
|
|
||||||
|
实际上可以按照自己喜欢的任意格式进行数据准备(csv, json, jsonl)等皆可,不过为了方便上手,推荐按照已有的主观数据集的格式进行构建或按照如下的json格式进行构建。
|
||||||
|
对于对战模式和打分模式,我们各提供了一个demo测试集如下:
|
||||||
|
|
||||||
|
```python
|
||||||
|
### 对战模式示例
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"question": "如果我在空中垂直抛球,球最初向哪个方向行进?",
|
||||||
|
"capability": "知识-社会常识",
|
||||||
|
"others": {
|
||||||
|
"question": "如果我在空中垂直抛球,球最初向哪个方向行进?",
|
||||||
|
"evaluating_guidance": "",
|
||||||
|
"reference_answer": "上"
|
||||||
|
}
|
||||||
|
},...]
|
||||||
|
|
||||||
|
### 打分模式数据集示例
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"question": "请你扮演一个邮件管家,我让你给谁发送什么主题的邮件,你就帮我扩充好邮件正文,并打印在聊天框里。你需要根据我提供的邮件收件人以及邮件主题,来斟酌用词,并使用合适的敬语。现在请给导师发送邮件,询问他是否可以下周三下午15:00进行科研同步会,大约200字。",
|
||||||
|
"capability": "邮件通知",
|
||||||
|
"others": ""
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
如果要准备自己的数据集,请按照以下字段进行提供,并整理为一个json文件:
|
||||||
|
|
||||||
|
- 'question':问题描述
|
||||||
|
- 'capability':题目所属的能力维度
|
||||||
|
- 'others':其他可能需要对题目进行特殊处理的项目
|
||||||
|
|
||||||
|
以上三个字段是必要的,用户也可以添加其他字段,如果需要对每个问题的prompt进行单独处理,可以在'others'字段中进行一些额外设置,并在Dataset类中添加相应的字段。
|
||||||
|
|
||||||
|
### 第二步:构建评测配置
|
||||||
|
|
||||||
|
以Alignbench为例`configs/datasets/subjective/alignbench/alignbench_judgeby_critiquellm.py`,
|
||||||
|
|
||||||
|
1. 首先需要设置`subjective_reader_cfg`,用以接收从自定义的Dataset类里return回来的相关字段并指定保存文件时的output字段
|
||||||
|
2. 然后需要指定数据集的根路径`data_path`以及数据集的文件名`subjective_all_sets`,如果有多个子文件,在这个list里进行添加即可
|
||||||
|
3. 指定`subjective_infer_cfg`和`subjective_eval_cfg`,配置好相应的推理和评测的prompt
|
||||||
|
4. 在相应的位置指定`mode`等额外信息,注意,对于不同的主观数据集,所需指定的字段可能不尽相同。
|
||||||
|
5. 定义后处理与得分统计。例如opencompass/opencompass/datasets/subjective/alignbench下的alignbench_postprocess处理函数
|
||||||
|
|
||||||
|
### 第三步 启动评测并输出评测结果
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python run.py configs/eval_subjective.py -r
|
||||||
|
```
|
||||||
|
|
||||||
|
- `-r` 参数支持复用模型推理和评估结果。
|
||||||
|
|
||||||
|
JudgeLLM的评测回复会保存在 `output/.../results/timestamp/xxmodel/xxdataset/.json`
|
||||||
|
评测报告则会输出到 `output/.../summary/timestamp/report.csv`。
|
||||||
|
|
||||||
|
## 主观多轮对话评测
|
||||||
|
|
||||||
|
在OpenCompass中我们同样支持了主观的多轮对话评测,以MT-Bench为例,对MTBench的评测可以参见`configs/datasets/subjective/multiround`
|
||||||
|
|
||||||
|
在多轮对话评测中,你需要将数据格式整理为如下的dialogue格式
|
||||||
|
|
||||||
|
```
|
||||||
|
"dialogue": [
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "Imagine you are participating in a race with a group of people. If you have just overtaken the second person, what's your current position? Where is the person you just overtook?"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"role": "assistant",
|
||||||
|
"content": ""
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"role": "user",
|
||||||
|
"content": "If the \"second person\" is changed to \"last person\" in the above question, what would the answer be?"
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"role": "assistant",
|
||||||
|
"content": ""
|
||||||
|
}
|
||||||
|
],
|
||||||
|
```
|
||||||
|
|
||||||
|
值得注意的是,由于MTBench各不同的题目类型设置了不同的温度,因此我们需要将原始数据文件按照温度分成三个不同的子集以分别推理,针对不同的子集我们可以设置不同的温度,具体设置参加`configs\datasets\subjective\multiround\mtbench_single_judge_diff_temp.py`
|
||||||
|
|
@ -0,0 +1,231 @@
|
||||||
|
# flake8: noqa
|
||||||
|
# Configuration file for the Sphinx documentation builder.
|
||||||
|
#
|
||||||
|
# This file only contains a selection of the most common options. For a full
|
||||||
|
# list see the documentation:
|
||||||
|
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
||||||
|
|
||||||
|
# -- Path setup --------------------------------------------------------------
|
||||||
|
|
||||||
|
# If extensions (or modules to document with autodoc) are in another directory,
|
||||||
|
# add these directories to sys.path here. If the directory is relative to the
|
||||||
|
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
||||||
|
#
|
||||||
|
import os
|
||||||
|
import subprocess
|
||||||
|
import sys
|
||||||
|
|
||||||
|
import pytorch_sphinx_theme
|
||||||
|
from sphinx.builders.html import StandaloneHTMLBuilder
|
||||||
|
|
||||||
|
sys.path.insert(0, os.path.abspath('../../'))
|
||||||
|
|
||||||
|
# -- Project information -----------------------------------------------------
|
||||||
|
|
||||||
|
project = 'OpenCompass'
|
||||||
|
copyright = '2023, OpenCompass'
|
||||||
|
author = 'OpenCompass Authors'
|
||||||
|
|
||||||
|
# The full version, including alpha/beta/rc tags
|
||||||
|
version_file = '../../opencompass/__init__.py'
|
||||||
|
|
||||||
|
|
||||||
|
def get_version():
|
||||||
|
with open(version_file, 'r') as f:
|
||||||
|
exec(compile(f.read(), version_file, 'exec'))
|
||||||
|
return locals()['__version__']
|
||||||
|
|
||||||
|
|
||||||
|
release = get_version()
|
||||||
|
|
||||||
|
# -- General configuration ---------------------------------------------------
|
||||||
|
|
||||||
|
# Add any Sphinx extension module names here, as strings. They can be
|
||||||
|
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
||||||
|
# ones.
|
||||||
|
extensions = [
|
||||||
|
'sphinx.ext.autodoc',
|
||||||
|
'sphinx.ext.autosummary',
|
||||||
|
'sphinx.ext.intersphinx',
|
||||||
|
'sphinx.ext.napoleon',
|
||||||
|
'sphinx.ext.viewcode',
|
||||||
|
'myst_parser',
|
||||||
|
'sphinx_copybutton',
|
||||||
|
'sphinx_tabs.tabs',
|
||||||
|
'notfound.extension',
|
||||||
|
'sphinxcontrib.jquery',
|
||||||
|
'sphinx_design',
|
||||||
|
]
|
||||||
|
|
||||||
|
# Add any paths that contain templates here, relative to this directory.
|
||||||
|
templates_path = ['_templates']
|
||||||
|
|
||||||
|
# The suffix(es) of source filenames.
|
||||||
|
# You can specify multiple suffix as a list of string:
|
||||||
|
#
|
||||||
|
source_suffix = {
|
||||||
|
'.rst': 'restructuredtext',
|
||||||
|
'.md': 'markdown',
|
||||||
|
}
|
||||||
|
|
||||||
|
language = 'cn'
|
||||||
|
|
||||||
|
# The master toctree document.
|
||||||
|
root_doc = 'index'
|
||||||
|
|
||||||
|
# List of patterns, relative to source directory, that match files and
|
||||||
|
# directories to ignore when looking for source files.
|
||||||
|
# This pattern also affects html_static_path and html_extra_path.
|
||||||
|
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
||||||
|
|
||||||
|
# -- Options for HTML output -------------------------------------------------
|
||||||
|
|
||||||
|
# The theme to use for HTML and HTML Help pages. See the documentation for
|
||||||
|
# a list of builtin themes.
|
||||||
|
#
|
||||||
|
html_theme = 'pytorch_sphinx_theme'
|
||||||
|
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
||||||
|
|
||||||
|
# Theme options are theme-specific and customize the look and feel of a theme
|
||||||
|
# further. For a list of options available for each theme, see the
|
||||||
|
# documentation.
|
||||||
|
# yapf: disable
|
||||||
|
html_theme_options = {
|
||||||
|
'menu': [
|
||||||
|
{
|
||||||
|
'name': 'GitHub',
|
||||||
|
'url': 'https://github.com/open-compass/opencompass'
|
||||||
|
},
|
||||||
|
],
|
||||||
|
# Specify the language of shared menu
|
||||||
|
'menu_lang': 'cn',
|
||||||
|
# Disable the default edit on GitHub
|
||||||
|
'default_edit_on_github': False,
|
||||||
|
}
|
||||||
|
# yapf: enable
|
||||||
|
|
||||||
|
# Add any paths that contain custom static files (such as style sheets) here,
|
||||||
|
# relative to this directory. They are copied after the builtin static files,
|
||||||
|
# so a file named "default.css" will overwrite the builtin "default.css".
|
||||||
|
html_static_path = ['_static']
|
||||||
|
html_css_files = [
|
||||||
|
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.css',
|
||||||
|
'css/readthedocs.css'
|
||||||
|
]
|
||||||
|
html_js_files = [
|
||||||
|
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.js',
|
||||||
|
'js/custom.js'
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Options for HTMLHelp output ---------------------------------------------
|
||||||
|
|
||||||
|
# Output file base name for HTML help builder.
|
||||||
|
htmlhelp_basename = 'opencompassdoc'
|
||||||
|
|
||||||
|
# -- Options for LaTeX output ------------------------------------------------
|
||||||
|
|
||||||
|
latex_elements = {
|
||||||
|
# The paper size ('letterpaper' or 'a4paper').
|
||||||
|
#
|
||||||
|
# 'papersize': 'letterpaper',
|
||||||
|
|
||||||
|
# The font size ('10pt', '11pt' or '12pt').
|
||||||
|
#
|
||||||
|
# 'pointsize': '10pt',
|
||||||
|
|
||||||
|
# Additional stuff for the LaTeX preamble.
|
||||||
|
#
|
||||||
|
# 'preamble': '',
|
||||||
|
}
|
||||||
|
|
||||||
|
# Grouping the document tree into LaTeX files. List of tuples
|
||||||
|
# (source start file, target name, title,
|
||||||
|
# author, documentclass [howto, manual, or own class]).
|
||||||
|
latex_documents = [
|
||||||
|
(root_doc, 'opencompass.tex', 'OpenCompass Documentation', author,
|
||||||
|
'manual'),
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Options for manual page output ------------------------------------------
|
||||||
|
|
||||||
|
# One entry per manual page. List of tuples
|
||||||
|
# (source start file, name, description, authors, manual section).
|
||||||
|
man_pages = [(root_doc, 'opencompass', 'OpenCompass Documentation', [author],
|
||||||
|
1)]
|
||||||
|
|
||||||
|
# -- Options for Texinfo output ----------------------------------------------
|
||||||
|
|
||||||
|
# Grouping the document tree into Texinfo files. List of tuples
|
||||||
|
# (source start file, target name, title, author,
|
||||||
|
# dir menu entry, description, category)
|
||||||
|
texinfo_documents = [
|
||||||
|
(root_doc, 'opencompass', 'OpenCompass Documentation', author,
|
||||||
|
'OpenCompass Authors', 'AGI evaluation toolbox and benchmark.',
|
||||||
|
'Miscellaneous'),
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Options for Epub output -------------------------------------------------
|
||||||
|
|
||||||
|
# Bibliographic Dublin Core info.
|
||||||
|
epub_title = project
|
||||||
|
|
||||||
|
# The unique identifier of the text. This can be a ISBN number
|
||||||
|
# or the project homepage.
|
||||||
|
#
|
||||||
|
# epub_identifier = ''
|
||||||
|
|
||||||
|
# A unique identification for the text.
|
||||||
|
#
|
||||||
|
# epub_uid = ''
|
||||||
|
|
||||||
|
# A list of files that should not be packed into the epub file.
|
||||||
|
epub_exclude_files = ['search.html']
|
||||||
|
|
||||||
|
# set priority when building html
|
||||||
|
StandaloneHTMLBuilder.supported_image_types = [
|
||||||
|
'image/svg+xml', 'image/gif', 'image/png', 'image/jpeg'
|
||||||
|
]
|
||||||
|
|
||||||
|
# -- Extension configuration -------------------------------------------------
|
||||||
|
# Ignore >>> when copying code
|
||||||
|
copybutton_prompt_text = r'>>> |\.\.\. '
|
||||||
|
copybutton_prompt_is_regexp = True
|
||||||
|
|
||||||
|
# Auto-generated header anchors
|
||||||
|
myst_heading_anchors = 3
|
||||||
|
# Enable "colon_fence" extension of myst.
|
||||||
|
myst_enable_extensions = ['colon_fence', 'dollarmath']
|
||||||
|
|
||||||
|
# Configuration for intersphinx
|
||||||
|
intersphinx_mapping = {
|
||||||
|
'python': ('https://docs.python.org/3', None),
|
||||||
|
'numpy': ('https://numpy.org/doc/stable', None),
|
||||||
|
'torch': ('https://pytorch.org/docs/stable/', None),
|
||||||
|
'mmengine': ('https://mmengine.readthedocs.io/en/latest/', None),
|
||||||
|
'transformers':
|
||||||
|
('https://huggingface.co/docs/transformers/main/en/', None),
|
||||||
|
}
|
||||||
|
napoleon_custom_sections = [
|
||||||
|
# Custom sections for data elements.
|
||||||
|
('Meta fields', 'params_style'),
|
||||||
|
('Data fields', 'params_style'),
|
||||||
|
]
|
||||||
|
|
||||||
|
# Disable docstring inheritance
|
||||||
|
autodoc_inherit_docstrings = False
|
||||||
|
# Mock some imports during generate API docs.
|
||||||
|
autodoc_mock_imports = ['rich', 'attr', 'einops']
|
||||||
|
# Disable displaying type annotations, these can be very verbose
|
||||||
|
autodoc_typehints = 'none'
|
||||||
|
|
||||||
|
# The not found page
|
||||||
|
notfound_template = '404.html'
|
||||||
|
|
||||||
|
|
||||||
|
def builder_inited_handler(app):
|
||||||
|
subprocess.run(['./cp_origin_docs.sh'])
|
||||||
|
subprocess.run(['./statis.py'])
|
||||||
|
|
||||||
|
|
||||||
|
def setup(app):
|
||||||
|
app.connect('builder-inited', builder_inited_handler)
|
||||||
|
|
@ -0,0 +1,9 @@
|
||||||
|
#!/usr/bin/env bash
|
||||||
|
|
||||||
|
# Copy *.md files from docs/ if it doesn't have a Chinese translation
|
||||||
|
|
||||||
|
for filename in $(find ../en/ -name '*.md' -printf "%P\n");
|
||||||
|
do
|
||||||
|
mkdir -p $(dirname $filename)
|
||||||
|
cp -n ../en/$filename ./$filename
|
||||||
|
done
|
||||||
|
|
@ -0,0 +1,2 @@
|
||||||
|
[html writers]
|
||||||
|
table_style: colwidths-auto
|
||||||
|
|
@ -0,0 +1,147 @@
|
||||||
|
# 常见问题
|
||||||
|
|
||||||
|
## 通用
|
||||||
|
|
||||||
|
### ppl 和 gen 有什么区别和联系?
|
||||||
|
|
||||||
|
`ppl` 是困惑度 (perplexity) 的缩写,是一种评价模型进行语言建模能力的指标。在 OpenCompass 的语境下,它一般指一种选择题的做法:给定一个上下文,模型需要从多个备选项中选择一个最合适的。此时,我们会将 n 个选项拼接上上下文后,形成 n 个序列,然后计算模型对这 n 个序列的 perplexity,我们认为其中 perplexity 最低的序列所对应的选项即为模型在这道题上面的推理结果,该种评测方法的后处理简单直接、确定性高。
|
||||||
|
|
||||||
|
`gen` 是生成 (generate) 的缩写。在 OpenCompass 的语境下,它指的是在给定上下文的情况下,模型往后续写的结果就是这道题目上的推理结果。一般来说,续写得到的字符串需要结合上比较重的后处理过程,才能进行可靠的答案提取,从而完成评测。
|
||||||
|
|
||||||
|
从使用上来说,基座模型的单项选择题和部分具有选择题性质的题目会使用 `ppl`,基座模型的不定项选择和非选择题都会使用 `gen`。而对话模型的所有题目都会使用 `gen`,因为许多商用 API 模型不会暴露 `ppl` 的接口。但也存在例外情况,例如我们希望基座模型输出解题思路过程时 (例如 Let's think step by step),我们同样会使用 `gen`,但总体的使用如下图所示:
|
||||||
|
|
||||||
|
| | ppl | gen |
|
||||||
|
| -------- | ----------- | ------------------ |
|
||||||
|
| 基座模型 | 仅 MCQ 任务 | MCQ 以外的其他任务 |
|
||||||
|
| 对话模型 | 无 | 所有任务 |
|
||||||
|
|
||||||
|
与 `ppl` 高度类似地,条件对数概率 `clp` (conditional log probability) 是在给定上下文的情况下,计算下一个 token 的概率。它也仅适用于选择题,考察概率的范围仅限于备选项标号所对应的 token,取其中概率最高的 token 所对应的选项为模型的推理结果。与 ppl 相比,`clp` 的计算更加高效,仅需要推理一次,而 ppl 需要推理 n 次,但坏处是,`clp` 受制于 tokenizer,在例如选项前后有无空格符号时,tokenizer 编码的结果会有变化,导致测试结果不可靠。因此 OpenCompass 中很少使用 `clp`。
|
||||||
|
|
||||||
|
### OpenCompass 如何控制 few shot 评测的 shot 数目?
|
||||||
|
|
||||||
|
在数据集配置文件中,有一个 `retriever` 的字段,该字段表示如何召回数据集中的样本作为上下文样例,其中最常用的是 `FixKRetriever` 表示固定使用某 k 个样本,因此即为 k-shot。另外还有 `ZeroRetriever` 表示不使用任何样本,这在大多数情况下意味着 0-shot。
|
||||||
|
|
||||||
|
另一方面,in context 的样本也可以直接在数据集的模板中指定,在该情况下亦会搭配使用 `ZeroRetriever`,但此时的评测并不是 0-shot,而需要根据具体的模板来进行确定。具体请看 [prompt](../prompt/prompt_template.md)
|
||||||
|
|
||||||
|
### OpenCompass task 的默认划分逻辑是什么样的?
|
||||||
|
|
||||||
|
OpenCompass 默认使用 num_worker_partitioner。OpenCompass 的评测从本质上来说就是有一系列的模型和一系列的数据集,然后两两组合,用每个模型去跑每个数据集。对于同一个模型,OpenCompass 会将其拆分为 `--max-num-workers` (或 config 中的 `infer.runner.max_num_workers`) 个 task,为了保证每个 task 的运行耗时均匀,每个 task 均会所有数据集的一部分。示意图如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### OpenCompass 在 slurm 等方式运行时,为什么会有部分 infer log 不存在?
|
||||||
|
|
||||||
|
因为 log 的文件名并不是一个数据集的切分,而是一个 task 的名字。由于 partitioner 有可能会将多个较小的任务合并成一个大的,而 task 的名字往往就是第一个数据集的名字。因此该 task 中后面的数据集的名字对应的 log 都不会出现,而是会直接写在第一个数据集对应的 log 中
|
||||||
|
|
||||||
|
### OpenCompass 中的断点继续逻辑是什么样的?
|
||||||
|
|
||||||
|
只要使用 --reuse / -r 开关,则会进行断点继续。首先 OpenCompass 会按照最新的 config 文件配置模型和数据集,然后在 partitioner 确定分片大小并切片后,对每个分片依次查找,若该分片已完成,则跳过;若该分片未完成或未启动,则加入待测列表。然后将待测列表中的任务依次进行执行。注意,未完成的任务对应的输出文件名一般是 `tmp_xxx`,此时模型会从该文件中标号最大的一个数据开始往后继续跑,直到完成这个分片。
|
||||||
|
|
||||||
|
根据上述过程,有如下推论:
|
||||||
|
|
||||||
|
- 在已有输出文件夹的基础上断点继续时,不可以更换 partitioner 的切片方式,或者不可以修改 `--max-num-workers` 的入参。(除非使用了 `tools/prediction_merger.py` 工具)
|
||||||
|
- 如果数据集有了任何修改,不要断点继续,或者根据需要将原有的输出文件进行删除后,全部重跑。
|
||||||
|
|
||||||
|
### OpenCompass 如何分配 GPU?
|
||||||
|
|
||||||
|
OpenCompass 使用称为 task (任务) 的单位处理评估请求。每个任务都是模型和数据集的独立组合。任务所需的 GPU 资源完全由正在评估的模型决定,具体取决于 `num_gpus` 参数。
|
||||||
|
|
||||||
|
在评估过程中,OpenCompass 部署多个工作器并行执行任务。这些工作器不断尝试获取 GPU 资源直到成功运行任务。因此,OpenCompass 始终努力充分利用所有可用的 GPU 资源。
|
||||||
|
|
||||||
|
例如,如果您在配备有 8 个 GPU 的本地机器上使用 OpenCompass,每个任务要求 4 个 GPU,那么默认情况下,OpenCompass 会使用所有 8 个 GPU 同时运行 2 个任务。但是,如果您将 `--max-num-workers` 设置为 1,那么一次只会处理一个任务,只使用 4 个 GPU。
|
||||||
|
|
||||||
|
### 我如何控制 OpenCompass 占用的 GPU 数量?
|
||||||
|
|
||||||
|
目前,没有直接的方法来指定 OpenCompass 可以使用的 GPU 数量。但以下是一些间接策略:
|
||||||
|
|
||||||
|
**如果在本地评估:**
|
||||||
|
您可以通过设置 `CUDA_VISIBLE_DEVICES` 环境变量来限制 OpenCompass 的 GPU 访问。例如,使用 `CUDA_VISIBLE_DEVICES=0,1,2,3 python run.py ...` 只会向 OpenCompass 暴露前四个 GPU,确保它同时使用的 GPU 数量不超过这四个。
|
||||||
|
|
||||||
|
**如果使用 Slurm 或 DLC:**
|
||||||
|
尽管 OpenCompass 没有直接访问资源池,但您可以调整 `--max-num-workers` 参数以限制同时提交的评估任务数量。这将间接管理 OpenCompass 使用的 GPU 数量。例如,如果每个任务需要 4 个 GPU,您希望分配总共 8 个 GPU,那么应将 `--max-num-workers` 设置为 2。
|
||||||
|
|
||||||
|
### 找不到 `libGL.so.1`
|
||||||
|
|
||||||
|
opencv-python 依赖一些动态库,但环境中没有,最简单的解决办法是卸载 opencv-python 再安装 opencv-python-headless。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip uninstall opencv-python
|
||||||
|
pip install opencv-python-headless
|
||||||
|
```
|
||||||
|
|
||||||
|
也可以根据报错提示安装对应的依赖库
|
||||||
|
|
||||||
|
```bash
|
||||||
|
sudo apt-get update
|
||||||
|
sudo apt-get install -y libgl1 libglib2.0-0
|
||||||
|
```
|
||||||
|
|
||||||
|
### 运行报错 Error: mkl-service + Intel(R) MKL
|
||||||
|
|
||||||
|
报错全文如下:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Error: mkl-service + Intel(R) MKL: MKL_THREADING_LAYER=INTEL is incompatible with libgomp-a34b3233.so.1 library.
|
||||||
|
Try to import numpy first or set the threading layer accordingly. Set MKL_SERVICE_FORCE_INTEL to force it.
|
||||||
|
```
|
||||||
|
|
||||||
|
可以通过设置环境变量 `MKL_SERVICE_FORCE_INTEL=1` 来解决这个问题。
|
||||||
|
|
||||||
|
## 网络
|
||||||
|
|
||||||
|
### 运行报错:`('Connection aborted.', ConnectionResetError(104, 'Connection reset by peer'))` 或 `urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='cdn-lfs.huggingface.co', port=443)`
|
||||||
|
|
||||||
|
由于 HuggingFace 的实现,OpenCompass 在首次加载某些数据集和模型时需要网络(尤其是与 HuggingFace 的连接)。此外,每次启动时都会连接到 HuggingFace。为了成功运行,您可以:
|
||||||
|
|
||||||
|
- 通过指定环境变量 `http_proxy` 和 `https_proxy`,挂上代理;
|
||||||
|
- 使用其他机器的缓存文件。首先在有 HuggingFace 访问权限的机器上运行实验,然后将缓存文件复制 / 软链到离线的机器上。缓存文件默认位于 `~/.cache/huggingface/`([文档](https://huggingface.co/docs/datasets/cache#cache-directory))。当缓存文件准备好时,您可以在离线模式下启动评估:
|
||||||
|
```python
|
||||||
|
HF_DATASETS_OFFLINE=1 TRANSFORMERS_OFFLINE=1 HF_EVALUATE_OFFLINE=1 HF_HUB_OFFLINE=1 python run.py ...
|
||||||
|
```
|
||||||
|
这样,评估不再需要网络连接。但是,如果缓存中缺少任何数据集或模型的文件,仍然会引发错误。
|
||||||
|
- 使用中国大陆内的镜像源,例如 [hf-mirror](https://hf-mirror.com/)
|
||||||
|
```python
|
||||||
|
HF_ENDPOINT=https://hf-mirror.com python run.py ...
|
||||||
|
```
|
||||||
|
|
||||||
|
### 我的服务器无法连接到互联网,我如何使用 OpenCompass?
|
||||||
|
|
||||||
|
如 [网络-Q1](#运行报错Connection-aborted-ConnectionResetError104-Connection-reset-by-peer-或-urllib3exceptionsMaxRetryError-HTTPSConnectionPoolhostcdn-lfshuggingfaceco-port443) 所述,使用其他机器的缓存文件。
|
||||||
|
|
||||||
|
## 效率
|
||||||
|
|
||||||
|
### 为什么 OpenCompass 将每个评估请求分割成任务?
|
||||||
|
|
||||||
|
鉴于大量的评估时间和大量的数据集,对 LLM 模型进行全面的线性评估可能非常耗时。为了解决这个问题,OpenCompass 将评估请求分为多个独立的 “任务”。然后,这些任务被派发到各种 GPU 组或节点,实现全并行并最大化计算资源的效率。
|
||||||
|
|
||||||
|
### 任务分区是如何工作的?
|
||||||
|
|
||||||
|
OpenCompass 中的每个任务代表等待评估的特定模型和数据集部分的组合。OpenCompass 提供了各种任务分区策略,每种策略都针对不同的场景。在推理阶段,主要的分区方法旨在平衡任务大小或计算成本。这种成本是从数据集大小和推理类型中启发式地得出的。
|
||||||
|
|
||||||
|
### 为什么在 OpenCompass 上评估 LLM 模型需要更多时间?
|
||||||
|
|
||||||
|
请检查:
|
||||||
|
|
||||||
|
1. 是否有使用 vllm / lmdeploy 等推理后端,这会大大提速测试过程
|
||||||
|
2. 对于使用原生 huggingface 跑的,`batch_size` 为 1 会大幅拖慢测试过程,可以适当调大 `batch_size`
|
||||||
|
3. 如果是 huggingface 上下载的模型,是否有大量的时间卡在网络连接或模型下载上面了
|
||||||
|
4. 模型的推理结果是否会意外地长,尤其是模型是否在尝试再出若干题并尝试进行解答,这在基座模型中会尤其常见。可以通过在数据集中添加 `stopping_criteria` 的方式来解决
|
||||||
|
|
||||||
|
如果上述检查项没有解决问题,请考虑给我们报 bug
|
||||||
|
|
||||||
|
## 模型
|
||||||
|
|
||||||
|
### 如何使用本地已下好的 Huggingface 模型?
|
||||||
|
|
||||||
|
如果您已经提前下载好 Huggingface 的模型文件,请手动指定模型路径. 示例如下
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --datasets siqa_gen winograd_ppl --hf-type base --hf-path /path/to/model
|
||||||
|
```
|
||||||
|
|
||||||
|
## 数据集
|
||||||
|
|
||||||
|
### 如何构建自己的评测数据集
|
||||||
|
|
||||||
|
- 客观数据集构建参见:[支持新数据集](../advanced_guides/new_dataset.md)
|
||||||
|
- 主观数据集构建参见:[主观评测指引](../advanced_guides/subjective_evaluation.md)
|
||||||
|
|
@ -0,0 +1,141 @@
|
||||||
|
# 安装
|
||||||
|
|
||||||
|
## 基础安装
|
||||||
|
|
||||||
|
1. 使用Conda准备 OpenCompass 运行环境:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
conda create --name opencompass python=3.10 -y
|
||||||
|
# conda create --name opencompass_lmdeploy python=3.10 -y
|
||||||
|
|
||||||
|
conda activate opencompass
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你希望自定义 PyTorch 版本,请参考 [官方文档](https://pytorch.org/get-started/locally/) 准备 PyTorch 环境。需要注意的是,OpenCompass 要求 `pytorch>=1.13`。
|
||||||
|
|
||||||
|
2. 安装 OpenCompass:
|
||||||
|
|
||||||
|
- pip安装
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 支持绝大多数数据集及模型
|
||||||
|
pip install -U opencompass
|
||||||
|
|
||||||
|
# 完整安装(支持更多数据集)
|
||||||
|
# pip install "opencompass[full]"
|
||||||
|
|
||||||
|
# API 测试(例如 OpenAI、Qwen)
|
||||||
|
# pip install "opencompass[api]"
|
||||||
|
```
|
||||||
|
|
||||||
|
- 如果希望使用 OpenCompass 的最新功能,也可以从源代码构建它:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/open-compass/opencompass opencompass
|
||||||
|
cd opencompass
|
||||||
|
pip install -e .
|
||||||
|
```
|
||||||
|
|
||||||
|
## 其他安装
|
||||||
|
|
||||||
|
### 推理后端
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 模型推理后端,由于这些推理后端通常存在依赖冲突,建议使用不同的虚拟环境来管理它们。
|
||||||
|
pip install "opencompass[lmdeploy]"
|
||||||
|
# pip install "opencompass[vllm]"
|
||||||
|
```
|
||||||
|
|
||||||
|
- LMDeploy
|
||||||
|
|
||||||
|
可以通过下列命令判断推理后端是否安装成功,更多信息请参考 [官方文档](https://lmdeploy.readthedocs.io/zh-cn/latest/get_started.html)
|
||||||
|
|
||||||
|
```bash
|
||||||
|
lmdeploy chat internlm/internlm2_5-1_8b-chat --backend turbomind
|
||||||
|
```
|
||||||
|
|
||||||
|
- vLLM
|
||||||
|
可以通过下列命令判断推理后端是否安装成功,更多信息请参考 [官方文档](https://docs.vllm.ai/en/latest/getting_started/quickstart.html)
|
||||||
|
|
||||||
|
```bash
|
||||||
|
vllm serve facebook/opt-125m
|
||||||
|
```
|
||||||
|
|
||||||
|
### API
|
||||||
|
|
||||||
|
Opencompass支持不同的商业模型API调用,你可以通过pip方式安装,或者参考 [API](https://github.com/open-compass/opencompass/blob/main/requirements/api.txt) 安装对应的API模型依赖
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install opencompass[api]
|
||||||
|
|
||||||
|
# pip install openai # GPT-3.5-Turbo / GPT-4-Turbo / GPT-4 / GPT-4o (API)
|
||||||
|
# pip install anthropic # Claude (API)
|
||||||
|
# pip install dashscope # 通义千问 (API)
|
||||||
|
# pip install volcengine-python-sdk # 字节豆包 (API)
|
||||||
|
# ...
|
||||||
|
```
|
||||||
|
|
||||||
|
### 数据集
|
||||||
|
|
||||||
|
基础安装可以支持绝大部分基础数据集,针对某些数据集(i.e. Alpaca-eval, Longbench etc.),需要安装额外的依赖。
|
||||||
|
你可以通过pip方式安装,或者参考 [额外依赖](https://github.com/open-compass/opencompass/blob/main/requirements/extra.txt) 安装对应的依赖
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install opencompass[full]
|
||||||
|
```
|
||||||
|
|
||||||
|
针对 HumanEvalX / HumanEval+ / MBPP+ 需要手动clone git仓库进行安装
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone --recurse-submodules git@github.com:open-compass/human-eval.git
|
||||||
|
cd human-eval
|
||||||
|
pip install -e .
|
||||||
|
pip install -e evalplus
|
||||||
|
```
|
||||||
|
|
||||||
|
部分智能体评测需要安装大量依赖且可能会与已有运行环境冲突,我们建议创建不同的conda环境来管理
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# T-Eval
|
||||||
|
pip install lagent==0.1.2
|
||||||
|
# CIBench
|
||||||
|
pip install -r requirements/agent.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
## 数据集准备
|
||||||
|
|
||||||
|
OpenCompass 支持的数据集主要包括三个部分:
|
||||||
|
|
||||||
|
1. Huggingface 数据集: [Huggingface Dataset](https://huggingface.co/datasets) 提供了大量的数据集,这部分数据集运行时会**自动下载**。
|
||||||
|
|
||||||
|
2. ModelScope 数据集:[ModelScope OpenCompass Dataset](https://modelscope.cn/organization/opencompass) 支持从 ModelScope 自动下载数据集。
|
||||||
|
|
||||||
|
要启用此功能,请设置环境变量:`export DATASET_SOURCE=ModelScope`,可用的数据集包括(来源于 OpenCompassData-core.zip):
|
||||||
|
|
||||||
|
```plain
|
||||||
|
humaneval, triviaqa, commonsenseqa, tydiqa, strategyqa, cmmlu, lambada, piqa, ceval, math, LCSTS, Xsum, winogrande, openbookqa, AGIEval, gsm8k, nq, race, siqa, mbpp, mmlu, hellaswag, ARC, BBH, xstory_cloze, summedits, GAOKAO-BENCH, OCNLI, cmnli
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 自建以及第三方数据集:OpenCompass 还提供了一些第三方数据集及自建**中文**数据集。运行以下命令**手动下载解压**。
|
||||||
|
|
||||||
|
在 OpenCompass 项目根目录下运行下面命令,将数据集准备至 `${OpenCompass}/data` 目录下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
|
||||||
|
unzip OpenCompassData-core-20240207.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
如果需要使用 OpenCompass 提供的更加完整的数据集 (~500M),可以使用下述命令进行下载和解压:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-complete-20240207.zip
|
||||||
|
unzip OpenCompassData-complete-20240207.zip
|
||||||
|
cd ./data
|
||||||
|
find . -name "*.zip" -exec unzip "{}" \;
|
||||||
|
```
|
||||||
|
|
||||||
|
两个 `.zip` 中所含数据集列表如[此处](https://github.com/open-compass/opencompass/releases/tag/0.2.2.rc1)所示。
|
||||||
|
|
||||||
|
OpenCompass 已经支持了大多数常用于性能比较的数据集,具体支持的数据集列表请直接在 `configs/datasets` 下进行查找。
|
||||||
|
|
||||||
|
接下来,你可以阅读[快速上手](./quick_start.md)了解 OpenCompass 的基本用法。
|
||||||
|
|
@ -0,0 +1,444 @@
|
||||||
|
# 快速开始
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 概览
|
||||||
|
|
||||||
|
在 OpenCompass 中评估一个模型通常包括以下几个阶段:**配置** -> **推理** -> **评估** -> **可视化**。
|
||||||
|
|
||||||
|
**配置**:这是整个工作流的起点。您需要配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
|
||||||
|
|
||||||
|
**推理与评估**:在这个阶段,OpenCompass 将会开始对模型和数据集进行并行推理和评估。**推理**阶段主要是让模型从数据集产生输出,而**评估**阶段则是衡量这些输出与标准答案的匹配程度。这两个过程会被拆分为多个同时运行的“任务”以提高效率,但请注意,如果计算资源有限,这种策略可能会使评测变得更慢。如果需要了解该问题及解决方案,可以参考 [FAQ: 效率](faq.md#效率)。
|
||||||
|
|
||||||
|
**可视化**:评估完成后,OpenCompass 将结果整理成易读的表格,并将其保存为 CSV 和 TXT 文件。你也可以激活飞书状态上报功能,此后可以在飞书客户端中及时获得评测状态报告。
|
||||||
|
|
||||||
|
接下来,我们将展示 OpenCompass 的基础用法,展示基座模型模型 [InternLM2-1.8B](https://huggingface.co/internlm/internlm2-1_8b) 和对话模型 [InternLM2-Chat-1.8B](https://huggingface.co/internlm/internlm2-chat-1_8b)、[Qwen2-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2-1.5B-Instruct) 在 [GSM8K](https://github.com/openai/grade-school-math) 和 [MATH](https://github.com/hendrycks/math) 下采样数据集上的评估。它们的配置文件可以在 [configs/eval_chat_demo.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_chat_demo.py) 和 [configs/eval_base_demo.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_base_demo.py) 中找到。
|
||||||
|
|
||||||
|
在运行此实验之前,请确保您已在本地安装了 OpenCompass。这个例子 (应该) 可以在一台 _GTX-1660-6G_ GPU 下成功运行。
|
||||||
|
|
||||||
|
对于参数更大的模型,如 Llama3-8B,请参考 [configs 目录](https://github.com/open-compass/opencompass/tree/main/configs) 中提供的其他示例。
|
||||||
|
|
||||||
|
## 配置评估任务
|
||||||
|
|
||||||
|
在 OpenCompass 中,每个评估任务由待评估的模型和数据集组成。评估的入口点是 `run.py`。用户可以通过命令行或配置文件选择要测试的模型和数据集。
|
||||||
|
|
||||||
|
对于对话模型
|
||||||
|
|
||||||
|
`````{tabs}
|
||||||
|
````{tab} 命令行(自定义 HF 模型)
|
||||||
|
|
||||||
|
对于 HuggingFace 模型,用户可以通过命令行直接设置模型参数,无需额外的配置文件。例如,对于 `internlm/internlm2-chat-1_8b` 模型,您可以使用以下命令进行评估:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
|
||||||
|
--hf-type chat \
|
||||||
|
--hf-path internlm/internlm2-chat-1_8b \
|
||||||
|
--debug
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,通过这种方式,OpenCompass 一次只评估一个模型,而其他方式可以一次评估多个模型。
|
||||||
|
|
||||||
|
:::{dropdown} HF 模型完整参数列表
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
| 命令行参数 | 描述 | 样例数值 |
|
||||||
|
| --- | --- | --- |
|
||||||
|
| `--hf-type` | HuggingFace 模型类型,可选值为 `chat` 或 `base` | chat |
|
||||||
|
| `--hf-path` | HuggingFace 模型路径 | internlm/internlm2-chat-1_8b |
|
||||||
|
| `--model-kwargs` | 构建模型的参数 | device_map='auto' |
|
||||||
|
| `--tokenizer-path` | HuggingFace tokenizer 路径(如果与模型路径相同,可以省略) | internlm/internlm2-chat-1_8b |
|
||||||
|
| `--tokenizer-kwargs` | 构建 tokenizer 的参数 | padding_side='left' truncation='left' trust_remote_code=True |
|
||||||
|
| `--generation-kwargs` | 生成的参数 | do_sample=True top_k=50 top_p=0.95 |
|
||||||
|
| `--max-seq-len` | 模型可以接受的最大序列长度 | 2048 |
|
||||||
|
| `--max-out-len` | 生成的最大 token 数 | 100 |
|
||||||
|
| `--min-out-len` | 生成的最小 token 数 | 1 |
|
||||||
|
| `--batch-size` | 批量大小 | 64 |
|
||||||
|
| `--hf-num-gpus` | 运行一个模型实例所需的 GPU 数量 | 1 |
|
||||||
|
| `--stop-words` | 停用词列表 | '<\|im_end\|>' '<\|im_start\|>' |
|
||||||
|
| `--pad-token-id` | 填充 token 的 ID | 0 |
|
||||||
|
| `--peft-path` | (例如) LoRA 模型的路径 | internlm/internlm2-chat-1_8b |
|
||||||
|
| `--peft-kwargs` | (例如) 构建 LoRA 模型的参数 | trust_remote_code=True |
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{dropdown} 更复杂的命令样例
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
例如一个占用 2 卡进行测试的 Qwen1.5-14B-Chat, 开启数据采样,模型的命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --datasets demo_gsm8k_chat_gen demo_math_chat_gen \
|
||||||
|
--hf-type chat \
|
||||||
|
--hf-path Qwen/Qwen1.5-14B-Chat \
|
||||||
|
--max-out-len 1024 \
|
||||||
|
--min-out-len 1 \
|
||||||
|
--hf-num-gpus 2 \
|
||||||
|
--generation-kwargs do_sample=True temperature=0.6 \
|
||||||
|
--stop-words '<|im_end|>' '<|im_start|>' \
|
||||||
|
--debug
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
````
|
||||||
|
````{tab} 命令行
|
||||||
|
|
||||||
|
用户可以使用 `--models` 和 `--datasets` 结合想测试的模型和数据集。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--models hf_internlm2_chat_1_8b hf_qwen2_1_5b_instruct \
|
||||||
|
--datasets demo_gsm8k_chat_gen demo_math_chat_gen \
|
||||||
|
--debug
|
||||||
|
```
|
||||||
|
|
||||||
|
模型和数据集的配置文件预存于 `configs/models` 和 `configs/datasets` 中。用户可以使用 `tools/list_configs.py` 查看或过滤当前可用的模型和数据集配置。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 列出所有配置
|
||||||
|
python tools/list_configs.py
|
||||||
|
# 列出与llama和mmlu相关的所有配置
|
||||||
|
python tools/list_configs.py llama mmlu
|
||||||
|
```
|
||||||
|
|
||||||
|
:::{dropdown} 关于 `list_configs`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
运行 `python tools/list_configs.py llama mmlu` 将产生如下输出:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-----------------+-----------------------------------+
|
||||||
|
| Model | Config Path |
|
||||||
|
|-----------------+-----------------------------------|
|
||||||
|
| hf_llama2_13b | configs/models/hf_llama2_13b.py |
|
||||||
|
| hf_llama2_70b | configs/models/hf_llama2_70b.py |
|
||||||
|
| ... | ... |
|
||||||
|
+-----------------+-----------------------------------+
|
||||||
|
+-------------------+---------------------------------------------------+
|
||||||
|
| Dataset | Config Path |
|
||||||
|
|-------------------+---------------------------------------------------|
|
||||||
|
| cmmlu_gen | configs/datasets/cmmlu/cmmlu_gen.py |
|
||||||
|
| cmmlu_gen_ffe7c0 | configs/datasets/cmmlu/cmmlu_gen_ffe7c0.py |
|
||||||
|
| ... | ... |
|
||||||
|
+-------------------+---------------------------------------------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
用户可以使用第一列中的名称作为 `python run.py` 中 `--models` 和 `--datasets` 的输入参数。对于数据集,同一名称的不同后缀通常表示其提示或评估方法不同。
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{dropdown} 没有列出的模型?
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
如果您想评估其他模型,请查看 “命令行(自定义 HF 模型)”选项卡,了解无需配置文件自定义 HF 模型的方法,或 “配置文件”选项卡,了解准备模型配置的通用方法。
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
````
|
||||||
|
````{tab} 配置文件
|
||||||
|
|
||||||
|
除了通过命令行配置实验外,OpenCompass 还允许用户在配置文件中编写实验的完整配置,并通过 `run.py` 直接运行它。配置文件是以 Python 格式组织的,并且必须包括 `datasets` 和 `models` 字段。
|
||||||
|
|
||||||
|
本次测试配置在 [configs/eval_chat_demo.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_chat_demo.py) 中。此配置通过 [继承机制](../user_guides/config.md#继承机制) 引入所需的数据集和模型配置,并以所需格式组合 `datasets` 和 `models` 字段。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.demo.demo_gsm8k_chat_gen import gsm8k_datasets
|
||||||
|
from .datasets.demo.demo_math_chat_gen import math_datasets
|
||||||
|
from .models.qwen.hf_qwen2_1_5b_instruct import models as hf_qwen2_1_5b_instruct_models
|
||||||
|
from .models.hf_internlm.hf_internlm2_chat_1_8b import models as hf_internlm2_chat_1_8b_models
|
||||||
|
|
||||||
|
datasets = gsm8k_datasets + math_datasets
|
||||||
|
models = hf_qwen2_1_5b_instruct_models + hf_internlm2_chat_1_8b_models
|
||||||
|
```
|
||||||
|
|
||||||
|
运行任务时,我们只需将配置文件的路径传递给 `run.py`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_chat_demo.py --debug
|
||||||
|
```
|
||||||
|
|
||||||
|
:::{dropdown} 关于 `models`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
OpenCompass 提供了一系列预定义的模型配置,位于 `configs/models` 下。以下是与 [InternLM2-Chat-1.8B](https://github.com/open-compass/opencompass/blob/main/configs/models/hf_internlm/hf_internlm2_chat_1_8b.py)(`configs/models/hf_internlm/hf_internlm2_chat_1_8b.py`)相关的配置片段:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 使用 `HuggingFacewithChatTemplate` 评估由 HuggingFace 的 `AutoModelForCausalLM` 支持的对话模型
|
||||||
|
from opencompass.models import HuggingFacewithChatTemplate
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFacewithChatTemplate,
|
||||||
|
abbr='internlm2-chat-1.8b-hf', # 模型的缩写
|
||||||
|
path='internlm/internlm2-chat-1_8b', # 模型的 HuggingFace 路径
|
||||||
|
max_out_len=1024, # 生成的最大 token 数
|
||||||
|
batch_size=8, # 批量大小
|
||||||
|
run_cfg=dict(num_gpus=1), # 该模型所需的 GPU 数量
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
使用配置时,我们可以通过命令行参数 `--models` 指定相关文件,或使用继承机制将模型配置导入到配置文件中的 `models` 列表中。
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
有关模型配置的更多信息,请参见 [准备模型](../user_guides/models.md)。
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{dropdown} 关于 `datasets`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
与模型类似,数据集的配置文件也提供在 `configs/datasets` 下。用户可以在命令行中使用 `--datasets`,或通过继承在配置文件中导入相关配置
|
||||||
|
|
||||||
|
下面是来自 `configs/eval_chat_demo.py` 的与数据集相关的配置片段:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base # 使用 mmengine.read_base() 读取基本配置
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# 直接从预设的数据集配置中读取所需的数据集配置
|
||||||
|
from .datasets.demo.demo_gsm8k_chat_gen import gsm8k_datasets # 读取 GSM8K 配置,使用 4-shot,基于生成式进行评估
|
||||||
|
from .datasets.demo.demo_math_chat_gen import math_datasets # 读取 MATH 配置,使用 0-shot,基于生成式进行评估
|
||||||
|
|
||||||
|
datasets = gsm8k_datasets + math_datasets # 最终的配置需要包含所需的评估数据集列表 'datasets'
|
||||||
|
```
|
||||||
|
|
||||||
|
数据集配置通常有两种类型:`ppl` 和 `gen`,分别指示使用的评估方法。其中 `ppl` 表示辨别性评估,`gen` 表示生成性评估。对话模型仅使用 `gen` 生成式评估。
|
||||||
|
|
||||||
|
此外,[configs/datasets/collections](https://github.com/open-compass/opencompass/blob/main/configs/datasets/collections) 收录了各种数据集集合,方便进行综合评估。OpenCompass 通常使用 [`chat_OC15.py`](https://github.com/open-compass/opencompass/blob/main/configs/dataset_collections/chat_OC15.py) 进行全面的模型测试。要复制结果,只需导入该文件,例如:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --models hf_internlm2_chat_1_8b --datasets chat_OC15 --debug
|
||||||
|
```
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
您可以从 [配置数据集](../user_guides/datasets.md) 中找到更多信息。
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
````
|
||||||
|
`````
|
||||||
|
|
||||||
|
对于基座模型
|
||||||
|
|
||||||
|
`````{tabs}
|
||||||
|
````{tab} 命令行(自定义 HF 模型)
|
||||||
|
|
||||||
|
对于 HuggingFace 模型,用户可以通过命令行直接设置模型参数,无需额外的配置文件。例如,对于 `internlm/internlm2-1_8b` 模型,您可以使用以下命令进行评估:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--datasets demo_gsm8k_base_gen demo_math_base_gen \
|
||||||
|
--hf-type base \
|
||||||
|
--hf-path internlm/internlm2-1_8b \
|
||||||
|
--debug
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,通过这种方式,OpenCompass 一次只评估一个模型,而其他方式可以一次评估多个模型。
|
||||||
|
|
||||||
|
:::{dropdown} 更复杂的命令样例
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
例如一个占用 2 卡进行测试的 Qwen1.5-14B, 开启数据采样,模型的命令如下:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py --datasets demo_gsm8k_base_gen demo_math_base_gen \
|
||||||
|
--hf-type chat \
|
||||||
|
--hf-path Qwen/Qwen1.5-14B \
|
||||||
|
--max-out-len 1024 \
|
||||||
|
--min-out-len 1 \
|
||||||
|
--hf-num-gpus 2 \
|
||||||
|
--generation-kwargs do_sample=True temperature=0.6 \
|
||||||
|
--debug
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
````
|
||||||
|
````{tab} 命令行
|
||||||
|
|
||||||
|
用户可以使用 `--models` 和 `--datasets` 结合想测试的模型和数据集。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py \
|
||||||
|
--models hf_internlm2_1_8b hf_qwen2_1_5b \
|
||||||
|
--datasets demo_gsm8k_base_gen demo_math_base_gen \
|
||||||
|
--debug
|
||||||
|
```
|
||||||
|
|
||||||
|
````
|
||||||
|
````{tab} 配置文件
|
||||||
|
|
||||||
|
除了通过命令行配置实验外,OpenCompass 还允许用户在配置文件中编写实验的完整配置,并通过 `run.py` 直接运行它。配置文件是以 Python 格式组织的,并且必须包括 `datasets` 和 `models` 字段。
|
||||||
|
|
||||||
|
本次测试配置在 [configs/eval_base_demo.py](https://github.com/open-compass/opencompass/blob/main/configs/eval_base_demo.py) 中。此配置通过 [继承机制](../user_guides/config.md#继承机制) 引入所需的数据集和模型配置,并以所需格式组合 `datasets` 和 `models` 字段。
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
from .datasets.demo.demo_gsm8k_base_gen import gsm8k_datasets
|
||||||
|
from .datasets.demo.demo_math_base_gen import math_datasets
|
||||||
|
from .models.qwen.hf_qwen2_1_5b import models as hf_qwen2_1_5b_models
|
||||||
|
from .models.hf_internlm.hf_internlm2_1_8b import models as hf_internlm2_1_8b_models
|
||||||
|
|
||||||
|
datasets = gsm8k_datasets + math_datasets
|
||||||
|
models = hf_qwen2_1_5b_models + hf_internlm2_1_8b_models
|
||||||
|
```
|
||||||
|
|
||||||
|
运行任务时,我们只需将配置文件的路径传递给 `run.py`:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_base_demo.py --debug
|
||||||
|
```
|
||||||
|
|
||||||
|
:::{dropdown} 关于 `models`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
OpenCompass 提供了一系列预定义的模型配置,位于 `configs/models` 下。以下是与 [InternLM2-1.8B](https://github.com/open-compass/opencompass/blob/main/configs/models/hf_internlm/hf_internlm2_1_8b.py)(`configs/models/hf_internlm/hf_internlm2_1_8b.py`)相关的配置片段:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# 使用 `HuggingFaceBaseModel` 评估由 HuggingFace 的 `AutoModelForCausalLM` 支持的基座模型
|
||||||
|
from opencompass.models import HuggingFaceBaseModel
|
||||||
|
|
||||||
|
models = [
|
||||||
|
dict(
|
||||||
|
type=HuggingFaceBaseModel,
|
||||||
|
abbr='internlm2-1.8b-hf', # 模型的缩写
|
||||||
|
path='internlm/internlm2-1_8b', # 模型的 HuggingFace 路径
|
||||||
|
max_out_len=1024, # 生成的最大 token 数
|
||||||
|
batch_size=8, # 批量大小
|
||||||
|
run_cfg=dict(num_gpus=1), # 该模型所需的 GPU 数量
|
||||||
|
)
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
使用配置时,我们可以通过命令行参数 `--models` 指定相关文件,或使用继承机制将模型配置导入到配置文件中的 `models` 列表中。
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
有关模型配置的更多信息,请参见 [准备模型](../user_guides/models.md)。
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{dropdown} 关于 `datasets`
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
|
||||||
|
与模型类似,数据集的配置文件也提供在 `configs/datasets` 下。用户可以在命令行中使用 `--datasets`,或通过继承在配置文件中导入相关配置
|
||||||
|
|
||||||
|
下面是来自 `configs/eval_base_demo.py` 的与数据集相关的配置片段:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from mmengine.config import read_base # 使用 mmengine.read_base() 读取基本配置
|
||||||
|
|
||||||
|
with read_base():
|
||||||
|
# 直接从预设的数据集配置中读取所需的数据集配置
|
||||||
|
from .datasets.demo.demo_gsm8k_base_gen import gsm8k_datasets # 读取 GSM8K 配置,使用 4-shot,基于生成式进行评估
|
||||||
|
from .datasets.demo.demo_math_base_gen import math_datasets # 读取 MATH 配置,使用 0-shot,基于生成式进行评估
|
||||||
|
|
||||||
|
datasets = gsm8k_datasets + math_datasets # 最终的配置需要包含所需的评估数据集列表 'datasets'
|
||||||
|
```
|
||||||
|
|
||||||
|
数据集配置通常有两种类型:`ppl` 和 `gen`,分别指示使用的评估方法。其中 `ppl` 表示判别性评估,`gen` 表示生成性评估。基座模型对于 "选择题" 类型的数据集会使用 `ppl` 判别性评估,其他则会使用 `gen` 生成式评估。
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
您可以从 [配置数据集](../user_guides/datasets.md) 中找到更多信息。
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
````
|
||||||
|
`````
|
||||||
|
|
||||||
|
```{warning}
|
||||||
|
OpenCompass 通常假定运行环境网络是可用的。如果您遇到网络问题或希望在离线环境中运行 OpenCompass,请参阅 [FAQ - 网络 - Q1](./faq.md#网络) 寻求解决方案。
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来的部分将使用基于配置的方法,评测对话模型,作为示例来解释其他特征。
|
||||||
|
|
||||||
|
## 启动评估
|
||||||
|
|
||||||
|
由于 OpenCompass 默认并行启动评估过程,我们可以在第一次运行时以 `--debug` 模式启动评估,并检查是否存在问题。包括在前述的所有文档中,我们都使用了 `--debug` 开关。在 `--debug` 模式下,任务将按顺序执行,并实时打印输出。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_chat_demo.py -w outputs/demo --debug
|
||||||
|
```
|
||||||
|
|
||||||
|
对话默写 'internlm/internlm2-chat-1_8b' 和 'Qwen/Qwen2-1.5B-Instruct' 将在首次运行期间从 HuggingFace 自动下载。
|
||||||
|
如果一切正常,您应该看到屏幕上显示 “Starting inference process”,且进度条开始前进:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
[2023-07-12 18:23:55,076] [opencompass.openicl.icl_inferencer.icl_gen_inferencer] [INFO] Starting inference process...
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,您可以按 `Ctrl+C` 中断程序,并以正常模式运行以下命令:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
python run.py configs/eval_chat_demo.py -w outputs/demo
|
||||||
|
```
|
||||||
|
|
||||||
|
在正常模式下,评估任务将在后台并行执行,其输出将被重定向到输出目录 `outputs/demo/{TIMESTAMP}`。前端的进度条只指示已完成任务的数量,而不考虑其成功或失败。**任何后端任务失败都只会在终端触发警告消息。**
|
||||||
|
|
||||||
|
:::{dropdown} `run.py` 中的更多参数
|
||||||
|
:animate: fade-in-slide-down
|
||||||
|
以下是与评估相关的一些参数,可以帮助您根据环境配置更有效的推理任务:
|
||||||
|
|
||||||
|
- `-w outputs/demo`:保存评估日志和结果的工作目录。在这种情况下,实验结果将保存到 `outputs/demo/{TIMESTAMP}`。
|
||||||
|
- `-r {TIMESTAMP/latest}`:重用现有的推理结果,并跳过已完成的任务。如果后面跟随时间戳,将重用工作空间路径下该时间戳的结果;若给定 latest 或干脆不指定,将重用指定工作空间路径下的最新结果。
|
||||||
|
- `--mode all`:指定任务的特定阶段。
|
||||||
|
- all:(默认)执行完整评估,包括推理和评估。
|
||||||
|
- infer:在每个数据集上执行推理。
|
||||||
|
- eval:根据推理结果进行评估。
|
||||||
|
- viz:仅显示评估结果。
|
||||||
|
- `--max-num-workers 8`:并行任务的最大数量。在如 Slurm 之类的分布式环境中,此参数指定提交任务的最大数量。在本地环境中,它指定同时执行的任务的最大数量。请注意,实际的并行任务数量取决于可用的 GPU 资源,可能不等于这个数字。
|
||||||
|
|
||||||
|
如果您不是在本地机器上执行评估,而是使用 Slurm 集群,您可以指定以下参数:
|
||||||
|
|
||||||
|
- `--slurm`:在集群上使用 Slurm 提交任务。
|
||||||
|
- `--partition(-p) my_part`:Slurm 集群分区。
|
||||||
|
- `--retry 2`:失败任务的重试次数。
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
入口还支持将任务提交到阿里巴巴深度学习中心(DLC),以及更多自定义评估策略。请参考 [评测任务发起](../user_guides/experimentation.md#评测任务发起) 了解详情。
|
||||||
|
```
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
## 可视化评估结果
|
||||||
|
|
||||||
|
评估完成后,评估结果表格将打印如下:
|
||||||
|
|
||||||
|
```text
|
||||||
|
dataset version metric mode qwen2-1.5b-instruct-hf internlm2-chat-1.8b-hf
|
||||||
|
---------- --------- -------- ------ ------------------------ ------------------------
|
||||||
|
demo_gsm8k 1d7fe4 accuracy gen 56.25 32.81
|
||||||
|
demo_math 393424 accuracy gen 18.75 14.06
|
||||||
|
```
|
||||||
|
|
||||||
|
所有运行输出将定向到 `outputs/demo/` 目录,结构如下:
|
||||||
|
|
||||||
|
```text
|
||||||
|
outputs/default/
|
||||||
|
├── 20200220_120000
|
||||||
|
├── 20230220_183030 # 每个实验一个文件夹
|
||||||
|
│ ├── configs # 用于记录的已转储的配置文件。如果在同一个实验文件夹中重新运行了不同的实验,可能会保留多个配置
|
||||||
|
│ ├── logs # 推理和评估阶段的日志文件
|
||||||
|
│ │ ├── eval
|
||||||
|
│ │ └── infer
|
||||||
|
│ ├── predictions # 每个任务的推理结果
|
||||||
|
│ ├── results # 每个任务的评估结果
|
||||||
|
│ └── summary # 单个实验的汇总评估结果
|
||||||
|
├── ...
|
||||||
|
```
|
||||||
|
|
||||||
|
打印评测结果的过程可被进一步定制化,用于输出一些数据集的平均分 (例如 MMLU, C-Eval 等)。
|
||||||
|
|
||||||
|
关于评测结果输出的更多介绍可阅读 [结果展示](../user_guides/summarizer.md)。
|
||||||
|
|
||||||
|
## 更多教程
|
||||||
|
|
||||||
|
想要更多了解 OpenCompass, 可以点击下列链接学习。
|
||||||
|
|
||||||
|
- [配置数据集](../user_guides/datasets.md)
|
||||||
|
- [准备模型](../user_guides/models.md)
|
||||||
|
- [任务运行和监控](../user_guides/experimentation.md)
|
||||||
|
- [如何调 Prompt](../prompt/overview.md)
|
||||||
|
- [结果展示](../user_guides/summarizer.md)
|
||||||
|
- [学习配置文件](../user_guides/config.md)
|
||||||
|
|
@ -0,0 +1,97 @@
|
||||||
|
欢迎来到 OpenCompass 中文教程!
|
||||||
|
==========================================
|
||||||
|
|
||||||
|
OpenCompass 上手路线
|
||||||
|
-------------------------------
|
||||||
|
|
||||||
|
为了用户能够快速上手,我们推荐以下流程:
|
||||||
|
|
||||||
|
- 对于想要使用 OpenCompass 的用户,我们推荐先阅读 开始你的第一步_ 部分来设置环境,并启动一个迷你实验熟悉流程。
|
||||||
|
|
||||||
|
- 对于一些基础使用,我们建议用户阅读 教程_ 。
|
||||||
|
|
||||||
|
- 如果您想调整提示词(prompt),您可以浏览 提示词_ 。
|
||||||
|
|
||||||
|
- 若您想进行更多模块的自定义,例如增加数据集和模型,我们提供了 进阶教程_ 。
|
||||||
|
|
||||||
|
- 还有更多实用的工具,如提示词预览、飞书机器人上报等功能,我们同样提供了 工具_ 教程。
|
||||||
|
|
||||||
|
|
||||||
|
我们始终非常欢迎用户的 PRs 和 Issues 来完善 OpenCompass!
|
||||||
|
|
||||||
|
.. _开始你的第一步:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: 开始你的第一步
|
||||||
|
|
||||||
|
get_started/installation.md
|
||||||
|
get_started/quick_start.md
|
||||||
|
get_started/faq.md
|
||||||
|
|
||||||
|
.. _教程:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: 教程
|
||||||
|
|
||||||
|
user_guides/framework_overview.md
|
||||||
|
user_guides/config.md
|
||||||
|
user_guides/datasets.md
|
||||||
|
user_guides/models.md
|
||||||
|
user_guides/evaluation.md
|
||||||
|
user_guides/experimentation.md
|
||||||
|
user_guides/metrics.md
|
||||||
|
user_guides/deepseek_r1.md
|
||||||
|
|
||||||
|
.. _提示词:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: 提示词
|
||||||
|
|
||||||
|
prompt/overview.md
|
||||||
|
prompt/prompt_template.md
|
||||||
|
prompt/meta_template.md
|
||||||
|
prompt/chain_of_thought.md
|
||||||
|
|
||||||
|
.. _进阶教程:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: 进阶教程
|
||||||
|
|
||||||
|
advanced_guides/new_dataset.md
|
||||||
|
advanced_guides/custom_dataset.md
|
||||||
|
advanced_guides/new_model.md
|
||||||
|
advanced_guides/evaluation_lmdeploy.md
|
||||||
|
advanced_guides/accelerator_intro.md
|
||||||
|
advanced_guides/math_verify.md
|
||||||
|
advanced_guides/llm_judge.md
|
||||||
|
advanced_guides/code_eval.md
|
||||||
|
advanced_guides/code_eval_service.md
|
||||||
|
advanced_guides/subjective_evaluation.md
|
||||||
|
advanced_guides/persistence.md
|
||||||
|
|
||||||
|
.. _工具:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: 工具
|
||||||
|
|
||||||
|
tools.md
|
||||||
|
|
||||||
|
.. _数据集列表:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: 数据集列表
|
||||||
|
|
||||||
|
dataset_statistics.md
|
||||||
|
|
||||||
|
.. _其他说明:
|
||||||
|
.. toctree::
|
||||||
|
:maxdepth: 1
|
||||||
|
:caption: 其他说明
|
||||||
|
|
||||||
|
notes/contribution_guide.md
|
||||||
|
|
||||||
|
索引与表格
|
||||||
|
==================
|
||||||
|
|
||||||
|
* :ref:`genindex`
|
||||||
|
* :ref:`search`
|
||||||
|
|
@ -0,0 +1,167 @@
|
||||||
|
# 为 OpenCompass 做贡献
|
||||||
|
|
||||||
|
- [为 OpenCompass 做贡献](#为-opencompass-做贡献)
|
||||||
|
- [什么是拉取请求?](#什么是拉取请求)
|
||||||
|
- [基本的工作流:](#基本的工作流)
|
||||||
|
- [具体步骤](#具体步骤)
|
||||||
|
- [1. 获取最新的代码库](#1-获取最新的代码库)
|
||||||
|
- [2. 从 `main` 分支创建一个新的开发分支](#2-从-main-分支创建一个新的开发分支)
|
||||||
|
- [3. 提交你的修改](#3-提交你的修改)
|
||||||
|
- [4. 推送你的修改到复刻的代码库,并创建一个拉取请求](#4-推送你的修改到复刻的代码库并创建一个拉取请求)
|
||||||
|
- [5. 讨论并评审你的代码](#5-讨论并评审你的代码)
|
||||||
|
- [6. `拉取请求`合并之后删除该分支](#6-拉取请求合并之后删除该分支)
|
||||||
|
- [代码风格](#代码风格)
|
||||||
|
- [Python](#python)
|
||||||
|
- [关于提交数据集](#关于提交数据集)
|
||||||
|
|
||||||
|
感谢你对于OpenCompass的贡献!我们欢迎各种形式的贡献,包括但不限于以下几点。
|
||||||
|
|
||||||
|
- 修改错别字或修复bug
|
||||||
|
- 添加文档或将文档翻译成其它语言
|
||||||
|
- 添加新功能和组件
|
||||||
|
|
||||||
|
## 什么是拉取请求?
|
||||||
|
|
||||||
|
`拉取请求` (Pull Request), [GitHub 官方文档](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/about-pull-requests)定义如下。
|
||||||
|
|
||||||
|
```
|
||||||
|
拉取请求是一种通知机制。你修改了他人的代码,将你的修改通知原来作者,希望他合并你的修改。
|
||||||
|
```
|
||||||
|
|
||||||
|
## 基本的工作流:
|
||||||
|
|
||||||
|
1. 获取最新的代码库
|
||||||
|
2. 从最新的 `main` 分支创建分支进行开发
|
||||||
|
3. 提交修改 ([不要忘记使用 pre-commit hooks!](#3-提交你的修改))
|
||||||
|
4. 推送你的修改并创建一个 `拉取请求`
|
||||||
|
5. 讨论、审核代码
|
||||||
|
6. 将开发分支合并到 `main` 分支
|
||||||
|
|
||||||
|
## 具体步骤
|
||||||
|
|
||||||
|
### 1. 获取最新的代码库
|
||||||
|
|
||||||
|
- 当你第一次提 PR 时
|
||||||
|
|
||||||
|
复刻 OpenCompass 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮即可
|
||||||
|

|
||||||
|
|
||||||
|
克隆复刻的代码库到本地
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git clone git@github.com:XXX/opencompass.git
|
||||||
|
```
|
||||||
|
|
||||||
|
添加原代码库为上游代码库
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git remote add upstream git@github.com:InternLM/opencompass.git
|
||||||
|
```
|
||||||
|
|
||||||
|
- 从第二个 PR 起
|
||||||
|
|
||||||
|
检出本地代码库的主分支,然后从最新的原代码库的主分支拉取更新。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git checkout main
|
||||||
|
git pull upstream main
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. 从 `main` 分支创建一个新的开发分支
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git checkout main -b branchname
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3. 提交你的修改
|
||||||
|
|
||||||
|
- 如果你是第一次尝试贡献,请在 OpenCompass 的目录下安装并初始化 pre-commit hooks。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install -U pre-commit
|
||||||
|
pre-commit install
|
||||||
|
```
|
||||||
|
|
||||||
|
````{tip}
|
||||||
|
对于中国地区的用户,由于网络原因,安装 pre-commit hook 可能会失败。可以尝试以下命令切换为国内镜像源:
|
||||||
|
```bash
|
||||||
|
pre-commit install -c .pre-commit-config-zh-cn.yaml
|
||||||
|
pre-commit run –all-files -c .pre-commit-config-zh-cn.yaml
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
- 提交修改。在每次提交前,pre-commit hooks 都会被触发并规范化你的代码格式。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# coding
|
||||||
|
git add [files]
|
||||||
|
git commit -m 'messages'
|
||||||
|
```
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
有时你的文件可能会在提交时被 pre-commit hooks 自动修改。这时请重新添加并提交修改后的文件。
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4. 推送你的修改到复刻的代码库,并创建一个拉取请求
|
||||||
|
|
||||||
|
- 推送当前分支到远端复刻的代码库
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git push origin branchname
|
||||||
|
```
|
||||||
|
|
||||||
|
- 创建一个拉取请求
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
- 修改拉取请求信息模板,描述修改原因和修改内容。还可以在 PR 描述中,手动关联到相关的议题 (issue),(更多细节,请参考[官方文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))。
|
||||||
|
|
||||||
|
- 你同样可以把 PR 关联给相关人员进行评审。
|
||||||
|
|
||||||
|
### 5. 讨论并评审你的代码
|
||||||
|
|
||||||
|
- 根据评审人员的意见修改代码,并推送修改
|
||||||
|
|
||||||
|
### 6. `拉取请求`合并之后删除该分支
|
||||||
|
|
||||||
|
- 在 PR 合并之后,你就可以删除该分支了。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git branch -d branchname # 删除本地分支
|
||||||
|
git push origin --delete branchname # 删除远程分支
|
||||||
|
```
|
||||||
|
|
||||||
|
## 代码风格
|
||||||
|
|
||||||
|
### Python
|
||||||
|
|
||||||
|
我们采用[PEP8](https://www.python.org/dev/peps/pep-0008/)作为首选的代码风格。
|
||||||
|
|
||||||
|
我们使用以下工具进行linting和格式化:
|
||||||
|
|
||||||
|
- [flake8](https://github.com/PyCQA/flake8): 一个围绕一些linter工具的封装器。
|
||||||
|
- [isort](https://github.com/timothycrosley/isort): 一个用于排序Python导入的实用程序。
|
||||||
|
- [yapf](https://github.com/google/yapf): 一个Python文件的格式化器。
|
||||||
|
- [codespell](https://github.com/codespell-project/codespell): 一个Python实用程序,用于修复文本文件中常见的拼写错误。
|
||||||
|
- [mdformat](https://github.com/executablebooks/mdformat): mdformat是一个有明确定义的Markdown格式化程序,可以用来在Markdown文件中强制执行一致的样式。
|
||||||
|
- [docformatter](https://github.com/myint/docformatter): 一个格式化docstring的工具。
|
||||||
|
|
||||||
|
yapf和isort的样式配置可以在[setup.cfg](https://github.com/OpenCompass/blob/main/setup.cfg)中找到。
|
||||||
|
|
||||||
|
## 关于贡献测试数据集
|
||||||
|
|
||||||
|
- 提交测试数据集
|
||||||
|
- 请在代码中实现自动下载数据集的逻辑;或者在 PR 中提供获取数据集的方法,OpenCompass 的维护者会跟进处理。如果数据集尚未公开,亦请注明。
|
||||||
|
- 提交数据配置文件
|
||||||
|
- 在数据配置同级目录下提供 README,README 中的内容应该包含,但不局限于:
|
||||||
|
- 该数据集的简单说明
|
||||||
|
- 该数据集的官方链接
|
||||||
|
- 该数据集的一些测试样例
|
||||||
|
- 该数据集在相关模型上的评测结果
|
||||||
|
- 该数据集的引用
|
||||||
|
- (可选) 数据集的 summarizer
|
||||||
|
- (可选) 如果测试过程无法通过简单拼接数据集和模型配置文件的方式来实现的话,还需要提供进行测试过程的配置文件
|
||||||
|
- (可选) 如果需要,请在文档相关位置处添加该数据集的说明。这在辅助用户理解该测试方案是非常必要的,可参考 OpenCompass 中该类型的文档:
|
||||||
|
- [循环评测](../advanced_guides/circular_eval.md)
|
||||||
|
- [代码评测](../advanced_guides/code_eval.md)
|
||||||
|
- [污染评估](../advanced_guides/contamination_eval.md)
|
||||||
|
|
@ -0,0 +1,40 @@
|
||||||
|
# 新闻
|
||||||
|
|
||||||
|
- **\[2024.05.08\]** 我们支持了以下四个MoE模型的评测配置文件: [Mixtral-8x22B-v0.1](configs/models/mixtral/hf_mixtral_8x22b_v0_1.py), [Mixtral-8x22B-Instruct-v0.1](configs/models/mixtral/hf_mixtral_8x22b_instruct_v0_1.py), [Qwen1.5-MoE-A2.7B](configs/models/qwen/hf_qwen1_5_moe_a2_7b.py), [Qwen1.5-MoE-A2.7B-Chat](configs/models/qwen/hf_qwen1_5_moe_a2_7b_chat.py) 。欢迎试用!
|
||||||
|
- **\[2024.04.30\]** 我们支持了计算模型在给定[数据集](configs/datasets/llm_compression/README.md)上的压缩率(Bits per Character)的评测方法([官方文献](https://github.com/hkust-nlp/llm-compression-intelligence))。欢迎试用[llm-compression](configs/eval_llm_compression.py)评测集! 🔥🔥🔥
|
||||||
|
- **\[2024.04.26\]** 我们报告了典型LLM在常用基准测试上的表现,欢迎访问[文档](https://opencompass.readthedocs.io/zh-cn/latest/user_guides/corebench.html)以获取更多信息!🔥🔥🔥.
|
||||||
|
- **\[2024.04.26\]** 我们废弃了 OpenCompass 进行多模态大模型评测的功能,相关功能转移至 [VLMEvalKit](https://github.com/open-compass/VLMEvalKit),推荐使用!🔥🔥🔥.
|
||||||
|
- **\[2024.04.26\]** 我们支持了 [ArenaHard评测](configs/eval_subjective_arena_hard.py) 欢迎试用!🔥🔥🔥.
|
||||||
|
- **\[2024.04.22\]** 我们支持了 [LLaMA3](configs/models/hf_llama/hf_llama3_8b.py) 和 [LLaMA3-Instruct](configs/models/hf_llama/hf_llama3_8b_instruct.py) 的评测,欢迎试用!🔥🔥🔥.
|
||||||
|
- **\[2024.02.29\]** 我们支持了MT-Bench、AlpacalEval和AlignBench,更多信息可以在[这里](https://opencompass.readthedocs.io/en/latest/advanced_guides/subjective_evaluation.html)找到。
|
||||||
|
- **\[2024.01.30\]** 我们发布了OpenCompass 2.0。更多信息,请访问[CompassKit](https://github.com/open-compass)、[CompassHub](https://hub.opencompass.org.cn/home)和[CompassRank](https://rank.opencompass.org.cn/home)。
|
||||||
|
- **\[2024.01.17\]** 我们支持了 [InternLM2](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py) 和 [InternLM2-Chat](https://github.com/open-compass/opencompass/blob/main/configs/eval_internlm2_chat_keyset.py) 的相关评测,InternLM2 在这些测试中表现出非常强劲的性能,欢迎试用!.
|
||||||
|
- **\[2024.01.17\]** 我们支持了多根针版本的大海捞针测试,更多信息见[这里](https://opencompass.readthedocs.io/zh-cn/latest/advanced_guides/needleinahaystack_eval.html#id8).
|
||||||
|
- **\[2023.12.28\]** 我们支持了对使用[LLaMA2-Accessory](https://github.com/Alpha-VLLM/LLaMA2-Accessory)(一款强大的LLM开发工具箱)开发的所有模型的无缝评估!
|
||||||
|
- **\[2023.12.22\]** 我们开源了[T-Eval](https://github.com/open-compass/T-Eval)用于评测大语言模型工具调用能力。欢迎访问T-Eval的官方[Leaderboard](https://open-compass.github.io/T-Eval/leaderboard.html)获取更多信息!
|
||||||
|
- **\[2023.12.10\]** 我们开源了多模评测框架 [VLMEvalKit](https://github.com/open-compass/VLMEvalKit),目前已支持 20+ 个多模态大模型与包括 MMBench 系列在内的 7 个多模态评测集.
|
||||||
|
- **\[2023.12.10\]** 我们已经支持了Mistral AI的MoE模型 **Mixtral-8x7B-32K**。欢迎查阅[MixtralKit](https://github.com/open-compass/MixtralKit)以获取更多关于推理和评测的详细信息.
|
||||||
|
- **\[2023.11.22\]** 我们已经支持了多个于API的模型,包括**百度、字节跳动、华为、360**。欢迎查阅[模型](https://opencompass.readthedocs.io/en/latest/user_guides/models.html)部分以获取更多详细信息。
|
||||||
|
- **\[2023.11.20\]** 感谢[helloyongyang](https://github.com/helloyongyang)支持使用[LightLLM](https://github.com/ModelTC/lightllm)作为后端进行评估。欢迎查阅[使用LightLLM进行评估](https://opencompass.readthedocs.io/en/latest/advanced_guides/evaluation_lightllm.html)以获取更多详细信息。
|
||||||
|
- **\[2023.11.13\]** 我们很高兴地宣布发布 OpenCompass v0.1.8 版本。此版本支持本地加载评估基准,从而无需连接互联网。请注意,随着此更新的发布,**您需要重新下载所有评估数据集**,以确保结果准确且最新。
|
||||||
|
- **\[2023.11.06\]** 我们已经支持了多个基于 API 的模型,包括ChatGLM Pro@智谱清言、ABAB-Chat@MiniMax 和讯飞。欢迎查看 [模型](https://opencompass.readthedocs.io/en/latest/user_guides/models.html) 部分以获取更多详细信息。
|
||||||
|
- **\[2023.10.24\]** 我们发布了一个全新的评测集,BotChat,用于评估大语言模型的多轮对话能力,欢迎查看 [BotChat](https://github.com/open-compass/BotChat) 获取更多信息.
|
||||||
|
- **\[2023.09.26\]** 我们在评测榜单上更新了[Qwen](https://github.com/QwenLM/Qwen), 这是目前表现最好的开源模型之一, 欢迎访问[官方网站](https://opencompass.org.cn)获取详情.
|
||||||
|
- **\[2023.09.20\]** 我们在评测榜单上更新了[InternLM-20B](https://github.com/InternLM/InternLM), 欢迎访问[官方网站](https://opencompass.org.cn)获取详情.
|
||||||
|
- **\[2023.09.19\]** 我们在评测榜单上更新了WeMix-LLaMA2-70B/Phi-1.5-1.3B, 欢迎访问[官方网站](https://opencompass.org.cn)获取详情.
|
||||||
|
- **\[2023.09.18\]** 我们发布了[长文本评测指引](docs/zh_cn/advanced_guides/longeval.md).
|
||||||
|
- **\[2023.09.08\]** 我们在评测榜单上更新了Baichuan-2/Tigerbot-2/Vicuna-v1.5, 欢迎访问[官方网站](https://opencompass.org.cn)获取详情。
|
||||||
|
- **\[2023.09.06\]** 欢迎 [**Baichuan2**](https://github.com/baichuan-inc/Baichuan2) 团队采用OpenCompass对模型进行系统评估。我们非常感谢社区在提升LLM评估的透明度和可复现性上所做的努力。
|
||||||
|
- **\[2023.09.02\]** 我们加入了[Qwen-VL](https://github.com/QwenLM/Qwen-VL)的评测支持。
|
||||||
|
- **\[2023.08.25\]** 欢迎 [**TigerBot**](https://github.com/TigerResearch/TigerBot) 团队采用OpenCompass对模型进行系统评估。我们非常感谢社区在提升LLM评估的透明度和可复现性上所做的努力。
|
||||||
|
- **\[2023.08.21\]** [**Lagent**](https://github.com/InternLM/lagent) 正式发布,它是一个轻量级、开源的基于大语言模型的智能体(agent)框架。我们正与Lagent团队紧密合作,推进支持基于Lagent的大模型工具能力评测 !
|
||||||
|
- **\[2023.08.18\]** OpenCompass现已支持**多模态评测**,支持10+多模态评测数据集,包括 **MMBench, SEED-Bench, COCO-Caption, Flickr-30K, OCR-VQA, ScienceQA** 等. 多模态评测榜单即将上线,敬请期待!
|
||||||
|
- **\[2023.08.18\]** [数据集页面](https://opencompass.org.cn/dataset-detail/MMLU) 现已在OpenCompass官网上线,欢迎更多社区评测数据集加入OpenCompass !
|
||||||
|
- **\[2023.08.11\]** 官网榜单上新增了[模型对比](https://opencompass.org.cn/model-compare/GPT-4,ChatGPT,LLaMA-2-70B,LLaMA-65B)功能,希望该功能可以协助提供更多发现!
|
||||||
|
- **\[2023.08.11\]** 新增了 [LEval](https://github.com/OpenLMLab/LEval) 评测支持.
|
||||||
|
- **\[2023.08.10\]** OpenCompass 现已适配 [LMDeploy](https://github.com/InternLM/lmdeploy). 请参考 [评测指南](https://opencompass.readthedocs.io/zh_CN/latest/advanced_guides/evaluation_lmdeploy.html) 对 **Turbomind** 加速后的模型进行评估.
|
||||||
|
- **\[2023.08.10\]** [Qwen-7B](https://github.com/QwenLM/Qwen-7B) 和 [XVERSE-13B](https://github.com/xverse-ai/XVERSE-13B)的评测结果已更新在 OpenCompass [大语言模型评测榜单](https://opencompass.org.cn/leaderboard-llm)!
|
||||||
|
- **\[2023.08.09\]** 更新更多评测数据集(**CMMLU, TydiQA, SQuAD2.0, DROP**) ,请登录 [大语言模型评测榜单](https://opencompass.org.cn/leaderboard-llm) 查看更多结果! 欢迎添加你的评测数据集到OpenCompass.
|
||||||
|
- **\[2023.08.07\]** 新增了 [MMBench 评测脚本](tools/eval_mmbench.py) 以支持用户自行获取 [MMBench](https://opencompass.org.cn/MMBench)-dev 的测试结果.
|
||||||
|
- **\[2023.08.05\]** [GPT-4](https://openai.com/gpt-4) 的评测结果已更新在 OpenCompass [大语言模型评测榜单](https://opencompass.org.cn/leaderboard-llm)!
|
||||||
|
- **\[2023.07.27\]** 新增了 [CMMLU](https://github.com/haonan-li/CMMLU)! 欢迎更多的数据集加入 OpenCompass.
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue