15 KiB
模型思考效率评测最佳实践
随着大语言模型的迅速发展,模型的推理能力得到了显著提升。特别是长推理模型(Long Reasoning Models),如OpenAI的o1、QwQ-32B、DeepSeek-R1-671B和Kimi K1.5等,因其展现出类似人类的深度思考能力而备受关注。这些模型通过长时间推理(Inference-Time Scaling),能够在解码阶段不断思考并尝试新的思路来得到正确的答案。
然而,随着研究的深入,科研人员发现这些模型在推理过程中存在两个极端问题:Underthinking(思考不足) 和Overthinking(过度思考) :
-
Underthinking(思考不足)1 现象指的是模型在推理过程中频繁地进行思路跳转,反复使用“alternatively”、“but wait”、“let me reconsider”等词,无法将注意力集中在一个正确的思路上并深入思考,从而得到错误答案。这种现象类似于人类的"注意力缺陷多动障碍",影响了模型的推理质量。
-
Overthinking(过度思考)2 现象则表现为模型在不必要的情况下生成过长的思维链,浪费了大量的计算资源。例如,对于简单的"2+3=?"这样的问题,某些长推理模型可能会消耗超过900个token来探索多种解题策略。尽管这种思维链策略对于复杂问题的解答非常有帮助,但在应对简单问题时,反复验证已有的答案和进行过于宽泛的探索显然是一种计算资源的浪费。3
这两种现象都凸显了一个关键问题:如何在保证答案质量的同时,提高模型的思考效率?换句话说,我们希望模型能够在尽可能短的输出中获取正确的答案。而在本最佳实践中,我们将在使用MATH-500数据集上衡量DeepSeek-R1-Distill-Qwen-7B等模型的思考效率,从模型推理token数、首次正确token数、剩余反思token数、token效率、子思维链数量和准确率六个维度来评估模型的表现,让我们一起开始吧。
安装依赖
首先,安装EvalScope模型评估框架:
pip install 'evalscope' -U
评测模型
下面我们将开始正式评测,整个过程分为两个主要步骤:
- 模型推理评估:使用EvalScope框架让模型在MATH-500数据集上进行推理。该数据集包含500个数学问题,每个问题由一个数学表达式和对应答案组成,难度从1级(简单)到5级(复杂)不等。这一步将获得模型对每个问题的推理结果,以及整体答题正确率。
- 模型思考效率评测:使用EvalScope框架中的EvalThink组件对模型的输出进行深入分析,从token效率、模型思考长度、子思维链数量等维度进一步评测模型的思考效率。
模型推理
准备评测模型
首先,我们需要通过OpenAI API兼容的推理服务接入模型能力,以进行评测。值得注意的是,EvalScope也支持使用transformers进行模型推理评测,详细信息可参考EvalScope文档。
除了将模型部署到支持OpenAI接口的云端服务外,还可以选择在本地使用vLLM、ollama等框架直接启动模型。这些推理框架能够很好地支持并发多个请求,从而加速评测过程。特别是对于R1类模型,其输出通常包含较长的思维链,输出token数量往往超过1万。使用高效的推理框架部署模型可以显著提高推理速度。
下面以DeepSeek-R1-Distill-Qwen-7B为例,介绍如何使用vLLM部署模型:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-1.5B --trust_remote_code --port 8801
使用EvalScope评测模型
运行以下命令,即可让模型在MATH-500数据集上进行推理,并获得模型在每个问题上的输出结果,以及整体答题正确率:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需要与部署时的模型名称一致)
eval_type='service', # 评测类型,SERVICE表示评测推理服务
datasets=['math_500'], # 数据集名称
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数
eval_batch_size=32, # 发送请求的并发数
generation_config={
'max_tokens': 20000, # 最大生成token数,建议设置为较大值避免输出截断
'temperature': 0.6, # 采样温度 (deepseek 报告推荐值)
'top_p': 0.95, # top-p采样 (deepseek 报告推荐值)
'n': 1, # 每个请求产生的回复数量
},
)
run_task(task_config)
输出结果如下,可以看到模型在每个等级问题上的模型回答正确率:
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=============================+===========+===============+==========+=======+=========+=========+
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
模型思考效率评估
在获取模型的推理结果后,我们便可以着手评估其思考效率。在开始之前,我们需要介绍评估过程中涉及的几个关键指标:token效率、模型思考长度以及子思维链数量。
-
模型推理token数(Reasoning Tokens):这是指模型在推理过程中生成的长思维链的token数量。对于O1/R1类型的推理模型,该指标表示
</think>标志前的token数量。 -
首次正确token数(First Correct Tokens):模型推理过程中,从起始位置到第一个可以识别为正确答案位置的token数。
-
剩余反思token数(Reflection Tokens):从第一个正确答案位置到推理结束的token数。
-
子思维链数量(Num Thought):这一指标表示模型在推理过程中生成的不同思维路径的数量。具体来说,是通过统计模型生成的标志词(如alternatively、but wait、let me reconsider等)的出现次数来计算的。这反映了模型在推理中切换思路的频率。
-
token效率(Token Efficiency):指的是首次正确token数与模型推理token总数的比值,其计算公式如下其计算公式如下:
$$ M_{token} = \frac{1}{N} \sum^{N}_{i=1} \frac{\hat{T_i}}{T_i}其中,
N为问题数量,\hat{T_i}是从模型回复开始到第一个可识别为正确答案部分的token数量,T_i是模型的思考长度。如果模型答案错误,则\hat{T_i}为0。指标值越高,表示模型有效思考占比越高。在本评估框架中,我们参考ProcessBench的构建方式,使用额外的模型
Qwen2.5-72B-Instruct来检测推理过程中最早出现的正确答案位置。为了实现这一点,我们首先将模型输出分解为多个步骤,对每个步骤进行编号,然后使用Qwen2.5-72B-Instruct模型对这些步骤进行检验,找出第一个正确答案的token位置。我们实现了三种分解策略:separator:使用\n\n标志进行分解。keywords:使用标志词(如alternatively、but wait、let me reconsider)进行分解。llm:去除回复中的\n标志,使用LLM重写回复并插入\n\n标志进行分解。
下面以Qwen2.5-72B-Instruct作为检测模型进行评估,只需运行以下命令,即可启动评估并获取结果:
from evalscope.third_party.thinkbench import run_task
judge_config = dict( # 评测服务配置
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1',
model_name='Qwen2.5-72B-Instruct',
)
model_config = dict(
report_path = './outputs/2025xxxx', # 上一步模型推理结果路径
model_name = 'DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path = 'deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # 模型tokenizer路径,用于计算token数量
dataset_name = 'math_500', # 上一步数据集名称
subsets = ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 上一步数据集子集
split_strategies='separator', # 推理步骤分割策略,可选值为separator、keywords、llm
judge_config=judge_config
)
max_tokens = 20000 # 筛选token数量小于max_tokens的输出,用于提升评测效率
count = 200 # 每个子集筛选count条输出,用于提升评测效率
# 评测模型思考效率
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
输出结果如下,可以看到模型在每个等级问题上的token效率、模型思考长度和子思维链数量:
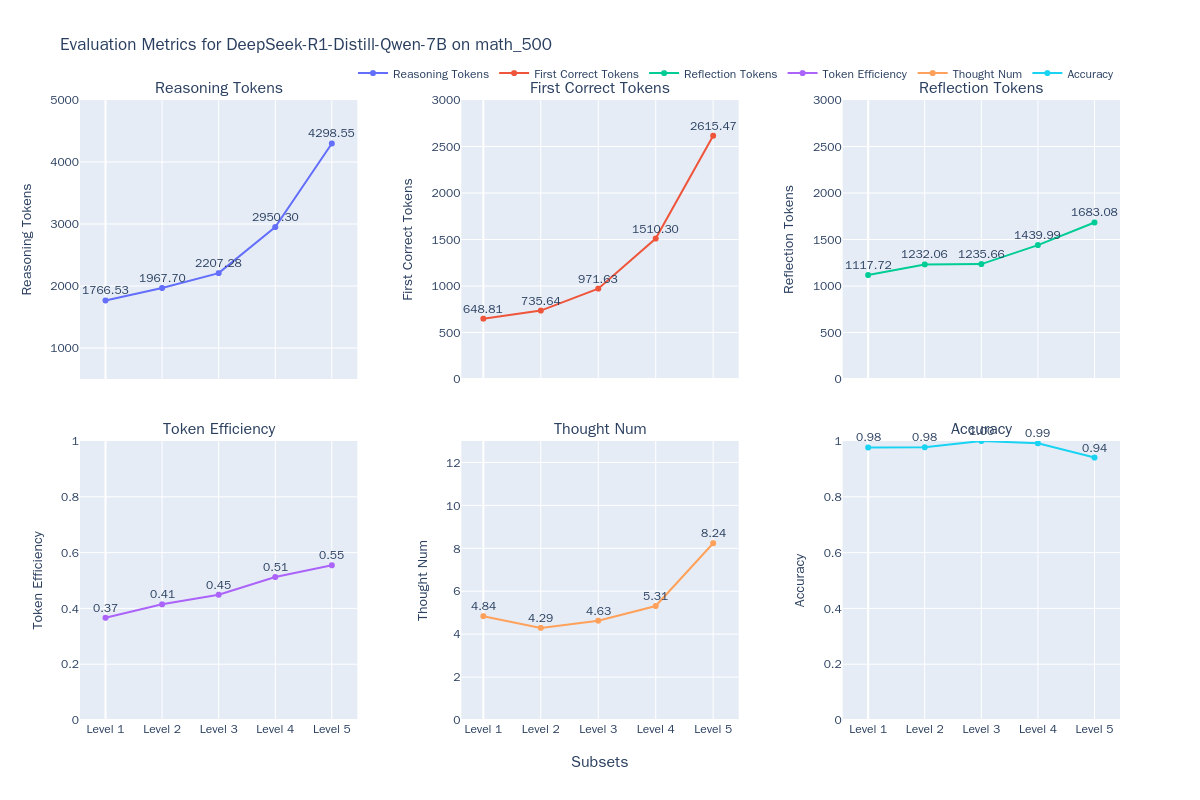 图1:DeepSeek-R1-Distill-Qwen-7B思考效率
图1:DeepSeek-R1-Distill-Qwen-7B思考效率
使用相同的方法,我们还对另外4个款推理模型QwQ-32B、QwQ-32B-Preview、DeepSeek-R1、DeepSeek-R1-Distill-Qwen-32B,以及一个非推理模型Qwen2.5-Math-7B-Instruct(将模型输出的所有token视为思考过程),以便观察不同类型模型的表现。具体结果整理如下:
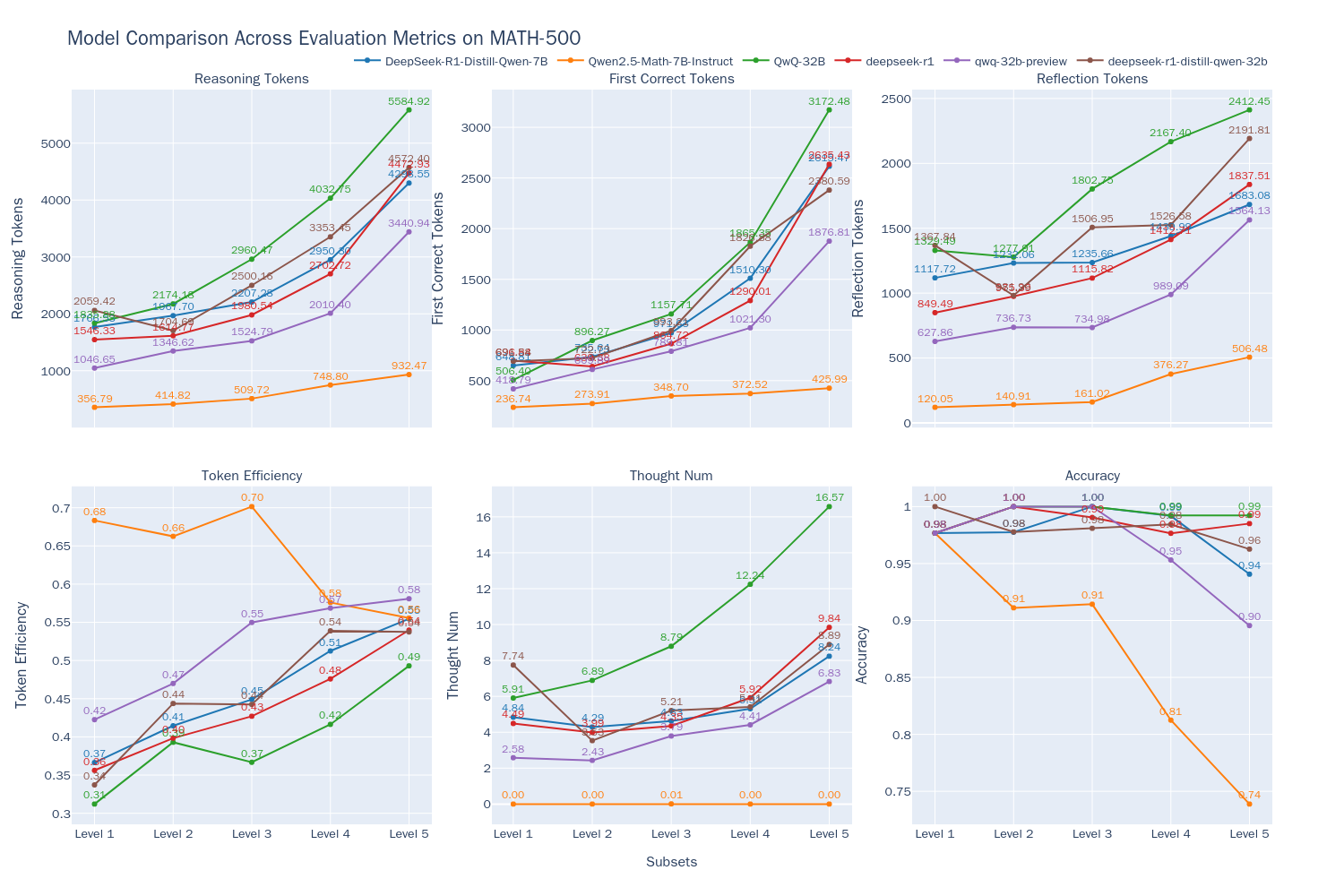 图2:6个模型思考效率对比率
图2:6个模型思考效率对比率
通过分析这些折线图,我们可以得出一些有趣的结论:
- 问题难度与模型表现:随着问题难度的增加,大多数模型的正确率呈现下降趋势,但QwQ-32B和DeepSeek-R1表现出色,在高难度问题上仍保持很高的准确率,其中QwQ-32B在最高难度级别上取得了最佳表现。同时,所有模型的输出长度都随问题难度增加而增加,这表明模型在解答更复杂问题时需要更长的"思考时间",与Inference-Time Scaling现象相符。
- O1/R1类推理模型的表现:
- 对于O1/R1推理模型,随着问题难度的提升,虽然输出长度稳定变长,但token的效率也有所提高(DeepSeek-R1从36%增长到54%,QwQ-32B从31%增长到49%)。这表明推理类型的模型,在更复杂的问题上其token的消耗会更加“物有所值”。而在相对简单的问题中,可能更多的存在不必须的token浪费:即使在简单问题上也可能不必要的对答案进行反复验证。其中QwQ-32B输出的token数量相较其他模型更多,这使得该模型在Level 5这种高难度问题上也能保持较高正确率,但另一方面也说明该模型可能存在过度分析的问题。
- 我们观察到一个有趣的现象:在难度Level 4及以下的问题中,DeepSeek系列的三个模型在子思维链数量上的变化相对稳定。然而,在最具挑战性的Level 5难度下,子思维链的数量会突然大幅增加。这可能是因为对于所测试的这些模型来说,Level 5的问题带来了极大的挑战,需要经过多轮尝试和思考才能找到解决方案。相比之下,QwQ-32B和QwQ-32B-Preview在思维链数量的增长上表现得更加均匀。这个现象可能反映了它们在处理复杂问题时的不同策略和能力。
- 非推理模型的表现:在处理高难度数学问题时,非推理模型Qwen2.5-Math-7B-Instruct的准确率显著下降。此外,由于缺乏深入的思考过程,该模型的输出数量仅为推理模型的三分之一。从图中不难看出,像Qwen2.5-Math-7B-Instruct这样的专门训练的数学模型在普通问题上的解题速率和资源消耗方面优于通用推理模型,但随着问题难度的提升,由于深入思考过程的缺乏所导致的模型性能下降的现象会更加明显,即存在明显的"天花板"效应。
Tips
:::{card}
💡 在撰写这篇最佳实践的过程中,我积累了一些心得与大家分享:
-
关于思考效率评测指标的定义:
-
关于指标的适用范围:
- 目前,这些指标主要在数学推理数据集上应用,因此可能无法全面反映模型在其他应用场景下的表现。例如,在开放性问答或需要创造性回复的场景中,这些指标可能不够充分。
-
关于token效率指标的计算:
- 在实现过程中,我们依赖一个额外的Judge模型来判断模型推理步骤的正确性。参考ProcessBench4的工作,这一任务对现有模型来说颇具挑战性,通常需要一个能力较强的模型来进行判断。
- 如果Judge模型做出错误判断,可能会影响到token效率指标的准确性,这也意味着在选择Judge模型时需格外谨慎。
:::
总结
本文基于MATH-500数据集,对包括QwQ-32B、DeepSeek-R1在内的几个主流Reasoning模型进行了推理效率的评测,从"Token efficiency"和"Accuracy"的视角,我们得到几个值得探讨的结论:
- 模型的“深入思考”能力,与模型的性能表现有明显的相关关系,更高难度的问题,需要“更深入”的思考过程
- 对于Reasoning效率评测,本文基于“overthinking”和“underthinking”的相关工作,探讨如何定义可量化的评测指标,以及在EvalScope框架上的工程实现
- 模型Reasoning效率的评测,对GRPO和SFT训练过程有非常重要的参考意义,有助于开发出"更高效"且能根据问题难度"自适应推理"的模型
参考文献
-
Wang, Y. et al. Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs. Preprint at https://doi.org/10.48550/arXiv.2501.18585 (2025). ↩︎
-
Chen, X. et al. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs. Preprint at https://doi.org/10.48550/arXiv.2412.21187 (2025). ↩︎
-
Think Less, Achieve More: Cut Reasoning Costs by 50% Without Sacrificing Accuracy. https://novasky-ai.github.io/posts/reduce-overthinking/. ↩︎
-
Zheng, C. et al. ProcessBench: Identifying Process Errors in Mathematical Reasoning. Preprint at https://doi.org/10.48550/arXiv.2412.06559(2024). ↩︎