3.9 KiB
3.9 KiB
Introduction
EvalScope is a comprehensive model evaluation and benchmarking framework meticulously crafted by the ModelScope community. It offers an all-in-one solution for your model assessment needs, regardless of the type of model you are developing:
- 🧠 Large Language Models
- 🎨 Multimodal Models
- 🔍 Embedding Models
- 🏆 Reranker Models
- 🖼️ CLIP Models
- 🎭 AIGC Models (Text-to-Image/Video)
- ...and more!
EvalScope is not merely an evaluation tool; it is a valuable ally in your model optimization journey:
- 🏅 Equipped with multiple industry-recognized benchmarks and evaluation metrics such as MMLU, CMMLU, C-Eval, GSM8K, and others.
- 📊 Performance stress testing for model inference to ensure your model excels in real-world applications.
- 🚀 Seamlessly integrates with the ms-swift training framework, enabling one-click evaluations and providing end-to-end support from training to assessment for your model development.
Overall Architecture
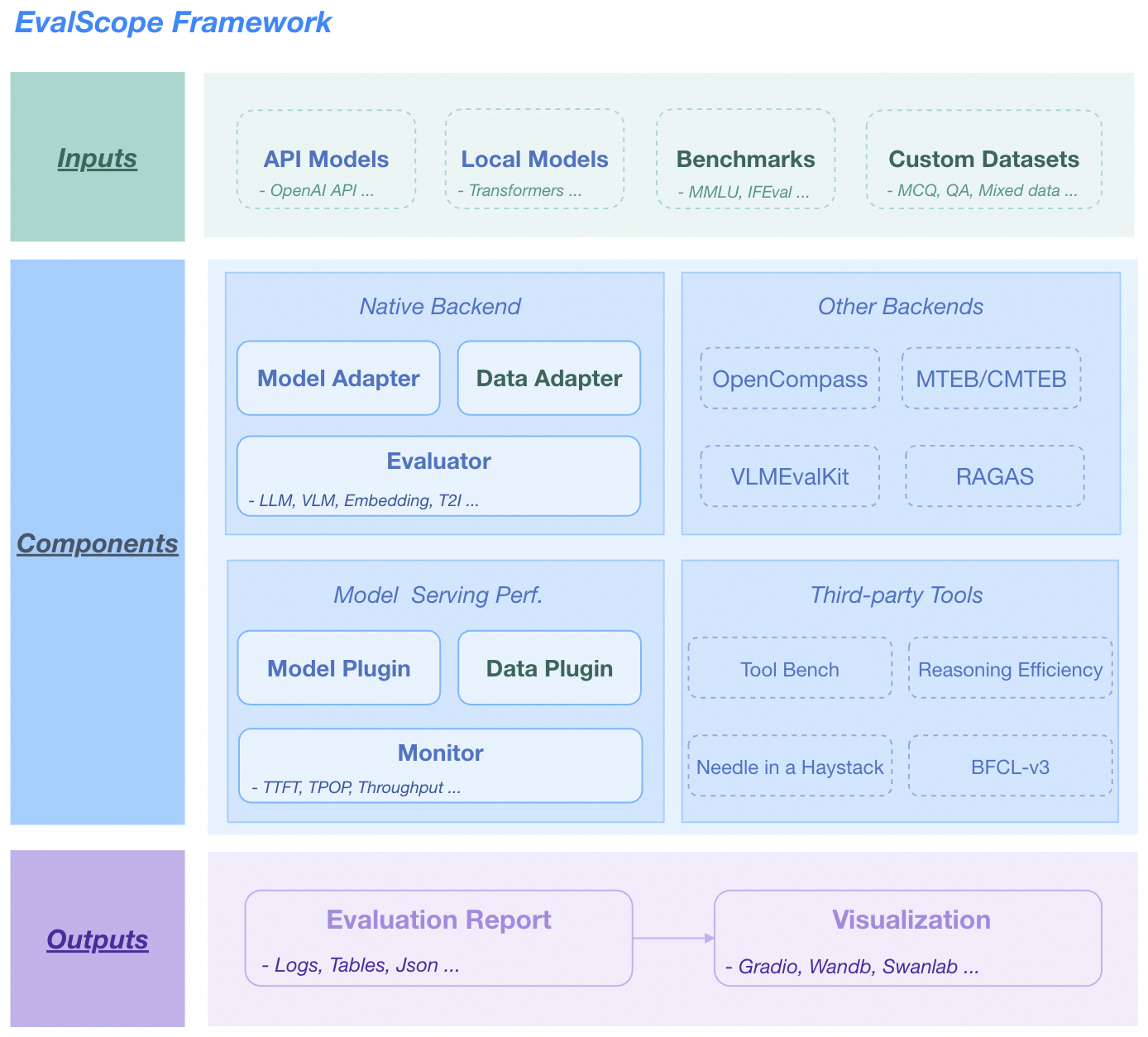 EvalScope Architecture Diagram.
EvalScope Architecture Diagram.
The architecture includes the following modules:
- Input Layer
- Model Sources: API models (OpenAI API), local models (ModelScope)
- Datasets: Standard evaluation benchmarks (MMLU/GSM8k, etc.), custom data (MCQ/QA)
- Core Functions
-
Multi-backend Evaluation
- Native backends: Unified evaluation for LLM/VLM/Embedding/T2I models
- Integrated frameworks: OpenCompass/MTEB/VLMEvalKit/RAGAS
-
Performance Monitoring
- Model plugins: Supports various model service APIs
- Data plugins: Supports multiple data formats
- Metric tracking: TTFT/TPOP/Stability and other metrics
-
Tool Extensions
- Integration: Tool-Bench/Needle-in-a-Haystack/BFCL-v3
- Output Layer
- Structured Reports: Supports JSON/Tables/Logs
- Visualization Platforms: Supports Gradio/Wandb/SwanLab
Framework Features
- Benchmark Datasets: Preloaded with several commonly used test benchmarks, including MMLU, CMMLU, C-Eval, GSM8K, ARC, HellaSwag, TruthfulQA, MATH, HumanEval, etc.
- Evaluation Metrics: Implements various commonly used evaluation metrics.
- Model Access: A unified model access mechanism that is compatible with the Generate and Chat interfaces of multiple model families.
- Automated Evaluation: Includes automatic evaluation of objective questions and complex task evaluation using expert models.
- Evaluation Reports: Automatically generates evaluation reports.
- Arena Mode: Used for comparisons between models and objective evaluation of models, supporting various evaluation modes, including:
- Single mode: Scoring a single model.
- Pairwise-baseline mode: Comparing against a baseline model.
- Pairwise (all) mode: Pairwise comparison among all models.
- Visualization Tools: Provides intuitive displays of evaluation results.
- Model Performance Evaluation: Offers a performance testing tool for model inference services and detailed statistics, see Model Performance Evaluation Documentation.
- OpenCompass Integration: Supports OpenCompass as the evaluation backend, providing advanced encapsulation and task simplification, allowing for easier task submission for evaluation.
- VLMEvalKit Integration: Supports VLMEvalKit as the evaluation backend, facilitating the initiation of multi-modal evaluation tasks, supporting various multi-modal models and datasets.
- Full-Link Support: Through seamless integration with the ms-swift training framework, provides a one-stop development process for model training, model deployment, model evaluation, and report viewing, enhancing user development efficiency.