9.0 KiB
BFCL-v3
Introduction
The Berkeley Function Calling Leaderboard (BFCL) is specifically designed to evaluate the function-calling capabilities of large language models (LLMs). Unlike previous assessments, BFCL considers various forms of function calls, diverse scenarios, and executability. This benchmark is widely used by multiple research teams (such as Llama, Qwen, etc.) and has been tested on several large language models.
- For detailed information, refer to the related Blog
- Dataset link and preview: AI-ModelScope/bfcl_v3
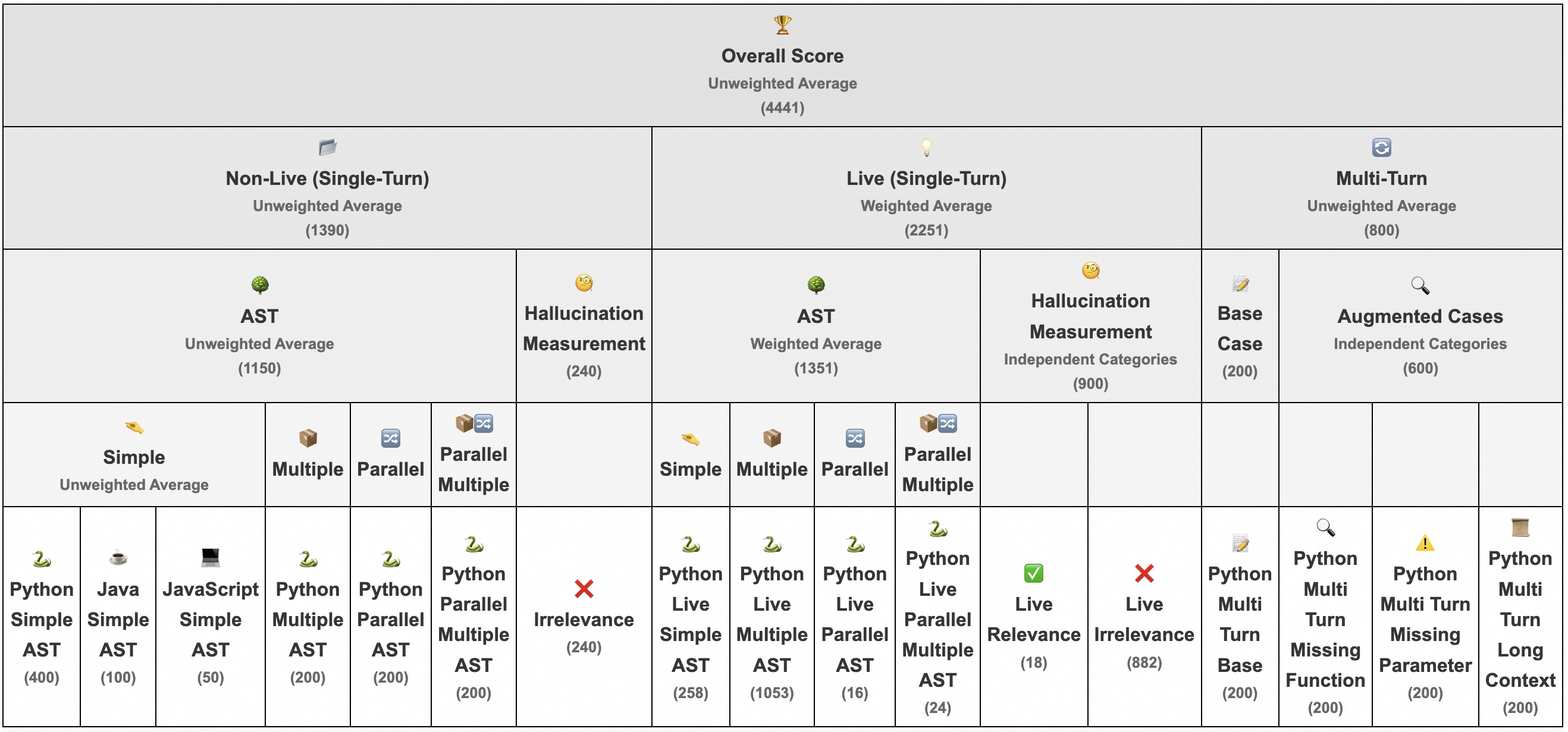
This benchmark consists of 17 tasks, covering a wide range of function-calling scenarios, as illustrated in the diagram below:
# BFCL-v3 task types and their respective categories
{
'simple': 'AST_NON_LIVE',
'multiple': 'AST_NON_LIVE',
'parallel': 'AST_NON_LIVE',
'parallel_multiple': 'AST_NON_LIVE',
'java': 'AST_NON_LIVE',
'javascript': 'AST_NON_LIVE',
'live_simple': 'AST_LIVE',
'live_multiple': 'AST_LIVE',
'live_parallel': 'AST_LIVE',
'live_parallel_multiple': 'AST_LIVE',
'irrelevance': 'RELEVANCE',
'live_relevance': 'RELEVANCE',
'live_irrelevance': 'RELEVANCE',
'multi_turn_base': 'MULTI_TURN',
'multi_turn_miss_func': 'MULTI_TURN',
'multi_turn_miss_param': 'MULTI_TURN',
'multi_turn_long_context': 'MULTI_TURN'
}
Installation Requirements
Before running the evaluation, you need to install the following dependencies:
pip install evalscope # Install evalscope
pip install bfcl-eval # Install bfcl-eval
Usage
Run the code below to start the evaluation. The following example uses the qwen-plus model for evaluation.
⚠️ Note: Only API model service evaluation is supported. For local model evaluation, it is recommended to use frameworks like vLLM to pre-launch the service.
import os
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='qwen-plus',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=os.getenv('DASHSCOPE_API_KEY'),
eval_type='service', # Use API model service
datasets=['bfcl_v3'],
eval_batch_size=10,
dataset_args={
'bfcl_v3': {
'extra_params':{
# The model refuses to use a dot ('.') in function names; set this to automatically convert dots to underscores during evaluation.
'underscore_to_dot': True,
# Whether the mode is a Function Calling Model; if so, function calling-related configurations will be enabled; otherwise, prompts will be used to bypass function calling.
'is_fc_model': True,
}
}
},
generation_config={
'temperature': 0,
'max_tokens': 4096,
'parallel_tool_calls': True, # Enable parallel function calls
},
limit=10, # Limit the number of evaluations for quick testing; it is recommended to remove this for formal evaluations
)
run_task(task_cfg=task_cfg)
Sample output:
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+===========+===========+=================+=========================+=======+=========+==============+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_simple | 10 | 0.9 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_multiple | 10 | 0.7 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_parallel | 10 | 0.6 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_parallel_multiple | 10 | 0.5 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | simple | 10 | 1 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multiple | 10 | 0.9 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | parallel | 10 | 0.8 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | parallel_multiple | 10 | 0.9 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | java | 10 | 0.7 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | javascript | 10 | 0.7 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_base | 10 | 0.1 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_miss_func | 10 | 0 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_miss_param | 10 | 0.1 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_long_context | 10 | 0.1 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | irrelevance | 10 | 0.5 | RELEVANCE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_relevance | 10 | 0.8 | RELEVANCE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_irrelevance | 10 | 0.6 | RELEVANCE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | OVERALL | 170 | 0.5823 | - |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
Evaluation Methodology
Single-Turn Tasks
Applicable Subsets: Non-Live (Single-Turn), Live (Single-Turn)
Evaluation Methods:
- AST Parsing (Abstract Syntax Tree): By parsing the function call parameter structure output by the model (such as Python/Java/JavaScript syntax trees), check if it conforms to predefined function signatures (parameter names, types, structures).
- Executable Function Evaluation: Directly execute the function calls generated by the model to verify if they can run correctly in the API system (e.g., whether file operations are successful).
- Relevance Detection: Determine whether the model calls functions relevant to the task (avoiding irrelevant function calls).
Characteristics:
- Relies on static code parsing (AST) or dynamic execution results (Exec).
- Does not involve multi-turn interaction, the user only initiates a single request.
Multi-Turn Tasks
Applicable Subsets: Base Multi-Turn, Augmented Multi-Turn (including missing parameters/functions/long context/complex scenarios)
Evaluation Methods:
- State-based Evaluation: At the end of each dialogue turn, check whether the internal state of the API system (such as file system content, user data) matches the expected state (by comparing attribute values of the system state). Applicable Scenarios: Write/delete operations (e.g., creating files, modifying databases).
- Response-based Evaluation: Check whether the model's function call trajectory includes the minimum necessary path (i.e., key function call sequences), allowing for redundant steps (e.g., multiple
lsto view directories). Applicable Scenarios: Read operations (e.g., querying weather, obtaining stock prices).
Termination Conditions:
- End the current turn if the model does not output a valid function call.
- Force termination if a single turn exceeds 20 steps, marking it as a failure.