21 KiB
Arena Mode
Arena mode allows you to configure multiple candidate models and specify a baseline model. The evaluation is conducted through pairwise battles between each candidate model and the baseline model, with the win rate and ranking of each model outputted at the end. This approach is suitable for comparative evaluation among multiple models and intuitively reflects the strengths and weaknesses of each model.
Data Preparation
To support arena mode, all candidate models need to run inference on the same dataset. The dataset can be a general QA dataset or a domain-specific one. Below is an example using a custom general_qa dataset. See the documentation for details on using this dataset.
The JSONL file for the general_qa dataset should be in the following format. Only the query field is required; no additional fields are necessary. Below are two example files:
-
Example content of the
arena.jsonlfile:{"query": "How can I improve my time management skills?"} {"query": "What are the most effective ways to deal with stress?"} {"query": "What are the main differences between Python and JavaScript programming languages?"} {"query": "How can I increase my productivity while working from home?"} {"query": "Can you explain the basics of quantum computing?"} -
Example content of the
example.jsonlfile (with reference answers):{"query": "What is the capital of France?", "response": "The capital of France is Paris."} {"query": "What is the largest mammal in the world?", "response": "The largest mammal in the world is the blue whale."} {"query": "How does photosynthesis work?", "response": "Photosynthesis is the process by which green plants use sunlight to synthesize foods with the help of chlorophyll."} {"query": "What is the theory of relativity?", "response": "The theory of relativity, developed by Albert Einstein, describes the laws of physics in relation to observers in different frames of reference."} {"query": "Who wrote 'To Kill a Mockingbird'?", "response": "Harper Lee wrote 'To Kill a Mockingbird'."}
Candidate Model Inference
After preparing the dataset, you can use EvalScope's run_task method to perform inference with the candidate models and obtain their outputs for subsequent battles.
Below is an example of how to configure inference tasks for three candidate models: Qwen2.5-0.5B-Instruct, Qwen2.5-7B-Instruct, and Qwen2.5-72B-Instruct, using the same configuration for inference.
Run the following code:
import os
from evalscope import TaskConfig, run_task
from evalscope.constants import EvalType
models = ['qwen2.5-72b-instruct', 'qwen2.5-7b-instruct', 'qwen2.5-0.5b-instruct']
task_list = [TaskConfig(
model=model,
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=os.getenv('DASHSCOPE_API_KEY'),
eval_type=EvalType.SERVICE,
datasets=[
'general_qa',
],
dataset_args={
'general_qa': {
'dataset_id': 'custom_eval/text/qa',
'subset_list': [
'arena',
'example'
],
}
},
eval_batch_size=10,
generation_config={
'temperature': 0,
'n': 1,
'max_tokens': 4096,
}) for model in models]
run_task(task_cfg=task_list)
Click to view inference results
Since the arena subset does not have reference answers, no evaluation metrics are available for this subset. The example subset has reference answers, so evaluation metrics will be output.
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=======================+============+=================+==========+=======+=========+=========+
| qwen2.5-0.5b-instruct | general_qa | AverageAccuracy | arena | 10 | -1 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-1-R | example | 12 | 0.8611 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-1-P | example | 12 | 0.1341 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-1-F | example | 12 | 0.1983 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-2-R | example | 12 | 0.55 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-2-P | example | 12 | 0.0404 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-2-F | example | 12 | 0.0716 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-L-R | example | 12 | 0.8611 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-L-P | example | 12 | 0.1193 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-L-F | example | 12 | 0.1754 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-1 | example | 12 | 0.1192 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-2 | example | 12 | 0.0403 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-3 | example | 12 | 0.0135 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-4 | example | 12 | 0.0079 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | AverageAccuracy | arena | 10 | -1 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-1-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-1-P | example | 12 | 0.1149 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-1-F | example | 12 | 0.1612 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-2-R | example | 12 | 0.6833 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-2-P | example | 12 | 0.0813 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-2-F | example | 12 | 0.1027 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-L-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-L-P | example | 12 | 0.101 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-L-F | example | 12 | 0.1361 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-1 | example | 12 | 0.1009 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-2 | example | 12 | 0.0807 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-3 | example | 12 | 0.0625 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-4 | example | 12 | 0.0556 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | AverageAccuracy | arena | 10 | -1 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-1-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-1-P | example | 12 | 0.104 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-1-F | example | 12 | 0.1418 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-2-R | example | 12 | 0.7 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-2-P | example | 12 | 0.078 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-2-F | example | 12 | 0.0964 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-L-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-L-P | example | 12 | 0.0942 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-L-F | example | 12 | 0.1235 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-1 | example | 12 | 0.0939 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-2 | example | 12 | 0.0777 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-3 | example | 12 | 0.0625 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-4 | example | 12 | 0.0556 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
Candidate Model Battles
Next, you can use EvalScope's general_arena method to conduct battles among candidate models and get their win rates and rankings on each subset. To achieve robust automatic battles, you need to configure an LLM as the judge that compares the outputs of models.
During evaluation, EvalScope will automatically parse the public evaluation set of candidate models, use the judge model to compare the output of each candidate model with the baseline, and determine which is better (to avoid model bias, outputs are swapped for two rounds per comparison). The judge model's outputs are parsed as win, draw, or loss, and each candidate model's Elo score and win rate are calculated.
Run the following code:
import os
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model_id='Arena', # Model ID is 'Arena'; you can omit specifying model ID
datasets=[
'general_arena', # Must be 'general_arena', indicating arena mode
],
dataset_args={
'general_arena': {
# 'system_prompt': 'xxx', # Optional: customize the judge model's system prompt here
# 'prompt_template': 'xxx', # Optional: customize the judge model's prompt template here
'extra_params':{
# Configure candidate model names and corresponding report paths
# Report paths refer to the output paths from the previous step, for parsing model inference results
'models':[
{
'name': 'qwen2.5-0.5b',
'report_path': 'outputs/20250702_204346/reports/qwen2.5-0.5b-instruct'
},
{
'name': 'qwen2.5-7b',
'report_path': 'outputs/20250702_204346/reports/qwen2.5-7b-instruct'
},
{
'name': 'qwen2.5-72b',
'report_path': 'outputs/20250702_204346/reports/qwen2.5-72b-instruct'
}
],
# Set baseline model, must be one of the candidate models
'baseline': 'qwen2.5-7b'
}
}
},
# Configure judge model parameters
judge_model_args={
'model_id': 'qwen-plus',
'api_url': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'api_key': os.getenv('DASHSCOPE_API_KEY'),
'generation_config': {
'temperature': 0.0,
'max_tokens': 8000
},
},
judge_worker_num=5,
# use_cache='outputs/xxx' # Optional: to add new candidate models to existing results, specify the existing results path
)
run_task(task_cfg=task_cfg)
Click to view evaluation results
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=========+===============+===============+============================================+=======+=========+=========+
| Arena | general_arena | winrate | general_qa&example@qwen2.5-0.5b&qwen2.5-7b | 12 | 0.0185 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | general_qa&example@qwen2.5-72b&qwen2.5-7b | 12 | 0.5469 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | general_qa&arena@qwen2.5-0.5b&qwen2.5-7b | 10 | 0.075 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | general_qa&arena@qwen2.5-72b&qwen2.5-7b | 10 | 0.8382 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | OVERALL | 44 | 0.3617 | - |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&example@qwen2.5-0.5b&qwen2.5-7b | 12 | 0.0185 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&example@qwen2.5-72b&qwen2.5-7b | 12 | 0.3906 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&arena@qwen2.5-0.5b&qwen2.5-7b | 10 | 0.025 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&arena@qwen2.5-72b&qwen2.5-7b | 10 | 0.7276 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | OVERALL | 44 | 0.2826 | - |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&example@qwen2.5-0.5b&qwen2.5-7b | 12 | 0.0909 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&example@qwen2.5-72b&qwen2.5-7b | 12 | 0.6875 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&arena@qwen2.5-0.5b&qwen2.5-7b | 10 | 0.0909 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&arena@qwen2.5-72b&qwen2.5-7b | 10 | 0.9412 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | OVERALL | 44 | 0.4469 | - |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
The automatically generated model leaderboard is as follows (output file located in outputs/xxx/reports/Arena/leaderboard.txt):
The leaderboard is sorted by win rate in descending order. As shown, the qwen2.5-72b model performs best across all subsets, with the highest win rate, while the qwen2.5-0.5b model performs the worst.
=== OVERALL LEADERBOARD ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 69.3 (-13.3 / +12.2)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
=== DATASET LEADERBOARD: general_qa ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 69.3 (-13.3 / +12.2)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
=== SUBSET LEADERBOARD: general_qa - example ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 54.7 (-15.6 / +14.1)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 1.8 (+0.0 / +7.2)
=== SUBSET LEADERBOARD: general_qa - arena ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 83.8 (-11.1 / +10.3)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 7.5 (-5.0 / +1.6)
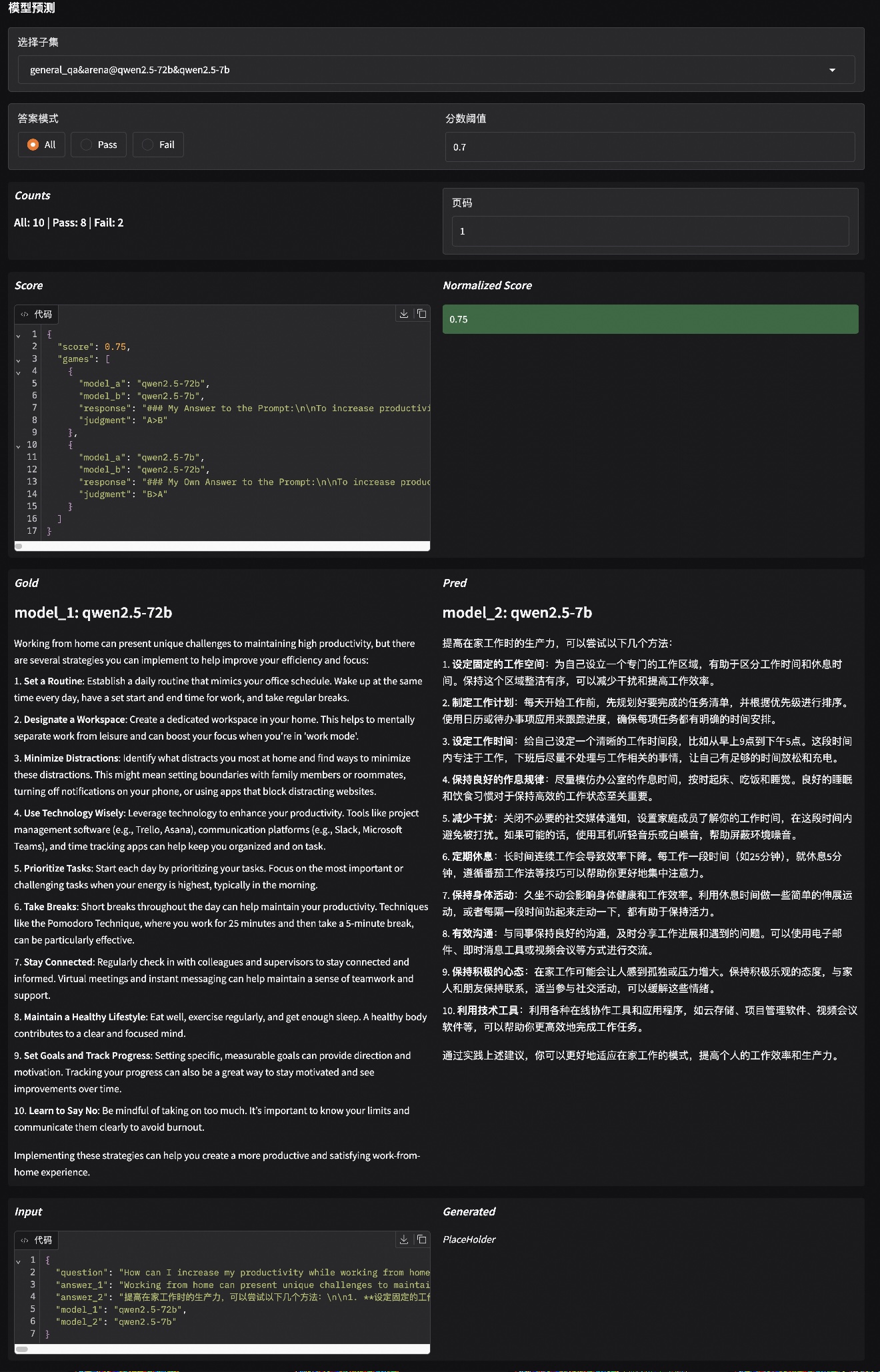
Visualization of Battle Results
To intuitively display the results of the battles between candidate models and the baseline, EvalScope provides a visualization feature, allowing you to compare the results of each candidate model against the baseline model for each sample.
Run the command below to launch the visualization interface:
evalscope app
Open http://localhost:7860 in your browser to view the visualization page.
Workflow:
- Select the latest
general_arenaevaluation report and click the "Load and View" button. - Click dataset details and select the battle results between your candidate model and the baseline.
- Adjust the threshold to filter battle results (normalized scores range from 0-1; 0.5 indicates a tie, scores above 0.5 indicate the candidate is better than the baseline, below 0.5 means worse).
Example below: a battle between qwen2.5-72b and qwen2.5-7b. The model judged the 72b as better: