62 lines
3.2 KiB
Markdown
62 lines
3.2 KiB
Markdown
# 简介
|
||
|
||
[EvalScope](https://github.com/modelscope/evalscope) 是魔搭社区倾力打造的模型评测与性能基准测试框架,为您的模型评估需求提供一站式解决方案。无论您在开发什么类型的模型,EvalScope 都能满足您的需求:
|
||
|
||
- 🧠 大语言模型
|
||
- 🎨 多模态模型
|
||
- 🔍 Embedding 模型
|
||
- 🏆 Reranker 模型
|
||
- 🖼️ CLIP 模型
|
||
- 🎭 AIGC模型(图生文/视频)
|
||
- ...以及更多!
|
||
|
||
EvalScope 不仅仅是一个评测工具,它是您模型优化之旅的得力助手:
|
||
|
||
- 🏅 内置多个业界认可的测试基准和评测指标:MMLU、CMMLU、C-Eval、GSM8K 等。
|
||
- 📊 模型推理性能压测:确保您的模型在实际应用中表现出色。
|
||
- 🚀 与 [ms-swift](https://github.com/modelscope/ms-swift) 训练框架无缝集成,一键发起评测,为您的模型开发提供从训练到评估的全链路支持。
|
||
|
||
## 整体架构
|
||
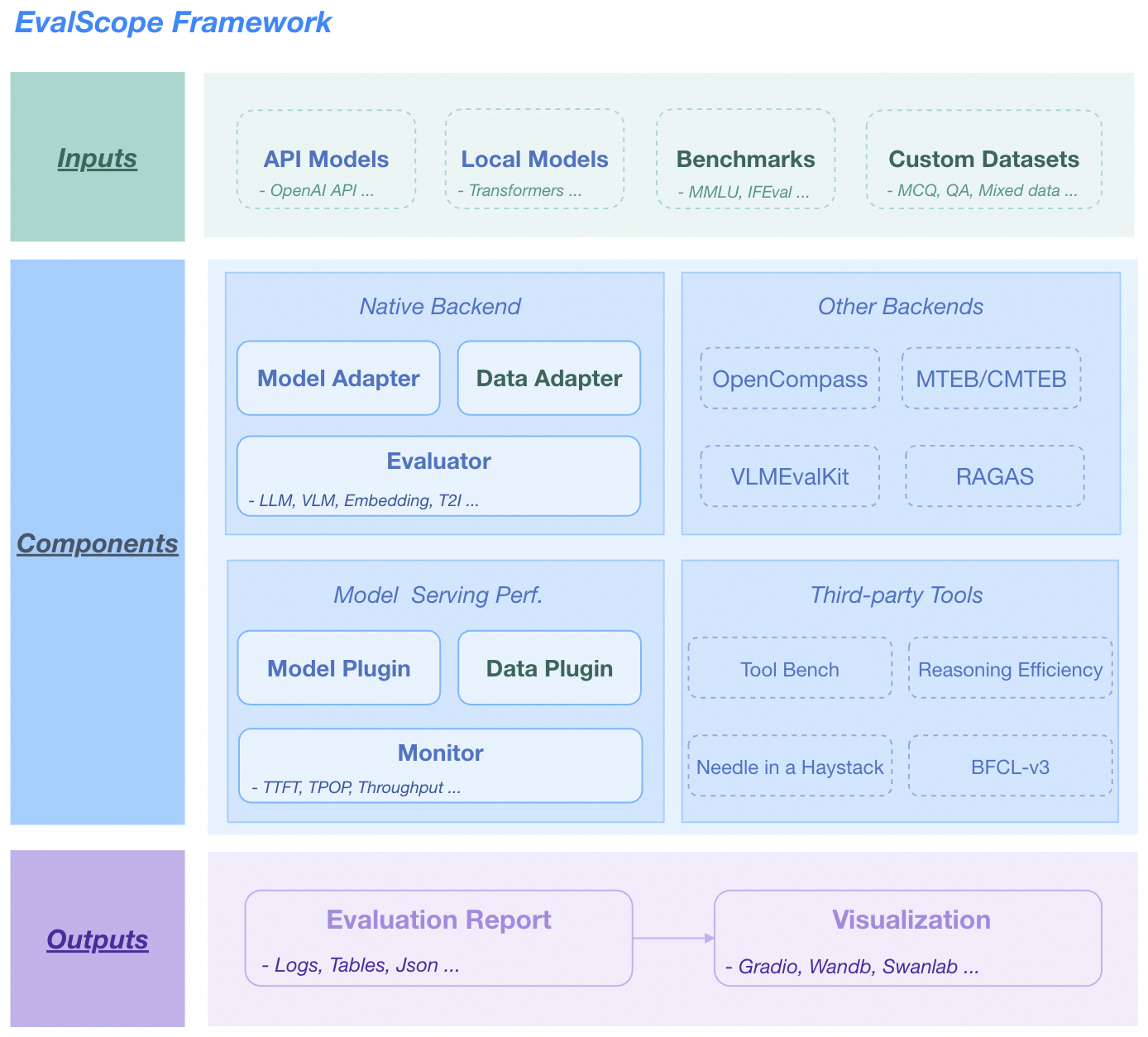
|
||
*EvalScope 架构图.*
|
||
|
||
包括以下模块:
|
||
|
||
1. 输入层
|
||
- **模型来源**:API模型(OpenAI API)、本地模型(ModelScope)
|
||
- **数据集**:标准评测基准(MMLU/GSM8k等)、自定义数据(MCQ/QA)
|
||
|
||
2. 核心功能
|
||
- **多后端评估**
|
||
- 原生后端:LLM/VLM/Embedding/T2I模型统一评估
|
||
- 集成框架:OpenCompass/MTEB/VLMEvalKit/RAGAS
|
||
|
||
- **性能监控**
|
||
- 模型插件:支持多种模型服务API
|
||
- 数据插件:支持多种数据格式
|
||
- 指标追踪:TTFT/TPOP/稳定性 等指标
|
||
|
||
- **工具扩展**
|
||
- 集成:Tool-Bench/Needle-in-a-Haystack/BFCL-v3
|
||
|
||
3. 输出层
|
||
- **结构化报告**: 支持JSON/Table/Logs
|
||
- **可视化平台**:支持Gradio/Wandb/SwanLab
|
||
|
||
## 框架特点
|
||
- **基准数据集**:预置了多个常用测试基准,包括:MMLU、CMMLU、C-Eval、GSM8K、ARC、HellaSwag、TruthfulQA、MATH、HumanEval等。
|
||
- **评测指标**:实现了多种常用评测指标。
|
||
- **模型接入**:统一的模型接入机制,兼容多个系列模型的Generate、Chat接口。
|
||
- **自动评测**:包括客观题自动评测和使用专家模型进行的复杂任务评测。
|
||
- **评测报告**:自动生成评测报告。
|
||
- **竞技场(Arena)模式**:用于模型间的比较以及模型的客观评测,支持多种评测模式,包括:
|
||
- **Single mode**:对单个模型进行评分。
|
||
- **Pairwise-baseline mode**:与基线模型进行对比。
|
||
- **Pairwise (all) mode**:所有模型间的两两对比。
|
||
- **可视化工具**:提供直观的评测结果展示。
|
||
- **模型性能评测**:提供模型推理服务压测工具和详细统计,详见[模型性能评测文档](../user_guides/stress_test/index.md)。
|
||
- **OpenCompass集成**:支持OpenCompass作为评测后端,对其进行了高级封装和任务简化,您可以更轻松地提交任务进行评测。
|
||
- **VLMEvalKit集成**:支持VLMEvalKit作为评测后端,轻松发起多模态评测任务,支持多种多模态模型和数据集。
|
||
- **全链路支持**:通过与[ms-swift](https://github.com/modelscope/ms-swift)训练框架的无缝集成,实现模型训练、模型部署、模型评测、评测报告查看的一站式开发流程,提升用户的开发效率。
|
||
|