8.6 KiB
8.6 KiB
BFCL-v3
简介
Berkeley Function Calling Leaderboard (BFCL) 专门用于评估大型语言模型(LLM)调用函数的能力。与之前的评估不同,BFCL 考虑了各种形式的函数调用、多样化的场景以及可执行性。该评测基准被多个研究团队广泛使用(Llama, Qwen等),并且在多个大型语言模型上进行了测试。
- 具体介绍可以参考相关:Blog
- 数据集链接和预览:AI-ModelScope/bfcl_v3
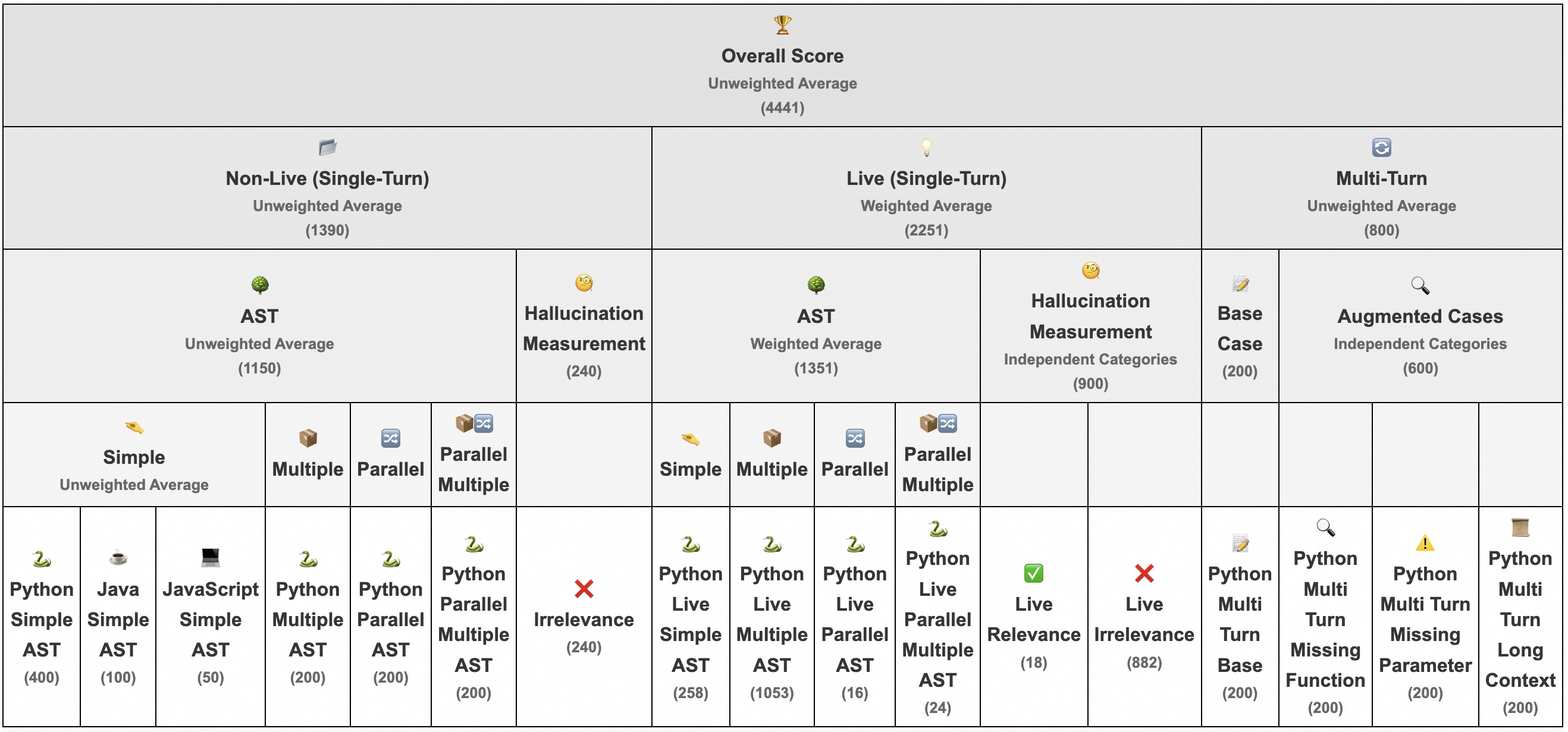
该评测基准由17个任务组成,涵盖了多种函数调用场景,组成和功能如下图所示:
# BFCL-v3任务类型及其所属类别
{
'simple': 'AST_NON_LIVE',
'multiple': 'AST_NON_LIVE',
'parallel': 'AST_NON_LIVE',
'parallel_multiple': 'AST_NON_LIVE',
'java': 'AST_NON_LIVE',
'javascript': 'AST_NON_LIVE',
'live_simple': 'AST_LIVE',
'live_multiple': 'AST_LIVE',
'live_parallel': 'AST_LIVE',
'live_parallel_multiple': 'AST_LIVE',
'irrelevance': 'RELEVANCE',
'live_relevance': 'RELEVANCE',
'live_irrelevance': 'RELEVANCE',
'multi_turn_base': 'MULTI_TURN',
'multi_turn_miss_func': 'MULTI_TURN',
'multi_turn_miss_param': 'MULTI_TURN',
'multi_turn_long_context': 'MULTI_TURN'
}
安装依赖
在运行评测之前需要安装以下依赖:
pip install evalscope # 安装 evalscope
pip install bfcl-eval # 安装 bfcl-eval
使用方法
运行下面的代码即可启动评测。下面以qwen-plus模型为例进行评测。
⚠️ 注意:仅支持API模型服务评测,本地模型评测建议使用vLLM等框架预先拉起服务。
import os
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='qwen-plus',
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=os.getenv('DASHSCOPE_API_KEY'),
eval_type='service', # 使用API模型服务
datasets=['bfcl_v3'],
eval_batch_size=10,
dataset_args={
'bfcl_v3': {
'extra_params':{
# 模型在函数名称中拒绝使用点号(`.`);设置此项,以便在评估期间自动将点号转换为下划线。
'underscore_to_dot': True,
# 模式是否为函数调用模型(Function Calling Model),如果是则会启用函数调用相关的配置;否则会使用prompt绕过函数调用。
'is_fc_model': True,
}
}
},
generation_config={
'temperature': 0,
'max_tokens': 4096,
'parallel_tool_calls': True, # 启用并行函数调用
},
limit=10, # 限制评测数量,便于快速测试,正式评测时建议去掉此项
)
run_task(task_cfg=task_cfg)
输出示例如下:
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+===========+===========+=================+=========================+=======+=========+==============+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_simple | 10 | 0.9 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_multiple | 10 | 0.7 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_parallel | 10 | 0.6 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_parallel_multiple | 10 | 0.5 | AST_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | simple | 10 | 1 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multiple | 10 | 0.9 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | parallel | 10 | 0.8 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | parallel_multiple | 10 | 0.9 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | java | 10 | 0.7 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | javascript | 10 | 0.7 | AST_NON_LIVE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_base | 10 | 0.1 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_miss_func | 10 | 0 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_miss_param | 10 | 0.1 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | multi_turn_long_context | 10 | 0.1 | MULTI_TURN |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | irrelevance | 10 | 0.5 | RELEVANCE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_relevance | 10 | 0.8 | RELEVANCE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | live_irrelevance | 10 | 0.6 | RELEVANCE |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
| qwen-plus | bfcl_v3 | AverageAccuracy | OVERALL | 170 | 0.5823 | - |
+-----------+-----------+-----------------+-------------------------+-------+---------+--------------+
评测方法说明
单轮任务(Single-Turn)
适用子集:Non-Live (Single-Turn)、Live (Single-Turn)
评测方法:
- AST解析(Abstract Syntax Tree):通过解析模型输出的函数调用参数结构(如Python/Java/JavaScript语法树),检查是否符合预定义的函数签名(参数名、类型、结构)。
- 可执行性验证(Executable Function Evaluation):直接执行模型生成的函数调用,验证能否在API系统中正确运行(如文件操作是否成功)。
- 相关性检测(Relevance Detection):判断模型是否调用与任务相关的函数(避免无关函数调用)。
特点:
- 依赖静态代码解析(AST)或动态执行结果(Exec)。
- 不涉及多轮交互,用户仅发起一次请求。
多轮任务(Multi-Turn)
适用子集:Base Multi-Turn、Augmented Multi-Turn(含缺失参数/函数/长上下文/复合场景)
评测方法:
- 状态验证(State-based Evaluation):在每轮对话结束时,检查API系统的内部状态(如文件系统内容、用户数据)是否与预期一致(通过对比系统状态的属性值)。适用场景:写入/删除类操作(如创建文件、修改数据库)。
- 响应验证(Response-based Evaluation):检查模型的函数调用轨迹是否包含最小必要路径(即关键函数调用序列),允许存在冗余步骤(如多次
ls查看目录)。适用场景:读取类操作(如查询天气、获取股价)。
终止条件:
- 模型未输出有效函数调用时,结束当前轮次。
- 单轮内超过20步则强制终止,标记为失败。