20 KiB
竞技场模式
竞技场模式允许配置多个候选模型,并指定一个baseline模型,通过候选模型与baseline模型进行对比(pairwise battle)的方式进行评测,最后输出模型的胜率和排名。该方法适合多个模型之间的对比评测,直观体现模型优劣。
数据准备
为支持竞技场模式,候选模型都需要在相同的数据集上进行推理。数据集可以是一个通用的问答数据集,也可以是一个特定领域的数据集。下面展示使用自定义的general_qa数据集作为示例,该数据集具体使用方法参考文档。
general_qa数据集的jsonline文件需要为下面的格式,仅需query字段即可,无需其他字段。下面展示两种示例文件:
-
arena.jsonl文件内容示例如下:{"query": "How can I improve my time management skills?"} {"query": "What are the most effective ways to deal with stress?"} {"query": "What are the main differences between Python and JavaScript programming languages?"} {"query": "How can I increase my productivity while working from home?"} {"query": "Can you explain the basics of quantum computing?"} -
example.jsonl文件内容示例如下(有参考答案):{"query": "What is the capital of France?", "response": "The capital of France is Paris."} {"query": "What is the largest mammal in the world?", "response": "The largest mammal in the world is the blue whale."} {"query": "How does photosynthesis work?", "response": "Photosynthesis is the process by which green plants use sunlight to synthesize foods with the help of chlorophyll."} {"query": "What is the theory of relativity?", "response": "The theory of relativity, developed by Albert Einstein, describes the laws of physics in relation to observers in different frames of reference."} {"query": "Who wrote 'To Kill a Mockingbird'?", "response": "Harper Lee wrote 'To Kill a Mockingbird'."}
候选模型推理
在构造好数据集后,可以使用EvalScope的run_task方法进行候选模型的推理,得到模型的输出,用于后续模型对战。
下面展示如何配置候选模型的推理任务,有三个候选模型:Qwen2.5-0.5B-Instruct, Qwen2.5-7B-Instruct, Qwen2.5-72B-Instruct,我们使用相同的配置进行推理。
运行下面的代码:
import os
from evalscope import TaskConfig, run_task
from evalscope.constants import EvalType
models = ['qwen2.5-72b-instruct', 'qwen2.5-7b-instruct', 'qwen2.5-0.5b-instruct']
task_list = [TaskConfig(
model=model,
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
api_key=os.getenv('DASHSCOPE_API_KEY'),
eval_type=EvalType.SERVICE,
datasets=[
'general_qa',
],
dataset_args={
'general_qa': {
'dataset_id': 'custom_eval/text/qa',
'subset_list': [
'arena',
'example'
],
}
},
eval_batch_size=10,
generation_config={
'temperature': 0,
'n': 1,
'max_tokens': 4096,
}) for model in models]
run_task(task_cfg=task_list)
点击查看推理结果
由于arena子集没有参考答案,因此推理结果中没有评测指标。example子集有参考答案,因此会输出评测指标。
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=======================+============+=================+==========+=======+=========+=========+
| qwen2.5-0.5b-instruct | general_qa | AverageAccuracy | arena | 10 | -1 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-1-R | example | 12 | 0.8611 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-1-P | example | 12 | 0.1341 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-1-F | example | 12 | 0.1983 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-2-R | example | 12 | 0.55 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-2-P | example | 12 | 0.0404 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-2-F | example | 12 | 0.0716 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-L-R | example | 12 | 0.8611 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-L-P | example | 12 | 0.1193 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | Rouge-L-F | example | 12 | 0.1754 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-1 | example | 12 | 0.1192 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-2 | example | 12 | 0.0403 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-3 | example | 12 | 0.0135 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-0.5b-instruct | general_qa | bleu-4 | example | 12 | 0.0079 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | AverageAccuracy | arena | 10 | -1 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-1-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-1-P | example | 12 | 0.1149 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-1-F | example | 12 | 0.1612 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-2-R | example | 12 | 0.6833 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-2-P | example | 12 | 0.0813 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-2-F | example | 12 | 0.1027 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-L-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-L-P | example | 12 | 0.101 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | Rouge-L-F | example | 12 | 0.1361 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-1 | example | 12 | 0.1009 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-2 | example | 12 | 0.0807 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-3 | example | 12 | 0.0625 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-72b-instruct | general_qa | bleu-4 | example | 12 | 0.0556 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | AverageAccuracy | arena | 10 | -1 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-1-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-1-P | example | 12 | 0.104 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-1-F | example | 12 | 0.1418 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-2-R | example | 12 | 0.7 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-2-P | example | 12 | 0.078 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-2-F | example | 12 | 0.0964 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-L-R | example | 12 | 0.9722 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-L-P | example | 12 | 0.0942 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | Rouge-L-F | example | 12 | 0.1235 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-1 | example | 12 | 0.0939 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-2 | example | 12 | 0.0777 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-3 | example | 12 | 0.0625 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
| qwen2.5-7b-instruct | general_qa | bleu-4 | example | 12 | 0.0556 | default |
+-----------------------+------------+-----------------+----------+-------+---------+---------+
候选模型对战
接下来可以使用EvalScope的general_arena方法进行候选模型的对战,得到模型在各个子集上的胜率和排名。为了得到良好的自动对战效果,我们需要配置一个LLM模型作为裁判,用于对比模型的输出哪个更好。
在评测过程中,EvalScope会自动解析候选模型的公共评测集,使用裁判模型对比每个候选模型与baseline模型的输出,并判断优劣(为避免模型偏见,每个输出会交换顺序进行两轮对战)。裁判模型的输出会被解析为胜利、平局或失败,并计算每个候选模型的Elo得分及胜率。
运行下面的代码:
import os
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model_id='Arena', # 模型ID为'Arena',可以不指定模型ID
datasets=[
'general_arena', # 必须指定为'general_arena',表示使用竞技场模式
],
dataset_args={
'general_arena': {
# 'system_prompt': 'xxx', # 可选,若想要自定义裁判模型的系统提示,可以在这里配置
# 'prompt_template': 'xxx', # 可选,若想要自定义裁判模型的提示模板,可以在这里配置
'extra_params':{
# 配置候选模型名称和对应的报告路径
# 报告路径为上一步中模型输出的路径,用来解析模型推理结果
'models':[
{
'name': 'qwen2.5-0.5b',
'report_path': 'outputs/20250702_204346/reports/qwen2.5-0.5b-instruct'
},
{
'name': 'qwen2.5-7b',
'report_path': 'outputs/20250702_204346/reports/qwen2.5-7b-instruct'
},
{
'name': 'qwen2.5-72b',
'report_path': 'outputs/20250702_204346/reports/qwen2.5-72b-instruct'
}
],
# 设置baseline模型,必须为候选模型之一
'baseline': 'qwen2.5-7b'
}
}
},
# 配置judge模型参数
judge_model_args={
'model_id': 'qwen-plus',
'api_url': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
'api_key': os.getenv('DASHSCOPE_API_KEY'),
'generation_config': {
'temperature': 0.0,
'max_tokens': 8000
},
},
judge_worker_num=5,
# use_cache='outputs/xxx' # 可选,若想在已有评测结果上添加新的候选模型,可以指定已有评测结果路径
)
run_task(task_cfg=task_cfg)
点击查看评测结果
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
+=========+===============+===============+============================================+=======+=========+=========+
| Arena | general_arena | winrate | general_qa&example@qwen2.5-0.5b&qwen2.5-7b | 12 | 0.0185 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | general_qa&example@qwen2.5-72b&qwen2.5-7b | 12 | 0.5469 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | general_qa&arena@qwen2.5-0.5b&qwen2.5-7b | 10 | 0.075 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | general_qa&arena@qwen2.5-72b&qwen2.5-7b | 10 | 0.8382 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate | OVERALL | 44 | 0.3617 | - |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&example@qwen2.5-0.5b&qwen2.5-7b | 12 | 0.0185 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&example@qwen2.5-72b&qwen2.5-7b | 12 | 0.3906 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&arena@qwen2.5-0.5b&qwen2.5-7b | 10 | 0.025 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | general_qa&arena@qwen2.5-72b&qwen2.5-7b | 10 | 0.7276 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_lower | OVERALL | 44 | 0.2826 | - |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&example@qwen2.5-0.5b&qwen2.5-7b | 12 | 0.0909 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&example@qwen2.5-72b&qwen2.5-7b | 12 | 0.6875 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&arena@qwen2.5-0.5b&qwen2.5-7b | 10 | 0.0909 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | general_qa&arena@qwen2.5-72b&qwen2.5-7b | 10 | 0.9412 | default |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
| Arena | general_arena | winrate_upper | OVERALL | 44 | 0.4469 | - |
+---------+---------------+---------------+--------------------------------------------+-------+---------+---------+
自动生成的模型排行榜如下(输出文件在outputs/xxx/reports/Arena/leaderboard.txt目录):
排行榜按胜率降序排列,可以看出,qwen2.5-72b模型在所有子集上表现最好,胜率最高,而qwen2.5-0.5b模型表现最差。
=== OVERALL LEADERBOARD ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 69.3 (-13.3 / +12.2)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
=== DATASET LEADERBOARD: general_qa ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 69.3 (-13.3 / +12.2)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
=== SUBSET LEADERBOARD: general_qa - example ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 54.7 (-15.6 / +14.1)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 1.8 (+0.0 / +7.2)
=== SUBSET LEADERBOARD: general_qa - arena ===
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 83.8 (-11.1 / +10.3)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 7.5 (-5.0 / +1.6)
对战结果可视化
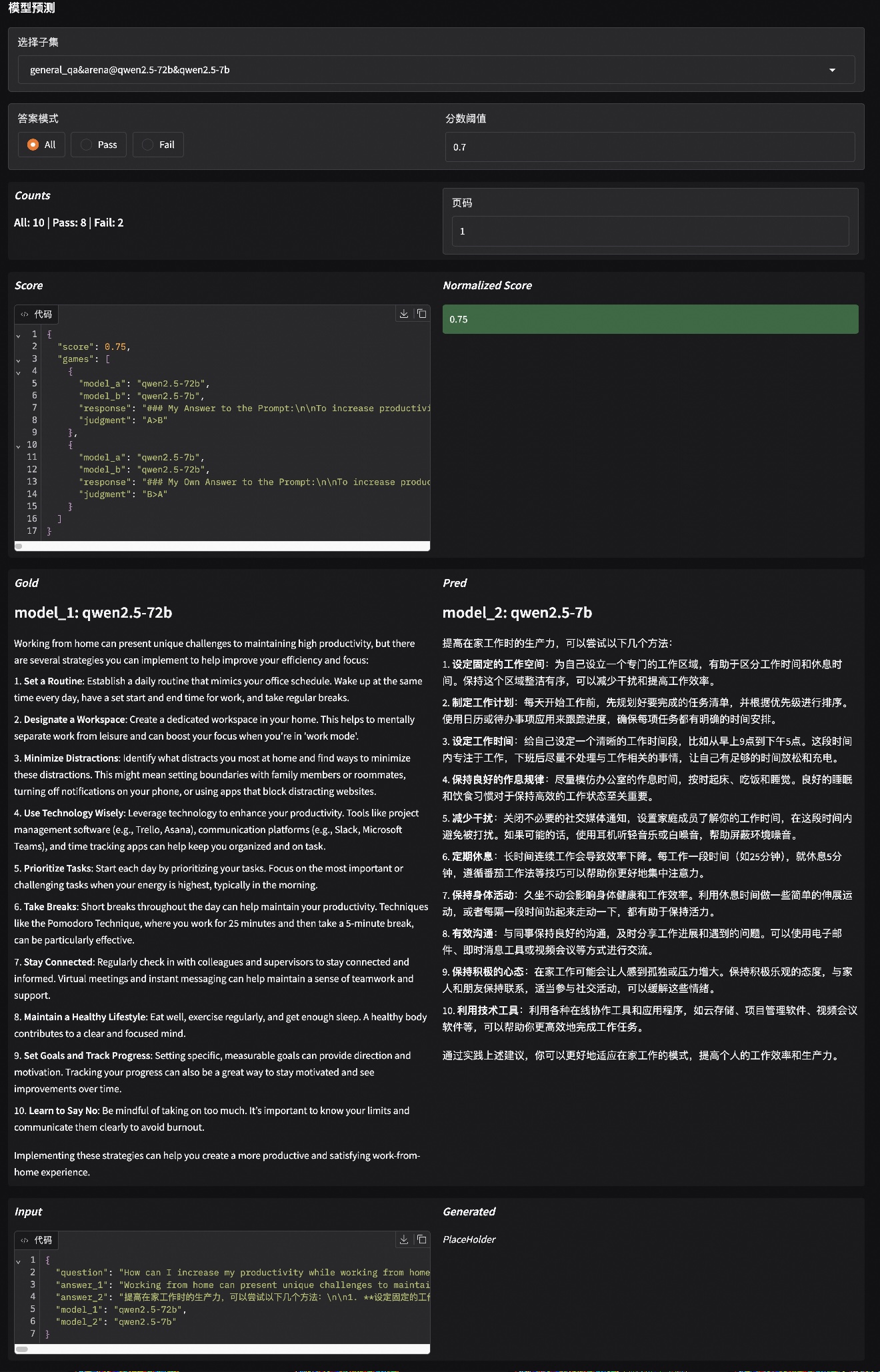
为了直观的展现模型候选模型与baseline模型的对战结果,EvalScope提供了可视化功能,可以对比每个候选模型与baseline模型在每个样本上的对战结果。
运行下面命令启动可视化界面:
evalscope app
在浏览器中打开http://localhost:7860,即可看到可视化界面。
使用流程为:
- 选择最近的
general_arena评测报告,点击加载并查看按钮 - 点击数据集详情,选择候选模型与baseline模型的对战结果
- 调整阈值可筛选对战结果(归一化的分数为0-1分,0.5表示持平,分数越高表明候选模型比baseline更优秀,反之更差)
示例如下,对比了qwen2.5-72b与qwen2.5-7b的一次对战结果,模型判断结果为72b模型更优: