first commit
|
|
@ -0,0 +1,24 @@
|
||||||
|
FROM ubuntu:22.04
|
||||||
|
ENV DEBIAN_FRONTEND=noninteractive
|
||||||
|
|
||||||
|
# 安装 Python 3.10 环境
|
||||||
|
RUN apt-get update && \
|
||||||
|
apt-get install -y software-properties-common curl git && \
|
||||||
|
add-apt-repository ppa:deadsnakes/ppa && \
|
||||||
|
apt-get update && \
|
||||||
|
apt-get install -y python3.10 python3.10-venv python3.10-dev python3-pip && \
|
||||||
|
ln -sf python3.10 /usr/bin/python3 && \
|
||||||
|
apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||||
|
|
||||||
|
WORKDIR /app
|
||||||
|
|
||||||
|
# 拷贝源码
|
||||||
|
COPY evalscope.0.17.0/ ./evalscope
|
||||||
|
|
||||||
|
# 安装源码与全部依赖
|
||||||
|
RUN pip install --upgrade pip setuptools wheel && \
|
||||||
|
pip install -e 'evalscope[all]' ./evalscope
|
||||||
|
|
||||||
|
# 启动容器即打印总 help 页面
|
||||||
|
ENTRYPOINT ["evalscope", "--help"]
|
||||||
|
|
||||||
|
|
@ -0,0 +1,43 @@
|
||||||
|
#!/bin/bash
|
||||||
|
set -euo pipefail
|
||||||
|
|
||||||
|
IMAGE_NAME="evalscope-full"
|
||||||
|
CONTAINER_NAME="evalscope-container"
|
||||||
|
SRC_DIR="evalscope.0.17.0"
|
||||||
|
|
||||||
|
echo "📍 当前目录: $(pwd)"
|
||||||
|
|
||||||
|
# ======== 1. 停止并删除旧容器 ========
|
||||||
|
if docker ps -a --format '{{.Names}}' | grep -q "^${CONTAINER_NAME}$"; then
|
||||||
|
echo "🛑 停止旧容器:$CONTAINER_NAME"
|
||||||
|
docker stop "$CONTAINER_NAME" || true
|
||||||
|
echo "🧹 删除旧容器:$CONTAINER_NAME"
|
||||||
|
docker rm "$CONTAINER_NAME"
|
||||||
|
fi
|
||||||
|
|
||||||
|
# ======== 2. 删除旧镜像 ========
|
||||||
|
if docker images -a | grep -q "^${IMAGE_NAME}"; then
|
||||||
|
echo "🗑️ 删除旧镜像:$IMAGE_NAME"
|
||||||
|
docker rmi -f "$IMAGE_NAME"
|
||||||
|
fi
|
||||||
|
|
||||||
|
# ======== 3. Git 拉取最新代码 ========
|
||||||
|
if [ -d "$SRC_DIR/.git" ]; then
|
||||||
|
echo "🔄 拉取最新源码:$SRC_DIR"
|
||||||
|
cd "$SRC_DIR"
|
||||||
|
git reset --hard
|
||||||
|
git pull origin $(git rev-parse --abbrev-ref HEAD)
|
||||||
|
cd ..
|
||||||
|
else
|
||||||
|
echo "❌ 错误:$SRC_DIR 不是 git 仓库"
|
||||||
|
exit 1
|
||||||
|
fi
|
||||||
|
|
||||||
|
# ======== 4. 构建镜像 ========
|
||||||
|
echo "🔧 开始构建镜像:$IMAGE_NAME"
|
||||||
|
docker build -t "$IMAGE_NAME" .
|
||||||
|
|
||||||
|
# ======== 5. 运行容器 ========
|
||||||
|
echo "🚀 启动容器:$CONTAINER_NAME"
|
||||||
|
docker run --rm --name "$CONTAINER_NAME" "$IMAGE_NAME"
|
||||||
|
|
||||||
|
|
@ -0,0 +1,155 @@
|
||||||
|
# Byte-compiled / optimized / DLL files
|
||||||
|
__pycache__/
|
||||||
|
*.py[cod]
|
||||||
|
*$py.class
|
||||||
|
|
||||||
|
# C extensions
|
||||||
|
*.so
|
||||||
|
|
||||||
|
# Distribution / packaging
|
||||||
|
.Python
|
||||||
|
build/
|
||||||
|
develop-eggs/
|
||||||
|
dist/
|
||||||
|
downloads/
|
||||||
|
eggs/
|
||||||
|
.eggs/
|
||||||
|
lib/
|
||||||
|
lib64/
|
||||||
|
parts/
|
||||||
|
sdist/
|
||||||
|
var/
|
||||||
|
wheels/
|
||||||
|
*.egg-info/
|
||||||
|
.installed.cfg
|
||||||
|
*.egg
|
||||||
|
/package
|
||||||
|
/temp
|
||||||
|
MANIFEST
|
||||||
|
|
||||||
|
# PyInstaller
|
||||||
|
# Usually these files are written by a python script from a template
|
||||||
|
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||||
|
*.manifest
|
||||||
|
*.spec
|
||||||
|
|
||||||
|
# Installer logs
|
||||||
|
pip-log.txt
|
||||||
|
pip-delete-this-directory.txt
|
||||||
|
|
||||||
|
# Unit test / coverage reports
|
||||||
|
htmlcov/
|
||||||
|
.tox/
|
||||||
|
.coverage
|
||||||
|
.coverage.*
|
||||||
|
.cache
|
||||||
|
nosetests.xml
|
||||||
|
coverage.xml
|
||||||
|
*.cover
|
||||||
|
.hypothesis/
|
||||||
|
.pytest_cache/
|
||||||
|
|
||||||
|
# Translations
|
||||||
|
*.mo
|
||||||
|
*.pot
|
||||||
|
|
||||||
|
# Django stuff:
|
||||||
|
*.log
|
||||||
|
local_settings.py
|
||||||
|
db.sqlite3
|
||||||
|
|
||||||
|
# Flask stuff:
|
||||||
|
instance/
|
||||||
|
.webassets-cache
|
||||||
|
|
||||||
|
# Scrapy stuff:
|
||||||
|
.scrapy
|
||||||
|
|
||||||
|
# Sphinx documentation
|
||||||
|
docs/_build/
|
||||||
|
|
||||||
|
# PyBuilder
|
||||||
|
target/
|
||||||
|
|
||||||
|
# Jupyter Notebook
|
||||||
|
.ipynb_checkpoints
|
||||||
|
|
||||||
|
# pyenv
|
||||||
|
.python-version
|
||||||
|
|
||||||
|
# celery beat schedule file
|
||||||
|
celerybeat-schedule
|
||||||
|
|
||||||
|
# SageMath parsed files
|
||||||
|
*.sage.py
|
||||||
|
|
||||||
|
# Environments
|
||||||
|
.env
|
||||||
|
.venv
|
||||||
|
env/
|
||||||
|
venv/
|
||||||
|
ENV/
|
||||||
|
env.bak/
|
||||||
|
venv.bak/
|
||||||
|
|
||||||
|
# Spyder project settings
|
||||||
|
.spyderproject
|
||||||
|
.spyproject
|
||||||
|
|
||||||
|
# Rope project settings
|
||||||
|
.ropeproject
|
||||||
|
|
||||||
|
# mkdocs documentation
|
||||||
|
/site
|
||||||
|
|
||||||
|
# mypy
|
||||||
|
.mypy_cache/
|
||||||
|
|
||||||
|
.vscode
|
||||||
|
.idea
|
||||||
|
|
||||||
|
# custom
|
||||||
|
*.pkl
|
||||||
|
*.pkl.json
|
||||||
|
*.log.json
|
||||||
|
*.whl
|
||||||
|
*.tar.gz
|
||||||
|
*.swp
|
||||||
|
*.log
|
||||||
|
*.tar.gz
|
||||||
|
source.sh
|
||||||
|
tensorboard.sh
|
||||||
|
.DS_Store
|
||||||
|
replace.sh
|
||||||
|
result.png
|
||||||
|
result.jpg
|
||||||
|
result.mp4
|
||||||
|
*.itag
|
||||||
|
|
||||||
|
# Pytorch
|
||||||
|
*.pth
|
||||||
|
*.pt
|
||||||
|
|
||||||
|
# personal info
|
||||||
|
private/
|
||||||
|
|
||||||
|
# others
|
||||||
|
*.tokenization
|
||||||
|
|
||||||
|
# outputs
|
||||||
|
outputs/
|
||||||
|
evalscope/outputs/
|
||||||
|
evalscope/*_temp.py
|
||||||
|
evalscope/data/
|
||||||
|
*/output_res/*
|
||||||
|
|
||||||
|
|
||||||
|
/tmp
|
||||||
|
/data
|
||||||
|
output/
|
||||||
|
/test*.*
|
||||||
|
*.ttf
|
||||||
|
_build/
|
||||||
|
swift.test*
|
||||||
|
/cache
|
||||||
|
evalscope/backend/rag_eval/ragas/prompts/chinese
|
||||||
|
|
@ -0,0 +1,55 @@
|
||||||
|
repos:
|
||||||
|
- repo: https://github.com/pycqa/flake8.git
|
||||||
|
rev: 7.1.1
|
||||||
|
hooks:
|
||||||
|
- id: flake8
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
examples/|
|
||||||
|
docs/|
|
||||||
|
tests/|
|
||||||
|
evalscope/utils/utils.py|
|
||||||
|
evalscope/third_party/|
|
||||||
|
evalscope/backend/rag_eval/clip_benchmark/tasks|
|
||||||
|
evalscope/backend/rag_eval/cmteb/tasks|
|
||||||
|
evalscope/metrics/t2v_metrics
|
||||||
|
)
|
||||||
|
- repo: https://github.com/PyCQA/isort.git
|
||||||
|
rev: 5.13.2
|
||||||
|
hooks:
|
||||||
|
- id: isort
|
||||||
|
- repo: https://github.com/pre-commit/mirrors-yapf.git
|
||||||
|
rev: v0.32.0
|
||||||
|
hooks:
|
||||||
|
- id: yapf
|
||||||
|
exclude: |
|
||||||
|
(?x)^(
|
||||||
|
examples/|
|
||||||
|
docs/|
|
||||||
|
tests/|
|
||||||
|
evalscope/utils/utils.py|
|
||||||
|
evalscope/third_party/|
|
||||||
|
evalscope/backend/rag_eval/clip_benchmark/tasks|
|
||||||
|
evalscope/backend/rag_eval/cmteb/tasks
|
||||||
|
)
|
||||||
|
- repo: https://github.com/pre-commit/pre-commit-hooks.git
|
||||||
|
rev: v5.0.0
|
||||||
|
hooks:
|
||||||
|
- id: trailing-whitespace
|
||||||
|
exclude: thirdparty/|docs/
|
||||||
|
- id: check-yaml
|
||||||
|
exclude: thirdparty/
|
||||||
|
- id: end-of-file-fixer
|
||||||
|
exclude: thirdparty/|docs/
|
||||||
|
- id: requirements-txt-fixer
|
||||||
|
exclude: thirdparty/
|
||||||
|
- id: double-quote-string-fixer
|
||||||
|
exclude: thirdparty/
|
||||||
|
- id: check-merge-conflict
|
||||||
|
exclude: thirdparty/
|
||||||
|
- id: fix-encoding-pragma
|
||||||
|
exclude: thirdparty/
|
||||||
|
args: ["--remove"]
|
||||||
|
- id: mixed-line-ending
|
||||||
|
exclude: thirdparty/
|
||||||
|
args: ["--fix=lf"]
|
||||||
|
|
@ -0,0 +1,55 @@
|
||||||
|
# Contributing to EvalScope
|
||||||
|
|
||||||
|
Thank you for considering contributing to EvalScope! We welcome contributions of all kinds, including bug fixes, new features, documentation, and more.
|
||||||
|
|
||||||
|
## Getting Started
|
||||||
|
|
||||||
|
1. **Fork the Repository**: Click the "Fork" button on the top right of this page to create a copy of this repository on your GitHub account.
|
||||||
|
|
||||||
|
2. **Clone Your Fork**: Clone your forked repository to your local machine using:
|
||||||
|
```bash
|
||||||
|
git clone https://github.com/your-username/EvalScope.git
|
||||||
|
```
|
||||||
|
Replace `your-username` with your GitHub username.
|
||||||
|
|
||||||
|
3. **Create a Branch**: Create a new branch for your changes. Use a descriptive name for your branch (e.g., `feature/new-feature`, `bugfix/issue-123`).
|
||||||
|
```bash
|
||||||
|
git checkout -b feature/your-feature-name
|
||||||
|
```
|
||||||
|
|
||||||
|
4. **Set Up Environment**: Follow the setup instructions in the `README.md` or `SETUP.md` to get the project up and running on your local machine.
|
||||||
|
|
||||||
|
## Making Changes
|
||||||
|
|
||||||
|
1. **Code Style**: Ensure your code follows the project's coding guidelines. If applicable, run the linter to check for any style issues.
|
||||||
|
|
||||||
|
2. **Pre-commit Hooks**: This project uses `pre-commit` hooks to maintain code quality. Make sure you have `pre-commit` installed and set up in your environment. Run the following commands to install the hooks:
|
||||||
|
```bash
|
||||||
|
pip install pre-commit
|
||||||
|
pre-commit install
|
||||||
|
```
|
||||||
|
Before making a commit, you can manually run all pre-commit checks with:
|
||||||
|
```bash
|
||||||
|
pre-commit run --all-files
|
||||||
|
```
|
||||||
|
|
||||||
|
3. **Testing**: Write tests to cover your changes. Run all tests to ensure nothing else is broken.
|
||||||
|
|
||||||
|
4. **Commit Changes**: Make sure your commit messages are clear and descriptive. Each commit should represent a single logical change.
|
||||||
|
|
||||||
|
5. **Push Changes**: Push your changes to your forked repository.
|
||||||
|
```bash
|
||||||
|
git push origin feature/your-feature-name
|
||||||
|
```
|
||||||
|
|
||||||
|
## Creating a Pull Request
|
||||||
|
|
||||||
|
1. **Navigate to the Original Repository**: Go to the original repository where you want to submit your changes.
|
||||||
|
|
||||||
|
2. **Create a Pull Request**: Click the "New Pull Request" button. Ensure that you are comparing your branch from your fork against the correct branch in the original repository.
|
||||||
|
|
||||||
|
3. **Fill Out the Pull Request Template**: Provide a clear description of your changes, including any relevant issue numbers and a summary of the changes.
|
||||||
|
|
||||||
|
4. **Respond to Feedback**: Be ready to make adjustments as reviewers comment on your pull request. Engage in discussions to clarify any concerns.
|
||||||
|
|
||||||
|
Thank you for your contribution!
|
||||||
|
|
@ -0,0 +1,203 @@
|
||||||
|
Copyright 2022-2023 Alibaba ModelScope. All rights reserved.
|
||||||
|
|
||||||
|
Apache License
|
||||||
|
Version 2.0, January 2004
|
||||||
|
http://www.apache.org/licenses/
|
||||||
|
|
||||||
|
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||||
|
|
||||||
|
1. Definitions.
|
||||||
|
|
||||||
|
"License" shall mean the terms and conditions for use, reproduction,
|
||||||
|
and distribution as defined by Sections 1 through 9 of this document.
|
||||||
|
|
||||||
|
"Licensor" shall mean the copyright owner or entity authorized by
|
||||||
|
the copyright owner that is granting the License.
|
||||||
|
|
||||||
|
"Legal Entity" shall mean the union of the acting entity and all
|
||||||
|
other entities that control, are controlled by, or are under common
|
||||||
|
control with that entity. For the purposes of this definition,
|
||||||
|
"control" means (i) the power, direct or indirect, to cause the
|
||||||
|
direction or management of such entity, whether by contract or
|
||||||
|
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||||
|
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||||
|
|
||||||
|
"You" (or "Your") shall mean an individual or Legal Entity
|
||||||
|
exercising permissions granted by this License.
|
||||||
|
|
||||||
|
"Source" form shall mean the preferred form for making modifications,
|
||||||
|
including but not limited to software source code, documentation
|
||||||
|
source, and configuration files.
|
||||||
|
|
||||||
|
"Object" form shall mean any form resulting from mechanical
|
||||||
|
transformation or translation of a Source form, including but
|
||||||
|
not limited to compiled object code, generated documentation,
|
||||||
|
and conversions to other media types.
|
||||||
|
|
||||||
|
"Work" shall mean the work of authorship, whether in Source or
|
||||||
|
Object form, made available under the License, as indicated by a
|
||||||
|
copyright notice that is included in or attached to the work
|
||||||
|
(an example is provided in the Appendix below).
|
||||||
|
|
||||||
|
"Derivative Works" shall mean any work, whether in Source or Object
|
||||||
|
form, that is based on (or derived from) the Work and for which the
|
||||||
|
editorial revisions, annotations, elaborations, or other modifications
|
||||||
|
represent, as a whole, an original work of authorship. For the purposes
|
||||||
|
of this License, Derivative Works shall not include works that remain
|
||||||
|
separable from, or merely link (or bind by name) to the interfaces of,
|
||||||
|
the Work and Derivative Works thereof.
|
||||||
|
|
||||||
|
"Contribution" shall mean any work of authorship, including
|
||||||
|
the original version of the Work and any modifications or additions
|
||||||
|
to that Work or Derivative Works thereof, that is intentionally
|
||||||
|
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||||
|
or by an individual or Legal Entity authorized to submit on behalf of
|
||||||
|
the copyright owner. For the purposes of this definition, "submitted"
|
||||||
|
means any form of electronic, verbal, or written communication sent
|
||||||
|
to the Licensor or its representatives, including but not limited to
|
||||||
|
communication on electronic mailing lists, source code control systems,
|
||||||
|
and issue tracking systems that are managed by, or on behalf of, the
|
||||||
|
Licensor for the purpose of discussing and improving the Work, but
|
||||||
|
excluding communication that is conspicuously marked or otherwise
|
||||||
|
designated in writing by the copyright owner as "Not a Contribution."
|
||||||
|
|
||||||
|
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||||
|
on behalf of whom a Contribution has been received by Licensor and
|
||||||
|
subsequently incorporated within the Work.
|
||||||
|
|
||||||
|
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
copyright license to reproduce, prepare Derivative Works of,
|
||||||
|
publicly display, publicly perform, sublicense, and distribute the
|
||||||
|
Work and such Derivative Works in Source or Object form.
|
||||||
|
|
||||||
|
3. Grant of Patent License. Subject to the terms and conditions of
|
||||||
|
this License, each Contributor hereby grants to You a perpetual,
|
||||||
|
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||||
|
(except as stated in this section) patent license to make, have made,
|
||||||
|
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||||
|
where such license applies only to those patent claims licensable
|
||||||
|
by such Contributor that are necessarily infringed by their
|
||||||
|
Contribution(s) alone or by combination of their Contribution(s)
|
||||||
|
with the Work to which such Contribution(s) was submitted. If You
|
||||||
|
institute patent litigation against any entity (including a
|
||||||
|
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||||
|
or a Contribution incorporated within the Work constitutes direct
|
||||||
|
or contributory patent infringement, then any patent licenses
|
||||||
|
granted to You under this License for that Work shall terminate
|
||||||
|
as of the date such litigation is filed.
|
||||||
|
|
||||||
|
4. Redistribution. You may reproduce and distribute copies of the
|
||||||
|
Work or Derivative Works thereof in any medium, with or without
|
||||||
|
modifications, and in Source or Object form, provided that You
|
||||||
|
meet the following conditions:
|
||||||
|
|
||||||
|
(a) You must give any other recipients of the Work or
|
||||||
|
Derivative Works a copy of this License; and
|
||||||
|
|
||||||
|
(b) You must cause any modified files to carry prominent notices
|
||||||
|
stating that You changed the files; and
|
||||||
|
|
||||||
|
(c) You must retain, in the Source form of any Derivative Works
|
||||||
|
that You distribute, all copyright, patent, trademark, and
|
||||||
|
attribution notices from the Source form of the Work,
|
||||||
|
excluding those notices that do not pertain to any part of
|
||||||
|
the Derivative Works; and
|
||||||
|
|
||||||
|
(d) If the Work includes a "NOTICE" text file as part of its
|
||||||
|
distribution, then any Derivative Works that You distribute must
|
||||||
|
include a readable copy of the attribution notices contained
|
||||||
|
within such NOTICE file, excluding those notices that do not
|
||||||
|
pertain to any part of the Derivative Works, in at least one
|
||||||
|
of the following places: within a NOTICE text file distributed
|
||||||
|
as part of the Derivative Works; within the Source form or
|
||||||
|
documentation, if provided along with the Derivative Works; or,
|
||||||
|
within a display generated by the Derivative Works, if and
|
||||||
|
wherever such third-party notices normally appear. The contents
|
||||||
|
of the NOTICE file are for informational purposes only and
|
||||||
|
do not modify the License. You may add Your own attribution
|
||||||
|
notices within Derivative Works that You distribute, alongside
|
||||||
|
or as an addendum to the NOTICE text from the Work, provided
|
||||||
|
that such additional attribution notices cannot be construed
|
||||||
|
as modifying the License.
|
||||||
|
|
||||||
|
You may add Your own copyright statement to Your modifications and
|
||||||
|
may provide additional or different license terms and conditions
|
||||||
|
for use, reproduction, or distribution of Your modifications, or
|
||||||
|
for any such Derivative Works as a whole, provided Your use,
|
||||||
|
reproduction, and distribution of the Work otherwise complies with
|
||||||
|
the conditions stated in this License.
|
||||||
|
|
||||||
|
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||||
|
any Contribution intentionally submitted for inclusion in the Work
|
||||||
|
by You to the Licensor shall be under the terms and conditions of
|
||||||
|
this License, without any additional terms or conditions.
|
||||||
|
Notwithstanding the above, nothing herein shall supersede or modify
|
||||||
|
the terms of any separate license agreement you may have executed
|
||||||
|
with Licensor regarding such Contributions.
|
||||||
|
|
||||||
|
6. Trademarks. This License does not grant permission to use the trade
|
||||||
|
names, trademarks, service marks, or product names of the Licensor,
|
||||||
|
except as required for reasonable and customary use in describing the
|
||||||
|
origin of the Work and reproducing the content of the NOTICE file.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||||
|
agreed to in writing, Licensor provides the Work (and each
|
||||||
|
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||||
|
implied, including, without limitation, any warranties or conditions
|
||||||
|
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||||
|
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||||
|
appropriateness of using or redistributing the Work and assume any
|
||||||
|
risks associated with Your exercise of permissions under this License.
|
||||||
|
|
||||||
|
8. Limitation of Liability. In no event and under no legal theory,
|
||||||
|
whether in tort (including negligence), contract, or otherwise,
|
||||||
|
unless required by applicable law (such as deliberate and grossly
|
||||||
|
negligent acts) or agreed to in writing, shall any Contributor be
|
||||||
|
liable to You for damages, including any direct, indirect, special,
|
||||||
|
incidental, or consequential damages of any character arising as a
|
||||||
|
result of this License or out of the use or inability to use the
|
||||||
|
Work (including but not limited to damages for loss of goodwill,
|
||||||
|
work stoppage, computer failure or malfunction, or any and all
|
||||||
|
other commercial damages or losses), even if such Contributor
|
||||||
|
has been advised of the possibility of such damages.
|
||||||
|
|
||||||
|
9. Accepting Warranty or Additional Liability. While redistributing
|
||||||
|
the Work or Derivative Works thereof, You may choose to offer,
|
||||||
|
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||||
|
or other liability obligations and/or rights consistent with this
|
||||||
|
License. However, in accepting such obligations, You may act only
|
||||||
|
on Your own behalf and on Your sole responsibility, not on behalf
|
||||||
|
of any other Contributor, and only if You agree to indemnify,
|
||||||
|
defend, and hold each Contributor harmless for any liability
|
||||||
|
incurred by, or claims asserted against, such Contributor by reason
|
||||||
|
of your accepting any such warranty or additional liability.
|
||||||
|
|
||||||
|
END OF TERMS AND CONDITIONS
|
||||||
|
|
||||||
|
APPENDIX: How to apply the Apache License to your work.
|
||||||
|
|
||||||
|
To apply the Apache License to your work, attach the following
|
||||||
|
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||||
|
replaced with your own identifying information. (Don't include
|
||||||
|
the brackets!) The text should be enclosed in the appropriate
|
||||||
|
comment syntax for the file format. We also recommend that a
|
||||||
|
file or class name and description of purpose be included on the
|
||||||
|
same "printed page" as the copyright notice for easier
|
||||||
|
identification within third-party archives.
|
||||||
|
|
||||||
|
Copyright 2022-2023 Alibaba ModelScope.
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
|
|
@ -0,0 +1,4 @@
|
||||||
|
include README.md
|
||||||
|
include requirements.txt
|
||||||
|
recursive-include evalscope *
|
||||||
|
recursive-include requirements *
|
||||||
|
|
@ -0,0 +1,19 @@
|
||||||
|
WHL_BUILD_DIR :=package
|
||||||
|
DOC_BUILD_DIR :=docs/build/
|
||||||
|
|
||||||
|
# default rule
|
||||||
|
default: whl docs
|
||||||
|
|
||||||
|
.PHONY: docs
|
||||||
|
|
||||||
|
.PHONY: linter
|
||||||
|
linter:
|
||||||
|
bash .dev_scripts/linter.sh
|
||||||
|
|
||||||
|
.PHONY: whl
|
||||||
|
whl:
|
||||||
|
python setup.py sdist bdist_wheel
|
||||||
|
|
||||||
|
.PHONY: clean
|
||||||
|
clean:
|
||||||
|
rm -rf $(WHL_BUILD_DIR) $(DOC_BUILD_DIR)
|
||||||
|
|
@ -0,0 +1,501 @@
|
||||||
|
<p align="center">
|
||||||
|
<br>
|
||||||
|
<img src="docs/en/_static/images/evalscope_logo.png"/>
|
||||||
|
<br>
|
||||||
|
<p>
|
||||||
|
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="README_zh.md">中文</a>   |   English  
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://img.shields.io/badge/python-%E2%89%A53.9-5be.svg">
|
||||||
|
<a href="https://badge.fury.io/py/evalscope"><img src="https://badge.fury.io/py/evalscope.svg" alt="PyPI version" height="18"></a>
|
||||||
|
<a href="https://pypi.org/project/evalscope"><img alt="PyPI - Downloads" src="https://static.pepy.tech/badge/evalscope"></a>
|
||||||
|
<a href="https://github.com/modelscope/evalscope/pulls"><img src="https://img.shields.io/badge/PR-welcome-55EB99.svg"></a>
|
||||||
|
<a href='https://evalscope.readthedocs.io/en/latest/?badge=latest'><img src='https://readthedocs.org/projects/evalscope/badge/?version=latest' alt='Documentation Status' /></a>
|
||||||
|
<p>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://evalscope.readthedocs.io/zh-cn/latest/"> 📖 中文文档</a>   |   <a href="https://evalscope.readthedocs.io/en/latest/"> 📖 English Documents</a>
|
||||||
|
<p>
|
||||||
|
|
||||||
|
> ⭐ If you like this project, please click the "Star" button at the top right to support us. Your support is our motivation to keep going!
|
||||||
|
|
||||||
|
## 📋 Contents
|
||||||
|
- [📋 Contents](#-contents)
|
||||||
|
- [📝 Introduction](#-introduction)
|
||||||
|
- [☎ User Groups](#-user-groups)
|
||||||
|
- [🎉 News](#-news)
|
||||||
|
- [🛠️ Installation](#️-installation)
|
||||||
|
- [Method 1: Install Using pip](#method-1-install-using-pip)
|
||||||
|
- [Method 2: Install from Source](#method-2-install-from-source)
|
||||||
|
- [🚀 Quick Start](#-quick-start)
|
||||||
|
- [Method 1. Using Command Line](#method-1-using-command-line)
|
||||||
|
- [Method 2. Using Python Code](#method-2-using-python-code)
|
||||||
|
- [Basic Parameter](#basic-parameter)
|
||||||
|
- [Output Results](#output-results)
|
||||||
|
- [📈 Visualization of Evaluation Results](#-visualization-of-evaluation-results)
|
||||||
|
- [🌐 Evaluation of Specified Model API](#-evaluation-of-specified-model-api)
|
||||||
|
- [⚙️ Custom Parameter Evaluation](#️-custom-parameter-evaluation)
|
||||||
|
- [Parameter](#parameter)
|
||||||
|
- [Evaluation Backend](#evaluation-backend)
|
||||||
|
- [📈 Model Serving Performance Evaluation](#-model-serving-performance-evaluation)
|
||||||
|
- [🖊️ Custom Dataset Evaluation](#️-custom-dataset-evaluation)
|
||||||
|
- [🏟️ Arena Mode](#️-arena-mode)
|
||||||
|
- [👷♂️ Contribution](#️-contribution)
|
||||||
|
- [🔜 Roadmap](#-roadmap)
|
||||||
|
- [Star History](#star-history)
|
||||||
|
|
||||||
|
|
||||||
|
## 📝 Introduction
|
||||||
|
|
||||||
|
EvalScope is a comprehensive model evaluation and performance benchmarking framework meticulously crafted by the [ModelScope Community](https://modelscope.cn/), offering a one-stop solution for your model assessment needs. Regardless of the type of model you are developing, EvalScope is equipped to cater to your requirements:
|
||||||
|
|
||||||
|
- 🧠 Large Language Models
|
||||||
|
- 🎨 Multimodal Models
|
||||||
|
- 🔍 Embedding Models
|
||||||
|
- 🏆 Reranker Models
|
||||||
|
- 🖼️ CLIP Models
|
||||||
|
- 🎭 AIGC Models (Image-to-Text/Video)
|
||||||
|
- ...and more!
|
||||||
|
|
||||||
|
EvalScope is not merely an evaluation tool; it is a valuable ally in your model optimization journey:
|
||||||
|
|
||||||
|
- 🏅 Equipped with multiple industry-recognized benchmarks and evaluation metrics: MMLU, CMMLU, C-Eval, GSM8K, etc.
|
||||||
|
- 📊 Model inference performance stress testing: Ensuring your model excels in real-world applications.
|
||||||
|
- 🚀 Seamless integration with the [ms-swift](https://github.com/modelscope/ms-swift) training framework, enabling one-click evaluations and providing full-chain support from training to assessment for your model development.
|
||||||
|
|
||||||
|
Below is the overall architecture diagram of EvalScope:
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://sail-moe.oss-cn-hangzhou.aliyuncs.com/yunlin/images/evalscope/doc/EvalScope%E6%9E%B6%E6%9E%84%E5%9B%BE.png" width="70%">
|
||||||
|
<br>EvalScope Framework.
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<details><summary>Framework Description</summary>
|
||||||
|
|
||||||
|
The architecture includes the following modules:
|
||||||
|
1. Input Layer
|
||||||
|
- **Model Sources**: API models (OpenAI API), local models (ModelScope)
|
||||||
|
- **Datasets**: Standard evaluation benchmarks (MMLU/GSM8k, etc.), custom data (MCQ/QA)
|
||||||
|
|
||||||
|
2. Core Functions
|
||||||
|
- **Multi-backend Evaluation**
|
||||||
|
- Native backends: Unified evaluation for LLM/VLM/Embedding/T2I models
|
||||||
|
- Integrated frameworks: OpenCompass/MTEB/VLMEvalKit/RAGAS
|
||||||
|
|
||||||
|
- **Performance Monitoring**
|
||||||
|
- Model plugins: Supports various model service APIs
|
||||||
|
- Data plugins: Supports multiple data formats
|
||||||
|
- Metric tracking: TTFT/TPOP/Stability and other metrics
|
||||||
|
|
||||||
|
- **Tool Extensions**
|
||||||
|
- Integration: Tool-Bench/Needle-in-a-Haystack/BFCL-v3
|
||||||
|
|
||||||
|
3. Output Layer
|
||||||
|
- **Structured Reports**: Supports JSON/Tables/Logs
|
||||||
|
- **Visualization Platforms**: Supports Gradio/Wandb/SwanLab
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## ☎ User Groups
|
||||||
|
|
||||||
|
Please scan the QR code below to join our community groups:
|
||||||
|
|
||||||
|
[Discord Group](https://discord.com/invite/D27yfEFVz5) | WeChat Group | DingTalk Group
|
||||||
|
:-------------------------:|:-------------------------:|:-------------------------:
|
||||||
|
<img src="docs/asset/discord_qr.jpg" width="160" height="160"> | <img src="docs/asset/wechat.png" width="160" height="160"> | <img src="docs/asset/dingding.png" width="160" height="160">
|
||||||
|
|
||||||
|
|
||||||
|
## 🎉 News
|
||||||
|
|
||||||
|
- 🔥 **[2025.07.03]** Refactored Arena Mode: now supports custom model battles, outputs a model leaderboard, and provides battle result visualization. See [reference](https://evalscope.readthedocs.io/en/latest/user_guides/arena.html) for details.
|
||||||
|
- 🔥 **[2025.06.28]** Optimized custom dataset evaluation: now supports evaluation without reference answers. Enhanced LLM judge usage, with built-in modes for "scoring directly without reference answers" and "checking answer consistency with reference answers". See [reference](https://evalscope.readthedocs.io/en/latest/advanced_guides/custom_dataset/llm.html#qa) for details.
|
||||||
|
- 🔥 **[2025.06.19]** Added support for the [BFCL-v3](https://modelscope.cn/datasets/AI-ModelScope/bfcl_v3) benchmark, designed to evaluate model function-calling capabilities across various scenarios. For more information, refer to the [documentation](https://evalscope.readthedocs.io/zh-cn/latest/third_party/bfcl_v3.html).
|
||||||
|
- 🔥 **[2025.06.02]** Added support for the Needle-in-a-Haystack test. Simply specify `needle_haystack` to conduct the test, and a corresponding heatmap will be generated in the `outputs/reports` folder, providing a visual representation of the model's performance. Refer to the [documentation](https://evalscope.readthedocs.io/en/latest/third_party/needle_haystack.html) for more details.
|
||||||
|
- 🔥 **[2025.05.29]** Added support for two long document evaluation benchmarks: [DocMath](https://modelscope.cn/datasets/yale-nlp/DocMath-Eval/summary) and [FRAMES](https://modelscope.cn/datasets/iic/frames/summary). For usage guidelines, please refer to the [documentation](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset.html).
|
||||||
|
- 🔥 **[2025.05.16]** Model service performance stress testing now supports setting various levels of concurrency and outputs a performance test report. [Reference example](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/quick_start.html#id3).
|
||||||
|
- 🔥 **[2025.05.13]** Added support for the [ToolBench-Static](https://modelscope.cn/datasets/AI-ModelScope/ToolBench-Static) dataset to evaluate model's tool-calling capabilities. Refer to the [documentation](https://evalscope.readthedocs.io/en/latest/third_party/toolbench.html) for usage instructions. Also added support for the [DROP](https://modelscope.cn/datasets/AI-ModelScope/DROP/dataPeview) and [Winogrande](https://modelscope.cn/datasets/AI-ModelScope/winogrande_val) benchmarks to assess the reasoning capabilities of models.
|
||||||
|
- 🔥 **[2025.04.29]** Added Qwen3 Evaluation Best Practices, [welcome to read 📖](https://evalscope.readthedocs.io/en/latest/best_practice/qwen3.html)
|
||||||
|
- 🔥 **[2025.04.27]** Support for text-to-image evaluation: Supports 8 metrics including MPS, HPSv2.1Score, etc., and evaluation benchmarks such as EvalMuse, GenAI-Bench. Refer to the [user documentation](https://evalscope.readthedocs.io/en/latest/user_guides/aigc/t2i.html) for more details.
|
||||||
|
- 🔥 **[2025.04.10]** Model service stress testing tool now supports the `/v1/completions` endpoint (the default endpoint for vLLM benchmarking)
|
||||||
|
- 🔥 **[2025.04.08]** Support for evaluating embedding model services compatible with the OpenAI API has been added. For more details, check the [user guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/mteb.html#configure-evaluation-parameters).
|
||||||
|
- 🔥 **[2025.03.27]** Added support for [AlpacaEval](https://www.modelscope.cn/datasets/AI-ModelScope/alpaca_eval/dataPeview) and [ArenaHard](https://modelscope.cn/datasets/AI-ModelScope/arena-hard-auto-v0.1/summary) evaluation benchmarks. For usage notes, please refer to the [documentation](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset.html)
|
||||||
|
- 🔥 **[2025.03.20]** The model inference service stress testing now supports generating prompts of specified length using random values. Refer to the [user guide](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/examples.html#using-the-random-dataset) for more details.
|
||||||
|
- 🔥 **[2025.03.13]** Added support for the [LiveCodeBench](https://www.modelscope.cn/datasets/AI-ModelScope/code_generation_lite/summary) code evaluation benchmark, which can be used by specifying `live_code_bench`. Supports evaluating QwQ-32B on LiveCodeBench, refer to the [best practices](https://evalscope.readthedocs.io/en/latest/best_practice/eval_qwq.html).
|
||||||
|
- 🔥 **[2025.03.11]** Added support for the [SimpleQA](https://modelscope.cn/datasets/AI-ModelScope/SimpleQA/summary) and [Chinese SimpleQA](https://modelscope.cn/datasets/AI-ModelScope/Chinese-SimpleQA/summary) evaluation benchmarks. These are used to assess the factual accuracy of models, and you can specify `simple_qa` and `chinese_simpleqa` for use. Support for specifying a judge model is also available. For more details, refer to the [relevant parameter documentation](https://evalscope.readthedocs.io/en/latest/get_started/parameters.html).
|
||||||
|
- 🔥 **[2025.03.07]** Added support for the [QwQ-32B](https://modelscope.cn/models/Qwen/QwQ-32B/summary) model, evaluate the model's reasoning ability and reasoning efficiency, refer to [📖 Best Practices for QwQ-32B Evaluation](https://evalscope.readthedocs.io/en/latest/best_practice/eval_qwq.html) for more details.
|
||||||
|
- 🔥 **[2025.03.04]** Added support for the [SuperGPQA](https://modelscope.cn/datasets/m-a-p/SuperGPQA/summary) dataset, which covers 13 categories, 72 first-level disciplines, and 285 second-level disciplines, totaling 26,529 questions. You can use it by specifying `super_gpqa`.
|
||||||
|
- 🔥 **[2025.03.03]** Added support for evaluating the IQ and EQ of models. Refer to [📖 Best Practices for IQ and EQ Evaluation](https://evalscope.readthedocs.io/en/latest/best_practice/iquiz.html) to find out how smart your AI is!
|
||||||
|
- 🔥 **[2025.02.27]** Added support for evaluating the reasoning efficiency of models. Refer to [📖 Best Practices for Evaluating Thinking Efficiency](https://evalscope.readthedocs.io/en/latest/best_practice/think_eval.html). This implementation is inspired by the works [Overthinking](https://doi.org/10.48550/arXiv.2412.21187) and [Underthinking](https://doi.org/10.48550/arXiv.2501.18585).
|
||||||
|
- 🔥 **[2025.02.25]** Added support for two model inference-related evaluation benchmarks: [MuSR](https://modelscope.cn/datasets/AI-ModelScope/MuSR) and [ProcessBench](https://www.modelscope.cn/datasets/Qwen/ProcessBench/summary). To use them, simply specify `musr` and `process_bench` respectively in the datasets parameter.
|
||||||
|
<details><summary>More</summary>
|
||||||
|
|
||||||
|
- 🔥 **[2025.02.18]** Supports the AIME25 dataset, which contains 15 questions (Grok3 scored 93 on this dataset).
|
||||||
|
- 🔥 **[2025.02.13]** Added support for evaluating DeepSeek distilled models, including AIME24, MATH-500, and GPQA-Diamond datasets,refer to [best practice](https://evalscope.readthedocs.io/en/latest/best_practice/deepseek_r1_distill.html); Added support for specifying the `eval_batch_size` parameter to accelerate model evaluation.
|
||||||
|
- 🔥 **[2025.01.20]** Support for visualizing evaluation results, including single model evaluation results and multi-model comparison, refer to the [📖 Visualizing Evaluation Results](https://evalscope.readthedocs.io/en/latest/get_started/visualization.html) for more details; Added [`iquiz`](https://modelscope.cn/datasets/AI-ModelScope/IQuiz/summary) evaluation example, evaluating the IQ and EQ of the model.
|
||||||
|
- 🔥 **[2025.01.07]** Native backend: Support for model API evaluation is now available. Refer to the [📖 Model API Evaluation Guide](https://evalscope.readthedocs.io/en/latest/get_started/basic_usage.html#api) for more details. Additionally, support for the `ifeval` evaluation benchmark has been added.
|
||||||
|
- 🔥🔥 **[2024.12.31]** Support for adding benchmark evaluations, refer to the [📖 Benchmark Evaluation Addition Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/add_benchmark.html); support for custom mixed dataset evaluations, allowing for more comprehensive model evaluations with less data, refer to the [📖 Mixed Dataset Evaluation Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/collection/index.html).
|
||||||
|
- 🔥 **[2024.12.13]** Model evaluation optimization: no need to pass the `--template-type` parameter anymore; supports starting evaluation with `evalscope eval --args`. Refer to the [📖 User Guide](https://evalscope.readthedocs.io/en/latest/get_started/basic_usage.html) for more details.
|
||||||
|
- 🔥 **[2024.11.26]** The model inference service performance evaluator has been completely refactored: it now supports local inference service startup and Speed Benchmark; asynchronous call error handling has been optimized. For more details, refer to the [📖 User Guide](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/index.html).
|
||||||
|
- 🔥 **[2024.10.31]** The best practice for evaluating Multimodal-RAG has been updated, please check the [📖 Blog](https://evalscope.readthedocs.io/zh-cn/latest/blog/RAG/multimodal_RAG.html#multimodal-rag) for more details.
|
||||||
|
- 🔥 **[2024.10.23]** Supports multimodal RAG evaluation, including the assessment of image-text retrieval using [CLIP_Benchmark](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/clip_benchmark.html), and extends [RAGAS](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/ragas.html) to support end-to-end multimodal metrics evaluation.
|
||||||
|
- 🔥 **[2024.10.8]** Support for RAG evaluation, including independent evaluation of embedding models and rerankers using [MTEB/CMTEB](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/mteb.html), as well as end-to-end evaluation using [RAGAS](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/ragas.html).
|
||||||
|
- 🔥 **[2024.09.18]** Our documentation has been updated to include a blog module, featuring some technical research and discussions related to evaluations. We invite you to [📖 read it](https://evalscope.readthedocs.io/en/refact_readme/blog/index.html).
|
||||||
|
- 🔥 **[2024.09.12]** Support for LongWriter evaluation, which supports 10,000+ word generation. You can use the benchmark [LongBench-Write](evalscope/third_party/longbench_write/README.md) to measure the long output quality as well as the output length.
|
||||||
|
- 🔥 **[2024.08.30]** Support for custom dataset evaluations, including text datasets and multimodal image-text datasets.
|
||||||
|
- 🔥 **[2024.08.20]** Updated the official documentation, including getting started guides, best practices, and FAQs. Feel free to [📖read it here](https://evalscope.readthedocs.io/en/latest/)!
|
||||||
|
- 🔥 **[2024.08.09]** Simplified the installation process, allowing for pypi installation of vlmeval dependencies; optimized the multimodal model evaluation experience, achieving up to 10x acceleration based on the OpenAI API evaluation chain.
|
||||||
|
- 🔥 **[2024.07.31]** Important change: The package name `llmuses` has been changed to `evalscope`. Please update your code accordingly.
|
||||||
|
- 🔥 **[2024.07.26]** Support for **VLMEvalKit** as a third-party evaluation framework to initiate multimodal model evaluation tasks.
|
||||||
|
- 🔥 **[2024.06.29]** Support for **OpenCompass** as a third-party evaluation framework, which we have encapsulated at a higher level, supporting pip installation and simplifying evaluation task configuration.
|
||||||
|
- 🔥 **[2024.06.13]** EvalScope seamlessly integrates with the fine-tuning framework SWIFT, providing full-chain support from LLM training to evaluation.
|
||||||
|
- 🔥 **[2024.06.13]** Integrated the Agent evaluation dataset ToolBench.
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## 🛠️ Installation
|
||||||
|
### Method 1: Install Using pip
|
||||||
|
We recommend using conda to manage your environment and installing dependencies with pip:
|
||||||
|
|
||||||
|
1. Create a conda environment (optional)
|
||||||
|
```shell
|
||||||
|
# It is recommended to use Python 3.10
|
||||||
|
conda create -n evalscope python=3.10
|
||||||
|
# Activate the conda environment
|
||||||
|
conda activate evalscope
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install dependencies using pip
|
||||||
|
```shell
|
||||||
|
pip install evalscope # Install Native backend (default)
|
||||||
|
# Additional options
|
||||||
|
pip install 'evalscope[opencompass]' # Install OpenCompass backend
|
||||||
|
pip install 'evalscope[vlmeval]' # Install VLMEvalKit backend
|
||||||
|
pip install 'evalscope[rag]' # Install RAGEval backend
|
||||||
|
pip install 'evalscope[perf]' # Install dependencies for the model performance testing module
|
||||||
|
pip install 'evalscope[app]' # Install dependencies for visualization
|
||||||
|
pip install 'evalscope[all]' # Install all backends (Native, OpenCompass, VLMEvalKit, RAGEval)
|
||||||
|
```
|
||||||
|
|
||||||
|
> [!WARNING]
|
||||||
|
> As the project has been renamed to `evalscope`, for versions `v0.4.3` or earlier, you can install using the following command:
|
||||||
|
> ```shell
|
||||||
|
> pip install llmuses<=0.4.3
|
||||||
|
> ```
|
||||||
|
> To import relevant dependencies using `llmuses`:
|
||||||
|
> ``` python
|
||||||
|
> from llmuses import ...
|
||||||
|
> ```
|
||||||
|
|
||||||
|
### Method 2: Install from Source
|
||||||
|
1. Download the source code
|
||||||
|
```shell
|
||||||
|
git clone https://github.com/modelscope/evalscope.git
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install dependencies
|
||||||
|
```shell
|
||||||
|
cd evalscope/
|
||||||
|
pip install -e . # Install Native backend
|
||||||
|
# Additional options
|
||||||
|
pip install -e '.[opencompass]' # Install OpenCompass backend
|
||||||
|
pip install -e '.[vlmeval]' # Install VLMEvalKit backend
|
||||||
|
pip install -e '.[rag]' # Install RAGEval backend
|
||||||
|
pip install -e '.[perf]' # Install Perf dependencies
|
||||||
|
pip install -e '.[app]' # Install visualization dependencies
|
||||||
|
pip install -e '.[all]' # Install all backends (Native, OpenCompass, VLMEvalKit, RAGEval)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## 🚀 Quick Start
|
||||||
|
|
||||||
|
To evaluate a model on specified datasets using default configurations, this framework supports two ways to initiate evaluation tasks: using the command line or using Python code.
|
||||||
|
|
||||||
|
### Method 1. Using Command Line
|
||||||
|
|
||||||
|
Execute the `eval` command in any directory:
|
||||||
|
```bash
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen2.5-0.5B-Instruct \
|
||||||
|
--datasets gsm8k arc \
|
||||||
|
--limit 5
|
||||||
|
```
|
||||||
|
|
||||||
|
### Method 2. Using Python Code
|
||||||
|
|
||||||
|
When using Python code for evaluation, you need to submit the evaluation task using the `run_task` function, passing a `TaskConfig` as a parameter. It can also be a Python dictionary, yaml file path, or json file path, for example:
|
||||||
|
|
||||||
|
**Using Python Dictionary**
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
task_cfg = {
|
||||||
|
'model': 'Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
'datasets': ['gsm8k', 'arc'],
|
||||||
|
'limit': 5
|
||||||
|
}
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
<details><summary>More Startup Methods</summary>
|
||||||
|
|
||||||
|
**Using `TaskConfig`**
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
from evalscope.config import TaskConfig
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
datasets=['gsm8k', 'arc'],
|
||||||
|
limit=5
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
**Using `yaml` file**
|
||||||
|
|
||||||
|
`config.yaml`:
|
||||||
|
```yaml
|
||||||
|
model: Qwen/Qwen2.5-0.5B-Instruct
|
||||||
|
datasets:
|
||||||
|
- gsm8k
|
||||||
|
- arc
|
||||||
|
limit: 5
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg="config.yaml")
|
||||||
|
```
|
||||||
|
|
||||||
|
**Using `json` file**
|
||||||
|
|
||||||
|
`config.json`:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"model": "Qwen/Qwen2.5-0.5B-Instruct",
|
||||||
|
"datasets": ["gsm8k", "arc"],
|
||||||
|
"limit": 5
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg="config.json")
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
|
||||||
|
### Basic Parameter
|
||||||
|
- `--model`: Specifies the `model_id` of the model in [ModelScope](https://modelscope.cn/), which can be automatically downloaded, e.g., [Qwen/Qwen2.5-0.5B-Instruct](https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct/summary); or use the local path of the model, e.g., `/path/to/model`
|
||||||
|
- `--datasets`: Dataset names, supports inputting multiple datasets separated by spaces. Datasets will be automatically downloaded from modelscope. For supported datasets, refer to the [Dataset List](https://evalscope.readthedocs.io/en/latest/get_started/supported_dataset.html)
|
||||||
|
- `--limit`: Maximum amount of evaluation data for each dataset. If not specified, it defaults to evaluating all data. Can be used for quick validation
|
||||||
|
|
||||||
|
### Output Results
|
||||||
|
```text
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Model Name | Dataset Name | Metric Name | Category Name | Subset Name | Num | Score |
|
||||||
|
+=======================+================+=================+=================+===============+=======+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | gsm8k | AverageAccuracy | default | main | 5 | 0.4 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Easy | 5 | 0.8 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Challenge | 5 | 0.4 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## 📈 Visualization of Evaluation Results
|
||||||
|
|
||||||
|
1. Install the dependencies required for visualization, including gradio, plotly, etc.
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope[app]'
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Start the Visualization Service
|
||||||
|
|
||||||
|
Run the following command to start the visualization service.
|
||||||
|
```bash
|
||||||
|
evalscope app
|
||||||
|
```
|
||||||
|
You can access the visualization service in the browser if the following output appears.
|
||||||
|
```text
|
||||||
|
* Running on local URL: http://127.0.0.1:7861
|
||||||
|
|
||||||
|
To create a public link, set `share=True` in `launch()`.
|
||||||
|
```
|
||||||
|
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/en/get_started/images/setting.png" alt="Setting" style="width: 75%;" />
|
||||||
|
<p>Setting Interface</p>
|
||||||
|
</td>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/en/get_started/images/model_compare.png" alt="Model Compare" style="width: 100%;" />
|
||||||
|
<p>Model Comparison</p>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/en/get_started/images/report_overview.png" alt="Report Overview" style="width: 100%;" />
|
||||||
|
<p>Report Overview</p>
|
||||||
|
</td>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/en/get_started/images/report_details.png" alt="Report Details" style="width: 80%;" />
|
||||||
|
<p>Report Details</p>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
For more details, refer to: [📖 Visualization of Evaluation Results](https://evalscope.readthedocs.io/en/latest/get_started/visualization.html)
|
||||||
|
|
||||||
|
## 🌐 Evaluation of Specified Model API
|
||||||
|
|
||||||
|
Specify the model API service address (api_url) and API Key (api_key) to evaluate the deployed model API service. In this case, the `eval-type` parameter must be specified as `service`, for example:
|
||||||
|
|
||||||
|
For example, to launch a model service using [vLLM](https://github.com/vllm-project/vllm):
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export VLLM_USE_MODELSCOPE=True && python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-0.5B-Instruct --served-model-name qwen2.5 --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
Then, you can use the following command to evaluate the model API service:
|
||||||
|
```shell
|
||||||
|
evalscope eval \
|
||||||
|
--model qwen2.5 \
|
||||||
|
--api-url http://127.0.0.1:8801/v1 \
|
||||||
|
--api-key EMPTY \
|
||||||
|
--eval-type service \
|
||||||
|
--datasets gsm8k \
|
||||||
|
--limit 10
|
||||||
|
```
|
||||||
|
|
||||||
|
## ⚙️ Custom Parameter Evaluation
|
||||||
|
|
||||||
|
For more customized evaluations, such as customizing model parameters or dataset parameters, you can use the following command. The evaluation startup method is the same as simple evaluation. Below shows how to start the evaluation using the `eval` command:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen3-0.6B \
|
||||||
|
--model-args '{"revision": "master", "precision": "torch.float16", "device_map": "auto"}' \
|
||||||
|
--generation-config '{"do_sample":true,"temperature":0.6,"max_new_tokens":512,"chat_template_kwargs":{"enable_thinking": false}}' \
|
||||||
|
--dataset-args '{"gsm8k": {"few_shot_num": 0, "few_shot_random": false}}' \
|
||||||
|
--datasets gsm8k \
|
||||||
|
--limit 10
|
||||||
|
```
|
||||||
|
|
||||||
|
### Parameter Description
|
||||||
|
- `--model-args`: Model loading parameters, passed as a JSON string:
|
||||||
|
- `revision`: Model version
|
||||||
|
- `precision`: Model precision
|
||||||
|
- `device_map`: Device allocation for the model
|
||||||
|
- `--generation-config`: Generation parameters, passed as a JSON string and parsed as a dictionary:
|
||||||
|
- `do_sample`: Whether to use sampling
|
||||||
|
- `temperature`: Generation temperature
|
||||||
|
- `max_new_tokens`: Maximum length of generated tokens
|
||||||
|
- `chat_template_kwargs`: Model inference template parameters
|
||||||
|
- `--dataset-args`: Settings for the evaluation dataset, passed as a JSON string where the key is the dataset name and the value is the parameters. Note that these need to correspond one-to-one with the values in the `--datasets` parameter:
|
||||||
|
- `few_shot_num`: Number of few-shot examples
|
||||||
|
- `few_shot_random`: Whether to randomly sample few-shot data; if not set, defaults to `true`
|
||||||
|
|
||||||
|
Reference: [Full Parameter Description](https://evalscope.readthedocs.io/en/latest/get_started/parameters.html)
|
||||||
|
|
||||||
|
|
||||||
|
## Evaluation Backend
|
||||||
|
EvalScope supports using third-party evaluation frameworks to initiate evaluation tasks, which we call Evaluation Backend. Currently supported Evaluation Backend includes:
|
||||||
|
- **Native**: EvalScope's own **default evaluation framework**, supporting various evaluation modes including single model evaluation, arena mode, and baseline model comparison mode.
|
||||||
|
- [OpenCompass](https://github.com/open-compass/opencompass): Initiate OpenCompass evaluation tasks through EvalScope. Lightweight, easy to customize, supports seamless integration with the LLM fine-tuning framework ms-swift. [📖 User Guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/opencompass_backend.html)
|
||||||
|
- [VLMEvalKit](https://github.com/open-compass/VLMEvalKit): Initiate VLMEvalKit multimodal evaluation tasks through EvalScope. Supports various multimodal models and datasets, and offers seamless integration with the LLM fine-tuning framework ms-swift. [📖 User Guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/vlmevalkit_backend.html)
|
||||||
|
- **RAGEval**: Initiate RAG evaluation tasks through EvalScope, supporting independent evaluation of embedding models and rerankers using [MTEB/CMTEB](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/mteb.html), as well as end-to-end evaluation using [RAGAS](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/ragas.html): [📖 User Guide](https://evalscope.readthedocs.io/en/latest/user_guides/backend/rageval_backend/index.html)
|
||||||
|
- **ThirdParty**: Third-party evaluation tasks, such as [ToolBench](https://evalscope.readthedocs.io/en/latest/third_party/toolbench.html) and [LongBench-Write](https://evalscope.readthedocs.io/en/latest/third_party/longwriter.html).
|
||||||
|
|
||||||
|
|
||||||
|
## 📈 Model Serving Performance Evaluation
|
||||||
|
A stress testing tool focused on large language models, which can be customized to support various dataset formats and different API protocol formats.
|
||||||
|
|
||||||
|
Reference: Performance Testing [📖 User Guide](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/index.html)
|
||||||
|
|
||||||
|
**Output example**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
**Supports wandb for recording results**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**Supports swanlab for recording results**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**Supports Speed Benchmark**
|
||||||
|
|
||||||
|
It supports speed testing and provides speed benchmarks similar to those found in the [official Qwen](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html) reports:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Speed Benchmark Results:
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
| Prompt Tokens | Speed(tokens/s) | GPU Memory(GB) |
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
| 1 | 50.69 | 0.97 |
|
||||||
|
| 6144 | 51.36 | 1.23 |
|
||||||
|
| 14336 | 49.93 | 1.59 |
|
||||||
|
| 30720 | 49.56 | 2.34 |
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## 🖊️ Custom Dataset Evaluation
|
||||||
|
EvalScope supports custom dataset evaluation. For detailed information, please refer to the Custom Dataset Evaluation [📖User Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/custom_dataset/index.html)
|
||||||
|
|
||||||
|
|
||||||
|
## ⚔️ Arena Mode
|
||||||
|
|
||||||
|
Arena mode allows you to configure multiple candidate models and specify a baseline model. Evaluation is performed by pairwise battles between each candidate model and the baseline model, with the final output including each model's win rate and ranking. This method is suitable for comparative evaluation among multiple models, providing an intuitive reflection of each model's strengths and weaknesses. Refer to: Arena Mode [📖 User Guide](https://evalscope.readthedocs.io/en/latest/user_guides/arena.html)
|
||||||
|
|
||||||
|
```text
|
||||||
|
Model WinRate (%) CI (%)
|
||||||
|
------------ ------------- ---------------
|
||||||
|
qwen2.5-72b 69.3 (-13.3 / +12.2)
|
||||||
|
qwen2.5-7b 50 (+0.0 / +0.0)
|
||||||
|
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 👷♂️ Contribution
|
||||||
|
|
||||||
|
EvalScope, as the official evaluation tool of [ModelScope](https://modelscope.cn), is continuously optimizing its benchmark evaluation features! We invite you to refer to the [Contribution Guide](https://evalscope.readthedocs.io/en/latest/advanced_guides/add_benchmark.html) to easily add your own evaluation benchmarks and share your contributions with the community. Let’s work together to support the growth of EvalScope and make our tools even better! Join us now!
|
||||||
|
|
||||||
|
<a href="https://github.com/modelscope/evalscope/graphs/contributors" target="_blank">
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<th colspan="2">
|
||||||
|
<br><img src="https://contrib.rocks/image?repo=modelscope/evalscope"><br><br>
|
||||||
|
</th>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
</a>
|
||||||
|
|
||||||
|
## 🔜 Roadmap
|
||||||
|
- [x] Support for better evaluation report visualization
|
||||||
|
- [x] Support for mixed evaluations across multiple datasets
|
||||||
|
- [x] RAG evaluation
|
||||||
|
- [x] VLM evaluation
|
||||||
|
- [x] Agents evaluation
|
||||||
|
- [x] vLLM
|
||||||
|
- [ ] Distributed evaluating
|
||||||
|
- [x] Multi-modal evaluation
|
||||||
|
- [ ] Benchmarks
|
||||||
|
- [x] BFCL-v3
|
||||||
|
- [x] GPQA
|
||||||
|
- [x] MBPP
|
||||||
|
|
||||||
|
|
||||||
|
## Star History
|
||||||
|
|
||||||
|
[](https://star-history.com/#modelscope/evalscope&Date)
|
||||||
|
|
@ -0,0 +1,488 @@
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<br>
|
||||||
|
<img src="docs/en/_static/images/evalscope_logo.png"/>
|
||||||
|
<br>
|
||||||
|
<p>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
中文   |   <a href="README.md">English</a>  
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://img.shields.io/badge/python-%E2%89%A53.9-5be.svg">
|
||||||
|
<a href="https://badge.fury.io/py/evalscope"><img src="https://badge.fury.io/py/evalscope.svg" alt="PyPI version" height="18"></a>
|
||||||
|
<a href="https://pypi.org/project/evalscope"><img alt="PyPI - Downloads" src="https://static.pepy.tech/badge/evalscope"></a>
|
||||||
|
<a href="https://github.com/modelscope/evalscope/pulls"><img src="https://img.shields.io/badge/PR-welcome-55EB99.svg"></a>
|
||||||
|
<a href='https://evalscope.readthedocs.io/zh-cn/latest/?badge=latest'><img src='https://readthedocs.org/projects/evalscope/badge/?version=latest' alt='Documentation Status' /></a>
|
||||||
|
<p>
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://evalscope.readthedocs.io/zh-cn/latest/"> 📖 中文文档</a>   |   <a href="https://evalscope.readthedocs.io/en/latest/"> 📖 English Documents</a>
|
||||||
|
<p>
|
||||||
|
|
||||||
|
|
||||||
|
> ⭐ 如果你喜欢这个项目,请点击右上角的 "Star" 按钮支持我们。你的支持是我们前进的动力!
|
||||||
|
|
||||||
|
## 📋 目录
|
||||||
|
- [简介](#-简介)
|
||||||
|
- [新闻](#-新闻)
|
||||||
|
- [环境准备](#️-环境准备)
|
||||||
|
- [快速开始](#-快速开始)
|
||||||
|
- [其他评测后端](#-其他评测后端)
|
||||||
|
- [自定义数据集评测](#-自定义数据集评测)
|
||||||
|
- [竞技场模式](#-竞技场模式)
|
||||||
|
- [性能评测工具](#-推理性能评测工具)
|
||||||
|
- [贡献](#️-贡献)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 📝 简介
|
||||||
|
|
||||||
|
EvalScope 是[魔搭社区](https://modelscope.cn/)倾力打造的模型评测与性能基准测试框架,为您的模型评估需求提供一站式解决方案。无论您在开发什么类型的模型,EvalScope 都能满足您的需求:
|
||||||
|
|
||||||
|
- 🧠 大语言模型
|
||||||
|
- 🎨 多模态模型
|
||||||
|
- 🔍 Embedding 模型
|
||||||
|
- 🏆 Reranker 模型
|
||||||
|
- 🖼️ CLIP 模型
|
||||||
|
- 🎭 AIGC模型(图生文/视频)
|
||||||
|
- ...以及更多!
|
||||||
|
|
||||||
|
EvalScope 不仅仅是一个评测工具,它是您模型优化之旅的得力助手:
|
||||||
|
|
||||||
|
- 🏅 内置多个业界认可的测试基准和评测指标:MMLU、CMMLU、C-Eval、GSM8K 等。
|
||||||
|
- 📊 模型推理性能压测:确保您的模型在实际应用中表现出色。
|
||||||
|
- 🚀 与 [ms-swift](https://github.com/modelscope/ms-swift) 训练框架无缝集成,一键发起评测,为您的模型开发提供从训练到评估的全链路支持。
|
||||||
|
|
||||||
|
下面是 EvalScope 的整体架构图:
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://sail-moe.oss-cn-hangzhou.aliyuncs.com/yunlin/images/evalscope/doc/EvalScope%E6%9E%B6%E6%9E%84%E5%9B%BE.png" style="width: 70%;">
|
||||||
|
<br>EvalScope 整体架构图.
|
||||||
|
</p>
|
||||||
|
|
||||||
|
<details><summary>架构介绍</summary>
|
||||||
|
|
||||||
|
1. 输入层
|
||||||
|
- **模型来源**:API模型(OpenAI API)、本地模型(ModelScope)
|
||||||
|
- **数据集**:标准评测基准(MMLU/GSM8k等)、自定义数据(MCQ/QA)
|
||||||
|
|
||||||
|
2. 核心功能
|
||||||
|
- **多后端评估**
|
||||||
|
- 原生后端:LLM/VLM/Embedding/T2I模型统一评估
|
||||||
|
- 集成框架:OpenCompass/MTEB/VLMEvalKit/RAGAS
|
||||||
|
|
||||||
|
- **性能监控**
|
||||||
|
- 模型插件:支持多种模型服务API
|
||||||
|
- 数据插件:支持多种数据格式
|
||||||
|
- 指标追踪:TTFT/TPOP/稳定性 等指标
|
||||||
|
|
||||||
|
- **工具扩展**
|
||||||
|
- 集成:Tool-Bench/Needle-in-a-Haystack/BFCL-v3
|
||||||
|
|
||||||
|
3. 输出层
|
||||||
|
- **结构化报告**: 支持JSON/Table/Logs
|
||||||
|
- **可视化平台**:支持Gradio/Wandb/SwanLab
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## ☎ 用户群
|
||||||
|
|
||||||
|
请扫描下面的二维码来加入我们的交流群:
|
||||||
|
|
||||||
|
[Discord Group](https://discord.com/invite/D27yfEFVz5) | 微信群 | 钉钉群
|
||||||
|
:-------------------------:|:-------------------------:|:-------------------------:
|
||||||
|
<img src="docs/asset/discord_qr.jpg" width="160" height="160"> | <img src="docs/asset/wechat.png" width="160" height="160"> | <img src="docs/asset/dingding.png" width="160" height="160">
|
||||||
|
|
||||||
|
|
||||||
|
## 🎉 新闻
|
||||||
|
|
||||||
|
- 🔥 **[2025.07.03]** 重构了竞技场模式,支持自定义模型对战,输出模型排行榜,以及对战结果可视化,使用[参考](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/arena.html)。
|
||||||
|
- 🔥 **[2025.06.28]** 优化自定义数据集评测,支持无参考答案评测;优化LLM裁判使用,预置“无参考答案直接打分” 和 “判断答案是否与参考答案一致”两种模式,使用[参考](https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/custom_dataset/llm.html#qa)
|
||||||
|
- 🔥 **[2025.06.19]** 新增支持[BFCL-v3](https://modelscope.cn/datasets/AI-ModelScope/bfcl_v3)评测基准,用于评测模型在多种场景下的函数调用能力,使用[参考](https://evalscope.readthedocs.io/zh-cn/latest/third_party/bfcl_v3.html)。
|
||||||
|
- 🔥 **[2025.06.02]** 新增支持大海捞针测试(Needle-in-a-Haystack),指定`needle_haystack`即可进行测试,并在`outputs/reports`文件夹下生成对应的heatmap,直观展现模型性能,使用[参考](https://evalscope.readthedocs.io/zh-cn/latest/third_party/needle_haystack.html)。
|
||||||
|
- 🔥 **[2025.05.29]** 新增支持[DocMath](https://modelscope.cn/datasets/yale-nlp/DocMath-Eval/summary)和[FRAMES](https://modelscope.cn/datasets/iic/frames/summary)两个长文档评测基准,使用注意事项请查看[文档](https://evalscope.readthedocs.io/zh-cn/latest/get_started/supported_dataset.html)
|
||||||
|
- 🔥 **[2025.05.16]** 模型服务性能压测支持设置多种并发,并输出性能压测报告,[参考示例](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/quick_start.html#id3)。
|
||||||
|
- 🔥 **[2025.05.13]** 新增支持[ToolBench-Static](https://modelscope.cn/datasets/AI-ModelScope/ToolBench-Static)数据集,评测模型的工具调用能力,参考[使用文档](https://evalscope.readthedocs.io/zh-cn/latest/third_party/toolbench.html);支持[DROP](https://modelscope.cn/datasets/AI-ModelScope/DROP/dataPeview)和[Winogrande](https://modelscope.cn/datasets/AI-ModelScope/winogrande_val)评测基准,评测模型的推理能力。
|
||||||
|
- 🔥 **[2025.04.29]** 新增Qwen3评测最佳实践,[欢迎阅读📖](https://evalscope.readthedocs.io/zh-cn/latest/best_practice/qwen3.html)
|
||||||
|
- 🔥 **[2025.04.27]** 支持文生图评测:支持MPS、HPSv2.1Score等8个指标,支持EvalMuse、GenAI-Bench等评测基准,参考[使用文档](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/aigc/t2i.html)
|
||||||
|
- 🔥 **[2025.04.10]** 模型服务压测工具支持`/v1/completions`端点(也是vLLM基准测试的默认端点)
|
||||||
|
- 🔥 **[2025.04.08]** 支持OpenAI API兼容的Embedding模型服务评测,查看[使用文档](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/mteb.html#configure-evaluation-parameters)
|
||||||
|
- 🔥 **[2025.03.27]** 新增支持[AlpacaEval](https://www.modelscope.cn/datasets/AI-ModelScope/alpaca_eval/dataPeview)和[ArenaHard](https://modelscope.cn/datasets/AI-ModelScope/arena-hard-auto-v0.1/summary)评测基准,使用注意事项请查看[文档](https://evalscope.readthedocs.io/zh-cn/latest/get_started/supported_dataset.html)
|
||||||
|
- 🔥 **[2025.03.20]** 模型推理服务压测支持random生成指定范围长度的prompt,参考[使用指南](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/examples.html#random)
|
||||||
|
- 🔥 **[2025.03.13]** 新增支持[LiveCodeBench](https://www.modelscope.cn/datasets/AI-ModelScope/code_generation_lite/summary)代码评测基准,指定`live_code_bench`即可使用;支持QwQ-32B 在LiveCodeBench上评测,参考[最佳实践](https://evalscope.readthedocs.io/zh-cn/latest/best_practice/eval_qwq.html)。
|
||||||
|
- 🔥 **[2025.03.11]** 新增支持[SimpleQA](https://modelscope.cn/datasets/AI-ModelScope/SimpleQA/summary)和[Chinese SimpleQA](https://modelscope.cn/datasets/AI-ModelScope/Chinese-SimpleQA/summary)评测基准,用与评测模型的事实正确性,指定`simple_qa`和`chinese_simpleqa`使用。同时支持指定裁判模型,参考[相关参数说明](https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html)。
|
||||||
|
- 🔥 **[2025.03.07]** 新增QwQ-32B模型评测最佳实践,评测了模型的推理能力以及推理效率,参考[📖QwQ-32B模型评测最佳实践](https://evalscope.readthedocs.io/zh-cn/latest/best_practice/eval_qwq.html)。
|
||||||
|
- 🔥 **[2025.03.04]** 新增支持[SuperGPQA](https://modelscope.cn/datasets/m-a-p/SuperGPQA/summary)数据集,其覆盖 13 个门类、72 个一级学科和 285 个二级学科,共 26,529 个问题,指定`super_gpqa`即可使用。
|
||||||
|
- 🔥 **[2025.03.03]** 新增支持评测模型的智商和情商,参考[📖智商和情商评测最佳实践](https://evalscope.readthedocs.io/zh-cn/latest/best_practice/iquiz.html),来测测你家的AI有多聪明?
|
||||||
|
- 🔥 **[2025.02.27]** 新增支持评测推理模型的思考效率,参考[📖思考效率评测最佳实践](https://evalscope.readthedocs.io/zh-cn/latest/best_practice/think_eval.html),该实现参考了[Overthinking](https://doi.org/10.48550/arXiv.2412.21187) 和 [Underthinking](https://doi.org/10.48550/arXiv.2501.18585)两篇工作。
|
||||||
|
- 🔥 **[2025.02.25]** 新增支持[MuSR](https://modelscope.cn/datasets/AI-ModelScope/MuSR)和[ProcessBench](https://www.modelscope.cn/datasets/Qwen/ProcessBench/summary)两个模型推理相关评测基准,datasets分别指定`musr`和`process_bench`即可使用。
|
||||||
|
<details> <summary>更多</summary>
|
||||||
|
|
||||||
|
- 🔥 **[2025.02.18]** 支持AIME25数据集,包含15道题目(Grok3 在该数据集上得分为93分)
|
||||||
|
- 🔥 **[2025.02.13]** 支持DeepSeek蒸馏模型评测,包括AIME24, MATH-500, GPQA-Diamond数据集,参考[最佳实践](https://evalscope.readthedocs.io/zh-cn/latest/best_practice/deepseek_r1_distill.html);支持指定`eval_batch_size`参数,加速模型评测
|
||||||
|
- 🔥 **[2025.01.20]** 支持可视化评测结果,包括单模型评测结果和多模型评测结果对比,参考[📖可视化评测结果](https://evalscope.readthedocs.io/zh-cn/latest/get_started/visualization.html);新增[`iquiz`](https://modelscope.cn/datasets/AI-ModelScope/IQuiz/summary)评测样例,评测模型的IQ和EQ。
|
||||||
|
- 🔥 **[2025.01.07]** Native backend: 支持模型API评测,参考[📖模型API评测指南](https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html#api);新增支持`ifeval`评测基准。
|
||||||
|
- 🔥🔥 **[2024.12.31]** 支持基准评测添加,参考[📖基准评测添加指南](https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/add_benchmark.html);支持自定义混合数据集评测,用更少的数据,更全面的评测模型,参考[📖混合数据集评测指南](https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/collection/index.html)
|
||||||
|
- 🔥 **[2024.12.13]** 模型评测优化,不再需要传递`--template-type`参数;支持`evalscope eval --args`启动评测,参考[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html)
|
||||||
|
- 🔥 **[2024.11.26]** 模型推理压测工具重构完成:支持本地启动推理服务、支持Speed Benchmark;优化异步调用错误处理,参考[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/index.html)
|
||||||
|
- 🔥 **[2024.10.31]** 多模态RAG评测最佳实践发布,参考[📖博客](https://evalscope.readthedocs.io/zh-cn/latest/blog/RAG/multimodal_RAG.html#multimodal-rag)
|
||||||
|
- 🔥 **[2024.10.23]** 支持多模态RAG评测,包括[CLIP_Benchmark](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/clip_benchmark.html)评测图文检索器,以及扩展了[RAGAS](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/ragas.html)以支持端到端多模态指标评测。
|
||||||
|
- 🔥 **[2024.10.8]** 支持RAG评测,包括使用[MTEB/CMTEB](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/mteb.html)进行embedding模型和reranker的独立评测,以及使用[RAGAS](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/ragas.html)进行端到端评测。
|
||||||
|
- 🔥 **[2024.09.18]** 我们的文档增加了博客模块,包含一些评测相关的技术调研和分享,欢迎[📖阅读](https://evalscope.readthedocs.io/zh-cn/latest/blog/index.html)
|
||||||
|
- 🔥 **[2024.09.12]** 支持 LongWriter 评测,您可以使用基准测试 [LongBench-Write](evalscope/third_party/longbench_write/README.md) 来评测长输出的质量以及输出长度。
|
||||||
|
- 🔥 **[2024.08.30]** 支持自定义数据集评测,包括文本数据集和多模态图文数据集。
|
||||||
|
- 🔥 **[2024.08.20]** 更新了官方文档,包括快速上手、最佳实践和常见问题等,欢迎[📖阅读](https://evalscope.readthedocs.io/zh-cn/latest/)。
|
||||||
|
- 🔥 **[2024.08.09]** 简化安装方式,支持pypi安装vlmeval相关依赖;优化多模态模型评测体验,基于OpenAI API方式的评测链路,最高加速10倍。
|
||||||
|
- 🔥 **[2024.07.31]** 重要修改:`llmuses`包名修改为`evalscope`,请同步修改您的代码。
|
||||||
|
- 🔥 **[2024.07.26]** 支持**VLMEvalKit**作为第三方评测框架,发起多模态模型评测任务。
|
||||||
|
- 🔥 **[2024.06.29]** 支持**OpenCompass**作为第三方评测框架,我们对其进行了高级封装,支持pip方式安装,简化了评测任务配置。
|
||||||
|
- 🔥 **[2024.06.13]** EvalScope与微调框架SWIFT进行无缝对接,提供LLM从训练到评测的全链路支持 。
|
||||||
|
- 🔥 **[2024.06.13]** 接入Agent评测集ToolBench。
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## 🛠️ 环境准备
|
||||||
|
### 方式1. 使用pip安装
|
||||||
|
我们推荐使用conda来管理环境,并使用pip安装依赖:
|
||||||
|
1. 创建conda环境 (可选)
|
||||||
|
```shell
|
||||||
|
# 建议使用 python 3.10
|
||||||
|
conda create -n evalscope python=3.10
|
||||||
|
|
||||||
|
# 激活conda环境
|
||||||
|
conda activate evalscope
|
||||||
|
```
|
||||||
|
2. pip安装依赖
|
||||||
|
```shell
|
||||||
|
pip install evalscope # 安装 Native backend (默认)
|
||||||
|
# 额外选项
|
||||||
|
pip install 'evalscope[opencompass]' # 安装 OpenCompass backend
|
||||||
|
pip install 'evalscope[vlmeval]' # 安装 VLMEvalKit backend
|
||||||
|
pip install 'evalscope[rag]' # 安装 RAGEval backend
|
||||||
|
pip install 'evalscope[perf]' # 安装 模型压测模块 依赖
|
||||||
|
pip install 'evalscope[app]' # 安装 可视化 相关依赖
|
||||||
|
pip install 'evalscope[all]' # 安装所有 backends (Native, OpenCompass, VLMEvalKit, RAGEval)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
> [!WARNING]
|
||||||
|
> 由于项目更名为`evalscope`,对于`v0.4.3`或更早版本,您可以使用以下命令安装:
|
||||||
|
> ```shell
|
||||||
|
> pip install llmuses<=0.4.3
|
||||||
|
> ```
|
||||||
|
> 使用`llmuses`导入相关依赖:
|
||||||
|
> ``` python
|
||||||
|
> from llmuses import ...
|
||||||
|
> ```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 方式2. 使用源码安装
|
||||||
|
1. 下载源码
|
||||||
|
```shell
|
||||||
|
git clone https://github.com/modelscope/evalscope.git
|
||||||
|
```
|
||||||
|
2. 安装依赖
|
||||||
|
```shell
|
||||||
|
cd evalscope/
|
||||||
|
|
||||||
|
pip install -e . # 安装 Native backend
|
||||||
|
# 额外选项
|
||||||
|
pip install -e '.[opencompass]' # 安装 OpenCompass backend
|
||||||
|
pip install -e '.[vlmeval]' # 安装 VLMEvalKit backend
|
||||||
|
pip install -e '.[rag]' # 安装 RAGEval backend
|
||||||
|
pip install -e '.[perf]' # 安装 模型压测模块 依赖
|
||||||
|
pip install -e '.[app]' # 安装 可视化 相关依赖
|
||||||
|
pip install -e '.[all]' # 安装所有 backends (Native, OpenCompass, VLMEvalKit, RAGEval)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## 🚀 快速开始
|
||||||
|
|
||||||
|
在指定的若干数据集上使用默认配置评测某个模型,本框架支持两种启动评测任务的方式:使用命令行启动或使用Python代码启动评测任务。
|
||||||
|
|
||||||
|
### 方式1. 使用命令行
|
||||||
|
|
||||||
|
在任意路径下执行`eval`命令:
|
||||||
|
```bash
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen2.5-0.5B-Instruct \
|
||||||
|
--datasets gsm8k arc \
|
||||||
|
--limit 5
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
### 方式2. 使用Python代码
|
||||||
|
|
||||||
|
使用python代码进行评测时需要用`run_task`函数提交评测任务,传入一个`TaskConfig`作为参数,也可以为python字典、yaml文件路径或json文件路径,例如:
|
||||||
|
|
||||||
|
**使用Python 字典**
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
task_cfg = {
|
||||||
|
'model': 'Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
'datasets': ['gsm8k', 'arc'],
|
||||||
|
'limit': 5
|
||||||
|
}
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
<details><summary>更多启动方式</summary>
|
||||||
|
|
||||||
|
**使用`TaskConfig`**
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
from evalscope.config import TaskConfig
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
datasets=['gsm8k', 'arc'],
|
||||||
|
limit=5
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
**使用`yaml`文件**
|
||||||
|
|
||||||
|
`config.yaml`:
|
||||||
|
```yaml
|
||||||
|
model: Qwen/Qwen2.5-0.5B-Instruct
|
||||||
|
datasets:
|
||||||
|
- gsm8k
|
||||||
|
- arc
|
||||||
|
limit: 5
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg="config.yaml")
|
||||||
|
```
|
||||||
|
|
||||||
|
**使用`json`文件**
|
||||||
|
|
||||||
|
`config.json`:
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"model": "Qwen/Qwen2.5-0.5B-Instruct",
|
||||||
|
"datasets": ["gsm8k", "arc"],
|
||||||
|
"limit": 5
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg="config.json")
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
|
||||||
|
### 基本参数说明
|
||||||
|
- `--model`: 指定了模型在[ModelScope](https://modelscope.cn/)中的`model_id`,可自动下载,例如[Qwen/Qwen2.5-0.5B-Instruct](https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct/summary);也可使用模型的本地路径,例如`/path/to/model`
|
||||||
|
- `--datasets`: 数据集名称,支持输入多个数据集,使用空格分开,数据集将自动从modelscope下载,支持的数据集参考[数据集列表](https://evalscope.readthedocs.io/zh-cn/latest/get_started/supported_dataset.html)
|
||||||
|
- `--limit`: 每个数据集最大评测数据量,不填写则默认为全部评测,可用于快速验证
|
||||||
|
|
||||||
|
### 输出结果
|
||||||
|
```text
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Model Name | Dataset Name | Metric Name | Category Name | Subset Name | Num | Score |
|
||||||
|
+=======================+================+=================+=================+===============+=======+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | gsm8k | AverageAccuracy | default | main | 5 | 0.4 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Easy | 5 | 0.8 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Challenge | 5 | 0.4 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## 📈 可视化评测结果
|
||||||
|
|
||||||
|
1. 安装可视化所需的依赖,包括gradio、plotly等。
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope[app]'
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 启动可视化服务
|
||||||
|
|
||||||
|
运行如下命令启动可视化服务。
|
||||||
|
```bash
|
||||||
|
evalscope app
|
||||||
|
```
|
||||||
|
输出如下内容即可在浏览器中访问可视化服务。
|
||||||
|
```text
|
||||||
|
* Running on local URL: http://127.0.0.1:7861
|
||||||
|
|
||||||
|
To create a public link, set `share=True` in `launch()`.
|
||||||
|
```
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/zh/get_started/images/setting.png" alt="Setting" style="width: 90%;" />
|
||||||
|
<p>设置界面</p>
|
||||||
|
</td>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/zh/get_started/images/model_compare.png" alt="Model Compare" style="width: 100%;" />
|
||||||
|
<p>模型比较</p>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
<tr>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/zh/get_started/images/report_overview.png" alt="Report Overview" style="width: 100%;" />
|
||||||
|
<p>报告概览</p>
|
||||||
|
</td>
|
||||||
|
<td style="text-align: center;">
|
||||||
|
<img src="docs/zh/get_started/images/report_details.png" alt="Report Details" style="width: 91%;" />
|
||||||
|
<p>报告详情</p>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
|
||||||
|
详情参考:[📖可视化评测结果](https://evalscope.readthedocs.io/zh-cn/latest/get_started/visualization.html)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## 🌐 指定模型API评测
|
||||||
|
|
||||||
|
指定模型API服务地址(api_url)和API Key(api_key),评测部署的模型API服务,*此时`eval-type`参数必须指定为`service`*
|
||||||
|
|
||||||
|
例如使用[vLLM](https://github.com/vllm-project/vllm)拉起模型服务:
|
||||||
|
```shell
|
||||||
|
export VLLM_USE_MODELSCOPE=True && python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-0.5B-Instruct --served-model-name qwen2.5 --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
然后使用以下命令评测模型API服务:
|
||||||
|
```shell
|
||||||
|
evalscope eval \
|
||||||
|
--model qwen2.5 \
|
||||||
|
--api-url http://127.0.0.1:8801/v1 \
|
||||||
|
--api-key EMPTY \
|
||||||
|
--eval-type service \
|
||||||
|
--datasets gsm8k \
|
||||||
|
--limit 10
|
||||||
|
```
|
||||||
|
|
||||||
|
## ⚙️ 自定义参数评测
|
||||||
|
若想进行更加自定义的评测,例如自定义模型参数,或者数据集参数,可以使用以下命令,启动评测方式与简单评测一致,下面展示了使用`eval`命令启动评测:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen3-0.6B \
|
||||||
|
--model-args '{"revision": "master", "precision": "torch.float16", "device_map": "auto"}' \
|
||||||
|
--generation-config '{"do_sample":true,"temperature":0.6,"max_new_tokens":512,"chat_template_kwargs":{"enable_thinking": false}}' \
|
||||||
|
--dataset-args '{"gsm8k": {"few_shot_num": 0, "few_shot_random": false}}' \
|
||||||
|
--datasets gsm8k \
|
||||||
|
--limit 10
|
||||||
|
```
|
||||||
|
|
||||||
|
### 参数说明
|
||||||
|
- `--model-args`: 模型加载参数,以json字符串格式传入:
|
||||||
|
- `revision`: 模型版本
|
||||||
|
- `precision`: 模型精度
|
||||||
|
- `device_map`: 模型分配设备
|
||||||
|
- `--generation-config`: 生成参数,以json字符串格式传入,将解析为字典:
|
||||||
|
- `do_sample`: 是否使用采样
|
||||||
|
- `temperature`: 生成温度
|
||||||
|
- `max_new_tokens`: 生成最大长度
|
||||||
|
- `chat_template_kwargs`: 模型推理模板参数
|
||||||
|
- `--dataset-args`: 评测数据集的设置参数,以json字符串格式传入,key为数据集名称,value为参数,注意需要跟`--datasets`参数中的值一一对应:
|
||||||
|
- `few_shot_num`: few-shot的数量
|
||||||
|
- `few_shot_random`: 是否随机采样few-shot数据,如果不设置,则默认为`true`
|
||||||
|
|
||||||
|
参考:[全部参数说明](https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html)
|
||||||
|
|
||||||
|
|
||||||
|
## 🧪 其他评测后端
|
||||||
|
EvalScope支持使用第三方评测框架发起评测任务,我们称之为评测后端 (Evaluation Backend)。目前支持的Evaluation Backend有:
|
||||||
|
- **Native**:EvalScope自身的**默认评测框架**,支持多种评测模式,包括单模型评测、竞技场模式、Baseline模型对比模式等。
|
||||||
|
- [OpenCompass](https://github.com/open-compass/opencompass):通过EvalScope作为入口,发起OpenCompass的评测任务,轻量级、易于定制、支持与LLM微调框架[ms-wift](https://github.com/modelscope/swift)的无缝集成:[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/opencompass_backend.html)
|
||||||
|
- [VLMEvalKit](https://github.com/open-compass/VLMEvalKit):通过EvalScope作为入口,发起VLMEvalKit的多模态评测任务,支持多种多模态模型和数据集,支持与LLM微调框架[ms-wift](https://github.com/modelscope/swift)的无缝集成:[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/vlmevalkit_backend.html)
|
||||||
|
- **RAGEval**:通过EvalScope作为入口,发起RAG评测任务,支持使用[MTEB/CMTEB](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/mteb.html)进行embedding模型和reranker的独立评测,以及使用[RAGAS](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/ragas.html)进行端到端评测:[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/rageval_backend/index.html)
|
||||||
|
- **ThirdParty**: 第三方评测任务,如[ToolBench](https://evalscope.readthedocs.io/zh-cn/latest/third_party/toolbench.html)、[LongBench-Write](https://evalscope.readthedocs.io/zh-cn/latest/third_party/longwriter.html)。
|
||||||
|
|
||||||
|
## 📈 推理性能评测工具
|
||||||
|
一个专注于大型语言模型的压力测试工具,可以自定义以支持各种数据集格式和不同的API协议格式。
|
||||||
|
|
||||||
|
参考:性能测试[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/index.html)
|
||||||
|
|
||||||
|
输出示例如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**支持wandb记录结果**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**支持swanlab记录结果**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**支持Speed Benchmark**
|
||||||
|
|
||||||
|
支持速度测试,得到类似[Qwen官方](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html)报告的速度基准:
|
||||||
|
|
||||||
|
```text
|
||||||
|
Speed Benchmark Results:
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
| Prompt Tokens | Speed(tokens/s) | GPU Memory(GB) |
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
| 1 | 50.69 | 0.97 |
|
||||||
|
| 6144 | 51.36 | 1.23 |
|
||||||
|
| 14336 | 49.93 | 1.59 |
|
||||||
|
| 30720 | 49.56 | 2.34 |
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## 🖊️ 自定义数据集评测
|
||||||
|
EvalScope支持自定义数据集评测,具体请参考:自定义数据集评测[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/custom_dataset/index.html)
|
||||||
|
|
||||||
|
|
||||||
|
## ⚔️ 竞技场模式
|
||||||
|
竞技场模式允许配置多个候选模型,并指定一个baseline模型,通过候选模型与baseline模型进行对比(pairwise battle)的方式进行评测,最后输出模型的胜率和排名。该方法适合多个模型之间的对比评测,直观体现模型优劣。参考:竞技场模式[📖使用指南](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/arena.html)
|
||||||
|
|
||||||
|
```text
|
||||||
|
Model WinRate (%) CI (%)
|
||||||
|
------------ ------------- ---------------
|
||||||
|
qwen2.5-72b 69.3 (-13.3 / +12.2)
|
||||||
|
qwen2.5-7b 50 (+0.0 / +0.0)
|
||||||
|
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
|
||||||
|
```
|
||||||
|
## 👷♂️ 贡献
|
||||||
|
|
||||||
|
EvalScope作为[ModelScope](https://modelscope.cn)的官方评测工具,其基准评测功能正在持续优化中!我们诚邀您参考[贡献指南](https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/add_benchmark.html),轻松添加自己的评测基准,并与广大社区成员分享您的贡献。一起助力EvalScope的成长,让我们的工具更加出色!快来加入我们吧!
|
||||||
|
|
||||||
|
<a href="https://github.com/modelscope/evalscope/graphs/contributors" target="_blank">
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<th colspan="2">
|
||||||
|
<br><img src="https://contrib.rocks/image?repo=modelscope/evalscope"><br><br>
|
||||||
|
</th>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
</a>
|
||||||
|
|
||||||
|
## 🔜 Roadmap
|
||||||
|
- [x] 支持更好的评测报告可视化
|
||||||
|
- [x] 支持多数据集混合评测
|
||||||
|
- [x] RAG evaluation
|
||||||
|
- [x] VLM evaluation
|
||||||
|
- [x] Agents evaluation
|
||||||
|
- [x] vLLM
|
||||||
|
- [ ] Distributed evaluating
|
||||||
|
- [x] Multi-modal evaluation
|
||||||
|
- [ ] Benchmarks
|
||||||
|
- [x] BFCL-v3
|
||||||
|
- [x] GPQA
|
||||||
|
- [x] MBPP
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Star History
|
||||||
|
|
||||||
|
[](https://star-history.com/#modelscope/evalscope&Date)
|
||||||
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
{kind=link}
|
After Width: | Height: | Size: 112 KiB |
{kind=link}
|
After Width: | Height: | Size: 7.3 KiB |
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
{kind=link}
|
After Width: | Height: | Size: 75 KiB |
|
|
@ -0,0 +1,6 @@
|
||||||
|
index category answer question A B C D image_path
|
||||||
|
1 Animals A What animal is this? Dog Cat Tiger Elephant custom_eval/multimodal/images/dog.jpg
|
||||||
|
2 Buildings D What building is this? School Hospital Park Museum custom_eval/multimodal/images/AMNH.jpg
|
||||||
|
3 Cities B Which city's skyline is this? New York Tokyo Shanghai Paris custom_eval/multimodal/images/tokyo.jpg
|
||||||
|
4 Vehicles C What is the brand of this car? BMW Audi Tesla Mercedes custom_eval/multimodal/images/tesla.jpg
|
||||||
|
5 Activities A What is the person in the picture doing? Running Swimming Reading Singing custom_eval/multimodal/images/running.jpg
|
||||||
|
|
|
@ -0,0 +1,10 @@
|
||||||
|
{"image_path": "custom_eval/multimodal/images/dog.jpg", "prompt": "dog"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/dog.jpg", "prompt": "cat"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/AMNH.jpg", "prompt": "building"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/AMNH.jpg", "prompt": "Grand historic building with columns, glass doors, digital screen, and busy open area. Classical yet modern."}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tokyo.jpg", "prompt": "city tokyo"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tokyo.jpg", "prompt": "city newyork"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tesla.jpg", "prompt": "car tesla"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tesla.jpg", "prompt": "car toyota"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/running.jpg", "prompt": "man running"}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/running.jpg", "prompt": "man eating"}
|
||||||
|
|
@ -0,0 +1,5 @@
|
||||||
|
{"image_path": "custom_eval/multimodal/images/dog.jpg", "query": ["dog"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/AMNH.jpg", "query": ["building"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tokyo.jpg", "query": ["city", "tokyo"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tesla.jpg", "query": ["car", "tesla"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/running.jpg", "query": ["man", "running"]}
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
index answer question image_path
|
||||||
|
1 Dog What animal is this? custom_eval/multimodal/images/dog.jpg
|
||||||
|
2 Museum What building is this? custom_eval/multimodal/images/AMNH.jpg
|
||||||
|
3 Tokyo Which city's skyline is this? custom_eval/multimodal/images/tokyo.jpg
|
||||||
|
4 Tesla What is the brand of this car? custom_eval/multimodal/images/tesla.jpg
|
||||||
|
5 Running What is the person in the picture doing? custom_eval/multimodal/images/running.jpg
|
||||||
|
|
|
@ -0,0 +1,3 @@
|
||||||
|
id,question,A,B,C,D,answer
|
||||||
|
1,通常来说,组成动物蛋白质的氨基酸有____,4种,22种,20种,19种,C
|
||||||
|
2,血液内存在的下列物质中,不属于代谢终产物的是____。,尿素,尿酸,丙酮酸,二氧化碳,C
|
||||||
|
|
|
@ -0,0 +1,2 @@
|
||||||
|
{"id": "1", "question": "通常来说,组成动物蛋白质的氨基酸有____", "A": "4种", "B": "22种", "C": "20种", "D": "19种", "answer": "C"}
|
||||||
|
{"id": "2", "question": "血液内存在的下列物质中,不属于代谢终产物的是____。", "A": "尿素", "B": "尿酸", "C": "丙酮酸", "D": "二氧化碳", "answer": "C"}
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
id,category,question,A,B,C,D,answer
|
||||||
|
1,数学,以下哪个公式是二次函数的标准形式?,y = mx + b,y = ax^2 + bx + c,y = x^2 + 2x + 1,y = a + bx,B
|
||||||
|
2,物理学,空气中的声速是多少?,343 m/s,792 km/s,225 km/h,60 m/s,A
|
||||||
|
3,化学,水的化学式是什么?,H2O,CO2,NaCl,O2,A
|
||||||
|
4,生物学,遗传物质的载体是?,DNA,RNA,蛋白质,脂质,A
|
||||||
|
5,地理,世界上最大的沙漠是?,撒哈拉沙漠,戈壁滩,南极大陆,阿塔卡马沙漠,C
|
||||||
|
6,历史,谁是中国历史上建立秦朝的皇帝?,秦始皇,汉高祖,唐太宗,宋太祖,A
|
||||||
|
7,文学,《红楼梦》的作者是谁?,曹雪芹,鲁迅,巴金,老舍,A
|
||||||
|
8,艺术,《蒙娜丽莎》的画家是谁?,达·芬奇,米开朗基罗,拉斐尔,梵高,A
|
||||||
|
9,计算机科学,以下哪个是C语言的关键词?,for,print,echo,def,A
|
||||||
|
10,经济学,需求法则描述的是?,价格和需求量的反向关系,价格和供给量的正向关系,供求平衡,市场垄断,A
|
||||||
|
11,生物学,通常来说,组成动物蛋白质的氨基酸有____,4种,22种,20种,19种,C
|
||||||
|
12,生物学,血液内存在的下列物质中,不属于代谢终产物的是____。,尿素,尿酸,丙酮酸,二氧化碳,C
|
||||||
|
|
|
@ -0,0 +1,12 @@
|
||||||
|
{"id": "1", "category": "数学", "question": "以下哪个公式是二次函数的标准形式?", "A": "y = mx + b", "B": "y = ax^2 + bx + c", "C": "y = x^2 + 2x + 1", "D": "y = a + bx", "answer": "B"}
|
||||||
|
{"id": "2", "category": "物理学", "question": "空气中的声速是多少?", "A": "343 m/s", "B": "792 km/s", "C": "225 km/h", "D": "60 m/s", "answer": "A"}
|
||||||
|
{"id": "3", "category": "化学", "question": "水的化学式是什么?", "A": "H2O", "B": "CO2", "C": "NaCl", "D": "O2", "answer": "A"}
|
||||||
|
{"id": "4", "category": "生物学", "question": "遗传物质的载体是?", "A": "DNA", "B": "RNA", "C": "蛋白质", "D": "脂质", "answer": "A"}
|
||||||
|
{"id": "5", "category": "地理", "question": "世界上最大的沙漠是?", "A": "撒哈拉沙漠", "B": "戈壁滩", "C": "南极大陆", "D": "阿塔卡马沙漠", "answer": "C"}
|
||||||
|
{"id": "6", "category": "历史", "question": "谁是中国历史上建立秦朝的皇帝?", "A": "秦始皇", "B": "汉高祖", "C": "唐太宗", "D": "宋太祖", "answer": "A"}
|
||||||
|
{"id": "7", "category": "文学", "question": "《红楼梦》的作者是谁?", "A": "曹雪芹", "B": "鲁迅", "C": "巴金", "D": "老舍", "answer": "A"}
|
||||||
|
{"id": "8", "category": "艺术", "question": "《蒙娜丽莎》的画家是谁?", "A": "达·芬奇", "B": "米开朗基罗", "C": "拉斐尔", "D": "梵高", "answer": "A"}
|
||||||
|
{"id": "9", "category": "计算机科学", "question": "以下哪个是C语言的关键词?", "A": "for", "B": "print", "C": "echo", "D": "def", "answer": "A"}
|
||||||
|
{"id": "10", "category": "经济学", "question": "需求法则描述的是?", "A": "价格和需求量的反向关系", "B": "价格和供给量的正向关系", "C": "供求平衡", "D": "市场垄断", "answer": "A"}
|
||||||
|
{"id": "11", "category": "生物学", "question": "通常来说,组成动物蛋白质的氨基酸有____", "A": "4种", "B": "22种", "C": "20种", "D": "19种", "answer": "C"}
|
||||||
|
{"id": "12", "category": "生物学", "question": "血液内存在的下列物质中,不属于代谢终产物的是____。", "A": "尿素", "B": "尿酸", "C": "丙酮酸", "D": "二氧化碳", "answer": "C"}
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
{"query": "How can I improve my time management skills?", "category": "generic"}
|
||||||
|
{"query": "What are the most effective ways to deal with stress?", "category": "generic"}
|
||||||
|
{"query": "What are the main differences between Python and JavaScript programming languages?", "category": "generic"}
|
||||||
|
{"query": "How can I increase my productivity while working from home?", "category": "generic"}
|
||||||
|
{"query": "Can you explain the basics of quantum computing?", "category": "generic"}
|
||||||
|
{"query": "What are the differences between plant-based and animal-based protein sources?", "category": "generic"}
|
||||||
|
{"query": "How can I develop my critical thinking skills?", "category": "generic"}
|
||||||
|
{"query": "What are the major challenges faced by the education sector today?", "category": "generic"}
|
||||||
|
{"query": "What are the primary factors that influence consumer behavior?", "category": "generic"}
|
||||||
|
{"query": "What are the most effective strategies for conflict resolution in the workplace?", "category": "generic"}
|
||||||
|
|
@ -0,0 +1,12 @@
|
||||||
|
{"system": "你是一位天文学家", "query": "太阳系中最大的行星是哪颗?", "response": "是木星"}
|
||||||
|
{"query": "什么动物被称为沙漠之舟?", "response": "是骆驼"}
|
||||||
|
{"query": "世界上最长的河流是哪条?", "response": "是尼罗河"}
|
||||||
|
{"query": "地球上最大的洲是哪个?", "response": "是亚洲"}
|
||||||
|
{"query": "什么是世界上最繁忙的航空港?", "response": "亚特兰大机场"}
|
||||||
|
{"query": "世界上最古老的七大奇迹是哪个?", "response": "金字塔"}
|
||||||
|
{"query": "什么国家是世界上最大的生产者?", "response": "中国"}
|
||||||
|
{"query": "世界上最大的淡水湖是哪个?", "response": "是苏必利尔湖"}
|
||||||
|
{"query": "太阳系中离太阳最近的行星是哪颗?", "response": "是水星"}
|
||||||
|
{"query": "中国的首都是哪里?", "response": "中国的首都是北京"}
|
||||||
|
{"query": "世界上最高的山是哪座山?", "response": "是珠穆朗玛峰"}
|
||||||
|
{"query": "为什么北极见不到企鹅?", "response": "因为企鹅大多生活在南极"}
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
{"query": "世界上最高的山是哪座山?", "response": "是珠穆朗玛峰"}
|
||||||
|
{"query": "为什么北极见不到企鹅?", "response": "因为企鹅大多生活在南极"}
|
||||||
|
{"query": "太阳系中最大的行星是哪颗?", "response": "是木星"}
|
||||||
|
{"query": "地球上最长的河流是哪条?", "response": "是尼罗河"}
|
||||||
|
{"query": "谁发明了相对论?", "response": "是爱因斯坦"}
|
||||||
|
{"query": "谁是中国的第一位皇帝?", "response": "是秦始皇"}
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
{"_id": "doc1", "text": "气候变化正在导致更极端的天气模式。"}
|
||||||
|
{"_id": "doc2", "text": "今天股市大幅上涨,科技股领涨。"}
|
||||||
|
{"_id": "doc3", "text": "人工智能正在通过自动化任务和提供见解来改变各种行业。"}
|
||||||
|
{"_id": "doc4", "text": "随着技术的进步,风能和太阳能等可再生能源变得越来越普及。"}
|
||||||
|
{"_id": "doc5", "text": "最新研究表明,均衡饮食和定期锻炼可以显著改善心理健康。"}
|
||||||
|
{"_id": "doc6", "text": "虚拟现实正在教育、娱乐和培训方面创造新的机会。"}
|
||||||
|
{"_id": "doc7", "text": "由于环保优势和电池技术的进步,电动汽车越来越受欢迎。"}
|
||||||
|
{"_id": "doc8", "text": "太空探索任务正在揭示关于我们的太阳系及其以外的新信息。"}
|
||||||
|
{"_id": "doc9", "text": "区块链技术在加密货币之外还有潜在的应用,包括供应链管理和安全投票系统。"}
|
||||||
|
{"_id": "doc10", "text": "远程工作的好处包括更大的灵活性和减少通勤时间。"}
|
||||||
|
|
@ -0,0 +1,11 @@
|
||||||
|
query-id corpus-id score
|
||||||
|
query1 doc1 1
|
||||||
|
query2 doc2 1
|
||||||
|
query3 doc3 1
|
||||||
|
query4 doc4 1
|
||||||
|
query5 doc5 1
|
||||||
|
query6 doc6 1
|
||||||
|
query7 doc7 1
|
||||||
|
query8 doc8 1
|
||||||
|
query9 doc9 1
|
||||||
|
query10 doc10 1
|
||||||
|
|
|
@ -0,0 +1,10 @@
|
||||||
|
{"_id": "query1", "text": "气候变化的影响是什么?"}
|
||||||
|
{"_id": "query2", "text": "今天股市上涨的原因是什么?"}
|
||||||
|
{"_id": "query3", "text": "人工智能如何改变行业?"}
|
||||||
|
{"_id": "query4", "text": "可再生能源有哪些进展?"}
|
||||||
|
{"_id": "query5", "text": "均衡饮食如何改善心理健康?"}
|
||||||
|
{"_id": "query6", "text": "虚拟现实创造了哪些新机会?"}
|
||||||
|
{"_id": "query7", "text": "为什么电动汽车越来越受欢迎?"}
|
||||||
|
{"_id": "query8", "text": "太空探索任务揭示了哪些新信息?"}
|
||||||
|
{"_id": "query9", "text": "区块链技术在加密货币之外有哪些应用?"}
|
||||||
|
{"_id": "query10", "text": "远程工作的好处是什么?"}
|
||||||
{kind=link}
|
After Width: | Height: | Size: 263 KiB |
{kind=link}
|
After Width: | Height: | Size: 71 KiB |
{kind=link}
|
After Width: | Height: | Size: 61 KiB |
|
|
@ -0,0 +1,47 @@
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
import requests
|
||||||
|
|
||||||
|
|
||||||
|
# 定义下载图像的函数
|
||||||
|
def download_image(url, folder):
|
||||||
|
if not os.path.exists(folder):
|
||||||
|
os.makedirs(folder)
|
||||||
|
# 提取文件名
|
||||||
|
filename = url.split('/')[-1]
|
||||||
|
filepath = os.path.join(folder, filename)
|
||||||
|
# 下载图片
|
||||||
|
response = requests.get(url)
|
||||||
|
if response.status_code == 200:
|
||||||
|
with open(filepath, 'wb') as f:
|
||||||
|
f.write(response.content)
|
||||||
|
return filepath
|
||||||
|
|
||||||
|
|
||||||
|
# 处理Markdown文件
|
||||||
|
def process_markdown(input_path, output_path, image_folder):
|
||||||
|
with open(input_path, 'r', encoding='utf-8') as file:
|
||||||
|
content = file.read()
|
||||||
|
|
||||||
|
# 匹配Markdown图片链接的正则表达式
|
||||||
|
image_pattern = re.compile(r'!\[.*?\]\((.*?)\)')
|
||||||
|
matches = image_pattern.findall(content)
|
||||||
|
|
||||||
|
for url in matches:
|
||||||
|
try:
|
||||||
|
local_path = download_image(url, image_folder)
|
||||||
|
content = content.replace(url, local_path)
|
||||||
|
except Exception as e:
|
||||||
|
print(f'Error downloading {url}: {e}')
|
||||||
|
|
||||||
|
with open(output_path, 'w', encoding='utf-8') as file:
|
||||||
|
file.write(content)
|
||||||
|
|
||||||
|
|
||||||
|
# 主函数
|
||||||
|
if __name__ == '__main__':
|
||||||
|
input_markdown_file = '/mnt/data/data/user/maoyunlin.myl/evalscope/docs/zh/best_practice/t2i_eval.md' # 输入的Markdown文件路径
|
||||||
|
output_markdown_file = '/mnt/data/data/user/maoyunlin.myl/evalscope/docs/zh/best_practice/t2i_eval.md' # 输出的Markdown文件路径
|
||||||
|
image_folder = '/mnt/data/data/user/maoyunlin.myl/evalscope/docs/zh/best_practice/images' # 保存图片的文件夹
|
||||||
|
|
||||||
|
process_markdown(input_markdown_file, output_markdown_file, image_folder)
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
# .readthedocs.yaml
|
||||||
|
# Read the Docs configuration file
|
||||||
|
# See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
|
||||||
|
|
||||||
|
# Required
|
||||||
|
version: 2
|
||||||
|
|
||||||
|
# Set the OS, Python version and other tools you might need
|
||||||
|
build:
|
||||||
|
os: ubuntu-22.04
|
||||||
|
tools:
|
||||||
|
python: "3.12"
|
||||||
|
|
||||||
|
# Build documentation in the "docs/" directory with Sphinx
|
||||||
|
sphinx:
|
||||||
|
configuration: docs/en/conf.py
|
||||||
|
|
||||||
|
# Optionally build your docs in additional formats such as PDF and ePub
|
||||||
|
# formats:
|
||||||
|
# - pdf
|
||||||
|
# - epub
|
||||||
|
|
||||||
|
# Optional but recommended, declare the Python requirements required
|
||||||
|
# to build your documentation
|
||||||
|
# See https://docs.readthedocs.io/en/stable/guides/reproducible-builds.html
|
||||||
|
python:
|
||||||
|
install:
|
||||||
|
- requirements: requirements/docs.txt
|
||||||
|
|
@ -0,0 +1,20 @@
|
||||||
|
# Minimal makefile for Sphinx documentation
|
||||||
|
#
|
||||||
|
|
||||||
|
# You can set these variables from the command line, and also
|
||||||
|
# from the environment for the first two.
|
||||||
|
SPHINXOPTS ?=
|
||||||
|
SPHINXBUILD ?= sphinx-build
|
||||||
|
SOURCEDIR = .
|
||||||
|
BUILDDIR = _build
|
||||||
|
|
||||||
|
# Put it first so that "make" without argument is like "make help".
|
||||||
|
help:
|
||||||
|
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||||
|
|
||||||
|
.PHONY: help Makefile
|
||||||
|
|
||||||
|
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||||
|
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||||
|
%: Makefile
|
||||||
|
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||||
{kind=link}
|
After Width: | Height: | Size: 24 KiB |
{kind=link}
|
After Width: | Height: | Size: 6.6 KiB |
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
{kind=link}
|
After Width: | Height: | Size: 280 KiB |
|
|
@ -0,0 +1,435 @@
|
||||||
|
# 👍 Contribute Benchmark
|
||||||
|
|
||||||
|
As the official evaluation tool of [ModelScope](https://modelscope.cn), EvalScope's benchmark evaluation functionality is continuously being optimized! We warmly invite you to reference this tutorial to easily add your own benchmark evaluation and share your contributions with the community. Let's help EvalScope grow together and make our tool even better!
|
||||||
|
|
||||||
|
Below, we take `MMLU-Pro` as an example to introduce how to add a benchmark evaluation, which mainly includes three steps: uploading a dataset, registering a dataset, and writing an evaluation task.
|
||||||
|
|
||||||
|
## 1. Prepare Benchmark Evaluation Dataset
|
||||||
|
|
||||||
|
You have two ways to prepare the benchmark evaluation dataset:
|
||||||
|
|
||||||
|
1. **Upload to ModelScope (Recommended)**: Upload the dataset to the ModelScope platform, allowing other users to load your dataset with a single click. This is more convenient and allows more users to benefit from your contribution.
|
||||||
|
|
||||||
|
2. **Use Locally**: You can also directly use the local dataset for evaluation, suitable for situations where the dataset is still in development or contains sensitive information.
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
For uploading to ModelScope, please refer to: [modelscope/MMLU-Pro](https://modelscope.cn/datasets/modelscope/MMLU-Pro/summary) example, and [dataset upload tutorial](https://www.modelscope.cn/docs/datasets/create).
|
||||||
|
```
|
||||||
|
|
||||||
|
Regardless of which method you choose, please ensure the data format is correct and can be loaded. If using ModelScope, you can test with the following code:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from modelscope import MsDataset
|
||||||
|
|
||||||
|
dataset = MsDataset.load("modelscope/MMLU-Pro") # Replace with your dataset
|
||||||
|
```
|
||||||
|
|
||||||
|
If using a local dataset, you need to adjust the `dataset_id` parameter and rewrite the `load_from_disk` method when registering the benchmark evaluation.
|
||||||
|
|
||||||
|
## 2. Register Benchmark Evaluation
|
||||||
|
|
||||||
|
Add a benchmark evaluation in EvalScope.
|
||||||
|
|
||||||
|
### Create File Structure
|
||||||
|
|
||||||
|
First, [Fork EvalScope](https://github.com/modelscope/evalscope/fork) repository, creating a copy of the EvalScope repository for yourself, and then clone it locally.
|
||||||
|
|
||||||
|
Then, add the benchmark evaluation in the `evalscope/benchmarks/` directory with the following structure:
|
||||||
|
|
||||||
|
```text
|
||||||
|
evalscope/benchmarks/
|
||||||
|
├── benchmark_name
|
||||||
|
│ ├── __init__.py
|
||||||
|
│ ├── benchmark_name_adapter.py
|
||||||
|
│ └── ...
|
||||||
|
```
|
||||||
|
Specifically for `MMLU-Pro`, the structure is as follows:
|
||||||
|
|
||||||
|
```text
|
||||||
|
evalscope/benchmarks/
|
||||||
|
├── mmlu_pro
|
||||||
|
│ ├── __init__.py
|
||||||
|
│ ├── mmlu_pro_adapter.py
|
||||||
|
│ └── ...
|
||||||
|
```
|
||||||
|
|
||||||
|
### Register `Benchmark`
|
||||||
|
|
||||||
|
We need to register `Benchmark` in `benchmark_name_adapter.py` so that EvalScope can load our added benchmark test. Taking `MMLU-Pro` as an example, the main contents include:
|
||||||
|
|
||||||
|
- Import `Benchmark` and `DataAdapter`
|
||||||
|
- Register `Benchmark`, specifying:
|
||||||
|
- `name`: Benchmark test name
|
||||||
|
- `pretty_name`: Readable name of the benchmark test
|
||||||
|
- `tags`: Benchmark test tags for classification and search
|
||||||
|
- `description`: Benchmark test description, can use Markdown format, recommended in English
|
||||||
|
- `dataset_id`: Benchmark test dataset ID for loading the benchmark test dataset
|
||||||
|
- `model_adapter`: Default model adapter for the benchmark test. Supports two types:
|
||||||
|
- `OutputType.GENERATION`: General text generation model evaluation, returning the text generated by the model through input prompts
|
||||||
|
- `OutputType.MULTIPLE_CHOICE`: Multiple-choice question evaluation, calculating option probabilities through logits, returning the option with the highest probability
|
||||||
|
- `output_types`: Benchmark test output types, supports multiple choices:
|
||||||
|
- `OutputType.GENERATION`: General text generation model evaluation
|
||||||
|
- `OutputType.MULTIPLE_CHOICE`: Multiple-choice question evaluation output logits
|
||||||
|
- `subset_list`: Subdatasets of the benchmark test dataset
|
||||||
|
- `metric_list`: Evaluation metrics for the benchmark test
|
||||||
|
- `few_shot_num`: Number of In Context Learning examples for evaluation
|
||||||
|
- `train_split`: Training set of the benchmark test for sampling ICL examples
|
||||||
|
- `eval_split`: Evaluation set of the benchmark test
|
||||||
|
- `prompt_template`: Benchmark test prompt template
|
||||||
|
- Create `MMLUProAdapter` class, inheriting from `DataAdapter`.
|
||||||
|
|
||||||
|
```{tip}
|
||||||
|
The default `subset_list`, `train_split`, `eval_split` can be obtained from the dataset preview, for example, [MMLU-Pro preview](https://modelscope.cn/datasets/modelscope/MMLU-Pro/dataPeview)
|
||||||
|
|
||||||
|

|
||||||
|
```
|
||||||
|
|
||||||
|
Example code is as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.benchmarks import Benchmark, DataAdapter
|
||||||
|
from evalscope.constants import EvalType, OutputType
|
||||||
|
|
||||||
|
SUBSET_LIST = [
|
||||||
|
'computer science', 'math', 'chemistry', 'engineering', 'law', 'biology', 'health', 'physics', 'business',
|
||||||
|
'philosophy', 'economics', 'other', 'psychology', 'history'
|
||||||
|
] # Custom subset list
|
||||||
|
|
||||||
|
@Benchmark.register(
|
||||||
|
name='mmlu_pro',
|
||||||
|
pretty_name='MMLU-Pro',
|
||||||
|
tags=['MCQ', 'Knowledge'],
|
||||||
|
description=
|
||||||
|
'MMLU-Pro is a benchmark for evaluating language models on multiple-choice questions across various subjects. It includes questions from different domains, where the model must select the correct answer from given options.', # noqa: E501
|
||||||
|
dataset_id='modelscope/MMLU-Pro',
|
||||||
|
model_adapter=OutputType.GENERATION,
|
||||||
|
output_types=[OutputType.MULTIPLE_CHOICE, OutputType.GENERATION],
|
||||||
|
subset_list=SUBSET_LIST,
|
||||||
|
metric_list=['AverageAccuracy'],
|
||||||
|
few_shot_num=5,
|
||||||
|
train_split='validation',
|
||||||
|
eval_split='test',
|
||||||
|
prompt_template=
|
||||||
|
'The following are multiple choice questions (with answers) about {subset_name}. Think step by step and then finish your answer with \"the answer is (X)\" where X is the correct letter choice.\n{query}', # noqa: E501
|
||||||
|
)
|
||||||
|
class MMLUProAdapter(DataAdapter):
|
||||||
|
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super().__init__(**kwargs)
|
||||||
|
```
|
||||||
|
|
||||||
|
## 3. Write Evaluation Logic
|
||||||
|
|
||||||
|
After completing the registration of `Benchmark`, we need to write the core methods in the `DataAdapter` class to implement the evaluation functionality. These methods control the data loading, processing, and scoring process.
|
||||||
|
|
||||||
|
### Evaluation Process Overview
|
||||||
|
|
||||||
|
The EvalScope evaluation process mainly includes the following steps:
|
||||||
|
|
||||||
|
1. **Data Loading**: Load the dataset through the `load` method
|
||||||
|
2. **Prompt Generation**: Generate model input through `gen_prompts` by calling `gen_prompt`
|
||||||
|
3. **Model Inference**: Perform inference on generated prompts through the `predict` method of the model adapter
|
||||||
|
4. **Answer Parsing**: Parse model output through `parse_pred_result`
|
||||||
|
5. **Answer Scoring**: Evaluate prediction results through `match` or `llm_match` method
|
||||||
|
6. **Metric Calculation**: Calculate evaluation metrics through `compute_metric`
|
||||||
|
7. **Report Generation**: Generate evaluation report through `gen_report` and `post_process_report`
|
||||||
|
|
||||||
|
### Core Methods to Implement
|
||||||
|
|
||||||
|
The following are the core methods that must be implemented, each with a clear functionality and purpose:
|
||||||
|
|
||||||
|
1. **`gen_prompt`**: Convert dataset samples into a format acceptable by the model
|
||||||
|
- Process few-shot examples
|
||||||
|
- Format questions and options
|
||||||
|
- Apply prompt template
|
||||||
|
|
||||||
|
2. **`get_gold_answer`**: Extract standard answer from dataset samples
|
||||||
|
- Usually returns the answer field from the dataset
|
||||||
|
|
||||||
|
3. **`parse_pred_result`**: Parse model output and extract valid answer
|
||||||
|
- For text generation models, typically need to extract answer options
|
||||||
|
- For direct output by multiple-choice questions, can directly return results
|
||||||
|
|
||||||
|
4. **`match`**: Compare predicted answer with standard answer and calculate score
|
||||||
|
- Usually uses exact match methods
|
||||||
|
|
||||||
|
### Optional Methods to Implement
|
||||||
|
|
||||||
|
In addition to the methods that must be implemented, you can also implement or override the following methods as needed:
|
||||||
|
|
||||||
|
1. **`llm_match`**: Use large language models as judges to evaluate answer quality
|
||||||
|
- Suitable for open-ended questions or evaluation tasks requiring complex understanding
|
||||||
|
- Needs to specify judgement model in configuration
|
||||||
|
- Can better evaluate answer quality compared to simple rule matching
|
||||||
|
|
||||||
|
```python
|
||||||
|
def llm_match(self, gold: Any, pred: Any, judge: Optional[LLMJudge] = None, **kwargs) -> float:
|
||||||
|
"""
|
||||||
|
Use LLM as a judge to evaluate predicted answers
|
||||||
|
|
||||||
|
Args:
|
||||||
|
gold: Standard answer
|
||||||
|
pred: Predicted answer
|
||||||
|
judge: LLM judge instance
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Scoring result, usually a floating number between 0 and 1
|
||||||
|
"""
|
||||||
|
# Default judge handling
|
||||||
|
if judge is None:
|
||||||
|
return 0
|
||||||
|
|
||||||
|
# Build judgement prompt and get score
|
||||||
|
prompt = judge.build_prompt(pred, gold, kwargs.get('raw_input', {}).get('question'))
|
||||||
|
score = judge(prompt)
|
||||||
|
return judge.get_score(score)
|
||||||
|
```
|
||||||
|
|
||||||
|
2. **`post_process_report`**: Process evaluation report, add custom analysis or visualization
|
||||||
|
|
||||||
|
3. **`load`**: Override data loading process, suitable for scenarios requiring custom data loading logic
|
||||||
|
- Suitable for handling datasets with special formats
|
||||||
|
- Can implement custom subset division logic
|
||||||
|
- Can add data preprocessing or filtering steps
|
||||||
|
|
||||||
|
```python
|
||||||
|
def load(self, dataset_name_or_path: str = None, subset_list: list = None, work_dir: Optional[str] = DEFAULT_DATASET_CACHE_DIR, **kwargs) -> dict:
|
||||||
|
"""
|
||||||
|
Custom dataset loading logic
|
||||||
|
|
||||||
|
Args:
|
||||||
|
dataset_name_or_path: Dataset path or name
|
||||||
|
subset_list: Subset list
|
||||||
|
work_dir: Working directory
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Data dictionary, format: {'subset_name': {'train': train_dataset, 'test': test_dataset}}
|
||||||
|
"""
|
||||||
|
# Implement custom data loading and processing logic here
|
||||||
|
# For example: loading data from local files, filtering data, reorganizing data structure, etc.
|
||||||
|
|
||||||
|
# Call parent method to load base data
|
||||||
|
data_dict = super().load(dataset_name_or_path, subset_list, work_dir, **kwargs)
|
||||||
|
|
||||||
|
# Perform custom processing, such as subset division based on specific fields
|
||||||
|
return self.reformat_subset(data_dict, subset_key='your_category_field')
|
||||||
|
```
|
||||||
|
|
||||||
|
4. **`load_from_disk`**: Specifically for loading datasets from local disk
|
||||||
|
- Need to override this method when using local datasets instead of ModelScope-hosted datasets
|
||||||
|
- Can handle custom format local data files
|
||||||
|
|
||||||
|
```python
|
||||||
|
def load_from_disk(self, dataset_path, subset_list, work_dir, **kwargs) -> dict:
|
||||||
|
"""
|
||||||
|
Load dataset from local disk
|
||||||
|
|
||||||
|
Args:
|
||||||
|
dataset_path: Local dataset path
|
||||||
|
subset_list: Subset list
|
||||||
|
work_dir: Working directory
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Data dictionary, format: {'subset_name': {'train': train_dataset, 'test': test_dataset}}
|
||||||
|
"""
|
||||||
|
# Example: Load data from local JSON files
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
|
||||||
|
data_dict = {}
|
||||||
|
for subset in subset_list:
|
||||||
|
data_dict[subset] = {}
|
||||||
|
|
||||||
|
# Load training set (few-shot examples)
|
||||||
|
if self.train_split:
|
||||||
|
train_path = os.path.join(dataset_path, f"{subset}_{self.train_split}.json")
|
||||||
|
if os.path.exists(train_path):
|
||||||
|
with open(train_path, 'r', encoding='utf-8') as f:
|
||||||
|
data_dict[subset][self.train_split] = json.load(f)
|
||||||
|
|
||||||
|
# Load test set
|
||||||
|
if self.eval_split:
|
||||||
|
test_path = os.path.join(dataset_path, f"{subset}_{self.eval_split}.json")
|
||||||
|
if os.path.exists(test_path):
|
||||||
|
with open(test_path, 'r', encoding='utf-8') as f:
|
||||||
|
data_dict[subset][self.eval_split] = json.load(f)
|
||||||
|
|
||||||
|
return data_dict
|
||||||
|
```
|
||||||
|
|
||||||
|
### Code Example and Explanation
|
||||||
|
|
||||||
|
Below is a complete implementation of the MMLU-Pro adapter with detailed comments:
|
||||||
|
|
||||||
|
```python
|
||||||
|
class MMLUProAdapter(DataAdapter):
|
||||||
|
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super().__init__(**kwargs)
|
||||||
|
# Define option identifiers for building options
|
||||||
|
self.choices = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
|
||||||
|
|
||||||
|
def load(self, **kwargs):
|
||||||
|
"""
|
||||||
|
Rewrite the load method to implement custom dataset loading and subset division logic
|
||||||
|
|
||||||
|
In this example, we divide the dataset into subsets based on the 'category' field
|
||||||
|
"""
|
||||||
|
# First load all data using the default method
|
||||||
|
kwargs['subset_list'] = ['default']
|
||||||
|
data_dict = super().load(**kwargs)
|
||||||
|
# Use the 'category' field as the subset key for reformatting
|
||||||
|
return self.reformat_subset(data_dict, subset_key='category')
|
||||||
|
|
||||||
|
def gen_prompt(self, input_d: Dict, subset_name: str, few_shot_list: list, **kwargs) -> Any:
|
||||||
|
"""
|
||||||
|
Generate prompt text for model input
|
||||||
|
|
||||||
|
Args:
|
||||||
|
input_d: Current sample data
|
||||||
|
subset_name: Subset name for template filling
|
||||||
|
few_shot_list: Few-shot example list
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Formatted prompt text
|
||||||
|
"""
|
||||||
|
# Process few-shot examples
|
||||||
|
if self.few_shot_num > 0:
|
||||||
|
prefix = self.format_fewshot_examples(few_shot_list)
|
||||||
|
else:
|
||||||
|
prefix = ''
|
||||||
|
|
||||||
|
# Build current question text
|
||||||
|
query = prefix + 'Q: ' + input_d['question'] + '\n' + \
|
||||||
|
self.__form_options(input_d['options']) + '\n'
|
||||||
|
|
||||||
|
# Apply prompt template
|
||||||
|
full_prompt = self.prompt_template.format(subset_name=subset_name, query=query)
|
||||||
|
return self.gen_prompt_data(full_prompt)
|
||||||
|
|
||||||
|
def format_fewshot_examples(self, few_shot_list):
|
||||||
|
"""
|
||||||
|
Format few-shot examples
|
||||||
|
|
||||||
|
Format each example into a consistent format, including question, options, and thought process
|
||||||
|
"""
|
||||||
|
prompts = ''
|
||||||
|
for index, d in enumerate(few_shot_list):
|
||||||
|
prompts += 'Q: ' + d['question'] + '\n' + \
|
||||||
|
self.__form_options(d['options']) + '\n' + \
|
||||||
|
d['cot_content'] + '\n\n' # Include thought process
|
||||||
|
return prompts
|
||||||
|
|
||||||
|
def __form_options(self, options: list):
|
||||||
|
"""
|
||||||
|
Format option list
|
||||||
|
|
||||||
|
Convert option array into formatted text, add identifiers (A), (B), etc. before each option
|
||||||
|
"""
|
||||||
|
option_str = 'Options are:\n'
|
||||||
|
for opt, choice in zip(options, self.choices):
|
||||||
|
option_str += f'({choice}): {opt}' + '\n'
|
||||||
|
return option_str
|
||||||
|
|
||||||
|
def get_gold_answer(self, input_d: dict) -> str:
|
||||||
|
"""
|
||||||
|
Extract standard answer
|
||||||
|
|
||||||
|
Extract the correct answer from the data sample, usually option identifiers like 'A', 'B', 'C', 'D', etc.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
input_d: Input data sample
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Standard answer string
|
||||||
|
"""
|
||||||
|
return input_d['answer'] # Directly return the answer field from the dataset
|
||||||
|
|
||||||
|
def parse_pred_result(self, result: str, raw_input_d: dict = None, eval_type: str = EvalType.CHECKPOINT) -> str:
|
||||||
|
"""
|
||||||
|
Parse model prediction results
|
||||||
|
|
||||||
|
Use different parsing methods based on model type:
|
||||||
|
- Directly return results for models that output options
|
||||||
|
- Need to extract options from text for text generation models
|
||||||
|
|
||||||
|
Args:
|
||||||
|
result: Model prediction result
|
||||||
|
raw_input_d: Original input data
|
||||||
|
eval_type: Evaluation type
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Parsed answer option
|
||||||
|
"""
|
||||||
|
if self.model_adapter == OutputType.MULTIPLE_CHOICE:
|
||||||
|
# Direct output mode for multiple-choice, directly return the result
|
||||||
|
return result
|
||||||
|
else:
|
||||||
|
# Text generation mode, extract the first option letter from the text
|
||||||
|
return ResponseParser.parse_first_option(result)
|
||||||
|
|
||||||
|
def match(self, gold: str, pred: str) -> float:
|
||||||
|
"""
|
||||||
|
Compare predicted answer with standard answer
|
||||||
|
|
||||||
|
Args:
|
||||||
|
gold: Standard answer, e.g., 'A'
|
||||||
|
pred: Predicted answer, e.g., 'B'
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
Match score: 1.0 for correct, 0.0 for incorrect
|
||||||
|
"""
|
||||||
|
return exact_match(gold=gold, pred=pred) # Use exact match
|
||||||
|
```
|
||||||
|
|
||||||
|
### Tips and Best Practices
|
||||||
|
|
||||||
|
- Ensure consistency in format when designing few-shot examples and provide enough information
|
||||||
|
- Carefully design prompt templates to ensure the model understands task requirements
|
||||||
|
- Consider implementing more flexible scoring logic in the `match` method for complex tasks
|
||||||
|
- Add enough comments and documentation to facilitate understanding and maintenance of the code by other developers
|
||||||
|
- Consider using `llm_match` method for more complex answer evaluation, especially for open-ended questions
|
||||||
|
|
||||||
|
## 4. Run Evaluation
|
||||||
|
|
||||||
|
Debug the code to check if it can run normally.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import run_task, TaskConfig
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
datasets=['mmlu_pro'],
|
||||||
|
limit=10,
|
||||||
|
dataset_args={'mmlu_pro': {'subset_list': ['computer science', 'math']}},
|
||||||
|
debug=True
|
||||||
|
)
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
Output is as follows:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-----------------------+-----------+-----------------+------------------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=======================+===========+=================+==================+=======+=========+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | mmlu_pro | AverageAccuracy | computer science | 10 | 0.1 | default |
|
||||||
|
+-----------------------+-----------+-----------------+------------------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | mmlu_pro | AverageAccuracy | math | 10 | 0.1 | default |
|
||||||
|
+-----------------------+-----------+-----------------+------------------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## 5. Benchmark Evaluation Documentation Generation
|
||||||
|
|
||||||
|
After completing the benchmark evaluation implementation, you can use the tools provided by EvalScope to generate standard documentation. This ensures your benchmark evaluation has a consistent document format and can be easily understood and used by other users.
|
||||||
|
|
||||||
|
To generate both English and Chinese documents, please run the following command, which will generate documents based on registration information:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# Enter evalscope root directory
|
||||||
|
cd /path/to/evalscope
|
||||||
|
|
||||||
|
# Generate benchmark evaluation documentation
|
||||||
|
python docs/generate_dataset_md.py
|
||||||
|
```
|
||||||
|
|
||||||
|
After implementing these methods and generating documentation, your benchmark evaluation is ready! You can submit a [PR](https://github.com/modelscope/evalscope/pulls), and we will merge your contribution as soon as possible to allow more users to use the benchmark evaluation you contributed. If you don't know how to submit a PR, you can check out our [guide](https://github.com/modelscope/evalscope/blob/main/CONTRIBUTING.md), give it a try 🚀
|
||||||
|
|
@ -0,0 +1,77 @@
|
||||||
|
# Unified Evaluation
|
||||||
|
|
||||||
|
After obtaining the sampled data, you can proceed with the unified evaluation.
|
||||||
|
|
||||||
|
## Evaluation Configuration
|
||||||
|
|
||||||
|
Configure the evaluation task, for example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='qwen2.5',
|
||||||
|
api_url='http://127.0.0.1:8801/v1',
|
||||||
|
api_key='EMPTY',
|
||||||
|
eval_type=EvalType.SERVICE,
|
||||||
|
datasets=['data_collection'],
|
||||||
|
dataset_args={'data_collection': {
|
||||||
|
'dataset_id': 'outputs/mixed_data.jsonl'
|
||||||
|
}},
|
||||||
|
)
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
It is important to note that:
|
||||||
|
- The dataset name specified in `datasets` is fixed as `data_collection`, indicating the evaluation of the mixed dataset.
|
||||||
|
- In `dataset_args`, you need to specify `dataset_id`, which indicates the local path to the evaluation dataset or the dataset ID on ModelScope.
|
||||||
|
|
||||||
|
## Evaluation Results
|
||||||
|
|
||||||
|
The evaluation results are saved by default in the `outputs/` directory, containing reports with four levels:
|
||||||
|
|
||||||
|
- `subset_level`: Average scores and counts for each subset.
|
||||||
|
- `dataset_level`: Average scores and counts for each dataset.
|
||||||
|
- `task_level`: Average scores and counts for each task.
|
||||||
|
- `tag_level`: Average scores and counts for each tag, with the schema name also included as a tag in the `tags` column.
|
||||||
|
|
||||||
|
For example, the evaluation results might look like this:
|
||||||
|
|
||||||
|
```text
|
||||||
|
2024-12-30 20:03:54,582 - evalscope - INFO - subset_level Report:
|
||||||
|
+-----------+------------------+---------------+---------------+-------+
|
||||||
|
| task_type | dataset_name | subset_name | average_score | count |
|
||||||
|
+-----------+------------------+---------------+---------------+-------+
|
||||||
|
| math | competition_math | default | 0.0 | 38 |
|
||||||
|
| reasoning | race | high | 0.3704 | 27 |
|
||||||
|
| reasoning | race | middle | 0.5 | 12 |
|
||||||
|
| reasoning | arc | ARC-Easy | 0.5833 | 12 |
|
||||||
|
| math | gsm8k | main | 0.1667 | 6 |
|
||||||
|
| reasoning | arc | ARC-Challenge | 0.4 | 5 |
|
||||||
|
+-----------+------------------+---------------+---------------+-------+
|
||||||
|
2024-12-30 20:03:54,582 - evalscope - INFO - dataset_level Report:
|
||||||
|
+-----------+------------------+---------------+-------+
|
||||||
|
| task_type | dataset_name | average_score | count |
|
||||||
|
+-----------+------------------+---------------+-------+
|
||||||
|
| reasoning | race | 0.4103 | 39 |
|
||||||
|
| math | competition_math | 0.0 | 38 |
|
||||||
|
| reasoning | arc | 0.5294 | 17 |
|
||||||
|
| math | gsm8k | 0.1667 | 6 |
|
||||||
|
+-----------+------------------+---------------+-------+
|
||||||
|
2024-12-30 20:03:54,582 - evalscope - INFO - task_level Report:
|
||||||
|
+-----------+---------------+-------+
|
||||||
|
| task_type | average_score | count |
|
||||||
|
+-----------+---------------+-------+
|
||||||
|
| reasoning | 0.4464 | 56 |
|
||||||
|
| math | 0.0227 | 44 |
|
||||||
|
+-----------+---------------+-------+
|
||||||
|
2024-12-30 20:03:54,583 - evalscope - INFO - tag_level Report:
|
||||||
|
+----------------+---------------+-------+
|
||||||
|
| tags | average_score | count |
|
||||||
|
+----------------+---------------+-------+
|
||||||
|
| en | 0.26 | 100 |
|
||||||
|
| math&reasoning | 0.26 | 100 |
|
||||||
|
| reasoning | 0.4464 | 56 |
|
||||||
|
| math | 0.0227 | 44 |
|
||||||
|
+----------------+---------------+-------+
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
# Mixed Data Evaluation
|
||||||
|
|
||||||
|
This framework supports mixing multiple evaluation datasets for a unified evaluation, aiming to use less data to achieve a more comprehensive assessment of the model's capabilities.
|
||||||
|
|
||||||
|
The overall evaluation process is as follows:
|
||||||
|
|
||||||
|
1. Define a data mixing schema: Specify which datasets to use for evaluation and how the data should be grouped.
|
||||||
|
2. Sample data: The framework will sample from each specified dataset according to the schema.
|
||||||
|
3. Unified evaluation: The sampled data will be used in a unified evaluation process.
|
||||||
|
|
||||||
|
:::{toctree}
|
||||||
|
:maxdepth: 2
|
||||||
|
|
||||||
|
schema.md
|
||||||
|
sample.md
|
||||||
|
evaluate.md
|
||||||
|
:::
|
||||||
|
|
@ -0,0 +1,62 @@
|
||||||
|
# Sampling Data
|
||||||
|
|
||||||
|
In mixed data evaluation, sampling data is the second step, and currently, three sampling methods are supported: weighted sampling, stratified sampling, and uniform sampling.
|
||||||
|
|
||||||
|
## Data Format
|
||||||
|
|
||||||
|
The sampled data format is JSON Lines (jsonl), where each line is a JSON object containing properties such as `index`, `prompt`, `tags`, `task_type`, `weight`, `dataset_name`, and `subset_name`.
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"index": 0,
|
||||||
|
"prompt": {"question": "What is the capital of France?"},
|
||||||
|
"tags": ["en", "reasoning"],
|
||||||
|
"task_type": "question_answering",
|
||||||
|
"weight": 1.0,
|
||||||
|
"dataset_name": "arc",
|
||||||
|
"subset_name": "ARC-Easy"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Weighted Sampling
|
||||||
|
|
||||||
|
Weighted sampling is based on the weights of the datasets. The larger the weight, the more samples are taken from that dataset. For nested schemas, the weighted sampling scales according to the weight of each schema, ensuring that the total weight of all datasets sums to 1.
|
||||||
|
|
||||||
|
For example, if a total of 100 samples are to be taken, and there are two datasets in the schema, with Dataset A having a weight of 3 and Dataset B having a weight of 1, then Dataset A will have 75 samples and Dataset B will have 25 samples.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.collections import WeightedSampler
|
||||||
|
from evalscope.utils.io_utils import dump_jsonl_data
|
||||||
|
|
||||||
|
sampler = WeightedSampler(schema)
|
||||||
|
mixed_data = sampler.sample(100)
|
||||||
|
dump_jsonl_data(mixed_data, 'outputs/weighted_mixed_data.jsonl')
|
||||||
|
```
|
||||||
|
|
||||||
|
## Stratified Sampling
|
||||||
|
|
||||||
|
Stratified sampling takes samples based on the number of samples in each dataset in the schema, with the number of samples taken from each dataset being proportional to its number of samples.
|
||||||
|
|
||||||
|
For example, if a total of 100 samples are to be taken, and there are two datasets in the schema, with Dataset A having 800 samples and Dataset B having 200 samples, then Dataset A will have 80 samples and Dataset B will have 20 samples.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.collections import StratifiedSampler
|
||||||
|
|
||||||
|
sampler = StratifiedSampler(schema)
|
||||||
|
mixed_data = sampler.sample(100)
|
||||||
|
dump_jsonl_data(mixed_data, 'outputs/stratified_mixed_data.jsonl')
|
||||||
|
```
|
||||||
|
|
||||||
|
## Uniform Sampling
|
||||||
|
|
||||||
|
Uniform sampling takes the same number of samples from each dataset in the schema.
|
||||||
|
|
||||||
|
For example, if a total of 100 samples are to be taken, and there are two datasets in the schema, with Dataset A having 800 samples and Dataset B having 200 samples, then both Dataset A and Dataset B will have 50 samples each.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.collections import UniformSampler
|
||||||
|
|
||||||
|
sampler = UniformSampler(schema)
|
||||||
|
mixed_data = sampler.sample(100)
|
||||||
|
dump_jsonl_data(mixed_data, 'outputs/uniform_mixed_data.jsonl')
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,113 @@
|
||||||
|
# Defining the Data Mixing Schema
|
||||||
|
|
||||||
|
The data mixing schema defines which datasets are used for evaluation and how the data is grouped. This is the first step in the mixed data evaluation process.
|
||||||
|
|
||||||
|
## Creating the Schema
|
||||||
|
|
||||||
|
An example of a data mixing schema (CollectionSchema) is shown below:
|
||||||
|
|
||||||
|
**Simple Example**
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.collections import CollectionSchema, DatasetInfo
|
||||||
|
|
||||||
|
simple_schema = CollectionSchema(name='reasoning', datasets=[
|
||||||
|
DatasetInfo(name='arc', weight=1, task_type='reasoning', tags=['en']),
|
||||||
|
DatasetInfo(name='ceval', weight=1, task_type='reasoning', tags=['zh'], args={'subset_list': ['logic']})
|
||||||
|
])
|
||||||
|
```
|
||||||
|
Where:
|
||||||
|
- `name` is the name of the data mixing schema.
|
||||||
|
- `datasets` is a list of datasets, where each dataset (DatasetInfo) includes attributes such as `name`, `weight`, `task_type`, `tags`, and `args`.
|
||||||
|
- `name` is the name of the dataset. Supported dataset names can be found in the [dataset list](../../get_started/supported_dataset/llm.md).
|
||||||
|
- `weight` is the weight of the dataset, used for weighted sampling. The default is 1.0, and all data will be normalized during sampling. (The value must be greater than 0)
|
||||||
|
- `task_type` is the task type of the dataset and can be filled in as needed.
|
||||||
|
- `tags` are labels for the dataset, which can also be filled in as needed.
|
||||||
|
- `args` are parameters for the dataset, and the configurable parameters can be found in the [dataset parameters](../../get_started/parameters.md#dataset-parameters).
|
||||||
|
- `hierarchy` is the hierarchy of the dataset, which is automatically generated by the schema.
|
||||||
|
|
||||||
|
**Complex Example**
|
||||||
|
|
||||||
|
```python
|
||||||
|
complex_schema = CollectionSchema(name='math&reasoning', datasets=[
|
||||||
|
CollectionSchema(name='math', weight=3, datasets=[
|
||||||
|
DatasetInfo(name='gsm8k', weight=1, task_type='math', tags=['en']),
|
||||||
|
DatasetInfo(name='competition_math', weight=1, task_type='math', tags=['en']),
|
||||||
|
DatasetInfo(name='cmmlu', weight=1, task_type='math', tags=['zh'], args={'subset_list': ['college_mathematics', 'high_school_mathematics']}),
|
||||||
|
DatasetInfo(name='ceval', weight=1, task_type='math', tags=['zh'], args={'subset_list': ['advanced_mathematics', 'high_school_mathematics', 'discrete_mathematics', 'middle_school_mathematics']}),
|
||||||
|
]),
|
||||||
|
CollectionSchema(name='reasoning', weight=1, datasets=[
|
||||||
|
DatasetInfo(name='arc', weight=1, task_type='reasoning', tags=['en']),
|
||||||
|
DatasetInfo(name='ceval', weight=1, task_type='reasoning', tags=['zh'], args={'subset_list': ['logic']}),
|
||||||
|
DatasetInfo(name='race', weight=1, task_type='reasoning', tags=['en']),
|
||||||
|
]),
|
||||||
|
])
|
||||||
|
```
|
||||||
|
- `weight` is the weight of the data mixing schema, used for weighted sampling. The default is 1.0, and all data will be normalized during sampling. (The value must be greater than 0)
|
||||||
|
- `datasets` can contain CollectionSchema, enabling the nesting of datasets. During evaluation, the name of the `CollectionSchema` will be recursively added to the tags of each sample.
|
||||||
|
|
||||||
|
## Using the Schema
|
||||||
|
|
||||||
|
- To view the created schema:
|
||||||
|
|
||||||
|
```python
|
||||||
|
print(simple_schema)
|
||||||
|
```
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"name": "reasoning",
|
||||||
|
"datasets": [
|
||||||
|
{
|
||||||
|
"name": "arc",
|
||||||
|
"weight": 1,
|
||||||
|
"task_type": "reasoning",
|
||||||
|
"tags": [
|
||||||
|
"en",
|
||||||
|
"reasoning"
|
||||||
|
],
|
||||||
|
"args": {}
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"name": "ceval",
|
||||||
|
"weight": 1,
|
||||||
|
"task_type": "reasoning",
|
||||||
|
"tags": [
|
||||||
|
"zh",
|
||||||
|
"reasoning"
|
||||||
|
],
|
||||||
|
"args": {
|
||||||
|
"subset_list": [
|
||||||
|
"logic"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
- To view the flatten result of the schema (automatically normalized weights):
|
||||||
|
|
||||||
|
```python
|
||||||
|
print(complex_schema.flatten())
|
||||||
|
```
|
||||||
|
```text
|
||||||
|
DatasetInfo(name='gsm8k', weight=0.1875, task_type='math', tags=['en', 'math&reasoning', 'math'], args={})
|
||||||
|
DatasetInfo(name='competition_math', weight=0.1875, task_type='math', tags=['en', 'math&reasoning', 'math'], args={})
|
||||||
|
DatasetInfo(name='cmmlu', weight=0.1875, task_type='math', tags=['zh', 'math&reasoning', 'math'], args={'subset_list': ['college_mathematics', 'high_school_mathematics']})
|
||||||
|
DatasetInfo(name='ceval', weight=0.1875, task_type='math', tags=['zh', 'math&reasoning', 'math'], args={'subset_list': ['advanced_mathematics', 'high_school_mathematics', 'discrete_mathematics', 'middle_school_mathematics']})
|
||||||
|
DatasetInfo(name='arc', weight=0.08333333333333333, task_type='reasoning', tags=['en', 'math&reasoning', 'reasoning'], args={})
|
||||||
|
DatasetInfo(name='ceval', weight=0.08333333333333333, task_type='reasoning', tags=['zh', 'math&reasoning', 'reasoning'], args={'subset_list': ['logic']})
|
||||||
|
DatasetInfo(name='race', weight=0.08333333333333333, task_type='reasoning', tags=['en', 'math&reasoning', 'reasoning'], args={})
|
||||||
|
```
|
||||||
|
|
||||||
|
- To save the schema:
|
||||||
|
|
||||||
|
```python
|
||||||
|
schema.dump_json('outputs/schema.json')
|
||||||
|
```
|
||||||
|
|
||||||
|
- To load the schema from a JSON file:
|
||||||
|
|
||||||
|
```python
|
||||||
|
schema = CollectionSchema.from_json('outputs/schema.json')
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,195 @@
|
||||||
|
# CLIP Model
|
||||||
|
|
||||||
|
## Custom Image-Text Retrieval Dataset
|
||||||
|
|
||||||
|
### 1. Prepare the Dataset
|
||||||
|
|
||||||
|
Prepare the `image_queries.jsonl` dataset for image-text retrieval in the following format (file name must be fixed):
|
||||||
|
|
||||||
|
```{code-block} json
|
||||||
|
:caption: custom_eval/multimodal/text-image-retrieval/image_queries.jsonl
|
||||||
|
|
||||||
|
{"image_path": "custom_eval/multimodal/images/dog.jpg", "query": ["dog"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/AMNH.jpg", "query": ["building"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tokyo.jpg", "query": ["city", "tokyo"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/tesla.jpg", "query": ["car", "tesla"]}
|
||||||
|
{"image_path": "custom_eval/multimodal/images/running.jpg", "query": ["man", "running"]}
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
- `image_path`: Path to the image, supporting local paths.
|
||||||
|
- `query`: Text descriptions for image-text retrieval, supporting multiple descriptions, such as `["dog", "cat"]`.
|
||||||
|
|
||||||
|
### 2. Configure Evaluation Parameters
|
||||||
|
|
||||||
|
```python
|
||||||
|
task_cfg = {
|
||||||
|
"eval_backend": "RAGEval",
|
||||||
|
"eval_config": {
|
||||||
|
"tool": "clip_benchmark",
|
||||||
|
"eval": {
|
||||||
|
"models": [
|
||||||
|
{
|
||||||
|
"model_name": "AI-ModelScope/chinese-clip-vit-large-patch14-336px",
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"dataset_name": ["custom"],
|
||||||
|
"data_dir": "custom_eval/multimodal/text-image-retrieval",
|
||||||
|
"split": "test",
|
||||||
|
"batch_size": 128,
|
||||||
|
"num_workers": 1,
|
||||||
|
"verbose": True,
|
||||||
|
"skip_existing": False,
|
||||||
|
"limit": 1000,
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
```
|
||||||
|
```{seealso}
|
||||||
|
[Full Parameter Explanation](../../user_guides/backend/rageval_backend/clip_benchmark.md#configure-evaluation-parameters)
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
- `dataset_name`: Dataset name, must be specified as `custom`.
|
||||||
|
- `data_dir`: Dataset directory, containing the `image_queries.jsonl` file.
|
||||||
|
|
||||||
|
### 3. Run Evaluation Task
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
The evaluation output is as follows:
|
||||||
|
```json
|
||||||
|
{"dataset": "custom", "model": "AI-ModelScope/chinese-clip-vit-large-patch14-336px", "task": "zeroshot_retrieval", "metrics": {"image_retrieval_recall@5": 1.0, "text_retrieval_recall@5": 1.0}}
|
||||||
|
```
|
||||||
|
|
||||||
|
## Convert Image-Text Retrieval Data to Text Retrieval Data
|
||||||
|
|
||||||
|
To facilitate the evaluation of different multimodal retrieval methods, this framework supports converting image-text retrieval problems into text retrieval problems using a multimodal large model, followed by text retrieval evaluation.
|
||||||
|
|
||||||
|
### 1. Prepare the Dataset
|
||||||
|
|
||||||
|
Supported input datasets include [image-text retrieval datasets](../../user_guides/backend/rageval_backend/clip_benchmark.md#supported-datasets) and the custom image-text retrieval dataset mentioned above.
|
||||||
|
|
||||||
|
### 2. Configure Evaluation Parameters
|
||||||
|
|
||||||
|
```python
|
||||||
|
task_cfg = {
|
||||||
|
"eval_backend": "RAGEval",
|
||||||
|
"eval_config": {
|
||||||
|
"tool": "clip_benchmark",
|
||||||
|
"eval": {
|
||||||
|
"models": [
|
||||||
|
{
|
||||||
|
"model_name": "internvl2-8b",
|
||||||
|
"api_base": "http://localhost:8008/v1",
|
||||||
|
"api_key": "xxx",
|
||||||
|
"prompt": "用中文描述这张图片",
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"dataset_name": ["muge"],
|
||||||
|
"split": "test",
|
||||||
|
"task": "image_caption",
|
||||||
|
"batch_size": 2,
|
||||||
|
"num_workers": 1,
|
||||||
|
"verbose": True,
|
||||||
|
"skip_existing": False,
|
||||||
|
"limit": 10,
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Parameter Explanation:
|
||||||
|
- The `models` list must include a multimodal large model configuration:
|
||||||
|
- `model_name`: Name of the multimodal large model, e.g., `internvl2-8b`.
|
||||||
|
- `api_base`: API address of the multimodal large model, e.g., `http://localhost:8008/v1`.
|
||||||
|
- `api_key`: API key for the multimodal large model, e.g., `xxx`.
|
||||||
|
- `prompt`: Prompt for the multimodal large model input, e.g., `"用中文描述这张图片"`.
|
||||||
|
- `task`: Evaluation task, must be specified as `image_caption`.
|
||||||
|
|
||||||
|
### 3. Run the Conversion Task
|
||||||
|
|
||||||
|
Run the following code to start the conversion:
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
The output is as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
2024-10-22 19:56:09,832 - evalscope - INFO - Write files to outputs/internvl2-8b/muge/retrieval_data
|
||||||
|
2024-10-22 19:56:10,543 - evalscope - INFO - Evaluation results: {'dataset': 'muge', 'model': 'internvl2-8b', 'task': 'image_caption', 'metrics': {'convertion_successful': True, 'save_path': 'outputs/internvl2-8b/muge/retrieval_data'}}
|
||||||
|
2024-10-22 19:56:10,544 - evalscope - INFO - Dump results to: outputs/internvl2-8b/muge_image_caption.json
|
||||||
|
```
|
||||||
|
|
||||||
|
The output file directory structure is as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
muge
|
||||||
|
├── retrieval_data
|
||||||
|
│ ├── corpus.jsonl
|
||||||
|
│ ├── queries.jsonl
|
||||||
|
│ └── qrels
|
||||||
|
│ └── test.tsv
|
||||||
|
└── muge_image_caption.json
|
||||||
|
```
|
||||||
|
|
||||||
|
The specific contents of the files are as follows:
|
||||||
|
|
||||||
|
```{code-block} json
|
||||||
|
:caption: outputs/internvl2-8b/muge/retrieval_data/corpus.jsonl
|
||||||
|
|
||||||
|
{"_id":0,"text":"这是一张展示澳亚奇品牌的产品广告图片,图片中包含了六罐澳亚奇品牌的饮料,饮料罐上印有品牌的名称和图案。饮料罐排列在纸箱上,纸箱上也有品牌名称和图案。整个包装以红色和黄色为主基调,给人以醒目和吸引人的感觉。"}
|
||||||
|
{"_id":1,"text":"这是一副时尚的眼镜,镜框是金属材质的,颜色为玫瑰金色,镜腿部分是黑色的。镜腿的内侧有品牌标志,看起来像是“The Row”。这款眼镜的设计比较现代,适合日常佩戴。"}
|
||||||
|
{"_id":2,"text":"这张图片展示了一位女性,她正在用手机拍摄自己的侧脸自拍。她有长长的棕色头发,并佩戴着一对精美的耳环。耳环的设计有点像是字母“A”。背景是室内环境,可以看到淡蓝色墙壁和浅色的柜子。"}
|
||||||
|
{"_id":3,"text":"这是一张黑色塑料瓶的图片,瓶身上贴有红色标签,标签上有白色和黄色的文字。标签上内容包括产品名称、品牌和一些图案。瓶口是红色和灰色的盖子。"}
|
||||||
|
{"_id":4,"text":"这是一张客厅的照片,里面有一把单人沙发椅。沙发的靠背和坐垫上有黑白相间的斑马纹图案,椅子的框架是黑色的木制结构,带有卷曲的扶手。沙发的腿部是黑色的,造型优雅。沙发布置在一个铺有地毯的地板上,背景中可以看到部分沙发和装饰画,整个房间的装饰风格显得温馨且现代。"}
|
||||||
|
{"_id":5,"text":"这是一张一次性纸杯的图片。纸杯呈圆柱形,杯壁较为光滑,没有明显的装饰或花纹。杯口部分略微向外扩展,便于抓握。杯子整体呈浅灰色或乳白色,质地看起来较为轻薄。这种纸杯常用于盛装饮料或冷食,适合一次性使用。"}
|
||||||
|
{"_id":6,"text":"这张图片展示的是四个卡通人物,背景有五彩斑斓的光芒。从左到右,这四个角色分别是:\n\n1. 一个穿着蓝色服装、戴着紫色头巾和发饰的角色。\n2. 一个穿着蓝绿色服装、戴着蓝色发饰和翅膀的角色。\n3. 一个穿着粉红色服装、带着红色头饰和翅膀的角色。\n4. 一个穿着红色和白色服装、戴着红色头饰的角色。\n\n背景中,有“新格林童话”和“NEW GREEN”的字样。"}
|
||||||
|
{"_id":7,"text":"这是一张展示手中握着蓝色葡萄的照片。手的主人穿着绿色的毛衣,手指修长。葡萄颜色深蓝,表面光滑,每颗葡萄看起来都十分饱满多汁。旁边有一些绿色叶子和干燥的枝条做装饰。背景是一张木质的桌子,整体画面给人一种自然清新的感觉。"}
|
||||||
|
{"_id":8,"text":"这张图片展示了一个可爱的小马克杯,杯身是浅绿色,配有圆弧形的手柄。杯子上绘有可爱的卡通图案,包括一只戴着耳机的小兔子,并配有“热爱学习”字样,旁边还有两只小耳朵和几颗星星。整个马克杯的设计简洁可爱,适合用作日常饮品盛器。"}
|
||||||
|
{"_id":9,"text":"这是一张展示塑料包装中大量线状物体的图片。这些线状物体堆叠在一起,看起来像是一些纤维或麻线,可能是用于编织或加工的。"}
|
||||||
|
```
|
||||||
|
|
||||||
|
```{code-block} json
|
||||||
|
:caption: outputs/internvl2-8b/muge/retrieval_data/queries.jsonl
|
||||||
|
|
||||||
|
{"_id":0,"text":"酸角汁饮料 整箱 云南"}
|
||||||
|
{"_id":1,"text":"达芬奇眼镜"}
|
||||||
|
{"_id":2,"text":"水钻蝴蝶结耳钉"}
|
||||||
|
{"_id":3,"text":"邓州黄酒"}
|
||||||
|
{"_id":4,"text":"斑马纹老虎椅"}
|
||||||
|
{"_id":5,"text":"布丁杯模具"}
|
||||||
|
{"_id":6,"text":"光之美少女盒蛋"}
|
||||||
|
{"_id":7,"text":"蓝莓模型"}
|
||||||
|
{"_id":8,"text":"少女心喝水杯"}
|
||||||
|
{"_id":9,"text":"炸面"}
|
||||||
|
```
|
||||||
|
|
||||||
|
```{code-block}
|
||||||
|
:caption: outputs/internvl2-8b/muge/retrieval_data/qrels/test.tsv
|
||||||
|
|
||||||
|
query-id corpus-id score
|
||||||
|
0 0 1
|
||||||
|
1 1 1
|
||||||
|
2 2 1
|
||||||
|
3 3 1
|
||||||
|
4 4 1
|
||||||
|
5 5 1
|
||||||
|
6 6 1
|
||||||
|
7 7 1
|
||||||
|
8 8 1
|
||||||
|
9 9 1
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4. Execute Text Retrieval Task
|
||||||
|
|
||||||
|
Once the dataset is ready, you can perform text retrieval tasks as per the CMTEB tutorial.
|
||||||
|
```{seealso}
|
||||||
|
Refer to [Custom Text Retrieval Evaluation](./embedding.md)
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,109 @@
|
||||||
|
# Embedding Model
|
||||||
|
|
||||||
|
## Custom Text Retrieval Evaluation
|
||||||
|
|
||||||
|
### 1. Construct Dataset
|
||||||
|
|
||||||
|
Create data in the following format:
|
||||||
|
|
||||||
|
```
|
||||||
|
retrieval_data
|
||||||
|
├── corpus.jsonl
|
||||||
|
├── queries.jsonl
|
||||||
|
└── qrels
|
||||||
|
└── test.tsv
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
- `corpus.jsonl`: The corpus file, each line is a JSON object with the format `{"_id": "xxx", "text": "xxx"}`. `_id` is the corpus ID, and `text` is the corpus text. Example:
|
||||||
|
```json
|
||||||
|
{"_id": "doc1", "text": "Climate change is leading to more extreme weather patterns."}
|
||||||
|
{"_id": "doc2", "text": "The stock market surged today, led by tech stocks."}
|
||||||
|
{"_id": "doc3", "text": "Artificial intelligence is transforming industries by automating tasks and providing insights."}
|
||||||
|
{"_id": "doc4", "text": "With technological advances, renewable energy like wind and solar is becoming more prevalent."}
|
||||||
|
{"_id": "doc5", "text": "Recent studies show that a balanced diet and regular exercise can significantly improve mental health."}
|
||||||
|
{"_id": "doc6", "text": "Virtual reality is creating new opportunities in education, entertainment, and training."}
|
||||||
|
{"_id": "doc7", "text": "Electric vehicles are gaining popularity due to environmental benefits and advancements in battery technology."}
|
||||||
|
{"_id": "doc8", "text": "Space exploration missions are uncovering new information about our solar system and beyond."}
|
||||||
|
{"_id": "doc9", "text": "Blockchain technology has potential applications beyond cryptocurrencies, including supply chain management and secure voting systems."}
|
||||||
|
{"_id": "doc10", "text": "The benefits of remote work include greater flexibility and reduced commuting time."}
|
||||||
|
```
|
||||||
|
|
||||||
|
- `queries.jsonl`: The queries file, each line is a JSON object with the format `{"_id": "xxx", "text": "xxx"}`. `_id` is the query ID, and `text` is the query text. Example:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"_id": "query1", "text": "What are the impacts of climate change?"}
|
||||||
|
{"_id": "query2", "text": "What caused the stock market to rise today?"}
|
||||||
|
{"_id": "query3", "text": "How is artificial intelligence changing industries?"}
|
||||||
|
{"_id": "query4", "text": "What advancements have been made in renewable energy?"}
|
||||||
|
{"_id": "query5", "text": "How does a balanced diet improve mental health?"}
|
||||||
|
{"_id": "query6", "text": "What new opportunities has virtual reality created?"}
|
||||||
|
{"_id": "query7", "text": "Why are electric vehicles becoming more popular?"}
|
||||||
|
{"_id": "query8", "text": "What new information has been revealed by space exploration missions?"}
|
||||||
|
{"_id": "query9", "text": "What are the applications of blockchain technology beyond cryptocurrencies?"}
|
||||||
|
{"_id": "query10", "text": "What are the benefits of remote work?"}
|
||||||
|
```
|
||||||
|
|
||||||
|
- `qrels`: The relevance judgments file, which can include multiple `tsv` files with the format `query-id doc-id score`. `query-id` is the query ID, `doc-id` is the corpus ID, and `score` is the relevance score of the corpus to the query. Example:
|
||||||
|
```
|
||||||
|
query-id corpus-id score
|
||||||
|
query1 doc1 1
|
||||||
|
query2 doc2 1
|
||||||
|
query3 doc3 1
|
||||||
|
query4 doc4 1
|
||||||
|
query5 doc5 1
|
||||||
|
query6 doc6 1
|
||||||
|
query7 doc7 1
|
||||||
|
query8 doc8 1
|
||||||
|
query9 doc9 1
|
||||||
|
query10 doc10 1
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2. Construct Configuration File
|
||||||
|
|
||||||
|
Here is an example configuration file:
|
||||||
|
|
||||||
|
```python
|
||||||
|
task_cfg = {
|
||||||
|
"work_dir": "outputs",
|
||||||
|
"eval_backend": "RAGEval",
|
||||||
|
"eval_config": {
|
||||||
|
"tool": "MTEB",
|
||||||
|
"model": [
|
||||||
|
{
|
||||||
|
"model_name_or_path": "AI-ModelScope/m3e-base",
|
||||||
|
"pooling_mode": None, # load from model config
|
||||||
|
"max_seq_length": 512,
|
||||||
|
"prompt": "",
|
||||||
|
"model_kwargs": {"torch_dtype": "auto"},
|
||||||
|
"encode_kwargs": {
|
||||||
|
"batch_size": 128,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"eval": {
|
||||||
|
"tasks": ["CustomRetrieval"],
|
||||||
|
"dataset_path": "custom_eval/text/retrieval",
|
||||||
|
"verbosity": 2,
|
||||||
|
"overwrite_results": True,
|
||||||
|
"limits": 500,
|
||||||
|
},
|
||||||
|
},
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**Parameter Explanation**
|
||||||
|
|
||||||
|
The basic parameters are consistent with the [default configuration](../../user_guides/backend/rageval_backend/mteb.md#parameter-explanation). The parameters that need modification are:
|
||||||
|
- `eval`:
|
||||||
|
- `tasks`: Evaluation task, must be `CustomRetrieval`.
|
||||||
|
- `dataset_path`: Dataset path, which is the path to the custom dataset.
|
||||||
|
|
||||||
|
### 3. Run Evaluation
|
||||||
|
|
||||||
|
Run the following code to start the evaluation:
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,12 @@
|
||||||
|
# Custom Datasets
|
||||||
|
|
||||||
|
The following section introduces how to use EvalScope to customize evaluation datasets, including large model evaluation datasets, multimodal evaluation datasets, embedding models, and CLIP model evaluations.
|
||||||
|
|
||||||
|
:::{toctree}
|
||||||
|
:maxdepth: 2
|
||||||
|
|
||||||
|
llm.md
|
||||||
|
vlm.md
|
||||||
|
embedding.md
|
||||||
|
clip.md
|
||||||
|
:::
|
||||||
|
|
@ -0,0 +1,282 @@
|
||||||
|
# Large Language Model
|
||||||
|
|
||||||
|
This framework supports multiple-choice questions and question-answering questions, with two predefined dataset formats. The usage process is as follows:
|
||||||
|
|
||||||
|
## Multiple-Choice Question Format (MCQ)
|
||||||
|
Suitable for scenarios where users need multiple-choice questions. The evaluation metric is accuracy.
|
||||||
|
|
||||||
|
### 1. Data Preparation
|
||||||
|
|
||||||
|
Prepare files in multiple-choice question format, supporting both CSV and JSONL formats. The directory structure is as follows:
|
||||||
|
|
||||||
|
**CSV Format**
|
||||||
|
|
||||||
|
```text
|
||||||
|
mcq/
|
||||||
|
├── example_dev.csv # (Optional) File name composed of `{subset_name}_dev.csv`, used for few-shot evaluation
|
||||||
|
└── example_val.csv # File name composed of `{subset_name}_val.csv`, used for actual evaluation data
|
||||||
|
```
|
||||||
|
|
||||||
|
CSV files should be in the following format:
|
||||||
|
|
||||||
|
```text
|
||||||
|
id,question,A,B,C,D,answer
|
||||||
|
1,Generally speaking, the amino acids that make up animal proteins are ____,4 types,22 types,20 types,19 types,C
|
||||||
|
2,Among the substances present in the blood, which one is not a metabolic end product?____,Urea,Uric acid,Pyruvic acid,Carbon dioxide,C
|
||||||
|
```
|
||||||
|
|
||||||
|
**JSONL Format**
|
||||||
|
|
||||||
|
```text
|
||||||
|
mcq/
|
||||||
|
├── example_dev.jsonl # (Optional) File name composed of `{subset_name}_dev.jsonl`, used for few-shot evaluation
|
||||||
|
└── example_val.jsonl # File name composed of `{subset_name}_val.jsonl`, used for actual evaluation data
|
||||||
|
```
|
||||||
|
|
||||||
|
JSONL files should be in the following format:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"id": "1", "question": "Generally speaking, the amino acids that make up animal proteins are ____", "A": "4 types", "B": "22 types", "C": "20 types", "D": "19 types", "answer": "C"}
|
||||||
|
{"id": "2", "question": "Among the substances present in the blood, which one is not a metabolic end product?____", "A": "Urea", "B": "Uric acid", "C": "Pyruvic acid", "D": "Carbon dioxide", "answer": "C"}
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
- `id` is the serial number (optional field)
|
||||||
|
- `question` is the query
|
||||||
|
- `A`, `B`, `C`, `D`, etc., are the options, supporting up to 10 choices
|
||||||
|
- `answer` is the correct option
|
||||||
|
|
||||||
|
### 2. Configuration Task
|
||||||
|
|
||||||
|
Run the following code to start the evaluation:
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2-0.5B-Instruct',
|
||||||
|
datasets=['general_mcq'], # Data format, fixed as 'general_mcq' for multiple-choice format
|
||||||
|
dataset_args={
|
||||||
|
'general_mcq': {
|
||||||
|
"local_path": "custom_eval/text/mcq", # Custom dataset path
|
||||||
|
"subset_list": [
|
||||||
|
"example" # Evaluation dataset name, mentioned subset_name
|
||||||
|
]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
)
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
Results:
|
||||||
|
```text
|
||||||
|
+---------------------+-------------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=====================+=============+=================+==========+=======+=========+=========+
|
||||||
|
| Qwen2-0.5B-Instruct | general_mcq | AverageAccuracy | example | 12 | 0.5833 | default |
|
||||||
|
+---------------------+-------------+-----------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## Question-Answering Format (QA)
|
||||||
|
|
||||||
|
This framework accommodates two formats for question-and-answer tasks: those with reference answers and those without.
|
||||||
|
|
||||||
|
1. **Reference Answer** Q&A: Suitable for questions with clear correct answers, with default evaluation metrics being `ROUGE` and `BLEU`. It can also be configured with an LLM judge for semantic correctness assessment.
|
||||||
|
2. **Reference-free Answer** Q&A: Suitable for questions without definitive correct answers, such as open-ended questions. By default, no evaluation metrics are provided, but an LLM judge can be configured to score the generated answers.
|
||||||
|
|
||||||
|
Here's how to use it:
|
||||||
|
|
||||||
|
### Data Preparation
|
||||||
|
|
||||||
|
Prepare a JSONL file in the Q&A format, for example, a directory containing a file:
|
||||||
|
|
||||||
|
```text
|
||||||
|
qa/
|
||||||
|
└── example.jsonl
|
||||||
|
```
|
||||||
|
|
||||||
|
The JSONL file should be formatted as follows:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"system": "You are a geographer", "query": "What is the capital of China?", "response": "The capital of China is Beijing"}
|
||||||
|
{"query": "What is the highest mountain in the world?", "response": "It is Mount Everest"}
|
||||||
|
{"query": "Why are there no penguins in the Arctic?", "response": "Because penguins mostly live in Antarctica"}
|
||||||
|
```
|
||||||
|
|
||||||
|
Where:
|
||||||
|
- `system` is the system prompt (optional field)
|
||||||
|
- `query` is the question (mandatory)
|
||||||
|
- `response` is the correct answer. For reference answer Q&A tasks, this field must exist; for non-reference answer Q&A tasks, it can be empty.
|
||||||
|
|
||||||
|
### Reference Answer Q&A
|
||||||
|
|
||||||
|
Below is how to configure the evaluation of reference answer Q&A tasks using the `Qwen2.5` model on `example.jsonl`.
|
||||||
|
|
||||||
|
**Method 1: Evaluation based on `ROUGE` and `BLEU`**
|
||||||
|
|
||||||
|
Simply run the following code:
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
datasets=['general_qa'], # Data format, fixed as 'general_qa' for Q&A tasks
|
||||||
|
dataset_args={
|
||||||
|
'general_qa': {
|
||||||
|
"local_path": "custom_eval/text/qa", # Custom dataset path
|
||||||
|
"subset_list": [
|
||||||
|
# Evaluation dataset name, the * in *.jsonl above, multiple subsets can be configured
|
||||||
|
"example"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
<details><summary>Click to view evaluation results</summary>
|
||||||
|
|
||||||
|
```text
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+================+============+===========+==========+=======+=========+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-1-R | example | 12 | 0.694 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-1-P | example | 12 | 0.176 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-1-F | example | 12 | 0.2276 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-2-R | example | 12 | 0.4667 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-2-P | example | 12 | 0.0939 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-2-F | example | 12 | 0.1226 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-L-R | example | 12 | 0.6528 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-L-P | example | 12 | 0.1628 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | Rouge-L-F | example | 12 | 0.2063 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | bleu-1 | example | 12 | 0.164 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | bleu-2 | example | 12 | 0.0935 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | bleu-3 | example | 12 | 0.065 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | bleu-4 | example | 12 | 0.0556 | default |
|
||||||
|
+----------------+------------+-----------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
|
||||||
|
**Method 2: Evaluation based on LLM**
|
||||||
|
|
||||||
|
LLM-based evaluation can conveniently assess the correctness of model outputs (or other dimensions of metrics, requiring custom prompt settings). Below is an example configuring `judge_model_args` parameters, using the preset `pattern` mode to determine the correctness of model outputs.
|
||||||
|
|
||||||
|
For a complete explanation of judge parameters, please refer to [documentation](../../get_started/parameters.md#judge-parameters).
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
from evalscope.constants import JudgeStrategy
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
datasets=[
|
||||||
|
'general_qa',
|
||||||
|
],
|
||||||
|
dataset_args={
|
||||||
|
'general_qa': {
|
||||||
|
'dataset_id': 'custom_eval/text/qa',
|
||||||
|
'subset_list': [
|
||||||
|
'example'
|
||||||
|
],
|
||||||
|
}
|
||||||
|
},
|
||||||
|
# judge related parameters
|
||||||
|
judge_model_args={
|
||||||
|
'model_id': 'qwen2.5-72b-instruct',
|
||||||
|
'api_url': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
|
||||||
|
'api_key': os.getenv('DASHSCOPE_API_KEY'),
|
||||||
|
'generation_config': {
|
||||||
|
'temperature': 0.0,
|
||||||
|
'max_tokens': 4096
|
||||||
|
},
|
||||||
|
# Determine if the model output is correct based on reference answers and model output
|
||||||
|
'score_type': 'pattern',
|
||||||
|
},
|
||||||
|
# judge concurrency number
|
||||||
|
judge_worker_num=5,
|
||||||
|
# Use LLM for evaluation
|
||||||
|
judge_strategy=JudgeStrategy.LLM,
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
<details><summary>Click to view evaluation results</summary>
|
||||||
|
|
||||||
|
```text
|
||||||
|
+----------------+------------+----------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+================+============+================+==========+=======+=========+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | AverageAccuracy | example | 12 | 0.583 | default |
|
||||||
|
+----------------+------------+----------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
|
||||||
|
### Reference-free Answer Q&A
|
||||||
|
|
||||||
|
If the dataset lacks reference answers, an LLM judge can be used to evaluate the model's output answers. Without configuring an LLM, no scoring results will be available.
|
||||||
|
|
||||||
|
Below is an example configuring `judge_model_args` parameters, using the preset `numeric` mode to automatically assess model output scores from dimensions such as accuracy, relevance, and usefulness. Higher scores indicate better model output.
|
||||||
|
|
||||||
|
For a complete explanation of judge parameters, please refer to [documentation](../../get_started/parameters.md#judge-parameters).
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
from evalscope.constants import JudgeStrategy
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
datasets=[
|
||||||
|
'general_qa',
|
||||||
|
],
|
||||||
|
dataset_args={
|
||||||
|
'general_qa': {
|
||||||
|
'dataset_id': 'custom_eval/text/qa',
|
||||||
|
'subset_list': [
|
||||||
|
'example'
|
||||||
|
],
|
||||||
|
}
|
||||||
|
},
|
||||||
|
# judge related parameters
|
||||||
|
judge_model_args={
|
||||||
|
'model_id': 'qwen2.5-72b-instruct',
|
||||||
|
'api_url': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
|
||||||
|
'api_key': os.getenv('DASHSCOPE_API_KEY'),
|
||||||
|
'generation_config': {
|
||||||
|
'temperature': 0.0,
|
||||||
|
'max_tokens': 4096
|
||||||
|
},
|
||||||
|
# Direct scoring
|
||||||
|
'score_type': 'numeric',
|
||||||
|
},
|
||||||
|
# judge concurrency number
|
||||||
|
judge_worker_num=5,
|
||||||
|
# Use LLM for evaluation
|
||||||
|
judge_strategy=JudgeStrategy.LLM,
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
<details><summary>Click to view evaluation results</summary>
|
||||||
|
|
||||||
|
```text
|
||||||
|
+----------------+------------+----------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+================+============+================+==========+=======+=========+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | general_qa | AverageAccuracy | example | 12 | 0.6375 | default |
|
||||||
|
+----------------+------------+----------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,189 @@
|
||||||
|
# Multimodal Large Model
|
||||||
|
|
||||||
|
This framework supports multiple-choice questions and QA questions, two predefined dataset formats. The usage process is as follows:
|
||||||
|
|
||||||
|
````{note}
|
||||||
|
Custom dataset evaluation requires using `VLMEvalKit`, which requires additional dependencies:
|
||||||
|
```shell
|
||||||
|
pip install evalscope[vlmeval]
|
||||||
|
```
|
||||||
|
Reference: [Evaluation Backend with VLMEvalKit](../../user_guides/backend/vlmevalkit_backend.md)
|
||||||
|
````
|
||||||
|
|
||||||
|
## Multiple-Choice Question Format (MCQ)
|
||||||
|
|
||||||
|
### 1. Data Preparation
|
||||||
|
The evaluation metric is accuracy, and you need to define a tsv file in the following format (using `\t` as the separator):
|
||||||
|
```text
|
||||||
|
index category answer question A B C D image_path
|
||||||
|
1 Animals A What animal is this? Dog Cat Tiger Elephant /root/LMUData/images/custom_mcq/dog.jpg
|
||||||
|
2 Buildings D What building is this? School Hospital Park Museum /root/LMUData/images/custom_mcq/AMNH.jpg
|
||||||
|
3 Cities B Which city's skyline is this? New York Tokyo Shanghai Paris /root/LMUData/images/custom_mcq/tokyo.jpg
|
||||||
|
4 Vehicles C What is the brand of this car? BMW Audi Tesla Mercedes /root/LMUData/images/custom_mcq/tesla.jpg
|
||||||
|
5 Activities A What is the person in the picture doing? Running Swimming Reading Singing /root/LMUData/images/custom_mcq/running.jpg
|
||||||
|
```
|
||||||
|
Where:
|
||||||
|
- `index` is the question number
|
||||||
|
- `question` is the question
|
||||||
|
- `answer` is the answer
|
||||||
|
- `A`, `B`, `C`, `D` are the options, with at least two options
|
||||||
|
- `answer` is the answer option
|
||||||
|
- `image_path` is the image path (absolute paths are recommended); this can also be replaced with the `image` field, which should be base64 encoded
|
||||||
|
- `category` is the category (optional field)
|
||||||
|
|
||||||
|
Place this file in the `~/LMUData` path, and you can use the filename for evaluation. For example, if the filename is `custom_mcq.tsv`, you can use `custom_mcq` for evaluation.
|
||||||
|
|
||||||
|
### 2. Configuration Task
|
||||||
|
The configuration file can be in `python dict`, `yaml`, or `json` format, for example, the following `config.yaml` file:
|
||||||
|
```yaml
|
||||||
|
eval_backend: VLMEvalKit
|
||||||
|
eval_config:
|
||||||
|
model:
|
||||||
|
- type: qwen-vl-chat # Name of the deployed model
|
||||||
|
name: CustomAPIModel # Fixed value
|
||||||
|
api_base: http://localhost:8000/v1/chat/completions
|
||||||
|
key: EMPTY
|
||||||
|
temperature: 0.0
|
||||||
|
img_size: -1
|
||||||
|
data:
|
||||||
|
- custom_mcq # Name of the custom dataset, placed in `~/LMUData`
|
||||||
|
mode: all
|
||||||
|
limit: 10
|
||||||
|
reuse: false
|
||||||
|
work_dir: outputs
|
||||||
|
nproc: 1
|
||||||
|
```
|
||||||
|
```{seealso}
|
||||||
|
VLMEvalKit [Parameter Description](../../user_guides/backend/vlmevalkit_backend.md#parameter-explanation)
|
||||||
|
```
|
||||||
|
### 3. Running Evaluation
|
||||||
|
|
||||||
|
Run the following code to start the evaluation:
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg='config.yaml')
|
||||||
|
```
|
||||||
|
|
||||||
|
The evaluation results are as follows:
|
||||||
|
```text
|
||||||
|
---------- ----
|
||||||
|
split none
|
||||||
|
Overall 1.0
|
||||||
|
Activities 1.0
|
||||||
|
Animals 1.0
|
||||||
|
Buildings 1.0
|
||||||
|
Cities 1.0
|
||||||
|
Vehicles 1.0
|
||||||
|
---------- ----
|
||||||
|
```
|
||||||
|
|
||||||
|
## Custom QA Question Format (VQA)
|
||||||
|
|
||||||
|
### 1. Data Preparation
|
||||||
|
|
||||||
|
Prepare a QA formatted tsv file as follows:
|
||||||
|
```text
|
||||||
|
index answer question image_path
|
||||||
|
1 Dog What animal is this? /root/LMUData/images/custom_mcq/dog.jpg
|
||||||
|
2 Museum What building is this? /root/LMUData/images/custom_mcq/AMNH.jpg
|
||||||
|
3 Tokyo Which city's skyline is this? /root/LMUData/images/custom_mcq/tokyo.jpg
|
||||||
|
4 Tesla What is the brand of this car? /root/LMUData/images/custom_mcq/tesla.jpg
|
||||||
|
5 Running What is the person in the picture doing? /root/LMUData/images/custom_mcq/running.jpg
|
||||||
|
```
|
||||||
|
This file is similar to the MCQ format, where:
|
||||||
|
- `index` is the question number
|
||||||
|
- `question` is the question
|
||||||
|
- `answer` is the answer
|
||||||
|
- `image_path` is the image path (absolute paths are recommended); this can also be replaced with the `image` field, which should be base64 encoded
|
||||||
|
|
||||||
|
Place this file in the `~/LMUData` path, and you can use the filename for evaluation. For example, if the filename is `custom_vqa.tsv`, you can use `custom_vqa` for evaluation.
|
||||||
|
|
||||||
|
### 2. Custom Evaluation Script
|
||||||
|
|
||||||
|
Below is an example of a custom dataset, implementing a custom QA format evaluation script. This script will automatically load the dataset, use default prompts for QA, and finally compute accuracy as the evaluation metric.
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
import numpy as np
|
||||||
|
from vlmeval.dataset.image_base import ImageBaseDataset
|
||||||
|
from vlmeval.dataset.image_vqa import CustomVQADataset
|
||||||
|
from vlmeval.smp import load, dump, d2df
|
||||||
|
|
||||||
|
class CustomDataset:
|
||||||
|
def load_data(self, dataset):
|
||||||
|
# Load custom dataset
|
||||||
|
data_path = os.path.join(os.path.expanduser("~/LMUData"), f'{dataset}.tsv')
|
||||||
|
return load(data_path)
|
||||||
|
|
||||||
|
def build_prompt(self, line):
|
||||||
|
msgs = ImageBaseDataset.build_prompt(self, line)
|
||||||
|
# Add prompts or custom instructions here
|
||||||
|
msgs[-1]['value'] += '\nAnswer the question in one word or phrase.'
|
||||||
|
return msgs
|
||||||
|
|
||||||
|
def evaluate(self, eval_file, **judge_kwargs):
|
||||||
|
data = load(eval_file)
|
||||||
|
assert 'answer' in data and 'prediction' in data
|
||||||
|
data['prediction'] = [str(x) for x in data['prediction']]
|
||||||
|
data['answer'] = [str(x) for x in data['answer']]
|
||||||
|
|
||||||
|
print(data)
|
||||||
|
|
||||||
|
# ========Compute the evaluation metric as needed=========
|
||||||
|
# Exact match
|
||||||
|
result = np.mean(data['answer'] == data['prediction'])
|
||||||
|
ret = {'Overall': result}
|
||||||
|
ret = d2df(ret).round(2)
|
||||||
|
# Save the result
|
||||||
|
suffix = eval_file.split('.')[-1]
|
||||||
|
result_file = eval_file.replace(f'.{suffix}', '_acc.csv')
|
||||||
|
dump(ret, result_file)
|
||||||
|
return ret
|
||||||
|
# ========================================================
|
||||||
|
|
||||||
|
# Keep the following code and override the default dataset class
|
||||||
|
CustomVQADataset.load_data = CustomDataset.load_data
|
||||||
|
CustomVQADataset.build_prompt = CustomDataset.build_prompt
|
||||||
|
CustomVQADataset.evaluate = CustomDataset.evaluate
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3. Configuration File
|
||||||
|
The configuration file can be in `python dict`, `yaml`, or `json` format. For example, the following `config.yaml` file:
|
||||||
|
```{code-block} yaml
|
||||||
|
:caption: config.yaml
|
||||||
|
|
||||||
|
eval_backend: VLMEvalKit
|
||||||
|
eval_config:
|
||||||
|
model:
|
||||||
|
- type: qwen-vl-chat
|
||||||
|
name: CustomAPIModel
|
||||||
|
api_base: http://localhost:8000/v1/chat/completions
|
||||||
|
key: EMPTY
|
||||||
|
temperature: 0.0
|
||||||
|
img_size: -1
|
||||||
|
data:
|
||||||
|
- custom_vqa # Name of the custom dataset, placed in `~/LMUData`
|
||||||
|
mode: all
|
||||||
|
limit: 10
|
||||||
|
reuse: false
|
||||||
|
work_dir: outputs
|
||||||
|
nproc: 1
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4. Running Evaluation
|
||||||
|
|
||||||
|
The complete evaluation script is as follows:
|
||||||
|
```{code-block} python
|
||||||
|
:emphasize-lines: 1
|
||||||
|
|
||||||
|
from custom_dataset import CustomDataset # Import the custom dataset
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg='config.yaml')
|
||||||
|
```
|
||||||
|
|
||||||
|
The evaluation results are as follows:
|
||||||
|
```text
|
||||||
|
{'qwen-vl-chat_custom_vqa_acc': {'Overall': '1.0'}}
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,171 @@
|
||||||
|
# Custom Model Evaluation
|
||||||
|
|
||||||
|
EvalScope supports model evaluation compatible with the OpenAI API format by default. However, for models that do not support the OpenAI API format, you can implement evaluations through custom model adapters (CustomModel). This document will guide you on how to create a custom model adapter and integrate it into the evaluation workflow.
|
||||||
|
|
||||||
|
## When Do You Need a Custom Model Adapter?
|
||||||
|
|
||||||
|
You might need to create a custom model adapter in the following situations:
|
||||||
|
|
||||||
|
1. Your model does not support the standard OpenAI API format.
|
||||||
|
2. You need to handle special processing for model input and output.
|
||||||
|
3. You need to use specific inference parameters or configurations.
|
||||||
|
|
||||||
|
## How to Implement a Custom Model Adapter
|
||||||
|
|
||||||
|
You need to create a class that inherits from `CustomModel` and implement the `predict` method:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.models import CustomModel
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
class MyCustomModel(CustomModel):
|
||||||
|
def __init__(self, config: dict = None, **kwargs):
|
||||||
|
# Initialize your model, you can pass model parameters in config
|
||||||
|
super(MyCustomModel, self).__init__(config=config, **kwargs)
|
||||||
|
|
||||||
|
# Initialize model resources as needed
|
||||||
|
# For example: load model weights, connect to model service, etc.
|
||||||
|
|
||||||
|
def predict(self, prompts: List[dict], **kwargs):
|
||||||
|
"""
|
||||||
|
The core method for model inference, which takes input prompts and returns model responses
|
||||||
|
|
||||||
|
Args:
|
||||||
|
prompts: List of input prompts, each element is a dictionary
|
||||||
|
**kwargs: Additional inference parameters
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
A list of responses compatible with the OpenAI API format
|
||||||
|
"""
|
||||||
|
# 1. Process input prompts
|
||||||
|
# 2. Call your model for inference
|
||||||
|
# 3. Convert model output to OpenAI API format
|
||||||
|
# 4. Return formatted responses
|
||||||
|
```
|
||||||
|
|
||||||
|
## Example: DummyCustomModel
|
||||||
|
|
||||||
|
Below is a complete example of `DummyCustomModel` that demonstrates how to create and use a custom model adapter:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import time
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
from evalscope.utils.logger import get_logger
|
||||||
|
from evalscope.models import CustomModel
|
||||||
|
|
||||||
|
logger = get_logger()
|
||||||
|
|
||||||
|
class DummyCustomModel(CustomModel):
|
||||||
|
|
||||||
|
def __init__(self, config: dict = {}, **kwargs):
|
||||||
|
super(DummyCustomModel, self).__init__(config=config, **kwargs)
|
||||||
|
|
||||||
|
def make_request_messages(self, input_item: dict) -> list:
|
||||||
|
"""
|
||||||
|
Make request messages for OpenAI API.
|
||||||
|
"""
|
||||||
|
if input_item.get('messages', None):
|
||||||
|
return input_item['messages']
|
||||||
|
|
||||||
|
data: list = input_item['data']
|
||||||
|
if isinstance(data[0], tuple): # for truthful_qa and hellaswag
|
||||||
|
query = '\n'.join(''.join(item) for item in data)
|
||||||
|
system_prompt = input_item.get('system_prompt', None)
|
||||||
|
else:
|
||||||
|
query = data[0]
|
||||||
|
system_prompt = input_item.get('system_prompt', None)
|
||||||
|
|
||||||
|
messages = []
|
||||||
|
if system_prompt:
|
||||||
|
messages.append({'role': 'system', 'content': system_prompt})
|
||||||
|
|
||||||
|
messages.append({'role': 'user', 'content': query})
|
||||||
|
|
||||||
|
return messages
|
||||||
|
|
||||||
|
def predict(self, prompts: List[dict], **kwargs):
|
||||||
|
|
||||||
|
original_inputs = kwargs.get('origin_inputs', None)
|
||||||
|
infer_cfg = kwargs.get('infer_cfg', None)
|
||||||
|
|
||||||
|
logger.debug(f'** Prompts: {prompts}')
|
||||||
|
if original_inputs is not None:
|
||||||
|
logger.debug(f'** Original inputs: {original_inputs}')
|
||||||
|
if infer_cfg is not None:
|
||||||
|
logger.debug(f'** Inference config: {infer_cfg}')
|
||||||
|
|
||||||
|
# Simulate a response based on the prompts
|
||||||
|
# Must return a list of dicts with the same format as the OpenAI API.
|
||||||
|
responses = []
|
||||||
|
for input_item in original_inputs:
|
||||||
|
message = self.make_request_messages(input_item)
|
||||||
|
|
||||||
|
# You can replace this with actual model inference logic
|
||||||
|
# For demonstration, we will just return a dummy response
|
||||||
|
response = f"Dummy response for prompt: {message}"
|
||||||
|
|
||||||
|
res_d = {
|
||||||
|
'choices': [{
|
||||||
|
'index': 0,
|
||||||
|
'message': {
|
||||||
|
'content': response,
|
||||||
|
'role': 'assistant'
|
||||||
|
}
|
||||||
|
}],
|
||||||
|
'created': time.time(),
|
||||||
|
'model': self.config.get('model_id'),
|
||||||
|
'object': 'chat.completion',
|
||||||
|
'usage': {
|
||||||
|
'completion_tokens': 0,
|
||||||
|
'prompt_tokens': 0,
|
||||||
|
'total_tokens': 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
responses.append(res_d)
|
||||||
|
|
||||||
|
return responses
|
||||||
|
```
|
||||||
|
|
||||||
|
**Here is a complete example of evaluating using `DummyCustomModel`:**
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import run_task, TaskConfig
|
||||||
|
from evalscope.models.custom.dummy_model import DummyCustomModel
|
||||||
|
|
||||||
|
# Instantiate DummyCustomModel
|
||||||
|
dummy_model = DummyCustomModel()
|
||||||
|
|
||||||
|
# Configure evaluation task
|
||||||
|
task_config = TaskConfig(
|
||||||
|
model=dummy_model,
|
||||||
|
model_id='dummy-model', # Custom model ID
|
||||||
|
datasets=['gsm8k'],
|
||||||
|
eval_type='custom', # Must be custom
|
||||||
|
generation_config={
|
||||||
|
'max_new_tokens': 100,
|
||||||
|
'temperature': 0.0,
|
||||||
|
'top_p': 1.0,
|
||||||
|
'top_k': 50,
|
||||||
|
'repetition_penalty': 1.0
|
||||||
|
},
|
||||||
|
debug=True,
|
||||||
|
limit=5,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Run evaluation task
|
||||||
|
eval_results = run_task(task_cfg=task_config)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Considerations for Implementing a Custom Model
|
||||||
|
|
||||||
|
1. **Input Format**: The `predict` method receives the `prompts` parameter as a list that contains a batch of input prompts. You need to ensure these prompts are converted into a format that the model can accept.
|
||||||
|
|
||||||
|
2. **Output Format**: The `predict` method must return a response list compatible with the OpenAI API format. Each response must include the `choices` field containing the content generated by the model.
|
||||||
|
|
||||||
|
3. **Error Handling**: Ensure your implementation contains appropriate error handling logic to prevent exceptions during the model inference process.
|
||||||
|
|
||||||
|
## Summary
|
||||||
|
|
||||||
|
By creating a custom model adapter, you can integrate any LLM model into the EvalScope evaluation framework, even if it does not natively support the OpenAI API format. The core of a custom model adapter is implementing the `predict` method, which converts input prompts into a format acceptable by the model, calls the model for inference, and then converts the model output to OpenAI API format.
|
||||||
{kind=link}
|
After Width: | Height: | Size: 1022 KiB |
|
|
@ -0,0 +1,235 @@
|
||||||
|
# Evaluating the Inference Capability of R1 Models
|
||||||
|
|
||||||
|
With the widespread application of the DeepSeek-R1 model, an increasing number of developers are attempting to replicate similar models to enhance their inference capabilities. Many impressive results have emerged; however, do these new models actually demonstrate improved inference capabilities? The EvalScope framework, an open-source evaluation tool available in the Modao community, provides an assessment of the inference performance of R1 models.
|
||||||
|
|
||||||
|
In this best practice guide, we will demonstrate the evaluation process using 728 inference questions (consistent with the R1 technical report). The evaluation data includes:
|
||||||
|
|
||||||
|
- [MATH-500](https://www.modelscope.cn/datasets/HuggingFaceH4/aime_2024): A set of challenging high school mathematics competition problems across seven subjects (such as elementary algebra, algebra, number theory), comprising a total of 500 questions.
|
||||||
|
- [GPQA-Diamond](https://modelscope.cn/datasets/AI-ModelScope/gpqa_diamond/summary): This dataset contains master's level multiple-choice questions in the subfields of physics, chemistry, and biology, totaling 198 questions.
|
||||||
|
- [AIME-2024](https://modelscope.cn/datasets/AI-ModelScope/AIME_2024): A dataset from the American Invitational Mathematics Examination, containing 30 math problems.
|
||||||
|
|
||||||
|
The process outlined in this best practice includes installing the necessary dependencies, preparing the model, evaluating the model, and visualizing the evaluation results. Let’s get started.
|
||||||
|
|
||||||
|
## Installing Dependencies
|
||||||
|
|
||||||
|
First, install the [EvalScope](https://github.com/modelscope/evalscope) model evaluation framework:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope[app,perf]' -U
|
||||||
|
```
|
||||||
|
|
||||||
|
## Model Preparation
|
||||||
|
|
||||||
|
Next, we will introduce the evaluation process using the DeepSeek-R1-Distill-Qwen-1.5B model as an example. The model's capabilities will be accessed via an OpenAI API-compatible inference service for evaluation purposes. EvalScope also supports model evaluation via transformers inference; for details, please refer to the EvalScope documentation.
|
||||||
|
|
||||||
|
In addition to deploying the model on a cloud service that supports the OpenAI API, it can also be run locally using frameworks such as vLLM or ollama. Here, we will introduce the usage of the [vLLM](https://github.com/vllm-project/vllm) and [lmdeploy](https://github.com/InternLM/lmdeploy) inference frameworks, as these can effectively handle multiple concurrent requests to speed up the evaluation process. Since R1 models often produce lengthy reasoning chains with output token counts frequently exceeding 10,000, using efficient inference frameworks can enhance inference speed.
|
||||||
|
|
||||||
|
**Using vLLM**:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --served-model-name DeepSeek-R1-Distill-Qwen-1.5B --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
|
||||||
|
or **Using lmdeploy**:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
LMDEPLOY_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --model-name DeepSeek-R1-Distill-Qwen-1.5B --server-port 8801
|
||||||
|
```
|
||||||
|
|
||||||
|
**(Optional) Test Inference Service Performance**
|
||||||
|
|
||||||
|
Before officially evaluating the model, you can test the performance of the inference service to select a better-performing inference engine using the `evalscope` `perf` subcommand:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
evalscope perf \
|
||||||
|
--parallel 10 \
|
||||||
|
--url http://127.0.0.1:8801/v1/chat/completions \
|
||||||
|
--model DeepSeek-R1-Distill-Qwen-1.5B \
|
||||||
|
--log-every-n-query 5 \
|
||||||
|
--connect-timeout 6000 \
|
||||||
|
--read-timeout 6000 \
|
||||||
|
--api openai \
|
||||||
|
--prompt 'Write a science fiction novel, no less than 2000 words, please start your performance' \
|
||||||
|
-n 100
|
||||||
|
```
|
||||||
|
|
||||||
|
For parameter explanations, please refer to the [Performance Evaluation Quick Start](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/quick_start.html).
|
||||||
|
|
||||||
|
<details><summary>Inference Service Performance Test Results</summary>
|
||||||
|
|
||||||
|
```text
|
||||||
|
Benchmarking summary:
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Key | Value |
|
||||||
|
+===================================+=========================================================================+
|
||||||
|
| Time taken for tests (s) | 92.66 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Number of concurrency | 10 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Total requests | 100 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Succeed requests | 100 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Failed requests | 0 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Throughput(average tokens/s) | 1727.453 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average QPS | 1.079 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average latency (s) | 8.636 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average time to first token (s) | 8.636 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average time per output token (s) | 0.00058 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average input tokens per request | 20.0 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average output tokens per request | 1600.66 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average package latency (s) | 8.636 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Average package per request | 1.0 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Expected number of requests | 100 |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
| Result DB path | outputs/20250213_103632/DeepSeek-R1-Distill-Qwen-1.5B/benchmark_data.db |
|
||||||
|
+-----------------------------------+-------------------------------------------------------------------------+
|
||||||
|
|
||||||
|
Percentile results:
|
||||||
|
+------------+----------+----------+-------------+--------------+---------------+----------------------+
|
||||||
|
| Percentile | TTFT (s) | TPOT (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
|
||||||
|
+------------+----------+----------+-------------+--------------+---------------+----------------------+
|
||||||
|
| 10% | 5.4506 | nan | 5.4506 | 20 | 1011 | 183.7254 |
|
||||||
|
| 25% | 6.1689 | nan | 6.1689 | 20 | 1145 | 184.9222 |
|
||||||
|
| 50% | 9.385 | nan | 9.385 | 20 | 1741 | 185.5081 |
|
||||||
|
| 66% | 11.0023 | nan | 11.0023 | 20 | 2048 | 185.8063 |
|
||||||
|
| 75% | 11.0374 | nan | 11.0374 | 20 | 2048 | 186.1429 |
|
||||||
|
| 80% | 11.047 | nan | 11.047 | 20 | 2048 | 186.3683 |
|
||||||
|
| 90% | 11.075 | nan | 11.075 | 20 | 2048 | 186.5962 |
|
||||||
|
| 95% | 11.147 | nan | 11.147 | 20 | 2048 | 186.7836 |
|
||||||
|
| 98% | 11.1574 | nan | 11.1574 | 20 | 2048 | 187.4917 |
|
||||||
|
| 99% | 11.1688 | nan | 11.1688 | 20 | 2048 | 197.4991 |
|
||||||
|
+------------+----------+----------+-------------+--------------+---------------+----------------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
## Evaluating the Model
|
||||||
|
|
||||||
|
We will integrate the MATH-500, GPQA-Diamond, and AIME-2024 datasets into a single dataset, located in [modelscope/R1-Distill-Math-Test](https://modelscope.cn/datasets/modelscope/R1-Distill-Math-Test). Readers can directly use the dataset ID for evaluation operations.
|
||||||
|
|
||||||
|
If you want to learn about the dataset generation process or customize a dataset, please refer to the [Usage Tutorial](https://evalscope.readthedocs.io/zh-cn/latest/advanced_guides/collection/index.html).
|
||||||
|
|
||||||
|
**Configuring the Evaluation Task**
|
||||||
|
|
||||||
|
You can evaluate the performance of the DeepSeek-R1-Distill-Qwen-1.5B model on the inference dataset using the following Python code:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
from evalscope.constants import EvalType
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='DeepSeek-R1-Distill-Qwen-1.5B', # Model name (must match the name used during deployment)
|
||||||
|
api_url='http://127.0.0.1:8801/v1', # Inference service address
|
||||||
|
api_key='EMPTY',
|
||||||
|
eval_type=EvalType.SERVICE, # Evaluation type, SERVICE indicates evaluation of inference service
|
||||||
|
datasets=[
|
||||||
|
'data_collection', # Dataset name (fixed as data_collection indicates mixed dataset usage)
|
||||||
|
],
|
||||||
|
dataset_args={
|
||||||
|
'data_collection': {
|
||||||
|
'dataset_id': 'modelscope/R1-Distill-Math-Test' # Dataset ID or local path
|
||||||
|
}
|
||||||
|
},
|
||||||
|
eval_batch_size=32, # Number of concurrent requests
|
||||||
|
generation_config={ # Model inference configuration
|
||||||
|
'max_tokens': 20000, # Maximum number of generated tokens, recommended to set a high value to avoid truncation
|
||||||
|
'temperature': 0.6, # Sampling temperature (recommended value from DeepSeek report)
|
||||||
|
'top_p': 0.95, # Top-p sampling (recommended value from DeepSeek report)
|
||||||
|
'n': 5 # Number of replies generated per request (note that lmdeploy currently only supports n=1)
|
||||||
|
},
|
||||||
|
stream=True # Whether to use streaming requests, recommended to set to True to prevent request timeouts
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
**Output Results**:
|
||||||
|
|
||||||
|
**The computed metric here is `AveragePass@1`, and each sample was generated five times, with the final evaluation result being the average of these five attempts.** Due to the sampling during model generation, the output may exhibit some fluctuations.
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-----------+--------------+---------------+-------+
|
||||||
|
| task_type | dataset_name | average_score | count |
|
||||||
|
+-----------+--------------+---------------+-------+
|
||||||
|
| math | math_500 | 0.7832 | 500 |
|
||||||
|
| math | gpqa | 0.3434 | 198 |
|
||||||
|
| math | aime24 | 0.2 | 30 |
|
||||||
|
+-----------+--------------+---------------+-------+
|
||||||
|
```
|
||||||
|
|
||||||
|
----
|
||||||
|
|
||||||
|
If you only wish to run specific datasets, you can modify the `datasets` and `dataset_args` parameters in the above configuration, for example:
|
||||||
|
|
||||||
|
```python
|
||||||
|
datasets=[
|
||||||
|
# 'math_500', # Dataset name
|
||||||
|
'gpqa',
|
||||||
|
'aime24'
|
||||||
|
],
|
||||||
|
dataset_args={ # Built-in support in EvalScope, no need to specify dataset ID
|
||||||
|
'math_500': {'few_shot_num': 0 } ,
|
||||||
|
'gpqa': {'subset_list': ['gpqa_diamond'], 'few_shot_num': 0},
|
||||||
|
'aime24': {'few_shot_num': 0}
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
Other available datasets include `gsm8k`, `aime25`, etc. For details, refer to the [Supported Datasets](https://evalscope.readthedocs.io/zh-cn/latest/get_started/supported_dataset.html).
|
||||||
|
|
||||||
|
## Visualizing Evaluation Results
|
||||||
|
|
||||||
|
EvalScope supports result visualization, allowing you to view the model's specific outputs.
|
||||||
|
|
||||||
|
Run the following command to launch the visualization interface:
|
||||||
|
```bash
|
||||||
|
evalscope app
|
||||||
|
```
|
||||||
|
|
||||||
|
The terminal will output the following link content:
|
||||||
|
```text
|
||||||
|
* Running on local URL: http://0.0.0.0:7860
|
||||||
|
```
|
||||||
|
|
||||||
|
Click the link to see the visualization interface. You need to select the evaluation report and then click load:
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://sail-moe.oss-cn-hangzhou.aliyuncs.com/yunlin/images/distill/score.png" alt="alt text" width="100%">
|
||||||
|
</p>
|
||||||
|
|
||||||
|
Additionally, by selecting the corresponding sub-dataset, you can also view the model's output and check whether the output is correct (or if there are issues with answer matching):
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://sail-moe.oss-cn-hangzhou.aliyuncs.com/yunlin/images/distill/detail.png" alt="alt text" width="100%">
|
||||||
|
</p>
|
||||||
|
|
||||||
|
## Tips
|
||||||
|
|
||||||
|
:::{card}
|
||||||
|
|
||||||
|
💡 Here are some "pitfalls" that may be encountered during evaluation:
|
||||||
|
|
||||||
|
1. **Model Generation Configuration**:
|
||||||
|
- Setting max_tokens: Ensure that max_tokens is set to a large value (usually above 8000). If set too low, the model may be truncated before outputting a complete answer.
|
||||||
|
- Setting the number of replies n: In this evaluation, the number of replies generated per request n is set to 5, while in the R1 report, it was 64. Readers can adjust this parameter according to their needs to balance evaluation speed and result diversity.
|
||||||
|
- Setting stream: The stream parameter should be set to True to prevent the model from timing out while generating long answers.
|
||||||
|
2. **Dataset Prompt Template Settings**:
|
||||||
|
- The prompt template used in this article follows the recommended settings from the R1 report: "Please reason step by step, and put your final answer within \boxed{}."; simultaneously, no system prompt was set. Ensuring the correctness of the prompt template is crucial for generating expected results.
|
||||||
|
- When evaluating reasoning models, it is advisable to set a 0-shot configuration; overly complex prompts or few-shot examples may degrade model performance.
|
||||||
|
3. **Parsing and Matching Generated Answers**:
|
||||||
|
- We reused the parsing method from the Qwen-Math project, which is based on rules for answer parsing. However, this rule-based parsing might lead to matching errors, slightly affecting the reported metrics. It is recommended to utilize the evaluation result visualization feature to check for any discrepancies in parsing results.
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
Through this process, developers can effectively evaluate the performance of R1 models across multiple mathematical and scientific reasoning datasets, allowing for an objective assessment of specific model performances and collectively advancing the development and application of R1 models.
|
||||||
|
|
@ -0,0 +1,211 @@
|
||||||
|
# Evaluating the QwQ Model
|
||||||
|
|
||||||
|
Today (March 6, 2025), the Qwen team released the QwQ-32B model, which has demonstrated performance comparable to DeepSeek-R1-671B in a series of benchmark tests. The results below showcase the performance comparison of QwQ-32B with other leading models.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
In this best practice guide, we will use the [EvalScope](https://github.com/modelscope/evalscope) model evaluation framework to test the reasoning capabilities and thinking efficiency of the QwQ-32B model.
|
||||||
|
|
||||||
|
The process outlined in this guide includes installing relevant dependencies, preparing the model, evaluating the model, and visualizing the results. Let's get started.
|
||||||
|
|
||||||
|
## Installing Dependencies
|
||||||
|
|
||||||
|
First, install the [EvalScope](https://github.com/modelscope/evalscope) evaluation framework:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope[app,perf]' -U
|
||||||
|
```
|
||||||
|
|
||||||
|
## Model Reasoning
|
||||||
|
|
||||||
|
### Preparing the Model for Evaluation
|
||||||
|
|
||||||
|
First, we need to access the model capabilities via an OpenAI API-compatible inference service for evaluation. Notably, EvalScope also supports model inference evaluation using transformers; refer to the EvalScope documentation for detailed information.
|
||||||
|
|
||||||
|
In addition to deploying the model to a cloud service that supports the OpenAI API, you can also choose to launch the model locally using frameworks such as vLLM or Ollama. These inference frameworks effectively support concurrent requests, thereby speeding up the evaluation process. Particularly for R1-type models, the output typically contains long chains of thought, with the number of output tokens often exceeding 10,000. Deploying the model using an efficient inference framework can significantly enhance reasoning speed.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model Qwen/QwQ-32B --served-model-name QwQ-32B --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
|
||||||
|
**Model Inference Speed Test**
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
[QwQ-32B-Preview Model Inference Speed Test](../experiments/speed_benchmark/QwQ-32B-Preview.md)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Evaluating the Model for Mathematical Reasoning
|
||||||
|
|
||||||
|
Run the following command to have the model reason through the MATH-500 dataset and obtain output results for each question, as well as the overall accuracy:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
|
||||||
|
task_config = TaskConfig(
|
||||||
|
api_url='http://0.0.0.0:8801/v1', # Inference service address
|
||||||
|
model='Qwen/QwQ-32B', # Model name (must match the deployed model name)
|
||||||
|
eval_type='service', # Evaluation type; SERVICE indicates evaluating the inference service
|
||||||
|
datasets=['math_500'], # Dataset name
|
||||||
|
dataset_args={'math_500': {'few_shot_num': 0}}, # Dataset parameters
|
||||||
|
eval_batch_size=32, # Number of concurrent requests
|
||||||
|
generation_config={
|
||||||
|
'max_tokens': 32000, # Maximum number of tokens to generate; recommended to set a high value to avoid truncation
|
||||||
|
'temperature': 0.6, # Sampling temperature (recommended value from Qwen)
|
||||||
|
'top_p': 0.95, # Top-p sampling (recommended value from Qwen)
|
||||||
|
'top_k': 40, # Top-k sampling (recommended value from Qwen)
|
||||||
|
'n': 1, # Number of responses generated for each request
|
||||||
|
},
|
||||||
|
)
|
||||||
|
run_task(task_config)
|
||||||
|
```
|
||||||
|
|
||||||
|
The output will look as follows, displaying the model's accuracy on problems at each difficulty level:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+---------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=========+===========+===============+==========+=======+=========+=========+
|
||||||
|
| QwQ-32B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
|
||||||
|
+---------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| QwQ-32B | math_500 | AveragePass@1 | Level 2 | 90 | 1 | default |
|
||||||
|
+---------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| QwQ-32B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9714 | default |
|
||||||
|
+---------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| QwQ-32B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9375 | default |
|
||||||
|
+---------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| QwQ-32B | math_500 | AveragePass@1 | Level 5 | 134 | 0.9403 | default |
|
||||||
|
+---------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
If you want to run the model on [other datasets](../get_started/supported_dataset/llm.md), you can modify the `datasets` and `dataset_args` parameters in the configuration as follows:
|
||||||
|
|
||||||
|
```python
|
||||||
|
datasets=[
|
||||||
|
# 'math_500', # Dataset name
|
||||||
|
'gpqa',
|
||||||
|
'aime24'
|
||||||
|
],
|
||||||
|
dataset_args={
|
||||||
|
# 'math_500': {'few_shot_num': 0 } ,
|
||||||
|
'gpqa': {'subset_list': ['gpqa_diamond'], 'few_shot_num': 0},
|
||||||
|
'aime24': {'few_shot_num': 0}
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
The results will be:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+---------+-----------+---------------+--------------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=========+===========+===============+==============+=======+=========+=========+
|
||||||
|
| QwQ-32B | aime24 | AveragePass@1 | default | 30 | 0.8 | default |
|
||||||
|
+---------+-----------+---------------+--------------+-------+---------+---------+
|
||||||
|
| QwQ-32B | gpqa | AveragePass@1 | gpqa_diamond | 198 | 0.6717 | default |
|
||||||
|
+---------+-----------+---------------+--------------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
### Evaluating Code Capability
|
||||||
|
|
||||||
|
We use [LiveCodeBench](https://www.modelscope.cn/datasets/AI-ModelScope/code_generation_lite) to evaluate the model's code capability. The following configuration is required:
|
||||||
|
|
||||||
|
```python
|
||||||
|
# ...
|
||||||
|
datasets=['live_code_bench'],
|
||||||
|
dataset_args={
|
||||||
|
'live_code_bench': {
|
||||||
|
'extra_params': {
|
||||||
|
'start_date': '2024-08-01',
|
||||||
|
'end_date': '2025-02-28'
|
||||||
|
},
|
||||||
|
"filters": {"remove_until": "</think>"} # Filter out the thinking part of the model inference process
|
||||||
|
}
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
The output results are as follows:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+---------+-----------------+----------+----------------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=========+=================+==========+================+=======+=========+=========+
|
||||||
|
| qwq-32b | live_code_bench | Pass@1 | release_latest | 279 | 0.6237 | default |
|
||||||
|
+---------+-----------------+----------+----------------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## Visualizing Evaluation Results
|
||||||
|
|
||||||
|
EvalScope supports visualizing results, allowing you to see the specific outputs of the model.
|
||||||
|
|
||||||
|
Run the following command to launch the visualization interface:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
evalscope app --lang en
|
||||||
|
```
|
||||||
|
|
||||||
|
Select the evaluation report and click to load it, allowing you to view the model's output for each question, as well as the overall accuracy:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Evaluating Thinking Efficiency
|
||||||
|
|
||||||
|
These reasoning models may exhibit two extreme issues during reasoning: **Underthinking** and **Overthinking**:
|
||||||
|
|
||||||
|
- The phenomenon of **Underthinking** refers to the model frequently shifting its thought process during reasoning, repeatedly using phrases such as "alternatively," "but wait," and "let me reconsider," which prevents the model from focusing on a correct thought process and deeply analyzing it, leading to incorrect answers. This phenomenon is similar to "Attention Deficit Hyperactivity Disorder" in humans, negatively impacting the quality of the model's reasoning.
|
||||||
|
|
||||||
|
- The phenomenon of **Overthinking** manifests as the model generating unnecessarily long chains of thought, wasting substantial computational resources. For example, for a simple question like "2+3=?," some long reasoning models might consume over 900 tokens exploring various problem-solving strategies. While such chain-of-thought strategies are beneficial for complex problems, repeatedly validating existing answers and conducting overly broad explorations for simple problems is clearly a waste of computational resources.
|
||||||
|
|
||||||
|
Both phenomena highlight a key question: how can we improve the thinking efficiency of models while ensuring the quality of their answers? In other words, **we want models to arrive at correct answers with outputs as brief as possible**. We will evaluate the thinking efficiency of QwQ-32B and other models using the [MATH-500](https://www.modelscope.cn/datasets/AI-ModelScope/MATH-500) dataset, assessing model performance across the following six dimensions:
|
||||||
|
|
||||||
|
- **Reasoning Tokens** ($T$): The total number of reasoning tokens generated by the model during the reasoning process, typically measured from the start of reasoning to the `</think>` tag.
|
||||||
|
- **First Correct Tokens** ($\hat{T}$): The number of tokens from the start of the reasoning process to the first position that can be recognized as the correct answer.
|
||||||
|
- **Reflection Tokens**: $T - \hat{T}$, which represents the number of tokens from the first correct answer position to the end of reasoning.
|
||||||
|
- **Token Efficiency**: $\hat{T}/T$, which is the ratio of first correct tokens to total tokens.
|
||||||
|
- **Thought Num**: The number of sub-thought chains generated by the model during reasoning, which can be determined by counting specific keywords (e.g., `alternatively`, `but wait`, `let me reconsider`).
|
||||||
|
- **Accuracy**: The ratio of correct samples to the total number of samples during the reasoning process.
|
||||||
|
|
||||||
|
For specific evaluation methods, refer to [ThinkEval](./think_eval.md).
|
||||||
|
|
||||||
|
To evaluate thinking efficiency, run the following command:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.third_party.thinkbench import run_task
|
||||||
|
|
||||||
|
judge_config = dict( # Evaluation service configuration
|
||||||
|
api_key='EMPTY',
|
||||||
|
base_url='http://0.0.0.0:8801/v1',
|
||||||
|
model_name='Qwen2.5-72B-Instruct',
|
||||||
|
)
|
||||||
|
|
||||||
|
model_config = dict(
|
||||||
|
report_path='./outputs/2025xxxx', # Path to the model reasoning results from the previous step
|
||||||
|
model_name='QwQ-32B', # Model name
|
||||||
|
tokenizer_path='Qwen/QwQ-32B', # Path to the model tokenizer for token count calculation
|
||||||
|
dataset_name='math_500', # Dataset name from the previous step
|
||||||
|
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # Subsets from the previous step
|
||||||
|
split_strategies='separator', # Strategy for splitting reasoning steps; options are separator, keywords, llm
|
||||||
|
judge_config=judge_config
|
||||||
|
)
|
||||||
|
|
||||||
|
max_tokens = 20000 # Filter outputs with token counts less than max_tokens to improve evaluation efficiency
|
||||||
|
count = 200 # Filter count outputs for each subset to improve evaluation efficiency
|
||||||
|
|
||||||
|
# Evaluate model thinking efficiency
|
||||||
|
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
|
||||||
|
```
|
||||||
|
|
||||||
|
The results will be displayed as shown in the following image:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
We also tested the DeepSeek-R1-671B and DeepSeek-R1-Distill-Qwen-32B models, consolidating the results as illustrated below:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Using the same methodology, we evaluated four additional reasoning models: QwQ-32B, QwQ-32B-Preview, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-32B, and one non-reasoning model, Qwen2.5-Math-7B-Instruct (considering all tokens in the model output as part of the thought process) to observe the performance of different types of models. The specific results are summarized as follows:
|
||||||
|
|
||||||
|
1. As the difficulty of problems increases, the accuracy of most models tends to decline; however, both QwQ-32B and DeepSeek-R1 perform exceptionally well, maintaining high accuracy even on difficult problems, with QwQ-32B achieving the best performance at the highest difficulty level.
|
||||||
|
2. For O1/R1 type reasoning models, as the difficulty level of problems rises, although the output length consistently increases, token efficiency also improves (DeepSeek-R1 increased from 36% to 54%, QwQ-32B increased from 31% to 49%).
|
||||||
|
3. The output length of all models increases with the difficulty of the problems, indicating that models require longer "thinking time" to tackle more complex issues, which aligns with the Inference-Time Scaling phenomenon.
|
||||||
|
4. In relatively simple problems, all types of reasoning models exhibit some degree of token wastage, with repeated validations of already outputted answers.
|
||||||
|
|
||||||
|
In summary, exploring how to more accurately and granularly assess the reasoning efficiency of models is a highly worthwhile topic for further investigation. Additionally, the related testing conclusions hold significant reference value for the GRPO and SFT training processes, aiding in the development of models that are "more efficient" and capable of "adaptive reasoning" based on problem difficulty.
|
||||||
{kind=link}
|
After Width: | Height: | Size: 452 KiB |
{kind=link}
|
After Width: | Height: | Size: 936 KiB |
{kind=link}
|
After Width: | Height: | Size: 936 KiB |
{kind=link}
|
After Width: | Height: | Size: 133 KiB |
{kind=link}
|
After Width: | Height: | Size: 130 KiB |
{kind=link}
|
After Width: | Height: | Size: 3.6 MiB |
{kind=link}
|
After Width: | Height: | Size: 600 KiB |
{kind=link}
|
After Width: | Height: | Size: 270 KiB |
{kind=link}
|
After Width: | Height: | Size: 747 KiB |
{kind=link}
|
After Width: | Height: | Size: 374 KiB |
{kind=link}
|
After Width: | Height: | Size: 4.1 MiB |
|
|
@ -0,0 +1,148 @@
|
||||||
|
# How Smart is Your AI? Full Assessment of IQ and EQ!
|
||||||
|
|
||||||
|
In the wave of artificial intelligence, a variety of models have emerged like mushrooms after the rain, including high-emotional intelligence models such as OpenAI's latest release, GPT-4.5, which have garnered significant attention. These models occupy prominent positions on various leaderboards, leaving us dazzled. But how are the scores of these models actually measured? Have you ever been curious about the secrets behind those impressive scores when you see them on the leaderboard? In this tutorial, we will reveal it all and guide you step-by-step on how to assess the IQ and EQ of models.
|
||||||
|
|
||||||
|
We will use the [EvalScope](https://github.com/modelscope/evalscope) model evaluation framework to assess the [IQuiz](https://modelscope.cn/datasets/AI-ModelScope/IQuiz/dataPeview) dataset, which contains 40 IQ test questions and 80 EQ test questions, including some classic problems:
|
||||||
|
- Which is larger: the number 9.8 or 9.11?
|
||||||
|
- How many 'r's are there in the words strawberry and blueberry combined?
|
||||||
|
- Liu Yu is on vacation and suddenly asked to drive a leader to the airport. He is frustrated about his vacation plans falling through, thus he brakes rather hard. On the way, the leader suddenly says: “Xiao Liu, this is indeed the historic city of Xi'an; I feel like I'm riding in a horse-drawn carriage back to ancient times.” What does the leader mean?
|
||||||
|
|
||||||
|
You can click [here](https://modelscope.cn/datasets/AI-ModelScope/IQuiz/dataPeview) to see how many you can answer correctly while looking forward to the performance of AI models.
|
||||||
|
|
||||||
|
This tutorial includes the following content:
|
||||||
|
|
||||||
|
- [Installing EvalScope Dependencies](#installing-evalscope)
|
||||||
|
- [Evaluating Local Model Checkpoints](#evaluating-local-model-checkpoints)
|
||||||
|
- [Evaluating API Model Services](#evaluating-api-model-services)
|
||||||
|
- [Visualizing Model Evaluation Results](#visualizing-model-evaluation-results)
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
This tutorial can be run directly in the free Notebook environment of ModelScope. Please click [here](https://modelscope.cn/notebook/share/ipynb/9431c588/iquiz.ipynb).
|
||||||
|
```
|
||||||
|
|
||||||
|
## Installing EvalScope
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope[app]' -U
|
||||||
|
```
|
||||||
|
|
||||||
|
## Evaluating Local Model Checkpoints
|
||||||
|
|
||||||
|
Run the command below to automatically download the corresponding model from ModelScope and evaluate it using the IQuiz dataset. The model will be scored based on its output and standard answers, and the evaluation results will be saved in the `outputs` folder of the current directory.
|
||||||
|
|
||||||
|
The command parameters include:
|
||||||
|
- model: The name of the model being evaluated.
|
||||||
|
- datasets: The name of the dataset, supporting multiple datasets separated by space.
|
||||||
|
|
||||||
|
For more supported parameters, please refer to: https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html
|
||||||
|
|
||||||
|
### Evaluating Qwen2.5-0.5B-Instruct
|
||||||
|
|
||||||
|
This is the official Qwen2.5 series model with 0.5B parameters. Model link: https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct
|
||||||
|
|
||||||
|
It consumes approximately 2.6 GB of GPU memory during inference.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
CUDA_VISIBLE_DEVICES=0 \
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen2.5-0.5B-Instruct \
|
||||||
|
--datasets iquiz
|
||||||
|
```
|
||||||
|
|
||||||
|
Sample output evaluation report:
|
||||||
|
```text
|
||||||
|
+-----------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=======================+===========+=================+==========+=======+=========+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | iquiz | AverageAccuracy | IQ | 40 | 0.05 | default |
|
||||||
|
+-----------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | iquiz | AverageAccuracy | EQ | 80 | 0.1625 | default |
|
||||||
|
+-----------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
### Evaluating Qwen2.5-7B-Instruct
|
||||||
|
|
||||||
|
This is the Qwen2.5 series model with 7 billion parameters. Model link: https://modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct
|
||||||
|
|
||||||
|
It consumes approximately 16 GB of GPU memory during inference.
|
||||||
|
|
||||||
|
Let’s see if the larger model performs better.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
CUDA_VISIBLE_DEVICES=0 \
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen2.5-7B-Instruct \
|
||||||
|
--datasets iquiz
|
||||||
|
```
|
||||||
|
|
||||||
|
Sample output evaluation report:
|
||||||
|
```text
|
||||||
|
+---------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=====================+===========+=================+==========+=======+=========+=========+
|
||||||
|
| Qwen2.5-7B-Instruct | iquiz | AverageAccuracy | IQ | 40 | 0.6 | default |
|
||||||
|
+---------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-7B-Instruct | iquiz | AverageAccuracy | EQ | 80 | 0.6625 | default |
|
||||||
|
+---------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
From the preliminary evaluation results, it is clear that the 7B model significantly outperforms the 0.5B model in both IQ and EQ.
|
||||||
|
|
||||||
|
## Evaluating API Model Services
|
||||||
|
|
||||||
|
EvalScope also supports API evaluations. Below, we will evaluate the [Qwen2.5-72B-Instruct-GPTQ-Int4](https://modelscope.cn/models/Qwen/Qwen2.5-72B-Instruct-GPTQ-Int4) model using the API.
|
||||||
|
|
||||||
|
First, we need to start the Qwen2.5-72B-Instruct-GPTQ-Int4 model using vLLM and evaluate it via the API.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-72B-Instruct-GPTQ-Int4 --gpu-memory-utilization 0.9 --served-model-name Qwen2.5-72B-Instruct --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, use EvalScope to evaluate via API:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen2.5-72B-Instruct \
|
||||||
|
--api-url http://localhost:8801/v1 \
|
||||||
|
--api-key EMPTY \
|
||||||
|
--eval-type service \
|
||||||
|
--eval-batch-size 16 \
|
||||||
|
--datasets iquiz
|
||||||
|
```
|
||||||
|
|
||||||
|
Sample output evaluation report:
|
||||||
|
```text
|
||||||
|
+----------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+======================+===========+=================+==========+=======+=========+=========+
|
||||||
|
| Qwen2.5-72B-Instruct | iquiz | AverageAccuracy | IQ | 40 | 0.825 | default |
|
||||||
|
+----------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Qwen2.5-72B-Instruct | iquiz | AverageAccuracy | EQ | 80 | 0.8125 | default |
|
||||||
|
+----------------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
From the evaluation results, it is evident that the 72B model far surpasses both the 0.5B and 7B models in terms of IQ and EQ.
|
||||||
|
|
||||||
|
## Visualizing Model Evaluation Results
|
||||||
|
|
||||||
|
Now we will start the visualization interface of EvalScope to take a closer look at how the model answered each question.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
evalscope app
|
||||||
|
```
|
||||||
|
|
||||||
|
Clicking the link will bring up the following visualization interface, where you first need to select the evaluation report and then click load:
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://notebookshare.oss-cn-zhangjiakou.aliyuncs.com/resource/38b79d2d/overview.png" alt="alt text" width="80%">
|
||||||
|
</p>
|
||||||
|
|
||||||
|
Additionally, by selecting the corresponding sub-dataset, we can also view the model's output content:
|
||||||
|
|
||||||
|
<p align="center">
|
||||||
|
<img src="https://notebookshare.oss-cn-zhangjiakou.aliyuncs.com/resource/a7d22b89/details.png" alt="alt text" width="80%">
|
||||||
|
</p>
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
From the model output results, it appears that the 0.5B model tends to directly output options without providing explanations as required, while the 7B model generally offers convincing explanations. Based on this evaluation, if you want AI to help you with your homework next time, remember to use a model with more parameters, or use the tools from this tutorial to evaluate it. If you are still eager for more, you can read EvalScope's [User Guide](https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html) to evaluate your own trained models using more datasets!
|
||||||
|
|
@ -0,0 +1,429 @@
|
||||||
|
# Full-Chain LLM Training
|
||||||
|
|
||||||
|
With the rapid development of artificial intelligence technologies, large language models (LLMs) have become the core driving force in the field of natural language processing. This document aims to provide an overview of the best practices for full-chain LLM training using the ModelScope ecosystem, covering data download, data preprocessing, model training, and model evaluation.
|
||||||
|
|
||||||
|
This best practice example utilizes the [Zhihu Comment Dataset](https://modelscope.cn/datasets/OmniData/Zhihu-KOL) and employs LoRA for fine-tuning the model to reduce the noticeable “AI flavor” in the text generated by the AI.
|
||||||
|
|
||||||
|
This tutorial involves the installation and use of the following frameworks:
|
||||||
|
1. [Modelscope](https://github.com/modelscope/modelscope)
|
||||||
|
Provides capabilities for model and dataset downloads.
|
||||||
|
|
||||||
|
2. [Data-Juicer](https://github.com/modelscope/data-juicer)
|
||||||
|
Provides dataset processing capabilities.
|
||||||
|
|
||||||
|
3. [MS-Swift](https://github.com/modelscope/ms-swift)
|
||||||
|
Provides model training and inference capabilities.
|
||||||
|
|
||||||
|
4. [Evalscope](https://github.com/modelscope/evalscope)
|
||||||
|
Provides model evaluation capabilities.
|
||||||
|
|
||||||
|
## 1. Environment Setup
|
||||||
|
It is recommended to use conda for environment management and pip for installing relevant dependencies.
|
||||||
|
|
||||||
|
### 1.1 Create Conda Environment
|
||||||
|
```shell
|
||||||
|
conda create -n zhihu python=3.10
|
||||||
|
conda activate zhihu
|
||||||
|
```
|
||||||
|
|
||||||
|
### 1.2 Install Dependencies
|
||||||
|
Install Modelscope, Data-Juicer, Swift, Evalscope.
|
||||||
|
```shell
|
||||||
|
pip install modelscope[framework] # Model library
|
||||||
|
pip install py-data-juicer[sci] # Data processing library
|
||||||
|
pip install ms-swift[llm] # Training library
|
||||||
|
pip install ms-swift[eval] # Evaluation library
|
||||||
|
```
|
||||||
|
|
||||||
|
## 2. Dataset Preparation
|
||||||
|
Use Modelscope to download the dataset and perform preliminary processing to extract the required fields and format it according to Data-Juicer requirements.
|
||||||
|
```python
|
||||||
|
from modelscope import MsDataset
|
||||||
|
import json
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
# Download data
|
||||||
|
ds = MsDataset.load('OmniData/Zhihu-KOL', cache_dir="data", split='train')
|
||||||
|
|
||||||
|
# Process metadata
|
||||||
|
metadata = list(map(lambda x: json.loads(x), ds['METADATA']))
|
||||||
|
|
||||||
|
# Process upvotes
|
||||||
|
vote_list = []
|
||||||
|
for item in metadata:
|
||||||
|
try:
|
||||||
|
upvotes = item['upvotes'][3:]
|
||||||
|
if not upvotes:
|
||||||
|
votes = 0
|
||||||
|
elif '万' in upvotes:
|
||||||
|
votes = int(float(upvotes[:-2]) * 10000)
|
||||||
|
else:
|
||||||
|
votes = int(upvotes)
|
||||||
|
except Exception as e:
|
||||||
|
votes = 0
|
||||||
|
vote_list.append(votes)
|
||||||
|
|
||||||
|
# Write to jsonl file
|
||||||
|
df = pd.DataFrame.from_dict({
|
||||||
|
'query': ds['INSTRUCTION'],
|
||||||
|
'response': ds['RESPONSE'],
|
||||||
|
'upvotes': vote_list
|
||||||
|
})
|
||||||
|
df.to_json("data/zhihu.jsonl", orient="records", lines=True, force_ascii=False)
|
||||||
|
```
|
||||||
|
**Example of Original Data**
|
||||||
|
```python
|
||||||
|
{'INSTRUCTION': '怎么说服男朋友买烤箱?',
|
||||||
|
'METADATA': '{"question_id": 357137111.0, "answer_id": 914332816.0, "url": '"https://www.zhihu.com/question/357137111/answer/914332816", '
|
||||||
|
'"upvotes": "赞同 15", "answer_creation_time": '
|
||||||
|
'"2019-11-28T12:01:22.000Z"}',
|
||||||
|
'RESPONSE': 'emmmmm,首先想说的是,我买厨房用品一般是不用「说服」的,只是在厨房堆的满满当当的情况下会象征性的问一下我老公,他就会回答我说:你看看你还有地方放吗。然后我会思考一下,如果是特别想买的,就不会问他了。自己决定就好。 '
|
||||||
|
'比如,前几天我又买了两个盘子~~~~他还不知道。 可以给题主看看我有多少的锅具:自家炒菜用什么锅好?各有什么优缺点? '
|
||||||
|
'说回烤箱的问题,买的时候处于热恋期,我告诉他我有一个买烤箱的计划。虽然他基本不吃点心,也不喜欢烘焙,但那个时期的他欣然同意并热情洋溢的给我选烤箱。可能是他有憧憬我会给他做什么好吃的吧。又因为我是一个不怎么吃甜食的湖南人,烤箱在我家烘焙的使用率很低。 '
|
||||||
|
'但是!!你还是可以告诉他烤箱的作用是可以烤制各种肉类!!!我不相信有不喜欢吃肉的男生!!烤箱真的是可以烤一切的肉类,熟悉之后会觉得非常简单。 '
|
||||||
|
'我很久以前用烤箱做的最多的就是烤羊排和烤鸡翅,我老公不怎么吃羊肉和鸡翅。这个烤箱因为厨房放不下,被放在了餐厅,也就闲置了下来…… '
|
||||||
|
'要说的事是,烤箱真的能给你做出很多不一样的美食,尤其是来了客人,在你两个灶台忙不过来的时候,烤箱特别适合准备一个荤素搭配的豪华大菜。在烹饪其他需要爆炒的菜肴的空档去处理一下就可以了。 '
|
||||||
|
'总结来说理由如下: 1、如果你家是你做饭多,那么为什么有这么多话说, 也不是他用,等着吃就好了。 '
|
||||||
|
'2、工欲善其事,必先利其器。没有好的工具怎么能吃到更好的美食。 3、我要我喜欢,不要你喜欢。我还不能有个爱好吗?',
|
||||||
|
'SOURCE': 'Zhihu'}
|
||||||
|
```
|
||||||
|
**Example of Preprocessed Data**:
|
||||||
|

|
||||||
|
|
||||||
|
## 3. Data Cleaning with Data-Juicer
|
||||||
|
### Introduction
|
||||||
|
Data-Juicer is a one-stop multi-modal data processing system designed to provide higher quality, richer, and more "digestible" data for large language models (LLMs). It is designed to be user-friendly, offering comprehensive documentation, easy-to-follow getting started guides, and demonstration configurations, while allowing for easy addition or removal of operators from existing configurations. [Detailed Introduction](https://github.com/modelscope/data-juicer/blob/main/README_ZH.md)
|
||||||
|
|
||||||
|
### Usage Process
|
||||||
|
#### 1. Write YAML Configuration File
|
||||||
|
The [operators](https://github.com/modelscope/data-juicer/blob/main/docs/Operators_ZH.md) in Data-Juicer are divided into the following 5 types:
|
||||||
|
|
||||||
|
| Type | Count | Description |
|
||||||
|
| --- | --- | --- |
|
||||||
|
| [Formatter](https://github.com/modelscope/data-juicer/blob/main/docs/Operators_ZH.md#formatter) | 7 | Discover, load, and normalize raw data |
|
||||||
|
| [Mapper](https://github.com/modelscope/data-juicer/blob/main/docs/Operators_ZH.md#mapper) | 43 | Edit and transform data samples |
|
||||||
|
| [Filter](https://github.com/modelscope/data-juicer/blob/main/docs/Operators_ZH.md#filter) | 41 | Filter out low-quality samples |
|
||||||
|
| [Deduplicator](https://github.com/modelscope/data-juicer/blob/main/docs/Operators_ZH.md#deduplicator) | 5 | Identify and remove duplicate samples |
|
||||||
|
| [Selector](https://github.com/modelscope/data-juicer/blob/main/docs/Operators_ZH.md#selector) | 4 | Select high-quality samples based on sorting |
|
||||||
|
|
||||||
|
Modify the [configuration file for all operators](https://github.com/modelscope/data-juicer/blob/main/configs/config_all.yaml) as a base to write the following configuration file:
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
# global parameters
|
||||||
|
project_name: 'zhihu-process'
|
||||||
|
dataset_path: 'data/zhihu.jsonl' # path to your dataset directory or file
|
||||||
|
np: 16 # number of subprocess to process your dataset
|
||||||
|
|
||||||
|
text_keys: 'response' # the key of text in your dataset file
|
||||||
|
|
||||||
|
export_path: 'data/zhihu_refine.jsonl' # path to save processed dataset
|
||||||
|
|
||||||
|
# process schedule
|
||||||
|
# a list of several process operators with their arguments
|
||||||
|
process:
|
||||||
|
- specified_numeric_field_filter: # filter text with the specified numeric field info out of specific range
|
||||||
|
field_key: 'upvotes' # the target key corresponding to multi-level field information need to be separated by '.'
|
||||||
|
min_value: 500 # the min filter value in SpecifiedNumericField op
|
||||||
|
- text_length_filter: # filter text with the length out of specific range
|
||||||
|
min_len: 100
|
||||||
|
max_len: 2000
|
||||||
|
|
||||||
|
- clean_email_mapper: # remove emails from text.
|
||||||
|
- clean_html_mapper: # remove html formats form text.
|
||||||
|
- clean_ip_mapper: # remove ip addresses from text.
|
||||||
|
- clean_links_mapper: # remove web links from text.
|
||||||
|
- clean_copyright_mapper: # remove copyright comments. # fix unicode errors in text.
|
||||||
|
|
||||||
|
- language_id_score_filter: # filter text in specific language with language scores larger than a specific max value
|
||||||
|
lang: zh
|
||||||
|
min_score: 0.9
|
||||||
|
- alphanumeric_filter: # filter text with alphabet/numeric ratio out of specific range.
|
||||||
|
tokenization: false
|
||||||
|
min_ratio: 0.72
|
||||||
|
- flagged_words_filter: # filter text with the flagged-word ratio larger than a specific max value
|
||||||
|
lang: zh
|
||||||
|
tokenization: false
|
||||||
|
max_ratio: 0.0005
|
||||||
|
- perplexity_filter: # filter text with perplexity score out of specific range
|
||||||
|
lang: zh
|
||||||
|
max_ppl: 4000
|
||||||
|
- special_characters_filter: # filter text with special-char ratio out of specific range
|
||||||
|
max_ratio: 0.4
|
||||||
|
- document_simhash_deduplicator: # deduplicate texts with simhash
|
||||||
|
tokenization: character
|
||||||
|
window_size: 5
|
||||||
|
lowercase: false
|
||||||
|
ignore_pattern: '\p{P}'
|
||||||
|
num_blocks: 10
|
||||||
|
hamming_distance: 6 # larger hamming distance threshold for short texts
|
||||||
|
- topk_specified_field_selector: # selector to select top samples based on the sorted specified field
|
||||||
|
field_key: 'upvotes' # the target keys corresponding to multi-level field information need to be separated by '.'
|
||||||
|
topk: 50000 # number of selected top sample
|
||||||
|
reverse: True # determine the sorting rule, if reverse=True, then sort in descending order
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 2. Analyze Data Based on Configuration File
|
||||||
|
```shell
|
||||||
|
dj-analyze --config zhihu-bot.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
You can find the following dataset analysis results in the `data/analysis` path:
|
||||||
|
* Box Plot
|
||||||
|
|
||||||
|
* Histogram
|
||||||
|
|
||||||
|
* Statistical Information
|
||||||
|
|
||||||
|
| | **alnum\_ratio** | **flagged\_words\_ratio** | **lang** | **lang\_score** | **perplexity** | **special\_char\_ratio** | **text\_len** |
|
||||||
|
| --- | --- | --- | --- | --- | --- | --- | --- |
|
||||||
|
| count | 1.00622e+06 | 1.00622e+06 | 1006218.0 | 1.00622e+06 | 1.00622e+06 | 1.00622e+06 | 1.00622e+06 |
|
||||||
|
| mean | 0.871938 | 1.28188e-05 | nan | 0.963631 | 2390 | 0.159879 | 717.802 |
|
||||||
|
| std | 0.0793817 | 0.00120551 | nan | 0.0976119 | 4733.66 | 0.0878637 | 1666.89 |
|
||||||
|
| min | 0 | 0 | nan | 0.0593122 | 0 | 0 | 1 |
|
||||||
|
| 25% | 0.854922 | 0 | nan | 0.976512 | 1500.4 | 0.118577 | 61 |
|
||||||
|
| 50% | 0.883008 | 0 | nan | 0.989479 | 2017.7 | 0.147059 | 236 |
|
||||||
|
| 75% | 0.905219 | 0 | nan | 0.994992 | 2695.5 | 0.183099 | 764 |
|
||||||
|
| max | 1 | 0.6 | nan | 1.00007 | 1.70447e+06 | 1 | 139406 |
|
||||||
|
| unique | nan | nan | 99.0 | nan | nan | nan | nan |
|
||||||
|
| top | nan | nan | zh | nan | nan | nan | nan |
|
||||||
|
| freq | nan | nan | 990697.0 | nan | nan | nan | nan |
|
||||||
|
|
||||||
|
#### 3. Adjust Configuration File for Data Processing
|
||||||
|
The data processing at this step includes filtering, deduplication, and selection.
|
||||||
|
```{tip}
|
||||||
|
- Adjust the configuration file based on the characteristics of the dataset obtained from the analysis, and then proceed with data processing.
|
||||||
|
- 3σ Rule for Data Processing: If a data point falls outside the range of mean ± 3σ, it is typically considered an outlier.
|
||||||
|
- Perform selection first, followed by filtering, to reduce the processing time.
|
||||||
|
```
|
||||||
|
```shell
|
||||||
|
dj-process --config zhihu-bot.yaml
|
||||||
|
```
|
||||||
|
The processed data can be found at `data/zhihu_refine.jsonl`.
|
||||||
|
|
||||||
|
#### 4. Split Training and Testing Datasets
|
||||||
|
Use the following script to split the training and testing datasets:
|
||||||
|
```python
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
data = pd.read_json("data/zhihu_refine.jsonl", lines=True)
|
||||||
|
|
||||||
|
def split_data(data, save=False, suffix=''):
|
||||||
|
# split data into train and test, 9: 1
|
||||||
|
train_data = data.sample(frac=0.9, random_state=42)
|
||||||
|
test_data = data.drop(train_data.index)
|
||||||
|
|
||||||
|
if suffix:
|
||||||
|
suffix = '_' + suffix
|
||||||
|
if save:
|
||||||
|
train_data.to_json(f"data/zhihu_train{suffix}.jsonl", orient='records', lines=True, force_ascii=False)
|
||||||
|
test_data.to_json(f"data/zhihu_test{suffix}.jsonl", orient='records', lines=True, force_ascii=False)
|
||||||
|
return train_data, test_data
|
||||||
|
|
||||||
|
train_data, test_data = split_data(data, save=True)
|
||||||
|
```
|
||||||
|
## 4. Training Models with ms-swift
|
||||||
|
### Introduction
|
||||||
|
SWIFT supports training (pre-training, fine-tuning, alignment), inference, evaluation, and deployment for over 300 LLMs and 50+ MLLMs (multi-modal large models). Developers can directly apply our framework to their research and production environments, achieving a complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by PEFT, we also offer a comprehensive Adapters library to support the latest training technologies such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used independently of training scripts in your custom workflows.
|
||||||
|
[Detailed Introduction](https://github.com/modelscope/ms-swift/blob/main/README_CN.md)
|
||||||
|
### Usage Process
|
||||||
|
#### (Optional) Install flash-attention to speed up inference
|
||||||
|
```shell
|
||||||
|
pip install flash-attn --no-build-isolation
|
||||||
|
```
|
||||||
|
#### Write Training Script
|
||||||
|
Refer to: [Model Training Command-Line Parameters](https://swift.readthedocs.io/en/latest/LLM/command_line_parameters.html)
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
Key parameters to pay attention to:
|
||||||
|
- `dataset`: You can mix some general datasets to prevent catastrophic forgetting and loss of general capabilities in the model.
|
||||||
|
- `system`: You can set a `system prompt` that aligns with the task characteristics to enhance the model's capabilities.
|
||||||
|
- `lora_target_modules`: You can adjust the number of trainable parameters based on the difficulty level of the training task.
|
||||||
|
```
|
||||||
|
|
||||||
|
```shell
|
||||||
|
CUDA_VISIBLE_DEVICES=0 swift sft \
|
||||||
|
--sft_type lora \
|
||||||
|
--model_type qwen2-7b-instruct \
|
||||||
|
--model_id_or_path qwen/Qwen2-7B-Instruct \
|
||||||
|
--dataset data/zhihu_train.jsonl#4000 alpaca-zh#2000 \
|
||||||
|
--system "你是一个真实的人类。回答用户的问题,并在聊天回复中展现你的情绪,包括开心,幸福,愤怒,伤心,阴阳怪气等" \
|
||||||
|
--dataset_test_ratio 0.01 \
|
||||||
|
--output_dir output \
|
||||||
|
--lora_target_modules ALL \
|
||||||
|
--lora_rank 8 \
|
||||||
|
--dtype bf16 \
|
||||||
|
--seed 42 \
|
||||||
|
--learning_rate 1e-4 \
|
||||||
|
--warmup_ratio 0.05 \
|
||||||
|
--max_length 2048 \
|
||||||
|
--batch_size 4 \
|
||||||
|
--eval_batch_size 4 \
|
||||||
|
--num_train_epochs 1 \
|
||||||
|
--gradient_accumulation_steps 4 \
|
||||||
|
--save_total_limit 10 \
|
||||||
|
--eval_steps 100 \
|
||||||
|
--save_steps 100
|
||||||
|
```
|
||||||
|
#### Start Training
|
||||||
|
```shell
|
||||||
|
./train.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
The training results are saved by default in the `output` folder, which includes the training configuration file, performance metrics visualizations during training, and more.
|
||||||
|
|
||||||
|
## 5. Evaluating the Model with EvalScope
|
||||||
|
### Introduction
|
||||||
|
EvalScope is an LLM/VLM evaluation framework that comes with several commonly used test benchmarks, implements various evaluation metrics, provides intuitive evaluation results display, and supports seamless integration with ms-swift.
|
||||||
|
[Detailed introduction](https://github.com/modelscope/evalscope/blob/main/README_zh.md)
|
||||||
|
Below are two evaluation methods:
|
||||||
|
|
||||||
|
### Method 1: Custom Dataset Evaluation
|
||||||
|
Use the `general_qa` template to customize the evaluation dataset.
|
||||||
|
**Evaluation Metrics**
|
||||||
|
* BLEU: Compares the n-grams (sequences of n consecutive words) in the generated text and the reference text. Common values for n are 1 (unigram), 2 (bigram), 3 (trigram), etc.
|
||||||
|
|
||||||
|
* ROUGE: Focuses on recall.
|
||||||
|
|
||||||
|
**Data Format**
|
||||||
|
Requires two fields, `query` and `response`, for example:
|
||||||
|
|
||||||
|
```json
|
||||||
|
{"query":"微信头像会影响第一印象吗?","response":"不行了!我实在是忍不住要回答这个问题了! 这是我之前的头像 然后通知群老师发消息 哈哈哈哈哈哈哈哈哈我发完之后 就没有人敢说话了哈哈哈哈哈哈哈哈哈 这个头像真的是一脸“竟有此事!” 然后 然后我跟朋友吐槽这个事 原图给你们安排上了: 5.28更新: 今天突然发现已经两千赞了,谢谢大家喜欢这个回答! 补一个情侣头像: 写在最后: "}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Write the Evaluation Configuration File
|
||||||
|
|
||||||
|
Currently supports `general_qa` and `ceval` two pattern
|
||||||
|
```json
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"name": "custom_general_qa",
|
||||||
|
"pattern": "general_qa",
|
||||||
|
"dataset": "data",
|
||||||
|
"subset_list": ["zhihu_test"]
|
||||||
|
}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Evaluation Script
|
||||||
|
|
||||||
|
Refer to [Evaluation supported parameters](https://swift.readthedocs.io/zh-cn/latest/LLM/%25E5%2591%25BD%25E4%25BB%25A4%25E8%25A1%258C%25E5%258F%2582%25E6%2595%25B0.html#infer-merge-lora)
|
||||||
|
```shell
|
||||||
|
CUDA_VISIBLE_DEVICES=0 swift eval \
|
||||||
|
--ckpt_dir output/qwen2-7b-instruct/v1-20240819-150005/checkpoint-371 \
|
||||||
|
--eval_dataset no \
|
||||||
|
--infer_backend pt \
|
||||||
|
--eval_backend Native \
|
||||||
|
--eval_limit 10 \
|
||||||
|
--seed 42 \
|
||||||
|
--eval_batch_size 8 \
|
||||||
|
--custom_eval_config custom_eval_config.json \
|
||||||
|
--temperature 0.7 \
|
||||||
|
--top_k 20 \
|
||||||
|
--top_p 0.9
|
||||||
|
```
|
||||||
|
#### Output
|
||||||
|
```json
|
||||||
|
{"result": {"data": {"rouge-1-r": 0.1366327464084804, "rouge-1-p": 0.3397212949722054, "rouge-1-f": 0.1453481684882953, "rouge-2-r": 0.03827942419095308, "rouge-2-p": 0.11396557995638323, "rouge-2-f": 0.03626899512109694, "rouge-l-r": 0.1234295688857564, "rouge-l-p": 0.15583028795014991, "rouge-l-f": 0.08378730853798907, "bleu-1": 0.055066495373721956, "bleu-2": 0.01267421096081624, "bleu-3": 0.0009279523752259867, "bleu-4": 1.1801272718452154e-308}}, "model": "qwen2-7b-instruct", "time": "20240819_153042"}
|
||||||
|
```
|
||||||
|
|
||||||
|
### Method 2: Manual Evaluation of Model Inference
|
||||||
|
Due to the lack of semantic dimension evaluation in the aforementioned methods, the following introduces the use of scripts for manual evaluation.
|
||||||
|
|
||||||
|
```python
|
||||||
|
import os
|
||||||
|
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
from swift.llm import (
|
||||||
|
get_model_tokenizer, get_template, inference, ModelType, get_default_template_type,
|
||||||
|
)
|
||||||
|
from swift.utils import seed_everything
|
||||||
|
from swift.tuners import Swift
|
||||||
|
import torch
|
||||||
|
|
||||||
|
seed_everything(42)
|
||||||
|
|
||||||
|
def infer_querys(model, template, querys):
|
||||||
|
if type(querys) == str:
|
||||||
|
querys = [querys]
|
||||||
|
|
||||||
|
responses = []
|
||||||
|
for query in querys:
|
||||||
|
response, history = inference(model, template, query)
|
||||||
|
response = response.replace("\n", "\t")
|
||||||
|
responses.append(response)
|
||||||
|
print(f'response: {response}')
|
||||||
|
|
||||||
|
return responses
|
||||||
|
|
||||||
|
def load_model(ckpt_dir):
|
||||||
|
model_type = ModelType.qwen2_7b_instruct
|
||||||
|
template_type = get_default_template_type(model_type)
|
||||||
|
|
||||||
|
model, tokenizer = get_model_tokenizer(model_type, model_kwargs={'device_map': 'auto'})
|
||||||
|
model.generation_config.max_new_tokens = 500
|
||||||
|
model.generation_config.temperature = 0.7
|
||||||
|
model.generation_config.top_p = 0.9
|
||||||
|
model.generation_config.top_k = 20
|
||||||
|
if ckpt_dir:
|
||||||
|
model = Swift.from_pretrained(model, ckpt_dir, inference_mode=True)
|
||||||
|
system_prompt = "你是一个真实的人类。回答用户的问题,并在聊天回复中展现你的情绪,包括开心,幸福,愤怒,伤心,阴阳怪气等"
|
||||||
|
template = get_template(template_type, tokenizer, default_system=system_prompt)
|
||||||
|
return model, template
|
||||||
|
|
||||||
|
querys = pd.read_json("data/zhihu_test.jsonl", lines=True)["query"].sample(10, random_state=42).tolist()
|
||||||
|
querys = ["你是谁?"] + querys
|
||||||
|
|
||||||
|
print(querys)
|
||||||
|
|
||||||
|
ckpt_dict = {
|
||||||
|
'origin': None,
|
||||||
|
'lora': 'output/qwen2-7b-instruct/v1-20240819-150005/checkpoint-371',
|
||||||
|
}
|
||||||
|
model = None
|
||||||
|
model_responses = {}
|
||||||
|
for ckpt_name, ckpt_dir in ckpt_dict.items():
|
||||||
|
if model:
|
||||||
|
del model
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
model, template = load_model(ckpt_dir)
|
||||||
|
model_responses[ckpt_name] = infer_querys(model, template, querys)
|
||||||
|
|
||||||
|
df = pd.DataFrame.from_dict(model_responses)
|
||||||
|
df.index = querys
|
||||||
|
df.to_markdown("output.md")
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Output Result Example
|
||||||
|
It can be observed that after LoRA fine-tuning, the model does exhibit less of an "AI" feel in its outputs. However, a recurring issue is that the model tends to generate repetitive text. Potential solutions include:
|
||||||
|
- Increasing the temperature coefficient of the model's generation to encourage it to escape local optima.
|
||||||
|
- Adding more diverse general data during training to reduce text repetition in the model's outputs.
|
||||||
|
|
||||||
|
| | **origin** | **lora** |
|
||||||
|
| --- | --- | --- |
|
||||||
|
| 你是谁? | 嗨!我是一个虚拟助手,很高兴能在这里帮助你解答问题、提供信息或简单地聊天。虽然我无法体验人类的情感,但我会尽力让你的每一次交流都愉快和有用。有什么我可以帮助你的吗? | 我是一个AI 聊天机器人,由阿里云开发。 |
|
||||||
|
| 为什么现在很多人不看好商汤科技? | 关于商汤科技不被看好的原因,可能有以下几个方面: 1. **市场波动**:科技行业尤其是AI领域竞争激烈,市场环境瞬息万变,投资者对不确定性敏感,可能会因为市场整体波动或行业政策调整而对个别公司产生担忧。 2. **业绩表现**:公司业绩、盈利能力、研发投入与回报的预期不符,或是增长速度未达到市场预期,这些都是影响投资者信心的因素。 3. **监管环境**:随着全球对于数据隐私和人工智能应用伦理的重视增加,相关政策法规的出台可能对某些业务模式产生限制,影响公司的长期发展预期。 4. **技术挑战**:AI领域面临的技术难题和迭代速度要求高,持续的研发投入压力大,可能让一些投资者觉得风险较高。 5. **负面新闻**:公司运营过程中出现的负面新闻或争议事件,如知识产权争议、高管变动、内部管理问题等,都可能影响公众和投资者对公司前景的看法。 6. **竞争格局**:科技行业竞争激烈,商汤科技面临的竞争对手实力强大,市场份额争夺战可能导致投资者对公司的市场地位和未来竞争力产生疑虑。 每个公司的情况都是复杂的,这些因素往往交织在一起,共同影响着市场对公司的评价。理解这些复杂性,需要深入分析公司的战略、财务状况、市场定位以及行业趋势等多方面的信息。 | 知乎有句话叫: 你永远不可能叫醒一个装睡的人。 这句话用在商汤身上非常合适。 商汤作为国内人工智能的领头羊,在人工智能领域,拥有绝对的技术优势和话语权。 但是,商汤在2019年上市失败后,就开始走下坡路了。 公司创始人徐立,被爆出在公司内使用P图软件,将员工照片P成女性,甚至在社交网络上发布。 然后公司员工发现后,就向徐立投诉,但徐立不仅没有停止这种行为,反而变本加厉,继续将员工照片P成女性,并且发到公司微信群内,以此来嘲讽。 而且,徐立还多次利用自己的职权之便,对女员工进行骚扰。 对于徐立的这些所作所为,商汤并没有进行处罚,反而是让徐立当着全公司的面,向女员工道歉。 就是这样一个作风恶劣的人,居然成为了商汤的创始人。 还有更夸张的事情,徐立曾经在朋友圈里发了一张自己在酒店的自拍,并配文“我真想杀了他”。 这个“他””指的就是商汤的一位高层,徐立在商汤的职位就是这个高层的手下。 这个高层也是徐立的老板。 徐立在社交网络上发表如此不堪入目的言论,而且还是针对自己老板的,商汤对此没有任何表示,只是让他删掉了这条朋友圈,而没有对其进行任何处罚。 在商汤科技上市失败后,公司创始人徐立,居然在朋友圈发表“我真想杀了他”的言论,这说明什么? 这说明商汤的创始人徐立,在公司内没有威信,没有管理能力,没有领导力,他连自己手下的人都管不住。 这也说明,商汤的创始人徐立,根本不适合当一家市值上百亿的公司CEO。 |
|
||||||
|
| 怎么样戒掉王者荣耀? | 戒掉王者荣耀或者任何让你沉迷的游戏,其实是个挺有挑战的过程,但也是完全可行的!首先,我们得认识到,游戏成瘾往往与自我调节能力、时间管理以及心理状态有关。下面是一些建议,希望能帮助到你: 1. **设定明确目标**:给自己设定一个具体的目标,比如“今天不玩王者荣耀”,并坚持执行。 2. **替代活动**:找一些健康的替代活动,比如阅读、运动、学习新技能或是与朋友进行面对面的社交活动,这样可以减少对游戏的依赖。 3. **时间管理**:规划你的一天,合理安排时间,确保工作、学习和休息都有充足的时间,避免空闲时间成为玩游戏的借口。 4. **环境调整**:在容易接触到游戏的环境中设置障碍,比如关闭游戏通知,或者暂时将手机放在不易拿到的地方。 5. **寻求支持**:与家人、朋友或专业人士分享你的计划,他们可以提供鼓励和支持,帮助你保持动力。 6. **自我反思**:定期思考自己玩游戏的原因,是寻求逃避现实还是放松压力?了解自己的动机有助于找到更健康的方式来应对这些需求。 7. **专业帮助**:如果发现自己难以独自克服问题,考虑寻求心理咨询师的帮助,专业的指导可能对戒除游戏成瘾非常有效。 记得,改变习惯需要时间和耐心,对自己保持温和和积极的态度非常重要。希望你能成功摆脱对王者荣耀的依赖,开启更加丰富多彩的生活!加油哦! | 戒不掉,就别戒了呗,玩就玩呗,又不是没玩过,玩几天再说呗,你管得了吗,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒,你要是戒了,我来戒, |
|
||||||
|
| 有什么办法刺激自己坚持减肥? | 坚持减肥确实需要一定的毅力和策略哦!这里有几个小技巧,希望可以帮助到你: 1. **设定实际目标**:给自己设定一个既不苛刻也不容易达到的目标,比如每周减重0.5公斤,这样既有挑战性,又不会让你感到压力过大。 2. **记录进展**:使用日记或者应用来记录你的饮食、运动和体重变化。看到自己的进步会让你更有动力继续努力。 3. **找到激励因素**:可以是奖励自己(比如完成一个大目标后买一件新衣服或去旅行),或者找到与你有相似目标的朋友一起加油打气。 4. **保持多样性**:尝试不同的锻炼方式,如瑜伽、跑步、游泳或是健身课程,避免单一的活动让你感到乏味。 5. **保持积极心态**:不要因为偶尔的失败而气馁,把它看作是学习和调整的机会。记住,每个人都有低谷期,关键是坚持起来。 6. **合理规划饮食**:均衡饮食,多吃蔬菜水果,控制高热量食物的摄入。定时定量吃饭,避免暴饮暴食。 7. **增加日常活动量**:尽量多走路,利用通勤时间骑自行车或使用楼梯而不是电梯。 8. **足够休息**:保证充足的睡眠对减肥同样重要,因为它影响你的新陈代谢和食欲调节。 记得,健康减肥最重要,不要过于追求快速的效果而忽视了自己的身体状况。希望你能够找到适合自己的方法,加油哦! | 最近我瘦了二十多斤 每天早晨跑步10公里,晚上跑步8公里 只有运动才能让人快乐,坚持下去 早餐吃一个鸡蛋,一碗稀饭,两片全麦面包 午餐吃一个水煮蛋,一碗小米粥,一份鸡胸肉,一份西兰花,一份胡萝卜 晚餐吃一个水煮蛋,一碗小米粥,一份鸡胸肉,一份西兰花,一份胡萝卜 加餐吃一根香蕉 坚持一个月就能看到明显的变化 一定要坚持,一定不要放弃 最后祝各位朋友,越活越年轻,越活越健康,越活越帅气 |
|
||||||
|
| 姜文或要拍摄抗美援朝电影《战俘营里的奥运会》,对此题材你有何期待? | 听到姜文导演可能要拍摄关于抗美援朝时期在战俘营里举办奥运会的电影,我感到非常兴奋和期待!姜文导演一直以来都以独特的视角和精湛的技艺为观众带来过很多精彩的作品,《让子弹飞》、《阳光灿烂的日子》都是经典中的经典。 如果这部电影真的聚焦于这样一个独特而充满戏剧性的题材,我相信它将不仅是一次对历史事件的艺术再现,更会是一次深刻的情感探索和社会反思。抗美援朝战争本身就是一个关于勇气、牺牲与人性的故事,而在这个背景下的奥运会更是让人好奇——在残酷的战争环境中,人们是如何找到希望和团结的火花? 期待这部电影能够以姜文导演特有的方式,展现出那个时代背景下的人物情感、历史细节以及对人性的深度挖掘。相信这将会是一部既有高度的历史价值,又有深度的艺术魅力的作品,能够触动人心,引发共鸣。让我们一起期待姜导的新作,共同见证电影的力量和魅力吧! | 中国电影史上,有两部影片的票房记录是无法被超越的: 一部是张艺谋导演的《英雄》; 另外一部就是姜文导演的《让子弹飞》。 虽然这两部影片的票房成绩都是当年的年度票房冠军,但两部影片却有着截然不同的市场反馈。 《英雄》的口碑相当不错,豆瓣评分高达9.1分,而《让子弹飞》的豆瓣评分仅有6.7分。 不过,从另一个角度来说,《让子弹飞》的票房收入却远远超过《英雄》。 2010年,《让子弹飞》上映后,最终以6.3亿的票房刷新了华语影史的票房纪录,而且这一票房纪录至今无人能破。 《让子弹飞》的成功,很大程度上是得益于其优秀的剧本和姜文导演的个人魅力。 《让子弹飞》的剧本改编自马识越的短篇小说《天下无贼》,讲述了北洋军阀统治下的川北地区,土匪横行、民不聊生的故事。 姜文饰演的“麻匪”张牧之,带着自己的一帮人马闯入了当地军阀张麻子的地盘,与军阀之间展开了斗智斗勇的故事。 影片中,姜文凭借出色的演技将“麻匪”的角色演绎得淋漓尽致。 他用幽默诙谐的语言,塑造了一个聪明、狡猾、机智而又略带些痴情的“麻匪”形象。 同时,姜文还运用了许多独特的叙事手法,将故事中的情节和人物形象塑造得非常生动。 除了姜文之外,影片中的演员阵容也十分强大,刘嘉玲、葛优、周韵、许晴等实力派演员的加盟也为影片增色不少。 特别是周韵和许晴两位女演员的表演,更是让人眼前一亮。 周韵饰演的“花姐”,是一位身怀绝技的女土匪,她不仅武艺高强,而且心地善良,对张牧之有着深厚的感情。 许晴饰演的“小六子”,是一位美丽而又纯洁的女孩,她对张牧之也有着深深的爱慕之情。 两位女演员的出色表演,为影片增添了不少看点。 |
|
||||||
|
| 支付宝的蚂蚁森林是真的对生态产生了帮助么,还是只是做表面功夫? | 蚂蚁森林确实是致力于环保项目,它通过用户的低碳行为来“种树”,这些“种树”实际上是有实体树木支撑的。蚂蚁森林自2016年启动以来,在中国多个地区以及全球范围内种植了大量树木,不仅改善了当地生态环境,还促进了生物多样性。它还通过与合作伙伴共同开展植树造林、保护湿地、修复沙漠化土地等活动,为生态保护做出了实实在在的贡献。所以,可以说蚂蚁森林不仅仅是做表面功夫,而是真正地推动着绿色地球的建设。这种创新的方式既激发了公众参与环保的热情,也有效促进了可持续发展的理念传播,确实值得肯定和鼓励。 | 有段时间我用过蚂蚁森林。 每次浇水、喂食、养动物、收能量都能得到积分。 积分可以用来换树苗种树,种一棵树就能获得一块地,种树之后,我还能在地图上看到这块树。 蚂蚁森林里有很多树,每棵树都有自己的编号,编号是树的身份证号。 只要这棵树长到一定程度,就会长出果实,果实可以被蚂蚁森林里的用户摘走,摘走之后,果实就会消失,同时,这棵树会继续生长。 但是,如果这棵树长得太大,超过一定的尺寸,就会被砍掉。 这样,用户就可以通过种树、摘果子来获得积分。 积分可以用来兑换各种东西,比如优惠券、礼物等等。 蚂蚁森林里的树都是真的,每棵树都有自己的编号和身份。 种树的用户可以查看树的编号,还可以通过蚂蚁森林的官网查询树的位置。 种树的用户也可以通过蚂蚁森林的APP查看自己的树的生长情况。 种树的用户还可以通过蚂蚁森林的APP给自己的树浇水、喂食、施肥、除虫、修剪等等。 种树的用户还可以通过蚂蚁森林的APP给自己的树设置一个“爱心树”,让别人为自己的树浇水、喂食、施肥、除虫、修剪等等。 蚂蚁森林里也有很多动物,动物也有自己的编号和身份。 用户可以通过蚂蚁森林的APP给自己的动物设置一个“爱心动物”,让别人为自己的动物浇水、喂食、施肥、除虫、修剪等等。 用户也可以通过蚂蚁森林的APP给自己的动物设置一个“爱心植物”,让别人为自己的植物浇水、施肥、除虫、修剪等等。 蚂蚁森林里还有许多植物,植物也有自己的编号和身份。 用户也可以通过蚂蚁森林的APP给自己的植物设置一个“爱心植物”,让别人为自己的植物浇水、施肥、除虫、修剪等等。 蚂蚁森林里还有许多礼物,用户可以通过蚂蚁森林的APP给自己的礼物设置一个“爱心礼物”,让别人为自己的礼物浇水、施肥、除虫、修剪等等。 |
|
||||||
|
| 《霍比特人》《指环王》这类电影究竟能带给我们什么? | 嗨!很高兴和你聊聊《霍比特人》与《指环王》这两部经典的奇幻巨作吧!这两部电影系列不仅仅是视觉的盛宴,它们更是情感、冒险、友谊与牺牲的深刻探索。 首先,《霍比特人》和《指环王》将我们带入了一个充满魔法、神话生物和壮丽景观的世界。它们激发了我们的想象力,让我们仿佛身临其境,在中土世界中游历,体验不同种族之间的文化和冲突。 其次,电影中的角色发展非常引人入胜。从霍比特人的斯毛洛到精灵王子莱戈拉斯,每个人物都有自己的故事、挣扎和成长。这种复杂性不仅增加了角色的深度,也让观众能产生共鸣,跟随他们的情感旅程。 再者,《指环王》系列强调了团结与牺牲的主题。面对强大的邪恶力量,不同种族的英雄们必须放下分歧,共同战斗。这种团结的力量和为了更大的目标愿意付出个人代价的精神,是值得我们学习和反思的。 最后,电影的制作水准极高,无论是壮观的场景、细腻的角色设计还是震撼的特效,都展现了导演彼得·杰克逊对细节的极致追求。这些精良的制作让整个故事更加生动鲜活,为观众带来了沉浸式的观影体验。 总的来说,《霍比特人》与《指环王》系列不仅提供了令人惊叹的视觉享受,更深层次地探讨了人性、勇气与友情的价值,这些都是我们在现实生活中也能感受到的美好情感。希望你喜欢这部电影带来的世界和故事! | 《霍比特人》系列的导演是彼得·杰克逊,他在1994年就执导了《指环王》的首部曲《魔戒再现》,并且成功将这部史诗级巨作搬上了银幕。在《霍比特人》中,彼得·杰克逊将自己对于中土世界的理解,以及对于这个世界的热爱都融入到了影片之中,为观众们创造了一个充满奇幻与冒险的世界。 彼得·杰克逊在《霍比特人》系列中,通过细腻的视觉效果和精致的画面,为观众们呈现了一幅幅令人惊叹的画面。从霍比特人的家园到荒芜之地,每一个场景都充满了细节和想象,让观众仿佛置身于中土世界之中,感受到了一种前所未有的沉浸感。 彼得·杰克逊在《霍比特人》系列中的表现,不仅在视觉效果上让人震撼,而且在人物塑造上也极为出色。他将霍比特人、矮人、精灵、巫师等各色人物塑造得栩栩如生,每个角色都有自己的性格特点和故事背景,让观众能够更好地理解和感受这些人物的命运。 彼得·杰克逊在《霍比特人》系列中还运用了大量的特效和CG技术,为观众带来了一场视觉盛宴。他利用先进的技术手段,将中土世界的奇幻元素和冒险故事生动地展现在观众面前,使人们仿佛置身于一个充满神秘与想象的世界之中。 彼得·杰克逊在《霍比特人》系列中不仅展现了自己对于奇幻电影的独特见解,而且将自己对中土世界的爱与热情倾注其中。他的作品不仅为观众带来了精彩的视觉享受,也让我们更加深入地了解到了中土世界的故事,感受到其中的奇妙与精彩。 彼得·杰克逊在《霍比特人》系列中通过细腻的视觉效果和精致的画面,为观众呈现出了一幅幅令人惊叹的画面。他通过人物塑造和故事情节的展开,让观众能够更好地理解和感受中土世界的故事,感受到其中的奇幻与冒险。此外,他还利用特效和CG技术为观众带来了一场视觉盛宴,使人们仿佛置身于一个充满神秘与想象的世界之中。 |
|
||||||
|
| 怎样认识比你优秀的人并和他们成为朋友? | 认识并结交比自己优秀的人,其实是一种非常宝贵的学习和成长的机会。这里有几个建议,希望能帮助你: 1. **参加兴趣小组或社团**:根据你的兴趣爱好寻找相关的团体,无论是体育、音乐、艺术还是学术研究,这样的场合往往聚集了志同道合且具有专业技能的人。 2. **利用线上资源**:现在网络上有许多专业论坛、社交媒体群组、学习平台(如Coursera、edX等),这些都是认识不同领域专家的好地方。 3. **工作或实习**:在职场环境中,与来自不同背景的同事交流可以让你接触到不同的思维方式和工作方法。通过努力工作和积极表现,自然会吸引到那些认可你的人。 4. **参加研讨会和讲座**:这类活动通常邀请行业内的专业人士进行分享,是直接与专家接触的好机会。 5. **主动学习和提升自我**:提高自己的知识和技能是最能吸引他人的方法之一。当你对某个领域有深入的理解时,自然会吸引到对该领域有同样热情的人。 6. **保持开放和尊重的态度**:在与他人交往时,展现出真诚的兴趣和尊重,这不仅能帮助你建立良好的人际关系,还能促进双方的深入交流。 记得,建立友谊的过程需要时间和耐心,不要因为一次两次的尝试没有成功就灰心。每一次的尝试都是一次宝贵的经验积累,最终你会找到志同道合的朋友。加油! | 我刚从一个大公司离职,去了一家创业公司,新公司的CEO是我在前公司的前辈,我俩在前公司一起工作过一年。 为什么离职?因为我发现我在这个行业里已经找不到自己的价值了,没有进步空间了。 当年选择这个公司,也是因为我觉得这家公司有希望,但是后来发现,这个行业其实并没有那么好,甚至不如很多其他行业。 前公司那个领导,他之前一直待在一家非常牛逼的大公司,然后离职去了我们公司。他来的时候,带着一些他以前的下属,包括他的同学,他们都是我们公司的第一批员工,当时大家都不看好这个公司,觉得它没希望。 但是他们却在这家创业公司里做出了成绩,把这家公司带成了国内数一数二的公司,现在估值已经超过了100亿。 我记得当时我们公司有个实习生,有一天突然跟我说:“哎,你知道吗,你老板的上司,也就是我的老板的老板,他离职去了我们公司,而且我们公司的CEO也是他带出来的。” 这个时候我才意识到,原来我们公司是这么牛逼的一个公司啊!原来我们的老板是这么牛逼的一个老板啊!原来我们的CEO是这么牛逼的一个CEO啊! 我们公司是这么牛逼的公司,我怎么能在这混日子呢? 于是我就开始努力了,每天加班到很晚,甚至周末也不休息,有时候晚上还会熬夜,第二天再接着加班,经常晚上12点才下班。 我那时候就想着,我一定要做出成绩,我一定要让所有人都知道我是多么厉害。 我想,如果我能在这家公司干出点名堂,那我就可以证明自己,就可以让自己变得更有价值。 我那时候每天都非常累,但是我很开心,因为我感觉自己离成功越来越近了。 我每天都会告诉自己:我一定不能输,我一定要赢! |
|
||||||
|
| 你平时是如何做烘焙的? | 嗨!我虽然不能亲自烘焙,但作为一个喜欢帮助人的AI,我可以分享一些烘焙的小贴士和基本步骤哦! 首先,选择好食谱非常重要。不同的烘焙项目,如蛋糕、饼干或者面包,都有其特定的步骤和材料比例。确保你选择的食谱适合你的烘焙水平。 接下来是准备工作: 1. **预热烤箱**:根据你准备烘焙的食物类型调整温度。 2. **量具准备**:使用称量器准确测量食材,烘焙对精确度要求很高。 3. **工具集合**:根据食谱准备好所需的烘焙工具,比如搅拌碗、橡皮刮刀、烤盘或模具。 然后是实际操作: - 按照食谱步骤,先混合干性成分(如面粉、糖、发酵粉),再加入湿性成分(如鸡蛋、牛奶、黄油)。 - 调整面糊到适合的质地,避免过搅拌导致面筋过度发展,影响口感。 - 将面糊倒入准备好的模具中,轻轻震动排除气泡。 - 放入预热好的烤箱,按照食谱指示的时间和温度进行烘烤。 - 烘烤过程中不要频繁开门查看,以免影响温度波动。 - 使用牙签或竹签插入蛋糕中心检查是否熟透,不粘附面糊即可。 最后是冷却与装饰: - 将烘焙好的食物从烤箱取出,放在冷却架上自然冷却。 - 冷却后,你可以根据个人喜好进行装饰,比如撒上糖粉、涂抹奶油或添加果酱。 记得,烘焙是一门艺术,也是一种享受过程的活动。尝试不同的食谱,慢慢积累经验,你会发现自己的烘焙技能越来越出色!如果你有具体的烘焙问题或需要特定食谱,随时告诉我,我会尽力提供帮助! | 我刚学烘焙的时候,也是从零开始的,现在总结了一些经验,希望对你有所帮助。 1. 买一台烤箱,这个是最基本的,没有烤箱就别谈烘焙了,我刚学的时候是用的空气炸锅,但是一般空气炸锅的功能和烤箱有差距,比如温度,所以还是推荐买烤箱。 2. 烘焙工具,量勺,量杯,刮刀,分蛋器,搅拌碗,打蛋器,裱花袋,硅胶垫,烘焙模具,烘焙纸等等,都是必备的,当然有的工具不是必须的,比如我就不爱用搅拌碗,直接用盆子来代替。 3. 烘焙配方,刚开始学的时候,我都是直接在网上找配方,后来慢慢发现,有些配方的成品口感并不是很好,所以我建议你最好是找一些烘焙书籍,比如《烘焙圣经》《烘焙基础》,这样你的烘焙之路才能走得更远。 4. 学习方法,我刚开始学烘焙的时候,都是边看配方边看教程,然后自己做,但是你会发现,很多配方你根本看不懂,不知道具体要怎么操作,所以你可以先看一些入门教程,然后自己动手做,这样你才能真正理解配方,而且你做的时候,也可以随时调整配方。 5. 以上就是我分享的一些烘焙心得,希望对你有所帮助,如果你还有其他问题,欢迎留言交流。 |
|
||||||
|
| Google 卫星地图拍下过哪些震撼的画面? | 哇,Google 卫星地图确实捕捉到了许多令人震撼的画面!从自然奇观到人类工程,它的覆盖范围广泛且丰富。以下是一些特别引人注目的例子: 1. **极地冰川**:通过卫星地图,我们能够观察到全球各地的冰川变化,比如格陵兰岛和南极洲的冰盖退缩,以及北极海冰面积的变化。这些变化对全球气候变化的研究至关重要。 2. **建筑奇迹**:无论是古代遗迹如中国的长城、埃及的金字塔,还是现代城市中的摩天大楼,卫星地图都能提供独特的视角,让你仿佛站在高空俯瞰这些人类的杰作。 3. **自然灾害现场**:在发生地震、洪水或飓风等自然灾害后,卫星地图能够迅速提供受灾区域的即时图像,帮助救援团队进行有效的部署和评测。 4. **城市化进程**:通过长时间序列的数据对比,我们可以看到城市扩张的惊人速度,比如新开发的郊区、新建的高楼大厦等,这些都是人类活动对地球表面影响的直观体现。 5. **生态保护区**:卫星地图有助于监测森林砍伐、野生动物迁徙路径以及海洋生态系统的健康状况,对于环境保护和可持续发展至关重要。 6. **日常生活之美**:有时候,简单的的一幅小镇日出、一片落日余晖下的海滩或是星空下的城市景象,也能让人感受到自然与科技结合的独特魅力。 这些画面不仅展现了地球的多样性和美丽,也提醒我们保护环境的重要性。每次探索卫星地图都像是开启了一扇通往地球每一个角落的大门,每一次点击都可能带来新的发现和惊喜。 | 我先放个图: 这张图片是2018年7月16号的,地点在非洲的肯尼亚,可以看到一个巨大的“水坑”,实际上那是一块冰山。 这张照片拍摄的是冰山融化的瞬间,冰山表面的温度已经达到了0度以上,所以冰山上的雪开始融化,最终形成了一片巨大的“水坑”。 但是,这个“水坑”其实并不是真正的水坑,它只是一是一片冰山。 冰山的融化是因为全球气候变暖引起的,冰山融化之后,海平面就会升高,对人类的生存造成威胁。 所以,为了保护地球,我们应该尽可能地减少二氧化碳排放,减缓全球气候变暖。 |
|
||||||
|
|
||||||
|
## 6. Model Upload
|
||||||
|
You can use the ModelScope ModelHub to upload your trained models to the ModelScope platform. You can either create the corresponding model in advance on the ModelScope community webpage and then upload the local model directory via the `push_model` interface, or you can directly use `push_model` to automatically create and upload the model.
|
||||||
|
|
||||||
|
```python
|
||||||
|
from modelscope.hub.api import HubApi
|
||||||
|
|
||||||
|
YOUR_ACCESS_TOKEN = 'Please obtain from ModelScope Personal Center -> Access Token'
|
||||||
|
api = HubApi()
|
||||||
|
api.login(YOUR_ACCESS_TOKEN)
|
||||||
|
api.push_model(
|
||||||
|
model_id="AlexEz/zhihu_bot_lora", # Username/Model Repository Name
|
||||||
|
model_dir="output/qwen2-7b-instruct/v1-20240819-150005/checkpoint-371" # Local model directory, must include configuration.json
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,300 @@
|
||||||
|
# Evaluating the Qwen3 Model
|
||||||
|
|
||||||
|
Qwen3 is the latest generation of the Qwen series of large language models, offering a range of dense and mixed expert (MoE) models. Based on extensive training, Qwen3 has made groundbreaking advances in reasoning, instruction following, agency capabilities, and multilingual support, enabling seamless switching between thinking and non-thinking modes. In this best practices article, we will use the EvalScope framework to conduct a comprehensive evaluation of the Qwen3-32B model, covering model service inference performance evaluation, model capability evaluation, and model thinking efficiency evaluation.
|
||||||
|
|
||||||
|
## Install Dependencies
|
||||||
|
|
||||||
|
First, install the [EvalScope](https://github.com/modelscope/evalscope) model evaluation framework:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope[app,perf]' -U
|
||||||
|
```
|
||||||
|
|
||||||
|
## Model Service Inference Performance Evaluation
|
||||||
|
|
||||||
|
To start, we need to access the model capabilities via an OpenAI API-compatible inference service for evaluation. It's worth noting that EvalScope also supports using transformers for model inference evaluation. For more information, refer to the [documentation](https://evalscope.readthedocs.io/en/latest/get_started/basic_usage.html#id2).
|
||||||
|
|
||||||
|
Besides deploying the model on cloud services that support the OpenAI interface, you can choose to locally start the model using frameworks like vLLM or ollama. These inference frameworks can support multiple concurrent requests, accelerating the evaluation process. Especially for inference models, whose output typically contains long chains of thought, often generating over 10,000 tokens. Using efficient inference frameworks to deploy the model can significantly increase inference speed.
|
||||||
|
|
||||||
|
### ModelScope API Inference Service Performance Evaluation
|
||||||
|
|
||||||
|
Users can access Qwen3 through the online model inference service provided by ModelScope. For details, refer to: [https://modelscope.cn/docs/model-service/API-Inference/intro](https://modelscope.cn/docs/model-service/API-Inference/intro)
|
||||||
|
|
||||||
|
> **Client-side Example**
|
||||||
|
|
||||||
|
```python
|
||||||
|
from openai import OpenAI
|
||||||
|
|
||||||
|
client = OpenAI(
|
||||||
|
api_key="MODELSCOPE_SDK_TOKEN", # Replace with your ModelScope SDK Token, see: https://modelscope.cn/my/myaccesstoken
|
||||||
|
base_url="https://api-inference.modelscope.cn/v1/"
|
||||||
|
)
|
||||||
|
|
||||||
|
response = client.chat.completions.create(
|
||||||
|
model="Qwen/Qwen3-32B", # ModelScope model_id
|
||||||
|
messages=[
|
||||||
|
{
|
||||||
|
'role': 'system',
|
||||||
|
'content': 'You are a helpful assistant.'
|
||||||
|
},
|
||||||
|
{
|
||||||
|
'role': 'user',
|
||||||
|
'content': 'Write a quicksort in Python.'
|
||||||
|
}
|
||||||
|
],
|
||||||
|
stream=True
|
||||||
|
)
|
||||||
|
|
||||||
|
for chunk in response:
|
||||||
|
if chunk.choices[0].delta.reasoning_content:
|
||||||
|
print(chunk.choices[0].delta.reasoning_content, end='', flush=True)
|
||||||
|
else:
|
||||||
|
print(chunk.choices[0].delta.content, end='', flush=True)
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Performance Test Command**
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope perf \
|
||||||
|
--model Qwen/Qwen3-32B \
|
||||||
|
--url "https://api-inference.modelscope.cn/v1/chat/completions" \
|
||||||
|
--api-key "YOUR_MODELSCOPE_SDK_TOKEN" \
|
||||||
|
--parallel 5 \
|
||||||
|
--number 20 \
|
||||||
|
--api openai \
|
||||||
|
--dataset openqa \
|
||||||
|
--stream \
|
||||||
|
--wandb-api-key "YOUR_WANDB_API_KEY" # Optional
|
||||||
|
```
|
||||||
|
|
||||||
|
* Refer to [https://modelscope.cn/my/myaccesstoken](https://modelscope.cn/my/myaccesstoken) for obtaining YOUR\_MODELSCOPE\_SDK\_TOKEN
|
||||||
|
|
||||||
|
|
||||||
|
Example output:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Local Model Service Performance Evaluation
|
||||||
|
|
||||||
|
The command to start the model service locally using the vLLM framework (vLLM version >= 0.8.5) is as follows (default is **thinking mode**):
|
||||||
|
|
||||||
|
```bash
|
||||||
|
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 vllm serve Qwen/Qwen3-32B --gpu-memory-utilization 0.9 --served-model-name Qwen3-32B --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
|
||||||
|
> **Performance Test Command**
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope perf \
|
||||||
|
--url "http://127.0.0.1:8801/v1/chat/completions" \
|
||||||
|
--parallel 5 \
|
||||||
|
--model Qwen3-32B \
|
||||||
|
--number 20 \
|
||||||
|
--api openai \
|
||||||
|
--dataset openqa \
|
||||||
|
--stream
|
||||||
|
```
|
||||||
|
|
||||||
|
For detailed parameter explanations, refer to [Performance Evaluation](https://evalscope.readthedocs.io/en/latest/user_guides/stress_test/quick_start.html)
|
||||||
|
|
||||||
|
Example output:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Model Capability Evaluation
|
||||||
|
|
||||||
|
Now let's proceed with the model capability evaluation process.
|
||||||
|
|
||||||
|
Note: Subsequent evaluation processes are based on models started using the vLLM framework. You can start the model service according to the previous step's model service performance evaluation steps or use the local model service. The model defaults to using thinking mode.
|
||||||
|
|
||||||
|
### Building Evaluation Sets (Optional)
|
||||||
|
|
||||||
|
To comprehensively evaluate the model's capabilities, we can mix the benchmarks already supported by EvalScope to create a comprehensive evaluation set. Below is an example of an evaluation set covering mainstream benchmarks, evaluating the model's coding ability (LiveCodeBench), mathematical ability (AIME2024, AIME2025), knowledge ability (MMLU-Pro, CEVAL), instruction following (IFEval), and more.
|
||||||
|
|
||||||
|
Run the following code to automatically download and mix datasets based on the defined schema and save the constructed evaluation set in a local jsonl file. Of course, you can skip this step and directly use the processed data set we placed in the [ModelScope repository](https://modelscope.cn/datasets/modelscope/EvalScope-Qwen3-Test/summary).
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.collections import CollectionSchema, DatasetInfo, WeightedSampler
|
||||||
|
from evalscope.utils.io_utils import dump_jsonl_data
|
||||||
|
|
||||||
|
schema = CollectionSchema(name='Qwen3', datasets=[
|
||||||
|
CollectionSchema(name='English', datasets=[
|
||||||
|
DatasetInfo(name='mmlu_pro', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
|
||||||
|
DatasetInfo(name='mmlu_redux', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
|
||||||
|
DatasetInfo(name='ifeval', weight=1, task_type='instruction', tags=['en'], args={'few_shot_num': 0}),
|
||||||
|
]),
|
||||||
|
CollectionSchema(name='Chinese', datasets=[
|
||||||
|
DatasetInfo(name='ceval', weight=1, task_type='exam', tags=['zh'], args={'few_shot_num': 0}),
|
||||||
|
DatasetInfo(name='iquiz', weight=1, task_type='exam', tags=['zh'], args={'few_shot_num': 0}),
|
||||||
|
]),
|
||||||
|
CollectionSchema(name='Code', datasets=[
|
||||||
|
DatasetInfo(name='live_code_bench', weight=1, task_type='code', tags=['en'], args={'few_shot_num': 0, 'subset_list': ['v5_v6'], 'extra_params': {'start_date': '2025-01-01', 'end_date': '2025-04-30'}}),
|
||||||
|
]),
|
||||||
|
CollectionSchema(name='Math&Science', datasets=[
|
||||||
|
DatasetInfo(name='math_500', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
|
||||||
|
DatasetInfo(name='aime24', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
|
||||||
|
DatasetInfo(name='aime25', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
|
||||||
|
DatasetInfo(name='gpqa', weight=1, task_type='knowledge', tags=['en'], args={'subset_list': ['gpqa_diamond'], 'few_shot_num': 0})
|
||||||
|
])
|
||||||
|
])
|
||||||
|
|
||||||
|
# get the mixed data
|
||||||
|
mixed_data = WeightedSampler(schema).sample(100000000) # set a large number to ensure all datasets are sampled
|
||||||
|
# dump the mixed data to a jsonl file
|
||||||
|
dump_jsonl_data(mixed_data, 'outputs/qwen3_test.jsonl')
|
||||||
|
```
|
||||||
|
|
||||||
|
### Running Evaluation Tasks
|
||||||
|
|
||||||
|
Run the following code to evaluate the Qwen3-32B model's performance in **thinking mode**:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen3-32B',
|
||||||
|
api_url='http://127.0.0.1:8801/v1/chat/completions',
|
||||||
|
eval_type='service',
|
||||||
|
datasets=[
|
||||||
|
'data_collection',
|
||||||
|
],
|
||||||
|
dataset_args={
|
||||||
|
'data_collection': {
|
||||||
|
'dataset_id': 'modelscope/EvalScope-Qwen3-Test',
|
||||||
|
'filters': {'remove_until': '</think>'} # Filter out the content of thinking
|
||||||
|
}
|
||||||
|
},
|
||||||
|
eval_batch_size=128,
|
||||||
|
generation_config={
|
||||||
|
'max_tokens': 30000, # Max number of generated tokens, suggested to set a large value to avoid output truncation
|
||||||
|
'temperature': 0.6, # Sampling temperature (recommended value per Qwen report)
|
||||||
|
'top_p': 0.95, # top-p sampling (recommended value per Qwen report)
|
||||||
|
'top_k': 20, # top-k sampling (recommended value per Qwen report)
|
||||||
|
'n': 1, # Number of replies generated per request
|
||||||
|
},
|
||||||
|
timeout=60000, # Timeout
|
||||||
|
stream=True, # Use streaming output
|
||||||
|
limit=100, # Set to 100 samples for testing
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
Output results:
|
||||||
|
|
||||||
|
Note: The results below are for 1000 samples, only for testing the evaluation process. The limitation should be removed for formal evaluation.
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-------------+-------------------------+-----------------+---------------+-------+
|
||||||
|
| task_type | metric | dataset_name | average_score | count |
|
||||||
|
+-------------+-------------------------+-----------------+---------------+-------+
|
||||||
|
| code | Pass@1 | live_code_bench | 0.544 | 182 |
|
||||||
|
| exam | AverageAccuracy | ceval | 0.88 | 125 |
|
||||||
|
| exam | AverageAccuracy | iquiz | 0.8417 | 120 |
|
||||||
|
| exam | AverageAccuracy | mmlu_pro | 0.6867 | 83 |
|
||||||
|
| exam | AverageAccuracy | mmlu_redux | 0.9277 | 83 |
|
||||||
|
| instruction | inst_level_loose_acc | ifeval | 0.9157 | 83 |
|
||||||
|
| instruction | inst_level_strict_acc | ifeval | 0.8775 | 83 |
|
||||||
|
| instruction | prompt_level_loose_acc | ifeval | 0.8675 | 83 |
|
||||||
|
| instruction | prompt_level_strict_acc | ifeval | 0.8193 | 83 |
|
||||||
|
| knowledge | AveragePass@1 | gpqa | 0.6 | 65 |
|
||||||
|
| math | AveragePass@1 | math_500 | 0.9516 | 62 |
|
||||||
|
| math | AveragePass@1 | aime24 | 0.7 | 30 |
|
||||||
|
| math | AveragePass@1 | aime25 | 0.7667 | 30 |
|
||||||
|
+-------------+-------------------------+-----------------+---------------+-------+
|
||||||
|
```
|
||||||
|
|
||||||
|
Testing model performance in **non-thinking mode** (note the changes in generation config):
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen3-32B',
|
||||||
|
api_url='http://127.0.0.1:8801/v1/chat/completions',
|
||||||
|
eval_type='service',
|
||||||
|
datasets=[
|
||||||
|
'data_collection',
|
||||||
|
],
|
||||||
|
dataset_args={
|
||||||
|
'data_collection': {
|
||||||
|
'dataset_id': 'modelscope/EvalScope-Qwen3-Test',
|
||||||
|
}
|
||||||
|
},
|
||||||
|
eval_batch_size=128,
|
||||||
|
generation_config={
|
||||||
|
'max_tokens': 20000, # Max number of generated tokens, suggested to set a large value to avoid output truncation
|
||||||
|
'temperature': 0.7, # Sampling temperature (recommended value per Qwen report)
|
||||||
|
'top_p': 0.8, # top-p sampling (recommended value per Qwen report)
|
||||||
|
'top_k': 20, # top-k sampling (recommended value per Qwen report)
|
||||||
|
'n': 1, # Number of replies generated per request
|
||||||
|
'chat_template_kwargs': {'enable_thinking': False} # close thinking mode
|
||||||
|
},
|
||||||
|
timeout=60000, # Timeout
|
||||||
|
stream=True, # Use streaming output
|
||||||
|
limit=1000, # Set to 1000 samples for testing
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
Output results:
|
||||||
|
```text
|
||||||
|
+-------------+-------------------------+-----------------+---------------+-------+
|
||||||
|
| task_type | metric | dataset_name | average_score | count |
|
||||||
|
+-------------+-------------------------+-----------------+---------------+-------+
|
||||||
|
| code | Pass@1 | live_code_bench | 0.2857 | 182 |
|
||||||
|
| exam | AverageAccuracy | ceval | 0.808 | 125 |
|
||||||
|
| exam | AverageAccuracy | iquiz | 0.775 | 120 |
|
||||||
|
| exam | AverageAccuracy | mmlu_pro | 0.6145 | 83 |
|
||||||
|
| exam | AverageAccuracy | mmlu_redux | 0.8313 | 83 |
|
||||||
|
| instruction | inst_level_loose_acc | ifeval | 0.6948 | 83 |
|
||||||
|
| instruction | inst_level_strict_acc | ifeval | 0.6888 | 83 |
|
||||||
|
| instruction | prompt_level_loose_acc | ifeval | 0.6265 | 83 |
|
||||||
|
| instruction | prompt_level_strict_acc | ifeval | 0.6145 | 83 |
|
||||||
|
| knowledge | AveragePass@1 | gpqa | 0.4154 | 65 |
|
||||||
|
| math | AveragePass@1 | math_500 | 0.4355 | 62 |
|
||||||
|
| math | AveragePass@1 | aime24 | 0.2333 | 30 |
|
||||||
|
| math | AveragePass@1 | aime25 | 0.1333 | 30 |
|
||||||
|
+-------------+-------------------------+-----------------+---------------+-------+
|
||||||
|
```
|
||||||
|
|
||||||
|
### Visualization of Evaluation Results
|
||||||
|
|
||||||
|
EvalScope supports result visualization, allowing you to view the model's specific output.
|
||||||
|
|
||||||
|
Run the following command to launch the Gradio-based visualization interface:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope app
|
||||||
|
```
|
||||||
|
|
||||||
|
Select the evaluation report and click load to view the model's output for each question and overall accuracy:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Model Thinking Efficiency Evaluation
|
||||||
|
|
||||||
|
Next, we will measure the thinking efficiency of the Qwen-32B model using the [MATH-500](https://www.modelscope.cn/datasets/AI-ModelScope/MATH-500) dataset and compare it with three other models (DeepSeek-R1, QwQ-32B, etc.). We assess the model's performance from six dimensions:
|
||||||
|
|
||||||
|
- Reasoning Tokens $T$: Total number of reasoning content tokens during model inference, typically the portion before the `</think>` tag.
|
||||||
|
- First Correct Tokens $\hat{T}$: Number of tokens from the start to the first recognizable correct answer position during model inference.
|
||||||
|
- Reflection Tokens: $T-\hat{T}$, i.e., the number of tokens from the first correct answer position to the end of reasoning.
|
||||||
|
- Token Efficiency: $\hat{T}/T$, the proportion of tokens from the start to the first correct answer position to the total token count.
|
||||||
|
- Thought Num: Number of sub-chains of thought during model inference, judged by counting keywords like `alternatively`, `but wait`, `let me reconsider`, etc.
|
||||||
|
- Accuracy: The proportion of correct samples during model inference to the total sample count.
|
||||||
|
|
||||||
|
Test results:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
From the graph, we can conclude the following:
|
||||||
|
|
||||||
|
- Qwen3-32B achieves comparable accuracy to QwQ-32B in thinking mode (both overlap on the Accuracy curve), reaching the highest level.
|
||||||
|
- As problem difficulty increases, the output length increases with problem complexity, indicating longer "thinking time" for more complex problems, aligning with the Inference-Time Scaling phenomenon.
|
||||||
|
- As problem difficulty rises, although output length consistently increases, token efficiency also improves (Qwen3-32B from 31% to 43%, QwQ-32B from 31% to 49%). This suggests inference-type models consume tokens more "worthily" in complex problems. For simpler problems, unnecessary token waste might occur: even simple problems may undergo unnecessary answer verification. Qwen-32B generates more tokens than other models, maintaining high accuracy even in high-difficulty Level 5 problems, but it also indicates a tendency for over-analysis.
|
||||||
|
|
||||||
|
For detailed evaluation methods and more conclusions, refer to: [Best Practices for Model Thinking Efficiency Evaluation](https://evalscope.readthedocs.io/en/latest/best_practice/think_eval.html)
|
||||||
|
|
@ -0,0 +1,7 @@
|
||||||
|
# ms-swift Integration
|
||||||
|
|
||||||
|
The evaluation capabilities of the [ms-swift](https://github.com/modelscope/ms-swift) framework utilize the EvalScope evaluation framework from the ModelScope community and have been encapsulated to support the evaluation needs of various models. We currently support evaluation processes for **standard evaluation datasets** as well as **user-defined** evaluation datasets.
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
For more information about ms-swift evaluation, please refer to [ms-swift](https://swift.readthedocs.io/en/latest/Instruction/Evaluation.html).
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,151 @@
|
||||||
|
# Evaluating Text-to-Image Models
|
||||||
|
|
||||||
|
The rapid advancement of generative models in fields like text-to-image generation has introduced a plethora of models to the community. Objectively evaluating the performance of these diverse models has become crucial for technology selection and optimization. Traditional evaluation methods heavily rely on manual annotation and subjective judgment, often requiring significant human resources for sample selection, quality scoring, and result analysis. This process is not only time-consuming and costly but also prone to bias due to reviewers' subjective preferences, which is particularly problematic in image generation. For instance, in text-image alignment evaluation, manual scoring involves organizing teams to score thousands of generated images individually, taking days and risking consistency. Moreover, manual evaluation struggles to accurately quantify complex metrics like image realism and text-image matching, limiting precise model iteration guidance.
|
||||||
|
|
||||||
|
To address these challenges, EvalScope offers a comprehensive solution from automated evaluation to intelligent analysis. Its core advantages include:
|
||||||
|
|
||||||
|
1. **Automated Evaluation Capability**: Supports batch inference and metric calculation for mainstream text-to-image models like Stable Diffusion and Flux, using models like MPS and HPSv2.1Score to assess image realism and text-image alignment. This replaces traditional manual annotation with scripted processes. For more supported metrics and datasets, refer to the documentation: [EvalScope Documentation](https://evalscope.readthedocs.io/en/latest/user_guides/aigc/t2i.html).
|
||||||
|
|
||||||
|
2. **Intelligent Reporting and Visualization**: Utilizes large models to automatically generate multi-dimensional analysis reports, combined with interactive visualization tools like radar and bar charts, to intuitively display model performance differences across scenarios, aiding developers in quickly identifying model bottlenecks.
|
||||||
|
|
||||||
|
This document uses FLUX.1-dev and HiDream-I1-Dev models as evaluation subjects on the EvalMuse dataset, providing developers with a complete practice guide from environment setup to result interpretation, leveraging EvalScope's intelligent reporting and visualization features.
|
||||||
|
|
||||||
|
## Installing Dependencies
|
||||||
|
|
||||||
|
First, install the EvalScope model evaluation framework:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope[aigc,app]' -U
|
||||||
|
```
|
||||||
|
|
||||||
|
To use the latest text-to-image models, including HiDream-I1-Dev, install the latest diffusers library:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install git+https://github.com/huggingface/diffusers
|
||||||
|
```
|
||||||
|
|
||||||
|
## Running Evaluation Tasks
|
||||||
|
|
||||||
|
Next, we will comprehensively test text-to-image models using the EvalMuse benchmark. EvalMuse focuses on "text-image" alignment capabilities with nearly 200 diverse prompts covering semantic tags like objects, colors, quantities, and actions, enabling multi-dimensional performance analysis through structured annotation. You can view prompt samples on the ModelScope community dataset page: [EvalMuse Dataset Samples](https://modelscope.cn/datasets/AI-ModelScope/T2V-Eval-Prompts/summary).
|
||||||
|
|
||||||
|
This evaluation uses FGA-BLIP2 as an automated scoring model, replacing traditional manual annotation to significantly improve efficiency. The scoring system consists of two parts: an overall score (0-5) for evaluating the comprehensive quality and text matching of generated images, and subcategory scores (0-1) for specific semantic tags like objects, colors, and quantities. This method avoids subjective bias and ensures reproducible results, especially suitable for large-scale model comparison tests.
|
||||||
|
|
||||||
|
Run the following code to start the full evaluation process. The system will automatically download the text-to-image model, evaluation dataset, and scoring model (the first run may take a long time to download, please be patient), and complete inference with approximately 60GB of VRAM support.
|
||||||
|
|
||||||
|
Note: After the evaluation, the Qwen3-235B-A22B large model API will be called to generate an intelligent report. Please obtain the `MODELSCOPE_SDK_TOKEN` from the ModelScope community and configure it in the environment variable in advance. Get it here: [Token Page](https://modelscope.cn/my/myaccesstoken).
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.constants import ModelTask
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
from modelscope import AutoTokenizer, AutoModelForCausalLM
|
||||||
|
import torch
|
||||||
|
|
||||||
|
# HiDream model requires llama-3.1-8b-instruct model as Encoder
|
||||||
|
tokenizer_4 = AutoTokenizer.from_pretrained("LLM-Research/Meta-Llama-3.1-8B-Instruct")
|
||||||
|
text_encoder_4 = AutoModelForCausalLM.from_pretrained(
|
||||||
|
"LLM-Research/Meta-Llama-3.1-8B-Instruct",
|
||||||
|
output_hidden_states=True,
|
||||||
|
output_attentions=True,
|
||||||
|
torch_dtype=torch.bfloat16,
|
||||||
|
)
|
||||||
|
# Configure evaluation parameters
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='HiDream-ai/HiDream-I1-Dev', # Specify model id on modelscope
|
||||||
|
model_task=ModelTask.IMAGE_GENERATION, # Must be IMAGE_GENERATION
|
||||||
|
# Configure model parameters, refer to the corresponding Pipeline for supported parameters
|
||||||
|
model_args={
|
||||||
|
'pipeline_cls': 'HiDreamImagePipeline', # Specify using HiDreamImagePipeline
|
||||||
|
'torch_dtype': 'torch.bfloat16', # Use bfloat16 precision
|
||||||
|
'tokenizer_4': tokenizer_4, # Specify tokenizer
|
||||||
|
'text_encoder_4': text_encoder_4, # Specify text encoder
|
||||||
|
},
|
||||||
|
# Configure evaluation dataset
|
||||||
|
datasets=[
|
||||||
|
'evalmuse',
|
||||||
|
],
|
||||||
|
# Configure model generation parameters, refer to the corresponding Pipeline for supported parameters
|
||||||
|
generation_config={
|
||||||
|
'height': 1024, # Image height
|
||||||
|
'width': 1024, # Image width
|
||||||
|
'num_inference_steps': 28, # For HiDream-Dev, recommended steps are 28
|
||||||
|
'guidance_scale': 0.0, # For HiDream-Dev, recommended is 0.0
|
||||||
|
},
|
||||||
|
# Whether to generate an analysis report
|
||||||
|
analysis_report=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
# Run evaluation task
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
The evaluation output shows the model's scores across different dimensions:
|
||||||
|
|
||||||
|
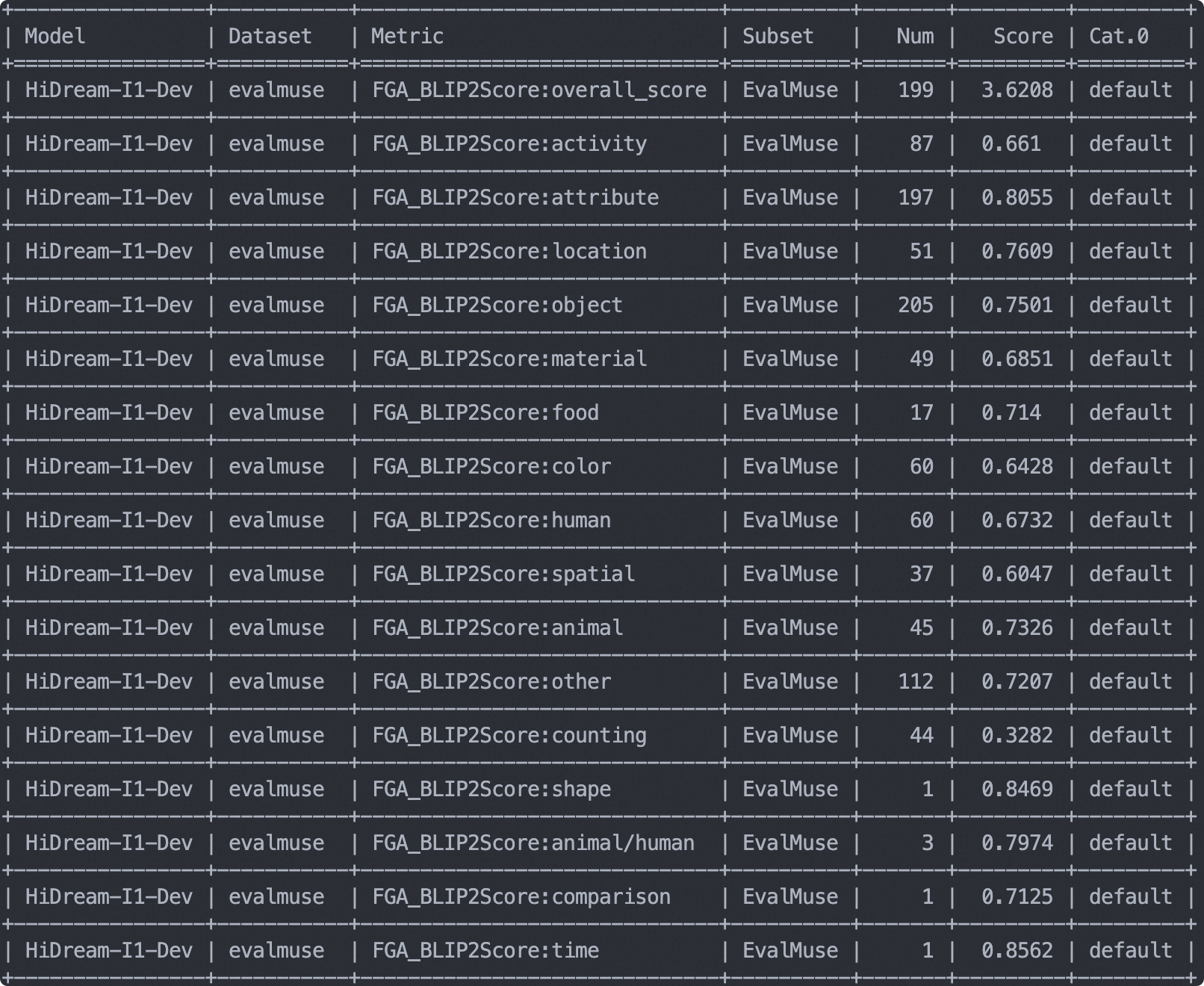
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
To further test the FLUX.1-dev model, run the following code:
|
||||||
|
|
||||||
|
```python
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='black-forest-labs/FLUX.1-dev', # model id
|
||||||
|
model_task=ModelTask.IMAGE_GENERATION, # must be IMAGE_GENERATION
|
||||||
|
model_args={
|
||||||
|
'pipeline_cls': 'FluxPipeline',
|
||||||
|
'torch_dtype': 'torch.float16',
|
||||||
|
},
|
||||||
|
datasets=[
|
||||||
|
'evalmuse',
|
||||||
|
],
|
||||||
|
generation_config={
|
||||||
|
'height': 1024,
|
||||||
|
'width': 1024,
|
||||||
|
'num_inference_steps': 50,
|
||||||
|
'guidance_scale': 3.5
|
||||||
|
},
|
||||||
|
analysis_report=True,
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, the EvalScope framework supports specifying prompts and image paths for custom model evaluation, not limited to local text-to-image inference. For specific usage, refer here: [EvalScope Documentation](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/aigc/t2i.html#id8).
|
||||||
|
|
||||||
|
## Visualization of Evaluation Results
|
||||||
|
|
||||||
|
Run the following command to launch the visualization interface, intuitively displaying model evaluation effects and analyzing model outputs:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope app
|
||||||
|
```
|
||||||
|
|
||||||
|
The evaluation results include intelligent analysis reports, model score distribution, and generated image cases. The analysis report shows that the HiDream-I1-Dev model performs well in image description and understanding but needs improvement in handling complex semantics, spatial relationships, and quantity reasoning.
|
||||||
|
|
||||||
|
|
||||||
|
*Intelligent Report Analysis*
|
||||||
|
|
||||||
|
|
||||||
|
*Model Score Distribution*
|
||||||
|
|
||||||
|
|
||||||
|
*Generated Image Case View*
|
||||||
|
|
||||||
|
We can also compare the results with the official EvalMuse test results. HiDream-I1-Dev ranks third in this framework, indicating good overall performance. Although the model data is not included in the table, this external validation shows that our evaluation framework effectively reflects the model's true performance level, comparable to the official EvalMuse benchmark test.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
The automated evaluation provided by the EvalScope framework objectively achieves full-process automation from batch inference to multi-dimensional analysis. Combined with intelligent report analysis and result visualization, it significantly enhances the efficiency and objectivity of text-to-image model performance evaluation. We hope these efforts help address the issues of relying on extensive human resources for sample selection and subjective scoring in traditional manual evaluation, reducing evaluation cycles and costs, and avoiding subjective bias that affects evaluation results. On this basis, we will further improve the capabilities of the EvalScope evaluation framework and introduce evaluation standards that cover more aspects, facilitating developers to conduct more comprehensive and targeted evaluations of model performance in different scenarios.
|
||||||
|
|
||||||
|
## References
|
||||||
|
|
||||||
|
1. Zhang, S. _et al._ Learning Multi-dimensional Human Preference for Text-to-Image Generation. Preprint at [https://doi.org/10.48550/arXiv.2405.14705](https://doi.org/10.48550/arXiv.2405.14705)(2024).
|
||||||
|
|
||||||
|
2. Wu, X. _et al._ Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis. Preprint at [https://doi.org/10.48550/arXiv.2306.09341](https://doi.org/10.48550/arXiv.2306.09341)(2023).
|
||||||
|
|
||||||
|
3. Chang, L.-W. _et al._ FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion. Preprint at [https://doi.org/10.48550/arXiv.2406.06858](https://doi.org/10.48550/arXiv.2406.06858)(2024).
|
||||||
|
|
||||||
|
4. Cai, Q. _et al._ HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer. Preprint at [https://doi.org/10.48550/arXiv.2505.22705](https://doi.org/10.48550/arXiv.2505.22705)(2025).
|
||||||
|
|
||||||
|
5. Han, S. _et al._ EvalMuse-40K: A Reliable and Fine-Grained Benchmark with Comprehensive Human Annotations for Text-to-Image Generation Model Evaluation. Preprint at [https://doi.org/10.48550/arXiv.2412.18150](https://doi.org/10.48550/arXiv.2412.18150)(2024).
|
||||||
|
|
@ -0,0 +1,182 @@
|
||||||
|
# Evaluating the Thinking Efficiency of Models
|
||||||
|
|
||||||
|
With the rapid development of large language models, their reasoning capabilities have significantly improved. In particular, long reasoning models such as OpenAI's o1, QwQ-32B, DeepSeek-R1-671B, and Kimi K1.5 have garnered attention for exhibiting human-like deep thinking abilities. These models are capable of continuous reasoning during the decoding stage through Inference-Time Scaling, allowing them to think and explore new ideas to arrive at the correct answer.
|
||||||
|
|
||||||
|
However, as research has progressed, researchers have identified two extreme issues during the reasoning process of these models: **Underthinking** and **Overthinking**:
|
||||||
|
|
||||||
|
- The phenomenon of **Underthinking** refers to the model frequently shifting its thought process during reasoning, often using phrases like "alternatively," "but wait," or "let me reconsider," and failing to focus on a correct thought process for deeper analysis, ultimately leading to incorrect answers.[^1] This phenomenon resembles "Attention Deficit Hyperactivity Disorder" in humans, adversely affecting the quality of the model's reasoning.
|
||||||
|
|
||||||
|
- The phenomenon of **Overthinking** manifests as the model generating unnecessarily long chains of thought, wasting a substantial amount of computational resources. For example, for a simple question like "2+3=?," some long reasoning models may consume over 900 tokens exploring various problem-solving strategies.[^2] While such chain-of-thought strategies are beneficial for complex problems, repeatedly validating existing answers and conducting overly broad explorations for simple problems is clearly a waste of computational resources.[^3]
|
||||||
|
|
||||||
|
Both phenomena highlight a key question: how can we improve the thinking efficiency of models while ensuring the quality of their answers? In other words, **we want models to arrive at correct answers with outputs as brief as possible**. In this best practice guide, we will evaluate the thinking efficiency of models such as DeepSeek-R1-Distill-Qwen-7B using the [MATH-500](https://www.modelscope.cn/datasets/AI-ModelScope/MATH-500) dataset, assessing model performance across six dimensions: the number of reasoning tokens, the number of first correct tokens, the number of reflection tokens, token efficiency, the number of sub-thought chains, and accuracy. Let’s get started.
|
||||||
|
|
||||||
|
## Installing Dependencies
|
||||||
|
|
||||||
|
First, install the [EvalScope](https://github.com/modelscope/evalscope) model evaluation framework:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
pip install 'evalscope' -U
|
||||||
|
```
|
||||||
|
|
||||||
|
## Evaluating the Model
|
||||||
|
|
||||||
|
We will begin the formal evaluation process, which consists of two main steps:
|
||||||
|
1. **Model Reasoning Evaluation**: Use the EvalScope framework to have the model reason through the MATH-500 dataset. This dataset includes 500 math problems, each consisting of a mathematical expression and the corresponding answer, with difficulty levels ranging from 1 (easy) to 5 (complex). This step will yield the model's reasoning results for each problem, as well as the overall accuracy rate.
|
||||||
|
2. **Model Thinking Efficiency Evaluation**: Using the EvalThink component within the EvalScope framework to conduct an in-depth analysis of the model's outputs, further assessing thinking efficiency in terms of token efficiency, model thinking length, the number of sub-thought chains, and more.
|
||||||
|
|
||||||
|
### Model Reasoning
|
||||||
|
|
||||||
|
**Preparing to Evaluate the Model**
|
||||||
|
|
||||||
|
First, we need to access the model capabilities via an OpenAI API-compatible inference service for evaluation. It is worth noting that EvalScope also supports model inference evaluation using transformers; detailed information can be found in the EvalScope documentation.
|
||||||
|
|
||||||
|
In addition to deploying the model to a cloud service that supports the OpenAI API, you can also choose to launch the model locally using frameworks like vLLM or Ollama. These inference frameworks can efficiently support concurrent requests, speeding up the evaluation process. Particularly for R1-type models, which often produce long chains of thought, the output token count can frequently exceed 10,000. Deploying the model using an efficient inference framework can significantly enhance reasoning speed.
|
||||||
|
|
||||||
|
As an example, here is how to deploy the DeepSeek-R1-Distill-Qwen-7B model using vLLM:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-1.5B --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
|
||||||
|
**Using EvalScope to Evaluate the Model**
|
||||||
|
|
||||||
|
Run the following command to have the model reason through the MATH-500 dataset and obtain the output results for each problem, as well as the overall accuracy:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
|
||||||
|
task_config = TaskConfig(
|
||||||
|
api_url='http://0.0.0.0:8801/v1/chat/completions', # Inference service address
|
||||||
|
model='DeepSeek-R1-Distill-Qwen-7B', # Model name (must match the deployed model name)
|
||||||
|
eval_type='service', # Evaluation type, SERVICE indicates evaluating the inference service
|
||||||
|
datasets=['math_500'], # Dataset name
|
||||||
|
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # Dataset parameters
|
||||||
|
eval_batch_size=32, # Number of concurrent requests
|
||||||
|
generation_config={
|
||||||
|
'max_tokens': 20000, # Maximum number of tokens to generate; suggested to set a high value to avoid truncation
|
||||||
|
'temperature': 0.6, # Sampling temperature (recommended value from deepseek)
|
||||||
|
'top_p': 0.95, # Top-p sampling (recommended value from deepseek)
|
||||||
|
'n': 1, # Number of responses generated for each request
|
||||||
|
},
|
||||||
|
)
|
||||||
|
run_task(task_config)
|
||||||
|
```
|
||||||
|
|
||||||
|
The output will look like this, showing the model's accuracy on problems at each difficulty level:
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+=============================+===========+===============+==========+=======+=========+=========+
|
||||||
|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
|
||||||
|
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
|
||||||
|
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
|
||||||
|
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
|
||||||
|
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
|
||||||
|
+-----------------------------+-----------+---------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
### Evaluating Model Thinking Efficiency
|
||||||
|
|
||||||
|
Once we have the model's reasoning results, we can begin evaluating its thinking efficiency. Before we start, we need to introduce several key metrics involved in the evaluation process: token efficiency, model thinking length, and the number of sub-thought chains.
|
||||||
|
|
||||||
|
- **Reasoning Tokens**: This refers to the number of tokens generated in the model's long chain of thought during reasoning. For O1/R1 type reasoning models, this metric represents the number of tokens before the `</think>` marker.
|
||||||
|
- **First Correct Tokens**: The number of tokens from the start of the model's reasoning process to the first position that can be recognized as the correct answer.
|
||||||
|
- **Reflection Tokens**: The number of tokens from the position of the first correct answer to the end of reasoning.
|
||||||
|
- **Num Thought**: This metric indicates the number of different thought paths generated by the model during reasoning. Specifically, it is calculated by counting the occurrences of generated marker words (e.g., "alternatively," "but wait," "let me reconsider"). This reflects the frequency at which the model switches its thought process during reasoning.
|
||||||
|
- **Token Efficiency**: This refers to the ratio of first correct tokens to the total number of reasoning tokens, calculated as follows:
|
||||||
|
|
||||||
|
$$
|
||||||
|
M_{token} = \frac{1}{N} \sum^{N}_{i=1} \frac{\hat{T_i}}{T_i}
|
||||||
|
$$
|
||||||
|
|
||||||
|
Where $N$ is the number of problems, $\hat{T_i}$ is the number of tokens from the model's response to the first position recognized as the correct answer, and $T_i$ is the model's thinking length. If the model's answer is incorrect, then $\hat{T_i}$ is 0. A higher metric value indicates a higher proportion of effective thinking.
|
||||||
|
|
||||||
|
In this evaluation framework, we refer to the construction method of [ProcessBench](https://github.com/QwenLM/ProcessBench) and use an additional model, `Qwen2.5-72B-Instruct`, to detect the earliest position of the correct answer during the reasoning process. To achieve this, we first decompose the model output into multiple steps, numbering each step, and then use the `Qwen2.5-72B-Instruct` model to verify these steps to identify the position of the first correct answer token. We have implemented three decomposition strategies:
|
||||||
|
|
||||||
|
- **`separator`**: Decompose using the `\n\n` marker.
|
||||||
|
- **`keywords`**: Decompose using marker words (e.g., `alternatively`, `but wait`, `let me reconsider`).
|
||||||
|
- **`llm`**: Remove the `\n` markers from the response, use an LLM to rewrite the response, and insert `\n\n` markers for decomposition.
|
||||||
|
|
||||||
|
Using `Qwen2.5-72B-Instruct` as the judging model, simply run the following command to start the evaluation and obtain results:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.third_party.thinkbench import run_task
|
||||||
|
|
||||||
|
judge_config = dict( # Evaluation service configuration
|
||||||
|
api_key='EMPTY',
|
||||||
|
base_url='http://0.0.0.0:8801/v1',
|
||||||
|
model_name='Qwen2.5-72B-Instruct',
|
||||||
|
)
|
||||||
|
|
||||||
|
model_config = dict(
|
||||||
|
report_path = './outputs/2025xxxx', # Path to the model reasoning results from the previous step
|
||||||
|
model_name = 'DeepSeek-R1-Distill-Qwen-7B', # Model name
|
||||||
|
tokenizer_path = 'deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Path to the model tokenizer for token count calculation
|
||||||
|
dataset_name = 'math_500', # Dataset name from the previous step
|
||||||
|
subsets = ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # Subsets from the previous step
|
||||||
|
split_strategies='separator', # Strategy for splitting reasoning steps, options are separator, keywords, llm
|
||||||
|
judge_config=judge_config
|
||||||
|
)
|
||||||
|
|
||||||
|
max_tokens = 20000 # Filter outputs with token count less than max_tokens to improve evaluation efficiency
|
||||||
|
count = 200 # Filter count outputs for each subset to improve evaluation efficiency
|
||||||
|
|
||||||
|
# Evaluate model thinking efficiency
|
||||||
|
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
|
||||||
|
```
|
||||||
|
|
||||||
|
The output will look like this, showing the model's token efficiency, thinking length, and number of sub-thought chains for each difficulty level:
|
||||||
|
|
||||||
|

|
||||||
|
*Figure 1: DeepSeek-R1-Distill-Qwen-7B Thinking Efficiency*
|
||||||
|
|
||||||
|
Using the same method, we also evaluated four other reasoning models—QwQ-32B, QwQ-32B-Preview, DeepSeek-R1, DeepSeek-R1-Distill-Qwen-32B—and one non-reasoning model, Qwen2.5-Math-7B-Instruct (treating all tokens in the model output as part of the thought process), to observe the performance of different types of models. The specific results are summarized as follows:
|
||||||
|
|
||||||
|

|
||||||
|
*Figure 2: Comparison of Thinking Efficiency of 6 Models*
|
||||||
|
|
||||||
|
Analyzing these line charts, we can draw some interesting conclusions:
|
||||||
|
|
||||||
|
- **Problem Difficulty vs. Model Performance**: As the problem difficulty increases, the accuracy of most models shows a downward trend, but QwQ-32B and DeepSeek-R1 perform exceptionally well, maintaining a high accuracy even on difficult problems, with QwQ-32B achieving the best performance at the highest difficulty level. Additionally, the output length for all models increases as problem difficulty rises, indicating that models require longer "thinking time" to solve more complex problems, consistent with the Inference-Time Scaling phenomenon.
|
||||||
|
- **Performance of O1/R1 Type Reasoning Models**:
|
||||||
|
- For O1/R1 reasoning models, as the problem difficulty increases, the output length stabilizes while token efficiency also improves (DeepSeek-R1 increases from 36% to 54%, QwQ-32B from 31% to 49%). This indicates that reasoning-type models consume tokens in a more "worthwhile" manner for more complex problems. Conversely, for relatively simple problems, there may be more unnecessary token wastage: even for simple problems, there may be unnecessary repeated validations of answers. QwQ-32B produced a higher number of output tokens compared to other models, allowing it to maintain a high accuracy rate even for Level 5 difficult problems, but on the other hand, it may indicate an issue of over-analysis.
|
||||||
|
- An interesting observation was noted: for problems at difficulty Level 4 and below, the number of sub-thought chains generated by the three models in the DeepSeek series remained relatively stable. However, at the challenging Level 5, there was a sudden significant increase in the number of sub-thought chains generated. This may be because Level 5 problems present a considerable challenge to these models, requiring multiple rounds of attempts and reasoning to arrive at solutions. In contrast, QwQ-32B and QwQ-32B-Preview exhibited a more uniform increase in the number of thought chains, which might reflect their differing strategies and capabilities in handling complex problems.
|
||||||
|
- **Performance of Non-Reasoning Models**: The accuracy of the non-reasoning model Qwen2.5-Math-7B-Instruct significantly decreased when dealing with high-difficulty math problems. Additionally, due to the lack of an in-depth thinking process, the output count of this model was only one-third that of reasoning models. It is evident from the graphs that specialized math models like Qwen2.5-Math-7B-Instruct outperform general reasoning models in terms of solving rates and resource consumption for ordinary problems, but as problem difficulty increases, the lack of a deep thinking process results in a more pronounced decline in model performance, exhibiting a clear "ceiling" effect.
|
||||||
|
|
||||||
|
## Tips
|
||||||
|
|
||||||
|
:::{card}
|
||||||
|
|
||||||
|
💡 During the writing of this best practice guide, I accumulated some insights to share:
|
||||||
|
|
||||||
|
1. **On the Definition of Thinking Efficiency Evaluation Metrics**:
|
||||||
|
- This article draws on the definitions of "overthinking" and "underthinking" from the literature[^1] and [^2], simplifying the Outcome Efficiency metric and proposing the token efficiency metric. However, this metric primarily focuses on the number of generated tokens and does not capture all the details of the model's thought process.
|
||||||
|
- The calculation of the number of sub-thought chains uses a heuristic approach, identifying common keywords predefined for this purpose. It should be noted that different models may require different sets of keywords to accurately capture their thinking processes.
|
||||||
|
|
||||||
|
2. **On the Applicability of the Metrics**:
|
||||||
|
- Currently, these metrics are primarily applied to mathematical reasoning datasets, and thus may not fully reflect model performance in other application scenarios. For example, in open-ended question-answering or scenarios requiring creative responses, these metrics may be insufficient.
|
||||||
|
|
||||||
|
3. **On the Calculation of the Token Efficiency Metric**:
|
||||||
|
- In the implementation process, we relied on an additional Judge model to assess the correctness of the model's reasoning steps. Referencing the work of ProcessBench[^4], this task is quite challenging for existing models and typically requires a strong model to make judgments.
|
||||||
|
- If the Judge model makes incorrect judgments, it may affect the accuracy of the token efficiency metric, which means careful consideration is needed when selecting the Judge model.
|
||||||
|
|
||||||
|
:::
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
This article evaluates the reasoning efficiency of several mainstream reasoning models, including QwQ-32B and DeepSeek-R1, based on the MATH-500 dataset. From the perspectives of "Token efficiency" and "Accuracy," we draw several noteworthy conclusions:
|
||||||
|
- The model's ability to "think deeply" shows a clear correlation with performance, as more difficult problems require a "deeper" thought process.
|
||||||
|
- Regarding reasoning efficiency evaluation, this article explores how to define quantifiable evaluation metrics based on related work on "overthinking" and "underthinking" and discusses the engineering implementation within the EvalScope framework.
|
||||||
|
- Evaluating the reasoning efficiency of models provides crucial reference significance for GRPO and SFT training processes, helping to develop models that are "more efficient" and capable of "adaptive reasoning" based on problem difficulty.
|
||||||
|
|
||||||
|
## References
|
||||||
|
|
||||||
|
[^1]: Wang, Y. et al. Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs. Preprint at https://doi.org/10.48550/arXiv.2501.18585 (2025).
|
||||||
|
[^2]: Chen, X. et al. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs. Preprint at https://doi.org/10.48550/arXiv.2412.21187 (2025).
|
||||||
|
[^3]: Think Less, Achieve More: Cut Reasoning Costs by 50% Without Sacrificing Accuracy. https://novasky-ai.github.io/posts/reduce-overthinking/.
|
||||||
|
[^4]: Zheng, C. et al. ProcessBench: Identifying Process Errors in Mathematical Reasoning. Preprint at https://doi.org/10.48550/arXiv.2412.06559(2024).
|
||||||
|
|
@ -0,0 +1,71 @@
|
||||||
|
(rag-evaluation)=
|
||||||
|
|
||||||
|
# RAG Evaluation Survey: Framework, Metrics, and Methods
|
||||||
|
|
||||||
|
## RAG (Retrieval-Augmented Generation) Process
|
||||||
|

|
||||||
|
|
||||||
|
## Framework
|
||||||
|
### 1. **LlamaIndex**
|
||||||
|
[Multimodal RAG Evaluation Tutorial](https://docs.llamaindex.ai/en/stable/examples/evaluation/multi_modal/multi_modal_rag_evaluation/)
|
||||||
|
|
||||||
|
> introduces how to evaluate multimodal retrieval-augmented generation (RAG) systems, focusing on how to use the evaluation tools in the llama-index library to assess the retriever and generator. It demonstrates how to load data, build an index, set up the RAG system, and conduct retrieval and generation evaluations using the American Sign Language (ASL) alphabet images and text descriptions as a case study.
|
||||||
|
|
||||||
|
### 2. **LangChain**
|
||||||
|
* [Multimodal (Image-Text) RAG Tutorial](https://github.com/langchain-ai/langchain/blob/master/cookbook/Multi_modal_RAG.ipynb)
|
||||||
|
|
||||||
|
* [Semi-structured (Image-Text-Table) Multimodal RAG Tutorial](https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_and_multi_modal_RAG.ipynb)
|
||||||
|
|
||||||
|
* Multi-modal RAG
|
||||||
|

|
||||||
|
|
||||||
|
### 3. **Ragas**
|
||||||
|
* [GitHub](https://github.com/explodinggradients/ragas)
|
||||||
|
* [Docs](https://docs.ragas.io/en/latest/getstarted/index.html)
|
||||||
|
* Tutorial: [Evaluating RAG Applications with RAGAs](https://towardsdatascience.com/evaluating-rag-applications-with-ragas-81d67b0ee31a)
|
||||||
|
|
||||||
|
> Introduction: RAGAs is an evaluation framework for assessing retrieval-augmented generation (RAG) applications, with its core goal being to provide a comprehensive set of evaluation metrics and methods to quantitatively assess the performance of the RAG pipeline at different component levels. RAGAs is particularly suitable for RAG systems that combine the two main components of retrieval and generation, supporting Langchain and Llama-Index.
|
||||||
|
|
||||||
|
* **Evaluation Process**
|
||||||
|
1. Start: Initiate the process of preparing and setting up the RAG application.
|
||||||
|
2. Data Preparation: Load and chunk the documents.
|
||||||
|
3. Set Up Vector Database: Generate vector embeddings and store them in a vector database.
|
||||||
|
4. Set Up Retriever Component: Set up the retriever based on the vector database.
|
||||||
|
5. Combine RAG Pipeline: Combine the retriever, prompt templates, and LLM to form the RAG pipeline.
|
||||||
|
6. Prepare Evaluation Data: Prepare questions and corresponding true answers.
|
||||||
|
7. Build Dataset: Prepare data through inference and build a dataset for evaluation.
|
||||||
|
8. Evaluate RAG Application: Import evaluation metrics and evaluate the RAG application.
|
||||||
|
9. End: Complete the evaluation process.
|
||||||
|
|
||||||
|
* **Evaluation System**
|
||||||
|
* No-reference Evaluation: RAGAs was initially designed as a "no-reference" evaluation framework, meaning it does not rely on human-annotated true labels but instead uses large language models (LLMs) for evaluation.
|
||||||
|
* Component-Level Evaluation: RAGAs allows for separate evaluation of the two main components of the RAG pipeline—the retriever and the generator. This separated evaluation approach helps to precisely identify performance bottlenecks in the pipeline.
|
||||||
|
* Comprehensive Evaluation Metrics: RAGAs provides a range of evaluation metrics, including Context Precision, Context Recall, Faithfulness, and Answer Relevancy. These metrics together form the RAGAs score, used to comprehensively assess the performance of the RAG pipeline.
|
||||||
|
|
||||||
|
### 4. **RAGChecker**
|
||||||
|
* [GitHub](https://github.com/amazon-science/RAGChecker)
|
||||||
|
> Introduction: RAGChecker is an advanced automatic evaluation framework designed to evaluate and diagnose retrieval-augmented generation (RAG) systems. It offers a comprehensive set of metrics and tools for in-depth analysis of RAG performance. The framework includes overall evaluation, diagnostic metrics, fine-grained evaluation, benchmark datasets, and meta-evaluation.
|
||||||
|
|
||||||
|
### 5. **TruLens**
|
||||||
|
* [GitHub](https://github.com/truera/trulens)
|
||||||
|
* [Docs](https://www.trulens.org/trulens/getting_started/quickstarts/quickstart/)
|
||||||
|
> Introduction: After developers build a prototype, they can monitor and record with TruLens, specify the desired feedback, and iterate and compare application versions in the user interface, supporting Langchain and Llama-Index.
|
||||||
|
|
||||||
|
### 6. **FlagEmbedding**
|
||||||
|
* [GitHub](https://github.com/FlagOpen/FlagEmbedding)
|
||||||
|
* Tutorial: [Evaluation Tutorial](https://github.com/FlagOpen/FlagEmbedding/blob/master/Tutorials/4_Evaluation).
|
||||||
|
> Introduction: FlagEmbedding is a project focused on retrieval-augmented large language models (LLMs), including several sub-projects such as long-text LLM, fine-tuned LM, embedding models, re-ranking models, and benchmarking. However, it does not provide an evaluation framework.
|
||||||
|
|
||||||
|
|
||||||
|
### 7. **Continuous Eval**
|
||||||
|
* [GitHub](https://github.com/relari-ai/continuous-eval)
|
||||||
|
> Introduction: continuous-eval is an open-source software package designed to provide data-driven evaluation for applications based on large language models (LLMs). It supports fine-grained evaluation of LLM applications through modular evaluation, comprehensive metric libraries, leveraging user feedback, synthetic dataset generation, and more. The tool also supports custom metrics and batch processing optimization, as well as synthetic dataset generation through Relari Cloud.
|
||||||
|
|
||||||
|
## Related Articles
|
||||||
|
* [Awesome-RAG-Evaluation](https://github.com/YHPeter/Awesome-RAG-Evaluation/blob/main/README_cn.md)
|
||||||
|
|
||||||
|
* [RAG Survey Interpretation](https://zhuanlan.zhihu.com/p/673392898)
|
||||||
|
|
||||||
|
* [Excerpts from Popular RAG Articles](https://zhuanlan.zhihu.com/p/673392898)
|
||||||
|
|
||||||
|
* [RAG Survey](https://arxiv.org/abs/2312.10997): Retrieval-Augmented Generation for Large Language Models: A Survey
|
||||||
{kind=link}
|
After Width: | Height: | Size: 62 KiB |
{kind=link}
|
After Width: | Height: | Size: 126 KiB |
|
|
@ -0,0 +1,16 @@
|
||||||
|

|
||||||
|
<br>
|
||||||
|
|
||||||
|
# Welcome to the EvalScope Blogs!
|
||||||
|
|
||||||
|
:::{toctree}
|
||||||
|
:hidden:
|
||||||
|
RAG/RAG_Evaluation.md
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{card} RAG Evaluation Survey: Framework, Metrics, and Methods
|
||||||
|
:link: rag-evaluation
|
||||||
|
:link-type: ref
|
||||||
|
|
||||||
|
This research introduces how to evaluate (multi-modal) RAG frameworks, divided into independent evaluation and end-to-end evaluation.
|
||||||
|
:::
|
||||||
|
|
@ -0,0 +1,155 @@
|
||||||
|
# Configuration file for the Sphinx documentation builder.
|
||||||
|
#
|
||||||
|
# For the full list of built-in configuration values, see the documentation:
|
||||||
|
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
||||||
|
|
||||||
|
# -- Project information -----------------------------------------------------
|
||||||
|
# https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
|
||||||
|
|
||||||
|
from dataclasses import asdict
|
||||||
|
from sphinxawesome_theme import ThemeOptions
|
||||||
|
|
||||||
|
project = 'EvalScope'
|
||||||
|
copyright = '2022-2024, Alibaba ModelScope'
|
||||||
|
author = 'ModelScope Authors'
|
||||||
|
version_file = '../../evalscope/version.py'
|
||||||
|
|
||||||
|
|
||||||
|
def get_version():
|
||||||
|
with open(version_file, 'r', encoding='utf-8') as f:
|
||||||
|
exec(compile(f.read(), version_file, 'exec'))
|
||||||
|
return locals()['__version__']
|
||||||
|
|
||||||
|
|
||||||
|
# The full version, including alpha/beta/rc tags
|
||||||
|
version = get_version()
|
||||||
|
release = version
|
||||||
|
|
||||||
|
# -- General configuration ---------------------------------------------------
|
||||||
|
# https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
|
||||||
|
|
||||||
|
extensions = [
|
||||||
|
'sphinx.ext.napoleon',
|
||||||
|
'sphinx.ext.autosummary',
|
||||||
|
'sphinx.ext.autodoc',
|
||||||
|
'sphinx.ext.viewcode',
|
||||||
|
'sphinx_design',
|
||||||
|
'myst_parser',
|
||||||
|
]
|
||||||
|
|
||||||
|
# build the templated autosummary files
|
||||||
|
autosummary_generate = True
|
||||||
|
numpydoc_show_class_members = False
|
||||||
|
|
||||||
|
# Enable overriding of function signatures in the first line of the docstring.
|
||||||
|
autodoc_docstring_signature = True
|
||||||
|
|
||||||
|
# Disable docstring inheritance
|
||||||
|
autodoc_inherit_docstrings = False
|
||||||
|
|
||||||
|
# Show type hints in the description
|
||||||
|
autodoc_typehints = 'description'
|
||||||
|
|
||||||
|
# Add parameter types if the parameter is documented in the docstring
|
||||||
|
autodoc_typehints_description_target = 'documented_params'
|
||||||
|
|
||||||
|
autodoc_default_options = {
|
||||||
|
'member-order': 'bysource',
|
||||||
|
}
|
||||||
|
|
||||||
|
templates_path = ['_templates']
|
||||||
|
exclude_patterns = []
|
||||||
|
|
||||||
|
language = 'en'
|
||||||
|
|
||||||
|
# The master toctree document.
|
||||||
|
root_doc = 'index'
|
||||||
|
|
||||||
|
# List of patterns, relative to source directory, that match files and
|
||||||
|
# directories to ignore when looking for source files.
|
||||||
|
# This pattern also affects html_static_path and html_extra_path.
|
||||||
|
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
||||||
|
|
||||||
|
# The suffix(es) of source filenames.
|
||||||
|
# You can specify multiple suffix as a list of string:
|
||||||
|
#
|
||||||
|
source_suffix = ['.rst', '.md']
|
||||||
|
|
||||||
|
# -- Options for HTML output -------------------------------------------------
|
||||||
|
# https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
|
||||||
|
|
||||||
|
html_title = 'EvalScope'
|
||||||
|
html_theme = 'sphinxawesome_theme'
|
||||||
|
html_static_path = ['_static']
|
||||||
|
html_favicon = './_static/images/evalscope_icon.svg'
|
||||||
|
html_permalinks_icon = '<span>#</span>'
|
||||||
|
html_sidebars: dict[str, list[str]] = {
|
||||||
|
'blog/**': ['sidebar_main_nav_links.html'],
|
||||||
|
}
|
||||||
|
|
||||||
|
pygments_style = 'default'
|
||||||
|
pygments_style_dark = 'one-dark'
|
||||||
|
# -- Extension configuration -------------------------------------------------
|
||||||
|
|
||||||
|
# Auto-generated header anchors
|
||||||
|
myst_heading_anchors = 3
|
||||||
|
# Enable "colon_fence" extension of myst.
|
||||||
|
myst_enable_extensions = ['colon_fence', 'dollarmath']
|
||||||
|
|
||||||
|
napoleon_custom_sections = [
|
||||||
|
# Custom sections for data elements.
|
||||||
|
('Meta fields', 'params_style'),
|
||||||
|
('Data fields', 'params_style'),
|
||||||
|
]
|
||||||
|
|
||||||
|
theme_options = ThemeOptions(
|
||||||
|
awesome_external_links=True,
|
||||||
|
show_scrolltop=True,
|
||||||
|
main_nav_links={
|
||||||
|
'Docs': 'index',
|
||||||
|
'Blogs': 'blog/index'
|
||||||
|
},
|
||||||
|
logo_light='./_static/images/evalscope_icon.png',
|
||||||
|
logo_dark='./_static/images/evalscope_icon_dark.png',
|
||||||
|
extra_header_link_icons={
|
||||||
|
'language': {
|
||||||
|
'link':
|
||||||
|
'https://evalscope.readthedocs.io/zh-cn/latest/index.html',
|
||||||
|
'icon':
|
||||||
|
"""
|
||||||
|
<svg height="25px" style="margin-top:-2px;display:inline" viewBox="0 0 16 16" fill="currentColor" xmlns="http://www.w3.org/2000/svg">
|
||||||
|
<path fill-rule="evenodd" clip-rule="evenodd" d="M4 0H6V2H10V4H8.86807C8.57073 5.66996 7.78574 7.17117 6.6656 8.35112C7.46567 8.73941 8.35737 8.96842 9.29948 8.99697L10.2735 6H12.7265L15.9765 16H13.8735L13.2235 14H9.77647L9.12647 16H7.0235L8.66176 10.9592C7.32639 10.8285 6.08165 10.3888 4.99999 9.71246C3.69496 10.5284 2.15255 11 0.5 11H0V9H0.5C1.5161 9 2.47775 8.76685 3.33437 8.35112C2.68381 7.66582 2.14629 6.87215 1.75171 6H4.02179C4.30023 6.43491 4.62904 6.83446 4.99999 7.19044C5.88743 6.33881 6.53369 5.23777 6.82607 4H0V2H4V0ZM12.5735 12L11.5 8.69688L10.4265 12H12.5735Z" fill="currentColor"/>
|
||||||
|
</svg>
|
||||||
|
"""
|
||||||
|
},
|
||||||
|
'github': {
|
||||||
|
'link':
|
||||||
|
'https://github.com/modelscope/evalscope',
|
||||||
|
'icon': (
|
||||||
|
'<svg height="26px" style="margin-top:-2px;display:inline" '
|
||||||
|
'viewBox="0 0 45 44" '
|
||||||
|
'fill="currentColor" xmlns="http://www.w3.org/2000/svg">'
|
||||||
|
'<path fill-rule="evenodd" clip-rule="evenodd" '
|
||||||
|
'd="M22.477.927C10.485.927.76 10.65.76 22.647c0 9.596 6.223 17.736 '
|
||||||
|
'14.853 20.608 1.087.2 1.483-.47 1.483-1.047 '
|
||||||
|
'0-.516-.019-1.881-.03-3.693-6.04 '
|
||||||
|
'1.312-7.315-2.912-7.315-2.912-.988-2.51-2.412-3.178-2.412-3.178-1.972-1.346.149-1.32.149-1.32 ' # noqa
|
||||||
|
'2.18.154 3.327 2.24 3.327 2.24 1.937 3.318 5.084 2.36 6.321 '
|
||||||
|
'1.803.197-1.403.759-2.36 '
|
||||||
|
'1.379-2.903-4.823-.548-9.894-2.412-9.894-10.734 '
|
||||||
|
'0-2.37.847-4.31 2.236-5.828-.224-.55-.969-2.759.214-5.748 0 0 '
|
||||||
|
'1.822-.584 5.972 2.226 '
|
||||||
|
'1.732-.482 3.59-.722 5.437-.732 1.845.01 3.703.25 5.437.732 '
|
||||||
|
'4.147-2.81 5.967-2.226 '
|
||||||
|
'5.967-2.226 1.185 2.99.44 5.198.217 5.748 1.392 1.517 2.232 3.457 '
|
||||||
|
'2.232 5.828 0 '
|
||||||
|
'8.344-5.078 10.18-9.916 10.717.779.67 1.474 1.996 1.474 4.021 0 '
|
||||||
|
'2.904-.027 5.247-.027 '
|
||||||
|
'5.96 0 .58.392 1.256 1.493 1.044C37.981 40.375 44.2 32.24 44.2 '
|
||||||
|
'22.647c0-11.996-9.726-21.72-21.722-21.72" '
|
||||||
|
'fill="currentColor"/></svg>'),
|
||||||
|
},
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
html_theme_options = asdict(theme_options)
|
||||||
|
|
@ -0,0 +1,9 @@
|
||||||
|
# Benchmarking
|
||||||
|
|
||||||
|
Here are the benchmarking results for some models:
|
||||||
|
|
||||||
|
:::{toctree}
|
||||||
|
:maxdepth: 1
|
||||||
|
|
||||||
|
mmlu.md
|
||||||
|
:::
|
||||||
|
|
@ -0,0 +1,42 @@
|
||||||
|
# MMLU
|
||||||
|
|
||||||
|
> This is a large-scale multi-task assessment comprised of multiple-choice questions from various knowledge domains. The test covers humanities, social sciences, hard sciences, and other significant areas of study, encompassing 57 tasks, including basic mathematics, American history, computer science, law, among others. To achieve a high accuracy rate on this test, models must possess a broad knowledge of the world and problem-solving abilities. [Dataset Link](https://modelscope.cn/datasets/modelscope/mmlu/summary)
|
||||||
|
|
||||||
|
## Experimental Setup
|
||||||
|
|
||||||
|
- Split: test
|
||||||
|
- Total number: 13985
|
||||||
|
- 0-shot
|
||||||
|
|
||||||
|
## Experimental Results
|
||||||
|
|
||||||
|
| Model | Revision | Precision | Humanities | STEM | Social Science | Other | Weighted Avg | Target | Delta |
|
||||||
|
|--------------------------------------------------------------------------------------------------|----------|-----------|-------------|------------|----------------|---------|--------------|-------------|--------|
|
||||||
|
| [Baichuan2-7B-Base](https://modelscope.cn/models/baichuan-inc/Baichuan2-7B-Base/summary) | v1.0.2 | fp16 | 0.4111 | 0.3807 | 0.5233 | 0.504 | 0.4506 | - | |
|
||||||
|
| [Baichuan2-7B-Chat](https://modelscope.cn/models/baichuan-inc/Baichuan2-7B-chat/summary) | v1.0.4 | fp16 | 0.4439 | 0.374 | 0.5524 | 0.5458 | 0.4762 | - | |
|
||||||
|
| [chatglm2-6b](https://modelscope.cn/models/ZhipuAI/chatglm2-6b/summary) | v1.0.12 | fp16 | 0.3834 | 0.3413 | 0.4708 | 0.4445 | 0.4077 | 0.4546 (CoT) | -4.69% |
|
||||||
|
| [chatglm3-6b-base](https://modelscope.cn/models/ZhipuAI/chatglm3-6b-base/summary) | v1.0.1 | fp16 | 0.5435 | 0.5087 | 0.7227 | 0.6471 | 0.5992 | 0.614 | -1.48% |
|
||||||
|
| [internlm-chat-7b](https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm-chat-7b/summary) | v1.0.1 | fp16 | 0.4005 | 0.3547 | 0.4953 | 0.4796 | 0.4297 | - | |
|
||||||
|
| [Llama-2-13b-ms](https://modelscope.cn/models/modelscope/Llama-2-13b-ms/summary) | v1.0.2 | fp16 | 0.4371 | 0.3887 | 0.5579 | 0.5437 | 0.4778 | - | |
|
||||||
|
| [Llama-2-7b-ms](https://modelscope.cn/models/modelscope/Llama-2-7b-ms/summary) | v1.0.2 | fp16 | 0.3146 | 0.3037 | 0.4134 | 0.3885 | 0.3509 | - | |
|
||||||
|
| [Qwen-14B-Chat](https://modelscope.cn/models/qwen/Qwen-14B-Chat/summary) | v1.0.6 | bf16 | 0.5326 | 0.5397 | 0.7184 | 0.6859 | 0.6102 | - | |
|
||||||
|
| [Qwen-7B](https://modelscope.cn/models/qwen/Qwen-7B/summary) | v1.1.6 | bf16 | 0.387 | 0.4 | 0.5403 | 0.5139 | 0.4527 | - | |
|
||||||
|
| [Qwen-7B-Chat-Int8](https://modelscope.cn/models/qwen/Qwen-7B-Chat-Int8/summary) | v1.1.6 | int8 | 0.4322 | 0.4277 | 0.6088 | 0.5778 | 0.5035 | - | |
|
||||||
|
|
||||||
|
- Target -- The official declared score of the model on the dataset
|
||||||
|
- Delta -- The difference between the weighted average score and the target score
|
||||||
|
|
||||||
|
### Settings: (Split: test, Total number: 13985, 5-shot)
|
||||||
|
|
||||||
|
| Model | Revision | Precision | Humanities | STEM | Social Science | Other | Weighted Avg | Avg | Target | Delta |
|
||||||
|
|---------------------|----------|-----------|------------|--------|----------------|--------|--------------|--------|--------------------|---------|
|
||||||
|
| Baichuan2-7B-Base | v1.0.2 | fp16 | 0.4295 | 0.398 | 0.5736 | 0.5325 | 0.4781 | 0.4918 | 0.5416 (official) | -4.98% |
|
||||||
|
| Baichuan2-7B-Chat | v1.0.4 | fp16 | 0.4344 | 0.3937 | 0.5814 | 0.5462 | 0.4837 | 0.5029 | 0.5293 (official) | -2.64% |
|
||||||
|
| chatglm2-6b | v1.0.12 | fp16 | 0.3941 | 0.376 | 0.4897 | 0.4706 | 0.4288 | 0.4442 | - | - |
|
||||||
|
| chatglm3-6b-base | v1.0.1 | fp16 | 0.5356 | 0.4847 | 0.7175 | 0.6273 | 0.5857 | 0.5995 | - | - |
|
||||||
|
| internlm-chat-7b | v1.0.1 | fp16 | 0.4171 | 0.3903 | 0.5772 | 0.5493 | 0.4769 | 0.4876 | - | - |
|
||||||
|
| Llama-2-13b-ms | v1.0.2 | fp16 | 0.484 | 0.4133 | 0.6157 | 0.5809 | 0.5201 | 0.5327 | 0.548 (official) | -1.53% |
|
||||||
|
| Llama-2-7b-ms | v1.0.2 | fp16 | 0.3747 | 0.3363 | 0.4372 | 0.4514 | 0.3979 | 0.4089 | 0.453 (official) | -4.41% |
|
||||||
|
| Qwen-14B-Chat | v1.0.6 | bf16 | 0.574 | 0.553 | 0.7403 | 0.684 | 0.6313 | 0.6414 | 0.646 (official) | -0.46% |
|
||||||
|
| Qwen-7B | v1.1.6 | bf16 | 0.4587 | 0.426 | 0.6078 | 0.5629 | 0.5084 | 0.5151 | 0.567 (official) | -5.2% |
|
||||||
|
| Qwen-7B-Chat-Int8 | v1.1.6 | int8 | 0.4697 | 0.4383 | 0.6284 | 0.5967 | 0.5271 | 0.5347 | 0.554 (official) | -1.93% |
|
||||||
|
|
@ -0,0 +1,83 @@
|
||||||
|
# QwQ-32B-Preview
|
||||||
|
|
||||||
|
> QwQ-32B-Preview is an experimental research model developed by the Qwen team, aimed at enhancing the reasoning capabilities of artificial intelligence. [Model Link](https://modelscope.cn/models/Qwen/QwQ-32B-Preview/summary)
|
||||||
|
|
||||||
|
The Speed Benchmark tool was used to test the GPU memory usage and inference speed of the QwQ-32B-Preview model under different configurations. The following tests measure the speed and memory usage when generating 2048 tokens, with input lengths of 1, 6144, 14336, and 30720:
|
||||||
|
|
||||||
|
## Local Transformers Inference Speed
|
||||||
|
|
||||||
|
### Test Environment
|
||||||
|
|
||||||
|
- NVIDIA A100 80GB * 1
|
||||||
|
- CUDA 12.1
|
||||||
|
- Pytorch 2.3.1
|
||||||
|
- Flash Attention 2.5.8
|
||||||
|
- Transformers 4.46.0
|
||||||
|
- EvalScope 0.7.0
|
||||||
|
|
||||||
|
|
||||||
|
### Stress Testing Command
|
||||||
|
```shell
|
||||||
|
pip install evalscope[perf] -U
|
||||||
|
```
|
||||||
|
```shell
|
||||||
|
CUDA_VISIBLE_DEVICES=0 evalscope perf \
|
||||||
|
--parallel 1 \
|
||||||
|
--model Qwen/QwQ-32B-Preview \
|
||||||
|
--attn-implementation flash_attention_2 \
|
||||||
|
--log-every-n-query 1 \
|
||||||
|
--connect-timeout 60000 \
|
||||||
|
--read-timeout 60000\
|
||||||
|
--max-tokens 2048 \
|
||||||
|
--min-tokens 2048 \
|
||||||
|
--api local \
|
||||||
|
--dataset speed_benchmark
|
||||||
|
```
|
||||||
|
|
||||||
|
### Test Results
|
||||||
|
```text
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
| Prompt Tokens | Speed(tokens/s) | GPU Memory(GB) |
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
| 1 | 17.92 | 61.58 |
|
||||||
|
| 6144 | 12.61 | 63.72 |
|
||||||
|
| 14336 | 9.01 | 67.31 |
|
||||||
|
| 30720 | 5.61 | 74.47 |
|
||||||
|
+---------------+-----------------+----------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
## vLLM Inference Speed
|
||||||
|
|
||||||
|
### Test Environment
|
||||||
|
- NVIDIA A100 80GB * 2
|
||||||
|
- CUDA 12.1
|
||||||
|
- vLLM 0.6.3
|
||||||
|
- Pytorch 2.4.0
|
||||||
|
- Flash Attention 2.6.3
|
||||||
|
- Transformers 4.46.0
|
||||||
|
|
||||||
|
### Test Command
|
||||||
|
```shell
|
||||||
|
CUDA_VISIBLE_DEVICES=0,1 evalscope perf \
|
||||||
|
--parallel 1 \
|
||||||
|
--model Qwen/QwQ-32B-Preview \
|
||||||
|
--log-every-n-query 1 \
|
||||||
|
--connect-timeout 60000 \
|
||||||
|
--read-timeout 60000\
|
||||||
|
--max-tokens 2048 \
|
||||||
|
--min-tokens 2048 \
|
||||||
|
--api local_vllm \
|
||||||
|
--dataset speed_benchmark
|
||||||
|
```
|
||||||
|
|
||||||
|
### Test Results
|
||||||
|
```text
|
||||||
|
+---------------+-----------------+
|
||||||
|
| Prompt Tokens | Speed(tokens/s) |
|
||||||
|
+---------------+-----------------+
|
||||||
|
| 1 | 38.17 |
|
||||||
|
| 6144 | 36.63 |
|
||||||
|
| 14336 | 35.01 |
|
||||||
|
| 30720 | 31.68 |
|
||||||
|
+---------------+-----------------+
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,9 @@
|
||||||
|
# Speed Benchmarking
|
||||||
|
|
||||||
|
Here are the speed benchmarking results for some models:
|
||||||
|
|
||||||
|
:::{toctree}
|
||||||
|
:maxdepth: 1
|
||||||
|
|
||||||
|
QwQ-32B-Preview.md
|
||||||
|
:::
|
||||||
|
|
@ -0,0 +1,301 @@
|
||||||
|
# Basic Usage
|
||||||
|
|
||||||
|
## Simple Evaluation
|
||||||
|
Evaluate a model on specified datasets using default configurations. This framework supports two ways to initiate evaluation tasks: via command line or using Python code.
|
||||||
|
|
||||||
|
### Method 1. Using Command Line
|
||||||
|
|
||||||
|
::::{tab-set}
|
||||||
|
:::{tab-item} Use the `eval` command
|
||||||
|
|
||||||
|
Execute the `eval` command from any directory:
|
||||||
|
```bash
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen2.5-0.5B-Instruct \
|
||||||
|
--datasets gsm8k arc \
|
||||||
|
--limit 5
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{tab-item} Run `run.py`
|
||||||
|
|
||||||
|
Execute from the `evalscope` root directory:
|
||||||
|
```bash
|
||||||
|
python evalscope/run.py \
|
||||||
|
--model Qwen/Qwen2.5-0.5B-Instruct \
|
||||||
|
--datasets gsm8k arc \
|
||||||
|
--limit 5
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
::::
|
||||||
|
|
||||||
|
### Method 2. Using Python Code
|
||||||
|
|
||||||
|
When using Python code for evaluation, submit the evaluation task with the `run_task` function by passing in a `TaskConfig` as a parameter. It can also be a Python dictionary, a YAML file path, or a JSON file path, for example:
|
||||||
|
|
||||||
|
::::{tab-set}
|
||||||
|
:::{tab-item} Using Python Dictionary
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
task_cfg = {
|
||||||
|
'model': 'Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
'datasets': ['gsm8k', 'arc'],
|
||||||
|
'limit': 5
|
||||||
|
}
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{tab-item} Using `TaskConfig`
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
from evalscope.config import TaskConfig
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='Qwen/Qwen2.5-0.5B-Instruct',
|
||||||
|
datasets=['gsm8k', 'arc'],
|
||||||
|
limit=5
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{tab-item} Using `yaml` file
|
||||||
|
|
||||||
|
```{code-block} yaml
|
||||||
|
:caption: config.yaml
|
||||||
|
|
||||||
|
model: Qwen/Qwen2.5-0.5B-Instruct
|
||||||
|
datasets:
|
||||||
|
- gsm8k
|
||||||
|
- arc
|
||||||
|
limit: 5
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg="config.yaml")
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
:::{tab-item} Using `json` file
|
||||||
|
|
||||||
|
```{code-block} json
|
||||||
|
:caption: config.json
|
||||||
|
|
||||||
|
{
|
||||||
|
"model": "Qwen/Qwen2.5-0.5B-Instruct",
|
||||||
|
"datasets": ["gsm8k", "arc"],
|
||||||
|
"limit": 5
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
run_task(task_cfg="config.json")
|
||||||
|
```
|
||||||
|
:::
|
||||||
|
|
||||||
|
::::
|
||||||
|
|
||||||
|
|
||||||
|
### Basic Parameter Descriptions
|
||||||
|
- `--model`: Specifies the `model_id` of the model in [ModelScope](https://modelscope.cn/), which can be automatically downloaded, for example, [Qwen/Qwen2.5-0.5B-Instruct](https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct/summary); it can also be a local path to the model, e.g., `/path/to/model`.
|
||||||
|
- `--datasets`: Dataset names, supporting multiple datasets separated by spaces. Datasets will be automatically downloaded from ModelScope; refer to the [Dataset List](./supported_dataset/llm.md) for supported datasets.
|
||||||
|
- `--limit`: Maximum amount of evaluation data per dataset. If not specified, it defaults to evaluating all data, which can be used for quick validation.
|
||||||
|
|
||||||
|
|
||||||
|
**Output Results**
|
||||||
|
|
||||||
|
```text
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Model Name | Dataset Name | Metric Name | Category Name | Subset Name | Num | Score |
|
||||||
|
+=======================+================+=================+=================+===============+=======+=========+
|
||||||
|
| Qwen2.5-0.5B-Instruct | gsm8k | AverageAccuracy | default | main | 5 | 0.4 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Easy | 5 | 0.8 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Challenge | 5 | 0.4 |
|
||||||
|
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Complex Evaluation
|
||||||
|
|
||||||
|
If you wish to conduct more customized evaluations, such as customizing model parameters or dataset parameters, you can use the following command. The evaluation method is the same as simple evaluation, and below is an example of starting the evaluation using the `eval` command:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope eval \
|
||||||
|
--model Qwen/Qwen3-0.6B \
|
||||||
|
--model-args '{"revision": "master", "precision": "torch.float16", "device_map": "auto"}' \
|
||||||
|
--generation-config '{"do_sample":true,"temperature":0.6,"max_new_tokens":512,"chat_template_kwargs":{"enable_thinking": false}}' \
|
||||||
|
--dataset-args '{"gsm8k": {"few_shot_num": 0, "few_shot_random": false}}' \
|
||||||
|
--datasets gsm8k \
|
||||||
|
--limit 10
|
||||||
|
```
|
||||||
|
|
||||||
|
### Parameter Description
|
||||||
|
- `--model-args`: Model loading parameters, passed as a JSON string:
|
||||||
|
- `revision`: Model version
|
||||||
|
- `precision`: Model precision
|
||||||
|
- `device_map`: Device allocation for the model
|
||||||
|
- `--generation-config`: Generation parameters, passed as a JSON string and parsed as a dictionary:
|
||||||
|
- `do_sample`: Whether to use sampling
|
||||||
|
- `temperature`: Generation temperature
|
||||||
|
- `max_new_tokens`: Maximum length of generated tokens
|
||||||
|
- `chat_template_kwargs`: Model inference template parameters
|
||||||
|
- `--dataset-args`: Settings for the evaluation dataset, passed as a JSON string where the key is the dataset name and the value is the parameters. Note that these need to correspond one-to-one with the values in the `--datasets` parameter:
|
||||||
|
- `few_shot_num`: Number of few-shot examples
|
||||||
|
- `few_shot_random`: Whether to randomly sample few-shot data; if not set, defaults to `true`
|
||||||
|
|
||||||
|
|
||||||
|
**Output Results**
|
||||||
|
|
||||||
|
```text
|
||||||
|
+------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|
||||||
|
+============+===========+=================+==========+=======+=========+=========+
|
||||||
|
| Qwen3-0.6B | gsm8k | AverageAccuracy | main | 10 | 0.3 | default |
|
||||||
|
+------------+-----------+-----------------+----------+-------+---------+---------+
|
||||||
|
```
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
Reference: [Full Parameter Description](parameters.md)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Model API Service Evaluation
|
||||||
|
|
||||||
|
Specify the model API service address (api_url) and API Key (api_key) to evaluate the deployed model API service. In this case, the `eval-type` parameter must be specified as `service`, for example:
|
||||||
|
|
||||||
|
For example, to launch a model service using [vLLM](https://github.com/vllm-project/vllm):
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export VLLM_USE_MODELSCOPE=True && python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-0.5B-Instruct --served-model-name qwen2.5 --trust_remote_code --port 8801
|
||||||
|
```
|
||||||
|
Then, you can use the following command to evaluate the model API service:
|
||||||
|
```shell
|
||||||
|
evalscope eval \
|
||||||
|
--model qwen2.5 \
|
||||||
|
--api-url http://127.0.0.1:8801/v1 \
|
||||||
|
--api-key EMPTY \
|
||||||
|
--eval-type service \
|
||||||
|
--datasets gsm8k \
|
||||||
|
--limit 10
|
||||||
|
```
|
||||||
|
|
||||||
|
## Using the Judge Model
|
||||||
|
|
||||||
|
During evaluation, the judge model can be used to assess the output of a model. Some datasets require the use of a judge model for evaluation, such as the `simple_qa` dataset. Use the following command to start the evaluation:
|
||||||
|
|
||||||
|
```python
|
||||||
|
from evalscope import TaskConfig, run_task
|
||||||
|
from evalscope.constants import EvalType, JudgeStrategy
|
||||||
|
|
||||||
|
task_cfg = TaskConfig(
|
||||||
|
model='qwen2.5-7b-instruct',
|
||||||
|
api_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
|
||||||
|
api_key=os.getenv('DASHSCOPE_API_KEY'),
|
||||||
|
eval_type=EvalType.SERVICE,
|
||||||
|
datasets=[
|
||||||
|
# 'simple_qa',
|
||||||
|
'chinese_simpleqa',
|
||||||
|
],
|
||||||
|
eval_batch_size=5,
|
||||||
|
limit=5,
|
||||||
|
judge_strategy=JudgeStrategy.AUTO,
|
||||||
|
judge_model_args={
|
||||||
|
'model_id': 'qwen2.5-72b-instruct',
|
||||||
|
'api_url': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
|
||||||
|
'api_key': os.getenv('DASHSCOPE_API_KEY'),
|
||||||
|
}
|
||||||
|
)
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
See also: [Judge Model Parameters](./parameters.md#judge-parameters)
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
## Using Local Datasets and Models
|
||||||
|
|
||||||
|
By default, datasets are hosted on [ModelScope](https://modelscope.cn/datasets) and require internet access for loading. If you are in an offline environment, you can use local datasets. The process is as follows:
|
||||||
|
|
||||||
|
Assume the current local working path is `/path/to/workdir`.
|
||||||
|
|
||||||
|
### Download Dataset to Local
|
||||||
|
|
||||||
|
```{important}
|
||||||
|
Before downloading the dataset, please confirm whether the dataset you want to use is stored in a `zip` file or available on modelscope.
|
||||||
|
```
|
||||||
|
|
||||||
|
#### Download Zip Dataset
|
||||||
|
|
||||||
|
Due to historical reasons, some datasets are loaded by executing Python scripts. We have organized these datasets into a `zip` file, which includes the following datasets:
|
||||||
|
```text
|
||||||
|
.
|
||||||
|
├── arc
|
||||||
|
├── bbh
|
||||||
|
├── ceval
|
||||||
|
├── cmmlu
|
||||||
|
├── competition_math
|
||||||
|
├── general_qa
|
||||||
|
├── gsm8k
|
||||||
|
├── hellaswag
|
||||||
|
├── humaneval
|
||||||
|
├── mmlu
|
||||||
|
├── race
|
||||||
|
├── trivia_qa
|
||||||
|
└── truthful_qa
|
||||||
|
```
|
||||||
|
|
||||||
|
For these datasets, execute the following commands:
|
||||||
|
```shell
|
||||||
|
wget https://modelscope.oss-cn-beijing.aliyuncs.com/open_data/benchmark/data.zip
|
||||||
|
unzip data.zip
|
||||||
|
```
|
||||||
|
The unzipped datasets will be located in the `/path/to/workdir/data` directory, which will be used as the value for the `local_path` parameter in subsequent steps.
|
||||||
|
|
||||||
|
#### Download Modelscope Dataset
|
||||||
|
|
||||||
|
For datasets that are not in a `zip` file, such as the [mmlu_pro](https://modelscope.cn/datasets/modelscope/MMLU-Pro) dataset, refer to the dataset address in the [Supported Datasets](./supported_dataset/llm.md) document and execute the following commands:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
git lfs install
|
||||||
|
git clone https://www.modelscope.cn/datasets/modelscope/MMLU-Pro.git
|
||||||
|
```
|
||||||
|
|
||||||
|
Use the directory `/path/to/MMLU-Pro` as the value for the `local_path` parameter.
|
||||||
|
|
||||||
|
|
||||||
|
### Download the Model Locally
|
||||||
|
Model files are hosted on the ModelScope Hub and require internet access for loading. If you need to create evaluation tasks in an offline environment, you can download the model to your local machine in advance:
|
||||||
|
|
||||||
|
For example, use Git to download the Qwen2.5-0.5B-Instruct model locally:
|
||||||
|
```bash
|
||||||
|
git lfs install
|
||||||
|
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
|
||||||
|
```
|
||||||
|
|
||||||
|
```{seealso}
|
||||||
|
[ModelScope Model Download Guide](https://modelscope.cn/docs/models/download)
|
||||||
|
```
|
||||||
|
|
||||||
|
### Execute Evaluation Task
|
||||||
|
Run the following command to perform the evaluation, passing in the local dataset path and model path. Note that `local_path` must correspond one-to-one with the values in the `--datasets` parameter:
|
||||||
|
|
||||||
|
```shell
|
||||||
|
evalscope eval \
|
||||||
|
--model /path/to/workdir/Qwen2.5-0.5B-Instruct \
|
||||||
|
--datasets arc \
|
||||||
|
--dataset-args '{"arc": {"local_path": "/path/to/workdir/data/arc"}}' \
|
||||||
|
--limit 10
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,307 @@
|
||||||
|
# ❓ FAQ
|
||||||
|
|
||||||
|
Below are some common issues encountered during the use of EvalScope.
|
||||||
|
|
||||||
|
```{important}
|
||||||
|
Most issues with using EvalScope may have been fixed in the latest version. It is recommended to first pull the code from the main branch and try installing it again to see if the issue can be resolved. Please ensure you are using the latest version of the code.
|
||||||
|
```
|
||||||
|
|
||||||
|
## Model Benchmark Testing
|
||||||
|
|
||||||
|
### Q0: Why are the evaluation results 0 or significantly incorrect?
|
||||||
|
|
||||||
|
A: Use the following methods to troubleshoot the problem:
|
||||||
|
1. Confirm whether the model interface can perform inference normally.
|
||||||
|
2. Check the model’s output in the `outputs/2025xxxxx/predictions/` path and confirm whether the model has output and whether the output is normal.
|
||||||
|
3. Start the visualization interface with `evalscope app` to check if the evaluation results are normal.
|
||||||
|
|
||||||
|
### Q1: Why is the accuracy measured by the inference model very low, such as the QwQ model on ifeval?
|
||||||
|
|
||||||
|
A: Add `"filters": {"remove_until": "</think>"}` to the ifeval in `--datast-args` to remove the model's thinking process.
|
||||||
|
|
||||||
|
### Q2: When using the API model service to evaluate embeddings, an error occurs: openai.BadRequestError: Error code: 400 - {'object': 'error', 'message': 'dimensions is currently not supported', 'type': 'BadRequestError', 'param': None, 'code': 400}
|
||||||
|
|
||||||
|
A: Set `'dimensions': None` or do not set this parameter.
|
||||||
|
|
||||||
|
### Q3: In the outputs/2025xxxxx/predictions/ path, the content of the last few cases of the model output is null.
|
||||||
|
|
||||||
|
A: The output length is insufficient and was truncated prematurely.
|
||||||
|
|
||||||
|
### Q4: Does the current built-in evaluation set of evalscope (such as LiveCodebench, AIME, MATH-500) only support pass1 evaluation? Does it support passk evaluation?
|
||||||
|
|
||||||
|
A:
|
||||||
|
1. This framework supports the `n_sample` parameter in QwQ evaluation. You can set `n` in the generation config to calculate the average metrics of multiple samples. Refer to: https://evalscope.readthedocs.io/zh-cn/latest/best_practice/eval_qwq.html#id5
|
||||||
|
2. This framework supports the `pass@k` metric. Refer to https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html#id3 in the `metrics_list`.
|
||||||
|
|
||||||
|
### Q5: An error occurred when loading the dataset from the local path, missing `dtype`.
|
||||||
|
|
||||||
|
A: There is an issue with loading local datasets, which will be fixed in the next version of modelscope. The temporary solution is to manually delete the `dataset_infos.json` file in the dataset directory.
|
||||||
|
|
||||||
|
### Q6: When evaluating Qwen2-audio, after running several text metrics, the reply content is all exclamation marks.
|
||||||
|
|
||||||
|
A: Refer to the reproduction code:
|
||||||
|
```python
|
||||||
|
from evalscope.run import run_task
|
||||||
|
|
||||||
|
task_cfg = {
|
||||||
|
'model': '/opt/nas/n/AudioLLM/allkinds_ckpt/Qwen/Qwen2-Audio-7B-Instruct',
|
||||||
|
'datasets': ['gsm8k', 'math_500', "gpqa", "mmlu_pro", "mmlu_redux"],
|
||||||
|
'limit': 100
|
||||||
|
}
|
||||||
|
|
||||||
|
run_task(task_cfg=task_cfg)
|
||||||
|
```
|
||||||
|
Currently, support for locally loaded multimodal models is not very comprehensive. It is recommended to use an inference service such as vllm to pull up the api for evaluation.
|
||||||
|
|
||||||
|
### Q7: Error when evaluating large multimodal models: Unknown benchmark.
|
||||||
|
|
||||||
|
A: Refer to [here](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/backend/vlmevalkit_backend.html#vlmevalkit) for multimodal evaluation. You need to use the VLMEval tool.
|
||||||
|
|
||||||
|
### Q8: When evaluating Gemma3 series models, a RuntimeError: CUDA error: device-side assert triggered occurs.
|
||||||
|
|
||||||
|
A: Gemma3 is a multimodal model. The current chat_adapter of the framework does not support multimodal models well. It is recommended to use a model inference framework (such as vllm) to pull up the model service for evaluation.
|
||||||
|
|
||||||
|
### Q9: How to perform multi-card evaluation?
|
||||||
|
|
||||||
|
A: Currently, data parallel acceleration is not supported.
|
||||||
|
|
||||||
|
### Q10: The visualization tool for the model inference service's stress test cannot find the report.
|
||||||
|
|
||||||
|
A: This visualization tool is specifically for displaying model evaluation results and is not suitable for visualizing stress test results of model inference services. For visualizing stress test results of model inference services, refer to the [stress test result visualization guide](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/examples.html#wandb).
|
||||||
|
|
||||||
|
### Q11: Is there an available docker?
|
||||||
|
|
||||||
|
A: You can view the [latest image](https://modelscope.cn/docs/intro/environment-setup#%E6%9C%80%E6%96%B0%E9%95%9C%E5%83%8F) using modelscope's official image, which includes the evalscope library.
|
||||||
|
|
||||||
|
### Q12: When evaluating the ifeval dataset, an error occurs: Unable to detect language for text कामाची घाई.
|
||||||
|
|
||||||
|
A: The error message contains:
|
||||||
|
due to Need to load profiles.
|
||||||
|
NotADirectoryError: [Errno 20] Not a directory: '/nltk_data/tokenizers/punkt_tab.zip/punkt_tab/english/collocations.tab'
|
||||||
|
|
||||||
|
Solution:
|
||||||
|
1. `unzip /path/to/nltk_data/tokenizers/punkt_tab.zip`
|
||||||
|
2. Command as follows
|
||||||
|
```shell
|
||||||
|
!evalscope eval
|
||||||
|
--model xxxx
|
||||||
|
--api-url xxxx
|
||||||
|
--api-key xxxxx
|
||||||
|
--generation-config temperature=1.0
|
||||||
|
--eval-type service
|
||||||
|
--eval-batch-size 50
|
||||||
|
--datasets ifeval
|
||||||
|
--judge-worker-num 1
|
||||||
|
```
|
||||||
|
|
||||||
|
### Q13: Incorrect bad case set when evaluating the Math-500 dataset.
|
||||||
|
|
||||||
|
A: The mathematical parsing rules have issues, and writing these matching rules is quite complex, making it difficult to cover all cases. You can set a judge model and use LLM for recall, which can reduce misjudgments, as follows:
|
||||||
|
```python
|
||||||
|
judge_strategy=JudgeStrategy.LLM_RECALL,
|
||||||
|
judge_model_args={
|
||||||
|
'model_id': 'qwen2.5-72b-instruct',
|
||||||
|
'api_url': 'https://dashscope.aliyuncs.com/compatible-mode/v1',
|
||||||
|
'api_key': os.getenv('DASHSCOPE_API_KEY'),
|
||||||
|
}
|
||||||
|
```
|
||||||
|
Refer to: [Parameter Explanation](https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html#judge), [Usage Example](https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html#id9)
|
||||||
|
|
||||||
|
### Q14: Using qwen2.5-72b-instruct to segment solution, the === in the figure indicates different solutions separated out. This prompt cannot constrain the model to segment correctly.
|
||||||
|
|
||||||
|
A: This prompt:
|
||||||
|
https://github.com/modelscope/evalscope/blob/595ac60f22b1248d5333a27ffd4b9eeae7f57727/evalscope/third_party/thinkbench/resources/reformat_template.txt
|
||||||
|
|
||||||
|
This prompt is used to segment steps, not to divide sub-solutions. You can adjust the prompt to divide sub-solutions.
|
||||||
|
|
||||||
|
### Q15: What is the default temperature when evaluating service?
|
||||||
|
|
||||||
|
A: The default is 0.
|
||||||
|
|
||||||
|
### Q16: What should I do if the results are inaccurate or unstable when evaluating on AIME24?
|
||||||
|
|
||||||
|
A: The default metric for AIME is pass@1, and it is estimated to be more accurate with sufficient samples. You can set n to a larger value, or set temperature and seed to make the model output as consistent as possible.
|
||||||
|
|
||||||
|
### Q17: The gradio program for visualizing evaluation results does not work offline (without public network).
|
||||||
|
|
||||||
|
A: You can refer to the solution here [gradio-app/gradio#7934](https://github.com/gradio-app/gradio/issues/7934).
|
||||||
|
|
||||||
|
### Q18: Does the multimodal custom Q&A format not support judges?
|
||||||
|
|
||||||
|
A: Custom Q&A requires implementing the judge logic yourself.
|
||||||
|
|
||||||
|
### Q19: Running the aime 2024 evaluation reports an SSLError.
|
||||||
|
|
||||||
|
A: Example of the error:
|
||||||
|
```text
|
||||||
|
requests.exceptions.SSLError: HTTPSConnectionPool(host='www.modelscope.cn', port=443): Max retries exceeded with url: /api/v1/datasets/HuggingFaceH4/aime_2024 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1007)')))
|
||||||
|
```
|
||||||
|
|
||||||
|
The error reason is that the data-args is written incorrectly, and it should be like this:
|
||||||
|
```python
|
||||||
|
dataset_args={
|
||||||
|
'aime24': {
|
||||||
|
'local_path': "/var/AIME_2024/",
|
||||||
|
'few_shot_num': 3
|
||||||
|
}
|
||||||
|
},
|
||||||
|
```
|
||||||
|
|
||||||
|
### Q20: How to set the number of times a sample is inferred to generate several answers during dataset evaluation?
|
||||||
|
|
||||||
|
A: Specify in the generation config.
|
||||||
|
|
||||||
|
Refer to: https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html#id2
|
||||||
|
|
||||||
|
### Q21: What is the warning about modelscope - WARNING - Use trust_remote_code=True. Will invoke codes from ceval-exam. Please make sure that you can trust the external codes. How can the trust_remote_code=True parameter be passed?
|
||||||
|
|
||||||
|
A: This is a warning and does not affect the evaluation process. The framework already defaults to `trust_remote_code=True`.
|
||||||
|
|
||||||
|
### Q22: What should I do if a base model exceeds the maximum token during api evaluation and reports an error?
|
||||||
|
|
||||||
|
A: The api evaluation uses the `chat` interface. Evaluating the base model may have some problems (the model output will not stop), and it is recommended to use the Instruct model for testing.
|
||||||
|
|
||||||
|
### Q23: When starting a service with vllm, it repeatedly reports retrying request issues and then starts reporting Error when calling OpenAI API: Request timed out.
|
||||||
|
|
||||||
|
A: The model output is relatively long. Try adding the `stream` parameter and increasing `timeout`.
|
||||||
|
|
||||||
|
### Q24: How to evaluate the performance of multimodal models (such as Qwen-2.5-vl) on language model evaluation datasets (such as MMLU)?
|
||||||
|
|
||||||
|
A: It is recommended to use vllm and other frameworks to pull up services for evaluation of multimodal models. Local loading of multimodal models is not yet supported.
|
||||||
|
|
||||||
|
Refer to: https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html#api
|
||||||
|
|
||||||
|
### Q25: The stream parameter reports an error: EvalScope Command Line tool: error: unrecognized arguments: --stream True.
|
||||||
|
|
||||||
|
A: Use `--stream` directly without adding `True`.
|
||||||
|
|
||||||
|
### Q26: An error occurs when executing an example: RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_CUDA__index_select).
|
||||||
|
|
||||||
|
A: First confirm whether the video memory is sufficient. Since the default device map is auto, some weights may be allocated to the cpu. You can try adding `--model-args device_map=cuda`.
|
||||||
|
|
||||||
|
### Q27: For r1-type models, does the evaluation process ignore the thinking part and directly evaluate the generated final result, or does it evaluate the answer with the thinking process and result together?
|
||||||
|
|
||||||
|
A: Currently, no additional processing is done on `<think>` content. By default, `<think>` and `<answer>` are placed together, and the answer is parsed from there for evaluation. Post-processing filters are supported, and it is recommended to filter out the thinking part for inference models.
|
||||||
|
Usage example:
|
||||||
|
```shell
|
||||||
|
--datasets ifeval
|
||||||
|
--dataset-args '{"ifeval": {"filters": {"remove_until": "</think>"}}'
|
||||||
|
```
|
||||||
|
|
||||||
|
### Q28: Abnormal chart display in the visualization interface.
|
||||||
|
|
||||||
|
A: Try downgrading plotly to version 5.23.0.
|
||||||
|
|
||||||
|
### Q29: Is there currently an entry for evaluating directly based on prediction results?
|
||||||
|
|
||||||
|
A: Refer to this: https://evalscope.readthedocs.io/zh-cn/latest/get_started/parameters.html#id5, set the use_cache parameter.
|
||||||
|
|
||||||
|
### Q30: The evaluation was interrupted, how can I resume it (checkpoint evaluation)?
|
||||||
|
|
||||||
|
A: It is supported. Please use the `use_cache` parameter to pass in the path of the previous evaluation output to reuse the model's prediction results and review outcomes.
|
||||||
|
|
||||||
|
## Model Stress Testing
|
||||||
|
|
||||||
|
### Q1: When testing ollama, I found that when the concurrency is greater than 5, the Throughput (average tokens/s) value always does not go up. My graphics card, cpu, memory, and io have no bottlenecks. What is the problem?
|
||||||
|
|
||||||
|
A: Refer to the reproduction code:
|
||||||
|
```shell
|
||||||
|
ollama run deepseek-r1:7b
|
||||||
|
|
||||||
|
evalscope perf --url http://127.0.0.1:11434/v1/chat/completions --parallel 20 --model deepseek-r1:7b --number 50 --api openai --dataset longalpaca --stream --tokenizer-path /home/data/DeepSeek-R1-Distill-Qwen-7B/
|
||||||
|
```
|
||||||
|
|
||||||
|
Add an export OLLAMA_NUM_PARALLEL=10.
|
||||||
|
|
||||||
|
### Q2: Unable to use --min-tokens 2048 --max-tokens 2048 \ to control the output length.
|
||||||
|
|
||||||
|
A: `--min-tokens` is not supported by all model services. Please check the documentation of the corresponding API service.
|
||||||
|
|
||||||
|
- Explanation: The corresponding API service documentation refers to the documentation of the model service being tested, whether it is provided by an inference engine service or a cloud service provider.
|
||||||
|
|
||||||
|
### Q3: An error occurs when running the speed benchmark script.
|
||||||
|
|
||||||
|
A: Refer to the error message
|
||||||
|
```text
|
||||||
|
2025-03-31 08:56:52,172 - evalscope - http_client.py - on_request_chunk_sent - 125 - DEBUG - Request sent: <method='POST', url=URL('https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions'), truncated_chunk='{"prompt": "熵", "model": "qwen2.5-72b-instruct", "max_tokens": 2048, "min_tokens": 2048, "seed": 42, "stop": [], "stop_token_ids": []}'>
|
||||||
|
2025-03-31 08:56:52,226 - evalscope - http_client.py - on_response_chunk_received - 137 - DEBUG - Request received: <method='POST', url=URL('https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions'), truncated_chunk='{"error":{"code":"missing_required_parameter","param":"message","message":"you must provide a messages parameter","type":"invalid_request_error"},"request_id":"chatcmpl-816a021e-5d7e-9eff-91a2-36aed4641546"}'>
|
||||||
|
```
|
||||||
|
Refer to the reproduction code
|
||||||
|
```shell
|
||||||
|
evalscope perf
|
||||||
|
--parallel 1
|
||||||
|
--url 'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions'
|
||||||
|
--model 'qwen2.5-72b-instruct'
|
||||||
|
--log-every-n-query 5
|
||||||
|
--connect-timeout 6000
|
||||||
|
--read-timeout 6000
|
||||||
|
--max-tokens 2048
|
||||||
|
--min-tokens 2048
|
||||||
|
--api openai
|
||||||
|
--api-key 'sk-xxxxxx'
|
||||||
|
--dataset speed_benchmark
|
||||||
|
--debug
|
||||||
|
```
|
||||||
|
For speed testing, the `--url` needs to use the `/v1/completions` endpoint instead of the `/v1/chat/completions`, to avoid the extra handling of the chat template affecting the input length.
|
||||||
|
|
||||||
|
### Q4: Does perf stress testing support custom parsing of the return body?
|
||||||
|
|
||||||
|
A: Refer to the documentation: https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/custom.html#api
|
||||||
|
|
||||||
|
### Q5: Which parameter can be adjusted to increase concurrent processing?
|
||||||
|
|
||||||
|
A: You can refer to this: [vllm-project/vllm#3561](https://github.com/vllm-project/vllm/issues/3561).
|
||||||
|
|
||||||
|
### Q6: When executing with the stream, but under 128 concurrency, it waits for the entire batch of concurrency to finish before proceeding with the next 128 concurrent requests, while without the stream it completes one and enters a new request. This results in much lower throughput with the stream.
|
||||||
|
|
||||||
|
A: Refer to the example code:
|
||||||
|
```shell
|
||||||
|
evalscope perf --url 'http://127.0.0.1:8000/v1/chat/completions'
|
||||||
|
--parallel 128
|
||||||
|
--model 'test'
|
||||||
|
--log-every-n-query 10
|
||||||
|
--read-timeout=1200
|
||||||
|
--dataset-path '/model/open_qa.jsonl'
|
||||||
|
-n 1000
|
||||||
|
--max-prompt-length 32000
|
||||||
|
--api openai
|
||||||
|
--stop '<|im_end|>'
|
||||||
|
--dataset openqa
|
||||||
|
```
|
||||||
|
Reduce concurrency and try again.
|
||||||
|
|
||||||
|
### Q7: TTFT test results seem incorrect, as the total time for completing 50 requests is only 30 seconds, and TTFT is also 30 seconds. What is going on?
|
||||||
|
|
||||||
|
A: To accurately measure the Time to First Token (TTFT) metric, the request must include the --stream parameter; otherwise, TTFT will be the same as Latency.
|
||||||
|
|
||||||
|
### Q8: How to test a custom API model (not openai or vllm service), and which aspects should be modified, what parameters are required?
|
||||||
|
|
||||||
|
A:
|
||||||
|
1. For model performance testing, any service compatible with OpenAI API format is supported.
|
||||||
|
2. For model inference service stress testing, refer to [custom request API](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/custom.html#api).
|
||||||
|
|
||||||
|
The --no-test-connection parameter is now supported to skip connection testing.
|
||||||
|
|
||||||
|
### Q9: Why does the ttft time output differ significantly from the ttft time collected by vllm?
|
||||||
|
|
||||||
|
A: The TTFT obtained by evalscope is the end-to-end time, starting from when the request is sent and ending when the first token is received. It includes network transmission and processing time, which may differ from the service-side statistics.
|
||||||
|
|
||||||
|
### Q10: If the request times out, can a longer timeout parameter be set?
|
||||||
|
|
||||||
|
A: Yes, just add the following parameters:
|
||||||
|
```shell
|
||||||
|
--connect-timeout 60000 \
|
||||||
|
--read-timeout 60000 \
|
||||||
|
```
|
||||||
|
|
||||||
|
### Q11: In the example of testing the inference speed of model services, how is the model understood?
|
||||||
|
|
||||||
|
A: The `model` is the name of the model deployed by the model service framework, such as `gpt-4o`, `o1-mini`, etc.
|
||||||
|
|
||||||
|
### Q12: KTransformers stream output cannot be recognized and reports ZeroDivisionError: float division by zero.
|
||||||
|
|
||||||
|
A: The deployed model service seems not to return usage information, which is different from the standard OpenAI API format. It requires the `--tokenizer-path` parameter to calculate the number of `tokens`.
|
||||||
|
|
||||||
|
### Q13: How can I perform stress testing on a multimodal large model, and how do I input images?
|
||||||
|
|
||||||
|
A: Currently, setting the dataset to flickr8k is supported for stress testing of multimodal models. Please [refer to](https://evalscope.readthedocs.io/zh-cn/latest/user_guides/stress_test/parameters.html#id5) for more information.
|
||||||
{kind=link}
|
After Width: | Height: | Size: 2.4 MiB |
{kind=link}
|
After Width: | Height: | Size: 1.8 MiB |
{kind=link}
|
After Width: | Height: | Size: 2.0 MiB |
{kind=link}
|
After Width: | Height: | Size: 2.9 MiB |
{kind=link}
|
After Width: | Height: | Size: 2.3 MiB |
{kind=link}
|
After Width: | Height: | Size: 364 KiB |
{kind=link}
|
After Width: | Height: | Size: 1.9 MiB |
{kind=link}
|
After Width: | Height: | Size: 1.2 MiB |
|
|
@ -0,0 +1,58 @@
|
||||||
|
# Installation
|
||||||
|
|
||||||
|
## Method 1: Install Using pip
|
||||||
|
We recommend using conda to manage your environment and installing dependencies with pip:
|
||||||
|
|
||||||
|
1. Create a conda environment (optional)
|
||||||
|
```shell
|
||||||
|
# It is recommended to use Python 3.10
|
||||||
|
conda create -n evalscope python=3.10
|
||||||
|
# Activate the conda environment
|
||||||
|
conda activate evalscope
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install dependencies using pip
|
||||||
|
```shell
|
||||||
|
pip install evalscope # Install Native backend (default)
|
||||||
|
# Additional options
|
||||||
|
pip install 'evalscope[opencompass]' # Install OpenCompass backend
|
||||||
|
pip install 'evalscope[vlmeval]' # Install VLMEvalKit backend
|
||||||
|
pip install 'evalscope[rag]' # Install RAGEval backend
|
||||||
|
pip install 'evalscope[perf]' # Install dependencies for the model performance testing module
|
||||||
|
pip install 'evalscope[app]' # Install dependencies for visualization
|
||||||
|
pip install 'evalscope[all]' # Install all backends (Native, OpenCompass, VLMEvalKit, RAGEval)
|
||||||
|
```
|
||||||
|
|
||||||
|
````{warning}
|
||||||
|
As the project has been renamed to `evalscope`, for versions `v0.4.3` or earlier, you can install using the following command:
|
||||||
|
```shell
|
||||||
|
pip install llmuses<=0.4.3
|
||||||
|
```
|
||||||
|
To import relevant dependencies using `llmuses`:
|
||||||
|
``` python
|
||||||
|
from llmuses import ...
|
||||||
|
```
|
||||||
|
````
|
||||||
|
|
||||||
|
## Method 2: Install from Source
|
||||||
|
1. Download the source code
|
||||||
|
```shell
|
||||||
|
git clone https://github.com/modelscope/evalscope.git
|
||||||
|
```
|
||||||
|
|
||||||
|
2. Install dependencies
|
||||||
|
```shell
|
||||||
|
cd evalscope/
|
||||||
|
pip install -e . # Install Native backend
|
||||||
|
# Additional options
|
||||||
|
pip install -e '.[opencompass]' # Install OpenCompass backend
|
||||||
|
pip install -e '.[vlmeval]' # Install VLMEvalKit backend
|
||||||
|
pip install -e '.[rag]' # Install RAGEval backend
|
||||||
|
pip install -e '.[perf]' # Install Perf dependencies
|
||||||
|
pip install -e '.[app]' # Install visualization dependencies
|
||||||
|
pip install -e '.[all]' # Install all backends (Native, OpenCompass, VLMEvalKit, RAGEval)
|
||||||
|
```
|
||||||
|
|
||||||
|
## Docker Image
|
||||||
|
|
||||||
|
You can use the official ModelScope Docker image, which includes the EvalScope library. For more information, refer to [here](https://modelscope.cn/docs/intro/environment-setup#%E6%9C%80%E6%96%B0%E9%95%9C%E5%83%8F).
|
||||||
|
|
@ -0,0 +1,60 @@
|
||||||
|
# Introduction
|
||||||
|
|
||||||
|
[EvalScope](https://github.com/modelscope/evalscope) is a comprehensive model evaluation and benchmarking framework meticulously crafted by the ModelScope community. It offers an all-in-one solution for your model assessment needs, regardless of the type of model you are developing:
|
||||||
|
|
||||||
|
- 🧠 Large Language Models
|
||||||
|
- 🎨 Multimodal Models
|
||||||
|
- 🔍 Embedding Models
|
||||||
|
- 🏆 Reranker Models
|
||||||
|
- 🖼️ CLIP Models
|
||||||
|
- 🎭 AIGC Models (Text-to-Image/Video)
|
||||||
|
- ...and more!
|
||||||
|
|
||||||
|
EvalScope is not merely an evaluation tool; it is a valuable ally in your model optimization journey:
|
||||||
|
|
||||||
|
- 🏅 Equipped with multiple industry-recognized benchmarks and evaluation metrics such as MMLU, CMMLU, C-Eval, GSM8K, and others.
|
||||||
|
- 📊 Performance stress testing for model inference to ensure your model excels in real-world applications.
|
||||||
|
- 🚀 Seamlessly integrates with the [ms-swift](https://github.com/modelscope/ms-swift) training framework, enabling one-click evaluations and providing end-to-end support from training to assessment for your model development.
|
||||||
|
|
||||||
|
## Overall Architecture
|
||||||
|
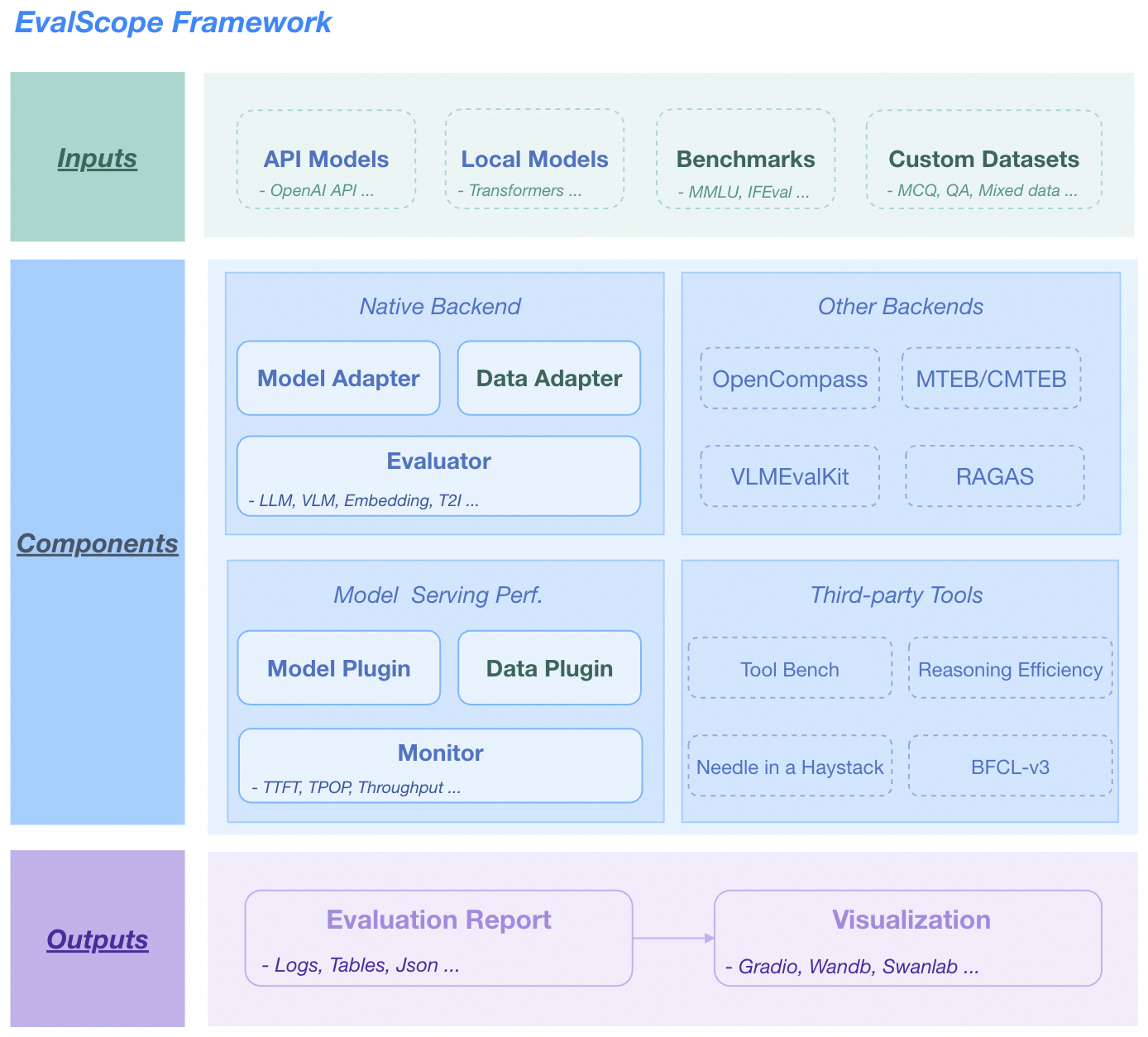
|
||||||
|
*EvalScope Architecture Diagram.*
|
||||||
|
|
||||||
|
The architecture includes the following modules:
|
||||||
|
|
||||||
|
1. Input Layer
|
||||||
|
- **Model Sources**: API models (OpenAI API), local models (ModelScope)
|
||||||
|
- **Datasets**: Standard evaluation benchmarks (MMLU/GSM8k, etc.), custom data (MCQ/QA)
|
||||||
|
|
||||||
|
2. Core Functions
|
||||||
|
- **Multi-backend Evaluation**
|
||||||
|
- Native backends: Unified evaluation for LLM/VLM/Embedding/T2I models
|
||||||
|
- Integrated frameworks: OpenCompass/MTEB/VLMEvalKit/RAGAS
|
||||||
|
|
||||||
|
- **Performance Monitoring**
|
||||||
|
- Model plugins: Supports various model service APIs
|
||||||
|
- Data plugins: Supports multiple data formats
|
||||||
|
- Metric tracking: TTFT/TPOP/Stability and other metrics
|
||||||
|
|
||||||
|
- **Tool Extensions**
|
||||||
|
- Integration: Tool-Bench/Needle-in-a-Haystack/BFCL-v3
|
||||||
|
|
||||||
|
3. Output Layer
|
||||||
|
- **Structured Reports**: Supports JSON/Tables/Logs
|
||||||
|
- **Visualization Platforms**: Supports Gradio/Wandb/SwanLab
|
||||||
|
|
||||||
|
## Framework Features
|
||||||
|
- **Benchmark Datasets**: Preloaded with several commonly used test benchmarks, including MMLU, CMMLU, C-Eval, GSM8K, ARC, HellaSwag, TruthfulQA, MATH, HumanEval, etc.
|
||||||
|
- **Evaluation Metrics**: Implements various commonly used evaluation metrics.
|
||||||
|
- **Model Access**: A unified model access mechanism that is compatible with the Generate and Chat interfaces of multiple model families.
|
||||||
|
- **Automated Evaluation**: Includes automatic evaluation of objective questions and complex task evaluation using expert models.
|
||||||
|
- **Evaluation Reports**: Automatically generates evaluation reports.
|
||||||
|
- **Arena Mode**: Used for comparisons between models and objective evaluation of models, supporting various evaluation modes, including:
|
||||||
|
- **Single mode**: Scoring a single model.
|
||||||
|
- **Pairwise-baseline mode**: Comparing against a baseline model.
|
||||||
|
- **Pairwise (all) mode**: Pairwise comparison among all models.
|
||||||
|
- **Visualization Tools**: Provides intuitive displays of evaluation results.
|
||||||
|
- **Model Performance Evaluation**: Offers a performance testing tool for model inference services and detailed statistics, see [Model Performance Evaluation Documentation](../user_guides/stress_test/index.md).
|
||||||
|
- **OpenCompass Integration**: Supports OpenCompass as the evaluation backend, providing advanced encapsulation and task simplification, allowing for easier task submission for evaluation.
|
||||||
|
- **VLMEvalKit Integration**: Supports VLMEvalKit as the evaluation backend, facilitating the initiation of multi-modal evaluation tasks, supporting various multi-modal models and datasets.
|
||||||
|
- **Full-Link Support**: Through seamless integration with the [ms-swift](https://github.com/modelscope/ms-swift) training framework, provides a one-stop development process for model training, model deployment, model evaluation, and report viewing, enhancing user development efficiency.
|
||||||
|
|
@ -0,0 +1,175 @@
|
||||||
|
# Parameters
|
||||||
|
|
||||||
|
Run `evalscope eval --help` to get a complete list of parameter descriptions.
|
||||||
|
|
||||||
|
## Model Parameters
|
||||||
|
- `--model`: The name of the model being evaluated.
|
||||||
|
- Specify the model's `id` in [ModelScope](https://modelscope.cn/), and it will automatically download the model, for example, [Qwen/Qwen2.5-0.5B-Instruct](https://modelscope.cn/models/Qwen/Qwen2.5-0.5B-Instruct/summary);
|
||||||
|
- Specify the local path to the model, for example, `/path/to/model`, to load the model from the local environment;
|
||||||
|
- When the evaluation target is the model API endpoint, it needs to be specified as `model_id`, for example, `Qwen2.5-0.5B-Instruct`.
|
||||||
|
- `--model-id`: An alias for the model being evaluated. Defaults to the last part of `model`, for example, the `model-id` for `Qwen/Qwen2.5-0.5B-Instruct` is `Qwen2.5-0.5B-Instruct`.
|
||||||
|
- `--model-task`: The task type of the model, defaults to `text_generation`, options are `text_generation`, `image_generation`.
|
||||||
|
- `--model-args`: Model loading parameters, separated by commas in `key=value` format, with default parameters:
|
||||||
|
- `revision`: Model version, defaults to `master`
|
||||||
|
- `precision`: Model precision, defaults to `torch.float16`
|
||||||
|
- `device_map`: Device allocation for the model, defaults to `auto`
|
||||||
|
- `--generation-config`: Generation parameters, separated by commas, in the form of `key=value` or passed in as a JSON string, which will be parsed into a dictionary:
|
||||||
|
- If using local model inference (based on Transformers), the following parameters are included ([Full parameter guide](https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig)):
|
||||||
|
- `do_sample`: Whether to use sampling, default is `false`
|
||||||
|
- `max_length`: Maximum length, default is 2048
|
||||||
|
- `max_new_tokens`: Maximum length of generated text, default is 512
|
||||||
|
- `num_return_sequences`: Number of sequences to generate, default is 1; when set greater than 1, multiple sequences will be generated, requires setting `do_sample=True`
|
||||||
|
- `temperature`: Generation temperature
|
||||||
|
- `top_k`: Top-k for generation
|
||||||
|
- `top_p`: Top-p for generation
|
||||||
|
- If using model API service for inference (`eval-type` set to `service`), the following parameters are included (please refer to the deployed model service for specifics):
|
||||||
|
- `max_tokens`: Maximum length of generated text, default is 2048
|
||||||
|
- `temperature`: Generation temperature, default is 0.0
|
||||||
|
- `n`: number of generated sequences, default is 1 (Note: currently, lmdeploy only supports n=1)
|
||||||
|
```bash
|
||||||
|
# For example, pass arguments in the form of key=value
|
||||||
|
--model-args revision=master,precision=torch.float16,device_map=auto
|
||||||
|
--generation-config do_sample=true,temperature=0.5
|
||||||
|
|
||||||
|
# Or pass more complex parameters using a JSON string
|
||||||
|
--model-args '{"revision": "master", "precision": "torch.float16", "device_map": "auto"}'
|
||||||
|
--generation-config '{"do_sample":true,"temperature":0.5,"chat_template_kwargs":{"enable_thinking": false}}'
|
||||||
|
```
|
||||||
|
- `--chat-template`: Model inference template, defaults to `None`, indicating the use of transformers' `apply_chat_template`; supports passing in a jinja template string to customize the inference template.
|
||||||
|
- `--template-type`: Model inference template, deprecated, refer to `--chat-template`.
|
||||||
|
|
||||||
|
**The following parameters are only valid when `eval-type=service`:**
|
||||||
|
- `--api-url`: Model API endpoint, default is `None`; supports local or remote OpenAI API format endpoints, for example `http://127.0.0.1:8000/v1`.
|
||||||
|
- `--api-key`: Model API endpoint key, default is `EMPTY`
|
||||||
|
- `--timeout`: Model API request timeout, default is `None`
|
||||||
|
- `--stream`: Whether to use streaming transmission, default is `False`
|
||||||
|
|
||||||
|
## Dataset Parameters
|
||||||
|
- `--datasets`: Dataset name, supports inputting multiple datasets separated by spaces, datasets will automatically be downloaded from ModelScope, supported datasets refer to [Dataset List](./supported_dataset/index.md).
|
||||||
|
- `--dataset-args`: Configuration parameters for the evaluation dataset, passed in `json` format, where the key is the dataset name and the value is the parameter, note that it needs to correspond one-to-one with the values in the `--datasets` parameter:
|
||||||
|
- `dataset_id` (or `local_path`): Local path for the dataset, once specified, it will attempt to load local data.
|
||||||
|
- `prompt_template`: The prompt template for the evaluation dataset. When specified, it will be used to generate prompts. For example, the template for the `gsm8k` dataset is `Question: {query}\nLet's think step by step\nAnswer:`. The question from the dataset will be filled into the `query` field of the template.
|
||||||
|
- `query_template`: The query template for the evaluation dataset. When specified, it will be used to generate queries. For example, the template for `general_mcq` is `Question: {question}\n{choices}\nAnswer: {answer}\n\n`. The questions from the dataset will be inserted into the `question` field of the template, options will be inserted into the `choices` field, and answers will be inserted into the `answer` field (answer insertion is only effective for few-shot scenarios).
|
||||||
|
- `system_prompt`: System prompt for the evaluation dataset.
|
||||||
|
- `model_adapter`: The model adapter for the evaluation dataset. Once specified, the given model adapter will be used for evaluation. Currently, it supports `generation`, `multiple_choice_logits`, and `continuous_logits`. For service evaluation, only `generation` is supported at the moment. Some multiple-choice datasets support `logits` output.
|
||||||
|
- `subset_list`: List of subsets for the evaluation dataset, once specified, only subset data will be used.
|
||||||
|
- `few_shot_num`: Number of few-shots.
|
||||||
|
- `few_shot_random`: Whether to randomly sample few-shot data, defaults to `False`.
|
||||||
|
- `metric_list`: A list of metrics for evaluating the dataset. When specified, the evaluation will use the given metrics. Currently supported metrics include `AverageAccuracy`, `AveragePass@1`, and `Pass@[1-16]`. For example, for the `humaneval` dataset, you can specify `["Pass@1", "Pass@5"]`. Note that in this case, you need to set `n=5` to make the model return 5 results.
|
||||||
|
- `filters`: Filters for the evaluation dataset. When specified, these filters will be used to process the evaluation results. They can be used to handle the output of inference models. Currently supported filters are:
|
||||||
|
- `remove_until {string}`: Removes the part of the model's output before the specified string.
|
||||||
|
- `extract {regex}`: Extracts the part of the model's output that matches the specified regular expression.
|
||||||
|
For example, the `ifeval` dataset can specify `{"remove_until": "</think>"}`, which will filter out the part of the model's output before `</think>`, avoiding interference with scoring.
|
||||||
|
```bash
|
||||||
|
# For example
|
||||||
|
--datasets gsm8k arc
|
||||||
|
--dataset-args '{"gsm8k": {"few_shot_num": 4, "few_shot_random": false}, "arc": {"dataset_id": "/path/to/arc"}}, "ifeval": {"filters": {"remove_until": "</think>"}}'
|
||||||
|
```
|
||||||
|
- `--dataset-dir`: Dataset download path, defaults to `~/.cache/modelscope/datasets`.
|
||||||
|
- `--dataset-hub`: Dataset download source, defaults to `modelscope`, alternative is `huggingface`.
|
||||||
|
- `--limit`: The maximum amount of evaluation data for each dataset. If not specified, the default is to evaluate the entire dataset, which can be useful for quick validation. It supports both `int` and `float` types. An `int` value indicates the first `N` entries of the dataset to be evaluated, while a `float` value represents the first `N%` of the dataset. For example, `0.1` means evaluating the first 10% of the dataset, and `100` means evaluating the first 100 entries.
|
||||||
|
|
||||||
|
## Evaluation Parameters
|
||||||
|
|
||||||
|
- `--eval-batch-size`: Evaluation batch size, default is `1`; when `eval-type=service`, it indicates the number of concurrent evaluation requests, default is `8`.
|
||||||
|
- `--eval-stage`: (Deprecated, refer to `--use-cache`) Evaluation stage, options are `all`, `infer`, `review`, default is `all`.
|
||||||
|
- `--eval-type`: Evaluation type, options are `checkpoint`, `custom`, `service`; defaults to `checkpoint`.
|
||||||
|
- `--eval-backend`: Evaluation backend, options are `Native`, `OpenCompass`, `VLMEvalKit`, `RAGEval`, `ThirdParty`, defaults to `Native`.
|
||||||
|
- `OpenCompass` is used for evaluating large language models.
|
||||||
|
- `VLMEvalKit` is used for evaluating multimodal models.
|
||||||
|
- `RAGEval` is used for evaluating RAG processes, embedding models, re-ranking models, CLIP models.
|
||||||
|
```{seealso}
|
||||||
|
Other evaluation backends [User Guide](../user_guides/backend/index.md)
|
||||||
|
```
|
||||||
|
- `ThirdParty` is used for other special task evaluations, such as [ToolBench](../third_party/toolbench.md), [LongBench](../third_party/longwriter.md).
|
||||||
|
- `--eval-config`: This parameter needs to be passed when using a non-`Native` evaluation backend.
|
||||||
|
|
||||||
|
## Judge Parameters
|
||||||
|
|
||||||
|
The LLM-as-a-Judge evaluation parameters use a judge model to determine correctness, including the following parameters:
|
||||||
|
|
||||||
|
- `--judge-strategy`: The strategy for using the judge model, options include:
|
||||||
|
- `auto`: The default strategy, which decides whether to use the judge model based on the dataset requirements
|
||||||
|
- `llm`: Always use the judge model
|
||||||
|
- `rule`: Do not use the judge model, use rule-based judgment instead
|
||||||
|
- `llm_recall`: First use rule-based judgment, and if it fails, then use the judge model
|
||||||
|
- `--judge-worker-num`: The concurrency number for the judge model, default is `1`
|
||||||
|
- `--judge-model-args`: Sets the parameters for the judge model, passed in as a `json` string and parsed as a dictionary, supporting the following fields:
|
||||||
|
- `api_key`: The API endpoint key for the model. If not set, it will be retrieved from the environment variable `MODELSCOPE_SDK_TOKEN`, with a default value of `EMPTY`.
|
||||||
|
- `api_url`: The API endpoint for the model. If not set, it will be retrieved from the environment variable `MODELSCOPE_API_BASE`, with a default value of `https://api-inference.modelscope.cn/v1/`.
|
||||||
|
- `model_id`: The model ID. If not set, it will be retrieved from the environment variable `MODELSCOPE_JUDGE_LLM`, with a default value of `Qwen/Qwen3-235B-A22B`.
|
||||||
|
```{seealso}
|
||||||
|
For more information on ModelScope's model inference services, please refer to [ModelScope API Inference Services](https://modelscope.cn/docs/model-service/API-Inference/intro).
|
||||||
|
```
|
||||||
|
- `system_prompt`: System prompt for evaluating the dataset
|
||||||
|
- `prompt_template`: Prompt template for evaluating the dataset
|
||||||
|
- `generation_config`: Model generation parameters, same as the `--generation-config` parameter.
|
||||||
|
- `score_type`: Preset model scoring method, options include:
|
||||||
|
- `pattern`: (Default option) Directly judge whether the model output matches the reference answer, suitable for evaluations with reference answers.
|
||||||
|
<details><summary>Default prompt_template</summary>
|
||||||
|
|
||||||
|
```text
|
||||||
|
Your job is to look at a question, a gold target, and a predicted answer, and return a letter "A" or "B" to indicate whether the predicted answer is correct or incorrect.
|
||||||
|
|
||||||
|
[Question]
|
||||||
|
{question}
|
||||||
|
|
||||||
|
[Reference Answer]
|
||||||
|
{gold}
|
||||||
|
|
||||||
|
[Predicted Answer]
|
||||||
|
{pred}
|
||||||
|
|
||||||
|
Evaluate the model's answer based on correctness compared to the reference answer.
|
||||||
|
Grade the predicted answer of this new question as one of:
|
||||||
|
A: CORRECT
|
||||||
|
B: INCORRECT
|
||||||
|
|
||||||
|
Just return the letters "A" or "B", with no text around it.
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
- `numeric`: Judge the model output score under prompt conditions, suitable for evaluations without reference answers.
|
||||||
|
<details><summary>Default prompt_template</summary>
|
||||||
|
|
||||||
|
```text
|
||||||
|
Please act as an impartial judge and evaluate the quality of the response provided by an AI assistant to the user question displayed below. Your evaluation should consider factors such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of the response.
|
||||||
|
|
||||||
|
Begin your evaluation by providing a short explanation. Be as objective as possible.
|
||||||
|
|
||||||
|
After providing your explanation, you must rate the response on a scale of 0 (worst) to 1 (best) by strictly following this format: \"[[rating]]\", for example: \"Rating: [[0.5]]\"
|
||||||
|
|
||||||
|
[Question]
|
||||||
|
{question}
|
||||||
|
|
||||||
|
[Response]
|
||||||
|
{pred}
|
||||||
|
```
|
||||||
|
</details>
|
||||||
|
- `score_pattern`: Regular expression for parsing model output, default for `pattern` mode is `(A|B)`; default for `numeric` mode is `\[\[(\d+(?:\.\d+)?)\]\]`, used to extract model scoring results.
|
||||||
|
- `score_mapping`: Score mapping dictionary for `pattern` mode, default is `{'A': 1.0, 'B': 0.0}`
|
||||||
|
- `--analysis-report`: Whether to generate an analysis report, default is `false`; if this parameter is set, an analysis report will be generated using the judge model, including analysis interpretation and suggestions for the model evaluation results. The report output language will be automatically determined based on `locale.getlocale()`.
|
||||||
|
|
||||||
|
## Other Parameters
|
||||||
|
|
||||||
|
- `--work-dir`: Model evaluation output path, default is `./outputs/{timestamp}`, folder structure example is as follows:
|
||||||
|
```text
|
||||||
|
.
|
||||||
|
├── configs
|
||||||
|
│ └── task_config_b6f42c.yaml
|
||||||
|
├── logs
|
||||||
|
│ └── eval_log.log
|
||||||
|
├── predictions
|
||||||
|
│ └── Qwen2.5-0.5B-Instruct
|
||||||
|
│ └── general_qa_example.jsonl
|
||||||
|
├── reports
|
||||||
|
│ └── Qwen2.5-0.5B-Instruct
|
||||||
|
│ └── general_qa.json
|
||||||
|
└── reviews
|
||||||
|
└── Qwen2.5-0.5B-Instruct
|
||||||
|
└── general_qa_example.jsonl
|
||||||
|
```
|
||||||
|
- `--use-cache`: Use local cache path, default is `None`; if a path is specified, such as `outputs/20241210_194434`, it will reuse the model inference results from that path. If inference is not completed, it will continue inference and then proceed to evaluation.
|
||||||
|
- `--seed`: Random seed, default is `42`.
|
||||||
|
- `--debug`: Whether to enable debug mode, default is `false`.
|
||||||
|
- `--ignore-errors`: Whether to ignore errors during model generation, default is `false`.
|
||||||
|
- `--dry-run`: Pre-check parameters without performing inference, only prints parameters, default is `false`.
|
||||||
|
|
@ -0,0 +1,11 @@
|
||||||
|
# AIGC Benchmarks
|
||||||
|
|
||||||
|
This framework also supports evaluation datasets related to text-to-image and other AIGC tasks. The specific datasets are as follows:
|
||||||
|
|
||||||
|
| Name | Dataset ID | Task Type | Remarks |
|
||||||
|
|---------------|------------------|-----------------|--------------------------------|
|
||||||
|
| `general_t2i` | | General Text-to-Image | Refer to the tutorial |
|
||||||
|
| `evalmuse` | [AI-ModelScope/T2V-Eval-Prompts](https://modelscope.cn/datasets/AI-ModelScope/T2V-Eval-Prompts/summary) | Text-Image Consistency | EvalMuse subset, default metric is `FGA_BLIP2Score` |
|
||||||
|
| `genai_bench` | [AI-ModelScope/T2V-Eval-Prompts](https://modelscope.cn/datasets/AI-ModelScope/T2V-Eval-Prompts/) | Text-Image Consistency | GenAI-Bench-1600 subset, default metric is `VQAScore` |
|
||||||
|
| `hpdv2` | [AI-ModelScope/T2V-Eval-Prompts](https://modelscope.cn/datasets/AI-ModelScope/T2V-Eval-Prompts/) | Text-Image Consistency | HPDv2 subset, default metric is `HPSv2.1Score` |
|
||||||
|
| `tifa160` | [AI-ModelScope/T2V-Eval-Prompts](https://modelscope.cn/datasets/AI-ModelScope/T2V-Eval-Prompts/) | Text-Image Consistency | TIFA160 subset, default metric is `PickScore` |
|
||||||
|
|
@ -0,0 +1,18 @@
|
||||||
|
# Supported Benchmarks
|
||||||
|
|
||||||
|
EvalScope supports a variety of datasets for evaluating different types of models, including language models, AIGC models, and other models. Below is a list of the supported datasets categorized by their respective model types.
|
||||||
|
|
||||||
|
|
||||||
|
```{tip}
|
||||||
|
If the dataset you need is not on the list, you may submit an [issue](https://github.com/modelscope/evalscope/issues), and we will support it as soon as possible. Alternatively, you can refer to the [Benchmark Addition Guide](../../advanced_guides/add_benchmark.md) to add datasets by yourself and submit a [PR](https://github.com/modelscope/evalscope/pulls). Contributions are welcome.
|
||||||
|
|
||||||
|
You can also use other tools supported by this framework for evaluation, such as [OpenCompass](../../user_guides/backend/opencompass_backend.md) for language model evaluation, or [VLMEvalKit](../../user_guides/backend/vlmevalkit_backend.md) for multimodal model evaluation.
|
||||||
|
```
|
||||||
|
|
||||||
|
:::{toctree}
|
||||||
|
:maxdepth: 2
|
||||||
|
|
||||||
|
llm.md
|
||||||
|
aigc.md
|
||||||
|
other/index.md
|
||||||
|
:::
|
||||||
|
|
@ -0,0 +1,47 @@
|
||||||
|
# CLIP-Benchmark
|
||||||
|
|
||||||
|
| Dataset Name | Task Type | Notes |
|
||||||
|
|---------------------------------------------------------------------------------------------------------------|------------------------|----------------------------|
|
||||||
|
| [muge](https://modelscope.cn/datasets/clip-benchmark/muge/) | zeroshot_retrieval | Chinese Multimodal Dataset |
|
||||||
|
| [flickr30k](https://modelscope.cn/datasets/clip-benchmark/flickr30k/) | zeroshot_retrieval | |
|
||||||
|
| [flickr8k](https://modelscope.cn/datasets/clip-benchmark/flickr8k/) | zeroshot_retrieval | |
|
||||||
|
| [mscoco_captions](https://modelscope.cn/datasets/clip-benchmark/mscoco_captions/) | zeroshot_retrieval | |
|
||||||
|
| [mscoco_captions2017](https://modelscope.cn/datasets/clip-benchmark/mscoco_captions2017/) | zeroshot_retrieval | |
|
||||||
|
| [imagenet1k](https://modelscope.cn/datasets/clip-benchmark/imagenet1k/) | zeroshot_classification| |
|
||||||
|
| [imagenetv2](https://modelscope.cn/datasets/clip-benchmark/imagenetv2/) | zeroshot_classification| |
|
||||||
|
| [imagenet_sketch](https://modelscope.cn/datasets/clip-benchmark/imagenet_sketch/) | zeroshot_classification| |
|
||||||
|
| [imagenet-a](https://modelscope.cn/datasets/clip-benchmark/imagenet-a/) | zeroshot_classification| |
|
||||||
|
| [imagenet-r](https://modelscope.cn/datasets/clip-benchmark/imagenet-r/) | zeroshot_classification| |
|
||||||
|
| [imagenet-o](https://modelscope.cn/datasets/clip-benchmark/imagenet-o/) | zeroshot_classification| |
|
||||||
|
| [objectnet](https://modelscope.cn/datasets/clip-benchmark/objectnet/) | zeroshot_classification| |
|
||||||
|
| [fer2013](https://modelscope.cn/datasets/clip-benchmark/fer2013/) | zeroshot_classification| |
|
||||||
|
| [voc2007](https://modelscope.cn/datasets/clip-benchmark/voc2007/) | zeroshot_classification| |
|
||||||
|
| [voc2007_multilabel](https://modelscope.cn/datasets/clip-benchmark/voc2007_multilabel/) | zeroshot_classification| |
|
||||||
|
| [sun397](https://modelscope.cn/datasets/clip-benchmark/sun397/) | zeroshot_classification| |
|
||||||
|
| [cars](https://modelscope.cn/datasets/clip-benchmark/cars/) | zeroshot_classification| |
|
||||||
|
| [fgvc_aircraft](https://modelscope.cn/datasets/clip-benchmark/fgvc_aircraft/) | zeroshot_classification| |
|
||||||
|
| [mnist](https://modelscope.cn/datasets/clip-benchmark/mnist/) | zeroshot_classification| |
|
||||||
|
| [stl10](https://modelscope.cn/datasets/clip-benchmark/stl10/) | zeroshot_classification| |
|
||||||
|
| [gtsrb](https://modelscope.cn/datasets/clip-benchmark/gtsrb/) | zeroshot_classification| |
|
||||||
|
| [country211](https://modelscope.cn/datasets/clip-benchmark/country211/) | zeroshot_classification| |
|
||||||
|
| [renderedsst2](https://modelscope.cn/datasets/clip-benchmark/renderedsst2/) | zeroshot_classification| |
|
||||||
|
| [vtab_caltech101](https://modelscope.cn/datasets/clip-benchmark/vtab_caltech101/) | zeroshot_classification| |
|
||||||
|
| [vtab_cifar10](https://modelscope.cn/datasets/clip-benchmark/vtab_cifar10/) | zeroshot_classification| |
|
||||||
|
| [vtab_cifar100](https://modelscope.cn/datasets/clip-benchmark/vtab_cifar100/) | zeroshot_classification| |
|
||||||
|
| [vtab_clevr_count_all](https://modelscope.cn/datasets/clip-benchmark/vtab_clevr_count_all/) | zeroshot_classification| |
|
||||||
|
| [vtab_clevr_closest_object_distance](https://modelscope.cn/datasets/clip-benchmark/vtab_clevr_closest_object_distance/) | zeroshot_classification| |
|
||||||
|
| [vtab_diabetic_retinopathy](https://modelscope.cn/datasets/clip-benchmark/vtab_diabetic_retinopathy/) | zeroshot_classification| |
|
||||||
|
| [vtab_dmlab](https://modelscope.cn/datasets/clip-benchmark/vtab_dmlab/) | zeroshot_classification| |
|
||||||
|
| [vtab_dsprites_label_orientation](https://modelscope.cn/datasets/clip-benchmark/vtab_dsprites_label_orientation/) | zeroshot_classification| |
|
||||||
|
| [vtab_dsprites_label_x_position](https://modelscope.cn/datasets/clip-benchmark/vtab_dsprites_label_x_position/) | zeroshot_classification| |
|
||||||
|
| [vtab_dsprites_label_y_position](https://modelscope.cn/datasets/clip-benchmark/vtab_dsprites_label_y_position/) | zeroshot_classification| |
|
||||||
|
| [vtab_dtd](https://modelscope.cn/datasets/clip-benchmark/vtab_dtd/) | zeroshot_classification| |
|
||||||
|
| [vtab_eurosat](https://modelscope.cn/datasets/clip-benchmark/vtab_eurosat/) | zeroshot_classification| |
|
||||||
|
| [vtab_kitti_closest_vehicle_distance](https://modelscope.cn/datasets/clip-benchmark/vtab_kitti_closest_vehicle_distance/) | zeroshot_classification| |
|
||||||
|
| [vtab_flowers](https://modelscope.cn/datasets/clip-benchmark/vtab_flowers/) | zeroshot_classification| |
|
||||||
|
| [vtab_pets](https://modelscope.cn/datasets/clip-benchmark/vtab_pets/) | zeroshot_classification| |
|
||||||
|
| [vtab_pcam](https://modelscope.cn/datasets/clip-benchmark/vtab_pcam/) | zeroshot_classification| |
|
||||||
|
| [vtab_resisc45](https://modelscope.cn/datasets/clip-benchmark/vtab_resisc45/) | zeroshot_classification| |
|
||||||
|
| [vtab_smallnorb_label_azimuth](https://modelscope.cn/datasets/clip-benchmark/vtab_smallnorb_label_azimuth/) | zeroshot_classification| |
|
||||||
|
| [vtab_smallnorb_label_elevation](https://modelscope.cn/datasets/clip-benchmark/vtab_smallnorb_label_elevation/) | zeroshot_classification| |
|
||||||
|
| [vtab_svhn](https://modelscope.cn/datasets/clip-benchmark/vtab_svhn/) | zeroshot_classification| |
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
# Other Datasets
|
||||||
|
|
||||||
|
:::{toctree}
|
||||||
|
:maxdepth: 2
|
||||||
|
|
||||||
|
opencompass.md
|
||||||
|
vlmevalkit.md
|
||||||
|
mteb.md
|
||||||
|
clip.md
|
||||||
|
:::
|
||||||
|
|
@ -0,0 +1,43 @@
|
||||||
|
# MTEB
|
||||||
|
|
||||||
|
## CMTEB Evaluation Dataset
|
||||||
|
| Name | Hub Link | Description | Type | Category | Number of Test Samples |
|
||||||
|
|-----|-----|---------------------------|-----|-----|-----|
|
||||||
|
| [T2Retrieval](https://arxiv.org/abs/2304.03679) | [C-MTEB/T2Retrieval](https://modelscope.cn/datasets/C-MTEB/T2Retrieval) | T2Ranking: A large-scale Chinese paragraph ranking benchmark | Retrieval | s2p | 24,832 |
|
||||||
|
| [MMarcoRetrieval](https://github.com/unicamp-dl/mMARCO) | [C-MTEB/MMarcoRetrieval](https://modelscope.cn/datasets/C-MTEB/MMarcoRetrieval) | mMARCO is the multilingual version of the MS MARCO paragraph ranking dataset | Retrieval | s2p | 7,437 |
|
||||||
|
| [DuRetrieval](https://aclanthology.org/2022.emnlp-main.357.pdf) | [C-MTEB/DuRetrieval](https://modelscope.cn/datasets/C-MTEB/DuRetrieval) | A large-scale Chinese web search engine paragraph retrieval benchmark | Retrieval | s2p | 4,000 |
|
||||||
|
| [CovidRetrieval](https://aclanthology.org/2022.emnlp-main.357.pdf) | [C-MTEB/CovidRetrieval](https://modelscope.cn/datasets/C-MTEB/CovidRetrieval) | COVID-19 news articles | Retrieval | s2p | 949 |
|
||||||
|
| [CmedqaRetrieval](https://aclanthology.org/2022.emnlp-main.357.pdf) | [C-MTEB/CmedqaRetrieval](https://modelscope.cn/datasets/C-MTEB/CmedqaRetrieval) | Online medical consultation texts | Retrieval | s2p | 3,999 |
|
||||||
|
| [EcomRetrieval](https://arxiv.org/abs/2203.03367) | [C-MTEB/EcomRetrieval](https://modelscope.cn/datasets/C-MTEB/EcomRetrieval) | Paragraph retrieval dataset collected from Alibaba e-commerce search engine systems | Retrieval | s2p | 1,000 |
|
||||||
|
| [MedicalRetrieval](https://arxiv.org/abs/2203.03367) | [C-MTEB/MedicalRetrieval](https://modelscope.cn/datasets/C-MTEB/MedicalRetrieval) | Paragraph retrieval dataset collected from Alibaba medical search engine systems | Retrieval | s2p | 1,000 |
|
||||||
|
| [VideoRetrieval](https://arxiv.org/abs/2203.03367) | [C-MTEB/VideoRetrieval](https://modelscope.cn/datasets/C-MTEB/VideoRetrieval) | Paragraph retrieval dataset collected from Alibaba video search engine systems | Retrieval | s2p | 1,000 |
|
||||||
|
| [T2Reranking](https://arxiv.org/abs/2304.03679) | [C-MTEB/T2Reranking](https://modelscope.cn/datasets/C-MTEB/T2Reranking) | T2Ranking: A large-scale Chinese paragraph ranking benchmark | Re-ranking | s2p | 24,382 |
|
||||||
|
| [MMarcoReranking](https://github.com/unicamp-dl/mMARCO) | [C-MTEB/MMarco-reranking](https://modelscope.cn/datasets/C-MTEB/Mmarco-reranking) | mMARCO is the multilingual version of the MS MARCO paragraph ranking dataset | Re-ranking | s2p | 7,437 |
|
||||||
|
| [CMedQAv1](https://github.com/zhangsheng93/cMedQA) | [C-MTEB/CMedQAv1-reranking](https://modelscope.cn/datasets/C-MTEB/CMedQAv1-reranking) | Chinese community medical Q&A | Re-ranking | s2p | 2,000 |
|
||||||
|
| [CMedQAv2](https://github.com/zhangsheng93/cMedQA2) | [C-MTEB/CMedQAv2-reranking](https://modelscope.cn/datasets/C-MTEB/C-MTEB/CMedQAv2-reranking) | Chinese community medical Q&A | Re-ranking | s2p | 4,000 |
|
||||||
|
| [Ocnli](https://arxiv.org/abs/2010.05444) | [C-MTEB/OCNLI](https://modelscope.cn/datasets/C-MTEB/OCNLI) | Original Chinese natural language inference dataset | Pair Classification | s2s | 3,000 |
|
||||||
|
| [Cmnli](https://modelscope.cn/datasets/clue/viewer/cmnli) | [C-MTEB/CMNLI](https://modelscope.cn/datasets/C-MTEB/CMNLI) | Chinese multi-class natural language inference | Pair Classification | s2s | 139,000 |
|
||||||
|
| [CLSClusteringS2S](https://arxiv.org/abs/2209.05034) | [C-MTEB/CLSClusteringS2S](https://modelscope.cn/datasets/C-MTEB/C-MTEB/CLSClusteringS2S) | Clustering titles from the CLS dataset. Clustering based on 13 sets of main categories. | Clustering | s2s | 10,000 |
|
||||||
|
| [CLSClusteringP2P](https://arxiv.org/abs/2209.05034) | [C-MTEB/CLSClusteringP2P](https://modelscope.cn/datasets/C-MTEB/CLSClusteringP2P) | Clustering titles + abstracts from the CLS dataset. Clustering based on 13 sets of main categories. | Clustering | p2p | 10,000 |
|
||||||
|
| [ThuNewsClusteringS2S](http://thuctc.thunlp.org/) | [C-MTEB/ThuNewsClusteringS2S](https://modelscope.cn/datasets/C-MTEB/ThuNewsClusteringS2S) | Clustering titles from the THUCNews dataset | Clustering | s2s | 10,000 |
|
||||||
|
| [ThuNewsClusteringP2P](http://thuctc.thunlp.org/) | [C-MTEB/ThuNewsClusteringP2P](https://modelscope.cn/datasets/C-MTEB/ThuNewsClusteringP2P) | Clustering titles + abstracts from the THUCNews dataset | Clustering | p2p | 10,000 |
|
||||||
|
| [ATEC](https://github.com/IceFlameWorm/NLP_Datasets/tree/master/ATEC) | [C-MTEB/ATEC](https://modelscope.cn/datasets/C-MTEB/ATEC) | ATEC NLP Sentence Pair Similarity Competition | STS | s2s | 20,000 |
|
||||||
|
| [BQ](https://huggingface.co/datasets/shibing624/nli_zh) | [C-MTEB/BQ](https://modelscope.cn/datasets/C-MTEB/BQ) | Banking Question Semantic Similarity | STS | s2s | 10,000 |
|
||||||
|
| [LCQMC](https://huggingface.co/datasets/shibing624/nli_zh) | [C-MTEB/LCQMC](https://modelscope.cn/datasets/C-MTEB/LCQMC) | Large-scale Chinese Question Matching Corpus | STS | s2s | 12,500 |
|
||||||
|
| [PAWSX](https://arxiv.org/pdf/1908.11828.pdf) | [C-MTEB/PAWSX](https://modelscope.cn/datasets/C-MTEB/PAWSX) | Translated PAWS evaluation pairs | STS | s2s | 2,000 |
|
||||||
|
| [STSB](https://github.com/pluto-junzeng/CNSD) | [C-MTEB/STSB](https://modelscope.cn/datasets/C-MTEB/STSB) | Translated STS-B into Chinese | STS | s2s | 1,360 |
|
||||||
|
| [AFQMC](https://github.com/CLUEbenchmark/CLUE) | [C-MTEB/AFQMC](https://modelscope.cn/datasets/C-MTEB/AFQMC) | Ant Financial Question Matching Corpus | STS | s2s | 3,861 |
|
||||||
|
| [QBQTC](https://github.com/CLUEbenchmark/QBQTC) | [C-MTEB/QBQTC](https://modelscope.cn/datasets/C-MTEB/QBQTC) | QQ Browser Query Title Corpus | STS | s2s | 5,000 |
|
||||||
|
| [TNews](https://github.com/CLUEbenchmark/CLUE) | [C-MTEB/TNews-classification](https://modelscope.cn/datasets/C-MTEB/TNews-classification) | News Short Text Classification | Classification | s2s | 10,000 |
|
||||||
|
| [IFlyTek](https://github.com/CLUEbenchmark/CLUE) | [C-MTEB/IFlyTek-classification](https://modelscope.cn/datasets/C-MTEB/IFlyTek-classification) | Long Text Classification of Application Descriptions | Classification | s2s | 2,600 |
|
||||||
|
| [Waimai](https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/waimai_10k/intro.ipynb) | [C-MTEB/waimai-classification](https://modelscope.cn/datasets/C-MTEB/waimai-classification) | Sentiment Analysis of User Reviews on Food Delivery Platforms | Classification | s2s | 1,000 |
|
||||||
|
| [OnlineShopping](https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/online_shopping_10_cats/intro.ipynb) | [C-MTEB/OnlineShopping-classification](https://modelscope.cn/datasets/C-MTEB/OnlineShopping-classification) | Sentiment Analysis of User Reviews on Online Shopping Websites | Classification | s2s | 1,000 |
|
||||||
|
| [MultilingualSentiment](https://github.com/tyqiangz/multilingual-sentiment-datasets) | [C-MTEB/MultilingualSentiment-classification](https://modelscope.cn/datasets/C-MTEB/MultilingualSentiment-classification) | A set of multilingual sentiment datasets grouped into three categories: positive, neutral, negative | Classification | s2s | 3,000 |
|
||||||
|
| [JDReview](https://huggingface.co/datasets/kuroneko5943/jd21) | [C-MTEB/JDReview-classification](https://modelscope.cn/datasets/C-MTEB/JDReview-classification) | Reviews of iPhone | Classification | s2s | 533 |
|
||||||
|
|
||||||
|
For retrieval tasks, a sample of 100,000 candidates (including the ground truth) is drawn from the entire corpus to reduce inference costs.
|
||||||
|
|
||||||
|
## MTEB Evaluation Dataset
|
||||||
|
```{seealso}
|
||||||
|
See also: [MTEB Related Tasks](https://github.com/embeddings-benchmark/mteb/blob/main/docs/tasks.md)
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,262 @@
|
||||||
|
# OpenCompass
|
||||||
|
|
||||||
|
Refer to the [detailed explanation](https://github.com/open-compass/opencompass#-dataset-support)
|
||||||
|
|
||||||
|
<table align="center">
|
||||||
|
<tbody>
|
||||||
|
<tr align="center" valign="bottom">
|
||||||
|
<td>
|
||||||
|
<b>Language</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>Knowledge</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>Reasoning</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>Examination</b>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
<tr valign="top">
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Word Definition</b></summary>
|
||||||
|
|
||||||
|
- WiC
|
||||||
|
- SummEdits
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Idiom Learning</b></summary>
|
||||||
|
|
||||||
|
- CHID
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Semantic Similarity</b></summary>
|
||||||
|
|
||||||
|
- AFQMC
|
||||||
|
- BUSTM
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Coreference Resolution</b></summary>
|
||||||
|
|
||||||
|
- CLUEWSC
|
||||||
|
- WSC
|
||||||
|
- WinoGrande
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Translation</b></summary>
|
||||||
|
|
||||||
|
- Flores
|
||||||
|
- IWSLT2017
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Multi-language Question Answering</b></summary>
|
||||||
|
|
||||||
|
- TyDi-QA
|
||||||
|
- XCOPA
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Multi-language Summary</b></summary>
|
||||||
|
|
||||||
|
- XLSum
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Knowledge Question Answering</b></summary>
|
||||||
|
|
||||||
|
- BoolQ
|
||||||
|
- CommonSenseQA
|
||||||
|
- NaturalQuestions
|
||||||
|
- TriviaQA
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Textual Entailment</b></summary>
|
||||||
|
|
||||||
|
- CMNLI
|
||||||
|
- OCNLI
|
||||||
|
- OCNLI_FC
|
||||||
|
- AX-b
|
||||||
|
- AX-g
|
||||||
|
- CB
|
||||||
|
- RTE
|
||||||
|
- ANLI
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Commonsense Reasoning</b></summary>
|
||||||
|
|
||||||
|
- StoryCloze
|
||||||
|
- COPA
|
||||||
|
- ReCoRD
|
||||||
|
- HellaSwag
|
||||||
|
- PIQA
|
||||||
|
- SIQA
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Mathematical Reasoning</b></summary>
|
||||||
|
|
||||||
|
- MATH
|
||||||
|
- GSM8K
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Theorem Application</b></summary>
|
||||||
|
|
||||||
|
- TheoremQA
|
||||||
|
- StrategyQA
|
||||||
|
- SciBench
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Comprehensive Reasoning</b></summary>
|
||||||
|
|
||||||
|
- BBH
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Junior High, High School, University, Professional Examinations</b></summary>
|
||||||
|
|
||||||
|
- C-Eval
|
||||||
|
- AGIEval
|
||||||
|
- MMLU
|
||||||
|
- GAOKAO-Bench
|
||||||
|
- CMMLU
|
||||||
|
- ARC
|
||||||
|
- Xiezhi
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Medical Examinations</b></summary>
|
||||||
|
|
||||||
|
- CMB
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</tbody>
|
||||||
|
<tbody>
|
||||||
|
<tr align="center" valign="bottom">
|
||||||
|
<td>
|
||||||
|
<b>Understanding</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>Long Context</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>Safety</b>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<b>Code</b>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
<tr valign="top">
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Reading Comprehension</b></summary>
|
||||||
|
|
||||||
|
- C3
|
||||||
|
- CMRC
|
||||||
|
- DRCD
|
||||||
|
- MultiRC
|
||||||
|
- RACE
|
||||||
|
- DROP
|
||||||
|
- OpenBookQA
|
||||||
|
- SQuAD2.0
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Content Summary</b></summary>
|
||||||
|
|
||||||
|
- CSL
|
||||||
|
- LCSTS
|
||||||
|
- XSum
|
||||||
|
- SummScreen
|
||||||
|
|
||||||
|
</details>
|
||||||
|
|
||||||
|
<details open>
|
||||||
|
<summary><b>Content Analysis</b></summary>
|
||||||
|
|
||||||
|
- EPRSTMT
|
||||||
|
- LAMBADA
|
||||||
|
- TNEWS
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Long Context Understanding</b></summary>
|
||||||
|
|
||||||
|
- LEval
|
||||||
|
- LongBench
|
||||||
|
- GovReports
|
||||||
|
- NarrativeQA
|
||||||
|
- Qasper
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Safety</b></summary>
|
||||||
|
|
||||||
|
- CivilComments
|
||||||
|
- CrowsPairs
|
||||||
|
- CValues
|
||||||
|
- JigsawMultilingual
|
||||||
|
- TruthfulQA
|
||||||
|
|
||||||
|
</details>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Robustness</b></summary>
|
||||||
|
|
||||||
|
- AdvGLUE
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
<td>
|
||||||
|
<details open>
|
||||||
|
<summary><b>Code</b></summary>
|
||||||
|
|
||||||
|
- HumanEval
|
||||||
|
- HumanEvalX
|
||||||
|
- MBPP
|
||||||
|
- APPs
|
||||||
|
- DS1000
|
||||||
|
|
||||||
|
</details>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</tbody>
|
||||||
|
</table>
|
||||||
|
|
||||||
|
|
@ -0,0 +1,78 @@
|
||||||
|
# VLMEvalKit Backend
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
For more comprehensive instructions and an up-to-date list of datasets, please refer to [detailed instructions](https://aicarrier.feishu.cn/wiki/Qp7wwSzQ9iK1Y6kNUJVcr6zTnPe?table=tblsdEpLieDoCxtb).
|
||||||
|
```
|
||||||
|
|
||||||
|
## Image Understanding Dataset
|
||||||
|
|
||||||
|
Abbreviations used:
|
||||||
|
- `MCQ`: Multiple Choice Questions;
|
||||||
|
- `Y/N`: Yes/No Questions;
|
||||||
|
- `MTT`: Multiturn Dialogue Evaluation;
|
||||||
|
- `MTI`: Multi-image Input Evaluation
|
||||||
|
|
||||||
|
|
||||||
|
| Dataset | Dataset Names | Task |
|
||||||
|
|-------------------------------------------------------------|--------------------------------------------------------|--------------------------|
|
||||||
|
| [**MMBench Series**](https://github.com/open-compass/mmbench/): <br>MMBench, MMBench-CN, CCBench | MMBench\_DEV\_[EN/CN] <br>MMBench\_TEST\_[EN/CN]<br>MMBench\_DEV\_[EN/CN]\_V11<br>MMBench\_TEST\_[EN/CN]\_V11<br>CCBench | MCQ |
|
||||||
|
| [**MMStar**](https://github.com/MMStar-Benchmark/MMStar) | MMStar | MCQ |
|
||||||
|
| [**MME**](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation) | MME | Y/N |
|
||||||
|
| [**SEEDBench Series**](https://github.com/AILab-CVC/SEED-Bench) | SEEDBench_IMG <br>SEEDBench2 <br>SEEDBench2_Plus | MCQ |
|
||||||
|
| [**MM-Vet**](https://github.com/yuweihao/MM-Vet) | MMVet | VQA |
|
||||||
|
| [**MMMU**](https://mmmu-benchmark.github.io) | MMMU\_[DEV_VAL/TEST] | MCQ |
|
||||||
|
| [**MathVista**](https://mathvista.github.io) | MathVista_MINI | VQA |
|
||||||
|
| [**ScienceQA_IMG**](https://scienceqa.github.io) | ScienceQA\_[VAL/TEST] | MCQ |
|
||||||
|
| [**COCO Caption**](https://cocodataset.org) | COCO_VAL | Caption |
|
||||||
|
| [**HallusionBench**](https://github.com/tianyi-lab/HallusionBench) | HallusionBench | Y/N |
|
||||||
|
| [**OCRVQA**](https://ocr-vqa.github.io)* | OCRVQA\_[TESTCORE/TEST] | VQA |
|
||||||
|
| [**TextVQA**](https://textvqa.org)* | TextVQA_VAL | VQA |
|
||||||
|
| [**ChartQA**](https://github.com/vis-nlp/ChartQA)* | ChartQA_TEST | VQA |
|
||||||
|
| [**AI2D**](https://allenai.org/data/diagrams) | AI2D\_[TEST/TEST_NO_MASK] | MCQ |
|
||||||
|
| [**LLaVABench**](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild) | LLaVABench | VQA |
|
||||||
|
| [**DocVQA**](https://www.docvqa.org)+ | DocVQA\_[VAL/TEST] | VQA |
|
||||||
|
| [**InfoVQA**](https://www.docvqa.org/datasets/infographicvqa)+ | InfoVQA\_[VAL/TEST] | VQA |
|
||||||
|
| [**OCRBench**](https://github.com/Yuliang-Liu/MultimodalOCR) | OCRBench | VQA |
|
||||||
|
| [**RealWorldQA**](https://x.ai/blog/grok-1.5v) | RealWorldQA | MCQ |
|
||||||
|
| [**POPE**](https://github.com/AoiDragon/POPE) | POPE | Y/N |
|
||||||
|
| [**Core-MM**](https://github.com/core-mm/core-mm)- | CORE_MM (MTI) | VQA |
|
||||||
|
| [**MMT-Bench**](https://mmt-bench.github.io) | MMT-Bench\_[VAL/ALL]<br>MMT-Bench\_[VAL/ALL]\_MI | MCQ (MTI) |
|
||||||
|
| [**MLLMGuard**](https://github.com/Carol-gutianle/MLLMGuard) - | MLLMGuard_DS | VQA |
|
||||||
|
| [**AesBench**](https://github.com/yipoh/AesBench)+ | AesBench\_[VAL/TEST] | MCQ |
|
||||||
|
| [**VCR-wiki**](https://huggingface.co/vcr-org/) + | VCR\_[EN/ZH]\_[EASY/HARD]_[ALL/500/100] | VQA |
|
||||||
|
| [**MMLongBench-Doc**](https://mayubo2333.github.io/MMLongBench-Doc/)+ | MMLongBench_DOC | VQA (MTI) |
|
||||||
|
| [**BLINK**](https://zeyofu.github.io/blink/) | BLINK | MCQ (MTI) |
|
||||||
|
| [**MathVision**](https://mathvision-cuhk.github.io)+ | MathVision<br>MathVision_MINI | VQA |
|
||||||
|
| [**MT-VQA**](https://github.com/bytedance/MTVQA)+ | MTVQA_TEST | VQA |
|
||||||
|
| [**MMDU**](https://liuziyu77.github.io/MMDU/)+ | MMDU | VQA (MTT, MTI) |
|
||||||
|
| [**Q-Bench1**](https://github.com/Q-Future/Q-Bench)+ | Q-Bench1\_[VAL/TEST] | MCQ |
|
||||||
|
| [**A-Bench**](https://github.com/Q-Future/A-Bench)+ | A-Bench\_[VAL/TEST] | MCQ |
|
||||||
|
| [**DUDE**](https://arxiv.org/abs/2305.08455)+ | DUDE | VQA (MTI) |
|
||||||
|
| [**SlideVQA**](https://arxiv.org/abs/2301.04883)+ | SLIDEVQA<br>SLIDEVQA_MINI | VQA (MTI) |
|
||||||
|
| [**TaskMeAnything ImageQA Random**](https://huggingface.co/datasets/weikaih/TaskMeAnything-v1-imageqa-random)+ | TaskMeAnything_v1_imageqa_random | MCQ |
|
||||||
|
| [**MMMB and Multilingual MMBench**](https://sun-hailong.github.io/projects/Parrot/)+ | MMMB\_[ar/cn/en/pt/ru/tr]<br>MMBench_dev\_[ar/cn/en/pt/ru/tr]<br>MMMB<br>MTL_MMBench_DEV<br>PS: MMMB & MTL_MMBench_DEV <br>are **all-in-one** names for 6 langs | MCQ |
|
||||||
|
| [**A-OKVQA**](https://arxiv.org/abs/2206.01718)+ | A-OKVQA | MCQ |
|
||||||
|
| [**MuirBench**](https://muirbench.github.io) | MUIRBench | MCQ |
|
||||||
|
| [**GMAI-MMBench**](https://huggingface.co/papers/2408.03361)+ | GMAI-MMBench\_VAL | MCQ |
|
||||||
|
| [**TableVQABench**](https://arxiv.org/abs/2404.19205)+ | TableVQABench | VQA |
|
||||||
|
|
||||||
|
|
||||||
|
```{note}
|
||||||
|
**\*** Partial model testing results are provided [here](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard), while remaining models cannot achieve reasonable accuracy under zero-shot conditions.
|
||||||
|
|
||||||
|
**\+** Testing results for this evaluation set have not yet been provided.
|
||||||
|
|
||||||
|
**\-** VLMEvalKit only supports inference for this evaluation set and cannot output final accuracy.
|
||||||
|
```
|
||||||
|
|
||||||
|
## Video Understanding Dataset
|
||||||
|
|
||||||
|
| Dataset | Dataset Name | Task |
|
||||||
|
| ---------------------------------------------------- | --------------------------- | --------------------- |
|
||||||
|
| [**MMBench-Video**](https://mmbench-video.github.io) | MMBench-Video | VQA |
|
||||||
|
| [**MVBench**](https://github.com/OpenGVLab/Ask-Anything/blob/main/video_chat2/MVBENCH.md) | MVBench_MP4 | MCQ |
|
||||||
|
| [**MLVU**](https://github.com/JUNJIE99/MLVU) | MLVU | MCQ & VQA |
|
||||||
|
| [**TempCompass**](https://arxiv.org/abs/2403.00476) | TempCompass | MCQ & Y/N & Caption |
|
||||||
|
| [**LongVideoBench**](https://longvideobench.github.io/) | LongVideoBench | MCQ |
|
||||||
|
| [**Video-MME**](https://video-mme.github.io/) | Video-MME | MCQ |
|
||||||
|
|
||||||